
基于非局部关注和多重特征融合的视频行人重识别
2021-03-07 05:16刘紫燕朱明成马珊珊陈霖周廷
计算机应用 2021年2期
刘紫燕,朱明成,袁 磊,马珊珊,陈霖周廷
(1.贵州大学大数据与信息工程学院,贵阳 550025;2.贵州理工学院航空航天工程学院,贵阳 550003)
(*通信作者电子邮箱Leizy@sina.com)
0 引言
行人重识别是利用计算机技术判断图像或视频中是否存在特定行人的技术,作为计算机视觉领域中图像检索的子任务,它的目的是解决跨非重叠摄像机之间的行人匹配问题,被广泛应用于智能安防、智能寻人系统、相册聚类和家庭机器人等领域。由于不同相机存在差异,同时行人特征多样复杂,易受穿着、尺度、遮挡、姿态、视角和光照等影响,因此行人重识别成为了一个具有挑战性和研究价值的热门课题。
传统方法主要集中在基于图像的行人重识别上[1],只包含空间特征,缺少时序信息,在复杂条件下的精度不高;视频序列则包含丰富的行人时序特征,因此对视频行人重识别的研究具有重要意义[2-3]。随着基于视频的大规模数据集的出现[4],研究者设计了多种深度神经网络来学习视频的鲁棒表示[5-6]。
在基于视频的行人重识别研究中,经典方法是将视频序列投影到低维特征空间,然后通过计算样本之间的距离来执行身份匹配排序。目前使用卷积神经网络(Convolutional Neural Network,CNN)提取行人特征已经远远优于手工特征方案[7-9]。文献[10]中采用三维梯度方向直方图(3D Histogram of Oriented Gradients,HOG3D)和步态能量图像(Gait Engery Image,GEI)结合CNN 来学习行人子空间下的特征,当对具有遮挡、复杂背景和姿态变化等多种情况的数据集进行特征学习时,运动特征的效果较差;文献[11]中设计了递归深度神经网络(Deeply-Recursive Convolutional Network,DRCN)模型学习视频行人特征,该方法只关注短期时间特征;文献[12]中提出了一种顺序渐进融合模型将人工特征(如局部二值特征(Local Binary Pattern,LBP)和颜色)嵌入到长短时记忆(Long Short-Term Memory,LSTM)网络,虽然融合多种特征,但是对全局特征提取不足,无法有效获取长时间时序特征;文献[13]中提出了两个CNN 流来同时捕获时间和空间信息,由于此模型对图像采取同等关注度而无法处理序列中的遮挡或空间不对齐问题;文献[14]中提出注意力机制结合多粒度特征表示法来对特定空间位置进行聚集获得更好的表示形式,但它们注重局部特征而忽略了全局特征;文献[15]中利用相似性聚合方法对视频片段进行剪辑从而提取出代表性的位置信息,但该方法注重空间特征而忽略了时间特征;文献[16]中对时间特征进行了有效的提取和表示,但着重提取高级特征而忽略了跟中低层特征的融合;文献[17]中提出了一个兼顾全局和局部特征的网络来提取时间特征,但该网络注重高级特征忽略了对中低级特征的提取;文献[18]中采用生成对抗网络对被遮挡行人进行数据增强,存在引入低质量图像的问题;文献[19]中使用自然语义研究中的全局关注机制进行视频行人重识别研究,然而存在使用特征较为单一而无法适应复杂环境的问题。
