
基于多波束前视声呐的水下静态目标的探测识别技术
2021-03-08 14:43乔鹏飞覃月明
数字海洋与水下攻防 2021年1期
乔鹏飞,邵 成,覃月明
(中国船舶重工集团有限公司第七一〇研究所,湖北 宜昌 443003)
0 引言
水下目标的检测、识别和跟踪是近年来的研究热点之一,其应用非常广泛,包括海床的建模与绘制、海上打捞与救助、海底管道探测等方面,在军事上可用于水雷、潜艇、UUV等水下目标的探测和跟踪,具有重要的军事战略意义。水下目标一般可通过声呐设备探测,其利用目标对声波的反射形成图像。现有的声呐设备主要包括前视声呐[1]、侧扫声呐[2]和合成孔径声呐[3]3种:侧扫声呐和合成孔径声呐通常用来采集航行器左右两侧下方的海底图像,具有分辨率高、覆盖范围广的优点,但其在航行器的正下方存在一定的视野盲区;前视声呐安装在水下航行器的头部,可以采集航行器前下方的图像数据,常用于水下航行器的自主避障和补充侧扫及合成孔径声呐的盲区间隙。
传统声呐图像识别技术的关键在于特征的提取、匹配,如水下目标的形状、纹理等特征,然而由于声学图像成像质量差、对比度低、边缘模糊、海洋环境复杂以及水下目标的多变,这类方法已经无法满足水下目标检测和识别的要求[4]。近年来,随着人工智能技术的发展,基于深度学习的方法被广泛应用到目标检测中,并发展出一系列的检测模型,这些模型可以自动学习图像中丰富的分层特征[5],在光学图像检测领域中取得巨大成功。本文将目标检测模型YOLOv3[6]引入声呐图像的检测任务中,验证算法的可行性和高效性。
1 算法概述
1.1 声呐图像预处理
