
一种时间维度的论文影响力评价研究
2021-03-17 22:44许恩平贾娜李敏余以胜
重庆大学学报(社会科学版) 2021年6期
关键词:评价指标
许恩平 贾娜 李敏 余以胜



摘要:针对目前h指数存在的不足,学界尚缺乏一种综合有效的评价指标,为此,笔者期待介绍一种论文评价的ammaa算法,并提出一种融入时间维度的优化算法,即t_ammaa算法,通过对论文影响力的评价来反映学者个人的影响力评价。研究过程中,以Web of Science作为数据源,聚焦国内图情领域作者发文,计算论文ammaa值及t_ammaa值,进而得出学者的ammaa值及t_ammaa值,并將两种算法结果排名与学者H值排名通过归一化处理,进行实证对比分析。结果表明:t_ammaa算法综合考虑发文被引次数、被引次数的阙值限制、合著者人数及论文被引时间的异质性,既可以对独著和合著论文影响力进行综合性评价,也可以消除时间因素带来的影响,是一种更为合理的学者和论文影响力评价计量方法。
关键词:ammaa算法;时间异质性;多作者论文影响力;作者影响力;评价指标;破“五唯”
中图分类号:G350;G6444 文献标志码:A 文章编号:1008-5831(2021)06-0111-14
众所周知,学者所进行的科学研究及成果传播在科学进步及社会发展中发挥着重要作用[1],其成果形式多以学术论文、著作和专利为主。事实上,高校和科研单位的
人才引进、职称评定也愈加倚重学术论文在个人学术影响力评价中的作用。2018年教育部联合多个部门,开展清理“唯论文、唯帽子、唯职称、唯学历、唯奖项”(以下简称“五唯”)专项行动。需要注意的是,在破“五唯”过程中,尤其是破“唯论文”现象时,尚应充分考虑我国科研发展的不同阶段及其具体情况,“一步到位”既不现实也无必要,笔者以为应着力于扭转不科学的教育评价导向,进而对学者进行合理的学术影响力评价。
目前,国际上广泛应用的学术影响力评价指标,如被引次数、h指数、g指数等均是用于评估单作者影响力的方法。但随着信息技术的发展,科学合作与知识交流普遍常态化,多著者合作的形式可以显著提高学术研究水平[2],科学研究的进步需要多领域研究人员之间的合作[3]。在理工科领域,物理学论文的合作者可达上百人,目前共同作者数量有增加的趋势,文章由不止一位作者撰写成为越来越正常的现象[4]。但近年来,客座作者[5]、礼物作者[6]、非学术合作者[7]等署名资格问题[8]已经成为影响科研诚信的重要议题。相关研究也发现,合著者人数的增多,却未必能提高研究成果的影响力,如被引频次、下载量等[9]。因此,学术期刊大多要求每位合著者都要作出相应的努力和贡献[10-12],基于此,D.Gnana Bharathi提出了一种多作者聚合分析算法指标,即aggregating metrics for multiple authors’ analysis,简称ammaa算法[13]。
一、相关研究文献分析
2005年,Hirsch[14]提出综合考虑学者发文数量和发文质量的h指数影响力评价指标,并得到学术界的认可和推广应用。同年,即被Nature文章[15]评论道,h指数的魅力在于它能凸显那些有持久重大贡献却未得到与其声望相称荣誉的研究者。自h指数提出以来,国内外学者对其做了很多研究。随着研究的不断深入,h指数的固有缺点也不断暴露,如:(1)虚假合作,不能区分作者贡献[16];(2)对论文数量不敏感,只考虑h核内的论文数量和被引频次,忽略h核以外的论文;(3)无法跨领域评价作者影响力[17];(4)无法对学者近期影响力进行评价[18]等。至今,对h指数的修正研究扩展指数已不下30余种[19]。