
基于百度搜索数据的区域经济指标预测模型研究
2021-03-22 05:27阳向军谢金芸梁宗经
生产力研究 2021年1期
阳向军,谢金芸,梁宗经,杨 昕
(1.广西师范大学经济管理学院,广西桂林 541004;2.桂林航天工业学院理学院,广西桂林 541004)
一、文献综述与问题的提出
在以往关于宏观经济预警的研究中,我们通常需要通过观测一组反映经济发展状况的敏感性指标的变动情况来判断经济系统当前的运动状况和未来的发展趋势[1-3]。但由于宏观经济系统的非线性和不确定性问题,传统的预测和预警模型与实际系统存在较大的误差[3]。近年来国内学者在非线性宏观经济预测模型方面进行了许多大胆创新和尝试,包括神经网络(贺京同等,2000)[3]、模糊数学(陈又星和徐辉,2010)[4]、行为经济学理论(肖争艳和陈彦斌,2006)[5]等。当前各文献的预测方法所用数据主要来源于各级政府部门、行业协会的统计数据,其具有滞后性特征,根据这些滞后数据所建立的预测不具时效性,不能实现实时预测监测。因此,寻找质量更高的数据资源对预测结果的改善具有重要意义。
近年来,网络搜索引擎查询数据的出现使宏观经济的实时预测预警成为可能。随着社会信息化的不断发展,网络已成为日常生活、企业发展、政府管理必不可少的信息来源,搜索引擎则是查询信息的主要工具。搜索引擎查询数据是用户使用搜索引擎查询信息后所记录下来的历史数据,包含了用户的丰富信息。网络用户的搜索行为通过关键词搜索来实现。搜索查询关键词的选取与外部的经济环境、社会环境和个人情况等密切相关,这种相关性近年来引起了国外学者的关注。Jeremy Ginsberg 等(2009)[6]通过分析发现Google 中与流感相关的部分关键词搜索量与美国疾病控制和防治中心发布的流感看诊量数据有很强的相关性,并指出监测每天全世界数百万用户在搜索引擎上提交的关于求医行为的查询是一种可以改进疾病早期检测的手段。国外随后兴起了相关研究,研究成果表明网络搜索数据与经济周期(Suhoy,2009)[7]、失业率(Askitas 和Zimmermann,2009)[8]、个人消费者指数(Konstantin 等,2009)[9]、零售业销售(Choi 和Varian,2009)[10]、房地产行业销售(Wu 和Erik,2014)[11]、股票价格波动(Zhi 和Joseph,2009)[12]等相关。国内学者近年来也对网络搜索数据应用进行了探讨:在金融领域,研究了网络搜索数据与金融市场的量化交易行为之间的相关性,从不同角度验证了基于网络搜索来预测股票市场是可行的(刘颖等,2011[13];俞庆进和张兵,2012[14];赵龙凯等,2013[15];杨欣等,2013[16];张谊浩等,2014[17]);在经济领域,从宏观层面研究了网络搜索数据与国内CPI(张崇等,2012)[18]、失业率(彭赓等,2013)[19]、通货膨胀(孙毅等,2014)[20]之间的关系;在行业层面,探讨了网络搜索数据在汽车销售量预测(袁庆玉等,2011)[21]、房地产价格预测(董倩等,2014)[22]、旅游客流量预测(任乐和崔东佳,2014)[23]和消费者信心指数构建(孙毅等,2014)[24]的应用。各项实证研究均显示引入网络搜索数据的预测模型具有较强的实效性和良好的预测效果。
