
一种改进的基于在线解耦的轻量级动态污点分析方法
2021-03-13 06:00潘家晔
小型微型计算机系统 2021年2期
潘家晔,庄 毅
(南京航空航天大学 计算机科学与技术学院,南京 211106)
1 引 言
当前,恶意代码仍然不断以新的形式来感染和攻陷各类终端系统,如:勒索软件,挖矿代码以及隐私窃取等[1,2].由于缺少源代码,改进和提高二进制程序的逆向调试和自动化分析方法仍然是一项重要研究内容[3,4].在过去十年内,动态污点分析方法作为一种有效的细粒度分析方法,尽管面临性能及可应用性等问题,但仍有许多研究工作对其进行改进[5-7],例如:在更广阔的系统范围内对目标程序进行分析[8,9];引入静态分析并对动态分析过程进行优化[10];将程序执行和分析过程进行解耦分离[11,12];采用在线与离线方式结合完成分析[13].一些代表性的研究工作如:A.Davanian等人提出改进的全系统动态污点分析系统DECAF++[14].Banerjee等人提出新的动态分析优化方法Iodine[15],避免在乐观分析下引起的频繁回滚.Kemerlis等人提出并实现更加通用的分析方法libdft[16],基于此方法可快速的构建分析工具对商业软件进行分析.Jee等人将静态与动态进行结合,通过静态分析提取数据流跟踪逻辑并消除冗余部分,减小动态分析时对目标程序的影响[10],而后又提出了加速数据流分析的方法ShadowReplica[11],将程序执行和分析过程进行解耦,利用多核CPU并行化完成分析.Ming等人提出了并行化的符号污点分析方法TaintPipe[17],同样分离程序执行过程与数据流分析,能够降低目标程序负载,提高分析速度.尽管存在针对动态污点分析的各类研究,但是在实际应用时仍然存在很多因素,使得动态污点分析难以在真实场景中得到更快捷及广泛的应用,例如:依赖一定程度的静态分析,限制于特定的分析场景,分析过程的构建比较复杂,对处理器资源消耗较大,或者难以面向现代大型应用程序,缺乏通用性.
因此,在已有研究基础上,本文提出一种改进的轻量级在线解耦的动态污点方法,称之为DOTA,其以解耦分析为主要思想,并具有较好的可应用性,能够支持对各类复杂应用程序进行分析.该方法首先对目标程序进行拦截,记录动态污点分析所需的运行时信息,与此同时构建用于分析的代码和执行环境.与其它方法相比,本文所提的方法灵活高效,分析的构建过程更加快捷和简单;不依赖于静态分析而进行优化,能构建相对独立、能进行迁移的分析环境,降低对目标程序的影响,并且支持对各类多线程程序进行分析.
2 方法概述
动态污点分析属于指令级别的细粒度分析方法,传统方法在分析时需要对目标程序进行大范围的插桩,同时消耗大量的内存空间,因此本文所提方法的重要目标是尽量降低对目标程序执行环境的影响.方法的总体架构示意图如图1所示,当前主要针对用户模式下的程序进行分析,我们在独立的进程空间或内核空间中构建分析环境.针对目标程序涉及的进程环境中的每个线程,创建一个相对应的分析线程,并且处理两者之间的数据读写与分析同步问题.分析环境由一系列分析线程和辅助缓冲区构成,可构建于一个最基本的进程执行环境中,该进程可由拦截模块创建,其生存周期基本与目标程序相同,也可直接构建于内核空间中.当目标程序执行完成时,其对应的分析过程也将同步完成.对于污点分析时所需的额外辅助内存,如构建指令分析代码,存储分析状态等,则直接在分析进程空间中分配和创建.根据拦截方式的不同,拦截模块可位于目标进程空间内或者内核中,当其获取到线程创建、内存分配以及新程序块执行等事件时,同时在分析环境中创建分析线程和所需的辅助空间.图中拦截模块出现在目标进程内,可采用动态插桩方法来实现[18],实际上也可以采用其它方法.