2006年,L.Egghhe从论文被引频次的累计贡献角度,提出g指数[14],同样侧重论文被引频次角度的还有R指数及Hr指数[20]。2010年,Prathap G.提出p指数,优化了h指数的灵敏度和区分度[21]。从作者合作角度进行修正的改进则包括均等共享和差异分享论文影响力两种。差异分享论文影响力研究包括考虑主要贡献作者和计算合作者权重。其中,考虑主要贡献作者是在计算h指数时,只纳入该作者作为主要贡献作者的论文,如hmaj指数[22];计算合作者权重则基于作者排序和合著者数量的荣誉分配法[23]。均等共享论文影响力研究包括直接对h指数进行平均和对论文数或被引次数进行平均,前者如hI指数[24],后者如hm指数[25]、pf指数[22]等。2016年,学者Shaon Sahoo针对合著论文个人贡献率问题提出I指数,使得各合著者随着论文作者数量的增加而减小,在一定程度上降低了没有实质贡献的“论文挂名”的影响[26]。2019年,学者D.Gnana Bharathi提出多作者聚合分析算法指标,即ammaa算法[13],该算法实现了通过对论文影响力的评价进而对学者影响力进行评价的目的。
综合以上研究,虽然都在一定程度上对h指数的缺点有所弥补或改进,但依然没有一种综合有效的方法应用于学者影响力评价中。为此,笔者期待在D.Gnana Bharathi提出的ammaa算法基础上考虑到时间异质性,提出一种融入时间因素的改进算法,即t_ammaa算法,并尝试通过数据实证,与h指数进行对比和相关性分析,证明t_ammaa算法对学者影响力评价结果更全面、公平和精细。
二、ammaa算法介绍
(一)ammaa算法原理
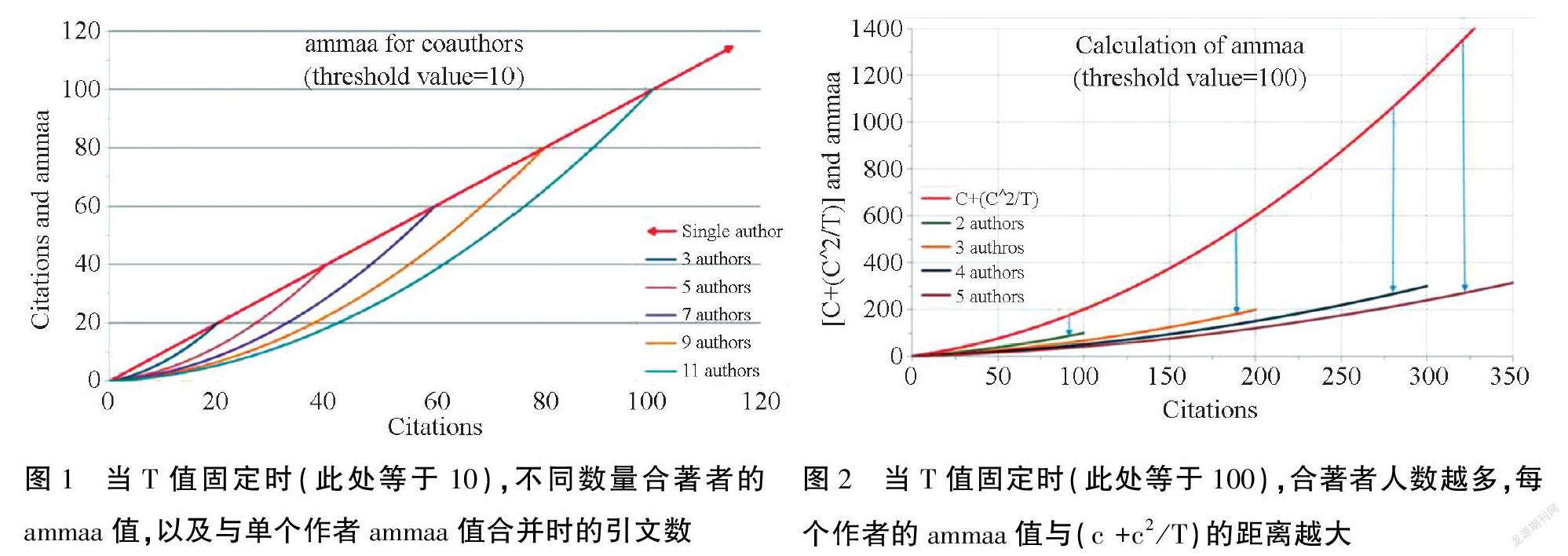
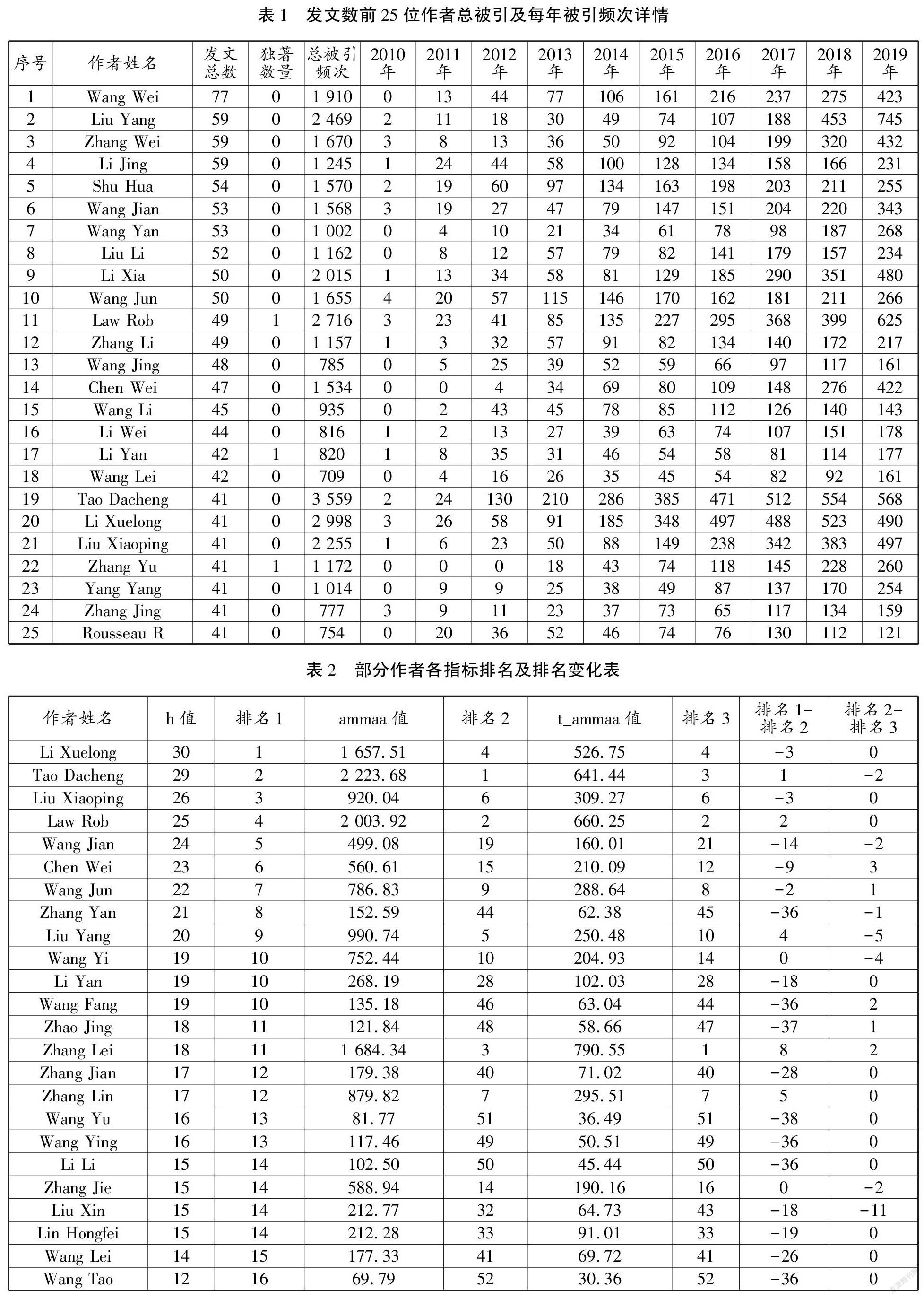
ammaa算法引入一种阈值变量T,也就是合著者数量的乘数。对任一论文而言,从以下公式(1)(2)(3)不难看出,若论文为单作者独著成果,则该文ammaa值就是其被引频次;当作者人数大于1时,其ammaa值是总引文量的平方除以阈值T和作者数量,再加上按著者数平分总引文量的值,使得每篇论文的影响力都随着引文数的增加而增加,直至该值达到由合著者数量和阈值设定的引文限制(即aT-T),其ammaa值才等于文章的总引文量,如以下公式(2)所示,这时,每个著者才可以算是获得了该文章所有的引文影响力。这种所有作者平均共享被引次数,每增加1次引用,其影响力的值就会同等份额逐渐增加的度量方法,原理类似于为工人生产率的每一次增长都提供同等的绩效激励,直至达到目标要求,团队的所有成员都可以得到全额奖励。这样既不会由所有作者平分引文总数那样弱化实际作者贡献值,降低合著者的积极性,也不会夸大没有实际贡献合著者的影响力。
一篇论文的ammaa值计算公式如下:
对于单作者的文章,ammaa值等于总被引次数,即:
当a=1时,AMMAA=c(1)
对于其他任何形式多作者合著文章,即:
当a>1,且c<aT-T时,AMMAA=(c+c2/T)/a(2)
当a>1,且c≥aT-T时,AMMAA=c(3)
式中,c为被引次数,a为作者人数,T为阈值变量。
在衡量同一学科的多作者论文影响力时,T值是相同的,所有合著者都享有的全部引文量阈值(aT-T)就会随着合著者人数的增多而变大,如图1所示。在达到阈值前,引文量相同的情况下,ammaa值会随着合著者人数a的增多而变小,如图2所示。由此,ammaa算法同时考虑了作者人数及论文被引频次两个因素,实现了既可以对单作者论文评价,也可以对多作者论文进行评价的创新融合。
