
视觉同时定位与建图方法综述*
2021-03-20 12:48朱东林徐光辉狄恩彪李明灿
通信技术 2021年3期
朱东林,徐光辉,周 捷,狄恩彪,李明灿
(陆军工程大学,江苏 南京 210007)
0 引言
机器人领域作为如今热门的研究领域之一受到了研究者们的广泛关注,但是机器人的研究始终伴随着如何使机器人能够在陌生的环境中自主探索和行动这个关键性问题。SLAM 先前由Smith Self 和Cheeseman 提出,至今已有30 多年的研究历程,大致分为传统时期、算法分析时期和鲁棒性-预测性时期3 个时间段。
对于未知环境,为了能够自主移动和探索,机器人需要依靠传感器获取环境数据。机器人首先需要解决定位问题即明确自身位置,随后测量自身周围的环境信息并建立地图,同时保存已建的地图以备后期在该地区内直接进行定位和导航。2007 年,MonoSLAM[1]是首个利用纯视觉恢复相机的移动路径,使用概率框架在线创建稀疏并持久的自然地标地图,同时由先验信息辅助系统完成初始化,由扩展卡尔曼滤波法实时更新状态。此外,相机采用恒速度运动模型,相机状态的误差用不确定性程度Qv衡量。2008 年,PTAM[2]实现了跟踪和建图用不同线程,并可在地图中显示AR 虚拟物体。前端采用FAST 角点检测算法且引入关键帧技术,利用极线约束法匹配特征点计算旋转矩阵,后端则采用非线性优化的BA(Bundle Adjustment)方法。2014 年,SVO[3]为了在无人机高速移动状态下估计准确位姿,采用特征点法和直接法相结合的方法实现高频高精度里程计。直接法中摒弃传统算法对图像中少量的大补丁图像块的提取,转而提取大量小补丁图像块。RTAB-MAP 针对大场景稠密建图,并提出内存管理方法来解决大场景长时间稠密建图存在的回环检测和实时性问题。2018 年,VINS-Mono[4]设计了一个完备的运动状态估计器。它是由单目和IMU组装成的一个小巧装置,用于度量六自由度,可以广泛应用移动机器人、无人机和移动电子设备等SLAM 系统。DSO[5]依靠图像上的采样像素生成稀疏地图,所用模型涉及光度校正来消除曝光时间和镜头渐晕等影响。ORB-SLAM 在PTAM 基础上添加了回环检测线程,是第一个具备跟踪、回环检测和建图环节的完整实例,最终准确实现了相机的运动轨迹和地图中轨迹的一致。2019 年,基于模型的视觉惯性里程计VIMO[6]正逐步取代传统的视觉惯性里程计VIO,关注点放在作用于系统的外力上,把动力学和外力结合在残差中作为约束产生了一种精度较高的状态估计器。2020 年,DeepFactors[7]建立在CodeSLAM[8]的基础上,结合深度学习重新表示已学习的紧凑性深度图对光度误差、重投影误差和几何误差,实现单目相机构建稠密地图。一个无需配置相机参数,便可较灵活地选择多个数量的相机组合使用,完成自适应初始化的SLAM 系统[9]。语义NodeSLAM[10]根据VAE 和概率渲染引擎判别物体形状及重构多视图物体。Vid2Curve[11]系统单凭RGB 视频流也可实现细线条物体三维重建,摒弃传统基于深度和图像纹理,而采用基于2D 曲线特征的方法抽取出骨骼曲线,沿曲线按物体宽度融合相应半径圆饼反映物体线条。AVP-SLAM[12]借助对视角和光照具有鲁棒性的语义特征构建地下停车场地图,完成了自动泊车任务。在任一亮环境下,基于物理的深度网络考虑反射、折射和内部全反射对物体表面法线重建,进一步实现透明物体的三维重建[13]。ESVO[14]是SLAM 领域首次用双目事件相机构建的视觉里程计,在保证每帧图像时空一致性前提下,逆深度估计附加时间戳,并采用了IRLS 非线性优化和前向合成Lucas-Kanade 方法。除此之外,目前开源并且框架完备的算法有ORB-SLAM[15]、DTAM[16]、RGBD-SLAM[17-18]、改善大场景下回环检测性能的算法[19-20]。综上所述,对大量视觉算法进行分析归纳出视觉SLAM框架涵盖传感器数据输入、前端VO、后端优化、回环检测和建图5 个主体。图1 为视觉SLAM 的算法流程。
1 前 端
前端视觉里程计部分实现对位姿的计算。计算方法大致有特征点法、直接法、光流法和深度学习与帧间估计4 种。如图2 所示,视觉里程计要计算估计出相机各帧位姿(R,t),从初始位置C0(可以自定义)起,当前位置Ck通过(R,t)和上一时刻的位置Ck-1来计算,公式为Ck=RCk-1+t。其中,(R,t)为K和K+1 时刻之间的相机平移和旋转变化,可根据图像变换的基本矩阵、单应矩阵和SVD 分解本质矩阵计算获得,从而恢复相机的运动轨迹。
1.1 特征点法
特征点法是在相邻帧之间选取特征点并进行匹配,然后使用RANSAC、M 估计或最小中值估计等方法,尽可能滤除错误匹配[21]的噪声点,最后求得位姿。介于对精度和时间的考虑,关键点检测器和描述符组合[22]搭配使用。检测器算法有ORB、SIFT 以及SURF 等,描述符算法有BRIEF、FREAK等。由于深度图像的取舍,前端将面临2D-2D、3D-2D 和3D-3D 共3 种情形,故使用特征点法时最主要考虑的问题是算法选择问题和计算(R,t)方法的选择问题。
(1)SIFT/SURF。SIFT[23]/SURF[24]算法使用基于梯度方法的HOG 作为描述符,通过物体在局部区域中的强度梯度分布来描述物体的结构。