多波束声呐图像普遍存在分辨率低、噪声和旁瓣干扰严重[7]等特点,增加了探测识别的难度,需要尽可能地滤除噪声并增强图像的对比度;且多波束前视声呐直接输出的数据是一个M行N列的矩阵,是航行器前方扇形区域以距离—方位为二维极坐标的回波强度信号,如图1(a)所示。横坐标为波束个数N,纵坐标为采样点个数M,每一个方格都代表一个回波点,我们需要把二维极坐标的回波强度数据在笛卡尔坐标系下显示才能更好地表示扇形扫描区域内目标的特征与分布,如图1(b)所示。
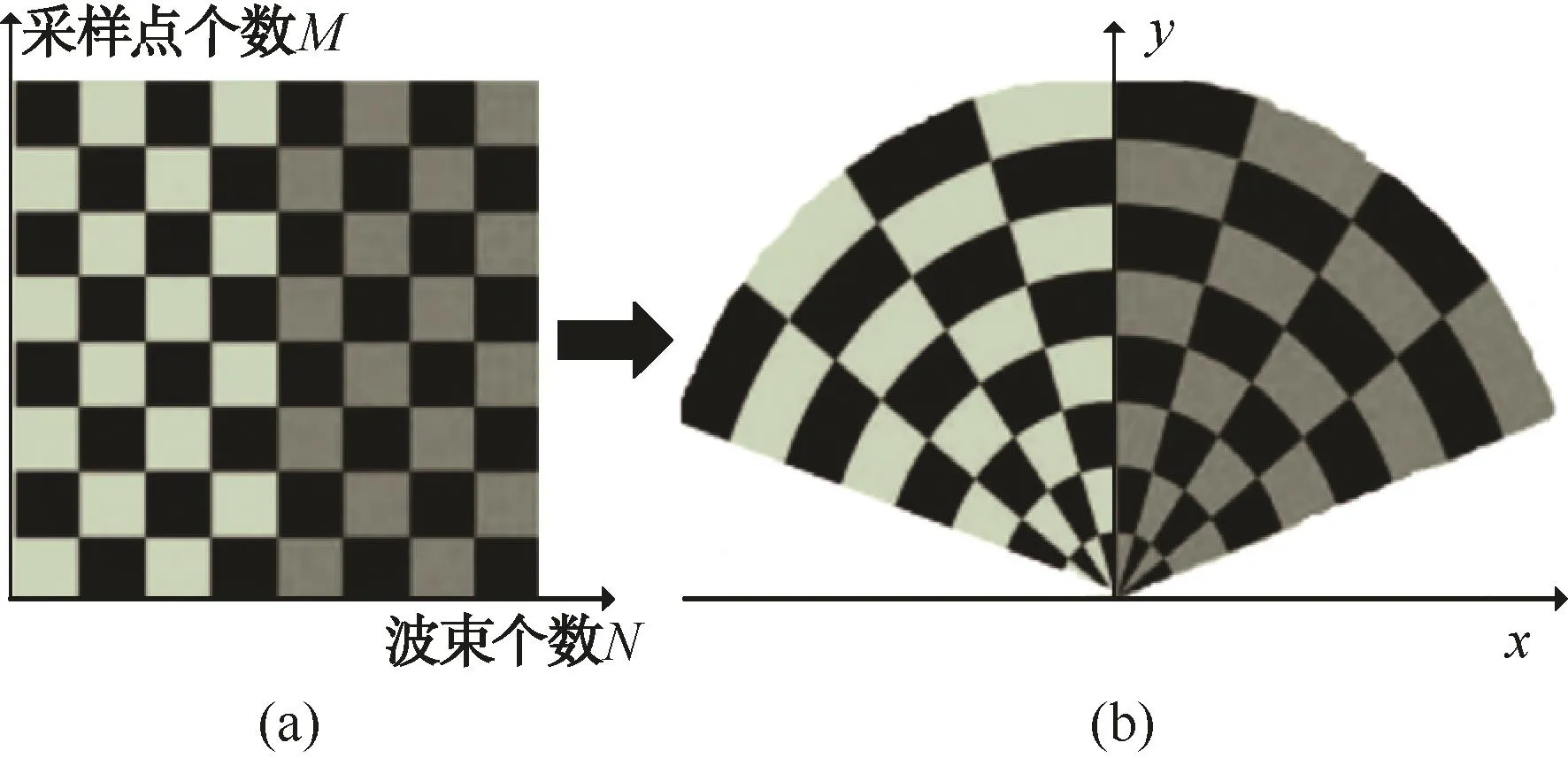
图1 坐标系变换示意图Fig.1 Schematic diagram of coordinate system transformation
1)极坐标系转换为笛卡尔坐标系。设多波束前视声呐水平视角为α,波束数为N,采样点数为M,采样间隔为 T,水中声速为 c,假设声呐的二维可视区域关于y轴对称,极坐标系的原点和笛卡尔坐标系的原点重合,则前视声呐的二维可视界面模型如图2所示。
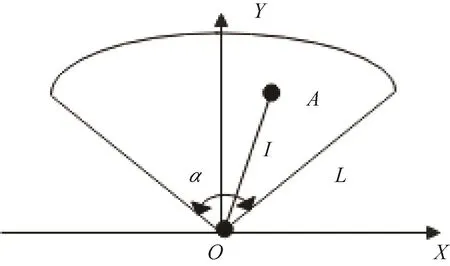
图2 声呐二维可视界面模型示意图Fig.2 Schematic diagram of two-dimensional visual interface model of sonar
现有一点A位于声呐成像矩阵的m行n列,则该点在极坐标系下的坐标为
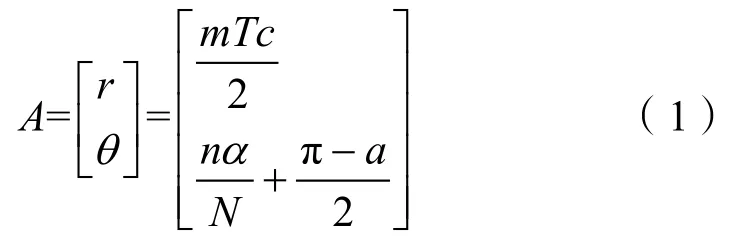
A点在笛卡尔坐标系下的坐标为
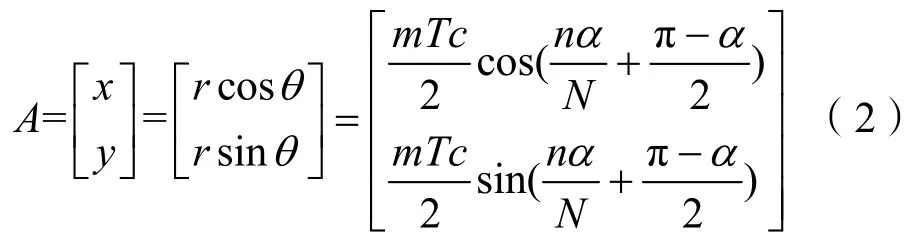
通过坐标系的装换,则极坐标系下的回波点(r,θ)的强度就可以采用笛卡尔坐标系下(x,y)的强度值进行表示,但对比图1(a)和图1(b),可以发现在角度方向,靠近扇形圆心的图形被压缩,远离圆心的图形被拉伸,这会导致图像中出现“空洞”,需要进行数据插值来填充。