T的赋值可通过普遍共识或由特定国家、团体或组织来确定。传统上被引用次数较少的学科,如地质学、数学,其T值较低。被引用次数较多的学科,如生物医学、生物化学,其T值较高。T的其他任何值也可以在科学合理的基础上设置,通用情况下,作者建议将T值暂设为100,一旦设置了T,就可以为每篇合著文章计算其ammaa值,也就是衡量每篇论文为合著者中的每位学者带来的影响力。T值的设定是根据学科性质确定的,所以,当出现普遍低被引学科的作者与普遍高被引学科的作者跨学科合作时,T值的设定还可以平衡由学科差异带来的影响。
(二)ammaa算法的不足
在论文影响力评价过程中,统计评价指标时常常忽略时间轴不统一的问题[27],从而降低评价的有效性。ammaa算法综合考虑了论文被引次数、作者人数两方面因素,却忽视了时间因素对评价效果的影响。论文被引时间的异质性体现论文成果传播的时间差异性,被引时刻才是知识传播和交流、发挥效用的时间,发文与被引的时间差反映了论文的知识流动性和影响力的大小[28]。两篇不同论文的发表时间不同,总被引频次相同时,发表时间更短的论文有更大的影响力;发表时间相同,总被引频次相同,引文量逐年上升和引文量逐年下降的论文学术价值也是不同的[29]。因此,笔者在分析ammaa算法忽略时间维度的情况下,力求基于发文时间和被引时间的异质性对ammaa算法进行优化。
三、t_ammaa算法的提出
加权是为平衡某一要素在整个要素体系中,因重要程度不同而分别赋予该要素不同权值的过程[30]。本优化方法对论文发表后每年的ammaa值赋予不同的权重,计算论文的加权ammaa。这样,一篇论文的t_ammaa值就是对它每年的ammaa值赋予不同权重后之和,作者的t_ammaa值就等于其所有论文t_ammaa值之和。
对于每篇论文而言:
t_ammaa=(1*ammaa1+2*ammaa2+3*ammaa3……+n*ammaan)/n(4)
式中,n=(数据采集时间-论文发表时间)/年;ammaa1、ammaa2……ammaan表示论文发表后第一年、第二年……第n年的ammaa值,每年的ammaa值利用作者所发文章在这一年的被引频次c计算。
对于每个作者而言:
t_ammaa=t_ammaa1+t_ammaa2+t_ammaa3……+t_ammaan(5)
式中n为某作者的第n篇论文;t_ammaa1、t_ammaa2、t_ammaa3……t_ammaan为该作者的第一篇、第二篇……第n篇论文的t_ammaa值。
四、t_ammaa算法实证研究
(一)数据来源及处理
本文以国内图情领域学者为研究对象,选取Web of Science核心合集(以下简称为WOS)作为实验数据来源,检索策略为:SU=(Information science and library science);检索时间跨度为2010年至2019年,限定语言类型为英文;精炼限定:国家/地区为(“PEOPLES R China”) OR (“China”),文献类型为ARTICLE,结果显示共有21 279条文献记录。
为保证所得数据的可靠性,剔除标注为“被撤回的出版物”以及无作者记录12条,考虑数据的可操作性,删除年均被引频次小于1的论文记录6 528条,剩余14 739条可用记录。通过Python程序分词统计得到60 342位作者,及每位作者的全部发文和被引详情。并采取前文所述中的作者建议,暂把T值设为100。根据公式(1)(2)(3)和公式(4)(5),分别计算每位作者的ammaa值和t_ammaa值,并排序。
(二)实验过程
本文尝试从两个角度进行数据梳理,然后再综合进行分析讨论。