鉴于现有方法没有深入挖掘视频序列的全局特征和时序信息,本文提出一种基于非局部关注(Non-local Attention)和多重特征融合的网络。主要工作如下:1)在ResNet-50残差网络中嵌入多层非局部关注块提取全局时空特征;2)在主干网络的中间层和全连接层提取中低级特征和局部特征,在特征池化阶段进行多重特征融合获取鲁棒性强的特征表示。本文提出的网络能有效提取视频连续帧之间的时空信息,充分利用全局特征、局部特征和中低级特征的信息,可以有效缓解单一特征带来的适应性差的问题。
1 非局部关注和多重特征融合网络
图1 是本文提出的非局部关注和多重特征融合网络结构示意图,主体网络为嵌入非局部关注块的ResNet-50 残差网络,用以提取全局特征;在主体网络的第二残差层(Res2)和全连接层(Fully Connected layer,FC)引出两个特征提取分支,分别提取低中级特征和局部特征;经过多重特征融合将中低级特征和局部特征输入到全局特征中融合得到行人显著特征,通过特征池化后,对整个行人特征进行相似性度量和排序;最后对待测行人进行身份预测,计算出视频行人重识别的精度。
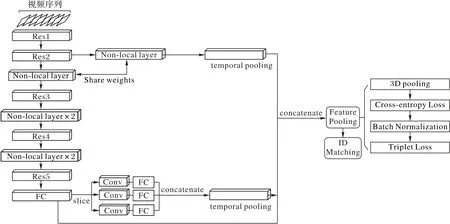
图1 基于非局部关注和多重特征融合网络示意图Fig.1 Schematic diagram of network based on non-local attention and multi-feature fusion
1.1 非局部关注
计算机视觉中非局部关注是一种全局注意力机制,被用来捕获长距离依赖信息,即建立视频帧之间的联系,不孤立学习单个图像的特征[19]。非局部关注在计算某个位置的响应时考虑到所有时空位置特征的加权,因此本文提出的网络模型采用嵌入的非局部关注块对连续视频帧进行特征提取。
根据非局部关注的定义,在深度神经网络中的非局部关注操作可用下式表示:

其中:x表示输入序列(特征),y表示输出特征;f(xi,xj)表示对于某一特定位置i对所有可能关联的位置j之间的关系函数,反映了位置i和j之间联系;g(j)表示在位置i处输入的特征值;c(x)表示归一化参数。根据式(1)可知,非局部关注是一种全局注意力机制,是当前特征输出与任意时空的综合关系的输出。由于输入值xi和xj之间的关系会影响最终输出,因此非局部关注要对位置相关性进行学习。
为了将非局部关注块嵌入到ResNet-50主体网络中,将非局部关注的操作表示为:

其中:Wz表示的是权重矩阵,zi表示非局部关注经过残差连接的输出,+xi表示的是残差连接。