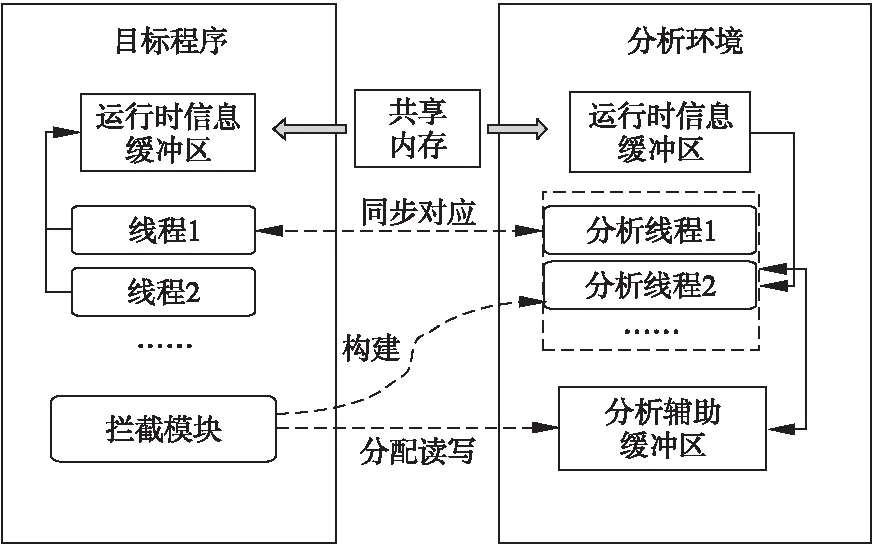
图1 总体架构示意图Fig.1 Overall architecture of the proposed method
在进行具体分析时,事实上主要需对两大类指令进行处理,一是对于涉及内存访问的指令,在执行过程中,指令访问的内存地址会发生变化,另外可能会受到多个线程以及系统内核的影响.因此,在分析过程中,较好的方法是实时获取这些信息以保证准确性.二是对于仅涉及寄存器运算的指令,在多数情况下,只会受到当前线程的上下文影响,因此可以直接对其进行分析,而无需获知其它信息.因此,与传统分析类似,首先需对目标程序进行拦截并记录一些运行时信息,并通过共享内存方式来进行进程,传输记录的运行时信息到分析环境,而后在构建分析环境时,需要对这两种情况进行不同的处理.需要注意的是,如果分析环境构建于内核中,则可直接映射并读取目标进程空间的相关内存数据.
3 分析代码构建
3.1 分析状态
线程上下文信息主要涉及寄存器状态,我们采用相同大小的内存空间来存储其分析状态.即32位平台下共有8个寄存器,对此采用32个字节存储状态,这里针对的是字节级别的污染状态传递情形.对于进程内存空间对应的分析状态,基于虚拟地址采用相应大小的映射空间来存储,即当目标程序分配可访问的内存页面时,同时在分析进程中分配相应的内存页面用于存储其分析状态,并且构建映射表项,在32位平台中整个映射表占用2MB空间.因此,在分析过程中内存分析状态的更新过程将得到简化,而存储分析状态所需的内存空间跟目标程序在运行时分配的内存大小相关,更具体地是跟提交分配的物理页面数量相关,这在实际应用中是相对有限的.另外需要注意的是,如果分析线程执行时,读取的分析状态存储页面还未分配时将会产生访问异常,此时在异常处理程序中重新分配和构建状态存储页面即可.当在分析过程中实际物理页面还未分配时,会导致上述情形出现.
3.2 分析代码块
当拦截模块捕捉到新的程序基本块出现时,同时在分析进程中为其构建相应的分析代码块,同时构建描述分析代码信息的结构体来记录分析代码的相关信息并添加到映射表项,便于获取分析代码信息及链接不同的分析代码块,并判断当前程序基本块对应的分析代码是否已经构建过,并检查原程序代码是否被修改.目标程序执行的指令地址到分析代码信息块的映射结构与进程页表结构类似,这里可采用三级索引结构.对于32位地址,与上节类似,一级索引表采用目标地址的高20位作为索引进行查询,而末级索引表则使用指令地址的最低2位比特.因此,一级索引表总共需要占用2MB的空间,而后两级结构的空间消耗取决于目标程序实际加载的代码大小.此外,为便于分析代码获取描述结构体信息,同时将描述结构地址保存在实际执行的分析代码之前.
