
基于BERT-BiGRU-ATT的社交媒体用户身份识别研究
2021-03-30 06:55张翼翔芦天亮
中国人民公安大学学报(自然科学版) 2021年1期
张翼翔,芦天亮,李 默
(中国人民公安大学信息网络安全学院, 北京 100038)
0 引言
近年来,伴随着互联网的兴起与飞速发展,人们的生活维度随之拓宽,社会活动轨迹不仅限于自然社会,网络空间逐渐演变成为人类社会的“第二类生存空间”。层见叠出的信息互联技术,譬如电子邮件、即时通讯工具、论坛、社交媒体、博客等,带给人们更快、更加有效的方式进行信息交流交换。据Global Web Index(GWI)发布的2020年第一季度《社交媒体趋势报告》显示,全球网民中有63%的用户社交媒体持续在线,高于2019年的56%,这一趋势还将继续上升。由此可见,社交媒体已经成为人们日常生活中越来越重要的工具。
由于网络传播具有匿名性与高效性等特点,近些年互联网犯罪数量呈指数级别增长,网络空间失范现象时有发生。同时,社交媒体目前正在成为网民表达诉求、反映民意的重要节点,但也逐渐成为宣泄情绪、散播负面信息的场所,更有甚者成为各政治力量同台竞技的新舞台。
通过识别社交媒体用户,关联同一自然人的不同虚拟身份,有助于降低网络匿名性带来的风险,协助网络监管者的监管活动,保护公民合法权益。目前如微博,推特等主流社交媒体平台由于其及时性,碎片性特点,使得平台信息载体多为短文本。短文本的内容简短、主题多元化、语法表达具有随意性等特点导致已有长文本识别模式无法应用于短文本上,也同时导致短文本的特征提取更加困难。本文的方法将使用BERT[1]预训练模型,结合门控循环单元网络(GRU)并引入注意力机制,实现对短文本作者的分类。加以实验证明该方法在短文本作者识别问题上具有较高准确率。
1 相关工作
关于文本作者身份分析的研究最初起源于语言学研究领域关于文体即文学风格[2]的归纳分析。由于社交网络的增长,越来越多关于作者识别的研究集中在网络文本的分析上。Mohtasseb等人[3]结合了心理学的工具语言探索与字词技术(LIWC)首次对博客作者进行识别。Pillay等人[4]针对网络论坛文本采用无监督与有监督学习相结合的方法训练出分类器实现了论坛发文作者的识。Cristani等人[5]基于二元聊天对话语料库,采用由会话提炼的特征值进行分析,从而识别出文本作者。Inches等人[6]首次使用统计数据研究会话文档完成在线即时聊天的作者归属问题研究。Hollingsworth[7]提出以一种基于最相邻词频排名的作者识别方法,使用DepWords代替原文标记单词以发掘单词间依赖关系对于作者识别的帮助,并在小说作者识别上得到较好反馈。但上述研究主要针对英文语料,不适用于处理中文文本。