图2 显示的是一个非局部关注块,其中特征图以张量形式表示,1 024 表示通道数,⊗表示矩阵乘法,⊕表示元素求和,激活函数采用softmax 函数。由于原始非局部关注块计算量很大,使用稀疏化计算技术将图中Wg、Wθ、Wφ的通道数相对输入通道数减为一半(1024 →512),最后将Wz放大至输入通道数以保证输入输出的尺寸一致。
给定的从一系列大小为C×H×W的T个特征图获得的输入特征张量X∈QC×T×H×W,按照非局部关注的要求在所有空间位置和帧之间的特征中交换信息。假设从输入X采样得xi∈QC,那么经过非局部关注的相应输出yi的公式如下:

其中:i、j∈[1,T×H×W]表示特征图上全部位置和所有视频帧。如图2,首先通过使用线性变换函数(1× 1× 1的卷积)将输入X投影到低维的嵌入空间QClow;然后通过使用嵌入式高斯实例化,计算所有xj位置的加权平均值来得出每个位置xi的响应;最终输出Z=WzY+X,其输出为原始特征张量X加上通过卷积Wz(1× 1× 1 的卷积)将Y映射到原始特征空间QC。
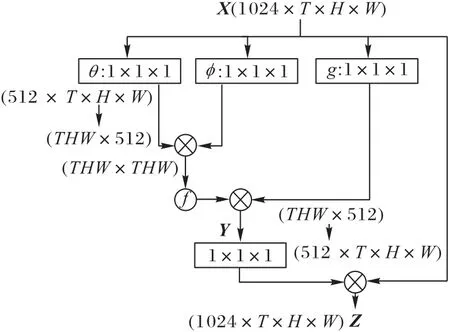
图2 非局部关注块Fig.2 Non-local attention block
经过上述设置将非局部关注块嵌入到ResNet-50 的任意层中,根据输入视频帧的长度来提取相应长度的帧间时序信息。非局部关注块可以灵活嵌入到网络中,同时能在长序列视频下提取长时间的特征信息,比LSTM 等应用循环或递归神经网络的模型更能对视频帧信息做到全局关注。
非局部关注对长时间的帧间信息进行特征提取,能有效避免个别图像中出现遮挡、光照、角度偏移等问题。对于视频来说,连续变化的图片会将同一行人的不同状态下的特征保留在帧间信息即时序信息中,非局部关注可以有效提取全局时序信息,这恰好解决了行人重识别存在的遮挡、光照、视角等问题。
1.2 多重特征融合
上述非局部关注块提取的是全局特征,由于单一的行人特征无法较好提升行人重识别的精度,因此本文提出一种多重特征融合网络对多个特征进行融合以获取显著的行人特征。本文在行人重识别网络中设置两个特征提取分支,分别提取低中级特征和局部特征。完整的多重特征融合网络如图3所示。
低中级特征提取层位于Res2 下的非局部关注层(Nonlocal Layer)之后经时间池化层进入特征融合阶段;局部特征提取层位于全连接层后,通过将特征切分成三部分经卷积层、合并层(Concatenate Layer)和时间池化层后进行特征融合。两个特征提取分支与非局部关注主体网络提取出的多重特征通过加法拼接和特征池化完成特征融合。
需要注意的是,在局部特征提取层上采用切片法将视频帧中的行人均分为上中下三部分,经过卷积层和全连接层进行局部特征映射;最后通过合并层将三部分特征进行组合。池化层采用最大池化尽可能减少纹理信息受卷积层参数误差的影响;激活函数采用ReLU 函数避免梯度消失和梯度爆炸问题。
对于长度l一定的视频序列Vin,经过局部特征层可得,然后经平均时间池化层得到flocal(vin)=;在低中级特征提取时同样经过平均时间池化层为;经过整个主体网络,则得到;最后将三者进行特征拼接,本文采用加法拼接进行融合,得到最终特征表示ffinal(vin)=flocal(vin)+flm(vin)+fnonlocal(vin)。
