
基于多源异构的医疗数据汇聚方法设计与应用
2021-03-12 07:00魏子重高妍方包国峰
软件导刊 2021年2期
徐 娟,魏子重,高妍方,包国峰
(1.山东第一医科大学附属省立医院信息网络管理办公室,山东济南 250021;2.浪潮云信息技术股份公司,山东 济南 250022;3.山东建筑大学 管理工程学院,山东 济南 250101)
0 引言
我国医院信息化经过近30 年的建设,大部分中大型医院已基本形成以医院信息管理系统(HIS)、电子病历(EMR)、实验室信息管理系统(LIS)、医学影像系统(PACS)以及放射信息管理系统(RIS)等为主要应用的综合性信息系统,能够满足临床服务流程业务需求,为医院管理提供一定的支撑[1]。
医院信息建设规模越来越大,应用越来越复杂,由于系统处理业务和采用的技术架构不同,导致在数据结构形式上呈现多源异构性,如影像、内镜、心电系统等产生的视频、图像等多媒体格式存储的非结构化数据,HIS、LIS 系统产生的患者信息、医嘱处方、检验指标等结构化数据,电子病历系统产生的半结构化数据。同一属性在各自系统中有不同命名和表达方式,类型不统一、数据来源广泛、非结构化程度高,必须对多源异构的医疗数据进行汇聚和整合,转换为高质量的数据集,为临床诊疗、大数据应用提供支撑。而如何研发医疗大数据挖掘与分析技术,构建临床数据中心,研发数据集融合技术,实现各类临床数据的采集,研究多模态异构、非结构化医疗大数据挖掘与分析技术体系成为重点[2]。
医疗大数据的融合与汇集一直是重要的研究课题。在大数据环境下,刘金晶等[3]提出了一种数据质量策略,通过建立数据质量评价体系,从完整性、一致性、准确性、及时性4 个方面评估数据质量,为提升数据质量提供管理依据;马云等[4]提出两种临床数据中心构建模型:共享信息模型与逻辑集中模型,分析认为逻辑集中方式比较适合医院构建临床数据中心。在信息建设初期,逻辑集中方式的临床数据中心构建,通过集成平台减少系统间数据访问,降低系统之间的耦合度,适合解决当前医疗机构多系统交互问题。而随着信息技术在医疗领域的应用,临床人员要求全面、准确的患者数据,构建基于大样本数据的科研应用需求日益凸显,整合构建独立的临床数据中心成为未来临床诊疗服务的必然过程。