
众筹项目推荐:面向隐式反馈的深度学习协同过滤
2021-03-13 06:00吴远琴干宏程
小型微型计算机系统 2021年2期
吴远琴,尹 裴,干宏程
(上海理工大学 管理学院,上海 200093)
1 引 言
众筹是一种随互联网兴起而产生的新的融资方式[1].迄今为止,世界上最大的众筹平台Kickstarter(1)https://www.kickstarter.com/,已通过16,475,171为165,564个项目成功融资4,384,962,222美元,欧洲著名的众筹平台Ulule(2)http://www.ulule.com拥有超过260万,成功融资28,294个项目,总融资额达到143,381,350欧元.然而,Kickstarter的融资成功率仅37%,Ulule也只有65%.项目创意、项目的广告曝光度、项目持续时间等都可能影响项目融资成功率[2].然而,最大的原因是平台上项目众多,投资者很难浏览到真正感兴趣的项目.因此,众筹项目推荐,匹配投资者的偏好,有利于提高平台的融资成功率.
调查显示,大多数众筹平台上用户行为的稀疏度高于99%.过于稀疏的数据使得常用的协同过滤算法失效,例如基于用户的协同过滤,由于大量数据的缺失,无法有效计算用户之间的相似度.此外,推荐系统研究常用的公共数据集采用的是用户评分,例如Movie-lens、Netflix Prize等,可以直接根据评分来判断用户的感兴趣程度,从而确定正、负反馈数据.然而,众筹平台的用户投资行为属于隐式反馈数据.
为了降低稀疏数据对推荐的影响,以奇异值分解(SVD)为代表的矩阵分解技术,通过将用户对项目的评分分解为用户、项目的特征向量矩阵,利用用户和项目之间的潜在关系得到预测值,从而实现对高维稀疏的矩阵降维[3].然而,矩阵分解在降维之后,利用低维空间估计高维用户-项目交互关系,从而影响推荐的精度.
近年来,由人工神经网络发展来的深度学习技术,在自然语言理解、语音识别和图像处理等领域取得了突破性进展[4],深度学习中的深层神经网络为推荐系统研究带来了新的机遇.面对海量交互数据,深度学习通过学习用户-项目矩阵深层的非线性网络结构,挖掘潜在非线性交互关系.
He等人[5]提出神经协同过滤的通用框架,以神经网络,而非矩阵分解的内积,评估用户和项目的交互.不同于以往使用深度神经网络为辅助信息(例如描述项目的文字、图片等)建模,该方法在协同过滤的基础上,采用深度学习算法,生成用户-项目的交互函数.实验证明,与基线方法相比,该方法在公共数据集上取得了更好的推荐效果.因此,基于深度神经网络对复杂数据结构的隐层特征学习,本文以众筹项目为研究对象,将协同过滤与卷积神经网络相结合,提出基于深度学习协同过滤的众筹项目推荐方法.
2 文献综述
协同过滤推荐是目前应用最广泛的推荐算法之一.Hu等人[6]将协同过滤推荐算法分为主要两类:一类为基于内存的协同过滤推荐,另一类为基于模型的协同过滤推荐.近几年,随着人工智能研究的兴起,不少学者将深度学习技术引入协同过滤推荐,由于其主要是构建模型对用户偏好进行学习,所以也属于基于模型的协同过滤推荐.
2.1 基于内存的协同过滤推荐
基于内存的协同过滤推荐通常将数据载入内存进行运算,根据相似度生成推荐.其中包括基于用户(user-based CF)和基于项目(Item-based CF)的协同推荐,例如Sarwar 等人[7]提出基于项目的协同过滤推荐,该算法认为基于用户的算法在用户剧增的情况下计算量增大,而物品之间的相似度是相对固定的,所以基于项目的算法推荐准确性较高,适用范围也更大.
然而,基于用户和基于项目的算法都难以处理数据稀疏性问题,近年来不少学者对此进行了多种改进.例如,Hong等人[8]提出基于的相关系数的协同过滤推荐算法,以基于项目的协同过滤算法为基础,根据相关系数填充未评分的项目,引入语义相似度,提高项目相似度的计算,以处理数据稀疏性问题;Logesh等人[9]提出基于生物启发聚类集成的协同过滤推荐系统,通过聚类的方法为用户找到最相近的邻域,并以此生成相似度矩阵进行推荐.