本文对比了最邻近插值(INTER-NEAREST)、双线性插值(INTERLINEAR)、双立方插值(INTER-CUBIC)、Lanczos插值(INTER-LANCZOS4)4种算法的图像效果,发现INTER-LINEAR、INTER-CUBIC、INTER-LANCZOS4的图像效果相似,且都比INTERNEAREST好,但INTER-LINEAR算法的效率更高,所以本文采用双线性插值算法填充图像。
2)声呐数据中携带的噪声大部分是由海底或海面反射、水中的水汽或漂浮物影响等产生,大部分属于椒盐噪声,本文采用中值滤波的方法去除噪声,其能够在平滑图像的同时,尽量减少图像细节信息的损失,是一种简单有效的滤波降噪方法。
3)本文采用动态亮度分配的方法增强图像的对比度。动态亮度分配[8]是将回波强度映射到线性灰度[0,255]的过程,可以通过优化映射函数增强目标与背景之间的对比度及图像的亮度,其映射函数如公式(3):
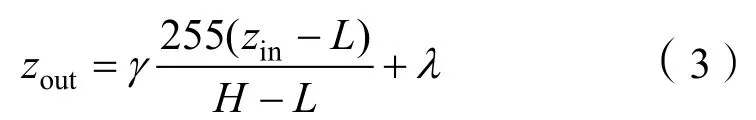
式中:L为图像回波强度的最小值;H为图像回波强度前10%的平均值;zin为输入的回波强度值;zout为输出的灰度值;γ为映射参数,用于增加图像的对比度;λ为映射参数,用于增加图像的亮度。
1.2 YOLOv3模型检测目标
YOLO(You Only Look Once)是一种基于回归思想的CNN目标检测模型,其经历了YOLOv1、YOLOv2和YOLOv3共3个版本的改进,目前已经发展到YOLOv4。YOLO系列与之前的检测模型不同,其不需要提取图像中目标候选区域,而是直接对整幅图片进行回归训练,拥有更高的运行速度(40帧/s),可以满足声呐识别的实时性要求。