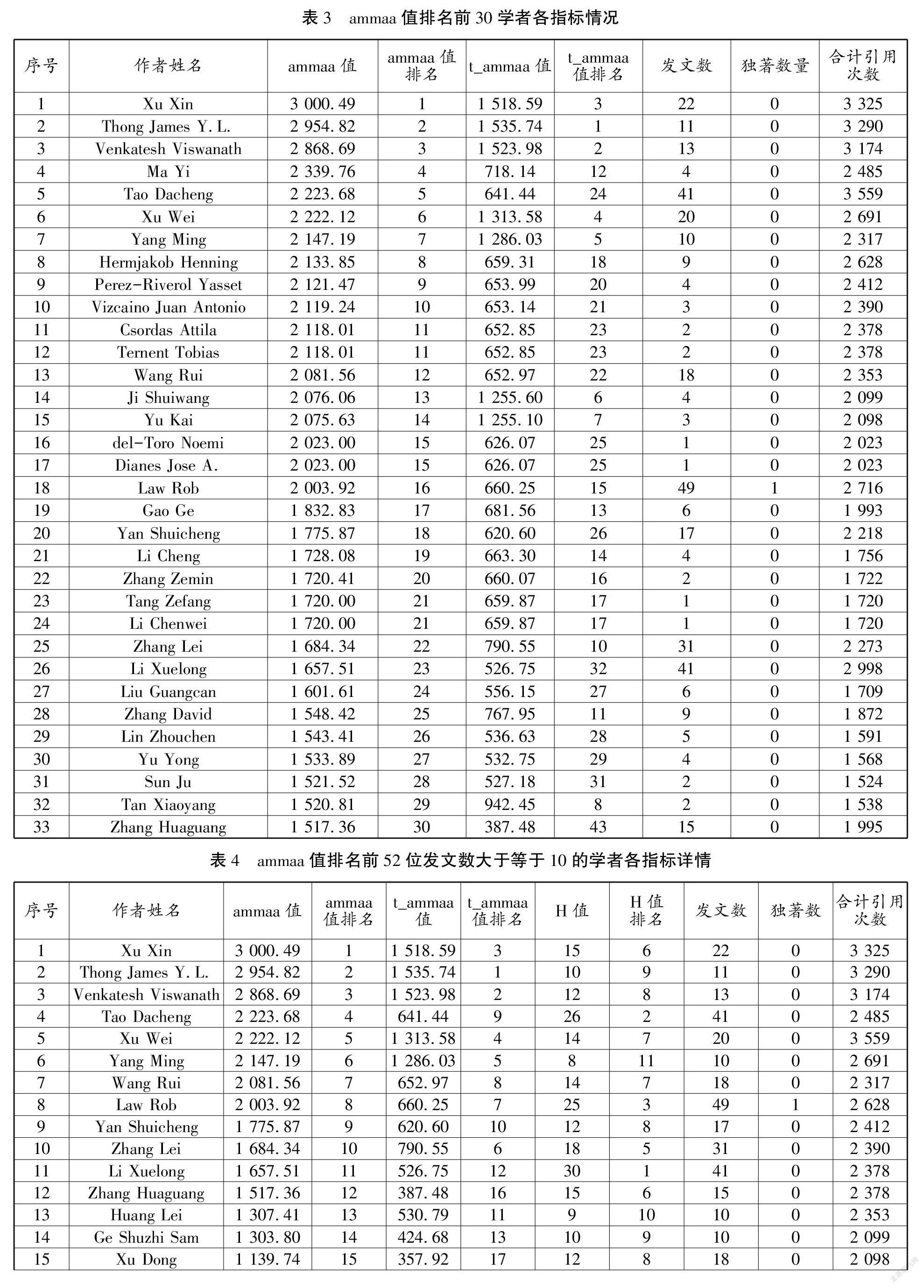
第一个角度,从发文量和引用量出发,比较分析ammaa算法及t_ammaa算法和h指数的区别和相关性。为保证实验可操作性,设定(1)年均被引频次40次以上,在2010—2019年所发论文总被引频次不少于400次,和(2)在(1)的基础上,年均发文3篇以上,在2010—2019年期间总发文量不少于30篇的作者两个筛选条件,最终筛选出52位符合以上条件的作者,并对52名作者进行核查,排除同名同姓的情况。因篇幅有限,摘录发文总数前25位作者发文及引用情况记录(表1)。
h指数為现行国际上使用的评价指标,故本文先通过ammaa算法与作者h值排名比较(即排名1-排名2),证明ammaa算法的调节力和区分度,再通过作者ammaa值排名减去t_ammaa值排名比较(即排名2-排名3),对比分析ammaa算法和t_ammaa算法。各位学者的h值是在WOS核心库中通过设定与数据源同一限定条件加上作者姓名检索获得。两排名比较中均采用正数表示作者排名上升,负数相反,数值绝对值表示作者排名变化量。因篇幅有限,现摘录部分学者结果,如表2所示。
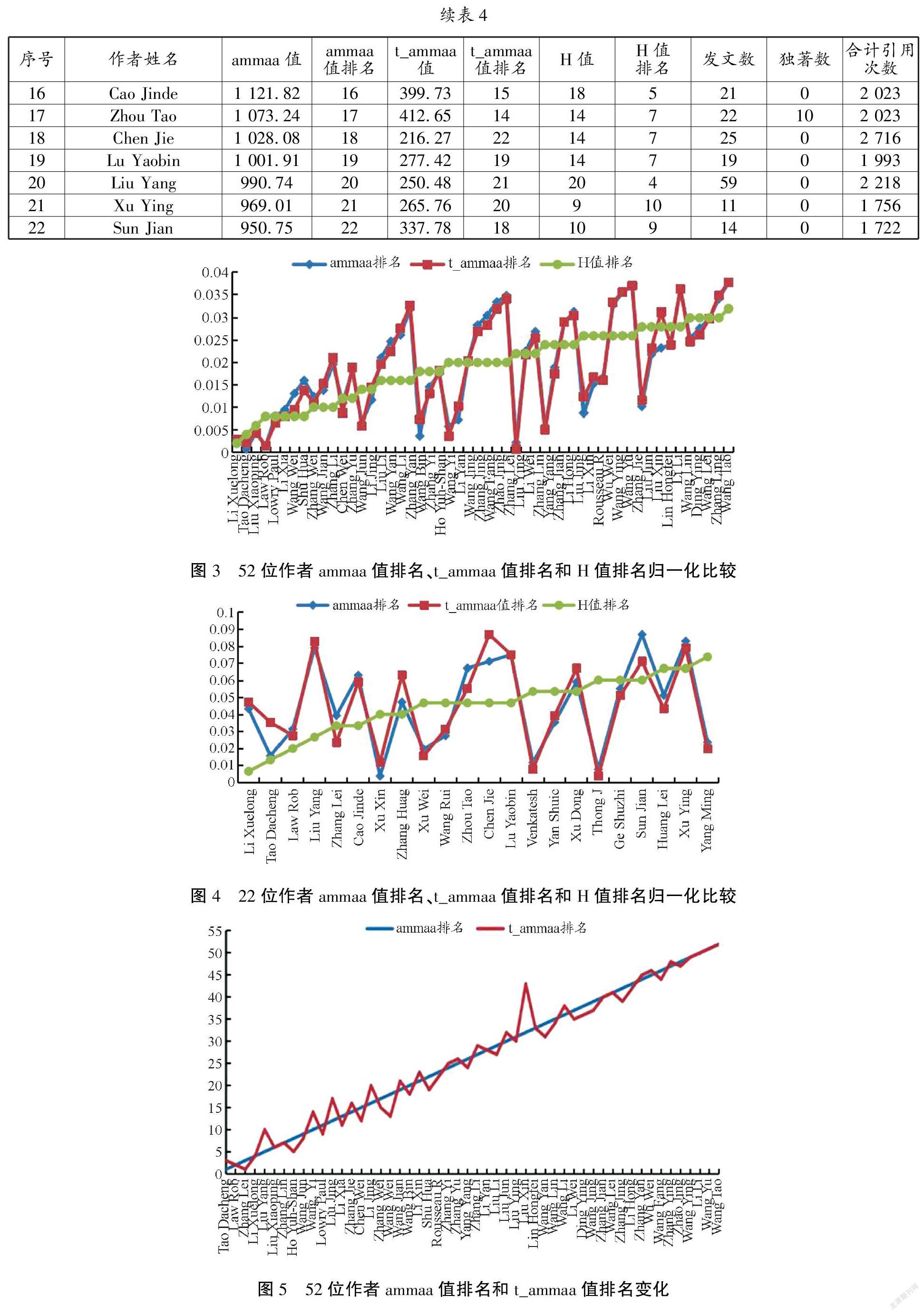
第二个角度,从ammaa值出发,分析讨论ammaa值排名靠前的学者发文及被引频次情况。参考前文数据,故保留前52位作者并进行核查,排除同名同姓情况。现摘录部分数据如表3所示。
(三)结果与分析
综合全部导出数据及表1可见,被调查的14 739篇论文中独著论文157篇,仅占1.07%。其中,发文数大于30篇,总被引频次大于400次的52位学者中,仅有7位学者在2010—2019年各发表了1篇独著论文,表明论文合著的形式已被
普遍接受,并可通过科学合作以提高科研成果影响力[2]。该结果与国家科学技术评估中心-科睿唯安分析结果及国内外学者的研究结论吻合[31-33]。
如表3所示,经计算ammaa值排名前52的学者中,发文数小于10篇的有21位,发文数介于10到30篇之间的学者有26位,占比50%,大于30篇的有5位,占比不到10%。学者Law Rob独著数1篇,学者Zhou Tao独著数10篇。其中,发文数与总被引频次均相同的学者有三组,分别为Csordas Attila和Ternent Tobias;del-Toro Noemi和Dianes Jose A;Tang Zefang和Li Chenwei。经调查详细数据发现,Csordas Attila和Ternent Tobias、del-Toro Noemi和Dianes Jose A参与合著1篇论文被引频次高达2 023次,Tang Zefang和Li Chenwei参与合著1篇论文被引频次为1 720次,且三组学者第一组仅有2篇论文发表,后两组仅有1篇。假若综合考虑发文数,排除发文数少于10篇的学者记录,且以年均发文至少1篇为限制条件,则ammaa算法既可以突出发文能力较强如独著较多的学者,也能筛选出文章质量较高的学者。
本研究中,我们保留ammaa值排名前52且发文至少10篇的学者各指标值,用与前文相同的条件查询各位学者的H值并排名(表4),综合第一角度一并做以下分析与讨论。
1.ammaa算法与t_ammaa算法调节能力结果与讨论
由表2和表4可知,两种算法的计算结果中,均未出现ammaa值、t_ammaa值相同的情况,而表2中H值查询结果中相同的学者有Law,Rob 等12组,共48位学者,占比92.3%;表4中H值相同的有Zhang,Lei等6组,共19位学者,占比86.4%。分别对H值、ammaa值和t_ammaa值三者排名进行归一化处理,并按照H值排序,如图3、图4所示,ammaa算法和t_ammaa算法排名较H指数排名总体趋势一致,二者均围绕H值排名上下浮动,且幅度较大;加入时间权重因素后,与ammaa值相比,表2中52位作者有40位学者的t_ammaa值名次发生变化,名次变化学者
