
基于条件随机场的图像标注方法研究
2021-03-25 04:06张扬睿王卓燃崔子琦傅于窈程世强王伟白晨阳
现代计算机 2021年4期
张扬睿,王卓燃,崔子琦,傅于窈,程世强,王伟,白晨阳
(中国矿业大学(北京)机电与信息工程学院,北京100083)
0 引言
图像自动标注是通过计算机自动分析和识别图像,并为图像标注标签的技术。图像自动标注有着人工标注无法企及的优点,例如标注速度快,能克服人工标注的主观性等。当前的标注方法主要有四类:①基于分类管理思想的图像标注。它把图像分割分类,是一种需要监督的机器学习研究方法。②基于相关模型的图像自动标注。它通过建立图像分割子区域与语义关键词间的概率相关模型来进行相关工作。③基于半监督模型的图像自动标注。它应用于图像信息巨大的情况。④基于图模型的自动标注。它在解决多标签分类问题中,建立了相互映射关系,为解决多标签分类问题提供了新的思路方向,例如,改进的BR(Binary Relevance)算法[1]。图像自动标注技术虽然在理论上已经取得了很大的进展,但是在应用到现实复杂场景时还是存在标注准确率不高等问题。实际上,标注标签之间通常具有一定的相关性。例如,“蓝天”和“白云”、“沙滩”和“大海”经常同时出现在一幅图像中。如何挖掘标签之间的相关性是提高图像标注准确率的重要方法之一。本文介绍了一种基于条件随机场(Conditional Random Field,CRF)的图像标注方法,可以挖掘标注标签之间的相关性。具体而言,在图像分割阶段把图像分割成若干区域,每一个分割的区域都对应一个标签,从而将图像自动标注问题转换成关于区域的分类问题,然后采用条件随机场模型完成图像标注工作,通过条件随机场模型挖掘标签相关性。
1 基于条件随机场的图像标注方法

图1 基于条件随机场的图像标注方法流程图
基于条件随机场的图像标注方法的核心思想是利用条件随机场对经过聚类后的图像特征和标签序列进行训练,以区域为单位对图像进行自动标注,图1 是基于条件随机场模型的图像自动标注算法的流程图,包含如下三步。
(1)首先采用Mean-Shift 算法对进行图像进行分割,即将一副图像划分成若干区域。
(2)然后对图像划分网格提取图像特征并建立视觉词袋模型。首先对每幅图像进行网格划分并基于网格提取图像特征,然后对网格特征进行聚类得到网格类别的集合,接着基于(1)中划分的图像区域统计区域网格类别频数,并再次对这些频数向量进行聚类从而得到视觉词袋,即实现将图像信息“文本化”。
(3)在图像训练集上训练基于条件随机场模型的图像自动标注模型,在训练好的模型上输入图像测试集以完成图像自动标注。上述步骤的详细原理如1.1-1.3 小节所示。
1.1 图像分割
Mean-Shift 算法是一种高效的聚类统计迭代方法,该算法完全依靠空间样本点,不需要先验知识且收敛速度快,具有很强的稳健性,因此被广泛应用于图像分割、视频追踪等领域[2]。在图像中以中心点x为初始迭代点,按一定半径选定半径区域内的点xi,求出中心点x到所有点xi的向量的均值,通过平均向量确定下一个新的中心点。算法不断地迭代并记录下所有收敛点[3]。均值漂移算法可描述为:在D维空间中给定n个样本点(x1,x2,…,xn),在x处的均值漂移向量的数学表达式为:

在Mean-Shift 向量中,h表示中心点的区域范围大小,k表示该区域内样本点的数量。在图像领域中,Sh是一个半径为h的圆形区域,满足以下条件:

因此依据各像素点的收敛点不同可划分出一个个小区域。在这些小区域的基础上可继续进行图像合并。图像合并主要合并一些收敛的中心点,这些中心点位置相邻并且灰度值相差不大。均值漂移算法的优点是可以自动调整,积分收敛速度即运动矢量的大小取决于概率密度函数的梯度。当趋近极值时,平均位移向量减小,对于均匀分布的核密度函数,收敛可以在有限的步骤内完成。经过Mean-Shift 算法进行分割后,可以得到图像集的区域集合:

其中,D为图像集区域集合,R为区域,N1为图像数量,Mi为第i幅图像的区域数量。
1.2 特征提取和词袋模型
(1)特征提取
对原始图像集的每幅图像划分大小相同的网格,并对每幅图像基于网格进行特征提取[4]。可以使用颜色直方图、颜色矩、Gabor 纹理特征、SIFT 算法[5]提取的形状特征组成图像的特征向量。颜色直方图描绘的每种颜色所占在每个网格所占比例;颜色矩描述颜色的分布;Gabor 纹理可以在频域不同尺度、不同方向上提取相关的特征;SIFT 算法可以得到网格的形状特征。建立每一个网格的特征向量f=(f1,f2,f3,f4),f1,f2,f3,f4子向量分别表示基于网格的颜色直方图、颜色矩、Gabor纹理和形状特征,则特征提取后的网格特征向量集为:
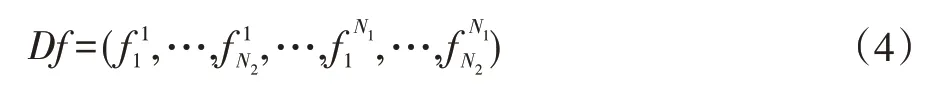
N1为图像数量,N2为每幅图像的网格数量,每幅图像会有N2个特征向量fi j,特征提取得到的网格特征向量集将作为词袋模型的输入进行聚类。
(2)建立词袋模型
词袋模型最初是用在自然语言处理的文本分类中的一个模型,将文本文档看作是一个特征向量[6]。词袋模型应用于图像时图像被看做为一个文本(即若干视觉词汇的集合),这些视觉词汇是图像的“图像特点”。建立词袋模型的步骤如下:
①特征提取:如1.2(1)所述,得到网格特征向量的集合。
②单词本的生成:使用K-Medoids 算法[7]对网格特征向量进行聚类,得到K1种不同的网格类别。对经过1.1 小节分割后的每幅图像统计每个区域的网格分布情况,计算第i幅图像的第j个区域中第p类网格的频率,用K1(网格类别数)维的分布向量表示,每一维度表示这个区域中这种类别的网格的频数:

代表第i幅图像的第q个网格的类别,代表第i幅图像的第q个网格所在的区域。将每个区域都进行网格频数分布计算,得到网格频数分布向量数据集:

其中,N1为图像数量,Mi为第i幅图像的区域数量。
③检索最匹配视觉单词:通过对②得到的每个区域的网格频数分布向量K-Medoids 聚类后得到由K 个视觉单词组成的词典(也称为词袋),可表示为:

vi表示视觉单词。本文采用最近邻搜索算法,搜索出与每幅图像的每个区域相似度最高的单词。
1.3 建立条件随机场模型

图2 链式条件随机场
条件随机场模型是基于概率图模型的分类学习方法,它是在隐马尔可夫模型和最大熵模型(Maximum Entropy Model,MEM)相结合的基础上,针对这两种方法的缺陷逐步提出改进而来[8]。条件随机场是条件概率分布模型P(Y|X)[9],X 与Y 的关系如图2 所示。这个条件概率分布模型是在给定一组观测序列X=(x1,x2,…,xZi) 的条件下求另一组标签序列Y=(y1,y2,…,yZi)的概率,条件随机场的参数化形式为:

式中,Z(X,θ)=∑Yexp{∑cϵCφc(Yc,X,θ)} 为全部序列集合的归一化元素。

式中,tk和sl分别是定义在无向图边上和节点上的特征函数,分别为状态转移特征和状态特征,λk,μl是特征函数tk,sl对应的权值。在定义特征函数阶段,可以将节点处的特征函数的初始值都设置为1,将边上的特征函数的初始值也设置为1。由于每个特征函数都分配有权重参数,因此在训练的时候,如果节点之间的特征不存在依赖关系,则该特征函数的权重参数会在训练结束后趋近于0。这种设定简化了条件随机场的建立过程。
构建条件随机场模型,需要先建立条件随机场对应的无向加权图,图模型中每一个观察点对应一个图像区域。为了训练特征权重参数θ,需要输入1.2 小节得到的区域网格频数分布向量vi的序列作为观测序列X,以及图像区域对应的标签序列表示第i幅图像第j个区域的标签。基于CRF 模型的图像自动标注算法就是用条件随机场模型来表示区域的频数分布向量集X与标签序列Y之间的关系[10],图像标注过程就是为每一个区域分配一个标签yi。CRF 模型在训练集上确定模型的参数后,对于测试集能够对给定的观察序列X输出合适的标签序列Y,该标签序列使得条件概率P(Y|X)最大。
2 结语
图像自动标注技术是当前机器学习的研究热点。本文介绍了一种基于条件随机场的图像自动标注方法,该方法包含图像分割、特征提取、构建词袋模型以及基于条件随机场模型进行图像标注的完整流程。由于条件随机场模型的状态转移特征函数可以表示标签之间的依赖关系,因此该模型可以处理标签间的相关性问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
华人时刊(2021年23期)2021-03-08
作文新天地(初中版)(2019年6期)2019-08-15
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
