
联合多种空间信息的高光谱半监督分类方法
2021-03-16 09:28王立国马骏宇李阳
哈尔滨工程大学学报 2021年2期
王立国, 马骏宇, 李阳
(哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001)
由于遥感学科[1]的进步以及高光谱数据的独特性质,高光谱技术已然成为了遥感领域的一个重要组成部分[2],而分类问题是高光谱图像研究中一个重要的方向[3]。在图像中,地物分布往往具有空间平滑特性[4],因此相距较近的像素属于同种类别的概率更高。传统的分类算法如标准SVM[5-6],三重训练[7]等通常只从光谱信息的角度出发对地物类别进行分类,而对图像中的空间特征进行了忽视。在分类过程中应用空间信息辅助分类,可以降低噪声并且能保证分类结果空间上的连续性。高光谱图像分类利用的空间信息主要包括3种:空间的纹理信息[8]、数学形态学信息以及邻域信息。文献[9]提出了一种基于数学形态学的高光谱数据预处理方法,在高光谱的城市数据集中取得了不错的效果。文献[10]在进行高光谱图像分类之后,使用了基于邻域多数投票策略的分类方法,以进一步改善分类结果。文献[11]将Gabor滤波器提取的空间纹理特征用于高光谱图像分类并实验验证了方法有效地提升了分类精度。因此,挖掘高光谱图像的空间信息对于提升图像分类精度具有十分重要的意义,如何有效运用高光谱图像的空间信息也是一个研究的热点话题。
基于以上内容,关注高光谱图像分类中利用空间信息的问题,本文提出了一种联合多种空间信息的高光谱图像半监督分类方法,在图像处理的预处理阶段、扩充样本集阶段、分类阶段和后处理阶段均引入了图像的空间信息进行辅助分类。并且在有标签样本少的情况下,利用空间邻域信息和改进的教与学算法2次扩充训练样本集,旨在有效利用高光谱图像的空间信息,进一步提升高光谱图像分类效果。
1 多阶段联合空间信息的分类方法
1.1 提取图像空间纹理特征
本文方法首先对高光谱图像进行降维操作。降维操作可以减少数据量,增大样本采样密度[12]。高光谱图像的空间特征差异较大,Gabor滤波器[13]可以从不同的频率及方向对图像的纹理信息进行提取,因此本文方法选用二维Gabor滤波器对高光谱图像提取特征,并选用文献[14]中的特征提取方式。设空间信息与光谱信息融合后的特征矢量为:
(1)
空谱核表达式为:
(2)
1.2 利用空间4-邻域信息辅助分类
半监督分类中一个十分重要的研究方向是采用一定的策略从无标签样本中选取置信水平高的样本变成“伪标记样本”,将其加入到训练样本集,本文方法在此理论基础上进行训练样本集的扩充,从有标签样本的邻域信息为出发点,选择置信水平高的有标签样本的4-邻域样本添加至训练样本集中。设样本为x(i,j),样本的分类类别为Li,j,其4-邻域样本集为:
D4={x(i,j),x(i-1,j),x(i,j-1),
x(i+1,j),x(i,j+1)}
(3)
第1次扩充训练样本集的过程如下:
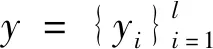