2.2 基于模型的协同过滤
基于模型的协同过滤是在用户历史评分的基础上,建立模型,从而进行评分预测.这类方法通常采用降维,提取用户和项目的隐含特征.例如,王建芳等人[10]提出将奇异值分解(Singular Value Decomposition,SVD)技术与信任模型相结合的算法,将高维稀疏的矩阵进行降维,然后通过引入信任因子提高预测精度.然而,SVD在分解维度1000以上数据时的速度过慢,应用于现实系统中高达上千万维度的计算有一定局限性.
在推荐系统研究中,相较于显式反馈数据,如评分,隐式反馈数据更为常见,包括用户的点击、购买和搜索等,由此引起越来越多学者的关注.例如,Hu等人[11]基于矩阵分解,对隐式反馈数据进行建模.他们认为显式反馈表示用户对物品的偏好程度,而隐式反馈则表示偏好程度的置信度,从而将用户行为数据为分解偏好程度和置信度,并引入矩阵分解的目标函数进行求解;Koren等人[12]提出支持隐式反馈的矩阵分解模型(SVD++),该模型是基于SVD的一种改进算法,引入隐式反馈信息增加了预测准确度;陈碧毅等人[13]提出结合显隐式反馈的EIFCF算法,充分利用隐式反馈数据反映用户隐藏偏好的作用和显式反馈反映用户偏好程度的作用,并用加权矩阵分解克服隐式反馈数据缺少负样本的问题,从而缓解数据稀疏问题的影响.
2.3 基于深度学习的协同过滤推荐
随着深度学习技术的广泛应用,基于深度学习的协同过滤已成为目前研究的热点,不仅提高推荐的准确度,扩宽应用场景,也丰富了基于模型的协同过滤推荐.
深度学习利用深度神经网络学习原始数据,能更细粒度地发现用户和物品更为抽象的特征表示关系.例如,Yi等人[14]提出的嵌入隐式反馈的深度矩阵分解模型,构建深度网络池,对输入的用户和项目信息提取潜在因子,并以此预测用户评分.Wu等人[15]提出一种协同降噪自编码器模型(Collaborative Denoising Auto-Encoders,CDAE),通过在用户的评分向量中加入噪声,提升模型的鲁棒性,并且得到低维的用户隐式向量,然后用其对缺失的评分进行预测.
卷积神经网络已被应用于推荐系统,以解决数据稀疏性问题.目前,卷积神经网络主要被用于对用户或物品的辅助信息(如物品描述、评论等)进行建模,而对用户和物品的交互信息(如用户-物品评分)仍然采用矩阵分解技术.例如,Kim等人[16]提出将卷积神经网络与矩阵分解相结合的卷积矩阵分解模型,该模型通过卷积神经网络,提取物品描述文档的上下文信息中的特征,利用物品的辅助信息解决稀疏性的问题,提高评分预测精度.Zheng等人[17]构建卷积神经网络,利用用户和物品的评论学习特征,再通过矩阵分解得到用户和物品交互信息,以此预测评分,从而减小数据稀疏性对推荐结果的影响.Zhang等人[18]提出协同知识库嵌入学习模型,该模型通过知识库挖掘隐式反馈信息,得到用户和物品的隐式向量,以此预测评分.
2.4 文献评述
现有的研究已经对数据稀疏的问题提出很多解决方法.然而,还存一些有待改进之处.
1)基于内存的协同过滤主要通过融合用户与物品的属性等特征,或者对用户进行聚类等方式,降低数据的稀疏度.然而,其面向的是显式反馈数据,以及收集到的用户和物品的辅助信息,对数据的依赖性强,扩展性不强.
2)基于模型的协同过滤对隐式反馈信息展开研究,矩阵分解技术也在一定程度上缓解了数据稀疏带来的问题.然而,矩阵分解方法主要使用一个简单、固定的内积,线性建模,不利于估计用户和物品之间复杂的关系.
3)基于深度学习的协同过滤通过对辅助信息的学习,处理数据稀疏的问题,并且在提取特征上,获取用户和物品之间更深层次的关系.然而,该类方法虽然利用辅助信息代替线性模型的构建,但是用户-物品的交互数据在协同过滤推荐中的稀疏性问题仍然没有解决.
因此,针对以上不足,本文提出基于深度学习与协同过滤的推荐算法.面向众筹项目的隐式反馈数据集,利用卷积神经网络对局部特征有效学习的优势,以及协同过滤算法对用户-项目交互信息进行建模的特点,减小用户-项目交互信息稀疏性对推荐精度的影响.