占比76.9%,表4中22位学者有21位学者名次发生变化,名次变化学者
占比95.5%。说明ammaa算法和t_ammaa算法识别效果都较H指数好,且t_ammaa算法较ammaa对学者影响力评价更敏感,调节作用更明显。
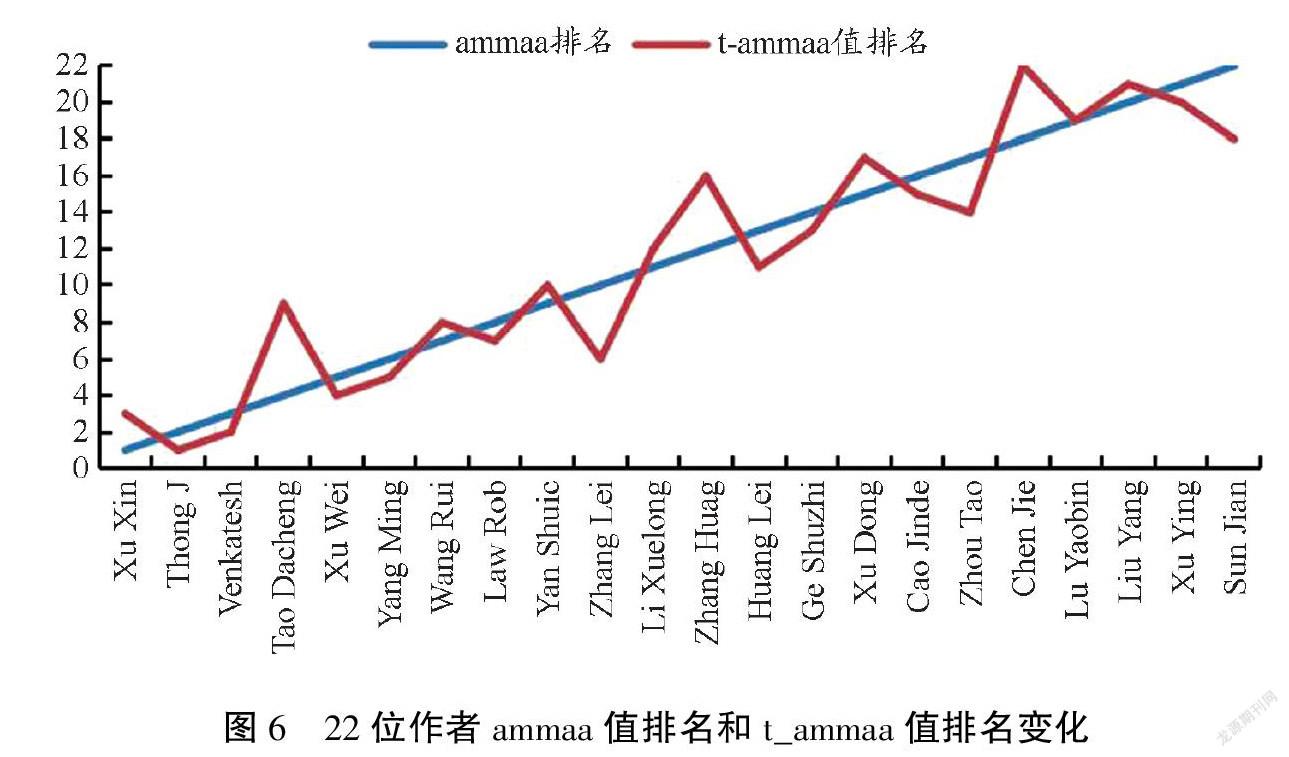
需要说明的是,图3、图4、图5、图6因版面所限,图面文字不够清晰,有兴趣者可与笔者线上交流。
首先分析比较ammaa算法与h指数。在表2中,两种评价方法下除Wang Yi和Zhang Jie两位学者名次未发生变化外,其余学者排名均产生变动,变化最多的是学者Wang Yu和Zhao Jing,变化值均为38。表4中,除学者Wang Rui名次未发生变化外,其余21位学者名次均发生变化,其中变化最大的是学者Liu Yang,变化值为16。
下面就表2中名次变化最大的学者Wang Yu分析原因,除各位学者原本h值排名并列的情况外,结合每位作者的所有发文和被引频次及合著者人数,对比分析下降名次最多的Wang Yu和与其h值相同排名却未发生变化的Zhang Lin,及排名上升最多的Zhang Lei(上升8个名次)三位作者,均取其被引频次大于10的论文,发现学者Wang Yu平均每篇论文的合著者人数为8.62,最高被引频次为41次,且该篇合著者人数为9人。而学者Zhang Lei和Zhang Lin,平均每篇论文的合著者人数分别为6.39和6.04,单篇最高被引频次分别为1 219次和389次,且两位学者该篇合著者人数均为3人,故学者Wang Yu的ammaa值排名明显下降。以上对比分析说明,考虑合著者人数的ammaa算法对合著论文的评价调节作用明显,且对高被引频次文章具有敏感的识别力。
2.t_ammaa算法与ammaa比较
观察表2的计算结果,有三组作者的ammaa值几乎相同,分别是Li Xia(588.96)和Zhang Jie(588.94),Liu Xin(212.77)和Lin Hongfei(212.28),Wang Jing(179.90)和Zhang Jian(179.38),进一步观察三组作者的t_ammaa值分别为236.17 和190.16,64.73 和91.01 ,78.38 和71.02 ,其差值分别为46.01,26.28和7.36。观察表4的计算结果,Tao Dacheng 和Xu Wei、Ge Shuzhi和Huang Lei两组学者的ammaa值分别为2 223.68和2 222.12、1 303.80和1 307.4,差值分别为1.56和3.6,进一步观察两组作者的t_ammaa值分别为641.44和1 313.58、424.68 和530.79,差值分别为672.13和106.11。可见,相比ammaa算法,t_ammaa算法的区分效果更加顯著。
由表2和图5可知,加入时间权重后,t_ammaa值名次下降最多的是作者Liu Xin,下降11个名次,居第43位;而总被引频次和ammaa值都比其小的学者Lin Hongfei却没有变化,仍居第33位。观察表4和图6可知,考虑时间因素后,t_ammaa值名次下降最多的是学者Tao Dacheng,下降5个名次,上升最多的是学者Zhang Lei和Sun Jian,均上升4个名次。这是在作者数量较少的情况下,如果作者数量较多,排名变化可能更大。