虽然YOLOv4的识别精度与YOLOv3相比有了稍微的提升,但其网络更复杂,计算耗时更长,并且YOLOv3具有C语言版本,程序运行更快、更稳定,适合于工程实际运用,所以本文采用YOLOv3进行探测识别。YOLOv3的网络结构如图3所示:其中 DBL组件为网络的基本单元,由卷积层、批归一化和激活函数构成;resn表示res模块中含有 n个残差单元。YOLOv3结合残差网络ResNet[9]中的跳跃连接和特征金字塔网络(Feature Pyramid Networks,FPN)等算法思想,用步幅为2的卷积层替代池化层完成对特征图的下采样,同时在每个卷积层后增加批量归一化操作(Batch Normalization,BN)[10],并使用激活函数 LeakyRelu来避免梯度消失及过拟合,最终形成53层的骨干网络DarkNet-53来提取图像的分层特征。在对目标物体进行分类时,其使用多个独立的逻辑回归分类器,这些分类器对于目标边框中出现的物体只判断其是否属于当前标签,即简单的二分类,这样便实现了多标签分类。
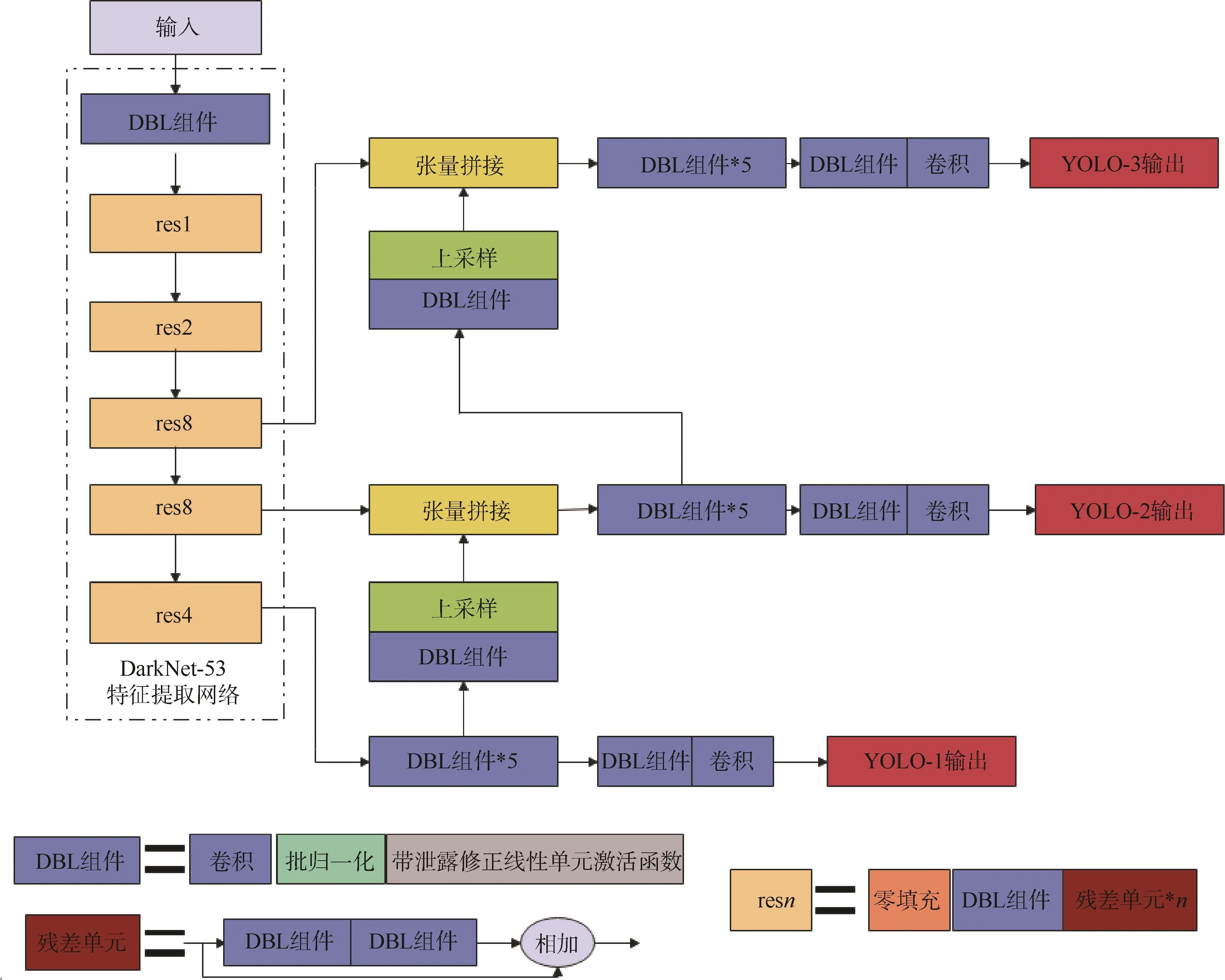
图3 YOLOv3的网络结构图Fig.3 Structure diagram of YOLOv3 network
在利用 YOLOv3训练模型及检测目标时,其输入的图片都需要有固定的尺寸(416×416),然而采集到的扇形声呐图片一般都不符合这个尺寸(本文的声呐图像为2 600×1 300)。如果我们直接对大的声呐图片进行缩放会导致图片模糊及损失一定的特征信息,所以本文对声呐图片进行了切片,如图4所示将一张声呐图片分成10份,并确保每一张切片与相邻的切片有部分的重合区域,以防止将目标区域分开。并且如果切片后仍不符合YOLOv3模型的输入尺寸,则可以直接对图片进行缩放,因为切片后的图片已经接近于YOLOv3的输入尺寸,直接进行缩放导致的图像损失较小,对识别的影响可忽略不计。