
基于LCSS的异常轨迹检测算法
2021-03-30 06:23张厚禄唐云祁
中国人民公安大学学报(自然科学版) 2021年1期
张厚禄,唐云祁,王 兴
(中国人民公安大学侦查学院, 北京 100038)
0 引言
移动互联网时代,微型移动终端成为了人们最为重要的生产生活工具。这些移动终端设备在极大便利人们生产生活的同时产生了海量轨迹数据。轨迹数据是某一时段内行为人在物理空间中的活动轨迹通过移动终端设备的记录感知成为其在电磁空间中的反映。因此,轨迹数据对于行为人在物理空间中的行为具有一定的指示性,可通过海量轨迹数据挖掘行为人在物理空间中的行为信息。异常轨迹检测是基于轨迹数据挖掘行为人在物理空间中的异常行为,研究这类问题一方面可以针对某一类特定案件中作案人的行为轨迹特点,设计轨迹预警模型,实现对该类案件的预警预测;另一方面,可以针对某一案件中作案人使用的危险化学品(如汽油等)等信息,设计涉案物品采购异常轨迹检测模型,挖掘嫌疑群体,提供侦查范围。
公共安全领域中的异常轨迹指的是可能给社会安全带来危害的非常规活动,包括案前踩点、购买危险化学品等。不同案件中,异常轨迹的具体内涵可能不同。如在以汽油为助燃剂的爆恐案件中,作案人往往需要预先准备大量汽油等助燃剂。这些危险化学品由工厂、实验室或其他场所管控流通,因此作案人需要在作案前多次前往这些地点采购这些危险化学品。此时作案人的轨迹便为异常轨迹。本文针对该类案件案发前作案人异常轨迹,设计自动检测算法,实现从海量轨迹数据中筛选侦查目标。为方便表述,下文中将“涉案危险化学品销售地点”称为“敏感地点”。
算法思路是首先按照停留点连续情况将轨迹切分小段,再使用逆编码方式通过GPS坐标获取地点名称;进而根据地点名称,使用LCSS(Longest Common Subsequence,最长公共子序列)算法计算各个轨迹小段之间的相似度;相似度低于给定阈值且地名为敏感地点,则作为疑似异常轨迹输出。
1 研究现状
从异常检测的领域看,异常模式挖掘的方法有很多,面向的应用场景也大多不同。陈锦阳等[2]提出了一种基于豪斯多夫(Hausdorff)距离的轨迹子段距离相似度算法,其利用特征点概念将轨迹划分成小段,分别计算各子段之间的距离相似度,以达到聚类的目的。周等人[3]则先将轨迹简化成有序线段,然后采用DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)算法将轨迹分类,依次检测时空异常轨迹点。李志等[4]人先通过轨迹获得用户的群体结构信息,然后使用多种异常模型识别用户在不同场景(如群体、时空和事件等)中的异常现象。上述算法都有其优点,但其解决的问题与本文不同,因此只能做参考而不能与本文算法对比优劣。
从相似度比较方法的领域看,较为经典的相似度比较方法有欧氏距离、DTW(Dynamic Time Warping,动态时间归整)算法、ED(Edit Distance ,编辑距离)算法、LCSS算法等。欧氏距离算法最为经典,但其计算复杂度高,抗噪声能力差;DTW动态时间规整算法可以将时间序列拉伸或压缩比较其相似性,但是同样对噪声敏感;编辑距离算法将序列看作是字符串,通过计算两字符串变成完全一致需要多少步操作体现两者的相似度;LCSS算法只对两序列之间的最长公共子序列敏感,因此具有较强的抗干扰和整体性。