污点分析过程中主要进行的任务是传递污染状态,该功能实际上相对较容易实现.因此,可以在分析代码中利用固定的寄存器来表示分析上下文以外的信息,例如:用ebx表示当前读取的运行时信息缓冲区地址,将edx指向存储寄存器分析状态的内存空间.而后针对上文所述两种类型的指令,我们分别构建相应的分析代码.对于涉及内存访问的指令,先从记录缓冲区中读取相应的内存地址并获取对应的状态存储地址,同时保证数据的同步,更具体的情况将在下文作进一步讨论.对于仅涉及寄存器运算的指令,则直接通过简单的传送指令完成分析状态的传递操作,并不依赖于其它线程和运行时信息.例如:对于原指令“mov eax,ecx”,则在分析代码中使用“mov eax,[edx+24];mov [edx+28],eax”两条指令来完成状态传递.
3.3 代码块的链接和执行
由于分析代码块与原程序产生的基本块保持对应关系,因此当原程序出现分支指令时,分析代码也需要能够正确的跳转到下一分析代码块继续执行.我们分别处理两种分支情况,一是间接跳转,如jmp eax、call [ecx]、 ret等.其中,对于涉及内存访问的指令,由于我们已经对其进行拦截并记录相关信息,因此可以从记录缓存区中附带取得下一个要执行的分析代码的指令地址.对于其它的间接跳转,同样可通过额外插桩记录来获取目标地址.二是直接跳转,即可直接从代码中获取跳转目标地址,但是对于其中的条件跳转,仍然需要根据实际执行情况来进行判断.与原程序不同,分析代码在分配时并不是连续的,因此需要重新建立不同分析代码块之间的依赖关系.如图2所示,我们在分析代码中结合无条件跳转指令来重建构建条件跳转指令,从而将不同的分析代码块关联在一起,保证其能连续正确的执行,并使用直接地址跳转来提高代码执行速度.
实际上分析代码在执行时,其下一个执行的目标地址将会出现在记录缓冲区中,为此在构建条件跳转指令时,可通过与下一个要读取的缓冲区内容进行比较来决定所要执行的跳转目标,如图2中“cmp [eax-4],241200”所示.需注意的是,这里比较的对象是分析代码所对应的描述结构信息,其目的是当原程序代码在执行过程中被修改时,实际的分析代码仍然能够被正确执行,即对于起始地址相同的原程序基本块,可能会有多个分析代码共享同一个分析代码描述结构.在这种情况下,我们将直接从记录缓冲区中获取下一个分析代码块并执行,如图2所示,100A6DE2处的代码修改,将导致其对应的分析代码重建,同时将其原来已链接的分析代码的开头处修改为间接跳转.
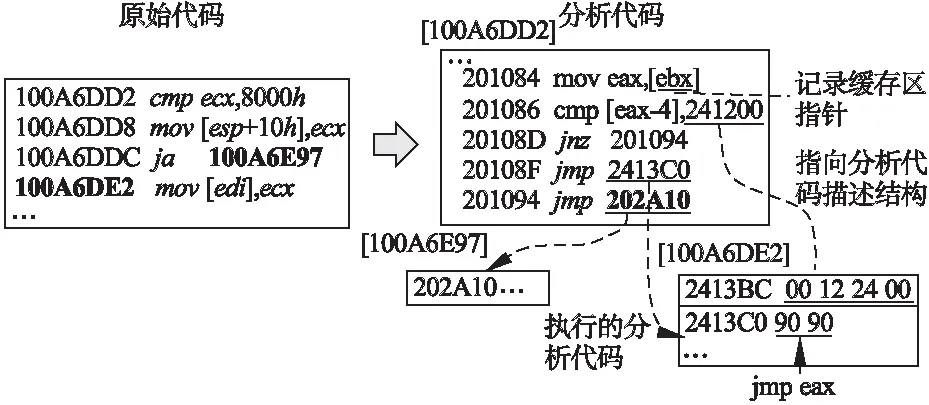
图2 条件跳转和分析代码Fig.2 Conditional jump and analysis code
针对上述条件跳转的情况,当拦截到目标程序执行新的程序基本块时,由于对已经执行的基本块进行了记录,因此我们可以获取到跳转至当前基本块的上一个基本块,并更新其对应的分析代码中的无条件跳转地址.如图2所示,从起始地址为100A6DD2的基本块可以执行到地址100A6E97,这样当拦截到100A6E97处的基本块时,同时更新上一个基本块对应的分析代码.如图2所示,无条件跳转目标地址202A10为更新后的指向实际分配的分析代码.