如果是较大目标,虽然切片时可能会将其分开,对识别造成影响,但由于基于深度学习的方法在学习图像的特征时,学习的是图像的本质特征,将目标分开这一因素对目标的本质特征影响不大,并且目标在声呐图像的显示中所占的像素较少。本文切片时还预留了重叠区域,目标分开的概率较小,所以将较大目标切开对识别的影响不大。
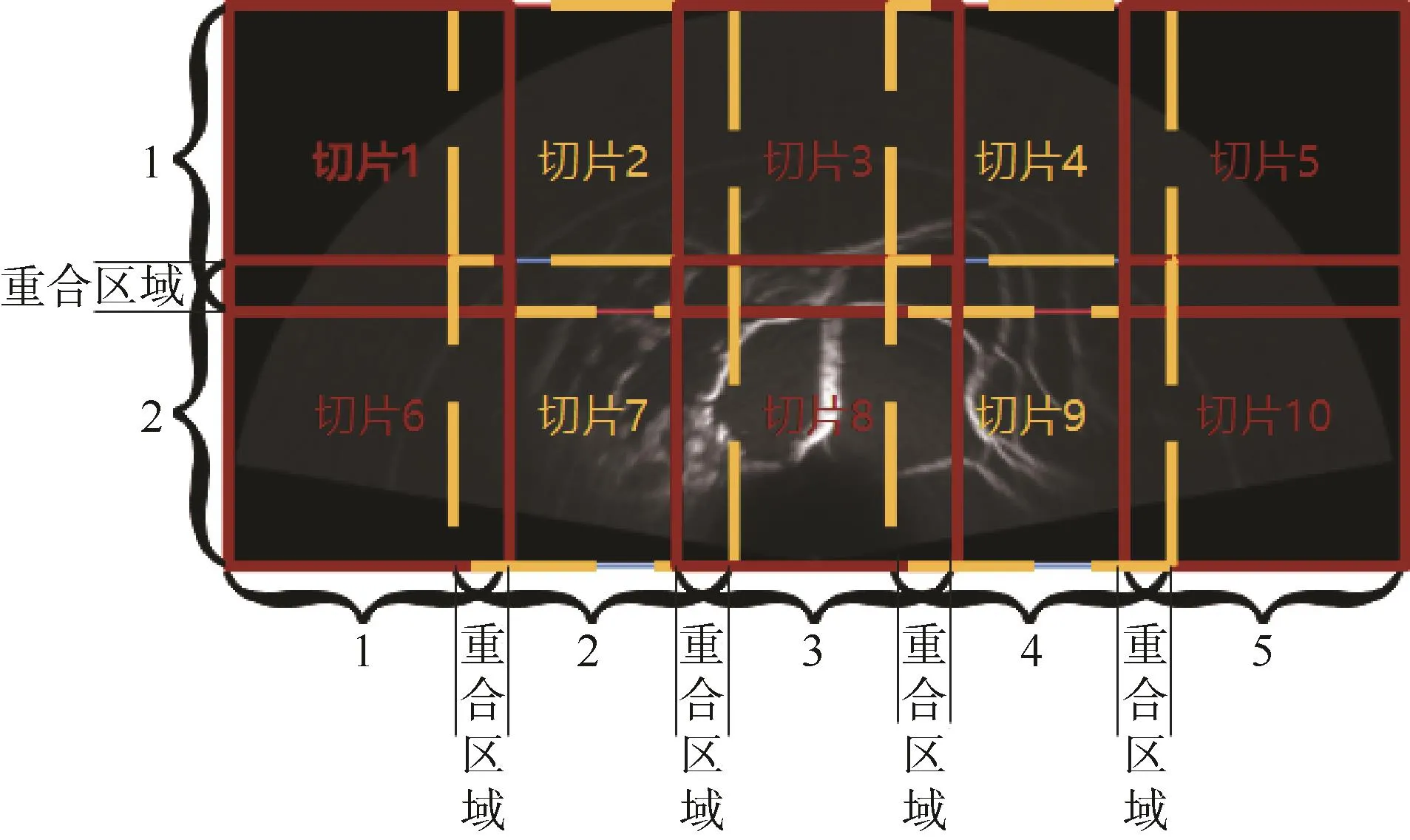
图4 声呐扇形图像的切片示意图Fig.4 Slice diagram of fan-shaped sonar images
1.3 声呐图像序列检测目标
试验表明,将基于卷积神经网络的 YOLOv3模型运用在声呐图像的目标检测中具有很高的识别率[4],但YOLO系列算法的基本思想:将输入图像看成一个S×S的栅格,若某个目标的中心位置落在一个栅格内,那么这个栅格就负责检测这个物体,如图5所示。图中某个目标的中心点(红色原点)落入第4行、第3列的格子内,则这个格子负责预测该目标,即每个栅格只能用来检测一个目标,所以如果一个栅格内存在多个小目标,则可能存在误检。
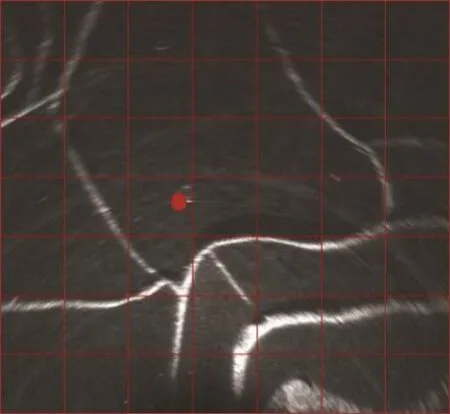
图5 YOLOv3检测示意图Fig.5 Schematic diagram of YOLOv3 detection
本文设计了一种降低误检率的方法,基本原理如下:首先,在单帧图像中利用 YOLOv3检测目标,将检测出的目标作为疑似目标并根据水声定位计算其经纬度;然后判断后续的4帧图像序列中该经纬度处是否都具有 YOLOv3检测的目标,如果是,则将该目标判断为正确目标,反之,则为虚假目标,图6为算法的流程图。计算疑似目标的经纬度方法如下:首先根据系统中的水声定位仪器我们可得声呐的经纬度;然后按式1、2可将图像中检测出的疑似目标的位置(x,y)转换成距离-方位形式(r,θ),则就可根据目标距声呐的距离和方向及声呐的经纬度推算出目标的经纬度。