由于最长公共子序列算法只对公共子序列敏感的特性,近两年许多研究人员都开始用最长公共子序列算法挖掘相似轨迹,比如张萍[5]提出一种先将轨迹对齐,然后使用最长公共子序列算法挖掘的方法;还有王前东[6]提出一种经典轨迹相似度快速算法,该算法先将实时轨迹进行压缩然后利用经典轨迹的点与实时轨迹线段之间的距离计算LCSS长度,并将LCSS长度与经典轨迹点数的比值作为经典轨迹的相似度。涉及到LCSS在轨迹领域应用的文章如李颖等人针对大货车轨迹相似度量的研究[7]、裴剑等人对相似车辆轨迹查找的研究[8]以及陈对笔尖运动轨迹的研究[9],还有其他文章[10-12]研究多侧重于利用LCSS算法抗干扰性强和运算速度较快的特点,很少有人关注LCSS算法的逻辑和人们日常活动的方式有天然的相似性。如常见的三点一线活动模式:宿舍—图书馆—食堂,体现在轨迹上可能还会有绕路或者其他不重要的地点,但是在使用最长公共子序列比较时,很容易就能发现该活动模式的几个关键地点和活动方式。本文仅针对连续停留点子轨迹,因此LCSS算法更适合本文场景。
2 异常轨迹检测方法
2.1 常见的异常检测方法
2.1.1 DTW算法
与LCSS算法类似,DTW算法也是针对时间序列匹配的计算方法,主要应用在语音识别中。DTW可以将时间序列的局部延伸或者缩小,以达到计算二者规整路径距离,并以此衡量两序列之间的相似性
如果有两个时间序列P={P1,P2,…,Pn}、Q={Q1,Q2,…,Qm},那么两个序列之间的相似度公式如下:
DTW(P,Q)=f(n,m)
(1)
(2)
其中‖·‖ 是两点之间的欧氏距离,f(·)是规整路径距离。DTW算法较欧氏距离有一定进步,但对于个别点的差异特别敏感,即很短时间内的差异就会导致整体相似度受到很大影响,并且对于时段不重合的轨迹效果也很有限。
2.1.2 ED算法
ED算法是Vladimir Levenshtein提出的,也用来度量两个序列的相似程度,它将序列看作一个单词,通过求从一个词W1转换为另一个词W2所需要的最少单字符编辑操作次数,其中单字符编辑操作仅限3种:插入(插入一个字符)、删除(删除一个字符)、替换(将其中一个字符替换成另一个字符)。单字符编辑次数越少相似度越高。ED算法按照单字符编辑次数距离计算相似度。如果“W1”转换成“W2”,那么经过计算后单字符编辑次数距离是1,两字符之间的相似度D为:
(3)
ED距离是一种较为均衡的算法,但是也受两组序列长度影响,如果两个序列之间长度相差较大,该方法将多余出的部分都作为多出的编辑距离,因此ED距离算法对序列长度极为敏感,不适合长度不定的时间序列。
2.2 基于LCSS的异常轨迹检测算法流程
定义1(轨迹,Trajectory):设T为对象Obj(人或者物)在给定时间段[t1,tn]内的轨迹,则T可以表示为按时间先后顺序排列的位置点的集合T={P1,P2,P3,…,Pn},其中Pi为对象Obj在时刻ti的位置点(xi,yi),i和n为自然数。
定义2(轨迹停留区域):轨迹t={Pj,Pj+1,…,Pj+k-1}为轨迹T={P1,P2,P3,…,Pj,Pj+1,…,Pj+k-1,Pn}在时间段[tj,tj+k-1]上的子轨迹,其中i、j、k和n为正整数,2≤k≤(n-j+1),i≤k-1。设V为速度阈值,如果子轨迹t内任意两个相邻轨迹点满足:

(4)
则将子轨迹t所覆盖的区域称为轨迹T中的停留区域。