3 基于深度学习协同过滤的推荐算法
3.1 深度协同过滤模型
本文的深度协同过滤模型是将矩阵分解与深度学习相结合,其基本思路如图1所示,利用投资者的投资行为数据和采集的负反馈数据,分别进行矩阵分解的线性学习,和深度学习的非线性学习,最后输出推荐列表.

图1 深度协同过滤算法的基本思路Fig.1 Basic idea of deep collaborative filtering algorithm
在协同过滤推荐算法中,以用户对项目的偏好形成用户-项目交互矩阵,并对这一交互矩阵进行建模,学习用户和项目的交互关系,最后得出预测值或推荐列表.本文提出的深度协同过滤算法,在协同过滤的基础上,利用深度学习在学习数据间非线性关系方面的优势,提高用户与项目之间的匹配度.
深度协同过滤的模型如图2所示,每一层的实现如下:
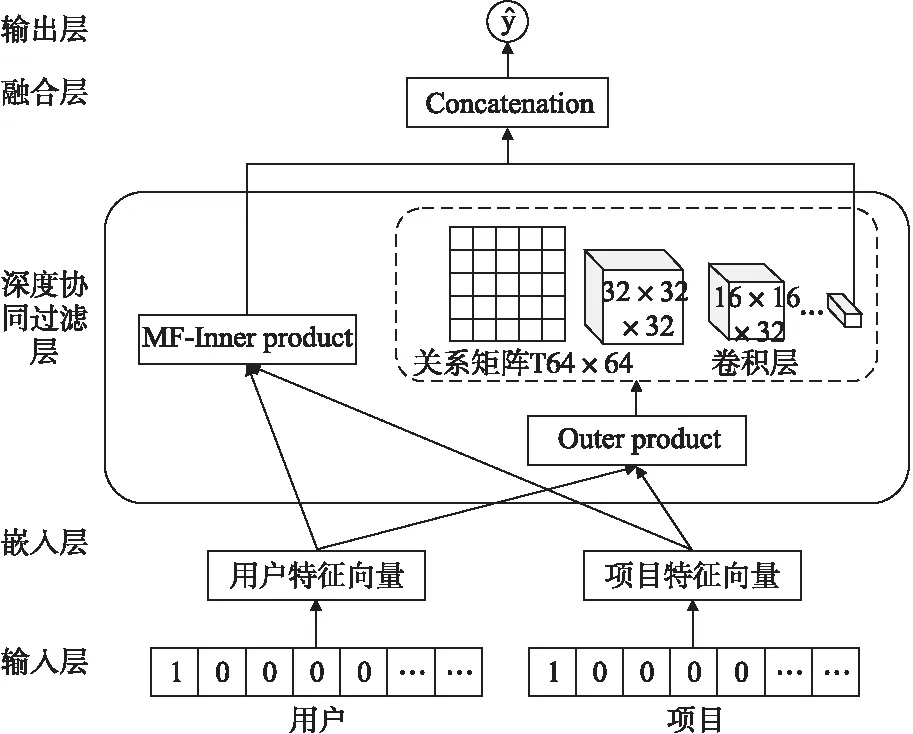
图2 深度协同过滤模型Fig.2 Deep collaborative filtering model
1)输入层:代表用户和项目特征的编号和正、负反馈数据作为输入,并用one-hot编码将它们转化为二值稀疏的向量vu和vi.
2)嵌入层:对输入层得到的稀疏向量进行降维得到pu和qi,即用户、项目特征向量,如公式(1)和公式(2)所示,其中嵌入矩阵pmxk和pnxk为K维的权重矩阵,通过K维特征表示所有的用户和项目.嵌入层的线性变换得到的稠密向量,不仅表示单个用户或项目降维后的对应关系,还表示所有用户或所有项目的内在关系.在训练模型的过程中,嵌入矩阵根据用户与用户、项目与项目之间的关系,更新权重.
pu=Pmxkvu
(1)
qi=Pnxkvi
(2)
3)深度协同过滤层:分别进行矩阵分解的线性学习和深度学习的非线性学习,如公式(3)和公式(4)所示.结合矩阵分解和深度学习两种方法的优势,训练推荐模型.通过矩阵分解的线性方式,将用户和项目的关系映射到潜在空间,得到f1;同时利用深度学习方法,学习用户和项目的隐层特征,得到f2.如此综合线性和非线性的学习方法,使得用户和项目的匹配度更加精确.
f1(pu,qi)=pu⊙qi
(3)
f2(pu,qi)=Φx(…Φ2(Φ1(pu⊗qi)))
(4)
4)融合层:将矩阵分解和深度学习分别学习得到的潜在特征向量f1和f2连接起来.