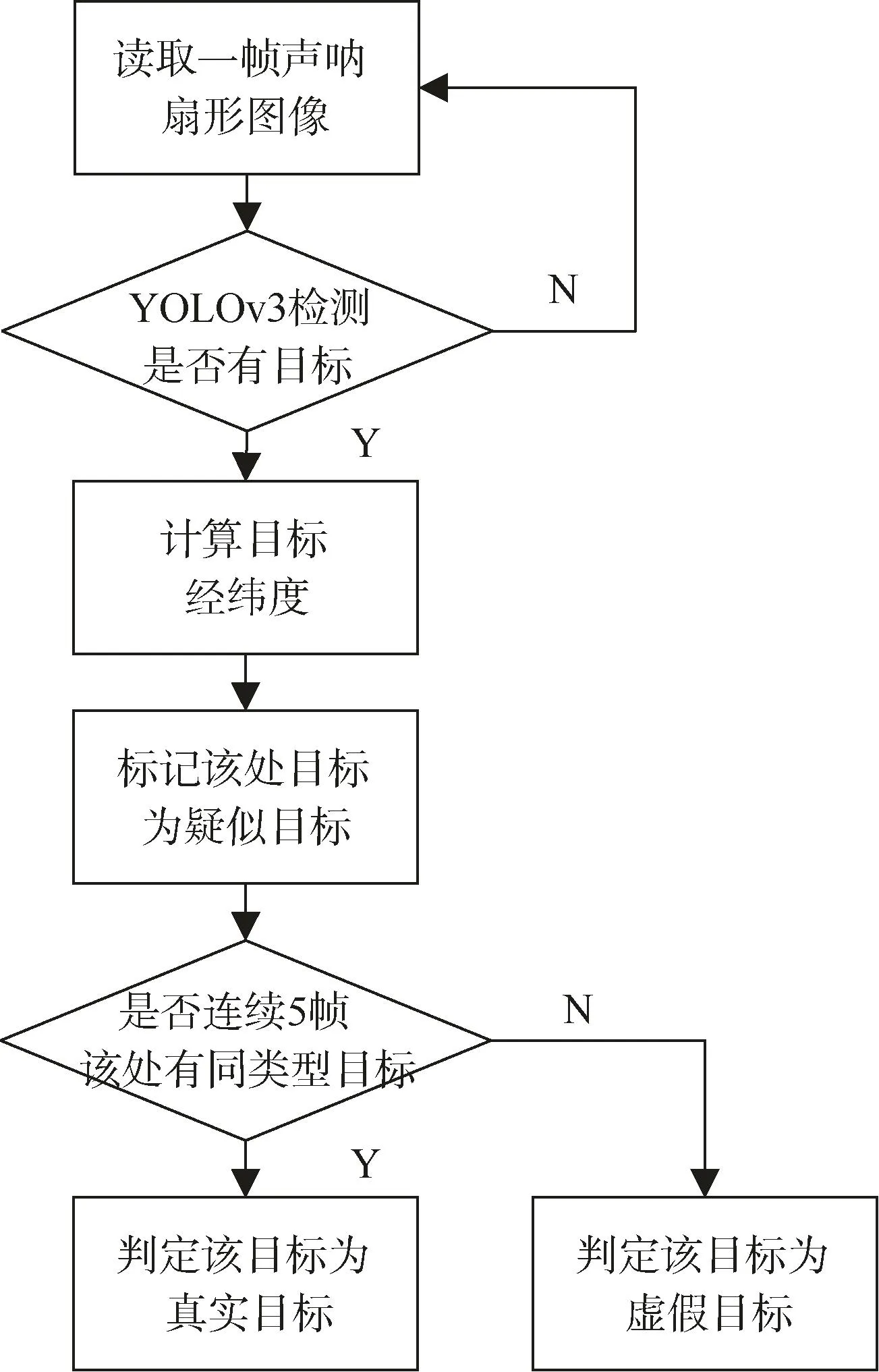
图6 算法流程图Fig.6 Algorithm flowchart
2 实验结果
本实验使用保利天同科技公司的400 d多波束前视声呐探测水下静态目标,整个探测系统如图7所示,其将声呐安装在拖鱼的头部,并采用船载拖曳式的方法拖动拖鱼。我们利用该探测系统在水库和海域采集了 2组数据用于训练 YOLOv3模型和评估算法的有效性。

图7 水下探测系统示意图Fig.7 Schematic diagram of underwater detection system
2.1 声呐图像预处理实验
图8左右2幅图分别为采用中值滤波前后的对比图,其滑动窗口大小为 5×5,从图中可看出椒盐噪声得到了去除,且保留了图像的边缘信息。图9为映射参数γ=0.4,0.6,0.8,1及γ=0时的声呐扇形图像,从图中可以看出随着γ的减小,目标和背景的对比度不断增强,但当γ=0.4时,过大的对比度又损失了部分细节,因此选择映射参数γ=0.6对图像进行预处理。

图8 中值滤波前后对比图Fig.8 Comparison diagram before and after median filtering

图9 对比度增强效果图Fig.9 Effect diagram of contrast enhancement
2.2 探测识别实验