综上国内外文献可知,网络搜索数据研究已逐步成为指标预测领域的一个新的重要的研究方向。但现有国内的相关研究大部分是针对宏观层面或者行业层面的指标预测,鲜见针对区域经济预测的成果。李方一等(2016)[25]基于百度搜索指数与经济指标之间的相关关系,运用多元回归方法构建了安徽省区域经济预测模型,但该文献并未充分考虑网络搜索数据的特点去构建多种模型进行比较选择。本文借鉴文献[26]的研究思路,采用不同的方法构建广西区域经济预测模型。文章选取工业总产值和居民消费价格指数作为预测的基准指标,若干个百度搜索关键词和与经济波动相关的政府统计指标作为分析的备选指标,利用从备选指标中选出的先行指标分别构建自回归差分移动平均(Autoregressive Integrated Moving Average,ARIMA)和自回归分布滞后(Autoregressive Distributed Lag Model,ARDL)两个系列的多个模型进行实证分析。研究将即时的网络搜索数据纳入区域经济的预测系统,拟通过构建和对比多种模型去探究网络搜索数据能否优化仅使用政府统计指标的区域经济预测模型。
二、数据选取和理论模型
(一)数据选取与处理
1.指标选取
(1)预测的基准指标。本研究选取能反映区域经济状况的5 类指标表征区域经济发展变化,包括经济发展指标(工业总产值)、价格指标(居民消费价格指数)、外贸指标(出口总额)、金融指标(金融机构各项贷款总额)和人力资本指标(失业率)。后3项指标后续拟另文探讨,本文只将工业总产值和居民消费价格指数作为基准指标纳入预测机制,从生产和消费两个不同的角度预测广西区域经济的增长。工业总产值是工业企业在一定时期内生产的以货币形式表现的工业最终产品和提供工业性劳务活动的总价值量①该定义取自国家统计局官网http://data.stats.gov.cn/.,可反映一定时期内工业生产的总规模和总水平;居民消费价格指数是反映一定时期内居民所消费商品及服务项目的价格水平变动趋势和变动程度的指标②该定义取自国家统计局官网http://data.stats.gov.cn/.,是衡量通货膨胀或者通货紧缩最重要的价格指数。
(2)分析的备选指标。研究中考虑到网络搜索数据具有高维性、结构复杂性和较大噪音的特点,而政府统计数据则相对严谨和噪音小,故建模过程中我们区别使用两类数据,将分析的备选指标分为政府统计数据和网络搜索数据两类考虑:①根据全面性、可靠性、稳定性、时效性、不可替代性的指标选取原则,结合广西经济发展综合情况,并参考相关文献(晏露蓉和吴伟,2005[27];高铁梅等,2006[28];陈可嘉和刘思峰,2010[29]),本文选取投资、消费、工业、财政、生产指数、货币、物流、外贸、工业企业和金融十大类47 个经济指标作为分析的备选指标,其中广西区域经济指标35 个,国家经济指标12 个;②借助百度指数推荐功能以及关键词搜索网站站长工具,并借鉴相关文献(董倩等,2014[22];樊国虎,2014[30];吴英明,2018[31]),筛选了涉及经济、就业、生活、物价、购房、投资、旅游等方面的75 个高频率搜索词汇也作为备选指标。备选指标共计122 个。
