
基于锯齿空洞残差卷积的单幅图像超分辨率重建研究*
2021-03-27 05:50蔺国梁马少斌
新疆大学学报(自然科学版)(中英文) 2021年2期
李 岚,蔺国梁,马少斌
(兰州文理学院数字媒体学院,甘肃兰州730000)
0 引言
超分辨率图像重建(Super Resolution Image Reconstruction,SRIR或SR)的思想是利用一组低质量、低分辨率图像(Low Resolution,LR)经过计算机技术和图像处理技术产生单帧或多帧高质量、高分辨率图像[1,2].SR是数字图像处理的一个重要研究方向,在计算机视觉领域有广泛的应用,如智能交通、安全监控、图像生成和医学成像等[3].目前SR方法主要分为3类:基于差值的方法[4]、基于重建的方法[5]和基于学习的方法[6,7].基于差值的方法是将图像看作一个点,利用先验知识由一个预定义的变换函数或插值来拟合平面上未知的信息,从而计算出高分辨率图像,该方法的主要缺点是很容易出现阶梯锯齿状现象及边缘模糊现象.基于重建的方法是目前被广泛研究的方法之一,这类方法主要是应用下采样技术使得一个或者多个低分辨率图像信息进行融合低像素精度的多帧信息,重建出更高分辨率的图像.这种方法重构精度高,但只能够利用高、低分辨率图像之间的关系,数学模型构建比较困难,导致重建图像纹理不清晰.
基于深度学习的方法近年来成为研究的热点,主要是利用相同图像的内部相似性及大量的训练样本数据,从中求出高、低分辨率图像对之间的映射关系,完成高分辨率图像特征的转化,从而实现SR的过程,这种方法对建模数据的集中特性要求非常高.Dong等[8]首次采用深度学习方法,网络总共设置了一个3层的卷积神经网络(Convolution Neural Network,CNN)实现超分辨率重建,并取得了良好的效果,从此开启了深度学习实现SR的热潮.这种方法在训练的过程中随着网络层数的增加,会出现超参数过多、梯度弥散/爆炸等问题,重建后的图像通常过于平滑,丢失了高频细节信息,图象质量仍有待提升.
Kim等[9]提出深度残差网络(VDSR)模型,利用残差学习加快网络收敛速度,证明了该方法对超分辨率的性能提升,但有增加计算的复杂度和梯度消失问题.Yang等[10]利用图像的稀疏性,约束高低分辨率图像对应的字典下的稀疏表示实现图像超分辨率重建,重建效果较好,其缺点是字典训练需要花费较长时间,并且在图像边缘会出现噪声.Tai等[11]提出DRRN模型,运用递归使用权重共享的网络模块,增加网络深度至52层,减少了模型的参数,但是每个递归单元优化不够,重建效果不够明显.Yu等[12]和Chen等[13]提出了空洞卷积(Dilated Convolution),通过在网络中不增加参数而改变卷积核大小的情况下获得更大的感受野,获取更多的原始图像信息,在重建中取得较好的效果,但该方法会出现“网格化”现象,卷积后导致更多图像信息丢失.
本文对以上方法进行了改进,提出了一种残差网络与锯齿空洞卷积相结合的图像超分辨率重建方法.该模型利用空洞卷积网络提取图像特征,然后运用残差网络结合锯齿空洞卷积进行图像非线性映射,再应用卷积网络得到与输入图像大小相等的残差图像,最后将预处理的低分辨率图像与残差图像线性融合得到最终的超分辨率图像.网络训练使用自适应时刻估计方法(Adaptive Moment Estimation,Adam)加速网络收敛,通过空洞卷积操作扩大了图像特征感受野的同时高质量地恢复了图像的纹理信息,提升了重建图像的视觉效果.
1 相关工作
1.1 空洞卷积
空洞卷积(Dilated Convolution)也称扩张卷积,是一种在特征图上进行数据采样的方式.通过在普通卷积核的每个像素之间补充0像素值,用来增加网络的扩张系数,可以在卷积核有效增大感受野的同时不增加模型参数或者计算量.在图像全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能较好地应用空洞卷积[10].对于一个3*3的卷积网络,其扩张率和感受野如图1所示.