图1 视觉SLAM 算法流程
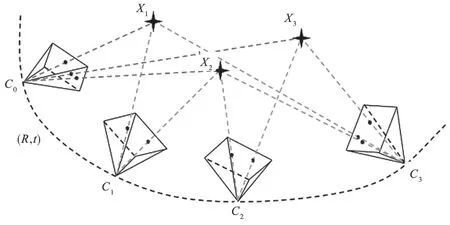
图2 相机运动轨迹
(2)RISK/BRIEF/ORB/KAZE/FREAK。上述算法使用二进制Binary 描述符,仅依靠图像自身强度信息,将关键点周围信息编码成一串二进制数。BRISK 算法[25]采用长距离对和短距离对,其中长距离对描述图像补丁的梯度方向,而短距离对用于组成二进制字符串来描述梯度大小。
长距离对搜索函数为:

短距离对搜索函数为:
长对计算关键点方向向量公式为:
短距离对组装成二进制串公式为:

上面使用相同数量图片及同一工程对所有可能的检测器和描述符组合进行性能比较实验。由表1 各种检测器和描述符组合的总运行时间结果可以看出,FAST+BRIEF 速度最快,FAST+ORB 次之。表1 中×表示当前检测器和描述符不能搭配使用,相应的实验结果也将不存在。表2 为各种检测器和描述符组合的匹配点数目结果,可以看出BRISK+BRIEF 匹配点数目最多,BRISK+SIFT 和BRISK+FREAK 次之。对于所有类型的几何变换来说,SIFT 和BRISK 的总体精度最高。
1.2 光流法
光流法[26]是为了应对图像中的特征点难提取、纹理简单且单一的情况提出的。它是基于亮度不变的假设I(x+dx,y+dy,t+dt,)=I(x,y,t),即图像中某一位置的像素其亮度在短时间内不会变化的思想来选取图像中某些像素点进行跟踪,最后计算出位姿。
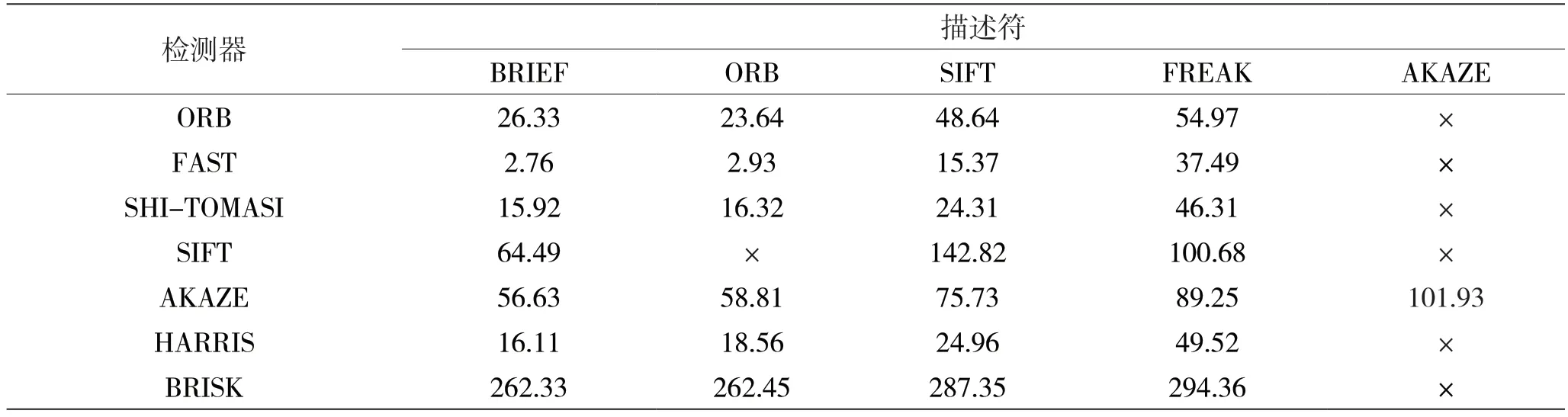
表1 各种检测器和描述符组合的总运行时间(单位:ms)

表2 各种检测器和描述符组合的匹配点数目(单位:个)