高光谱图像已标记标签样本数目少,SVM经过训练后得到的超分界面会产生一定偏差,这种问题不利于对各个情况的地物信息在高维空间的分布进行表达。针对此问题,本文将邻域样本信息和中心样本本身的信息加以结合后再进行SVM分类,这种方法可以降低样本的错分几率。此方法叫做基于空间信息的SVM。设目标像元为x0,其邻域像元集合为:
Ω(x0)=(x0,x1,x2,x3,x4)
(4)
SVM的判别函数为:
(5)
将判别函数代入SVM的输出公式:
(6)
其中K′(xi,Ω(x))为核函数,表达式为:
(7)
式中ωj、f(xj)分别为像元xj对应的权重值和输出值。
1.3 寻优扩充训练样本集
教与学算法收敛速度快且收敛能力优异,在本文方法中使用教与学(TLBO)[15]算法迭代筛选出信息量丰富的无标记样本,第2次扩充训练样本集。具体过程如下:
1)在无标签样本集中选择m个符合以下公式的样本,记为集合S:
(8)
式中|f(xi)|表示无标签样本xi到分类超平面的距离,|f(xi)|越小代表样本xi与分类超平面越接近;
2)对集合S的高光谱数据空间进行初始化种群操作,初始化方法为随机生成;
3)“教”阶段。在第n次迭代的教学阶段,学生根据和学生平均值Xmean之间的不同进行学习;
4)“学”阶段。学生在班级中随机挑选得到自己需要学习的对象,然后双方比较彼此的适应函数值。
为了丰富训练样本集合,在“学”阶段参考差分进化(DE)算法的交叉环节,对TLBO算法的进一步优化。TLBO算法随着收敛速度的加快容易产生局部最优的问题。而DE算法能够丰富训练样本集,本文中采用改进的TLBO算法,在保证搜索能力的情况下避免陷入局部最优的情况。
1.4 利用8-邻域信息进行后处理
根据高光谱图像像元处于同一相邻区域内的地物类别相同的概率高的特性,本步骤对分类结果进行后处理,平滑噪声,降低错分概率。具体过程为:首先选择出需要进一步确定标签的目标像元,针对目标像元周围的8个邻域像元的类别进行统计,其中相同数目像元的类别记录为D,数目记录为N。然后设定一个小于邻域样本数目的阈值T,当8-邻域样本中样本数目最多的样本D数目大于T时,如果选定的像元的类别不是D,将类别更改为D,否则类别不变。
1.5 本文高光谱图像分类方法流程
本文提出了一种联合多种空间信息的高光谱图像半监督分类方法。本文方法在多个环节应用了高光谱图像的空间信息,主要表现在预处理阶段,扩充训练样本集阶段和后处理阶段,在扩充训练样本集时采取了两次扩充方式,第1次应用邻域信息,第2次应用改进的TLBO算法。方法的具体流程如下:
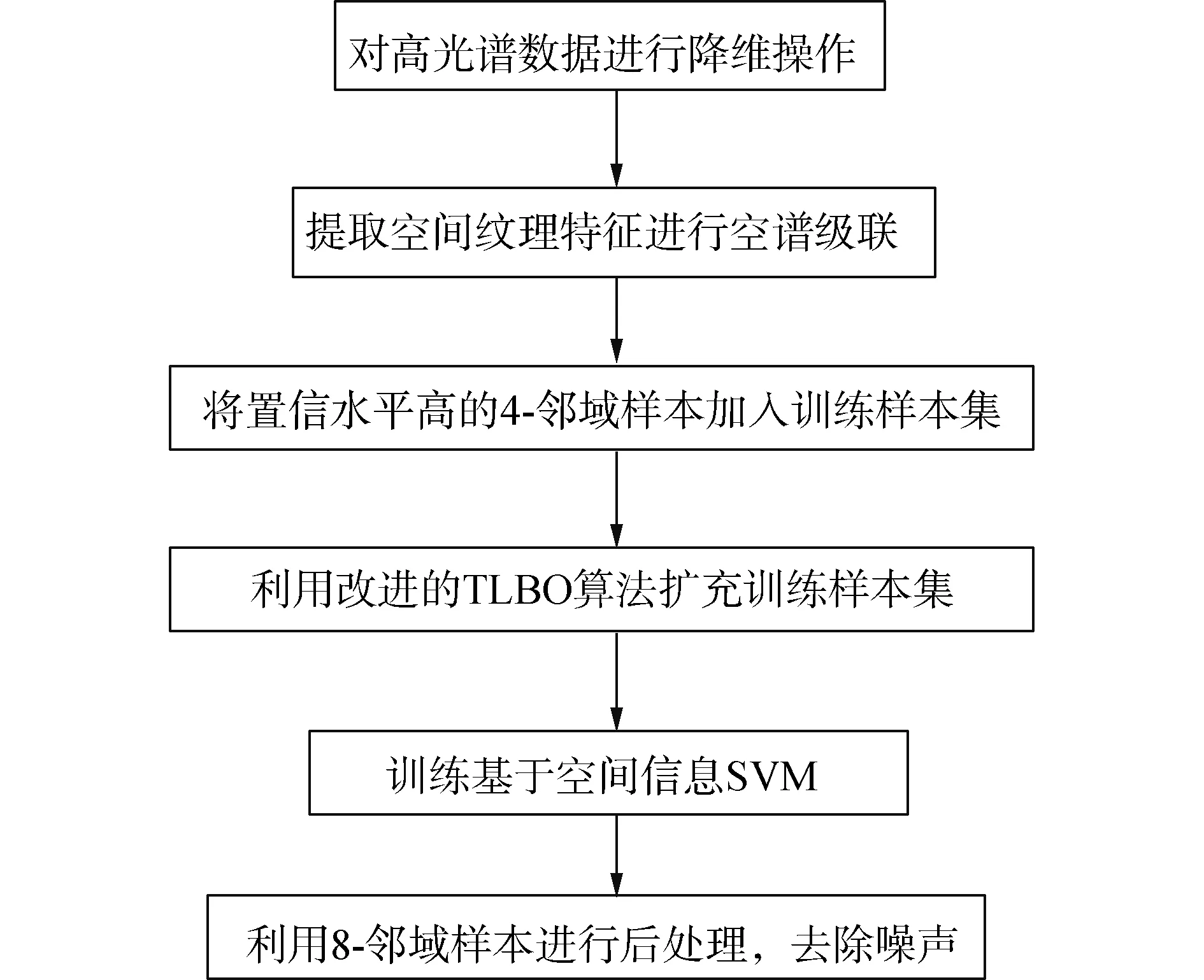
图1 本文方法流程Fig.1 Method flow chart
2 实验数据及对比实验
2.1 实验数据集
为验证方法的有效性,本文选用了Indian Pines和Pavia工程学院2组经典数据集进行实验。实验中,2个数据集的像素均选择145×145,Indian Pines数据集去掉噪声之后的波段数目为200个,Pavia工程学院数据集去掉噪声后的波段为103个。为使分类结果更清晰,2个数据集均选取8个主要地物类别进行分类,原始高光谱灰度图如图2(a)和图2(b)所示。