国家卫生健康委关于《国家医疗健康信息医院互联互通标准化成熟度测评》评级标准提出“具备基于医院信息平台独立的临床数据库”要求,对数据传输时效性提出明确标准。国家卫生健康委发布的《电子病历系统应用水平分级评价标准(试行)》将电子病历系统应用水平划分为9 个等级,要求“形成临床数据仓库,有统一索引与规范数据格式,形成结构化数据内容”。
为有效存储和利用相关数据,需要在既有业务系统上建立数据中心,对病人诊疗数据(数值、文字、波形、图像)进行统一管理和标准化存储,通过集成平台实现患者临床信息的整合及数据共享,同时建立并完善病人主索引(EM⁃PI)、全院统一的主数据管理(MDM)、统一用户管理等平台基础服务,在此基础上建立面向医院管理层的决策分析系统,满足医疗科研和临床决策支持等需求,以及支持区域医疗信息共享。曾汪旺等[5]通过构建数据实时采集子系统和增量式映射管理平台两个中间件,对多源异构医疗数据进行ETL 抽取;刘蔷等[6]提出基于Caché 数据库的ETL 过程,使用Speedminer 工具进行数据构建。Speedminer 是澳大利亚Trak 公司提供的第三方产品之一,与Caché 属于同平台关联产品,但相关研究对存储于后关系型数据库Caché 的数据抽取汇集到如SqlServer、Oracle 等关系型数据库中的方法较少提及。
为做好新冠肺炎疫情防控工作,合理安排医疗资源,需以医院全视图数据为视角,完成多源异构医疗数据,包括患者全视角病历信息、疫情管控信息、卫生统计报表等的汇聚。为此,以山东第一医科大学附属省立医院(以下简称山东省立医院)信息建设为例,提出后关系型数据、文档型数据汇聚、非结构化数据汇聚设计方法,并基于此进行医疗数据汇聚应用。
1 山东省立医院信息系统总体架构
山东省立医院信息系统由23 个业务子系统组成,各系统间的整合集成与扩展一直制约医院数字化发展。2014 年医院开始建设基于Ensemble 中间件的集成平台,在IHE、DICOM、HL7 等国际标准基础上,通过规范系统集成平台,制定覆盖医疗所有业务流程的系统集成规范,开发基于规范的系统集成平台。信息平台建设主要解决两个核心问题:①为各种医疗应用提供统一的医疗数据访问服务,消除各种医疗应用系统与医疗数据中心的直接耦合性;②通过HL7 和DICOM 等标准通讯协议为各种医疗应用系统提供集成服务,确保各个临床信息系统在工作流整合的基础上实现交互协作。