(5)
其中,m为用户数,n为项目数,f1是矩阵分解的内积函数,f2为深度学习的非线性函数,Φx为深度学习x层的非线性学习.
3.2 深度协同过滤算法
首先,本算法在嵌入层,利用矩阵分解得到用户和项目的特征稠密向量pu和qi.矩阵分解可以对高维稀疏数据进行降维,并且计算用户和项目的特征向量内积,以此预测评分.然而,用户的历史评分数据稀疏,造成评分矩阵出现大量的空缺,而矩阵分解学习用户-项目交互时采用简单的线性组合,难以填补空缺.因此,本文引入卷积神经网络,计算用户或项目的潜在非线性函数,以此学习用户与其交互的项目之间的潜在关系,从而补充缺失的数据.
其次,本算法通过外积学习特征向量每一维的关系,得到用户和项目的关系特征矩阵Tkxk,如公式(6)所示.
Tkxk=pu⊗qi
(6)
最后,将代表用户和项目每维关系的关系特征矩阵Tkxk,输入到卷积神经网络,在每层的卷积层中提取局部感知,利用卷积核在关系矩阵上做卷积,提取用户和项目的潜在交互关系.
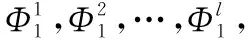
(7)
(8)
(9)
非线性激活函数通常为sigmoid,tanh或ReLU,这里选择ReLU函数,它与脑神经元对信息的激活反应相似,即只激活接受的信息,而其他信息会被过滤,因此ReLU函数更适合稀疏的数据集计算.而sigmoid和tanh函数都存在梯度消失的问题,并且训练过程中会出现过拟合的情况,实验结果也表明ReLU函数的表现好于另外两个.
3.3 深度协同过滤模型的训练
本文的众筹数据属于隐式反馈数据,取值为1或0,其中,1表示用户投资了该项目,即用户对该项目感兴趣,0则可能表示用户对项目不感兴趣,也可能表示用户不知道该项目的存在.显式反馈数据(如评分)直接反应用户对项目的偏好程度,而隐式反馈数据并不能表明用户的偏好程度,只能衡量用户偏好的置信度.因此,本模型的输出并非为评分预测,而是针对目标用户的推荐列表.
推荐列表中的项目排序,与用户对推荐结果的满意度相关.因此,本文通过成对学习正、负反馈样本的排序,采用贝叶斯个性化排序的损失函数[19],如公式(11)所示.

(10)
(11)
在模型训练中,采用自适应矩估计(Adaptive Moment Estimation,Adam)[20].随机梯度下降法(Stochastic gradient descent,SGD),在训练过程中保持学习率不变,也就是用单一的学习率修正权重,训练时间长.而Adam为不同的参数计算不同的自适应学习率,利用梯度的一阶和二阶矩估计,动态调整每个参数的学习率.Adam在本文的模型上收敛速度比SGD快.
4 实验设置与评价
4.1 实验设计
本文以欧洲第一大众筹平台Ulule上用户对项目的投资为研究对象,采集数据,设计实验,以衡量本文所提出算法的推荐性能.首先,通过深度协同过滤算法,分别对用户和项目数据进行线性和非线性降维,提取特征向量,生成特征矩阵,经过全连接层后输出;然后,通过训练集数据训练深度协同过滤模型,输出项目的预测评分,生成推荐列表;接着,进行迭代,基于Adam训练过程迭代更新权重和参数,在100次后保存最佳推荐列表,以及权重和参数;最后,设计实验,验证不同稀疏度的数据、卷积神经网络的层数、隐式反馈数据采集方法等因素对推荐性能的影响,并且选取基线方法,设计对比实验,验证本文所提出算法的有效性.实验流程如图3所示.

图3 实验流程图Fig.3 Experimental procedure
4.2 实验数据采集
众筹平台Ulule的主页实时显示平台的用户数,项目成功数以及成功率.平台对未注册的用户是公开的,访客可以查看和了解平台融资成功以及正在融资的项目.因此,本文采用网络爬虫技术,从平台获取实验数据.
采集到的数据包括:1)从项目出发,爬取所有成功融资和正在进行中的项目列表,其中项目列表的内容包括项目主页、是否已完成融资、融资总金额、发布者的国家、项目编码和项目的分类标签;2)根据项目,爬取投资过该项目的用户,再爬取每个用户投资过的项目,包括还在进行中的项目,其中用户列表的内容包括用户编码、用户主页、用户国家、语言、时区.如此反复迭代,直至数据集具有一定规模.