不变性假设关于时间t进行求导,得:

整理为矩阵形式,为:

式中:Ix代表该点x方向梯度,u代表该点x方向速度;同理,Iy、v分别代表y方向梯度和速度:It表示图像随时间的变化量。
1.3 直接法
直接法依据灰度不变性I1(x)=I2(x´)假设,利用图像中像素灰度值的变化来估计相机的运动方向。只要环境中有亮度并使得相机运动时图像像素点有亮度的变化,直接法就能工作。因为直接法只关注亮度变化,不关注特征信息,故效率较高。常见的块匹配算法有NCC[27]、SSD 等。
DVO[28]在假设条件下用高斯牛顿迭代法计算相机的运动位姿(R,t),预测场景点深度值和深度图提供的实际深度值之间的差异预估运动。
LSD-SLAM[29]是继特征点法后将直接法应用于SLAM 的典型算法,省略了特征点提取环节,从而提高了算法效率,将图像中梯度较大的像素点还原出对应3D 地图坐标来尽量反映场景物体的轮廓信息,即建立了半稠密的地图。
跟踪线程中以归一化的方差光度误差最小化为目标,对上一关键帧的姿态值左乘这两个关键帧之间的刚体变换值δξ(n),从而得到当前关键帧的位姿。
2 后 端
后端优化主要对前端的位姿值进行优化,尽量减少累积误差。前端当前建立的带有累积误差的局部地图,后端会优化当前的地图,避免地图误差越来越多。目前,最主要的后端算法包括基于滤波理论的扩展卡尔曼滤波法和基于优化理论的BA 和图优化法、位姿图法。除此之外,基于滤波理论的算法还有UKF[30]、EIF、SEIF 以及PF 等,基于优化理论的算法还有非线性优化、TORO 以及G2O 等。
2.1 滤波法
卡尔曼滤波器包含预测和更新两个任务,被看作两步骤程序。
步骤1:使用上一状态值估计下一状态及不确定性:

步骤2:使用当前的测量值透过加权平均来更新当前的状态估计值:

式中,Kk表示卡尔曼增益,Hk表示观测模型,表示残差。
MonoSLAM 的后端采用扩展卡尔曼滤波法,相机采用恒速度运动模型,受瞬间外力对相机的影响,需要再更新相机运动状态量。未知力度对相机瞬时作用的影响用噪声向量n表示,其中n包含短时间内外力的线加速度和角加速度产生的线速度和角速度。
2.2 优化法
BA(Bundle Adjustment)目标函数中,相机位姿变量xc=[ξ1,ξ2,…,ξm]T∈R6m和路标点变量xp=[p1,p2,…,pm]T∈R3n组成自变量,作为所有待优化的变量x=[ξ1,…,ξm,p1,…,pn]T。变量发生变化时对应的增量方程为:

式中,F、E分别表示关于相机位姿和路标点位置的偏导数。无论使用G-N 方法还是L-M 方法,最后都将面对增量线性方程:

以G-N 为例,则H矩阵为:

认识到矩阵H的稀疏结构,并发现该结构可以自然地用图优化来表示,此处引入G2O。若一个场景内有5 个相机位姿(C1,C2,C3,C4,C5)和2 个路标(P1,P2)。关系结构图如图3 所示,以最小化下列函数为目标,优化所有图中的变量:

式中,Pj表示第j个路标点,表示j=N个路标点分别在第i个相机下的像素坐标,si表示各路标点到各相机平面的深度值。

图3 关系结构
2.3 位姿图法
从图优化知,随着相机运动需加入大量路标节点。路标节点数量远大于位姿节点的数量,将严重降低计算效率。因此,舍弃路标节点变量的优化,只关注相机位姿变量xc=[ξ1,ξ2,…,ξm]T∈R6m的优化,如图4 所示。

图4 关系结构
首先根据两帧已记录(前端计算)的位姿得到相对位姿变换:

重新根据i、j两帧图像利用对极几何得到实际位姿增量Tij,优化的目标为:

若所有位姿节点之间的边集合记做κ,则总体目标函数为:

3 三维地图构建
三维地图的表达方式有深度图(Depth)、点云(Point Cloud)、体素(Voxel)和网格(Mesh)共4 种。图5 为4 类三维建图方式样例,深度图中每个像素表示物体距离相机平面的值。点云是大量点组成的数据集,每个点包含位置、颜色等信息。体素是由一个个矩形小方块组成,类似于三维空间中的像素。网格由许多三角形面拼接成的多边形以接近现实物体表面,每个网格包含三角形的顶点、边和面。