利用多重特征融合,对全局特征、局部特征、高级特征和中低级特征进行融合。由于不同的摄像机在不同的时间拍摄的行人视频具有复杂多变的特性,靠单一特征进行重识别容易出现识别性能参差不齐的情况,通过多重特征融合可以提升适应性和重识别精度。
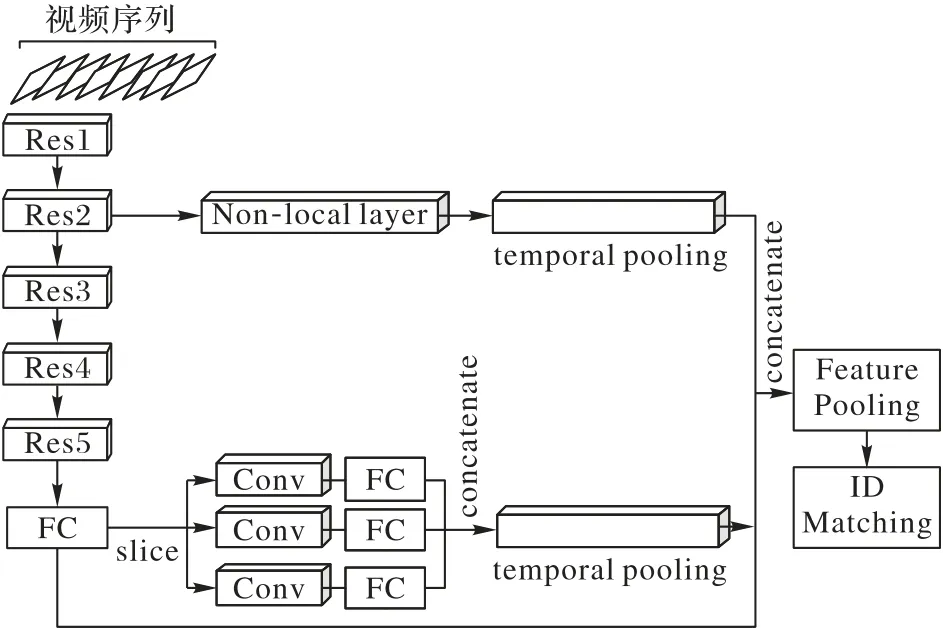
图3 多重特征融合网络示意图Fig.3 Schematic diagram of multi-feature fusion network
1.3 网络架构
本文的网络架构主要由数据预处理、非局部关注网络、多重特征融合网络、特征池化和行人身份排序五个部分组成。
1)数据预处理:通过随机抽样方法[12]选择视频帧的子集,然后通过非局部关注网络和特征池化进行特征提取得到特征向量。将给定输入视频Vin划分为相等长度的K个块{Ci}i=[1,K],训练时在每个块中随机抽取一个图像;测试时使用每块的第一个图像作为测试。所有训练视频序列由采样帧的有序集合表示{Ii}i=[1,K]。
2)非局部关注网络:本文设计的主体网络中共嵌入了5层非局部关注块,具体嵌入形式如图4 所示,其中非局部关注块有大小两个尺寸,设计大小根据输入的视频长度进行变化。本文设计的网络按16 帧和8 帧大小切分视频,通过对于长短连续视频帧的特征提取,获取短时间和长时间两种维度的特征信息,保证时序特征的多样性。这种做法通过将大尺寸分成两个小尺寸可以明显减少计算量,而保留两个大尺寸是为了提取较为完整的全局特征。
3)多重特征融合网络:本文采用的特征融合网络使用合并(Concat)融合策略,属于早融合(Early Fusion)策略,即对不同特征进行拼接形成最终的行人显著特征。由于全局特征属于主要特征,低中级特征和局部特征属于旁支特征,因此为体现其所占比重,在特征维数上对三种特征进行设计,全局特征维数占最终特征的1/2,中低级特征和局部特征各占1/4。
4)特征池化:融合特征沿时空维度应用3D 平均池化,将每个视频帧的融合特征聚合到一个代表性的矢量中,然后进行批处理归一化(Batch Normalization,BN)以及共同优化的交叉熵损失和难例挖掘三元组损失来训练网络。相关研究[20]表明,在BN层之前进行三元组损失优化,在BN层之后采用交叉熵损失优化会产生最佳的行人重识别性能。没有归一化的嵌入空间更适用于三元组损失这样的距离度量学习;归一化的特征空间使模型在交叉熵损失下分类[21]效果好。
5)行人身份排序:该部分主要对基于查询集和图库集的身份(Identity,ID)间距离的相似性分数进行排序,本文采用计算马氏距离来对行人进行排序。通过计算累积匹配特征曲线和平均精度均值来获得重识别精度。
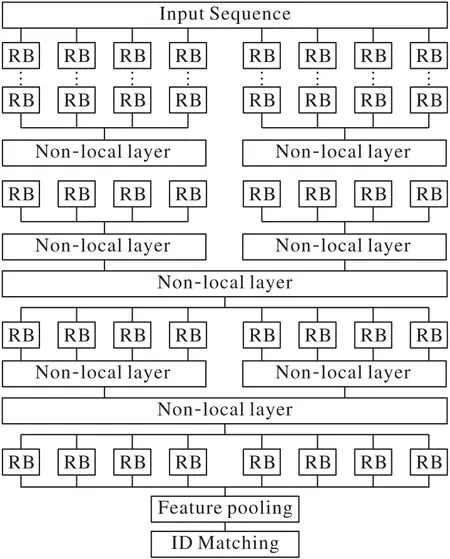
图4 非局部块嵌入形式图Fig.4 Non-local block embedding form diagram