临床数据中心(CDR)是医院为支持临床诊疗和全部医、教、研活动,以病人为中心重新构建的数据存储结构,是医院基于电子病历信息平台的核心构件。数据通过平台ETL 的抽取、清洗、转换、装载等处理,按照互联互通标准体系及不同的业务需要存储到不同的库中,形成以患者主索引(EMPI)、主数据管理(MDM)等按领域组织的临床数据集,在主数据基础上产生各个“维度”,统一数据口径,通过Ensemble 企业服务总线提供多种输入输出适配器,有效解决异构数据交互问题。系统总体架构如图1 所示。
2 多源异构数据汇聚设计
基于医院信息平台建设独立的临床信息数据库,存储以病人为中心的全程临床数据,如医嘱、电子病历、PACS等临床数据。临床数据中心建设主要目的是实现医疗数据挖掘,为医院的诊治、管理和运营提供决策支持。为确保数据应用性能和效率,需要实现数据的物理汇聚和集中存储。数据在不同业务系统中以面向对象数据库、关系型数据库、大文本文件、图像、XML 文件等形式存在。本文数据汇聚设计基于HL7 规范,使用SQLServerSSIS 工具包创建临床数据仓库模型。HL7 是由美国国家标准局(ANSI)授权的标准开发机构(Health Level Seven Inc,HL7 组织)研发的一个专门用于医疗卫生机构及医用仪器、设备数据信息传输的标准。数据汇聚的总体策略是在不影响在线业务系统运行前提下,尽量通过shadow 库,采用历史数据单次全量抽取,增量数据采用时间戳、WebService、CDC、非结构化文本解析等增量抽取方法,对临床异构多源数据实现增量汇聚及优化。在增量数据抽取时多种方式联合使用,优劣互补,以提高抽取性能。
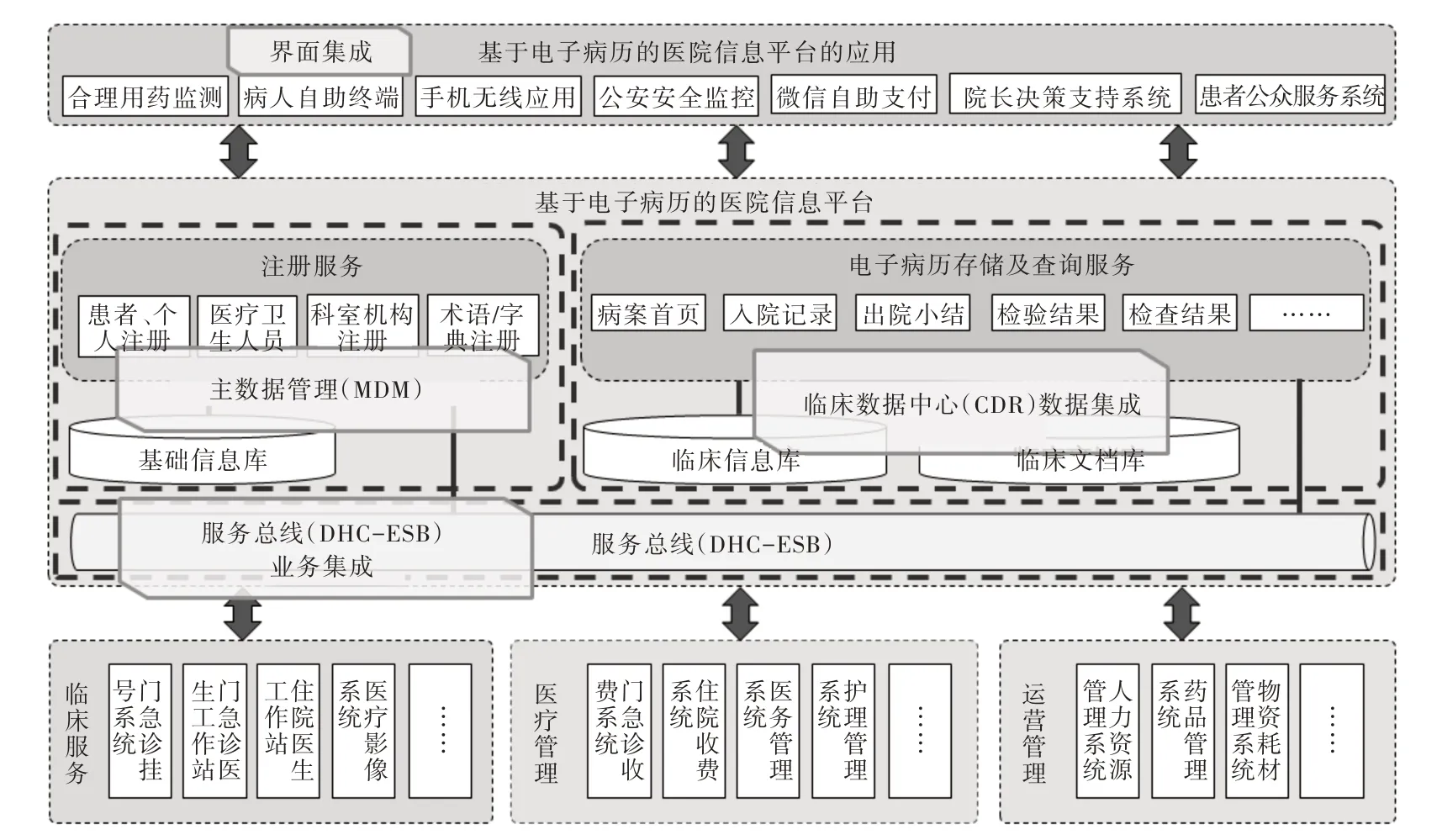
Fig.1 Shandong provincial hospital information platform technology architecture图1 山东省立医院信息平台技术架构