2.样本选取和数据来源
选取广西2012 年1 月—2017 年12 月相关指标的月度数据为研究样本,其中2012 年1 月—2017年9 月的数据作为训练集用于构建模型,2017 年10月—2017 年12 月的数据作为测试集用于检验预测效果。目前百度搜索是国内最主要的搜索引擎工具,本文使用百度搜索指数代表网络搜索数据。各数据来源于国家统计局、广西壮族自治区统计局、中国经济与社会发展统计数据库和百度搜索引擎③百度公司没有提供可以直接下载的百度指数数据,作者利用软件手工整理完成了相关指标百度指数原始数据的收集。,其中百度搜索指数为广西的PC 搜索指数。
(二)模型构建
1.理论模型。本文的被解释变量为2 个区域经济指标:工业总产值和居民消费价格指数。为方便起见,我们使用yt表示被解释变量,t=1,2,…,T 表示时期,yt-i表示被解释变量滞后i 期的值;解释变量为从各分析备选指标中选出来的符合条件的先行指标,分为政府统计指标和网络搜索指标两类,分别用Xmt和Znt表示,其中Xmt=(x1t,x2t,…,xmt)是m×1 的向量,每一个分量xkt代表一个政府统计指标,共有m 个指标;Znt=(z1t,z2t,…,znt)是n×1 的向量,每一个分量zjt代表一个网络搜索指标,共有n个指标。研究中为了减少波动性和异方差对计量结果的影响,我们对上述变量取自然对数后再依次构建ARMA 和ARDL 两个系列的5 个不同的模型。
首先,我们考虑利用被解释变量t 期之前的信息去预测t 期的值,构建yi的自回归差分移动平均模型ARIMA(p,d,q),如式(1)。当差分阶数d=0,即时间序列为平稳序列时,ARIMA(p,d,q)变为ARMA(p,q)模型,如式(2)。
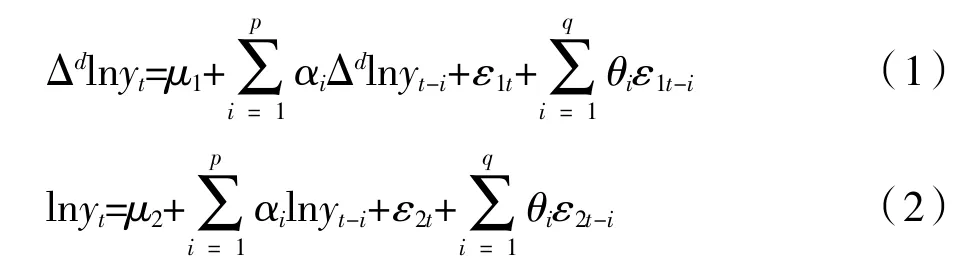
其次,我们将lnxkt、lnzjt和它们的不同组合纳入解释变量,构建ARDL 系列模型,其中模型(3)包含yi自身的信息和政府统计指标Xmt,记为ARDL+X;模型(4)包含yi自身信息和网络搜索指标Znt,记为ARDL+Z;模型(5)包含yi自身信息、政府统计指标Xmt和网络搜索数据Znt,记为ARDL+X+Z。
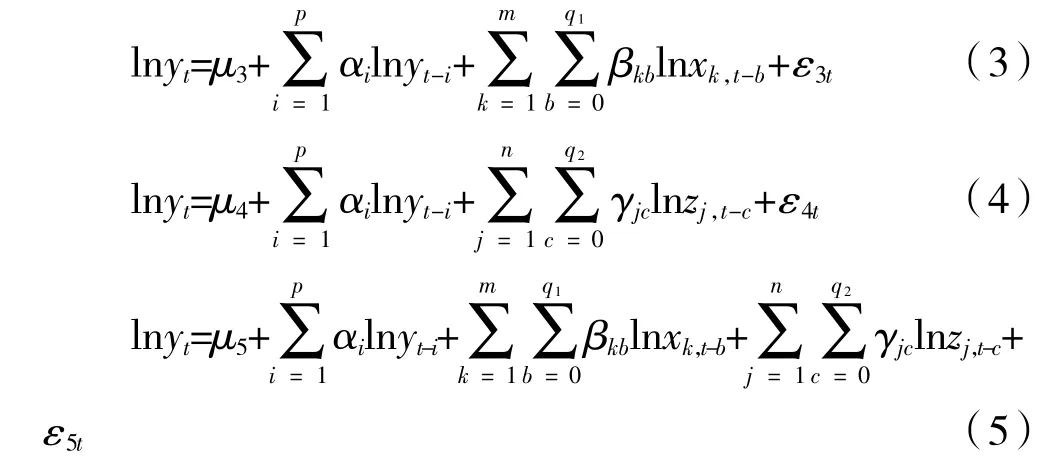
式(1)~式(5)中,yt、xkt、zjt、t、d 的含义如上所述,p 为解释变量的自回归阶数,q1、q2为解释变量的滞后阶数,εit为被解释变量在t 时期的误差项,ui为常数项,αi、βi、γi是各解释变量的估计系数,Δ 表示差分方程,即Δlnyit=lnyt-lnyt-1。
2.模型参数的挑选。上文我们构建了5 个包含被解释变量自身信息、政府统计数据、网络搜索数据或它们的不同组合做解释变量的模型,期望从中选出最佳预测模型。在遴选最优模型的过程中,如果解释变量中包含指标太多,容易导致过度参数化,而包含指标太少则会遗漏掉重要信息导致预测出现偏差。如何从众多的解释变量中挑选出少数重要变量是研究中一个关键步骤。我们的做法是先通过时差相关分析法选出符合一定标准的先行指标,然后通过单位根检验和格兰杰因果检验等方法筛选符合建模条件的指标作为解释变量,采用AIC、BC 准则等方法确定各解释变量的滞后阶数,并运用一些统计检验方法(如t 检验检验模型系数的显著性,DW检验自相关等)逐步剔除变量,最终将与被解释变量相关性较强且通过显著性检验的先行指标纳入模型,经过多次运行不同变量的组合确定最优模型。
