
基于Spark 框架的电影推荐系统的实现
2021-03-30 01:06赖丽君
鄂州大学学报 2021年2期
赖丽君
(泉州经贸职业技术学院信息技术系,福建泉州362000)
推荐系统通过分析海量信息来挖掘、 学习用户的兴趣或喜好,结合推荐技术及系统支撑框架,为每个用户推荐其感兴趣的产品或内容。 目前解决“信息过载”的两种重要的手段即是利用推荐系统与搜索引擎[1],两者均能协助用户获取感兴趣的内容, 不同于搜索引擎, 推荐系统在进行深度挖掘、分析用户数据,推测用户兴趣和喜好时是通过选用合适的推荐算法来进行处理, 把用户主动搜索的方式转化为系统主动推送其感兴趣的内容或产品,为用户提供智能化、个性化的推荐服务。
1 Spark 框架
推荐系统目前已经广泛应用于电影、 音乐、电子商务等网站中,并取得较好的推荐效果,推荐系统以往是基于Hadoop 框架下的MapReduce 的分布式计算平台的,能解决海量数据的高效存储和分布式计算问题, 但是随着网络和大数据技术的发展,对推荐系统的计算速度、实时性要求更高,而传统的基于Hadoop 计算平台不能满足需要,Spark 框架以其计算速度快、 实时性强等特点, 逐渐取代MapReduce 成为目前热门的推荐系统框架。
Apache Spark 是用于针对大规模数据处理的一种统一分析引擎[2]。 Spark 由Scala 语言实现,支持Python、Java、Scala 等语言开发, 可以和其他大数据工具如Hadoop、Kafka 等很好地整合。 Spark是基于内存计算的,且具有易操作的特点,能够快速、 简洁、 高效的进行并行化应用的开发[3]。 与Hadoop 相比,Spark 因其数据结构RDD 强大的计算能力, 对于处理数据挖掘与机器学习算法更加适合[4],能够更高效地实现MapReduce 的操作。
2 算法模型
2.1 协同过滤算法
基于协同过滤、内容的推荐、混合推荐的这类的算法是传统的推荐方法[5],在这三种算法中,当前使用最为广泛, 最为经典的方法则是协同过滤算法, 如矩阵因子分解借助于用户与项目或产品之间的交互信息,向用户提供推荐内容。 协同过滤算法目前有很多,主流的算法有两种,分别是基于模型的协同过滤与基于邻域的协同过滤。
基于邻域的协同过滤算法在进行推荐的过程中,通过对邻域进行搜索来计算相似度,主要相似度的计算为用户之间的相似度与项目之间的相似度,它的实现相对简单,但也存在过分依赖用户的评分的缺点,特别是数据很稀疏时,推荐系统的预测精度将会急剧下降, 这将导致无法为新用户进行推荐的问题出现[6],基于模型的协同过滤算法在这种情况下, 它的预测速度将会更快且算法的可扩展性更强, 有一种典型的代表就是使用最小二乘法(ALS)进行矩阵分解算法。