图2 原始图像Fig.2 Original image
2.2 实验条件及评价指标
本文实验应用Matlab2015b进行仿真实验。本文方法中Gabor滤波器相关参数设置情况:λmin=2.796 1,P=6,Q=10,σ=1,γ=1,φ=0。选择径向基核函数形式,惩罚系数根据网格搜索法从[10 103]中挑选,核函数从[10 2102]中挑选。采用“一对多”的分类器结构形式。本文参数均为多次实验验证后选择的最佳参数。本文实验的评价指标为:每个地物类别的分类精度、总体分类精度(overall accuracy, OA)、平均分类精度(average accuracy, AA)以及Kappa系数。最终记录数据为实验10次数据的平均值。
2.3 实验结果及分析
本文方法从4个阶段运用高光谱图像的空间信息:1)提取图像的空间纹理信息,进行空谱级联,简称为空谱级联;2)选取置信水平高样本的4-邻域样本,更新标记样本集,简称为邻域标记;3)利用基于4-邻域空间信息的SVM进行分类,简称为空间信息SVM;4)根据8-邻域样本对分类结果进行后处理,简称为邻域去噪。
2.3.1 实验1:单独使用空间信息对比实验
实验1主要将使用空间信息的5种方式进行比较,5种方式为:仅使用图像的光谱信息、空谱级联、邻域标记、空间信息SVM和邻域去噪。表1和表2分别为在Indian Pines数据集和Pavia工程学院数据集上使用5种空间信息辅助图像分类的结果。表中记录了OA、AA、Kappa系数、程序运行时间以及每项地物的具体分类精度情况。从2个数据集可以得出相同的结论:本文使用的4种利用空间信息方式均对于提高图像分类性能有效。