三、实证过程及结果分析
(一)研究方法及实证结果
1.数据预处理
本文建模前先对原始数据进行如下预处理:(1)文中所有指标均采用月度数据,所获取的关键词百度指数数据频度为日度,我们已将百度指数日度数据合成为月度数据。(2)因国家统计部门从2012年起不再对一月份的统计数据单独调查,故本文部分经济指标的数据存在缺失值,我们采用SPSS 软件相应功能替换和补全数据缺失值。(3)为了消除数据季节性、周期性、趋势性的影响,我们运用乘法模型对除居民消费价格指数、商品零售价格指数以外的经济指标和搜索指数关键词进行季节调整。
2.筛选先行指标
我们将预处理后的基准指标与备选指标进行时差相关分析,筛选出各个指标在相关系数绝对值最大时的超前或滞后阶数,并通过每个指标的超前或滞后阶数去判断各个基准指标与备选指标在时间上的对应关系是先行、一致或者滞后。由于研究的主要目的是进行经济预测,所以我们在三类指标中仅选取先行指标建模。通过对各先行指标与广西工业总产值和居民消费价格指数进行相关性检验,剔除相关性较弱的指标(本文选定弱相关的临界值为0.325)①指标选取临界值为0.325 的理由:本研究建模样本数n 为67,根据两变量之间线性关系的r 检验法[32]查相关系数检验临界值表可知,在1%的显著水平下,只要两个变量的相关系数的观察值|r|大于临界值ra(n-2)=0.325,就认为两个变量之间有显著的线性关系。。以基准指标“工业总产值”与备选指标“金融危机-广西百度指数”为例,我们先计算了备选指标从-12 阶到+12 阶与基准指标的相关系数,然后取相关系数绝对值最大时对应的阶数作为备选指标的最终时差,各相关系数的计算结果如表1 所示,从表1 可确定备选指标“金融危机-广西百度指数”的滞后阶数为-6。

表1 “工业总产值”与“金融危机-广西百度指数”的时差相关分析结果
运用上述方法,我们对其余121 个备选指标与基准指标“工业总产值”和“居民消费价格指数”分别进行了时差相关分析,其中相关系数绝对值大于0.325 的指标分别为110 个和108 个。考虑到模型中解释变量不宜太多且本研究仅需要先行指标进行预测,我们在其中选取了与基准指标最密切关联(按照相关系数绝对值的大小选取)且时差或延迟数L<-3 的先行指标作为建模的备选指标,每个基准指标包含10 个政府统计指标和10 个百度搜索指标。拟选用先行指标的时差相关分析结果如表2 所示。
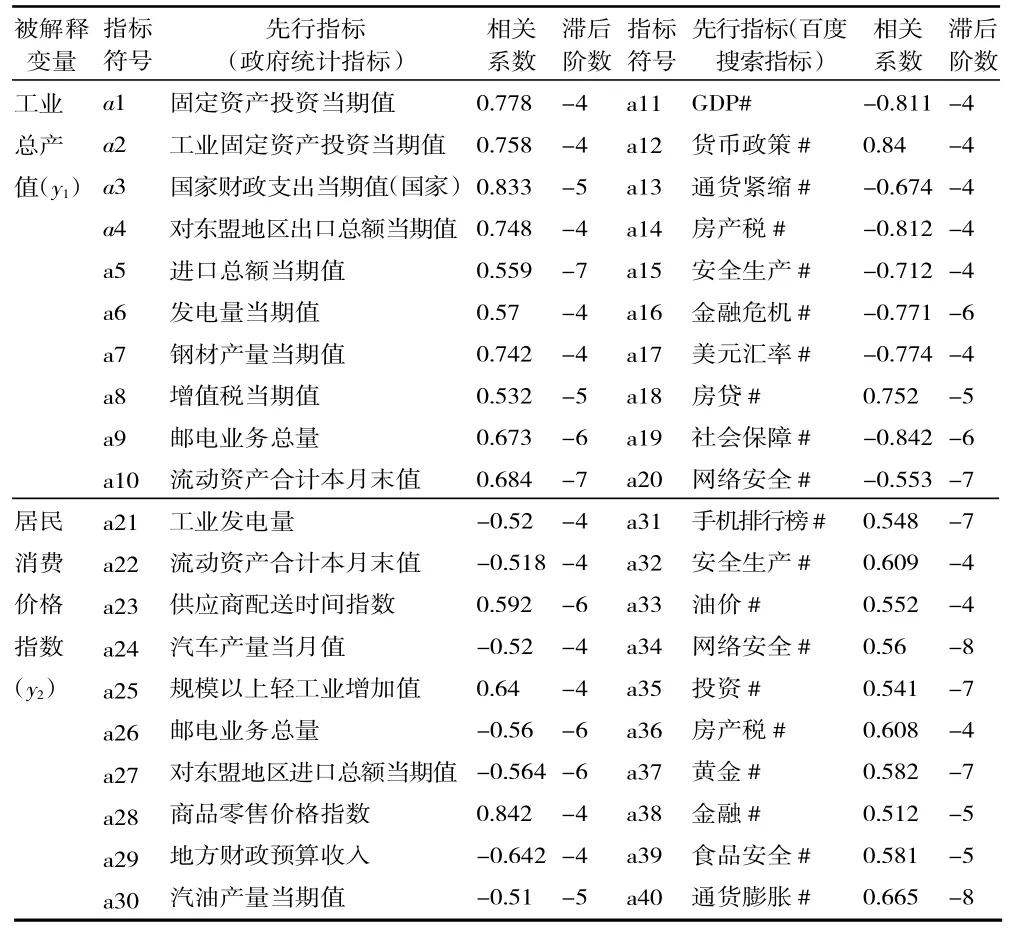
表2 时差相关分析筛选出的先行指标
根据上述选取的先行指标对应的最佳滞后阶数对数据进行月度平移调整得到新的数据集,对新数据集进行自变量和因变量的相关性分析,结果显示调整后的指标通过相关性检验,可以用来建立预测模型。
3.预测模型构建