4.3 实验数据描述
本文从众筹平台Ulule爬取数据,共获得274,292个投资者,及其参与的41,894个项目,其中成功融资的项目有27,241,成功率为65%,产生363,608次投资.然而大多数用户的投资次数小于5次,其中投资次数为1次的用户最多,约为82.5%.因此,计算平台的数据稀疏度达99.98%.
由于数据稀疏性对推荐精度的影响是本文的主要研究问题之一.因此,通过采集不同稀疏度的数据集,用于验证本文提出的模型在不同稀疏度数据集上的表现.根据用户投资众筹项目的次数对数据进行处理,按稀疏的程度分为低度稀疏数据(人均投资次数在9次及以上)、中等稀疏数据(人均投资次数在5次及以上)和极度稀疏数据(人均投资次数在3次及以上),如表1所示.可见,投资次数越多的用户量越少,项目越少,所呈现的数据稀疏度也就越低.
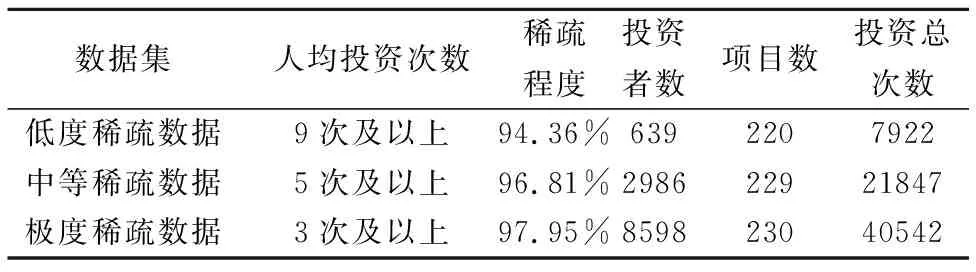
表1 不同稀疏度的数据集Table 1 Dataset of different sparsity
4.4 训练集与测试集
本文采用Leave one out方法,将包含n个样本的数据集分为训练集和测试集,其中n-1个样本为训练集,剩余1个样本为测试集.先从用户未投资过的项目中随机匹配99个项目,然后在用户投资过的项目中,按照时序取出最后一次投资的项目,构成100个未投资项目测试集;除去在测试集的一个项目,剩余的投资项目为训练集.
4.5 负反馈数据的采集
针对负反馈数据的采集,本文进行均匀采集和非均匀采集两种方式的实验.
1)均匀采集:均匀采集是在每次迭代中,采集用户所有未投资的项目作为负反馈数据,或者根据实验情况,灵活控制正反馈与负反馈的比例.
2)非均匀采集:非均匀的采集主要是对项目的选择设置一个标准,例如受欢迎程度高,曝光机会多等,因为用户在海量的项目中搜索到这些项目的可能性较高,所以如果用户没有投资,则对其不感兴趣的可能性较大.
分别对极度稀疏的数据集进行均匀采集和非均匀采集,极度稀疏数据集的投资次数为40,542,每一次投资(正反馈)采集4个负反馈,得到总采集个数162,168.用均匀采集方法,为每位用户随机采集4个负反馈,得到的负反馈在230个项目中的分布均匀,如图4所示.根据项目受欢迎程度方式采集项目,得到的负反馈集中在7个项目上,而其他项目只得到少量采集,如图5所示.本文的数据集在负反馈的采集上,均匀采集得到的负反馈样本的波动较小,数据离散程度小,而非均匀采集得到的样本离散程度大.

图4 均匀采集方法的负反馈分布图Fig.4 Distribution of negative feedback obtained by balanced collection method

图5 非均匀采集方法的负反馈分布图Fig.5 Distribution of negative feedback obtained by imbalanced collection method
4.6 评价方法
本文采用两种评估方法,衡量推荐算法的性能.
1)命中率(Hit Ratio,HR):衡量top-K推荐列表中属于测试集的筹资项目比率.
(12)
如公式(12)所示,其中n表示推荐列表中属于测试集项目的个数,N为测试集项目的总个数.
2)归一化折损累积增益(Normalize Discount Cumulative Gain,NDCG):衡量top-K推荐列表中项目排序的准确性.如果把一个用户不感兴趣的项目排在列表的前面,那么产生的误差率,比将其排列在后面更高.