1.4 损失函数
交叉熵损失函数(Cross-entropy Loss)作为行人重识别领域的常用损失函数,是一种利于分类网络进行标签置信度排序的函数,其中概率分布采用softmax 激活函数来计算。该损失函数的一般公式为:
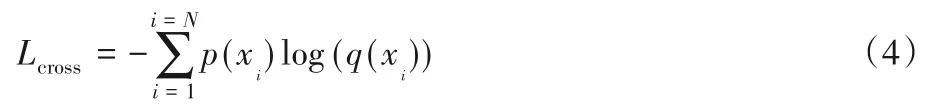
其中:i表示身份ID 标签序号,p(xi)表示真实概率,q(xi)表示预测概率。
难例挖掘三元组损失函数是通过对样本空间中的正样本对进行聚合、负样本对进行推离来进行优化的,一般公式为:
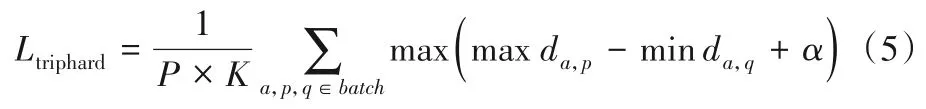
每输入一个批次的视频帧时,随机挑选P个ID 的行人,每个行人中随机挑选K张不同视频帧,则每个批次有P×K张。对于该批次中每个视频帧,挑选一个最难的正样本p和最难的负样本q与a构成一个三元组,α是阈值。难例挖掘损失函数通过计算a和同一批次中其他视频帧的欧氏距离,选出与a距离最远的正样本p和距离最近的负样本q来计算三元组损失。
最终的损失函数是对以上两项损失函数进行组合,其表达式为:

2 实验结果与分析
本文的实验平台采用Ubuntu16.04 操作系统,NVIDIA TITAN V100 显卡的硬件环境,使用预训练的ResNet-50 分别在三个视频行人重识别数据集上进行实验。设定视频序列长度L为8,并按此长度分割整段序列,长度不够的视频段舍去。每帧大小按照数据集的不同分为128× 64和256 × 128两种。实验以ImageNet 图像数据集预训练ResNet-50,使用交叉熵损失和难例挖掘三元组损失函数,采用Adam 优化器。初始学习率为1× 10-4,每隔50 个epoch 衰减0.1,总批次为300 个epoch。
2.1 标准数据集与评价指标
PRID2011数据集[22]包含934个身份共1 134段视频序列,由两个摄像机采集数据,平均长度为5 到675 帧之间,其中200 个身份同时出现在两个摄像机内。该数据集在视角、光照和背景上有明显差异。
MARS 数据集[4]包含1 261 个身份,总计17 503 个轨迹和3 248 个干扰轨迹,由6 个摄像头采集数据。625 个身份用于培训,636 个身份进行测试,每个身份平均有13 个视频轨迹,平均帧数为59帧。
DukeMTMC-VideoReID 数据集[5]是DukeMTMC 数据集的子集,总计1 812 个身份,702 个用于训练,702 个用于测试,408 个作为干扰,共有2 196 个视频用于训练,2 636 个视频用于测试,每个视频包含每12帧采样的人物图像。
本文在PRID 2011、MARS 和DukeMTMC-VideoReID 三大公共视频数据集中进行训练与测试,主要参数如表1所示。

表1 三大视频行人重识别数据集Tab.1 Three video person re-identification datasets