(1)单位根检验。本文以工业总产值(y1)和居民消费价格指数(y2)为被解释变量,以上文筛选出来的表2 中的先行指标按照其最佳滞后阶数变换后的数值为解释变量建模。为了减少波动性和异方差对计量结果的影响,我们先对各序列取对数再进行ADF 单位根检验。ARDL 模型要求建模数据序列必须为0 阶单整(即I(0))或1 阶单整(I(1)),但不要求同时同阶稳定。工业总产值(y1)及相关序列的检验结果为:lny1为I(1),lna1、lna2、lna3、lna4、lna6、lna8、lna9、lna11、lna12、lna13、lna14、lna16、lna17、lna18 共14 个序列为I(1),符合ARDL 建模标准,lna5、lna7、lna10、lna15、lna19、lna20 共6 个序列为I(2),不符合ARDL 建模标准。居民消费价格指数(y2)及相关序列的检验结果:lny2为I(0),lna23、lna24、lna27、lna28、lna30、lna32、lna38、lna39、lna40 共9 个序列为I(0),lna26、lna29、lna31、lna33、lna36、lna37 共7 个序列为I(1),这16 个序列符合ARDL 建模标准;lna21、lna22、lna25、lna34 共4 个序列为I(2),不符合ARDL建模标准。我们对符合建模标准的变量进行了格兰杰因果检验,共8 个变量是工业总产值的格兰杰原因,7 个变量是居民消费价格指数的格兰杰原因,结果如表3、表4 所示。根据单位根检验和格兰杰因果检验的结果并通过经济分析,我们最后在工业总产值(y1)预测模型中选择了lna1(固定资产投资当期值)、lna4(对东盟地区出口总额当期值)、lna6(发电量当月值)、lna11(GDP-广西百度指数)、lna12(货币政策-广西百度指数)和lna18(房贷-广西百度指数)作为自变量;在居民消费价格指数(y2)模型中选择了lna26(邮电业务总量)、lna29(地方财政预算收入)、lna30(汽油产量当期值)、lna36(房产税-广西百度指数)、lna38(金融-广西百度指数)、lna39(食品安全-广西百度指数)作为自变量。
(2)模型的计量结果及分析。我们将筛选出来的自变量纳入模型进行估计,工业总产值模型中用x1、x2、x3 和z1、z2、z3 分别表示a1t-4、a4t-4、a6t-4和a11t-4、a12t-4、a18t-5,居民消费价格指数模型中用x4、x5、x6 和z4、z5、z6 分别表示a26t-6、a29t-4、a30t-5和a36t-4、a38t-5、a39t-5①变量的滞后阶数如表2 所示。。根据方程(1)~(5)构建ARIMA和ARDL 系列模型,其计量结果如表5、表6 所示。
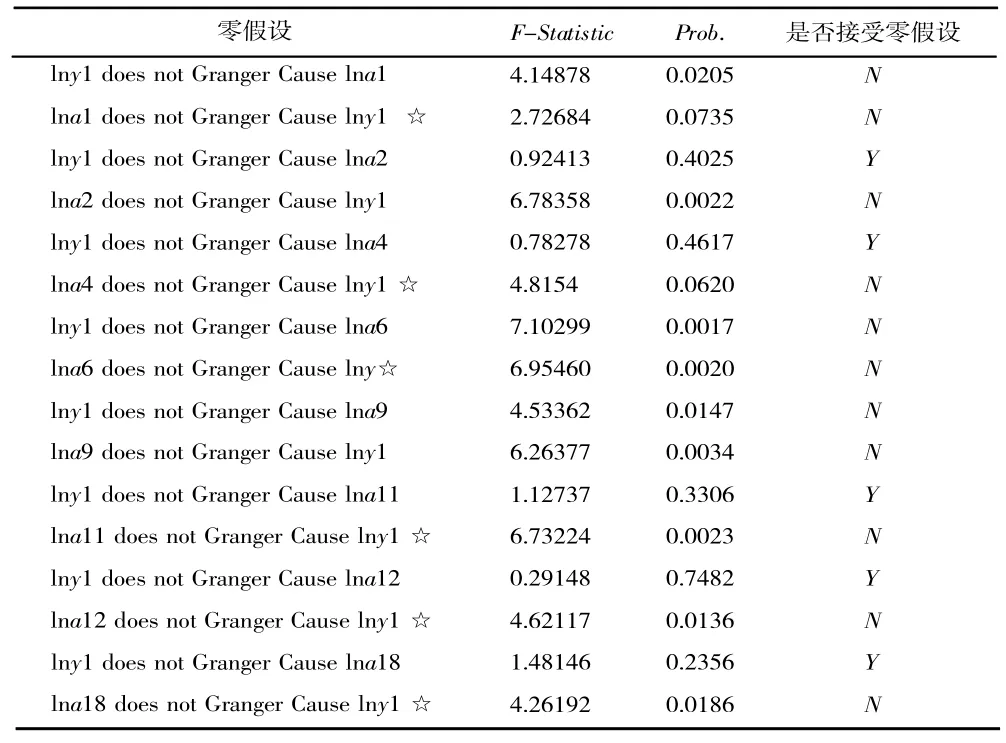
表3 工业总产值的格兰杰因果检验结果
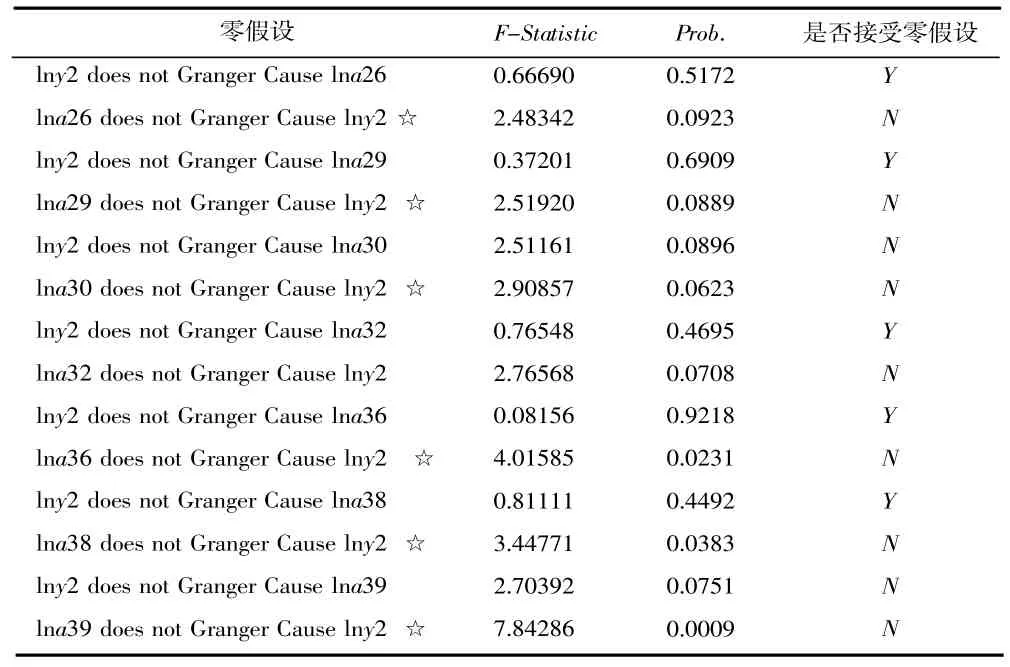
表4 居民消费价格指数的格兰杰因果检验结果