(13)
(14)
如公式(13)和公式(14)所示,其中,reli表示推荐列表中位置i的项目与用户的相关性,公式(13)表明,DCG将推荐准确率与排序位置结合起来.为了使不同推荐列表之间具有可比性,进行归一化处理,如公式(14)所示.DCG的值介于(0,IDCG],NDCG的值介于(0,1].
5 实验结果分析
5.1 不同稀疏度数据对推荐结果的影响
为了消除卷积层数对实验结果的影响,分别设置卷积层数为4层、5层和6层进行实验,得到的结果如表2和表3所示,深度协同过滤模型在取不同卷积层数时,都在极度稀疏的数据集上取得了最好的推荐效果.由于大多数基于内存的协同过滤算法,在数据极度稀疏且数据量大的情况下,会限制推荐性能,因为用户(项目)之间的相似度会随数据稀疏、维度增加而难以准确计算,进而影响推荐效果.而深度学习方法则可以突破此限制,使其在极度稀疏的数据集上取得更好的推荐结果,显示了将深度学习应用于协同过滤推荐系统的优势.此外,在众筹平台Ulule上,其数据稀疏度远大于本文选取的极度稀疏数据集,所以本文提出的模型适用于数据量大且更稀疏的Ulule平台.
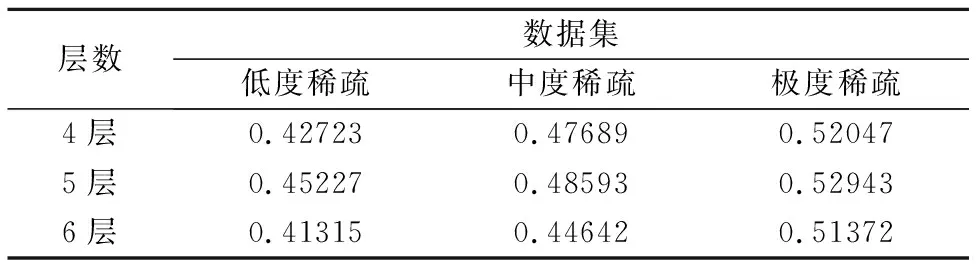
表2 不同稀疏度的数据集推荐结果HR最大值Table 2 Maximum value of HR of recommendation on datasets of different sparsity

表3 不同稀疏度的数据集推荐结果NDCG最大值Table 3 Maximum value of NDCG of recommendation on datasets of different sparsity
5.2 卷积神经网络卷积层数对推荐结果的影响
卷积神经网络的卷积层数会影响对用户和项目特征的提取,进而影响推荐的效果,因此,通过实验对比不同卷积层数对推荐结果的影响.
由于前述实验已证明本文提出的模型在极度稀疏数据集上的推荐效果最好,所以本次选择极度稀疏的数据集对卷积层数的影响进行分析.图6显示,HR值和NDCG值初始随着卷积层数增加而升高,当卷积层增加到6层时,HR值和NDCG值开始降低.由此可得,卷积神经网络的卷积层数对推荐结果有显著影响,并且当卷积层数增加到临界点时会取得最优推荐效果,继续增加层数反而会降低卷积神经网络特征提取的精确度.
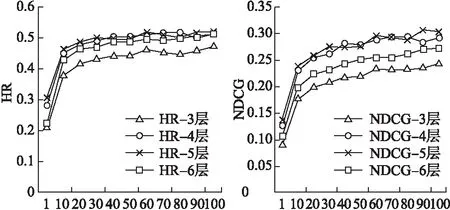
图6 在极度稀疏数据集上不同卷积层数的模型推荐结果HR和NDCG值Fig.6 HR and NDCG of recommendation based on the model with different convolution layers on extremely sparse dataset
5.3 负反馈数据采集方式对推荐结果的影响
同样以极度稀疏数据集为实验数据,对于每个用户分别采集1~4个负反馈,通过实验比较均匀采集和非均匀采集的负反馈数据采集方式对推荐结果的影响,结果如表4和表5所示.