表1 Indian Pines数据集使用空间信息分类结果Table 1 Classification results of Indian Pines using spatial information

表2 Pavia工程学院数据集使用空间信息分类结果Table 2 Classification results of Pavia University using spatial information
在分类精度上,利用邻域标记方法对于分类精度的提高最为有效。在Indian Pines数据集中,仅使用邻域标记的情况下,OA、AA和Kappa系数分别比仅使用光谱信息提升了16.44%、14.79%和0.190 7。在Pavia数据集中,OA、AA和Kappa系数分别比仅使用光谱信息提升6.32%、4.29%和0.838。因此,将带标记样本的4-邻域样本中置信水平高的邻域样本加入到已标记训练样本中,对于SVM分类超平面参数的计算十分重要。空间信息SVM在提升分类精度上也有着不错的效果。其他两种方法在精度提升方面起到的效果类似。
从时间角度来看,利用空谱级联方式耗时最少。这是因为空谱级联的方式进行了数据降维,在保留有效信息的情况下,去除了大量的冗余信息。使用空间信息SVM的方法进行类别判别的时候需要计算核函数,计算量较大,因此所需要的时间最长。
2.3.2 实验2:使用空间融合信息对比实验
实验2主要将本文方法中使用的空谱级联、邻域标记加邻域去噪和空间信息SVM几种空间融合方式与本文方法进行对比。
表3和表4分别展现了本文方法在Indian Pines和Pavia数据集中对高光谱图像数据空间信息融合的分类结果。通过2个表格可以看出,本文方法相对于对比实验的3种情况,OA、AA以及Kappa系数均有提高。数据有力的证明了本文方法对高光谱数据的空间信息利用的有效性,本文方法在提升高光谱图像的分类精度上起到了十分优异的效果。但是从运行时间来看,本文方法运行时间较长。
2.3.3 实验3:与其他算法对比实验
本节实验将本文方法与经典算法和几种利用空间信息且分类精度优异的算法进行对比。对比算法选择了标准SVM、三重训练算法(Tri-training)、基于谱聚类的半监督分类算法(SC-SC)、Laplace支持向量机(LapSVM)以及基于空间-光谱聚类的半监督分类方法(SC-S2C)。在LapSVM算法中,参数γA、γI的值在[10-3,103]区域内交叉验证获得最优解,光谱近邻数为4。在SC-SC算法中,光谱近邻值设为4。在Tri-training算法中,使用标准SVM作为基分类器。在SC-S2C算法中,光谱维数RNw设为5,空间信息维数RNs设为62,权重系数μ为0.4。Gabor滤波器参数为λmin=2.796 1,P=6,Q=10,σ=1,γ=1,φ=0。以上参数均选取多次实验后验证效果最好的参数。