图1 不同扩张率的3×3 pixels卷积
图1(a)是普通的卷积(即扩张率rrate=1的空洞卷积),代表的数据是原图3*3元素的卷积,感受野是3*3,相当于不扩充,rrate=1;图1(b)是扩张率rrate=2的空洞卷积,感受野是7*7,dilation=2;图1(c)是采用扩张率rrate=4的空洞卷积,感受野是15*15,dilation=4.空洞卷积对普通卷积的改进就是为了获得更大的感受野,感受野的大小计算用公式(1)表示.

其中:ksize表示卷积核的大小,rrate表示空洞卷积的扩张率,v表示感受野的大小.
空洞卷积不仅可以保留图像内部的特征信息,还能避免pooling造成的分辨率丢失,但其仍存在缺陷:相同的空洞卷积得到某一层的结果中,邻近的像素是从相互独立的子集中卷积得到的,相互之间缺少依赖,造成信息不连续,会出现“网格”效应,具体卷积如图2所示.

图2 相同扩张率的空洞卷积
图2(a)对应扩张率rrate=2的卷积层,感受野为5×5;图2(b)表示第二层卷积核,感受野为5×5,图2(c)为扩张率rrate=2的空洞卷积进行一次卷积的结果,感受野为9.如果所有空洞卷积都使用相同的扩张率,则计算方式类似于棋盘格,大范围的数据相互之间没有依赖关系,随着深度网络的层数进一步增加,导致重要信息丢失.针对这种问题,本文提出一种锯齿混合空洞卷积,如图3所示.

图3 不同扩张率的卷积结果
从图3可以看出,锯齿空洞卷积在增大感受野的同时能保证无盲区覆盖整个区域,从而能够有效提取特征,提高重建的准确率.由于插入0像素值不参与卷积运算,参与运算的仍是相同尺寸的卷积核,复杂度不变.
1.2 残差网络(ResNet)
对于CNN,如果简单地增加深度,会导致梯度弥散或梯度爆炸.He等[14]提出了残差学习网络ResNet,通过增加跳跃连接(恒等映射)来直接连接浅层网络与深层网络.在ResNet中每个卷积层后面都有一个批归一化(Batch Normalization),文献[15]中指出,BN层可以将特征归一化处理,提高网络的泛化能力,加速训练的收敛过程,但在一定程度上破坏了图像的空间信息,增加网络的训练参数,导致网络性能变差.所以,本文对ResNet进行了改进,残差单元中卷积层采用空洞卷积,并移除了BN层,有助于获得更好的图像超分辨率重建结果.
如果采用同一个扩张率进行卷积后,卷积核会产生“网格”现象,同时卷积核体积过大会携带冗余信息,造成不必要的内存占用.因此,本文设计了锯齿空洞残差单元,通过循环运算获得与标准卷积相同结构的特征图,在保留图像细节信息的同时可以增大网络的感受野,进而更好地拟合目标边界,提高图像重建质量.本文中的锯齿空洞残差单元与ResNet的残差单元结构如图4所示.

图4 残差网络单元
2 本文网络及实现过程
本文算法的思想是为了获取更多的图像信息,使用较小的卷积核,既不增加网络的层数和复杂度,又能够加快网络的收敛速度,同时避免了因为空洞出现的“盲区”现象.首先在残差网络中采用不同扩张率的空洞卷积对网络的输入图像进行训练,输出残差图像,然后将输入的低分辨率图像与残差网络输出的残差图像相加重建超分辨率图像.
2.1 网络结构
随着网络深度的不断增加,人们发现深度CNN网络并不是网络层数越深性能就越好,当达到一定的深度后继续增加层数反而会影响网络的收敛速度,感受野会减小,导致上下文信息减少,重建效果差.何凯明等[14]2015年提出深度残差网络(Deep Residual Network,ResNet),在ImageNet图像分类中通过增加网络深度可以提高网络分类的准确性,通过残差学习解决梯度消失和网络性能退化问题.