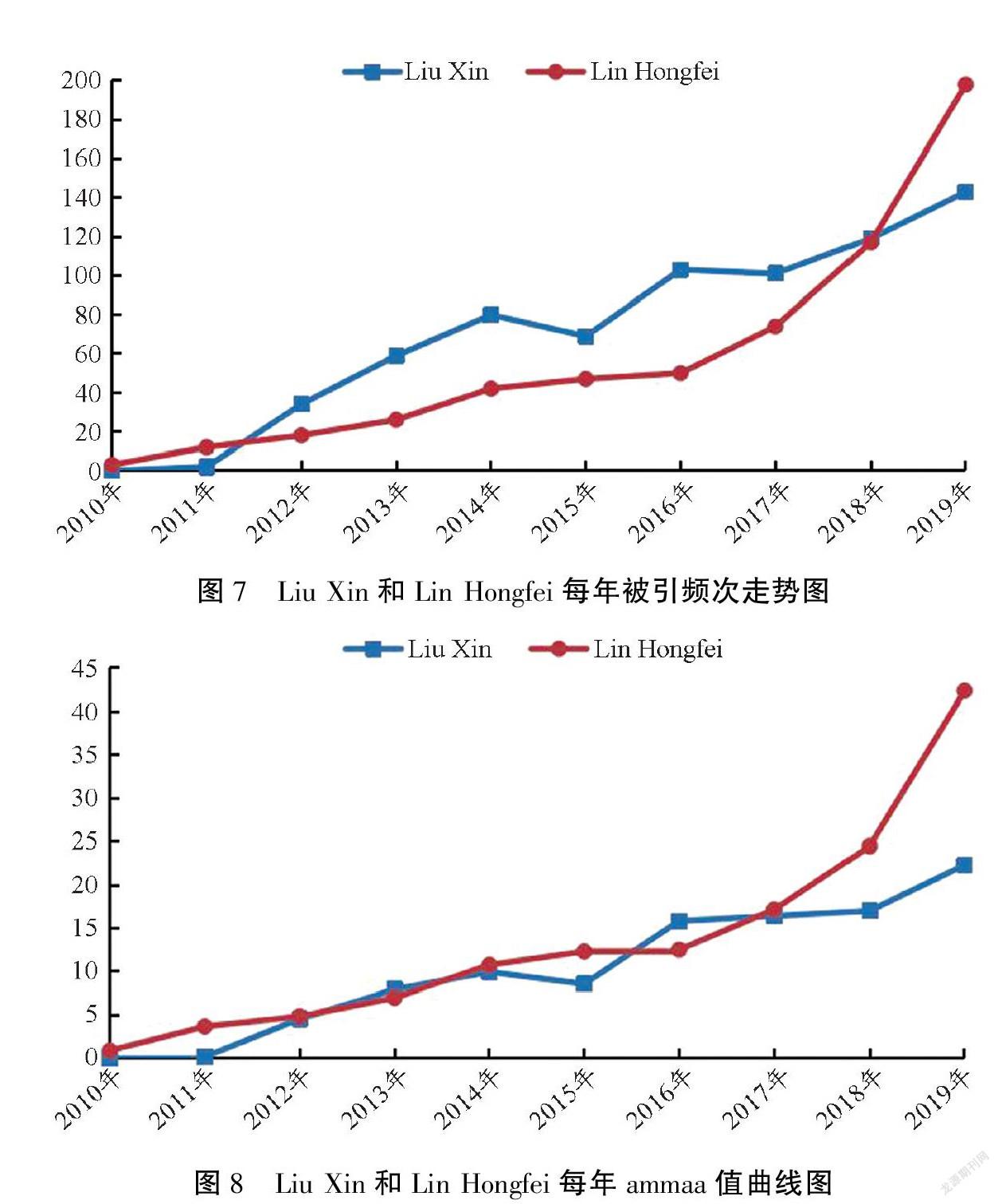
下面就学者Liu Xin和Lin Hongfei名次变化分析其原因。由表1及两位学者发文、每年被引次数可知:(1)在2010—2019年,两位学者均发文30篇,总被引次数分别为829和722次。(2)学者Liu Xin年被引频次在2015年较前一年下降,其余年份均较前一年有所增加,而学者Lin Hongfei年被引频次均保持逐年增加状态(图7)。(3)两位学者的ammaa值总体呈上升状态,学者Liu Xin仅在2013和2016年ammaa值略高于Lin Hongfei,其余年份与后者持平或远低于后者。以2015年为界,学者Liu Xin的ammaa值从2015年的8上升至2019年的22,而Lin Hongfei则从12上升到42,后者增幅较大(图8)。说明学者Lin Hongfei影响力在2015—2019年间已逐渐超过学者Liu Xin。故引入时间权值,越靠近统计时间的因素占比越重,学者Liu Xin的t_ammaa值排名较Lin Hongfei下降越明显。
另外,结合表2和图5可以看出,分别由ammaa算法和t_ammaa算法得出的排名中,前三名均是Tao Dacheng、Law Rob和Zhang Lei三位学者,后三名均是Li Li、Wang Yu和Wang Tao三位学者。结合表4和图6可以看出,ammaa算法和t_ammaa算法前三名均是Xu Xin 、Thong J和Venkatesh Viswanath,说明两种算法在描述作者学术影响力上的趋势是同步的,均能较准确识别高影响力学者。
3.各指标相关性分析
如果
某一算法改进后与原算法的计算结果相差太大,则认为对原算法的改进是不合理的[34]。引入时间因素的t_ammaa算法对学者影响力有一定的调节作用,但这种调节作用对ammaa算法的改善并不是颠覆性的。由此,我们将表2中52位作者的t_ammaa值、ammaa值、h值、总被引次数和年均被引次数,进行斯皮尔曼相关性分析,证明t_ammaa算法更具合理性(表5)。由分析数据可见,作者的t_ammaa值与其他指标均呈极显著相关关系,其中与ammaa值、h值、总被引次数和年均被引次数的相关系数分别为0.956、0.552、0.907及0.762。h值、总被引次数和年均被引频次均可用于对作者影响力进行评价[14,35-36],说明与h指数呈极显著正相关的ammaa算法和t_ammaa算法也适用于对作者影响力进行评价,且后者对前者的优化是合理的。
五、结论和建议
相对于h指数,笔者在ammaa算法的基础上,提出一种基于时间维度的ammaa优化方法——t_ammaa算法,通过对国内图情领域学者在WOS核心数据库中发文情况分析发现:(1)针对h指数无法识别高影响力论文,对合著论文评价不灵敏,以及无法涉及作者全部论文的缺陷,ammaa算法和t_ammaa算法对h值排名相同的情况有明显调节作用,通过设置阈值变量T和被引次数的平均共享,使合著论文的所有作者均等增加影响力的激励方法,不仅能更好地挖掘出高影响力和引用价值的科研文献,还能有效避免客座作者[5]、礼物作者[6]、非学术合作者[7]较多出现在论文署名中,从而影响评价结果的公平性,使得作者影响力评价方法更为合理和客观。(2)与ammaa算法相比,t_ammaa算法考虑时间因素,能有效识别领域内长时间保持高活跃度,影响力持续发挥或不断上升的学者。由此,t_ammaa算法综合考虑了作者发文数量、作者人数、被引频次、被引频次的阙值限制及被引时间异质性,解决了作者影响力评价方法中多作者署名问题,无法识别高影响力论文,被引次数受论文发表时间长短影响,以及跨领域合作学者影响力评价等需要解决的问题。(3)在图情人文社会科学领域中,合著已成为普遍现象,独著论文占比极少,且存在学者一篇论文被引频次极高、总发文數极少,但ammaa值和t_ammaa值排名居前的现象。建议在人文社科类评价过程中,可考虑设置学者必须在近些年,比如近3年或5年内必须有若干论文或独著成果产出,以削弱虚假合作者在评价中的影响力。