图5 4 类三维建图方式样例
3.1 深度图
Shao 等人[31]提出了一种立体视觉和阴影形状(Shape From Shading,SFS)算法,能够同时生成深度图和方向图,但很难作用在颜色和纹理不均一的场景。强度图像与对应的深度信息进行隐马尔可夫模型(Hidden Markov Model,HMM)建模,应用单张图像的3D 人脸或手的重构系统[32]。Saxena 等人[33]将图像划分出多个区域块,使用马尔可夫随机场(Markov Random Field,MRF)对逐个像素块计算出相应参数,以描述每块所指的3D 平面位置与方向,而各个平面共同组成最后的3D 场景。Liu等人[34]使用有监督的学习方法对非结构化场景图进行深度预测,其中模型采用经过区分训练的马尔可夫随机场(MRF)。受生物学复杂单元[35]的启发,对图像像素之间相关性进行编码,从数据中学习深度和运动线索实现3-D 运动分析。
最近,Karsch 等人[36]使用基于SIFT Flow[37]的KNN 传输机制从单个图像估计静态背景的深度,并利用运动信息对其进行增强,以更好地估计视频中的运动前景对象。Eigen 等人[38]使用两个深度网络分别进行图像粗略预测和局部细化预测,实现了对单张图像的深度估计,并提出了一个尺度不变的损失函数。Ladicky 等人[39]提出了将语义对象标签与单眼深度特征集成在一起的方法,以提高性能,但它们依靠手动添加的方式并使用超像素来分割图像。Laina 等人[40]建议使用基于ResNet 的网络结构来预测深度。Xu 等人[41]建议使用CNN 结构构建用于深度预测的多尺度条件随机场CRF。BA-Net[42]输入图像使用预先学习(端到端)的深度图生成器产生多个基础深度图,并通过特征量度BA 将这些深度图线性组合出最终深度。
3.2 点 云
Fan 等人[43]实现了对单图像中单个物体以点云形式进行三维重建,开创了点云生成的先例。从一张2D 图像恢复一个3D 物体可能出现多个可能的较好结果,使得此问题不适用经典回归或分类方法解决,转而研究基于点云表示的3D 几何生成网络。网络由输入图像和推断的视点位置确定3D 点云中的点位置。点集生成网络恢复出多个可能的结果,再经损失函数确立最终点云结果。图6 为系统的整体结构图。

图6 系统结构
2D 图恢复所有可能的3D 形状:

损失函数:
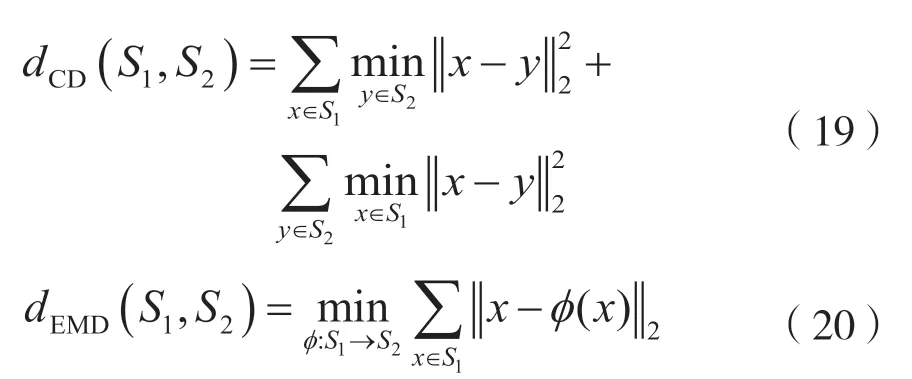
ElasticFusion[44]算法侧重构建清晰稠密地图。对RGB-D 相机获取的深度图进行操作,相关信息融合到初始的surfel 数学模型中,一步步优化模型外形,最后使用此模型描画场景。图7 展示了ElasticFusion 算法的整体实现流程。
建图线程的两个步骤。一是surfel 模型初始化采用Deformation 图使用均匀抽样初始化。它由许多node 组成,每个node 带有等参数来影响surfel 模型进行表面变形。二是RGB-D 相机获得深度图像,使用内参将深度图转为点云。点云和RGB彩色图像使用跟踪线程计算的相机几何位姿和光度位姿,并利用OPENGL 融合到surfel 模型中。
3.3 体 素
3D-R2N2[45]没有在观察对象之前需先匹配合适的3D 形状,以尽可能迎合2D 图像中所描述的物体。而受早期使用机器学习来学习2D 到3D 映射以进行场景理解的工作启发[33,46],引入深度卷积神经网络。网络建立在LSTM 和GRU 的基础上,实现了单视图和多视图的3D 重建。
网络框架包含Encoder、3D Convolutional LSTM和Decoder 共3 大部分,如图8 所示。Encoder 是一种CNN 结构对输入图像进行编码;Decoder 是解码过程;3D Convolutional LSTM 是由许多LSTM 单元组成的正立方体网格结构,每个单元负责一个已编码的部分并恢复出相应体素,所有体素格组成3D物体。损失函数使用二分类交叉熵函数,决定相应体素格状态是否占有。