图5 本文单幅图像超分辨率重建方法网络结构
本文基于文献[15]构建了一个锯齿洞卷积的残差网络,网络整体结构如图5所示,共包含20个卷积层,按照功能划分为5个部分,分别是低分辨率图像输入部分,卷积特征提取部分,紧接着是6个空洞残差块,每个残差块包含3个残差单元,然后是残差图像特征层,通过空洞残差使每个卷积层输出的特征图保持尺寸不变.
2.2 图像超分辨率重建过程
网络输入由图像单一颜色通道形成的数据经双三次差值预处理.
本文提出的空洞残差卷积神经网络超分辨率重建主要包括以下3个步骤:
(1)特征提取层(Conv+ReLU层)
除了最后一层卷积核大小为1个像素外,其余中间各层卷积特征尺寸都为3×3×64个像素点.在特征提取层中将输入的低分辨率图像X与3×3×1个像素大小的卷积核进行卷积操作,得到n1个特征图(这里n1=224),这里的1表示通道数.特征提取层包含一个卷积层和一个激活函数,并将该层获得的每个神经元传递到残差单元模块.特征提取过程的表达式为:

其中:*为卷积操作,W1为第一个卷层的卷积核;b1为第一个卷积层的偏置项,其维度与卷积核的维度保持一致;B0为从输入X中提取的第一个残差块的输入特征;f为ReLU激活函数.
本文网络中应用ReLU可以加快模型训练速度和缩短模型收敛时间,同时一定程度上抑制梯度消失现象,性能优于传统的激活函数Sigmoid[16](在深度卷积网络中梯度反向传递时导致梯度爆炸和梯度消失),表达式为:

其中:xi为ReLU函数的输入,f(xi)为ReLU函数的输出.
(2)非线性映射
对输入的低分辨率图像,采用提出的锯齿残差网络进行图像训练.该残差模块结构由6个空洞残差单元组成,每个空洞残差单元由3个空洞卷积层和3个非线性激活函数ReLU组成.每个残差单元设计有两部分:跳跃连接和恒等映射.这样既可以保留残差信息,又能通过跳跃连接将图像特征向后传递,有助于保持特征的多样性.
采用3×3像素的卷积核,扩张率的选择采用1、2、3的3个卷积层进行串联成为一个残差块,为了不改变卷积核的大小,在网络计算结束时保证输出为13×13的特征图.经过空洞残差块之后特征图像素点的感受野得到了扩张,获取更多的原始图像信息,每个残差单元的表达式为:
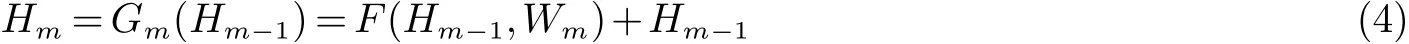
式中:Hm-1和Hm分别为第m个残差单元的输入与输出,F为学习到的残差映射,即:

其中:Wim,i=1,2,3为学习到的第i个卷积层权重.为简化公式,省略了偏置项,f为ReLU函数,*为卷积操作.
由于在深度卷积网络中设置了锯齿空洞卷积,经过网络训练,减少了“网格化”现象导致的图像信息不连续的问题.
(3)图像重构与输出
首先将残差网络输出的特征图作为最后一个卷积层的输入,与3×3的卷积核进行卷积生成与输入图像大小相等的残差图像,然后与输入的插值图像进行线性叠加,输出最终的超分辨率图像.图像重构阶段的结构如图6所示.

图6 图像的重构阶段
2.3 损失函数
网络模型应用了空洞残差,使得输入图像与输出图像大小相等,同时解决网络难以收敛的问题.以x表示双三次差值后的输入图像,fRes(x)表示输入图像x经过整个神经网络以后输出的残差图像,y表示原始高分辨率图像,y*表示网络预测输出的超分辨率图像,即

本文网络中应用均方误差(Mean Squared Error,MSE)函数作为整个网络的损失函数,通过计算生成的图像和原始高分辨率图像的均方误差达到最小值,得到最优解.损失函数计算公式为

其中:n为样本数,yi为高分辨率图像,f(xi;Θ)为网络的预测输出图像,Θ={w1,w2,···,b1,b2,···}.
3 实验与分析
3.1 实验环境
本文图像超分辨率重建算法的实验环境如表1所示.