由以上研究结论可以看出,通过论文影响力来间接揭示作者学术影响力,并非简单通过影响因子来评价,论文引用数据等仅可作为评价参考,尤其在2021年人社部、教育部印发《关于深化高等学校教师职称制度改革的指导意见》中特别强调,不得以SCI或SSCI等论文相关指标作为前置条件和判断的直接依据,必须考虑学术论文的实际内容,特别是真正具有高影响力和引用价值的代表性论文,本研究通过时间要素的引入,可以有效解决仅凭论文“数量”和引用次数评价的局限,在对有持续学术贡献力学者的甄别中,可以设置近1年或3年内发表论文的数量作为学者持续影响力的重要评价手段,解决了部分学者突击或集中于某个阶段发文,或在获得一定职称或荣誉后长期处于“学术休眠”状态的问题;最后,对于多作者的署名问题,本文提出的被引次数平均共享和T值,可以有效解决挂名作者、客座作者或通讯作者等问题,通过优化算法,使得真正有持续贡献力的学者可以被有效识别出来,提高论文或学者贡献度评价的客观性。
本研究也存在一些不足之处,一方面,本文仅选择图书情报领域学者在WOS中的发文数据对t_ammaa算法进行实证分析,样本涉及领域单一;另一方面,本文阈值T的设置采取原作者对通用领域的取值建议,今后可进一步研究科学设置
T值的学科和条件。
参考文献:
[1]马瑞敏,张慧.加权引用视角下的作者学术影响评价研究[J].情报学报,2017(8):790-797.
[2]POLYAKOV M,POLYAKOV S,IFTEKHAR M S.Does academic collaboration equally benefit impact of research across topics? The case of agricultural, resource, environmental and ecological economics[J].Scientometrics,2017,113(3):1385-1405.
[3]GAZNI A, SUGIMOTO C R,DIDEGAH F.Mapping world scientific collaboration: Authors, institutions, and countries[J]. Journal of the American Society for Information Science and Technology,2012,63(2):323-335.
[4]SHABAN S.Multiple authorship trends in prestigious journals from 1950 to 2005[J].Saudi Medical Journal,2007,28(6):927-932.
[5]WAGER E,SINGHVI S, KLEINERT S.Too much of a good thing? An observational study of prolific authors[J].PeerJ,2015(3):e1154.doi.org/10.7717/peerj.1154.