视频行人重识别主要使用累积匹配特征(Cumulative Match Characteristic,CMC)曲线和平均精度均值(mean Average Precision,mAP)作为评价指标,两者值越大表明精度越高。
CMC 曲线是表示top-k的击中概率的曲线,指在候选库(Gallery)中检索待测试行人,前k个检索结果中包含正确匹配结果的概率。Rank-k表示在前k个候选匹配目标中存在待测试行人的概率。通常CMC 曲线由Rank-1、Rank-5、Rank-10、Rank-20 来表示,其中Rank-1 表示真实的识别能力。CMC的表达式可以如下表示:
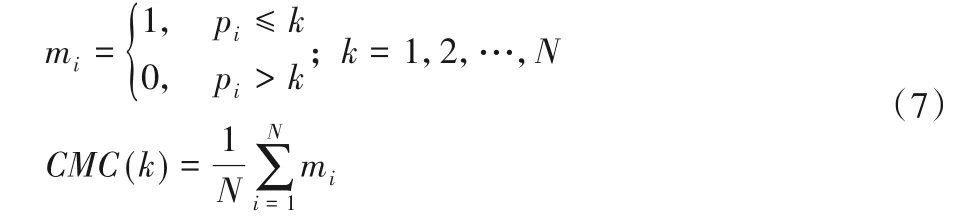
其中:给定候选集M中有N个行人,k表示前k个候选目标,pi表示查找集中行人在候选集中匹配正确的位置序号(即pi≤k表示能在前k个目标中匹配正确)。
mAP 是计算所有查询中平均精度的平均值,对于每个查询,其平均精度(Average Precision,AP)是从其精度调用曲线计算得出的。mAP 可以反映模型的评测精度的稳定性。AP和mAP的表达式为:

其中:i表示查询图像的序号,p(i)表示第i序号图像在全体图像中比例,r(i)表示i号图像与待识别图像匹配特性(正确为1,不正确为0);m表示与待识别图像匹配的个数;C表示待识别图像的个数。
2.2 本文方法分析
本文实验首先对提出的非局部关注块和多重特征融合网络在视频行人重识别的数据集上使用效果进行测试,其中,NLA(Non-Local Attention)表示非局部关注块,MLF(Multi-Layer Feature)表示多重特征融合。
根据图5 和图6 显示的本文方法在数据集MARS 和DukeMTMC-VideoReID 上帧级ID 损失趋势图可以明显看出,加入非局部关注块和多重特征融合可以降低损失值并且损失降低速率加快,在两个数据集上都比原始网络快30 至40 个epoch;此外可以发现加入非局部关注块在降低损失值方面更加明显。
表2 给出了在两个数据集上使用基本网络和加上非局部关注块、多重特征融合的改进网络输出的Rank-k和mAP 的值。在MARS 数据集上:当加入非局部关注块时,Rank-1、mAP分别提升3.6个百分点和3.8个百分点;当加入多重特征融合时,Rank-1、mAP分别提升2.5个百分点和1.4个百分点;当加入两种功能时,Rank-1、mAP 分别提升6.2 个百分点和7.2 个百分点。这说明非局部关注块对精度的提升作用优于多重特征融合,同时当两种功能都采用时精度提升明显。在DukeMTMC-VideoReID 数据集上,当分别加入非局部关注块和多重特征融合时,Rank-1、mAP 分别提升4.3 个百分点、5.3个百分点和3.5 个百分点、4.4 个百分点,这表明所提方法具有普适性,在不同视频数据集上精度都有明显提升。
因此在视频行人重识别上,本文所提网络可以明显加快重识别时收敛速度,更快捷地获取行人显著特征;同时,非局部关注块对精度提升由于多重特征融合,说明非局部关注对视频行人重识别有明显的提升精度价值。