本实验的待测目标为球形目标(globoid,GL)和圆柱形目标(cylinder,CY)2类,通过改变目标的位置及从多个方向进行探测,共采集了1 000张具有目标的声呐图片,利用图4所示的切片方法将所有的图片共分成了 1 000×10张图片,其中具有目标的图片有1 600张,对其中的1 000张图片利用Labelimg标注组成训练数据集,剩下的600张图片组成测试数据集。本文采用YOLO官网提供的基于C语言开发的YOLOv3模型,使用搭配 NVIDIA 2080显卡、CUDA9.0的计算机进行训练和测试。图 10展示了对声呐图像的检测结果示例,图中的目标是将切片的检测结果转换到整幅图像中进行标记显示的,可以看到在背景噪声较大的情况下,YOLOv3模型仍能够准确检测出目标。

图10 YOLOv3探测结果示例图Fig.10 Sample gram of YOLOv3 detection result
表1展示了第2 791~2 795帧图片的YOLOv3检测结果,可以看到第2 791和2 792帧中一共检测到3个目标,但通过计算图中3个目标的经纬度,且与布放目标时记录的经纬度比较,可以确定第1个目标(从上往下排列)为虚假目标,而我们通过查看第2 793~2 795帧的检测结果,可以发现第1个目标都没有被检测到,因此可以判断第1个目标为虚假目标,其与真实情况相同。
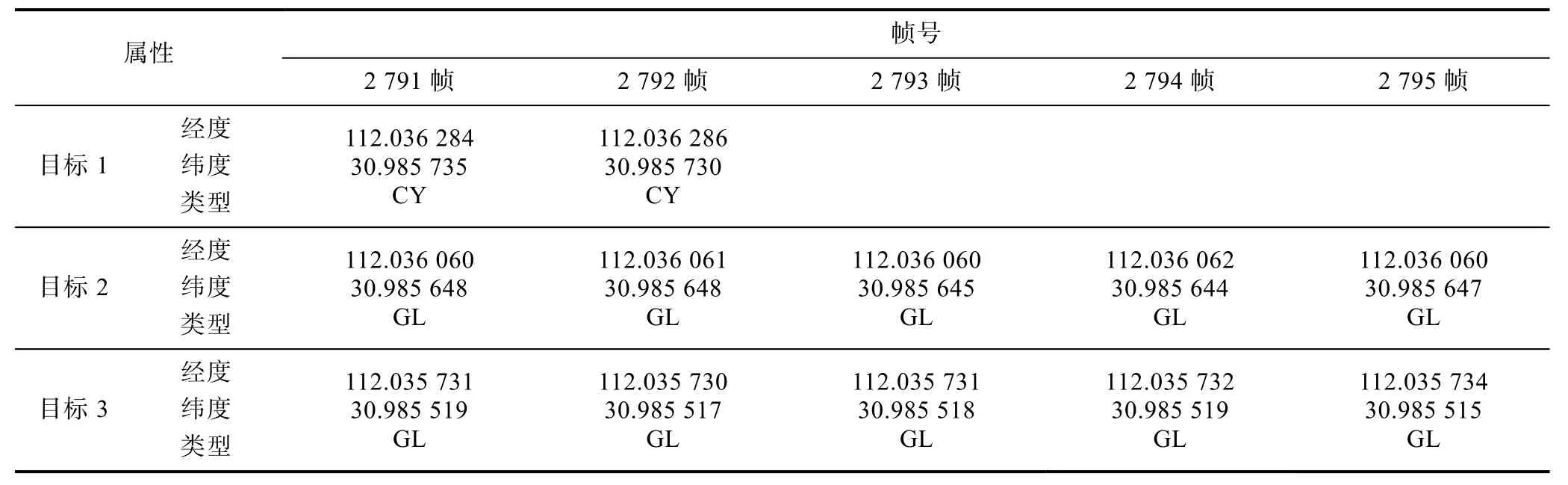
表1 第2 791~2 795帧检测结果Table 1 Detection results of picture frame 2 791-2 795
为了验证所提算法的高效性,文中引入了支持向量机(SVM)结合方向梯度直方图特征(HOG)的识别方法,HOG通过计算和统计图像局部区域的梯度方向直方图来构成特征,HOG 特征结合SVM分类器是经典的传统图像识别算法。