2.1 基于时间戳和ETL 的后关系型数据汇聚设计
医院HIS 系统是Caché 数据库,是一种后关系型数据库,数据存于树形多维数组中,以节点Global 的形式存在。利用类与对象模拟关系型数据库的管理表,表中的数据可通过SQL 查询,完成数据库中数据的对象化操作。支持JDBC 和ODBC 标准接口,方便与RDBMS 系统交互数据。但在数据汇聚设计时,该数据库事务日志记录Global 操作日志,无法直接解析到关系型库中,且映射到的关系型表没有时间戳,给数据抽取带来难度。
为解决医院HIS 数据实时同步抽取问题,经业务数据表结构分析,在对Caché 数据库业务数据处理上,采用时间戳(业务时间)+数据验证的ETL 增量数据处理方式。历史数据通过ETL 每天先从HIS 增量更新到ODS,再从ODS增量更新至CDR;增量数据更新方式为直接从HIS 至CDR,更新频率为每小时一次,数据范围为当天所有数据。由于源数据库未记录时间戳、部分表数据存在物理删除操作,因此根据业务时间ETL 增量更新可能会丢失或增加数据。通过数据验证判断各个具体数据源更新、删除情况,根据验证结论再次通过ETL 定期进行数据修复操作,最大程度减少数据误差。基于时间戳+数据验证的HIS 数据接入流程如图2 所示。
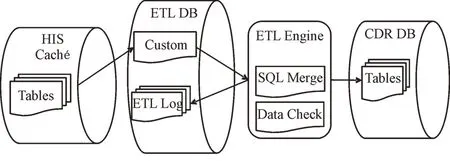
Fig.2 Ihs data access based on timestamp+data validation process图2 基于时间戳+数据验证的HIS 数据接入流程
HIS 数据接入流程如下:①通过数据分析确定HIS 和CDR 目标的对应关系,形成接入设计文档;②根据接入设计文档编写以HIS 数据库为对象的Custom SQL;③通过ETL 工具配置Custom SQL 对应的CDR Tables;④通过已封装的ETL Engin 轮循调用SQL Merge 将数据更新至CDR DB 对应的Tables 中;⑤记录日志供查询,并通过数据验证机制校验。
2.2 基于WebService 的文档型数据汇聚设计
电子病历系统、护理文书系统、手术麻醉系统等存在大量基于文档的数据,在各个系统中采用文本文件、XML文件、CDA 文件或关系型数据库进行文档存储。