国内学者针对中文文本开展了大量的研究,起初关于文本作者识别研究的主要对象偏向于长文本,如长篇文章或书籍作者的判定。王少康等人[8]以文章语句节奏控制角度为切入点,构建节奏特征矩阵,采用KL距离算法于点积法的结合衡量矩阵差异,提出最优区拟合的中轴线提取算法。李晓军等人[9]将复杂网络理论引入利用文本特征的作者识别研究领域,选取新闻报道文章做数据集,构造复杂网络模型提取文本特征,利用文本风格相似度识别作者身份。Tang等人[10]选择押韵,体裁,叠词等特征采取监督机器学习,实现小说作者与多位诗歌作家的同一作者认定。
但是,上述方法也存在弊端,在面对篇幅小、表述方式灵活的短文本时,以文体风格为主的研究便显得捉襟见肘。由于社交媒体的蓬勃发展,其信息载体大多为短文本,于是针对短文本作者身份识别的研究应运而生。祈瑞华等人[11]面向短文本博客,抽取字符、词汇、句法等特征建立多层面文体风格特征的模型并验证了该方法的准确性。Yang等人[12]提出一种对时间信息及单词顺序较为敏感的主题漂移模型(TDM)从写作风格和主题方向入手来完成作者识别任务。Zhang等人[13]将文本中语句的语法解析树编码得到分布式表示,即为每个词构造与之唯一对应的嵌入向量,将路径编码置于该单词对应的语法树中,并将获得的向量输入CNN模型中完成文本作者的认定并取得较好成效。徐晓霖等人[14]采用深度学习的方法提出了CABLSTM模型,可高质量完成中文微博作者识别任务。冯勇等人[15]提出了融合中文FastText、融合词频- 逆文本频率及隐含狄利克雷分布的短文本分类方法,在中文短文本分类上有较高精确率。
在以上针对短文本作者识别的研究中,文本特征提取起到至关重要的作用。在现有研究中,特征提取多以人工特征建模为主,需要复杂的设计处理。部分研究结合深度学习,使用词嵌入(word embedding)的方式取加权平均对短文本进行特征提取,但该方法最大的弊端是无法处理多义词。结合近几年兴起的采用神经网络识别作者的思路,本文提出了采用BERT模型提取短文本特征生成词向量,利用带有注意力机制的双向GRU网络进行训练,最终通过A-softmax分类器进行分类的作者识别模型。
2 社交媒体作者身份识别模型
本文提出的身份识别模型结构分为4层:文本输入层、Bi-GRU层、自注意力机制层以及A-softmax分类层。BERT-BiGRU-ATT短文本作者识别模型结构如图1所示。
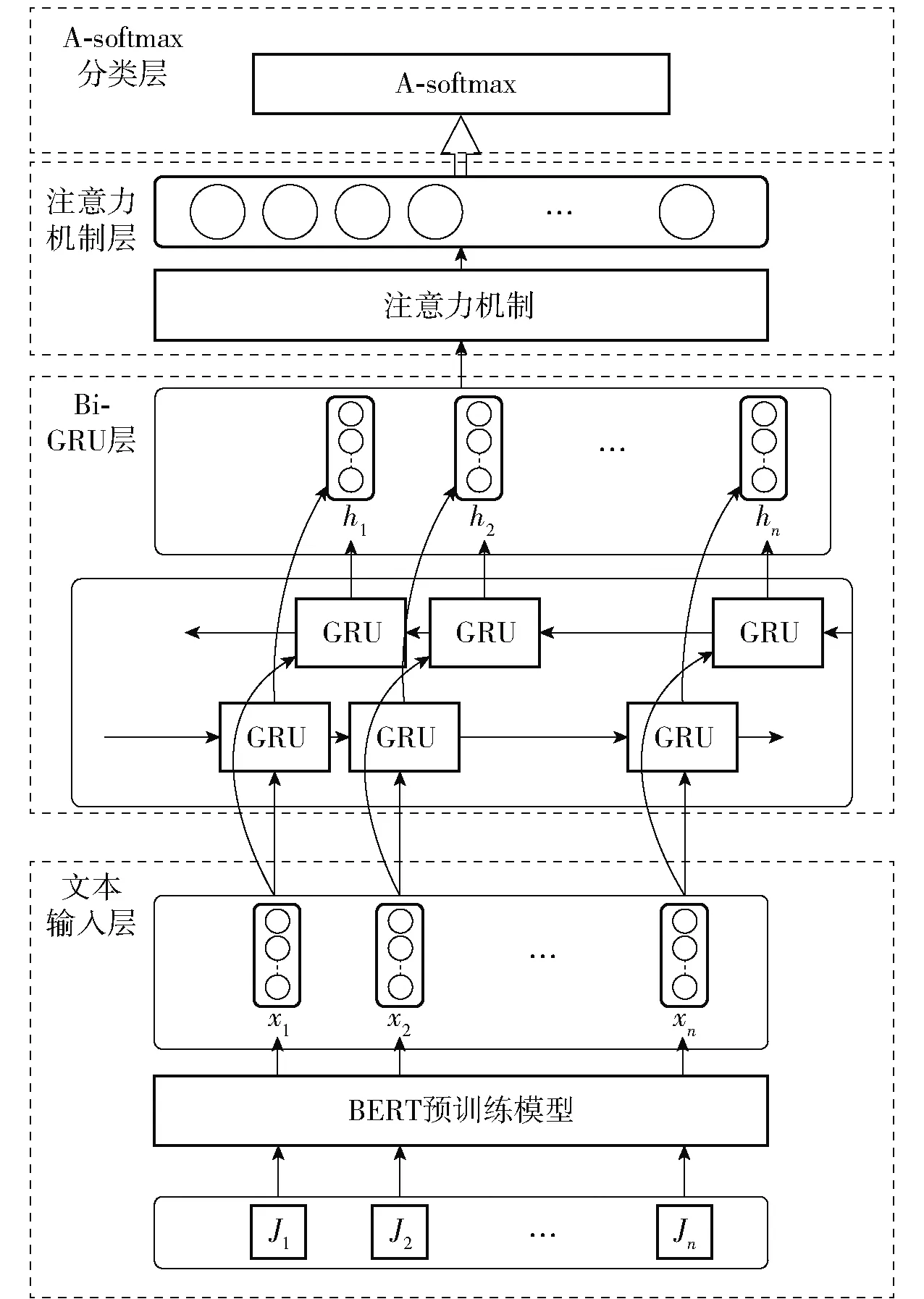
图1 BERT-BiGRU-ATT模型结构
文本输入层中针对短文本作者识别中文本特征提取难度较大的情况,为避免复杂的特征设计,针对中文文本利用预训练的BERT模型生成特征向量。将上述高质量的向量输入下游模型。
在文本深层次信息提取中采用了Bi-GRU神经网络作为下游模型,GRU是目前较为流行的循环神经网络(RNN)的一种,在LSTM的基础上诞生,适用于学习长期依赖。它相较LSTM而言训练参数更少,训练更快且需要更少的数据来泛化,十分贴合短文本作者识别的特点,本文采用的Bi-GRU由正向GRU和逆向GRU组合而成,其优点在可很好地理解文本上下文信息,捕获文本语境特征。