表1 本文实验环境
3.2 实验设置与评价指标
由于网络相对较深,算法要使用更大的训练集才能训练出更好的结果,分别选取与文献[13]相同的291张图片作为训练集,这些图片分别来自文献[18]提出的91张图片和BSD(Berkeley Segmentation Dataset)训练集中的200张图片[11],共291张图像.为了充分利用深度图像,对数据集图像进行水平翻转、垂直翻转和水平垂直翻转,并按照0.9、0.8的系数缩放,然后保存图片,共生成5 820张图像,图像尺寸大小不超过512×512.
在应用本文网络对图像进行训练的过程中,将训练图像转换到YCbCr空间[19].相对于颜色(CbCr通道信息)变化,人类对亮度(Y通道)的变化更敏感,所以本文设计的网络中只对Y通道做处理.图像卷积核大小都为3×3,特征图像通道数量为64.训练所采用的优化算法是Adam[20]与SGD(Stochastic Gradient Descent,SGD)相比较,Adam优化方法更灵活,具有自适应性,可以将每次迭代的学习率控制在一定范围内,使得参数学习比较稳定.设置网络的初始学习率为10-4,动量参数设置为0.9,采用mini-batch训练方式,batch-size为64,每10万次迭代降低为原来的一半.
实验中用Set5和Set14作为测试集,原始高分辨率图像为X,放大倍数取s=2,3,4,预处理后的图像作为网络的输入.
为了验证图像超分辨率重建方法是否符合预期,需要对重建后的高分辨率图像进行评价.目前,重建图像的质量评价方法分为两种:主观评价和客观评价.主观评价主要是指通过人眼观测和先验知识判断重建图像的感官差异,如图像的纹理、颜色等特征与原始高清图像的近似程度.主观评价主要依靠人为审美标准,受多方面因素影响,对图像质量判断存在一定的误差.客观评价是对图像分辨率进行定量分析,通过具体的指标评价图像质量.常见的客观评价指标有峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似比(Structural Similarity Index,SSIM).PSNR是通过计算图像内像素最大值与加性噪声功率的比值来衡量重建图像是否存在失真问题,其数值越大,说明重建图像的性能和真实程度越接近原始高分辨率图像,其计算方法与图像的均方误差(MSE)有直接关系,计算公式如下式(7)所示.


其中:H、W为图像的尺寸,M SE为均方根误差,ISR为重建图像,I为原始图像,L的值通常取255.PSNR的值越大,表示输出图像失真越小,与原始图像越接近.
SSIM是综合衡量两幅或者多幅图像之间结构度、亮度和对比度的相似程度,其值与1进行比较,越接近于1,表示输出图像质量越好,其具体公式如式(9)所示.
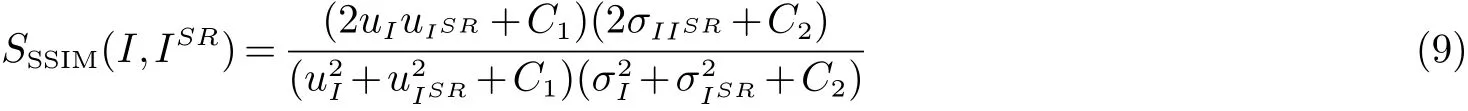
其中:uI和uISR表示原始图像I和重建图像ISR的均值;σI和σISR表示原始图像I和重建图像ISR的方差;σIISR表示两者的协方差;C1和C2是常数.
3.3 实验分析
首先将本文算法分别与Bicubic算法、FSRCNN算法和VSDR算法等单幅图像超分辨率重建领域中具有代表性的方法进行对比实验,主观效果对比如图7~9所示,其中红色框为感兴趣的区域.

图7 不同算法在Butterf ly上的重建结果
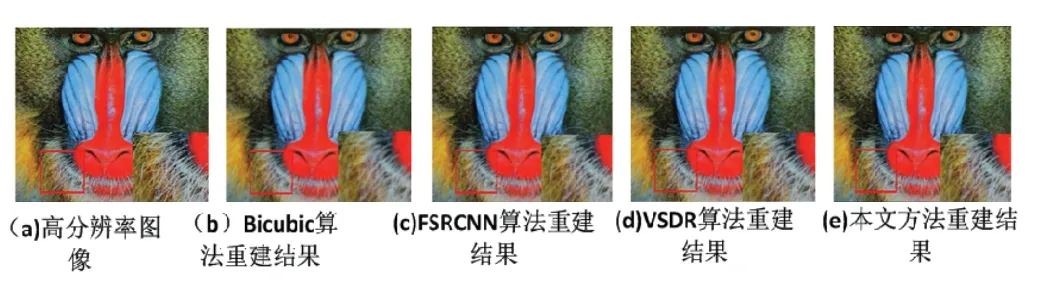
图8 不同算法在Baboon上的重建结果