如电子病历中的病程记录、手术记录等存在多个应用场景,需要将数据标准化为符合HL7 CDA 标准的可利用数据。医院电子病历文档通过加密方式存储在Oracle 数据库中,数据类型是Blob,整体进行数据抽取时无法很好解析病历结构,故要通过处理电子病历系统形成符合标准格式的文档,提供WebService 接口方式给第三方。临床数据仓库通过WebService 获取EMR 文档信息,返回htmlString与XmlString 内容。其中HtmlString 是完整的网页,用于展示EMR 文档信息;XmlString 是后结构化数据,用于对EMR 文档进行分析。通过分析返回报文,提取结构化报文中的数据变更信息,由ETL Engine 生成变更Sql,更新至CDR 数据表中。基于WebService 的文档型数据汇聚接入流程如图3 所示。
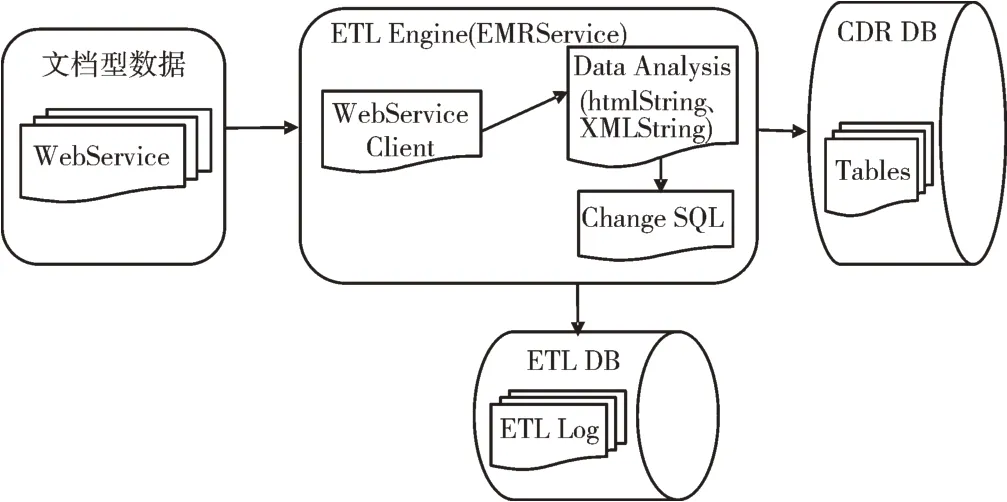
Fig.3 Document type data access process based on WebService图3 基于WebService 的文档型数据汇聚接入流程
2.3 基于CDC 和ETL 的非结构化数据汇聚设计
医院LIS、RIS/PACS 系统为Oracle、SQL Server 关系型数据库,一部分患者信息、报告等为结构化数据,一部分报告数据为存有图像化的非结构化数据。患者信息、检验检查申请单等结构化数据,基于关系型数据库支持日志文件分析特点开启redo log 日志服务,通过数据库上的变更数据捕获(Change Data Capture,CDC)机制采用CDC+ETL 平台增量抽取方式抽取到ETL 平台。业务系统将数据实时推送至ODSDB 环境更新每日数据日志,通过日志将数据实时更新至CDR 数据表中。而大量的图像数据因存储空间限制,仅与完成结构化的报告数据进行映射存储,与患者主索引及检查报告做ID 关联。