[6]JACK G.Is mass authorship destroying the credibility of papers[ED/OL].[2020-11-09]. https://www.timeshighereducation.com/news/mass-authorship-destroying-credibilitypapers#node-comments.
[7]SARNA-WOJCICKI D,PERRET M,EITZEL M V,et al.Where are the missing coauthors? Authorship practices in participatory research[J].Rural Sociology, 2017,82(4):713-746.
[8]高晓培,潘云涛,马峥.科技期刊论文署名规范化探讨与实践研究[J].编辑学报,2012(1):30-33.
[9]IRIBARREN-MAESTRO I,LASCURAIN-SNCHEZ M L,SANZ-CASADO E.Are multi-authorship and visibility related? Study of ten research areas at Carlos III University of Madrid[J].Scientometrics,2009,79(1):191-200.
[10]TARNOW E.Coauthorship in physics[J].Science and Engineering Ethics,2002,8(1):175-190.
[11]ILAKOVAC V,FISTER K,MARUSIC M,et al.Reliability of disclosure forms of authors’ contributions[J].CMAJ,2007,176(1):41-46.
[12]YAGER K.Each co-author should sign to reduce risk of fraud[J].Nature,2007,450(7170): 610.
[13]BHARATHI D G.Measuring the impact of an author of multi-authored articles—Aggregating metrics for multiple authors’ analysis[J].ISSI,2019,2(5):448-458.
[14]HIRSCH J E.An index to quantify an individual’s scientific research output[J].Proceedings of the National Academy of Sciences of the United States of America,2005,102(46): 16569-16572.
[15]BALL P.Index aims for fair ranking of scientists[J].Nature,2005,436(7053):900.
[16]周春雷.h指數合作式注水缺陷与对策[J].图书情报知识,2009(3):109-112.
[17]BORNMANN L,DANIEL H D.Does the h-index for ranking of scientists really work?[J].Scientometrics, 2005,65(3):391-392.
[18]COSTAS R,BORDONS M.The h-index:Advantages,limitations and its relation with other bibliometric indicators at the micro level[J].Journal of Informetrics,2007,1(3):193-203.
[19]WILDGAARD L,SCHNEIDER J W,LARSEN B.A review of the characteristics of 108 author-level bibliometric indicators[J].Scientometrics,2014,101(1):125-158.
[20]金碧辉,Rousseau Ronald.R指数、AR指数: h指数功能扩展的补充指标[J].科学观察,2007(3): 1-8.
[21]PRATHAP G.The 100 most prolific economists using the p-index[J].Scientometrics, 2010,84(1):167-172.
[22]HU X J,ROUSSEAU R,CHEN J.In those fields where multiple authorship is the rule, the h-index should be supplemented by role-based h-indices[J].Journal of Information Science,2010,36(1):73-85.
[23]SHEN H W,BARABASI A L.Collective credit allocation in science[J].PNAS,2014,111(34):12325-12330.
[24]BATISTA P D,CAMPITELI M G,KINOUCHI O.Is it possible to compare researchers with different scientific interests?[J].Scientometrics,2006,68(1):179-189.
[25]SCHREIBER M.To share the fame in a fair way, hm modifies h for multi-authored manuscripts[J].New Journal of Physics, 2008,10(4).
[26]SAHOO S.Analyzing research performance: Proposition of a new complementary index[J].Scientometrics, 2016,108(2):489-504.
[27]俞立平.期刊影响力指标的时间异质性及其重构研究:基于多属性评价的视角[J].图书情报工作,2016(12):109-114.
[28]谢瑞霞.基于“时间异质性”和“合著网络”的作者影响力评价研究[D].曲阜:曲阜师范大学, 2019.
[29]舒予,张黎俐.时序动态视角下的学术影响力评价方法及实证研究[J].现代情报,2017(11):74-80,86.
[30]科普中国.加权[EB/PL].[2020-10-09].https://baike.baidu.com/item/加权/91816?fr=Aladdin.
[31]National Center for Science and Technology Evaluation,Clarivate Analytics.China’s international scientific research collaboration—A bibliometric analysis[R].2018:1-69.
[32]张雪,张志强,陈秀娟.基于期刊论文的作者合作特征及其对科研产出的影响:以国际医学信息学领域高产作者为例[J].情报学报,2019(1):29-37.
[33]THELWALL M,SUD P.National,disciplinary and temporal variations in the extent to which articles with more authors have more impact: Evidence from a geometric field normalised citation indicator[J].Journal of Informetrics, 2016,10(1): 48-61.
[34]張欣,马瑞敏.基于改进Page Rank算法的核心专利发现研究[J].图书情报工作,2018(10):106-115.
[35]方卿,王珏.开放存取期刊学术质量评价(一):基于总被引频次视角的分析[J].出版学,2011(6):67-70.
[36]PASTERKAMP G,ROTMANS J I,KLEIJN D V P,et al.Citation frequency:A biased measure of research impact significantly influenced by the geographical origin of research articles[J]. Scientometrics, 2007,70(1):153-165.
Abstract: Aiming at the deficiency of h index and the lack of a comprehensive and effective evaluation index, this paper introduces an ammaa algorithm for paper evaluation, and proposes an optimization algorithm integrating time dimension: t-ammaa algorithm, which reflects the influence evaluation of individual scholars through the evaluation of paper influence. Using Web of Science as the data source and focusing on the papers published by domestic authors in the field of library and information science, the ammaa value and t-ammaa value of these papers are calculated, and then the ammaa value and t-ammaa value of the scholars are obtained. The result ranking of the two algorithms and the scholars’ H-value ranking are normalized for empirical comparison and analysis. The results show that t-ammaa algorithm considers the cited times, the cited threshold limit, co-author number and the temporal heterogeneity of the cited papers. It can not only comprehensively evaluate the influence of single-author and co-authored paper, but also eliminate the influence brought by time factor. It is a more reasonable measurement method for evaluating the influence of scholars and papers.
Key words: ammaa algorithm; temporal heterogeneity; multi-author paper influence; author influence; evaluation index; break the “five-only”
(责任编辑 彭建国)
3118500589214
猜你喜欢
中国科技纵横(2016年20期)2016-12-28
经济研究导刊(2016年30期)2016-12-24
电脑知识与技术(2016年27期)2016-12-15
时代金融(2016年29期)2016-12-05
科学与管理(2016年5期)2016-12-01
中国市场(2016年40期)2016-11-28
商(2016年33期)2016-11-24
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
中国市场(2016年38期)2016-11-15
中国市场(2016年33期)2016-10-18