2.2 交替最小二乘(ALS)算法
ALS 同时考虑了用户和物品两个方面, 将用户和物品的关系抽象为一个三元组<用户, 物品,用户对物品的评分>,并表示为一个评分矩阵,由于用户不可能对所有物品进行评分, 所以R 矩阵注定是一个稀疏矩阵,缺失不少评分。 为填充空值,ALS 算法采用“隐语义模型”,通过降维的方法来补全“用户-物品”矩阵,并对没有出现的值进行估计[7],这使得稀疏矩阵的问题能得到有效地解决。在ALS 算法中, 首先假设有m 个用户,n 个物品,用矩阵Rm×n来表示用户对物品的评分, 即矩阵元素Rij代表评分值为第i 个用户对第j 个物品的评分[8]。 Rm×n矩阵的规模通常很大,而且数据稀疏,为填充缺失值,ALS 算法假设评分矩阵是近似低秩的,将Rm×n分解为两个子矩阵Xm×k(用户对隐含特征的偏好矩阵),Yk×n(物品包含隐含特征的矩阵),使两个矩阵相乘近似得到Rm×n,其中k<<min(m,n)即k 值远小于m 和n,这样达到降维的目的,公式如下:
Rm×n≈Xm×kYTk×n
为了使得矩阵X 与矩阵Y 的乘积与原始矩阵R 值尽可能接近,ALS 采用最小化平方误差损失函数方法,同时对损失函数加上正则化项后表示如下:
L(X,Y)=∑u,i(rui-xuTyi)2+λ(|xu|2+|yi|2)
其中λ 是正则化项系数。 xu作为用户u 的隐含特征向量,yi是物品i 隐含的特征向量。 而rui则表示用户u 对物品i 的评分。
具体求解步骤如下:
(1)将矩阵Y 进行固定,再对xu求导[8],公式如下:
xu=(YTY+λI)-1YTru
(2)再固定矩阵X,然后对yi 求导[8],公式如下:
yi=(XTX+λI)-1XTri
在迭代过程中,随机对X,Y 进行初始化,交替对X、Y 进行迭代优化, 不断更新X 和Y 的值,直至收敛。
3 基于Spark 框架的电影推荐系统设计和实现
3.1 系统总体设计
本文基于Spark 生态框架及Mysql、IDEA、Node.js 等软件平台构建电影推荐系统。 由HDFS分布式存储结构来对海量的历史评分数据进行保存,为充分测试系统性能,使用的评分数据源于网络,在使用之前在Pycharm 平台进行预处理后,在IDEA 平台上进一步清洗数据,用户在浏览网站时的行为及轨迹产生的实时数据由Spark Streaming处理,系统将用户注册信息、最新评分数据、浏览历史记录等信息存储到Mysql 数据库中。 通过MLlib 平台实现ALS 算法, 训练数据获得最佳的推荐模型,产生推荐结果,向用户推荐电影,同时对电影进行点击率、评分排名处理,设计基于电影排名推荐功能, 与ALS 算法一起形成组合推荐模式,向用户推荐电影。 系统工作流程图如图1:
平乐古镇对原有古镇建筑进行保留,并对当地居民进行扶持,使其具有原始居民的人气。利用已经开发的建筑用地进行经营。不仅造福当地居民,增加当地居民的收入,而且利用当地居民对建筑群增加生机,营造古镇氛围吸引游客观光及停留。在业态经营上缺少多样性和独特性,在熙攘的人群中古镇之景韵味有所欠缺。
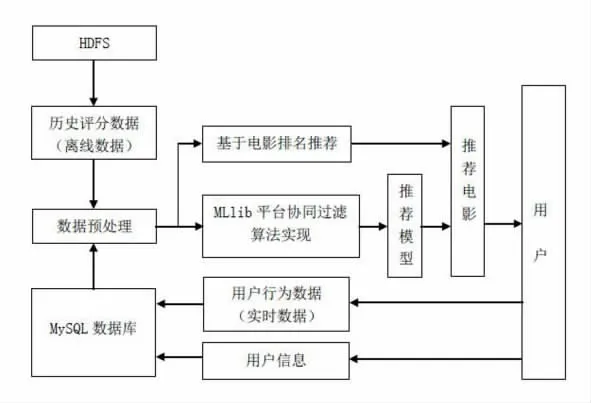
图1 系统总体设计
3.2 系统功能设计
系统主要分为用户信息,电影推荐,电影信息管理三个主要功能模块,用户信息模块分为注册、登录、用户信息管理功能,电影推荐模块主要有个性化电影推荐功能、用户评分功能,为解决ALS 算法存在的冷启动问题, 在此模块还增加热门电影推荐功能和好剧推荐功能, 使系统在向老用户推荐电影的同时, 也能为新用户提供电影推荐,此外,为进一步缓解冷启动问题,在用户注册模块增加年龄和对电影类别的偏好的信息填写, 增加用户特征属性,对于新用户进行辅助推荐。系统功能模块如图2:
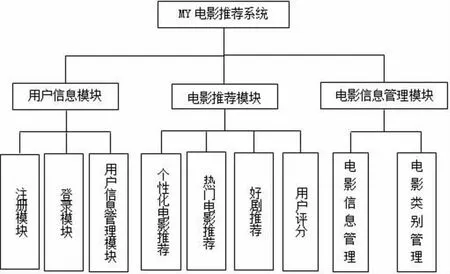
图2 系统功能设计
3.3 Spark 大数据处理框架搭建
在实验室搭建Spark 生态环境, 安装配置Kafka、Zookeeper、flume、MLlib、Spark SQL、Spark Streaming 等生态组件,搭建Hadoop 平台,配置1个Master 节点和2 个work 节点,采用其HDFS 分布式存储历史评分数据, 对于实时产生的评分数据,将其存于MySQL 数据库中。安装IDEA 平台采用Scala 编程语言开发程序, 安装Node.js 进行前端开发。 搭建Spark 环境部分效果如图3。
3.4 系统实现
3.4.1 算法实现
Spark 生态组件MLlib 是实现部分机器学习算法的平台, 其中的spark.ml 包有提供实现交替最小二乘算法的函数,在ALS 算法中,主要的实现过程如下几个步骤:
(1)对数据集和Spark 生态环境进行初始化操作, 通过语句(import org.apache.spark.mllib.recommendation.{ALS,ALSModel})来加载交替最小二乘ALS 算法模型。
(2)数据集转换,将样本评分数据分为3 部分,训练数据占70%,将最靠近最近时间段的数据作为测试数据占20%(通过用户评分表中的timestamp 排序获取),校验数据占10%。
(4)在对ALS 模型进行训练的过程中,既进行显式反馈数据模型的训练, 同时也对隐式反馈数据进行模型训练,通过调整参数,多次迭代训练,产生最佳模型。
图3 Spark 环境搭建