疫情防控需新增卫生统计上报、社区体温登记信息、关注人群(密切接触者、医护人员)健康信息、单位复工健康信息等,生成的非结构化文本数据需要汇聚时,采用基于文本解析的疫情相关数据接入流程。通过ETL Engine中的Data analysis 进行分析,按照文件模板标识提取csv、EXCEL、dbf 文件中的增量数据,并根据模板中字段对应关系汇总成增量Change SQL。使用Change SQL 完成CDR DB 的增量数据汇聚,进行数据应用与分析。基于CDC+ETL 的结构化数据汇聚流程如图4 所示。
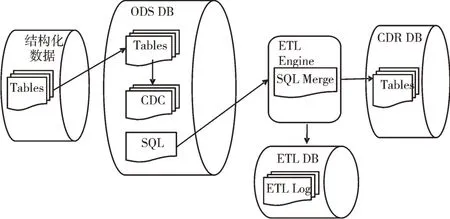
Fig.4 Based on the CDC+ETL structured data gathering process图4 基于CDC+ETL 的结构化数据汇聚流程
3 数据标准化清洗及汇聚实现
3.1 数据标准化清洗
由于医疗数据产生于不同业务系统,多数据源异构主要表现为字段名称和类型的不一致,以及数据所在的定义域不同等。医院按照卫生部《电子病历基本架构与数据标准》要求,参考HL7 CDA 标准进行文档标准化,采取统一元数据进行异构数据的标准化过程。为保证电子病历资源库中数据内容满足卫生数据元以及值域要求,医院统一对术语字典及值域映射进行管理,实现数据采集清洗的规则配置、基于标准的全息信息扩展、统一的字典注册整合及维护、数据采集清洗状态监控等。数据清洗标准化过程如图5 所示。
3.2 数据汇聚实现
做好从生产库到ODS 库以及ODS 库到临床数据中心数据抽取的质量控制,以确保和业务系统原始数据保持一致,实现数据完整性、一致性、准确性、及时性。
(1)多通道多任务技术。定义多个数据抽取通道,将任务拆分成更细粒度的任务,分片进行管理配置。根据每种数据源特征定制不同的分析方案,启动多个抽取服务。每个抽取服务监听一个通道,完成抽取任务,多个抽取服务并行运行,实现多通道多任务抽取,加快数据获取速率。
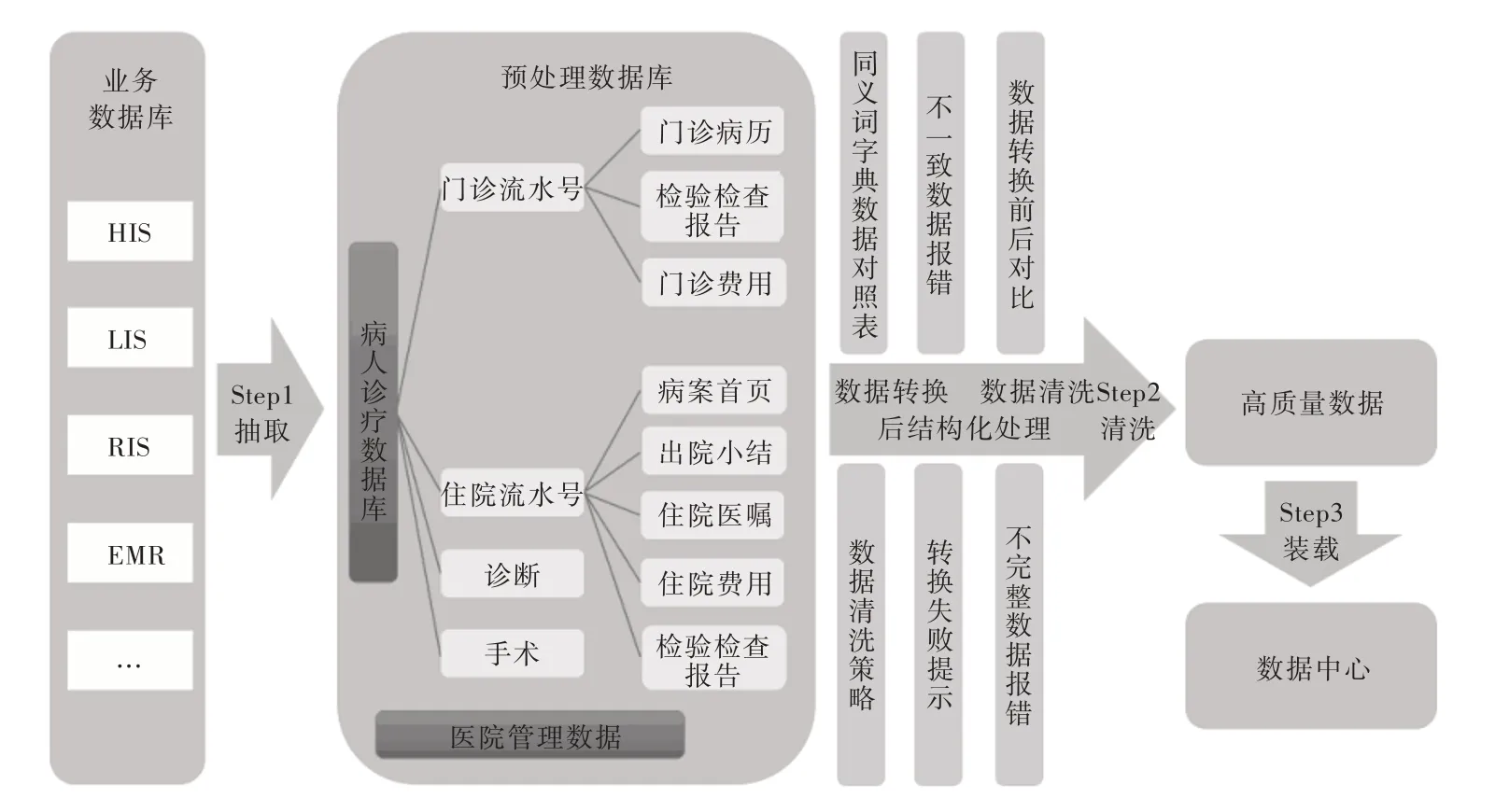
Fig.5 Standardization of data cleaning process图5 数据清洗标准化过程