图1所示为本文提出的基于LCSS的异常轨迹检测算法框图,算法的输入数据是某人在一段时间内(如1个月或者6个月)的轨迹数据,经过停留区域检测、停留区子轨迹归一化、LCSS相似度计算和敏感地点验证4个处理步骤后,最终得到异常的停留区。在停留区域检测模块,轨迹数据被划分为若干停留区域,未被停留区域覆盖的轨迹点被直接去除;在停留区子轨迹归一化模块,每一个停留区子轨迹中的轨迹点被匹配至具体地址,并根据地址将其编码为数字组成的字符串(如“北京市西城区木樨地南里1号”被编码为“100038”),进而将整个停留区子轨迹按时序组合编码为一个字符序列;在相似度计算模块,采用LCSS算法计算各停留区子轨迹编码间的相似度,并根据各停留区间的相似度判别得到异常停留区候选集;最后在敏感地点验证模块,将异常停留区候选集和敏感地点集的交集作为异常停留区域输出。
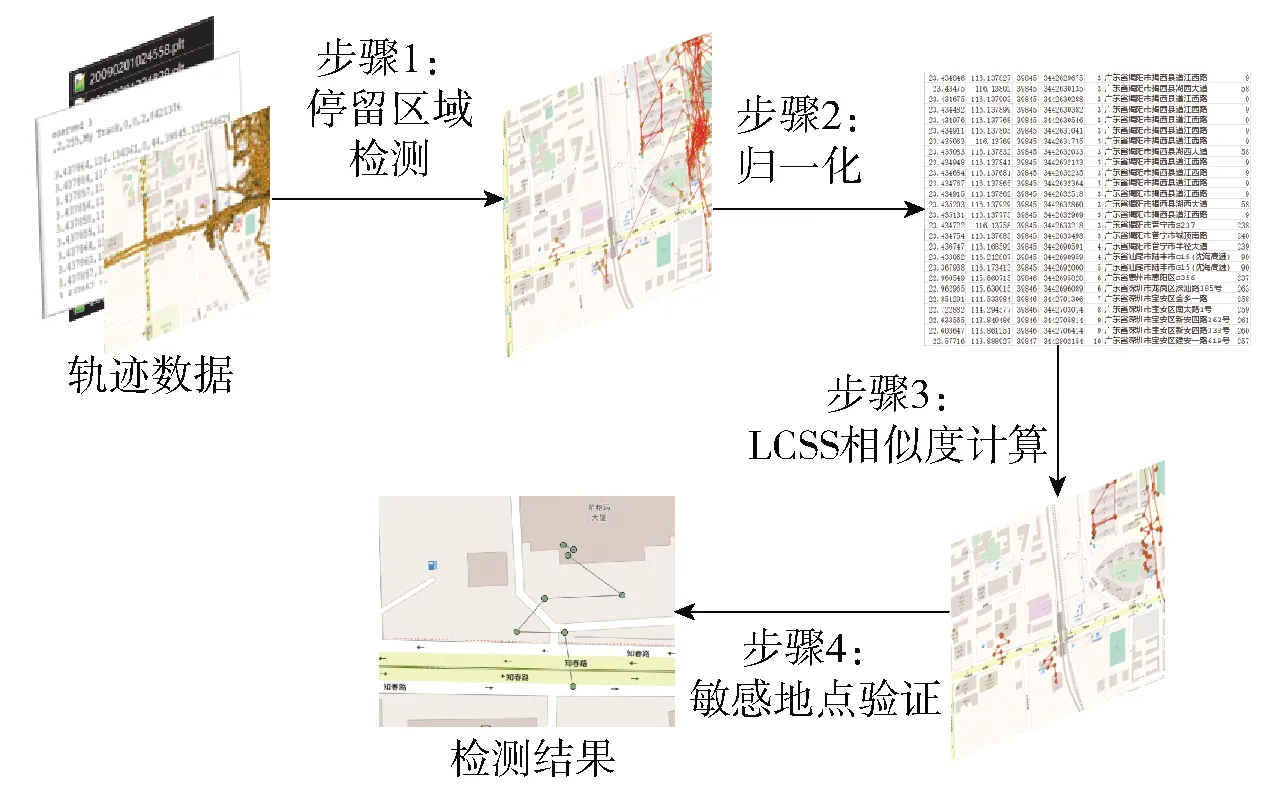
图1 算法框图
具体实现过程可分为以下4个步骤。
2.2.1 停留区域检测
一般常见数据集形式是{经纬度,时间}。在数据集中隐含了速度、间隔时间的信息,因此需要预处理将点及点中隐含的信息利用起来,提前排除无关的点。根据经纬度可以计算出两点之间的距离,结合时间就可以计算出两点之间活动的平均速度;根据时间间隔大小判断轨迹是否有长时间中断,以此作为划分子轨迹的依据。计算两点Pi,Pj之间距离的公式为:
(5)
其中,d(Pi,Pj)为两点之间的距离,Lat代表纬度,Lng代表经度。
日常活动时,绝大多数活动都要在低速状态下完成,并且本文算法针对的场景中,为区分路过敏感地点和到敏感地点活动之间的区别,在预处理阶段就将高速运动的部分过滤掉,以降低运算量,减少干扰量,方便后续算法设计。预处理仅保留轨迹中的停留区域,输出的数据形式仍为{经纬度,时间},但是原本的轨迹已经被切割成多个子轨迹。
2.2.2 停留区子轨迹归一化
同一段子轨迹的停留区域一般都是同一个地点,但是也存在有些对象移动速度低于停留点判断阈值v,持续时间较长,以至于同一段轨迹的停留区域起点和终点在逆编码时对应的地点相距甚远[13]。实际上,一段轨迹中的停留区域实际上多由两种模式混合在一起的,一种是停留在某处很长时间基本不移动,另一种是之前提到的以低于速度阈值的速度缓慢移动。多数情况下,这两种模式往往互相混合,共同构成停留区域内的活动,并且也都包含停留信息,因此很难区分出开来。由于在停留区域内也存在移动较远的情况,所以不能简单认为同一停留区域内的点都是同一地点。
百度地图逆地理编码服务可以将坐标点(经纬度)转换为对应位置信息(如所在行政区划、周围地标点分布)等,该服务同时支持全球行政区划位置描述和周边地表POI(Point of Information)数据召回。申请AK(Access Key)后可以直接在python中调用接口进行批量匹配。
为方便后面比较最长公共子序列相似度,本文算法先匹配详细地址,然后将详细地址编码为字符串,不同的地点对应不同的字符。这样在比较最长公共子序列时,每个子轨迹都是一串地址编码序列,只比较代表详细地址的字符串和地点对应的时间即可。归一化后输出数据的形式为{经纬度,时间,详细地址编码}
2.2.3 LCSS相似度计算
LCSS算法比较相似度的原理是直接取两条轨迹中最长的公共子序列,得到的子序列有序但不连续,因此LCSS算法对于长度的敏感度较差,受时段不重合的轨迹影响也较小。设γ为阈值,对于A、B,二者的LCSS相似度计算如下:

(6)
数据集经过预处理和标注后,可以直接比较各停留点子轨迹之间的相似度并使用相似度阈值及该模式出现频次区分是否符合日常活动模式。假设实验数据集共m条子轨迹,则每一段子轨迹与其他任意(m-1)条子轨迹的相似度满足下列条件时将该子轨迹作为异常输出:
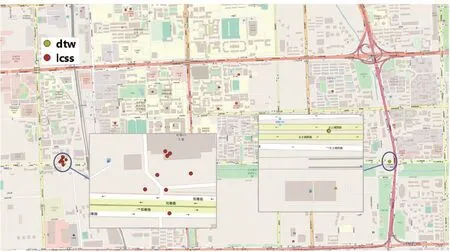
DLCSS(i) (7) 其中DLCSS(i)为第i条子轨迹与其他(m-1)条子轨迹中任意一条的相似度,Dts为相似度阈值,该阈值用以区分两条轨迹的重合部分是否足以认定为重合。如果相似度高于Dts,则两条轨迹认定为相似;如果低于阈值,则认定为不相似;如果该轨迹同其他所有轨迹的相似度都低于阈值,则将该轨迹输出为异常轨迹做下一步验证。 2.2.4 敏感地点验证 本文规定的敏感地点一般不会涉及类似保密单位改名或隐名的情况,所以直接做匹配验证[14]即可。百度地图API的POI召回功能中,可以通过输入经纬度,输出该经纬度附近一定范围内的指定类型地点,如果指定敏感地点类型空匹配,则证明其不是异常轨迹,如果输出地点是敏感地点,则作为异常输出。 实验环境为Windows10 64位系统,Intel Core i7-9750H @2.60 GHz CPU,16 GB内存,512GB+1TB固态硬盘,算法环境为MATLAB R2016a、Python 3.7、JupyterNotebook 6.0.1,GIS(Geo-Information system,地理信息系统)软件QGIS 3.12.2。数据集使用微软Geolife数据集[15-17],Geolife数据集是微软研究Geolife项目从2007年4月到2012年8月收集的182个用户的轨迹数据。这些数据包含了一系列按时间先后产生的点,每一个点包含经纬度、海拔等信息,共17 621条轨迹。 数据集中有些记录很短,总共才几百个点,缺乏周期活动参考,挖掘出的结果也没有什么意义。因此只保留点数较多的用户后,共13个用户(标号分别为:00,02,03,04,05,22,24,30,35,36,38,39,52),共2 279段轨迹。文中敏感地点以加油站举例实验。事先在GIS平台上结合实际地图标注了哪些用户访问了加油站。13个用户中,用户03有日常活动中在加油站停留的行为,7名用户(02、05、22、24、35、38、52)没有在加油站停留过,5名用户(00,04,30,36,39)有异常访问加油站的行为,其中用户30有在2个不同加油站停留的行为。 首先简介数据集的预处理。为降低噪声干扰、减少计算量,先删除移动速度大于1 m/s的点,然后去掉相对孤立的噪声点(在停留区域内连续数小于6的)。之后在JupyterNotebook中调用百度地图API,获取大致位置,并根据详细位置依次对应数字。