
基于动态记忆网络的序列推荐模型
2021-03-07 12:58朱馨培
现代计算机 2021年1期
朱馨培
(哈尔滨陆军预备役炮兵旅,哈尔滨150000)
0 引言
在推荐系统的发展历史中,用户的喜好在很长一段时间内都被看是静态不变的。由此对用户做出的推荐在层次上都会缺乏多样性,即便能够用神经网络拟合更好的特征,也很难发现用户的变化的潜在兴趣。另一个更为合理的假设是用户的兴趣是由用户的长期静态喜好和短期动态兴趣组成。用户的长期喜好受自身成长因素、性格特征等因素的影响,这部分喜好可看作是静止不变的。用户的短期动态兴趣随时间而动态变化,受当前环境和用户好友等周边因素影响较大。要对用户的短期动态喜好建模,需要将其与系统交互历史中的时间作为特征考虑进数据集中,这就是序列化推荐模型。本文提出了基于动态记忆网络的序列推荐模型,首先介绍序列推荐模型的范式,然后再对提出的模型结构进行详细的介绍。
1 序列推荐模型的范式
形式上,序列化推荐模型的任务是通过给定用户的历史行为序列对未来行为进行预测的推荐模型。假设有一组用户表示为用户u的按时间顺序排列的历史行为(点击或是购买)序列表示为是用户u购买或点击的第i个物品,然后模型在物品的全集I上预测物品的得分。用来表示用户在所有物品上的得分,其中表示用户在物品j上的预测分数或喜好程度。最后,模型在y中选择得分最高的k个物品作为推荐。
2 序列推荐模型框架
在序列推荐中,我们从两个角度对用户进行表示,得到用户的两种表示方法。其中一种方法学习用户的长期静态偏好,另一种方法提取用户的短期动态兴趣。在实际场景中,可以认为用户的静态偏好是缓慢变化或基本不变的,而用户的短期动态兴趣则会根据所处情境或上下文而变化。因此,本文基于用户的静态偏好和动态兴趣生成用户的全面表示,并提出基于门控机制和动态记忆网络的个性化序列推荐模型,模型的整体框架如图1。
从图1中可以看到,模型一共由4个独立的部分组成,包括处理用户输入序列的输入模块、编码用户长期静态喜好的用户模块、生成和更新用户记忆的记忆模块以及最后的结果输出模块。输入模块从输入的序列中检索出用户的动态兴趣,并保存每一时刻的状态信息。用户模块负责学习用户的静态喜好,该模块使用两种不同的方式对用户的静态偏好进行编码。然后,记忆模块在用户静态偏好的启发下,选择在存储的记忆中更新哪部分的信息。记忆模块的主要结构类似于。本文与这两篇论文不同在于,记忆模块中嵌入门控结构,该结构借鉴了高速网络(Highway Network)中的工作。所以,本文采用了一种比RNN更能有效记忆过去事实信息的方式来捕捉用户的动态喜好,并且将其和所得到的用户静态表示相结合,通过计算在所有物品上的偏好程度来对用户进行推荐。
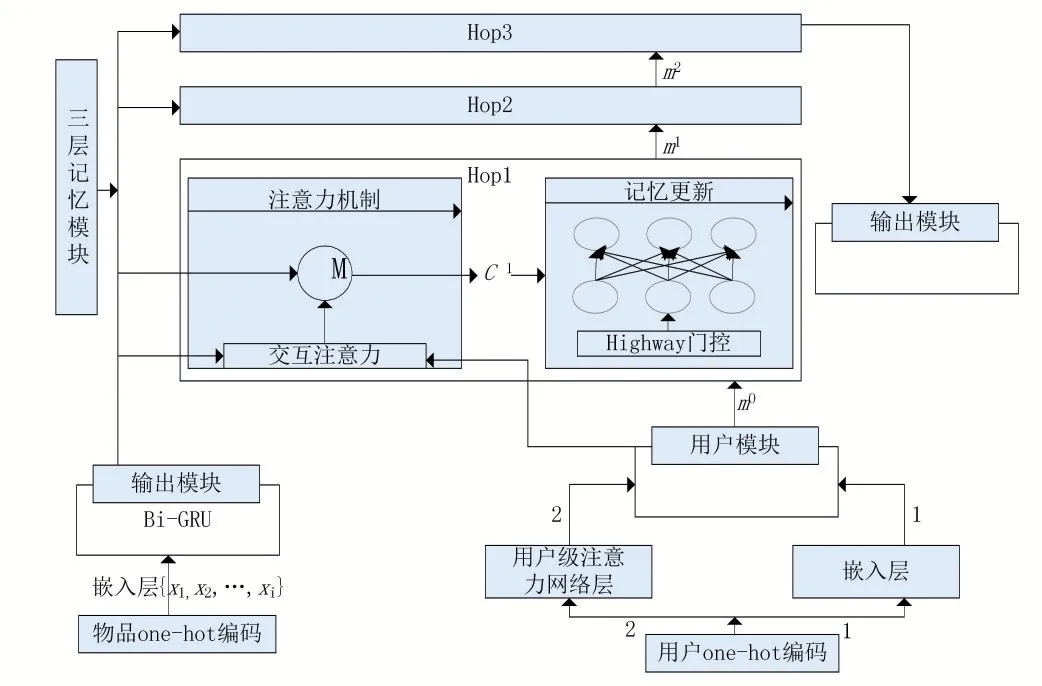
图1 模型整体框架
2.1 输入模块
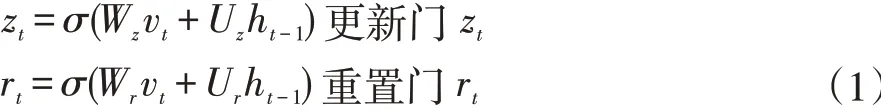