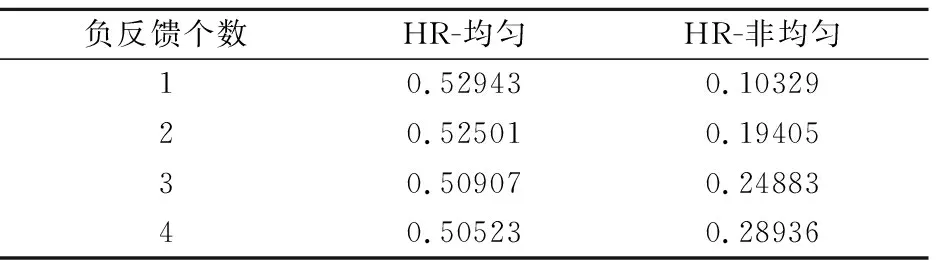
表4 在极度稀疏数据集中不同负反馈采集方式的推荐结果HR值Table 4 HR of recommendation with different negative feedback collection methods on extremely sparse dataset
表4和表5显示模型在极度稀疏的数据集上进行推荐,分别采用均匀和非均匀方式采集负反馈数据所得到的HR值和NDCG值,由此可见均匀采集方式得到推荐效果更好,并在采集个数为1时达到最佳.导致非均匀采集负反馈数据的实验结果效果不佳的原因,很可能是在本文构建的数据集中,用户对项目的受欢迎程度不敏感,负反馈数据集离散程度大,根据项目受欢迎程度进行的负反馈样本采集,只集中在受欢迎程度最高的7个项目,负反馈重复选取这7个项目,使得数据集不具有代表性,导致得到的效果极差.

表5 在极度稀疏数据集中不同负反馈采集方式的推荐结果NDCG值Table 5 NDCG of recommendation with different negative feedback collection methods on extremely sparse dataset
5.4 对比实验
本文选取基线方法,设计对比实验,以验证本文提出的算法的有效性.
选取的基线方法包括:
1)Most popular:该方法的推荐列表是根据项目受欢迎程度进行排序,属于非个性化推荐,也就是所有的用户得到相同的推荐结果,通常被用于对比推荐结果.
2)eALS:He等人[21]提出基于隐式反馈的矩阵分解模型,根据项目的受欢迎程度设置未评分部分的权重,同时为了提高模型参数的计算效率,设计eALS学习算法,并在此基础上建立适用于动态数据的在线更新策略,以捕捉用户的短期偏好,而且在线的场景使基于隐式反馈的矩阵分解能在大规模的实际环境中应用.
3)BPR:Rendle等人[19]提出基于贝叶斯理论的个性化排名算法,针对隐式反馈数据,在矩阵分解或者最近邻方法中生成的个性化推荐列表进行排序优化,提高用户对推荐列表的满意度.利用用户已购买的商品和未购买的商品的偏序关系,采用贝叶斯分析推导得到最大后验估计,进行模型训练,最后生成优化后的项目排名.
4)CM-RIMDCF:Fu等人[22]提出的分两阶段的深度协同过滤模型,第1阶段通过局部和全局模型对用户和项目分别进行学习,获得代表用户-用户和项目-项目的特征信息,再将此作为第2阶段的输入;第2阶段利用神经网络学习用户和项目相互作用的信息,得到预测评分.
5)multi-criteriaDCF:Nassar等人[23]提出的多准则深度协同过滤模型,将用户偏好分为总体评分和多准则评分,以量化用户对项目不同特征产生的兴趣.在此基础上,设计两阶段深度神经网络模型,第1阶段先预测多准则评分,再将其输入到下一阶段的深度神经网络,以预测总体评分.
对比实验使用公共数据集,Yahoo! Movies的用户评分数据集,验证本文提出的算法是否在推荐性能上相比基线方法有所提高.用户对电影的评分等级为A+到F,该数据集属于显式反馈数据集,所以需要将其预处理为隐式反馈数据.将“评分”这一行为(不论评分大小)视为1(即存在交互行为),反之为0.在此数据集中,用户评分的电影为10部以上,每部电影至少有一位用户评分.因此,总共7,642名用户和11,915部电影,评分(交互次数)为211,231次,稀疏度为99.77%.
本文提出的算法与基线方法的推荐结果如表6所示,其HR值和NDCG值都明显优于其他3种基线方法,说明本文提出的算法能有效提高推荐的性能.