注意力机制层对Bi-GRU提取到的特征向量加以优化,更好地为重要信息内容分配权重的同时获得文本的更深层特征。
最后将得到的特征向量输入A-softmax层进行分类,完成短文本作者的识别。
2.1 BERT模型
BERT模型是谷歌人工智能研究团队于2018年提出的里程碑式无监督预训练语言模型,其英文全称为Bidirectional Encoder Representation from Transformers,即来自Transformer的双向编码器表示。Transformer由编码器与解码器组成,是一种使用注意力机制搭建的序列到序列模型,能注意输入序列的不同位置以计算该序列表示能力。而BERT模型从名称上不难看出是一个用双向多层Transformer编码器作为特征提取器的预训练模型,其结构如图2所示。

图2 BERT模型结构
此前的语言训练模型(例如Word2Vec)都是单向的,只能从左至右或从右至左,无法得到整个文本的综合特征信息,这导致面对单词多义情况时容易出错,而BERT能很好解决这一问题。BERT在预训练方法上采用两个非监督训练任务,分别为遮盖语言建模(Masked LM)与下一句预测(Next sentence prediction)。
2.1.1 遮盖语言建模
该任务可以简单概括为随机屏蔽部分输入的单词,然后根据未被屏蔽的内容对已屏蔽的单词实现预测。在训练过程中随机屏蔽15%的单词,考虑到屏蔽标记对模型的影响,在这15%的单词中随机挑选十分之一替换成其他单词,五分之四被替换为“[MASK]”字符,剩下的维持原状。
2.1.2 下一句预测
该任务可以概括成判断连续的两句话中的第二句话是否紧随前句。其目的在于让模型更好理解两个句子之间的联系,提高上下文把控能力。
2.2 双向门控循环单元网络
GRU是循环神经网络的一种[16],是对LSTM的改进产物。GRU对LSTM的结构进行精简,将LSTM中的输入门与遗忘门合并为更新门,并与重置门共同组成GRU单元。故相较LSTM,GRU在同等算力下训练时间大大减少,GRU单元结构如图3所示。
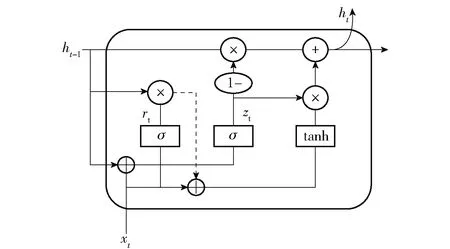
图3 GRU单元结构

zt=σ(wz[ht-1,xt]+bz)
(1)
rt=σ(wr[ht-1,xt]+br)
(2)
(3)
(4)
由于GRU网络中信息的传递是单向的,本文采用的BiGRU网络由一对方向相反的GRU单元组成,系双向传递的网络,弥补了普通GRU网络的单向传递缺陷,可以更充分捕获语句序列的文本特征。
式(5)、(6)分别表示t时刻前向、后向GRU单元隐含层输出,对输出拼接可得到BiGRU在该时刻的最终输出,如式(7)所示。
(5)
(6)
(7)
2.3 注意力机制