从表5、表6 可知:(1)确定各个估计模型的具体形式。由于工业总产值序列为1 阶单整,故采用ARIMA(p,d,q)和ARDL 系列模型;居民消费价格指数为0 阶单整,故采用ARMA(p,q)和ARDL 系列模型。各模型中,ARIMA(p,d,q)、ARMA(p,q)和ARDL+X 不包含百度搜索指数,ARDL+Z 和ARDL+X+Z 包含百度搜索指数。ARIMA 的p、d、q 参数采用BIC 准则确定,ARDL 模型的p、q 参数采用SC 准则确定,最终工业总产值的估计模型分别为ARIMA(6,1,1)、ARDL+X(4,3,0,0)、ARDL+Z(4,4,1,0)、ARDL+X+Z(3,2,0,0,2,0,4),居民消费价格指数的估计模型分别为ARMA(3,2)、ARDL+X(1,0,0,1)、ARDL+Z(1,0,0,0)、ARDL+X+Z(4,2,1,2,0,0,1)。(2)比较各模型的拟合程度。在工业总产值的4 个估计模型中,拟合参数R2分别为0.890 4、0.969 9、0.999 6、0.999 8,各模型均具有很好的拟合效果,其中ARDL+X+Z 模型的拟合程度最高,该模型F 统计量显著,DW 大于2;在居民消费价格指数的4 个估计模型中,R2分别为0.644 9、0.676 6、0.669 8、0.872 9,ARDL+X+Z 的拟合程度最高,该模型F 统计量显著,DW 大于2。(3)推断各变量间的关系。计量结果显示:ARDL 系列模型的被解释变量y1、y2均受到其前期数值的影响,但影响程度存在差异;不同模型包含不同的解释变量,反映着变量间不同的内在关系。通过模型的拟合系数,可以推断变量间的关系,如:在工业总产值的ARDL+X+Z 模型中,lny1与lnx1、lnx3、lnz1、lnz2、lnz3(或其滞后项)均在10%的显著性水平上存在相关关系,与lnx2 的系数在统计意义不显著;在居民消费价格指数的ARDL+X+Z 模型中,lny2除了与lnz4 统计意义不显著之外,与lnx4、lnx5、lnx6、lnz5、lnz6(或其滞后项)均在10%的显著性水平上存在相关关系。模型的计量结果表明区域经济预测指标与网络搜索数据和政府统计指标之间存在比较稳定的关系。
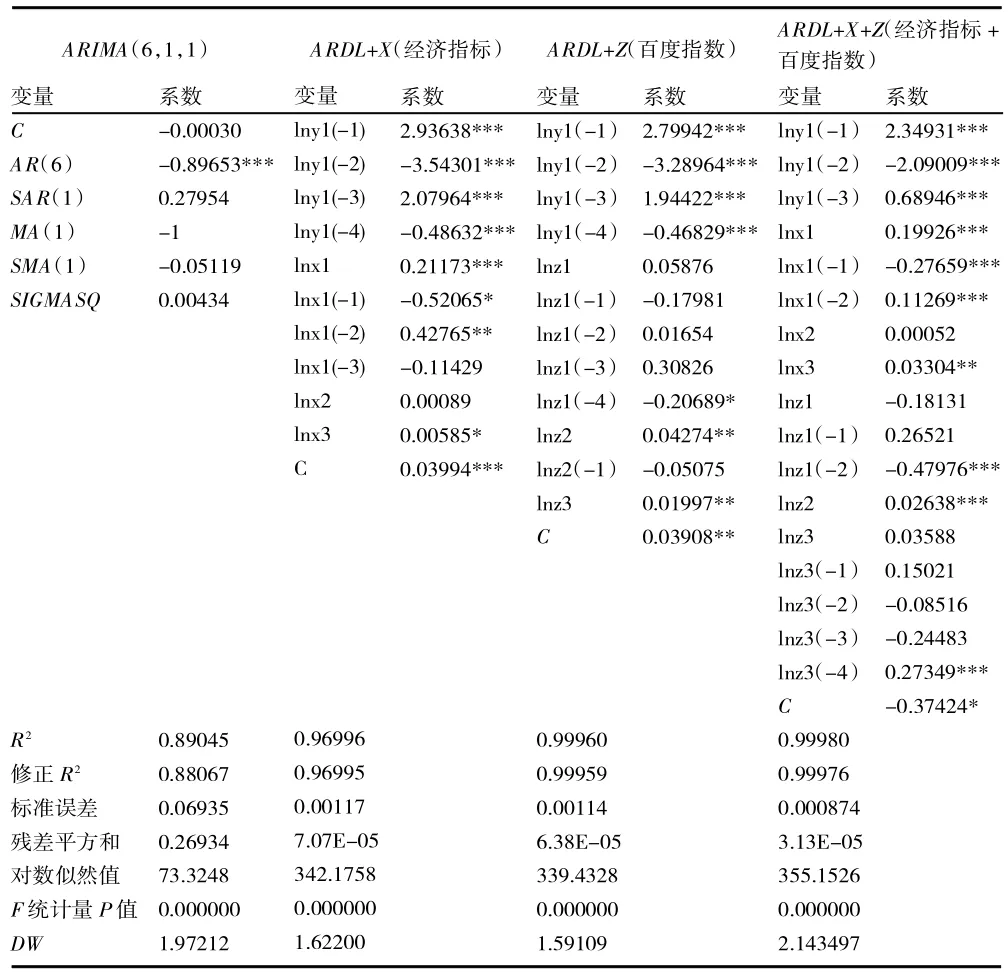
表5 各估计模型的计量结果(工业总产值)
(3)边界检验和稳定性检验。由于ARDL 模型的估计必须在因果变量存在协整关系的前提下才能进行,因此必须检验自变量之间是否存在协整关系。我们利用Pesaran 边界检验进行判断,表5、表6中工业总产值和居民消费价格指数的ARDL 系列模型的边界检验结果如表7 所示。各模型边界检验的F 统计量结果表明,各模型均在5%显著性水平下存在协整关系,说明我们构建的模型的系数估计在统计意义上成立。
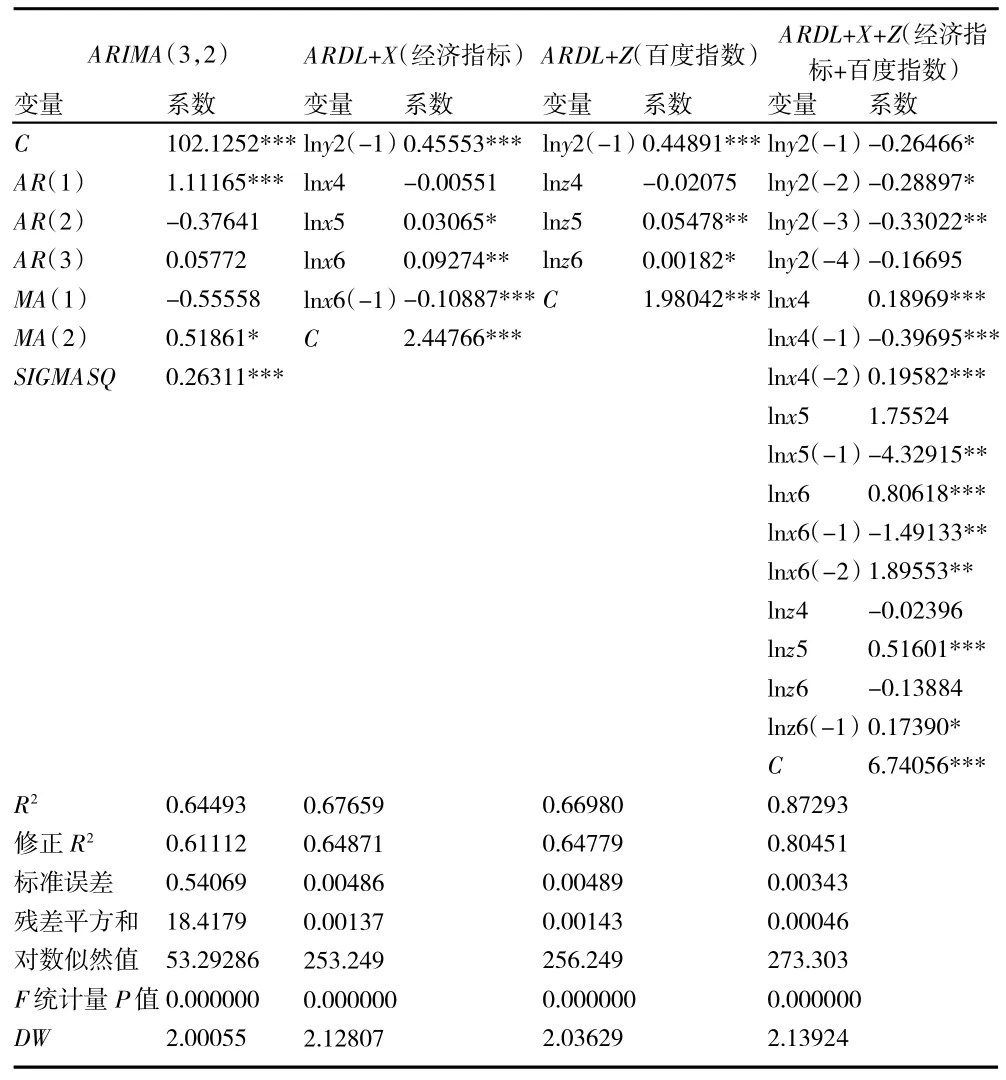
表6 各估计模型的计量结果(居民消费价格指数)
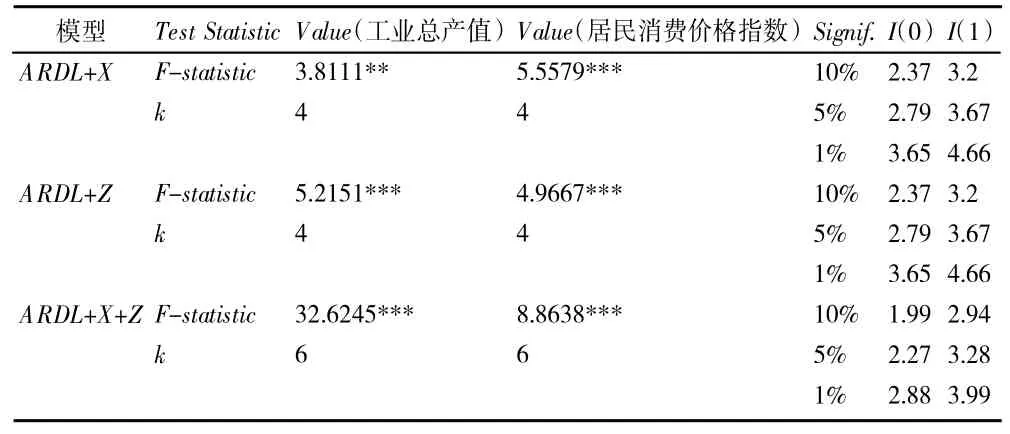
表7 F 边界检验结果
进一步,我们通过递归残差积累和(CUSUM)与递归残差平方积累和(CUSUMSQ)检验所构建的ARDL 模型的稳定性。检验结果显示各模型的CUSUM、CUSUMSQ 检验的残差值均在5%的误差内,表明构建的模型稳定,可以用于实际数的预测分析。图1 和图2 分别显示了工业总产值ARDL+X+Z 模型和居民消费价格指数ARDL+X+Z 模型的稳健性检验结果,图中粗线为5%误差范围,细线为残差值。
(二)模型预测效果评估和检验