另外,由于用户回调和异步执行调用等机制的存在,当用户模式下的程序从系统内核返回后未必会继续执行后面相邻的指令.所以对于会导致处理器特权级别切换的指令,如:sysenter,int等,也需在程序执行时记录下其返回后的指令执行地址,在分析代码中按照间接跳转的方式来处理.
4 信息记录与线程同步
目标程序在执行时同步记录进行污点分析所需的运行时信息,主要为涉及的内存地址与值,以及必要的分支信息,通常采用代码插桩的方式来完成.主要原因是这些信息容易发生变化,我们需保证整个分析过程的准确性.针对分支信息的记录,包括两种情况,一是如果当前程序基本块中包含有内存操作指令,则在第一个访存指令处同时记录当前基本块地址;另一种是当前基本块不包含访存指令,则在基本块开头处作额外插桩并记录其起始地址.在大多数情况下,基本块内都会有指令涉及内存访问操作.另外,对于不含访存指令的基本块,事实上可以从当前线程的上一次记录处开始,通过寄存器运算来得到跳转目标地址,但可能会增加上下文切换的额外开销和出错的可能性.
在进行信息记录时,为减小内存开销,可以采用单个环形队列或者多个缓冲区轮流记录的方式[17],同样可减少因线程同步所带来的额外开销.目标程序线程与分析线程并行同步执行,即当原线程被创建时,同步创建并执行对应的分析线程.多数情况下,由于分析线程完成的工作量要比原线程少,因此在每次从记录缓冲区中读取数据时,需要判断取值是否为空,以保证分析执行的一致性.如图3所示,当分析线程从缓冲区中读取到的值为空时,则继续读取直到其值不为空.在此情况下,各个分析线程间的同步基本能够得到保证.另外,为控制分析线程对处理器资源的占用,当目标程序进出系统内核执行时,在保存记录时设置特殊标记,这样分析线程可根据该标记来进行等待和被唤醒.同样,若采用多个缓冲区时,在单个写满时也应添加标记.如图3中的数字顺序所示,中间当目标线程遇到系统调用时,则向缓冲区中写入e,而对应的分析线程如果读取到该值,则进一步读取缓冲区中的下一个值,如果下一个值为空,则表明目标线程还未从内核返回,此时分析线程则可进入睡眠状态,直到目标线程返回时被唤醒.
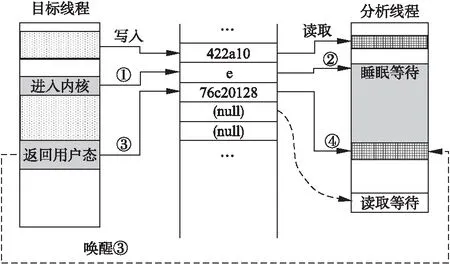
图3 线程同步示意图Fig.3 Synchronization between the native thread and analysis thread
5 实验与分析
本文在Windows平台上实现了该方法的原型,采用Intel Pin对目标程序进行插桩和拦截,并利用其提供的INS_InsertFillBuffer接口来记录目标程序的运行时信息[18],在记录缓存区满时使用系统函数WaitOnAddress来进行等待同步,具体的污点分析代码基于libdft的核心部分进行构建,并在实验中与之进行性能比较.实验环境为安装Intel Core i7-7700 CPU @ 3.60GHz、16GB内存的普通桌面终端,其中安装的操作系统为Windows 10 64-bit,当前测试目标为32位应用程序.