其中。表示向量间逐个元素的相乘,tanh(x)是神经网络中的非线性激活函数。通过将当前时刻的输入xt和保存了前t-1时刻的隐向量ht-1分别乘以不同的权重矩阵,再利用激活函数来将结果压缩到0-1之间得到更新门zt和重置门rt。将向量的值压缩到0-1之间,该单元格便能够充当门的作用。更新门zt可帮助模型确定需要将多少过去信息(来自前一时间步骤)传递给未来,为1表示全部复制过去的信息,为0则表示将该信息全部阻隔。同样地,在模型中使用重置门rt来决定忘记过去的信息量。候选状态向量ĥt利用重置门来得到当前的候选记忆,该候选记忆存储了过去的相关记忆。最后的状态向量ht需要用来保存当前时间戳的单元信息并将其传递到下游网络。为了做到这点需要用到更新门zt。它确定候选记忆ĥt和前一个时间步的隐状态ht-1中有多少信息可以用于更新当前时刻的记忆。使用更新门和重置门,能够消除RNN中存在的梯度消失问题。因为模型不是每次都清除新输入,而是保留相关信息并将其传递到网络的下一个时间步骤。
除此之外,由于文献[3]已经验证了双向的循环神经网络能够同时有效地捕捉到过去和未来的消息,所以本模型采用双向GRU,GRU层得到的最终的隐状态表示为最后,我们将该模块的输出向量h填充进记忆模块(2.3)来获取用户的整体兴趣表示。
2.2 特征记忆网络模块
用户模块的作用是捕捉用户长期的静态喜好,常规的方法可以使用用户id的one-hot编码,再根据类似物品映射到低维向量的方式去表示用户。但是,每个数据集下的用户id只是系统随机分配的一串独特的字符,本身并没有携带任何有关用户喜好的信息。为了能够更好地对用户的长期内在兴趣进行充分的挖掘,提出了另一种基于注意力机制的方法。用户在平台中的所有行为是在其内在兴趣上的动态性波动的结果。要捕捉用户的长期静态偏好,可以全局考虑所有用户的交互记录,使用注意力机制选择重要行为,并使用这些选择的行为表示用户的静态偏好。
为了验证本文提出的基于用户级别的注意力机制在表示用户长期偏好问题上的有效性,本文将同时实现上一段落中提到的两种用户表示方法。第一种onehot编码的表示与物品相类似,在此不再多做介绍。第二种方法是采用用户交互过的所有物品的加权和来表示该用户的内在偏好:

其中权重因子α是用户和隐状态的函数,αj=q(ui,hj)。表示的是输入中第j个位置的物品和用户u的对齐程度。同时这个权重值也决定了在编码用户的内在偏好时,哪些物品比较重要,哪些物品可以忽略。α可以用多种方式学习得到,本文采用的方式受启发于文献[4]。具体做法是将用户向量ui和物品向量hj映射在同一个空间中,然后对两个向量求点积,最后把缩放后的向量进行归一化便得到了用户i的表示中输入j位置的物品所占的权重:

其中,A1和A2是将两个向馈映射到同一空间中的参数矩阵,<>符号表示向量的内积。从公式可以看出,点乘的结果再经过一次大小为dH的缩放才进行Soft⁃max归一化。该步主要是为了得到一个soft attention,以便于求导和损失梯度的向前传递。
然后,把用户模块的输出作为记忆模块的其中一个输入,在记忆模块的每一层中触发记忆模块的注意力机制和门控机制来更新保存的记忆。
2.3 输出模块