表3 Indian Pines数据集高光谱图像融合空间信息分类结果Table 3 Classification results of hyperspectral image fusion spatial information in Indian Pines dataset
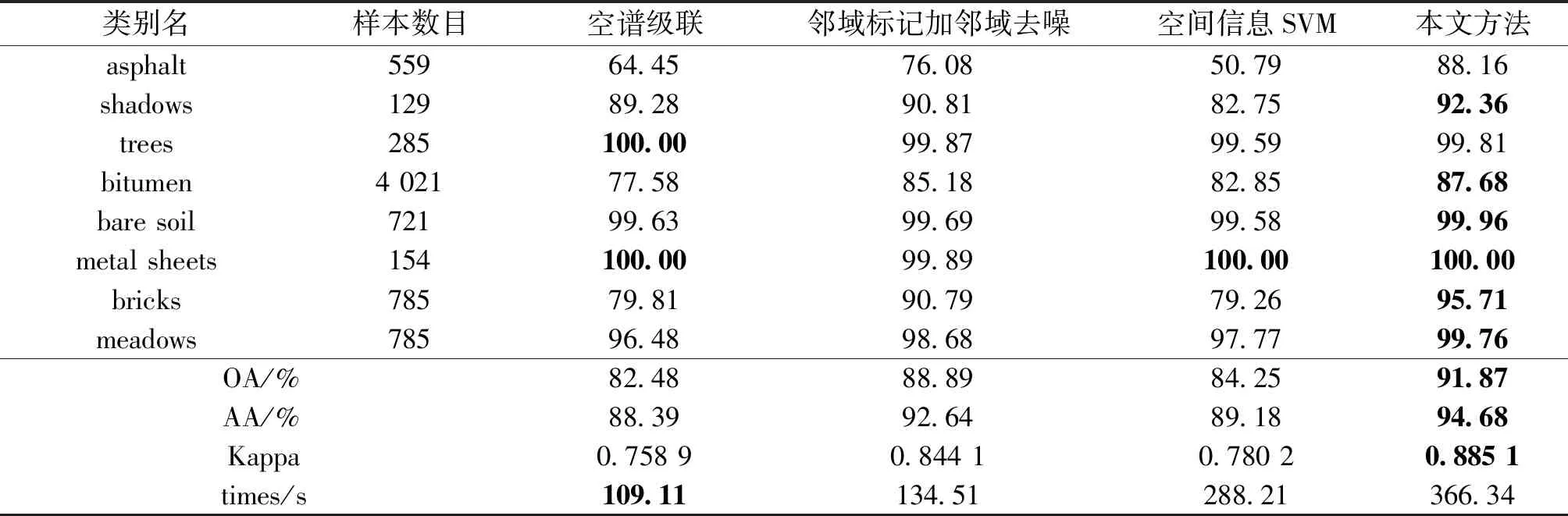
表4 Pavia工程学院数据集高光谱图像融合空间信息分类结果Table 4 Classification results of hyperspectral image fusion spatial information in Pavia University dataset
图3和图4分别为本节实验选取的6种方法的在Indian Pines数据集和Pavia工程学院数据集中的分类效果灰度图。根据图3和图4可以看出本文方法的分类图中噪点明显少于其他对比实验分类图。

图3 印第安农林数据集6种算法的分类效果Fig.3 Classification effect diagram of six algorithms of Indian agriculture and forestry dataset

图4 针对Pavia工程学院数据集6种算法的分类效果Fig.4 Classification effect diagram for six algorithms of dataset of Pavia College of Engineering

表5 6种分类算法OA对比(Indian Pines数据集)

表6 6种分类算法OA对比(Pavia数据集)
3 结论
1)不同于传统高光谱分类方法,本文方法在预处理阶段、扩充训练样本集阶段、分类阶段和后处理阶段均结合了高光谱图像的空间信息辅助分类。实验表明方法中每一阶段的结合空间信息均有利于提高分类精度,证明了将空间信息引入高光谱图像分类的有效性。
2)在2个经典数据集上进行对比实验,证明本文方法在分类性能上优于其他对比算法。特别在初始有标记样本少的情况下,本文提出的方法可以有效地利用空间信息,选择富含信息量的无标签样本扩充训练样本集,提升分类性能。
本文方法虽然有效利用了空间信息,提升了高光谱图像的分类精度,但是在提升精度的同时,也引入了大量计算。如何在减少计算量的情况下更好地应用空间信息需要进行下一步的探究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年7期)2022-07-09
逻辑学研究(2021年3期)2021-09-29
科技创新与应用(2020年6期)2020-02-29
计算机应用与软件(2018年12期)2018-12-13
指挥控制与仿真(2017年3期)2017-06-22
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
军事运筹与系统工程(2016年4期)2016-07-10
现代电子技术(2009年14期)2009-09-05