(2)提高批量数据写入效率。从生产库到ODS 库,采用Sql BulkCopy 技术批量写入数据。首先将插入的整个数据集整理为大数组,把整个大数组作为一个数据集调用BulkCopy 接口一次性写入到服务器,而不是循环对每行数据调用Insert。批量数据插入技术规避了多次与数据库建立连接的负荷压力,比传统循环调用insert 方式快5~10倍。
(3)维度渐变处理。通过临床数据中心模型生成器制定相关缓慢变化维度,并在生成的表结构扩展属性上标识该列。临床数据中心首先对基础数据进行刷新,然后对所有的维度表进行校验并保存完整性校验。在固定间隔内对需要处理渐变的数据维度属性检查一次,确保维度关键属性发生变化后能及时更新并反映到数据聚合上。
(4)增加容错补偿机制。对数据抽取过程进行控制,个性化定制自动抽取任务,提供抽取条件、时间点、任务循环、检查点、不符合条件消息处理等选项,提供抽取前处理、抽取中处理、抽取后数据处理程序。提供数据容错机制,定义无数据算出错,抽取出错自动补抽取,无需人工干预。通过抽取任务错误日志、短消息提醒进行追踪监测。
4 多源异构医疗数据汇聚应用
山东省立医院临床数据中心平台建设经过多年的探索实践,取得较好的建设效益。基于电子病历的医院信息平台架构包括主数据管理(MDM)、临床数据中心(CDR)、医院服务总线(DHC-ESB)、基于平台的应用等,实现了服务和消息注册、发布和订阅功能和接口消息复用。现在已经接入服务总线的系统有HIS、EMR、LIS、PACS、心电、手麻、掌上省医、护理系统、自助系统、ICU、分诊叫号系统、病案管理、预约诊疗系统、自动包药机、公安局安全系统、单点登录、院感、药品物流、手术上报、文档库管理系统、主数据管理系统等23 个子系统68 项平台服务。医院建设了独立的临床信息数据库,存储以病人为中心的全程临床数据,诸如医嘱、电子病历、PACS 等临床数据,形成患者主索引476 万条,共享数据库中CDA 文档共970 万份,用于病人的全视图信息共享及用于医院的临床业务监管、BI 分析、科研教学支持等。共享文档管理如图6 所示。
