
基于生成对抗网络的激光雷达超分辨率
2021-03-28 04:43黄丹阳田传印
电子元器件与信息技术 2021年12期
黄丹阳,田传印
(中汽数据(天津)有限公司,天津 300300)
0 引言
激光雷达是一类基于光学遥感技术进行立体环境探测的传感器,其内部射频器件经过高速旋转,可以周期性地向环境发射脉冲线束进行扫描,采集到的回波以若干包含三维坐标和回波强度的向量集合表示,构成具有环状结构的“点云”。激光雷达在多领域中被广泛使用,包括地理测绘、室内定位、无人驾驶等[1]。激光雷达的线束是指雷达内部垂直方向上的射频单元的数量,决定了在垂直方向上的探测范围角度和探测角度分辨率,然而高线束激光雷达价格昂贵,不利于民用研究和推广。为了解决上述问题,本文基于深度学习提出了一种激光雷达超分辨率模型,该模型以低线束激光雷达点云为输入,通过卷CNN输出高线束激光雷达点云。
1 生成对抗网络架构
近年来,生成对抗网络(Generative Adversarial Networks,GAN)作为一种新式的基于半监督或无监督学习的深度神经网络架构,在多种数据生成领域掀起研究热潮[2]。本文构建了GAN,并基于CNN分别构建了激光雷达超分辨率模型和激光雷达判别模型。其中激光雷达超分辨率模型作为生成网络,经过CNN的升维映射完成点云超分辨率;激光雷达判别模型在训练中负责识别高线束点云数据是来自数据集中的真实样本还是生成网络的合成样本,随后激光雷达判别模型的识别结果将作为网络损失回传给生成网络进行训练,GAN的架构如图1所示。

图1 生成对抗网络架构
2 卷积神经网络构建
CNN是一类典型的人工神经网络,它在原始的感知机基础上提出了感受野概念,通过对网络权重局部连接和区域共享大大削减的神经网络的参数[3],不仅有效避免模型的过拟合,还能更好地提取局部相关性特征,因此在图像和视频中的模式识别问题中被广泛地应用[4-5]。本文采用CNN构建了激光雷达超分辨率模型和判别网络。
2.1 激光雷达超分辨率模型
图2为激光雷达超分辨率模型的网络结构。该网络主要由卷积层、残差模块和上采样模块三部分共同组成。模型的输入是单通道距离图,进入网络后首先经过一层卷积核为9的卷积层,浅层网络侧重对图像中的纹理、边缘等通用特征的提取,而并非抽象语义特征,对于超分辨率任务而言,在较大的感受野中提取浅层特征有助于表征环境中的细节,并对激光雷达数据的邻域相似性进行更好地学习。此外,为了避免分辨率损失,在主干部分取缔池化层,并为所有卷积层设置对应的边缘补全[6]。
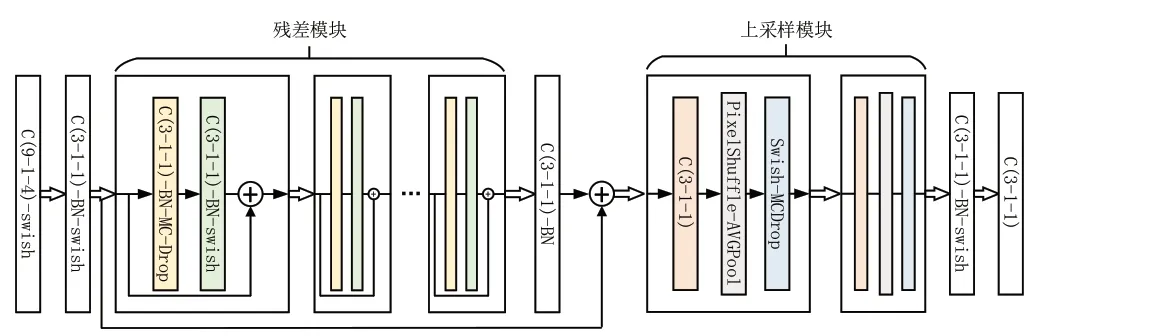
图2 生成网络的结构
超分辨率模型的主干由残差模块构成[7],残差模块由若干个残差单元组成,残差单元如图2中所示。每个残差单元由两个3-1-1(卷积核-卷积步长-边缘填充)的卷积层串联而成。每个残差单元的末端都部署二维蒙特卡罗Dropout,这是由于在对深度图进行卷积后不可避免地在图像边缘带来噪声,大量的Dropout可以模拟噪声分布。低线束数据经过多次处理,统计输出数据后可以得到模型的不确定性,进而可以像贝叶斯神经网络那样利用模型的不确定性进行正则化,过程见式(1)。其中X是对低线束数据进行N次处理的集合,yj是输出结果中第j个点,当所有结果在此点上的方差大于均值的λ倍,我们认为模型在此点的预测不确定性过大,予以剔除。
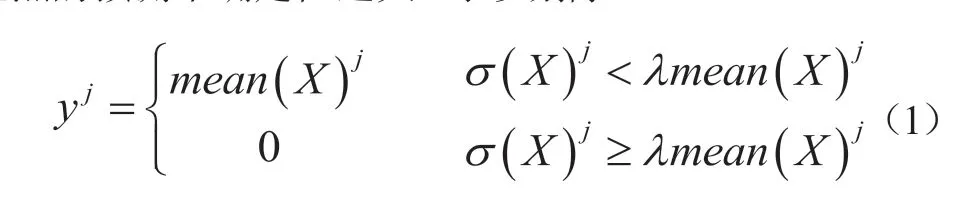
残差单元的输入经过一系列处理后,再与自身逐点求和,就作为一个残差单元的最终输出。深层的网络会带来过拟合风险,而残差单元的跨层连接令网络中的信息前馈更密集,有效提高深层特征的利用率,实现多尺度感受野特征的复用,从而避免过拟合风险。在网络的反向传递训练中,梯度也同样跨越式回传,提升网络的训练效率。
为了获得高线束的激光雷达数据,利用上采样模块实现对三维细节的重建。本文基于卷积、非对称平均池化和像素重组构建上采用模块,其结构如图2的末端所示。经过上采样后,利用两层3-1-1的卷积进行整合,完成整个生成网络的处理。
2.2 激光雷达判别模型
在GAN中判别网络是二元分类器,它本质上是一种可学习损失函数。判别网络对高线束激光雷达数据的来源进行分类,区分其来自数据集还是生成网络的合成样本。二分类结果在训练中交替式反馈至生成网络,不断优化生成网络的权重,促使生成网络合成数据更加真实;同时生成网络在训练中不断合成的数据作为负样本训练判别网络,二者通过对抗式训练共同收敛。本文构造朴素的CNN作为激光雷达判别模型。图3展示了判别模型的结构,由3-1-1的卷积层和非对称最大池化层串联而成,为了基于局部特征判别数据类型,使用卷积核为1的卷积层代替末端的全连接层。