调用接口配置如下(考虑到隐私,下文出现的AK删减了一位),其中location是经纬度形式: parameters={′ak′:′2iGZ9yaYi5Es8YoqZ2 noeF2ddsAZlG′,′output′:′json′,′coordtype′:′gcj02ll′,′latest_admin′: ′1′,′extensions_road′:′true′,′location′:location} base = ′http:∥api.map.baidu.com/reverse_geocoding/v3/′ response = requests.get(base, parameters) answer = response.json() 百度API返回的逆编码信息如下: {′status′: 0, ′result′: {′location′: {′lng′: 116.39988041445216, ′lat′: 39.91116559139336}, ′formatted_address′: ′北京市西城区人大会堂西路′, ′business′: ′前门,大栅栏,西单′, ′addressComponent′: {′country′: ′中国′, ′country_code′: 0, ′country_code_iso′: ′CHN′, ′country_code_iso2′: ′CN′, ′province′: ′北京市′, ′city′: ′北京市′, ′city_level′: 2, ′district′: ′西城区′, ′town′: ′′, ′town_code′: ′′, ′adcode′: ′110102′, ′street′: ′人大会堂西路′, ′street_number′: ′′, ′direction′: ′′, ′distance′: ′′}, ′pois′: [], ′roads′: [{′name′: ′人大会堂西路′, ′distance′: ′186′}, {′name′: ′广场西侧路′, ′distance′: ′268′}], ′poiRegions′: [], ′sematic_description′: ′′, ′cityCode′: 131}} 返回字段中formatted_address是详细地址,business是周边商圈,roads是具体街道。为提高地点范围精度,根据formatted_address字段,对应不同数字,方便之后相似度对比。 连续停留点子轨迹本就是分段的,直接选择子轨迹按顺序两两计算相似度即可,计算结果按轨迹顺序输出为N*N(N为子轨迹数量)矩阵形式。计算过相似度后,如果某条轨迹和其他轨迹的相似度都不大于相似度阈值,则将这条轨迹输入到百度地图接口中,返回其每个点附近50 m的敏感地点POI数据。如果返回值为空,则该点附近没有敏感地点;若返回值中有敏感地点,则作为异常输出。输出的敏感地点格式如下: [{′name′: ′壳牌(晶车月靓站)′, ′location′: {′lat′: 39.851217, ′lng′: 116.396679}, ′address′: ′北京市丰台区临泓路4号附近′, ′province′: ′北京市′, ′city′: ′北京市′, ′area′: ′丰台区′, ′street_id′: ′56fae0a3d4b892b64c6d462d′, ′telephone′: ′(010)87268571′, ′detail′: 1, ′uid′: ′97b848e0581e62 61c26c148e′}] 为观察不同阈值下算法变化,取0~1之间的不同阈值,比较FAR(False Acceptance Rate,错误接受率)和FRR(False Rejection Rate,错误拒绝率)。