首先,我们使用不同模型对样本数据进行预测,并采用平均绝对百分比误差(MAPE)、平均绝对误差(MAE)、希尔不等系数(Theil IC)和均方根误差(RMSE)4 个指标作为预测精度的衡量标准。各模型的预测结果如表8 所示。由表8 可见,以工业总产值为基准指标的预测结果中,ARDL+X+Z 模型在MAPE、MAE、Theil IC 和RMSE 方面均表现最好,其次是ARDL+Z 和ARDL+X 模型,ARIMA 模型预测精度最低;以居民消费价格指数为基准指标的各预测结果中,ARDL+X+Z 模型的各项预测误差值最小,随后依次为ARDL+Z、ARDL+X、ARMA。两个基准指标的各项预测结果显示,ARDL 系列模型比ARIMA 系列模型预测效果更好,包含网络搜索数据的模型(ARDL+Z 和ARDL+X+Z)比仅使用政府统计指标的传统模型(ARMA、ARIMA、ARDL+X)预测精度更高。综合表5、表6、表8 的结果,本文采用ARDL+X+Z 模型为工业总产值和居民消费价格指数的预测模型。
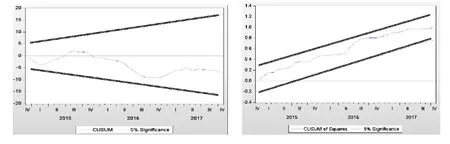
图1 ARDL+X+Z 模型的稳健性检验结果(工业总产值)
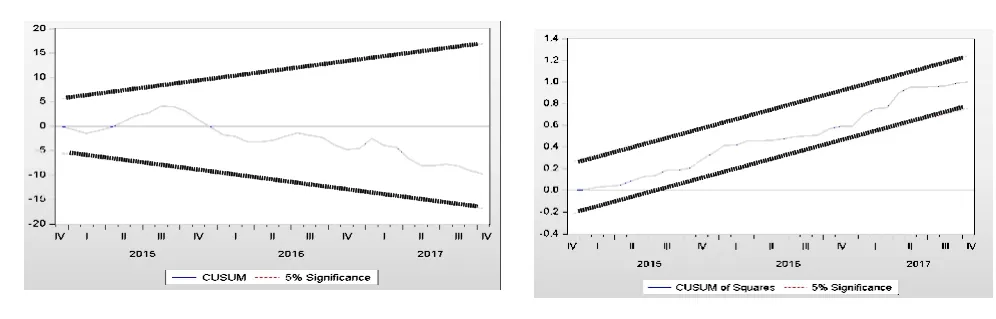
图2 ARDL+X+Z 模型的稳健性检验结果(居民消费价格指数)
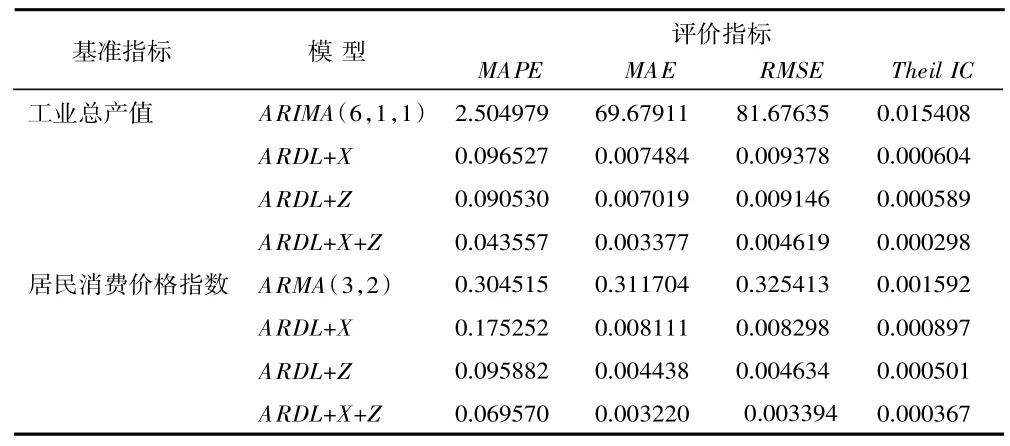
表8 预测模型对比结果
其次,运用ARDL+X+Z 模型计算出建模期间(2012 年1 月—2017 年9 月)广西工业总产值和居民消费价格指数的拟合值,将其与实际值对比来评估模型拟合度,对比结果如图3 所示。从图3 可知,我们构建的广西工业总产值模型在样本期间的拟合值与实际观测值拟合结果理想;构建的居民消费价格指数多元回归模型的拟合值虽与实际值在波峰与波谷处出现一些偏差,但也能比较准确地反映其大致的波动和趋势。
最后,运用ARDL+X+Z 模型计算检验期间(2017年10 月—2017 年12 月)的广西工业总产值和居民消费价格指数的拟合值,将其与实际值对比来检测模型的预测效果,对比结果如表9 所示。从表9 可知,工业总产值的预测误差率和居民消费价格指数预测模型的误差率均小于0.2%,说明所构建模型的预测效果很好。
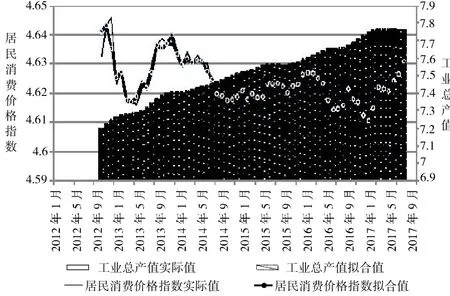
图3 模型拟合值与实际值的对比结果
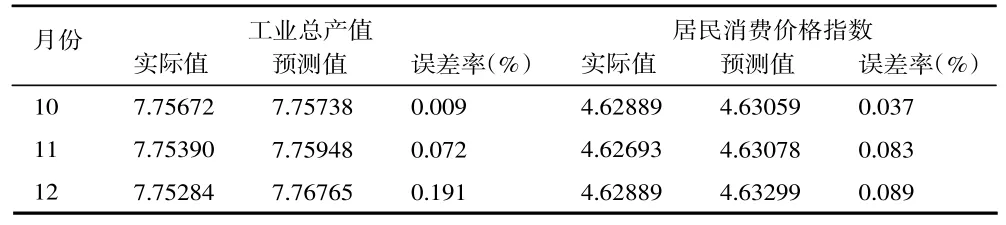
表9 ARDL+X+Z 模型预测结果及误差率
综上分析可见,本文构建的包含政府统计指标和百度搜索指标的两个ARDL+X+Z 模型有效地减小了预测误差,能够很好地对区域经济指标进行预测。由于工业总产值模型中的自变量滞后4~5 期,居民消费价格指数模型的自变量滞后4~6 期,所以我们构建的模型能利用这些数据比官方统计数据公布前给出预测结果。
四、结论与展望