注意力机制在2014年被Mnih等人[17]首次提出,是一种用来提升基于循环神经网络中encoder+decoder模型效果的机制,在自然语言处理等领域有着广泛应用。在自然语言处理中,注意力机制可以赋予句子中的每个词不同权重,能够更好地为重要信息分配权重,从而更加准确理解序列语义。首先利用激活函数形成对齐模型,随后获取注意力概率分布,最后将得到的权重矩阵与输入向量相乘得到最终输出结果。注意力机制公式如下:
mt=tanh(Wvht+bv)
(8)
(9)
(10)
上述式中,ht为BiGRU网络层的输出,Wv是注意力模型可调节权重,bv为偏置项,式(9)计算结果αt系注意力权重矩阵,其中权重值用kv表示,C为经过注意力模型计算后的特征向量。
2.4 A-softmax
A-softmax可以看作softmax的增强版本,在较小的数据集合上有着良好的效果且具有不错的可解释性。与softmax相比,A-softmax算法使得决策边界更加严格与分离,对更具区分性的特征学习有更大驱动力。关于A-softmax的损失函数定义如下:
(11)

3 实验与分析
3.1 实验环境及配置
为验证本文所提出模型的有效性,在如表1软硬件环境中进行实验。

表1 实验环境及配置表
3.2 数据集
本文数据集,分为微调BERT预训练模型所需的大量短文本博文与实验数据两部分,语料均来自微博。采用python的scrapy框架结合账号池与IP池基于weibo.cn站点进行微博信息爬取,共收集了26.8 G微博用户数据,经过清洗后的数据构成为用户名与该用户所有发文内容,从中挑选发文量超过2 000条的共20名用户制作测试集用作最后的模型准确率测试,共对应51 249条短文本,将上述20人的用户名作为该用户发文内容标签。剩余数据中的短文本内容用作训练语料,本文使用的是哈尔滨工业大学发布的基于全词遮罩(Whole Word Masking)技术的中文预训练模型BERT-wwm,其语料为通用的中文维基,采用了哈尔滨工业大学LTP作为分词工具,对于微博这类灵活的短文本敏感度会稍差,故加以使用微博语料训练集进一步预训练。
3.3 评价指标
本文使用在作者识别中普遍使用的精确率(Precision)、召回率(Recall)以及调和平均数(F1 Score)3项指标来测量各个模型的有效性。精确率表示所有预测正例样本的准确率,召回率用来度量有多少正例样本被分为正例,F1则对精确率与召回率进行调和,得出整体评价。各指标定义公式如下:
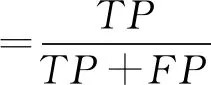
(12)
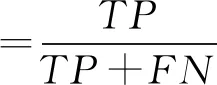
(13)

(14)
其中,TP表示正确预测正例样本的数量,被误判为正例样本的负例样本的数量用FP表示,FN代表被误判成负例样本的正例样本数。
3.4 实验结果及分析