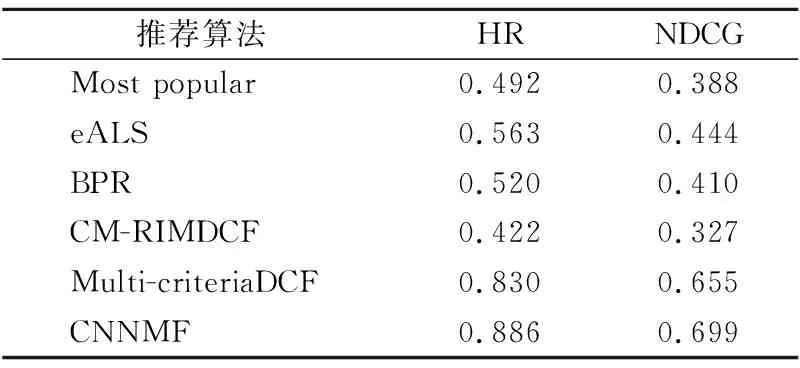
表6 不同算法的推荐结果对比Table 6 Comparison between the proposed algorithm and the baselines
通过以上5种基线方法与本文提出的算法进行对比,本文提出的算法在Yahoo! Movies数据集上得到的HR值和NDCG值,都优于其他五种基线方法.进一步分析原因如下:
1)在极度稀疏数据集(投资总次数40,542)中,受欢迎程度排前10的项目的投资次数,占总投资次数37.97%,而前10个项目在项目数上仅为总体的4.35%,由此可见受欢迎的前10个项目确实得到较多用户的关注,但它并不能为每个用户提供个性化的项目,所以推荐效果也是最差的.
2)BPR和Eals算法针对隐式反馈数据提出不同的优化方法,但仍以传统矩阵分解为基础构建模型,对于稀疏数据的处理存在一定局限,由此对模型训练和推荐结果都产生影响.
3)CM-RIMDCF算法以用户和项目之间的相关性为基础,学习用户和项目的相互作用,但是该方法提出的局部和全局表示模型,利用显式评分进行学习,却不适用于隐式反馈,从而影响第2阶段神经网络的预测.此外,该方法中的神经网络只有一层全连接隐藏层,在学习用户和项目的相互关系上有一定局限.
4)multi-criteriaDCF提出的多准则评分能够解释用户偏好的原因,然而,在实际应用场景中此类型的数据获取有限,大部分为单一的总体评分.此外,该方法仅利用深度神经网络计算多准则评分和总体评分,在将深度神经网络与协同过滤的融合上还存在不足.因此,本文提出的深度协同过滤模型通过更好地融合深度学习和协同过滤,更精准地提取用户和项目的交互信息,从而得到更好的推荐效果.
本文提出的算法结合卷积神经网络和矩阵分解的互补优势,学习用户和项目特征信息的潜在关系,比传统协同过滤推荐算法运用的线性学习更有效.
6 结 论
本文针对众筹平台Ulule数据极端稀疏的问题,以及平台用户投资行为为隐式反馈数据,没有负反馈这一特点,融合深度学习与协同过滤推荐算法,为投资者生成个性化的众筹项目推荐列表,以此提高投资者与项目之间的匹配度,进而提高众筹平台整体的融资成功率.
针对众筹平台的推荐问题,本文提出的算法进行了以下几个方面的改进:
1)提取用户和项目的特征数据,以及实际交互信息,训练模型;
2)在提取用户和项目特征信息的潜在关系时,结合矩阵分解和卷积神经网络,分别对特征信息进行学习,以发挥两种方法的互补优势,提高特征提取的精准性;
3)分别通过均匀和非均匀两种负反馈样本采集方式,对众筹平台的隐式反馈数据进行采样和分析.
为了验证本文提出算法的有效性,选取基线方法,设计对比实验.实验结果表明,相较于基线方法,本文提出的深度协同过滤模型在数据集上的推荐效果有明显的提升.由此说明融合深度学习技术学习投资者与项目的非线性交互,可以有效解决数据稀疏性对推荐效果的影响.并且数据量越大越稀疏,通过一定卷积层数的卷积神经网络,可以得到最佳的推荐性能.此外,针对负反馈数据的采集问题,需要考虑项目的特点,非均匀采集虽然有更好的解释效果,但不一定适用于本模型的训练.
本研究不仅有助于提高众筹平台的融资成功率,还丰富了推荐系统的研究体系.在今后的研究中,以下几方面值得深入探讨:
1)针对不同互联网金融平台和不同语言的用户、项目数据进行实验,以评估本文所提出方法的通用性;
2)添加辅助信息,或者多准则评分数据为实验数据;
3)进一步探索其他深度学习方法在推荐系统中的应用.
猜你喜欢
社会科学战线(2022年9期)2022-10-25
农业工程学报(2022年12期)2022-09-09
新班主任(2022年4期)2022-04-27
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
领导决策信息(2018年7期)2018-05-22
读与写·教育教学版(2017年10期)2017-11-10
民生周刊(2017年19期)2017-10-25
南都周刊(2015年4期)2015-09-10