本文将网络搜索数据纳入区域经济指标的实时预测体系,将网络搜索指标与政府统计指标相结合,从生产和消费两个不同的角度预测广西经济增长。首先,选取工业总产值和居民消费价格指数作为预测的基准指标,若干个百度搜索关键词和与经济波动相关的政府统计指标作为分析的备选指标,基于广西2012 年1 月—2017 年12 月间的相关数据运用时差相关分析法从备选指标中筛选出拟作为解释变量的先行指标;其次,在对各指标时间序列进行平稳性检验、协整检验的基础上,根据网络搜索数据的计量特性和指标间的内在关联性,采用ARMA 和ARDL 两个系列的5 个不同模型分别构建广西工业总产值预测模型和广西居民消费价格指数预测模型,其中,ARMA 系列和ARDL+X 为不包含网络搜索数据的模型,ARDL+Z 和ARDL+X+Z 为包含网络搜索数据的模型;最后,对所构建的模型进行实证拟合检验和对比分析得出最优预测模型,并利用最优模型评估预测效果。研究结果表明:(1)网络搜索行为与区域经济波动存在一定相关性,反映时滞的差异使得网络搜索指标与经济指标之间存在先行-滞后关系,采用科学的方法可以从众多网络搜索指标中识别出能优化区域经济预测模型的关键性先行指标。(2)本文构建的广西工业总产值和居民消费价格指数的ARDL+X+Z 模型,充分考虑了网络搜索数据和政府统计指标之间的内在关联性、网络搜索数据的计量特性,有效地进行了区域经济指标的预测,表明搜索数据与区域经济指标存在稳定的关系,合适关键词的百度搜索指数是区域经济预测的有效度量指标。(3)引入网络搜索数据的模型比仅使用政府统计指标的传统模型能够更及时更精确地进行区域经济预测预警分析。
借鉴国内外学者的研究,我们为网络搜索指标在区域经济预测预警领域的研究和应用在以下方面做了有益探索:(1)综合使用了时差相关分析、单位根检验和格兰杰因果检验相结合的方法从众多网络搜索指标中识别出能优化区域经济预测模型的关键性先行指标;(2)考虑指标间的内在关联和不同特性,将网络搜索指标与政府统计指标相结合构建多个不同的预测模型。由于使用网络搜索指标进行区域经济预测具有数据获取及时方便、预测精度高、样本统计意义明显等优势,本文的研究思路和方法可拓展到其他官方统计的月度公布数据的预测,也可为其他省份乃至全国的经济预测提供参考。但本文也存在一些局限性:(1)仅从百度搜索指数来考虑网络搜索行为与经济的关联,忽略了搜狗、360 等其他搜索引擎和微博、论坛等社交媒体的指标的影响;(2)在百度推荐功能和参考相关文献的基础上选择初始关键词样本库,未运用该研究领域的前沿方法。后续研究其他指标的预测时,我们将探讨LASSO、随机森林、支持向量基等机器学习方法来筛选初始关键词,并将网络搜索数据和互联网其他指标结合(如论坛评论、网络浏览等),进行数据的深入挖掘和整合,更准确地把握网络大数据与经济预测的关联。
猜你喜欢
纺织服装周刊(2022年15期)2022-05-12
今日农业(2021年5期)2021-11-27
Defence Technology(2020年4期)2020-07-02
青年与社会(2018年2期)2018-01-25
大众理财顾问(2016年10期)2016-12-02
大众理财顾问(2016年9期)2016-10-11
中国医学人文(2015年6期)2015-06-08
声屏世界(2015年1期)2015-03-11
现代企业(2015年8期)2015-02-28
现代企业(2015年8期)2015-02-28