图7 ElasticFusion 算法框架流程

3.4 网 格
Pixel2Mesh[47]在基于图的卷积神经网络中输出3D 网格图形。任一单图像输入之前,系统默认同步初始化一椭圆球作为初始的物体形状。全卷积神经网络一步一步提取2D 图像中的细节特征,同时图卷积神经网络受图像特征的约束将细节附加于初始的椭球体上,随着特征数量的不断增加致使椭球不断形变(粗糙到细密过程),最终得到最后物体。图9 为双网络协作流程。

图9 双网络协作流程
4 种约束网格形变的损失函数为:

图卷积神经网络中包含与Mesh 网格对应的顶点(V)、边(E)和特征向量(F),定义函数如下:

4 发展趋势
当前,视觉SLAM 的发展趋势主要涵盖以下3个方面。
4.1 面对特殊材质的透明物体的重建
透明物体的重建受光反射、折射和内部全反射等因素影响。透明物体成像的物理基础是界面处的折射遵循斯涅尔定律,反射由菲涅尔方程确定。由高折射率介质进入较低折射率介质界面处的入射角大于临界角时,就会发生全内反射。文献[13]中利用了深层网络学习和模拟图像形成的物理基础知识。网络内的渲染层可对最多两次反射的折射光路进行建模,以建立对应于物体正反两面投影光线的曲面法线,可在任意环境下使用不受约束的图像来重建透明形状。图10 为透明物体样例。

图10 透明物体样例
4.2 面对海面以下复杂场景的重建
由于无线电信号被海水吸收,因此无法使用GPS 系统定位水下机器人。Ferrera 等人[48]致力于在水下海床进行同步定位和制图,使用配备单目、IMU 和压力传感器的设备,采集制定了3 个不同环境下的数据集。对于每个数据集还使用SFM 离线计算了真实轨迹,以便能够使后期和实时定位建图方法进行比较。图11 为SFM 对水下场景的重建结果,曲线代表计算的水下机器人移动轨迹。此外,Ferrera 等人[49]提出一新型的单眼UW-VO(水下视觉测距法)算法,克服了由于介质特定属性导致的视觉退化。

图11 重建的水下场景结果
4.3 面对纤细复杂物体的重建
纤细物体(如树枝、电线和铁丝等)通常表面积小且缺乏纹理特征和点特征,故无法使用传统的基于图像特征点的重建方法获取3D 模型。Vid2Curve 使用曲线特征的新方法,锁定连续图像中同一物体的变化动态计算位姿,以一种迭代结构优化策略逐步添加和处理所有图像帧,并改进估计的物体曲线结构。图12 为铁丝物体的重建结果。Usumezbas 等人[50]实现将图像中大量2D 曲线拓扑连接为3D 曲线集合,最后生成一个3D 曲线图。

图12 重建的铁丝物体结果图
5 结语
本文分析了SLAM 算法近20 年的最新进展情况,归纳出视觉SLAM 算法的整体框架,并阐述前端和后端包含的各种方法和相关理论,实例分析三维建图的各种方式,突出介绍了苛刻环境下的地图构建。视觉SLAM 是未来立体视觉感知颇具潜力的发展方向,其中视觉传感器具有成本低和普及度高的优势,极大地促进了SLAM 的研究及未来在电子设施上的应用。
猜你喜欢
上海师范大学学报·自然科学版(2021年4期)2021-09-23
现代信息科技(2020年22期)2020-06-24
中学生数理化·高一版(2020年1期)2020-02-20
计算机应用(2019年3期)2019-07-31
山东工业技术(2019年16期)2019-07-19
电子技术与软件工程(2019年6期)2019-04-26
科技与创新(2018年12期)2018-06-22
软件导刊(2016年9期)2016-11-07
科技视界(2016年2期)2016-03-30
少儿科学周刊·儿童版(2015年2期)2015-07-07