图9 不同算法在Woman上的重建结果
比较图7~9中可以看出双Bicbuic算法局部感受野较小,可利用的区域图像特征单一,高分辨率重建的图像仍然存在边缘清晰度差的缺点,图像重建效果差.FSRCNN和VSDR算法对图像Baboon的毛发和嘴周围处理效果比原始高分辨率图像差.
本文算法在区分图像边缘和改善纹理细节中有较好的效果,对Woman的重建中头部饰品纹理细节在清晰度上有较好的提升.采用PSNR和SSIM两种指标对本文算法进行客观评价,分别与Bicubic算法、FSRCNN算法和VSDR算法进行比较,在Set5、Set14测试集上将输入图像的尺度因子放大2,3,4倍,经过不同方法的实验对比,重建的数据对比结果如表2所列.
从表2中可以看出,本文算法相较于Bicubic算法、FSRCNN和VSDR算法在扩大因子为2时,PSNR均值上分别提升了0.33、0.338和0.324 d B;扩大因子为3时提升了0.282、0.208、0.898;扩大因子为4时提升了0.4、0.464、1.048.在扩大因子为2时,SSIM平均提升了0.041 3、0.009 6和0.023 2;扩大因子为3时提升了0.016 0、0.006 6、0.005 2;扩大因子为4时提升了0.011 6、0.007 3、0.011 2.
从表3中可以看出,本文算法相较于Bicubic算法、FSRCNN和VSDR算法PSNR值在扩大因子为2时,均值上分别提升了0.45 d B、0.35 d B和0.23 d B;扩大因子为3时提升了1.8 d B、0.67 d B和0.05 d B;扩大因子为4时提升了13 d B、10 d B和0.8 dB.SSIM值在扩大因子为2时,平均提升了0.05、0.4和0.02,扩大因子为3时提升了0.8、0.009 6、0.001 7;扩大因子为4时提升了0.399、0.27、0.015.由定量数据分析可知,本文算法引入锯齿空洞残差卷积在一定程度上增强了重建图像的纹理信息和重建效果,缩减了运算时间,提高了图像重建效率.

表2 不同方法在set5数据集上的PSNR和SSIM结果(放大倍数=2,3,4)

表3 不同方法在set14数据集上的PSNR和SSIM结果(放大倍数=2,3,4)
4 结论
本文提出了一种基于VSDR算法改进的锯齿空洞残差卷积的图像超分辨率重建方法.该方法首先将低分辨率图像插值预处理后输入网络,通过一次卷积提取图像特征,然后应用6个连续的锯齿空洞残差卷积实现图像特征的非线性映射,有效避免了相同扩张率产生的“网格化”现象而出现的图像盲区,在扩大感受野的同时不改变图像尺寸,得到输出的残差图像,解决了网络梯度消失和梯度爆炸问题.最后将原始的低分辨率图像与残差图像进行线性相加,输出最终的高分辨率图像,提高了重建质量和效率.实验结果表明:与其他3种方法相比,对于单幅图像本文算法在峰值信噪比和结构相似比上达到了更优的效果.与原始彩色高分辨率图像比较,在纹理和清晰度上还有差距,下一步的研究工作中,将锯齿空洞卷积应用到更优的深度学习框架中,尝试更多的扩张率组合,实现图像超分辨率重建,更好地利用图像特征.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
中国典型病例大全(2022年12期)2022-05-13
北京大学学报(自然科学版)(2022年1期)2022-02-21
今日农业(2021年11期)2021-11-27
健康体检与管理(2021年10期)2021-01-03
北京航空航天大学学报(2020年10期)2020-11-14
学生天地(2020年18期)2020-08-25
北京航空航天大学学报(2019年9期)2019-10-26
计算机应用(2016年10期)2017-05-12
故事作文·高年级(2017年2期)2017-03-01