5.1 性能评估
采用Windows平台下多种常见应用程序来测试分析性能以及资源占用情况,具体列表如图4所示.具体的实验场景为,分别使用程序makecab、winzip(v21)及openssl(v1.0.2n)对大小为10MB的文本文件进行压缩或加密,其中openssl首
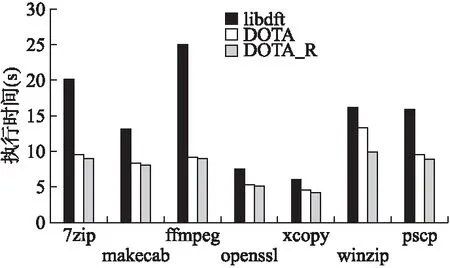
图4 针对多种应用程序的分析性能比较Fig.4 Comparisons of analysis performance for different programs
先要基于源码进行编译并使用aes-256-cbc加密模式.使用pscp(1)城镇化之前川渝地区乡下人居的正屋(又称“堂屋”)用作逢年过节祭祀点香用。从本地服务器下载大小为10MB的文件.而后使用7zip(v18.05)将大小为5MB的文本压缩为默认7z格式,使用ffmpeg(v4.0.2)将大小为1MB的wmv文件转换为mp4格式.最后使用系统内置程序xcopy复制系统分区中的WindowsINF文件夹到其它分区.选择不同的文件大小主要是基于执行时间和对比展示的综合考虑.在实验时,各场景重复多次并对相关结果计算平均值,并将结果与经典分析方法进行比较,主要结果如图4和图5所示.
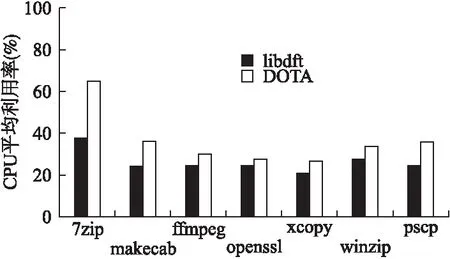
图5 对不同程序进行分析时的CPU占用率Fig.5 CPU usage in the analysis of different programs
在采用本文DOTA方法对不同程序进行分析时,其分析性能均会有提高,提高程度取决于具体的应用程序.如图4所示,对7zip和ffmpeg这类内存读写密集型程序,其分析效率提升效果会更加明显.另外图中DOTA_R表示仅对目标程序进行插桩并记录信息,但不进行分析的结果,与之相比,整个分析过程的效率降低并不明显.该情况表明线程同步和具体污点分析实际未对性能造成明显影响.多数情况下应用程序涉及内存访问的指令执行数量会占有较大的比例,由于实验中采用Pin来获取运行时信息,因此实际分析性能仍会受制于在线记录过程,尽管其可能不是速度最优的选择,但是较容易应用和部署的工具.从图5来看,分析线程导致的CPU占用率升高程度在可接受范围内,因为普通终端的总共可用CPU核心数量并不会太多,我们需要考虑其影响.另外,进行上述实验时,每个线程的记录缓冲区大小为256KB,记录时采用双缓冲来进行.
事实上,为控制CPU使用率,分析线程和原线程之间的同步仍然存在一定的开销,也会受到缓冲区大小的影响,其影响程度还依赖于目标程序的特点.我们选择上面的7zip程序进行同样的实验,但是改变记录缓冲区的数量来分析其带来的影响.从实验结果得知,当缓冲区数量为单个时,当其满时会因同步问题,导致分析效率明显下降.在其它情况下,完成分析所需时间和CPU占用率均随着缓冲区数量缓慢增长.其中一个主要原因是内存分配以及缓冲队列维护带来的开销.另外,若在实验中将缓冲区的数量固定为2个,则在此情况下,当单个缓冲区大小增加时,其分析性能并未一直随着提高.其原因是Pin会对已满的缓冲区进行清零处理,当其大小增加时,其对目标程序执行的影响程度会累积.总的来看,缓冲区的不同设置并不会对分析造成严重影响.