结果如表1所示。 表1 不同阈值的FAR和FRR 访问加油站的6名用户(00,03,04,30,36,39),在不同阈值下挖掘出的异常子轨迹数目(缺省用户的输出都为0)如表2所示。 表2 不同阈值下输出异常的轨迹子段数量 为验证文中算法(阈值取0.4)起到的效果,对比算法有两个:(1)仅经过预处理处理,不比较相似度直接POI匹配的;(2)经过预处理和DTW算法比较相似度的。DTW算法[18-19]适用于较短的时间序列数据,可以动态规划获得最佳匹配路径对应的匹配距离。选取各方法输出不同的结果,其异常轨迹数目(Number)以及F值如表3所示。 表3 不同方法处理得到轨迹数目和F值 图2 实验结果图示 就实验结果而言,不同相似度阈值对结果产生影响很小是最不符合实验前预想的部分,按照预想,阈值应该能起到筛选不同出现场景的功能,不同阈值输出的结果会有较大差别,但是实验结果中,绝大多数测试轨迹对阈值并不敏感。试验后,回顾整个实验流程,发现在阈值筛选部分起到的作用完全符合构想,随着阈值增大,输出的轨迹数量越来越多。只是数据集中,涉及到加油站的活动轨迹确实与其他活动轨迹有极大差别,并且出现频次很少,导致阈值即便取0.1,这类轨迹都能通过筛选和POI验证,03用户在阈值为0.5时输出轨迹的变化也能佐证阈值确实生效了。还有一个例证是在用户30的活动轨迹中,其常去的加油站被过滤掉了,只输出了不常去的地址,可见提出的算法实现了挖掘预期异常的效果。在实验时,阈值越小筛选出的点越少,计算时间也会更短。因此在实际应用时,阈值取值越小,相似度比较算法过滤掉的轨迹越多,可以根据实际应用场景和数据类型决定阈值的大小。 本文算法和未经相似度比较筛选的相比,筛选出的点更少,并且多次访问的地点也都没有输出,相对于直接检索关键字减少了许多干扰信息。运算速度上,选用了3个数据集进行了测试,算法全套流程走完(阈值0.5时)分别用时39秒、59秒、104秒,同硬件、同环境、同数据集情况下,未经相似度比较的方法用时分别为91秒、131秒、300秒。可见算法能有效提高该异常场景检测的速度。 同动态时间规划算法(DTW)处理的数据比较结果显示,DTW算法输出的结果有许多高频次访问的点,也就是相似度比较上出了问题,一些相似的轨迹区域计算成了不相似,显然就效果很差。并且,DTW算法对序列长度也很敏感,不同长度的序列比较相似度差别会很大。因此,对背景中的异常检测,本文算法获得的数据准确率和F值都更高。 本文提出了一种新的基于GPS坐标数据的异常轨迹检测算法,并在公开数据集Geolife上对算法性能进行了测试。从实验结果可知,文中算法在实验数据集中识别出了所有异常访问敏感地点的轨迹。并且和其他方法比起来,该算法运算速度更快,区分日常活动和异常活动轨迹的能力更强。但是对于本文提出的针对场景,仍然有无法挖掘的情况,比如作案人如果本身是危险物品管理人员,这种情况是本文算法识别不出来的,还需要其他方式方法补全。3 实验及分析
3.1 实验数据及配置
3.2 数据预处理
3.3 实验结果及分析




4 结论
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
小学生导刊(2018年34期)2018-12-18
思维与智慧·上半月(2018年11期)2018-11-30
母子健康(2015年1期)2015-02-28