接下来将进行两组实验分别对本文提出的BERT-BiGRU-ATT模型进行作者识别有效性验证。一个实验将比较BERT预训练模型与Word2Vec、fastText与GPT 3种不同词向量表示工具在对于短文本词向量提取方面效果的优劣,实验结果如表2所示;另一个实验将BERT-BiGRU-ATT模型作者识别效果结果同SVM、TextCNN与BERT-BiGRU 3种模型进行对比,实验结果如表3所示。

表2 不同词向量提取效果对比实验结果

表3 不同模型效果对比实验结果
最终结果表明,BERT在词向量提取效果方面均优于其他3种方式。在模型效果上,相较其他3种模型,BERT-BiGRU-ATT模型在精确率、召回率、F1值上的表现均处于领先地位。
由第一个实验的结果发现,采用不同词向量提取方式对模型的效果存在不同程度的影响。fastText方法优于Word2Vec,是因为fastText在训练词向量时将subword纳入考虑范围,且引入了字符级n-gram,使之更好地处理长词与低频词汇,在面对训练语料库以外的单词时也完成了词向量构建工作。GPT是一个生成式预训练模型,其特征抽取器采用了多层Transformer解码器构成,与fastText方法相比GPT能够捕捉语义信息以及识别多义词,所以采用GPT作为词向量工具的模型各方面效果均优于采用fastText的模型,F1值提升了6.3%。虽然BERT与GPT均采用transformer,但BERT使用的是双向编码,相比单向捕获信息的GPT模型,BERT能利用全部上下文信息,在词向量提取方面会更有优势。
从第2个实验结果来看,除SVM以外的3种模型在中文短文本作者识别任务中的精确率、召回率以及精确率与召回率的调和平均数数值上均超过84%,这表明将深度学习的方法运用在作者识别领域是可行且有效好的效果。与TextCNN进行比较,BERT-BiLSTM 模型的F1值高出8.4%,原因在于TextCNN采用窗口滑动的方式提取文本特征,是单向的,而BiLSTM可以联系上下文捕获文本特征,并且利用BERT预训练模型进行词嵌入可以提取更具表示能力的词向量,更好地满足下游任务。BERT-BiGRU-ATT与BERT-BiGRU相比,F1值提升了1.6%,由此可见的是增加注意力机制可以赋予重要的信息更高权重从而进一步提取有效地提取文本特征。
4 结语
针对中文短文本作者的识别,本文运用BERT模型提取文本特征,采用混合了BiGRU网络与注意力的深度学习模型,对提取的文本特征进行深层次特征提取,最后利用A-softmax实现作者识别。与传统的作者识别模型对比发现,本文所提出的BERT-BiGRU-ATT模型在针对短文本作者的分类上效果更好,可以运用到实战中帮助互联网监管者打击网络犯罪。
本文的研究仍存在改进空间,其一是BERT预训练模型使用的短文本语料可以大量补充,但是需要足够的算力与资源支撑模型的训练,其二可以采取提高文本分类效果这一思路来提升作者识别准确度,如可以引入对抗学习网络对文本分类效果进行提升。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