针对各程序进行分析时的内存资源占用情况如表1所示,分析代码的内存消耗情况跟实际执行的基本块数量相关,多数情况下处于较小的范围内.分析代码映射表中的二级索引大小与加载代码保持一致,而末级索引的内存开销可以忽略不计.依赖目标程序实际加载代码大小的还有污染状态存储空间,并且其还与程序执行时实际分配的内存相关.注意的是,实验中是根据目标程序分配的虚拟地址来分配状态存储空间的,而实际已分配物理页面并使用的虚拟地址数量会更少,但当前总体内存消耗在可接受范围.
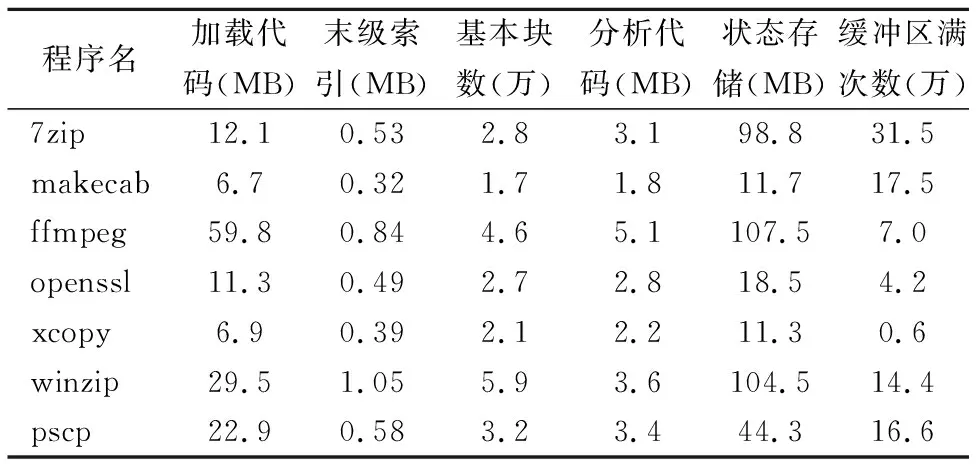
表1 资源占用情况统计Table 1 Statistics of other resource occupations
在采用真实环境程序进行实验的基础上,我们基于基准测试工具SPEC CPU 2006中的部分程序做进一步的性能测试,采用ref工作负载进行,并以程序原始执行所消耗的时间为基线值来计算其它两种分析环境下的执行速度的降低比率.如图6所示,从实验结果来看,在长时间的运行过程中,DOTA分析与传统分析相比仍然取得一定的分析性能的提升.由于基准测试程序运行时采用单线程,所以总体的CPU的开销为原来两倍左右.
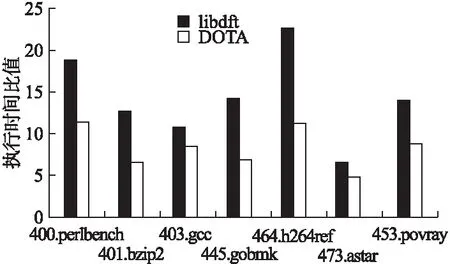
图6 采用基准程序进行测试的性能开销对比Fig.6 Performance comparisons for the tests on benchmark programs
5.2 案例分析
我们通过多个实际数据流分析的场景来验证本文所提方法的有效性.首先使用openssl对大小为1K的文件进行加密并将其内容保存至另一个文件;而后分别使用系统内置程序certutil,以及第三方应用程序aria2(v1.34)、curl for Windows(v7.61)、wget2所提供的下载功能从本地服务器上下载大小为1K的文件;最后对Trickbot恶意代码样本的数据发送功能进行分析,其在被感染的终端上启动运行后会创建文件client_id,读取内容后通过https协议发送到服务器端.而后在分析时,我们同时拦截NtReadFile、NtWriteFile和NtDeviceIoControlFile等系统函数,在其中标记相关内存地址为污染状态,并且及时检测数据污染情况.实验结果表明,本文方法均能够检测到污点数据的写入或者发送操作,并且通过多次重复实验得知其污点状态的传播情况基本上与传统分析时保持一致,而且不同的应用程序用于存储污点状态的内存开销在20MB至45MB之间,占用相对较低的内存资源,其它的统计信息如表2所示.