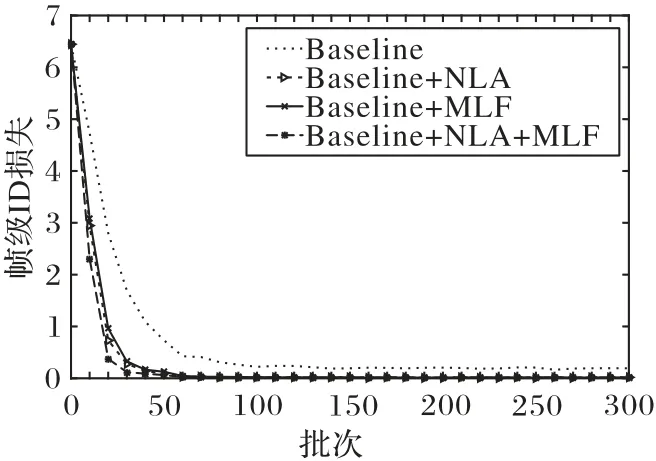
图5 MARS数据集上帧级ID损失Fig.5 Frame-level ID loss on MARS dataset
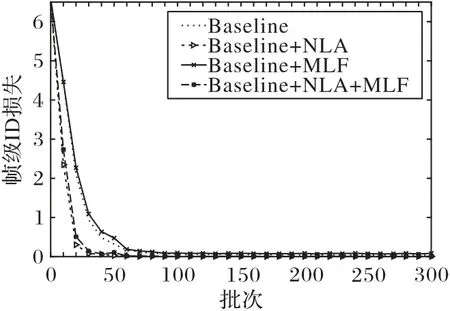
图6 DukeMTMC-VideoReID数据集上帧级ID损失Fig.6 Frame-level ID loss on DukeMTMC-VideoReID dataset

表2 含不同模块的基本网络在MARS和DukeMTMC-VideoReID数据集上的实验结果 单位:%Tab.2 Results of the baseline network with different modules on MARS and DukeMTMC-VideoReID datasets unit:%
2.3 与其他模型比较
本文模型与其他模型进行精度比较的分析如下,其中不同数据集的主流模型是不同的,因为不同模型的侧重和提出时间不同。
从表3 可以看出:本文模型比传统的AMOC(Accumulative Motion Context)[2]模 型 在Rank-1、mAP 上分别提升约20.4 个百分点和28.5 个百分点,比TriNet[6]高8.9 个百分点和13.7 个百分点,说明仅采用运动特征和三元损失的效果较差;比应用3D 卷积的3D-Conv+NLA(3D Convolutional Networks and Non-Local Attention)[7]和M3D(Multi-scale 3D Convolution)[8]模型高4.4 个百分点、4.4 个百分点和4.3 个百分点、7.3个百分点,说明3D卷积对时空特征的挖掘没有非局部关注深入,另外前者的非局部关注只是嵌入到3D卷积残差块中作为补充,对全局特征的挖掘较浅;比应用扩张卷积和时间自关注的GLTR(Global-Local Temporal Representations)[17]高0.3 个百分点和2.9 个百分点。相对于数据增强的VRSTC[18]模型,本文模型的Rank-1 结果略高0.2 个百分点,mAP 低了0.9 个百分点,说明本文模型在首张命中率表现更好。
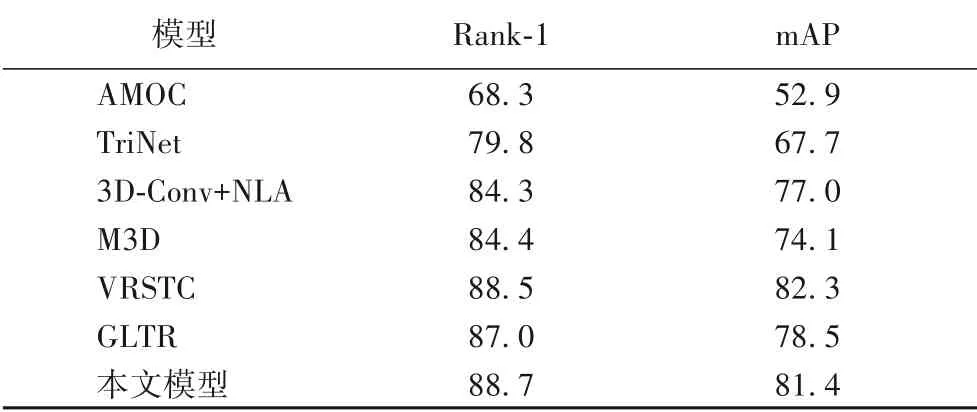
表3 MARS数据集上不同模型的Rank-1和mAP比较单位:%Tab.3 Comparison of Rank-1 and mAP by different models on MARS dataset unit:%