3种算法的试验对比结果如表2所示,其中识别率为600张测试图片中正确识别个数所占的百分比。从表中我们可以看到:采用 YOLOv3的识别率明显高于传统的 HOG+SVM方法,并且加入去除虚假目标方法后,YOLOv3的识别率又得到了提高;在检测速度上,YOLOv3检测一张完整的声呐图片只需要0.63 s,几乎比HOG+SVM快了一倍。
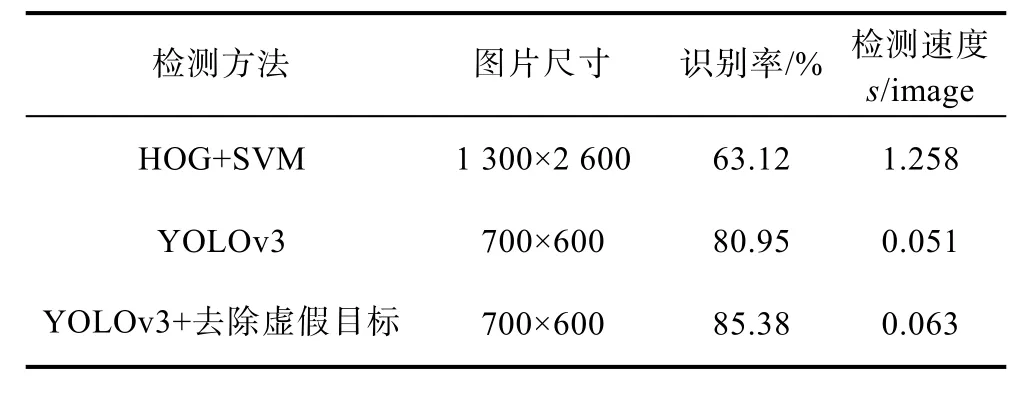
表2 不同方法对声呐图像的检测结果Table 2 Detection results of sonar images by different methods
3 结束语
本文通过中值滤波和动态亮度分配预处理,显著改善了多波束前视声呐的图像质量,为后续的探测识别创造了有利条件;将基于卷积神经网络的YOLOv3模型用于声呐图像的识别,试验结果证明该方法比传统的特征提取方法更高效;对单帧图像中有无目标先不进行判断,而根据图像序列中检测目标的出现次数进行判断,实验表明这样可以降低识别的误检率。本算法不仅可以满足民事上的运用,也可以在军事上运用于水雷和UUV等相似形状的目标探测中,拥有广泛的应用范围。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
科学与财富(2020年15期)2020-07-04
移动通信(2020年4期)2020-05-07
移动通信(2019年4期)2019-06-25
科技资讯(2018年10期)2018-10-26
现代信息科技(2018年4期)2018-07-12
新课程·中旬(2017年1期)2017-03-27
现代兵器(2016年12期)2016-12-22
现代兵器(2016年12期)2016-12-22
环球时报(2016-08-01)2016-08-01