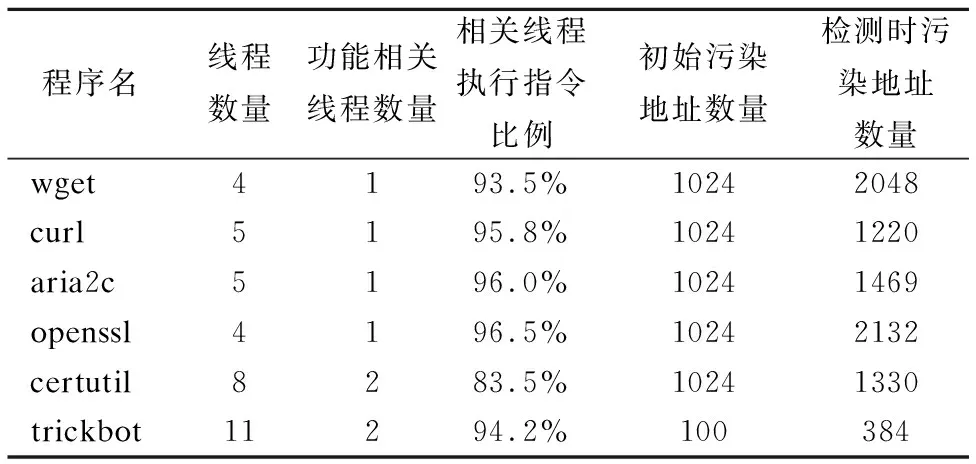
表2 功能分析的数据统计Table 2 Statistics of the functionality analysis
另外,certutil和trickbot程序在运行时由不同的线程来完成网络通信和文件读写过程,并且使用本文所提方法能够正确的进行污点分析,跨线程来传递污染状态,能检测到网络数据到目标文件的映射关系.此外,从表2中可以看出,尽管目标程序为多线程应用,但是与分析场景相关的往往只是部分线程以及部分执行代码.因此在实际分析中,我们可以只对相关线程涉及的代码进行拦截和分析,这将有利于对现代大型应用程序的分析.
6 讨 论
本文提供了一种针对多线程程序,快速构建在线解耦分析的思路,旨在充分利用现有插桩工具并进一步提高分析效率,通过实际程序验证了其可行性.与其它解耦分析相比,进一步提高了易用性和适用范围,并合理控制目标环境的资源开销.
该方法在线获取的运行时信息较为充分,尽管也会带来一定的性能开销,但是能够简化分析过程并保证准确性.当前分析效率仍受限于信息记录过程,而目标程序运行时的信息记录也可以采用其它更高效的插桩和记录方法来进行.在分析中该方法也可以采用其它污点分析引擎.
当前分析代码采用汇编语言编写构建,会导致分析缺乏一些灵活性.在实际中,如果有其它分析需求,可以先使用高级语言编写,再通过编译器优化功能来提取字节代码.
分析线程也可以在目标进程内执行,但这样会占用更多的目标进程的虚拟地址空间,也可以将其放入内核层.而其它的辅助缓冲区等内存也可以通过共享内存来进行.
在极端情况下,当不同目标线程间采用原子方式在极短时间内完成同步时,由于操作系统的线程调度机制,相对应的分析线程可能会未能及时处理该情况,此时需要加入额外的检查代码.
7 结 论
本文提出一种改进的轻量级在线解耦的动态污点分析方法,相比于传统分析方法能更高效的对目标程序进行细粒度分析,通过分离出部分可独立于原程序执行的分析任务,并构建相对应的分析代码,可降低对目标程序执行环境的影响并提高分析效率.本文通过采用多种真实程序及案例研究来验证了该方法的有效性和易用性.后续将针对任务分割、多线程同步以及64位平台开展进一步研究,以提高分析效率和部署灵活性.
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
散文诗世界(2019年10期)2019-09-10
思维与智慧·下半月(2019年4期)2019-05-04
中国新通信(2017年3期)2017-03-11
湖北教育·教育教学(2016年7期)2016-08-11
时代人物(2014年10期)2015-01-28
环球时报(2012-01-12)2012-01-12
城市建设理论研究(2011年23期)2011-12-20