图3 判别网络的结构
3 对抗式训练
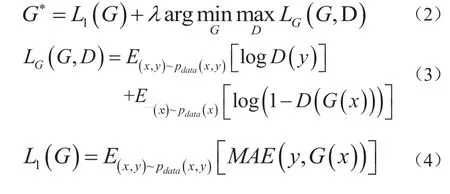
GAN的目标函数主要由对抗损失(3)和像素损失(4)两部分组成。其中对抗损失促使生成网络和判别网络在优化过程中彼此博弈,(3)中x为低线束点云,y为高线束点云,G和D分别为激光雷达超分辨率模型和判别模型,D的训练目标是最大化LG,即成功区分真实高线束数据y和合成数据G(x);G的训练目标是最小化LG,使合成点云成功混淆D。像素损失L1是高线束数据和合成样本之间的平均绝对误差作为损失回传给G进行训练,它约束输出与目标在像素级别上的相似性。
4 实验与结果分析
4.1 数据集构建和预处理
为了保证数据和标签完全对应,本文效仿[8]选取CARLA仿真软件生成的激光雷达点云构建数据集,仿真激光雷达型号为Velodyne VLP-64,垂直视野范围为30°,水平角度分辨率被设为360/1024。然后垂直均匀选取16线束的点云就获得与之完全对应的16线点云。将点云依次排列构成16×1024和64×1024的深度图,并将归一化后的距离填充进矩阵,实现3D点云向2D球平面的投影。数据集共包含6000个样本,对样本基于5:1的比重随机选取构建训练集和测试集。
本文基于Pytorch深度学习框架进行实验,GPU为英伟达2070s,选取两个Adam优化器训练生成网络和对抗网络,初始学习率均设为1×10-4。训练周期设100epoch,训练结束后单独提取生成网络作为超分辨率模型使用。实验通过计算超分辨率处理结果与VLP-64标签之间的均方误差衡量模型的性能。
4.2 实验结果

图4 不同方法输出结果的可视化
5 结语
实验结果如表1所示。由定量实验结果可知,深度学习方法在激光雷达点云超分辨率任务中明显优于传统方法,这是由于深度学习基于任务自动学习特征,在超分辨率重建过程中不仅基于浅层特征构建纹理,还基于深层抽象特征保持数据的语义信息。而传统方法仅基于局部像素结构进行重建,针对整齐平面效果较好,但是处理不规则平面和具有复杂结构物体的点云时性严重退化。实验结果同样表明GAN的性能优于全卷积网络,这是由于GAN中的判别网络对生成网络增加了语义不变的约束,这弥补了L1损失函数的缺陷,对抗式的结构使得生成网络从样本空间中拟合出语义一致的数据分布。

表1 实验结果
图4为五种方法得到的高线束数据的可视化,从结果可以直观地看出,由于插值运算的平滑性,传统方法在距离变化显著的区域不可避免地产生大量的“斜坡”结构,虽然与标签之间的MSE同样较低,但是显著地改变了原有的环境信息,这种数据无法支持后续的任务和应用。而本文的方法对环境的还原度更高,优于对比算法。
猜你喜欢
北京测绘(2022年5期)2022-11-22
网络安全与数据管理(2022年3期)2022-05-23
汽车电器(2022年5期)2022-05-23
汽车观察(2021年8期)2021-09-01
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
汽车实用技术(2015年8期)2015-12-26
汽车实用技术(2015年8期)2015-12-26