从表4 可以看出,本文模型在DukeMTMC-VideoReID 数据集上的表现良好,在Rank-1、mAP 上比只采用平均池化ResNet-50 的EUG(Exploit the Unknown Gradually)[4]模 型 高22.5个百分点和30.2个百分点;比采用学习片段相似度聚合(Learned Clip Similarity Aggregation,LCSA)[15]模型高6个百分点和4.9 个百分点;比GLTR 模型低1 个百分点和0.3 个百分点,这是因为该模型采用了对小目标特征敏感的扩张卷积技术,通过扩大感受野能获取较好的细节特征,另外该数据集复杂性比MARS低,GLTR模型在简单环境下表现较好。
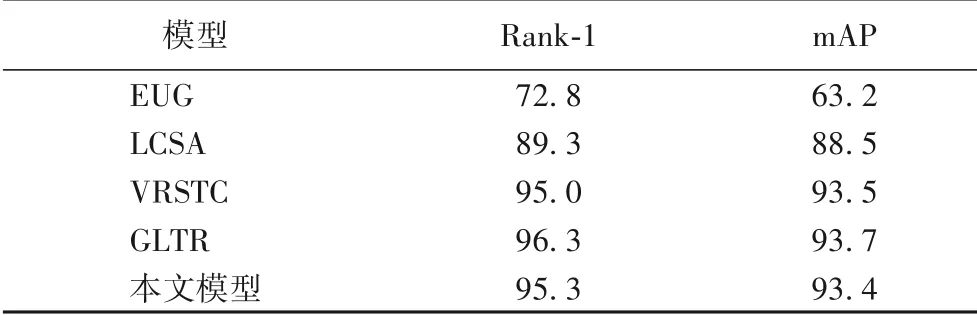
表4 DukeMTMC-VideoReID数据集上不同模型的Rank-1和mAP比较 单位:%Tab.4 Comparison of Rank-1 and mAP by different models on DukeMTMC-VideoReID dataset unit:%
表5 是在小数据集PRID2011 上不同模型的结果,由于在小数据集上各种模型的研究者并没有进行mAP 的精度测试,因此只比较Rank-1 的结果。本文模型比传统AMOC 模型高11.1 个百分点,比应用3D 卷积的M3D 和3D-Conv+NLA 的模型高0.4 个百分点和3.6 个百分点;现有的GLTR 模型比本文模型的结果仅高0.7 个百分点。由结果对比可知,在小数据集上本文的模型没有过拟合问题。

表5 PRID2011数据集上不同模型的Rank-1比较 单位:%Tab.5 Comparison of Rank-1 by different models on PRID2011 dataset unit:%
综上所述,本文提出的模型在各种尺寸和环境的数据集中都取得了较高的精度,采用非局部关注块和多重特征融合的深度残差网络可以提取显著的视频帧之间的时序特征,提高视频行人重识别的精度。
3 结语
本文针对当前视频行人重识别中无法有效地提取连续视频帧之间的全局时空特征的问题,结合自然语义中的全局关注技术,设计非局部关注块嵌入到ResNet-50 中,提取全局帧间特征;随后提出一种多重特征融合网络,提取显著性强的行人特征。在三个视频行人重识别数据集PRID 2011、MARS 和DukeMTMC-VideoReID 上的实验结果表明,本文模型对视频行人重识别精度有明显提升。下一步工作是要探寻生成对抗网络对视频行人重识别精度提升的效果和跨模态视频行人重识别。
猜你喜欢
西北大学学报(自然科学版)(2022年5期)2022-11-13
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
计算机研究与发展(2022年1期)2022-01-19
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
金桥(2018年4期)2018-09-26
小天使·一年级语数英综合(2017年6期)2017-06-07
文苑(2015年9期)2015-09-10
当代贵州(2014年13期)2014-09-21