记忆模块的输出,记作mu,是用户u的全局表示,它集成了用户的长期内在偏好和短期动态兴趣。输出模块根据得到的全局用户表示向量和物品的表示向量,采取类似于矩阵分解中的技术,将两个向量的点积作为该用户对物品的评分。最后,模型在所有物品评分上进行Softmax归一化,得到的0,1之间的值表示用户对该物品的喜好程度。
一般来说,序列预测模型采用全连接网络层计算用户在所有物品上的偏好分数。该计算方式下,这一步的待优化的参数是,其中是向量维度是待计算的物品的总数。因此,我们必须要保留足够人的空间来存储这些参数。为了降低空间使用成本,本文采用的计算方式是文献[5]中提出的双线性解码方案。该方案可以在保证不丟失精度的情况下有效地降低空间复杂度。具体地,用户u在候选物品i上的偏好得分计算如下:

最后,本文选择交叉熵损失函数作为模型的损失函数。
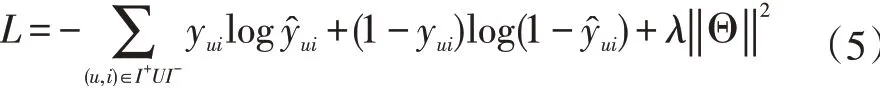
均方根平方误差RMSE在该模型中并不适用,本文的目标是预测下一个用户可能会消费的物品,类似于多分类问题。式(4)中,yui的值只有0和1,当用户u购买过该物品时为1,否则为0。I+表示的是在训练集中真实的下一个观测物品,相对的,I-则表示集合中的其他作为负例的物品。‖Θ‖是模型中所有涉及的参数集合。在损失函数中加入L2正则,防止模型在训练过程中发生过拟合。训练过程中,最小化该目标函数,并且通过动量优化的方式学习模型中的参数。
3 带辅助信息的模型
本文模型用到的信息是用户的隐式交互序列,忽略了序列中用户对每个物品的评分分数。在不变动模型其他部分的同时,加入数据集中的评分信息进行对比实验。
众所周知,评分系统广泛存在于各大电商、视频网站等平台。一个用户对某个物品的评分信息显式的表明了其对该物品的好恶。如果模型使用的是用户的历史评论记录,在某种意义上是把序列中的每一个物品都当成正例。
一般情况下,商品的评论数值为1-5或1-10的数值信息。想要使用该信息,必须首先把每个标量的数字向量化,每一个数字转化为一个向量。对于每个用户u来说,其历史行为序列中的每个物品也对应了一个相应的评论序列,记作与其对应的物品向量为本文将使用叠加方式利用这两个数据。每个时刻t输入校块对应的输入为:ft=vt+rt。
4 结语
本文先从整体上介绍了序列推荐模型中各模块的结构和具体作用,最后在模型中加入评分这一辅助信息验证其对模型效果的作用。序列推荐由于使用的是动态记忆网络,所以能够记忆更多内容,在长序列上的表现也超过基于循环神经网络的模型。模型还在记忆网络的基础上嵌入了注意力机制和门控机制,使得模型在理论上能够聚焦在有用信息上,从而做出更为个性化的推荐。
猜你喜欢
卫星应用(2022年7期)2022-09-05
汽车实用技术(2022年14期)2022-07-30
卫星应用(2022年3期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
卫星应用(2022年1期)2022-03-09
云南画报(2021年8期)2021-11-13
环球慈善(2019年6期)2019-09-25
阅读(低年级)(2019年4期)2019-05-20
魅力中国(2018年5期)2018-07-30
高中生学习·高三版(2016年9期)2016-05-14