通过对医院23 个主要业务系统和数据进行集成整合,将封闭在多套孤立信息系统中的数据集中,实现全院信息统一标准、统一来源、统一发布、统一管理。通过智能决策支持系统,管理者可以随时随地获取门诊状况、床位使用率、平均住院日、药占比、医疗质量、人力资源配置等核心运营指标。系统自动测算患者从开始分诊到就诊结束期间各个环节就诊时间路径图,通过分析结果发现哪些就诊环节存在就医瓶颈,从而有的放矢改进服务流程。整合从患者入院到出院整个诊疗过程中产生的所有医疗数据,包括病人基本信息、病历文书、检验检查、医嘱等。通过汇集以患者为中心的全周期研究数据,建立可供用户快捷检索的数据搜索平台及基础科研平台。主要数据类别有病案首页、病历、诊断、症状、用药、手术、处置类医嘱、非用药医嘱、检验、检查、分子病理、病理、生命体征、病种等4 797 个字段,并逐步增加。基于结构化的多重检索充分挖掘医院海量临床数据的潜在价值,提升医护人员开展临床科研工作效率及临床数据再利用能力,医院已基于该平台进行了50 多个科研项目。
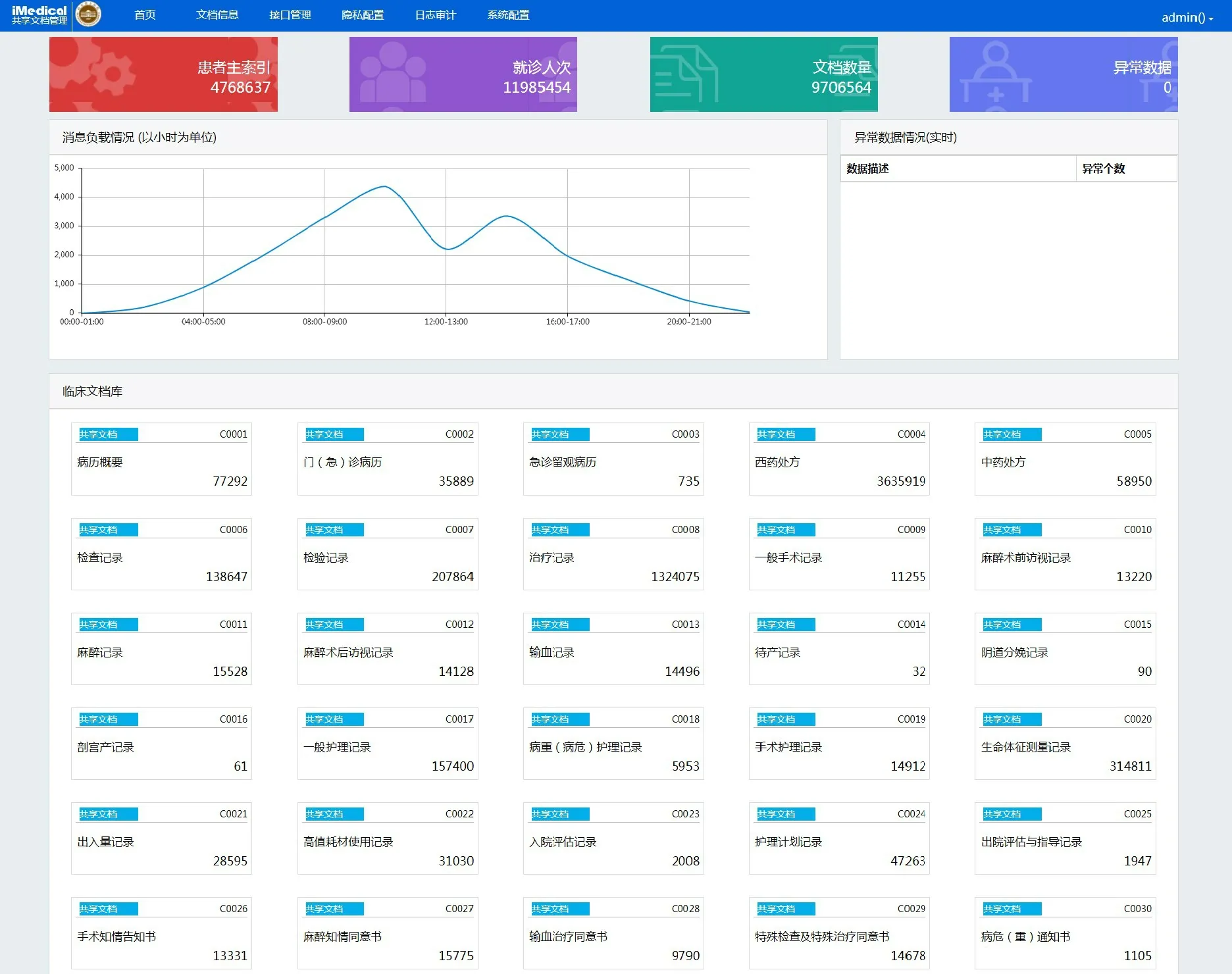
Fig.6 Clinical data center shared document management图6 临床数据中心共享文档管理
5 结语
本文结合山东省立医院信息建设情况介绍了多源异构数据汇聚方法,对后关系型数据、文档型数据、非结构化数据的汇聚提出了解决方案。采用增量时间戳、CDC、WebService 结合ETL 技术进行增量抽取,对临床异构多源数据进行增量汇聚及优化。阐述数据标准化清洗、数据抽取实现过程。整合了从患者入院到出院整个诊疗过程中产生的所有医疗数据。系统还存在一些不足,如在Caché数据库中部分业务数据以global 节点存储,未映射到关系表,ODBC 连接方式无法获取数据等。后续将从二次开发角度增加数据可视化,提供对外访问,提高对半结构化数据的语义分析能力。
猜你喜欢
客联(2022年3期)2022-05-31
趣味(语文)(2021年9期)2022-01-18
中国新闻周刊(2021年26期)2021-07-27
河北理科教学研究(2021年4期)2021-04-19
数学小灵通·3-4年级(2020年9期)2020-10-27
计算机教育(2020年5期)2020-07-24
信息安全研究(2016年4期)2016-12-01
中国卫生(2016年10期)2016-11-13
中国卫生(2015年10期)2015-11-10