(5)通过模型预测评分,计算与实际评分间的均方根误差RMSE,值越小越接近收敛。
(6)将推荐结果写入数据库,向用户推荐电影。
3.4.2 功能实现
(1)用户信息模块。 实现了用户注册、登录、用户信息管理三个子功能模块, 用户注册时尽可能简化用户操作,除了填写基本信息外,需要选择感兴趣的电影种类,以便对新用户进行电影推荐。 用户信息管理模块用于管理用户个人信息, 用户可以对自己的信息进行修改、完善,系统管理员也可查询和管理网站所有用户信息。 用户注册界面效果如图4。
(2)电影推荐模块。 这部分是网站的核心模块,实现了个性化电影推荐、热门电影推荐、好剧推荐、用户评分等四个子功能模块,用户选择对电影进行星级评分,并发表评论,后台管理员可以查看所有评分和评论并进行管理, 网站实现对每个用户提供个性化电影推荐服务, 并组合近一个月内点击率高及评论数多的热门电影, 和评分排名靠前的好剧进行推荐。 部分效果如图5、图6、图7所示。
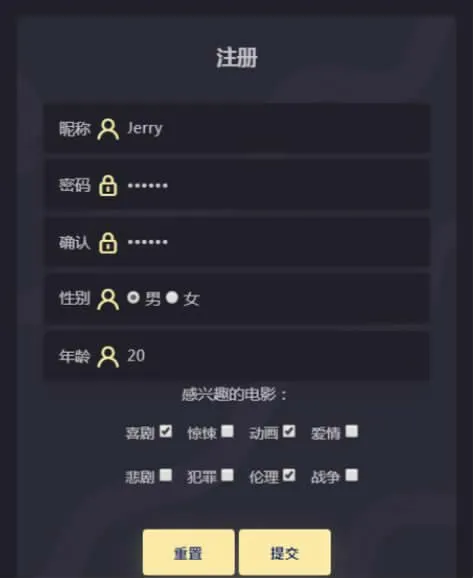
图4 用户注册界面
(3)电影信息管理模块。 实现电影信息管理、电影分类管理子功能模块, 便于网站管理员对电影信息进行查询、增加、修改、删除等操作。
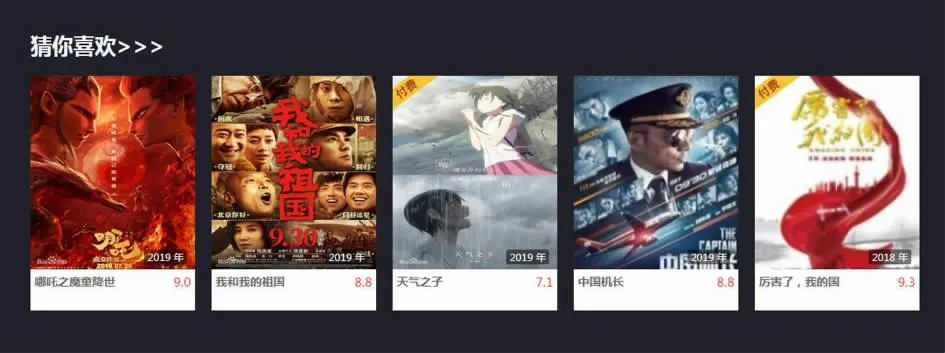
图5 猜你喜欢
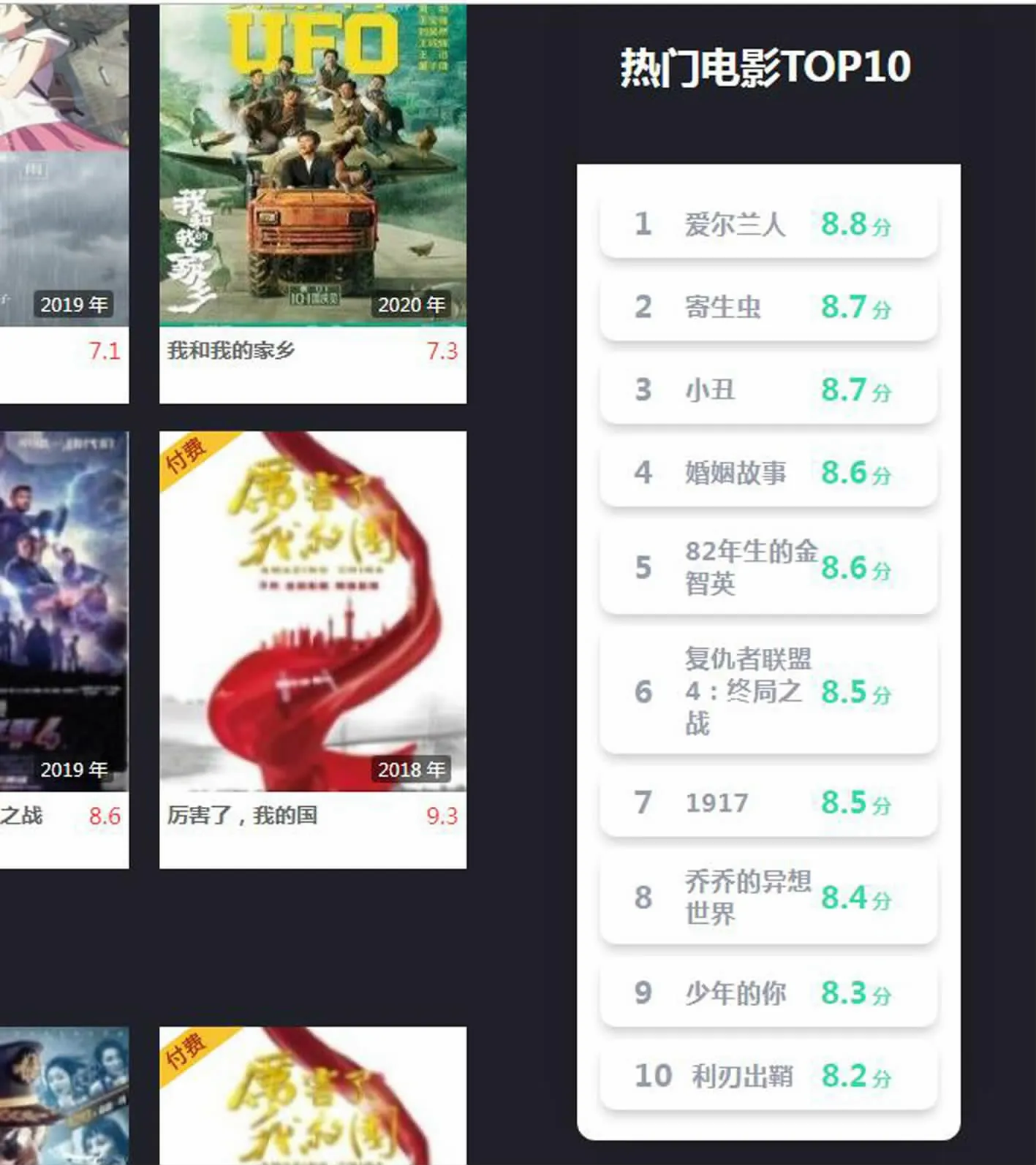
图6 热门电影推荐
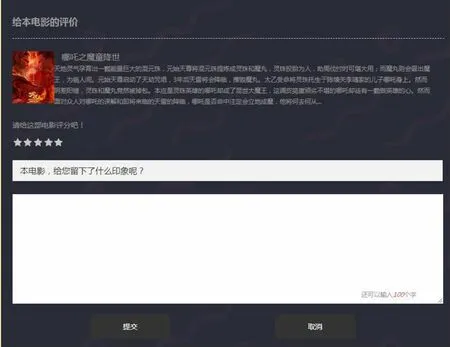
图7 电影评价
4 结语
大数据环境下, 推荐系统已进入到人们生活的各个方面, 为人们提供了更加丰富和便捷的体验, 应用前景广泛。 本文设计并实现了一个基于Spark 生态环境的电影推荐系统, 通过在Spark 框架中采用ALS 算法模型对数据进行反复的训练、优化调整,最终取得推荐的最佳模型,向用户提供个性化电影推荐服务。 面对新用户,推荐的挑战主要是冷启动问题,该系统以ALS 推荐算法为主,辅以热门电影和优质好剧推荐,同时将电影分类,以用户兴趣为出发点,结合电影点击率排名、评分排名向新用户提供电影推荐服务, 有效缓解冷启动问题。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
小学生学习指导(低年级)(2022年5期)2022-05-31
疯狂英语·初中天地(2021年11期)2021-02-16
少年漫画(艺术创想)(2019年2期)2019-06-06
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
小天使·一年级语数英综合(2015年8期)2015-07-06
