
基于机器学习的重庆长江航道雾图像特征识别研究
2021-03-06 08:43,2
气象与环境学报 2021年1期
,2
(1.重庆市气象服务中心,重庆 401147; 2.重庆市开州区气象局,重庆 405400)
引言
雾是常见的灾害性天气之一。重庆地处四川盆地东部,山地丘陵众多,长江与嘉陵江交汇,水汽充沛且不易扩散,潮湿的空气使重庆多云雾而少日照,年均雾日超过60 d,最高达148 d,素有“雾都”之称。大雾天气能见度较差,常导致船舶停航,或发生搁浅、触礁等事故,给航运安全带来诸多不利影响[1]。
雾的识别主要有遥感影像提取和图像直方图分析等方法。由于气象卫星发展较早,早期大部分学者都通过卫星的光谱波段差异提取雾特征,进而划分雾的发生区域,此种方法具有不受地形阻挡和分辨率统一的优点。一些学者[2-3]利用NOAA和GMS-5卫星资料监测沪宁高速公路的大雾,取得了较好效果。另一方面,由于卫星的分辨率较低,对公路、铁路以及长江航道的识别不够精细,因此近年来也出现了利用拍摄的雾的照片进行分析的方法。梁超圣等[4]基于形态学原理,提出了一种针对低能见度、前下视航拍机场图像中自动检测机场跑道的方法;孙晓宁和陆文骏[5]建立了协方差描述矩阵,对雾天图像进行显著性检测。
机器学习算法属于新型人工智能技术,在语言识别、图像识别、自然语言处理和专家系统等方面均有广泛应用。近年来,随着技术的成熟,智能图像识别技术在气象领域得到进一步发展。李才媛等[6]利用支持向量机的方法建立了武汉市24 h大雾预报模型;项文书[7]根据视频图像提取特征,建立了能见度等级的估计模型,并用直方图模块进行订正;史达伟等[8]基于多种机器学习算法,建立了强浓雾气象要素诊断模型。本文根据重庆市内长江航道雾过程视频资料,提取图像样本多维特征量,利用K最近邻、支持向量机、BP神经网络、随机森林等机器学习方法进行训练,构建模型对雾进行识别和检验,并基于模型训练及构建过程,设计了用于展示的交互式图形用户界面。
1 资料与方法
1.1 图像数据采集
2019年5月15日上午08—11时,长江航道巴南至长寿段出现了大雾天气,该过程持续时间长、图片记录完整。本文采集了在此期间黑石子、纳溪沟2个航道雷达站拍摄的长江江面视频(来源于重庆海事局,下同),逐帧无损转换为1920×1080像素的图片,总计22054张有雾图像样本。作为对比,另采集了2019年7月25—26日黑石子、纳溪沟、新港3个雷达站拍摄的无雾条件下长江江面视频并进行转换,总计得到8814张无雾图像样本。
1.2 特征量提取
在有雾天气中,雷达站摄像头采集的图像饱和度与无雾图像相比明显降低,其均值与方差可作为雾识别的特征量[9]。本文先将彩色RGB图像转换为HSV模式(H代表色调,S代表饱和度,V代表图像纯度),对每一张图像样本提取分量矩阵S,计算S的均值M和方差V:
(1)
(2)
(3)
计算机视觉通过统计图像的同质现象(纹理)来表征图像表面的纹路和图片的光滑或粗糙程度,有雾图片和无雾图片的纹理特征存在显著差异。灰度共生矩阵是一种分析图像纹理特征的重要方法,通过估计图像一定距离和一定方向上像素的灰度相关性来反映方向、间隔、变化幅度及快慢等图像纹理综合特性[10]。设f(x,y)为一幅二维图像,大小为M×N,灰度级别为Ng,则满足一定空间关系的灰度共生矩阵为:
P(i,j,d,θ)={(x1,y1),(x2,y2)∈M×N|f(x1,y1)=i,f(x2,y2)=j}
(4)
式(4)中,(x1,y1),(x2,y2)为图像像素坐标;i,j=1,2,…,Ng-1为灰度级;d为(x1,y1)和(x2,y2)之间的距离;θ为两者与坐标横轴的夹角角度,取0、45、90、135共4个值,灰度共生矩阵P(i,j,d,θ)为Ng×Ng的矩阵。
为了更直观地概括图像纹理状况,通常以从灰度共生矩阵导出的特征参数来描述,常用参数包括能量ASM、熵ENT、对比度Con、相关性Corr[10]。
能量:表征图像灰度分布均匀程度和纹理粗细度,值越大则纹理规则变化越稳定。
ASM=∑i∑jP(i,j)2
(5)
熵:表征图像灰度分布的复杂程度,值越大则图像越复杂。
ENT=-∑i∑jP(i,j)lnP(i,j)
(6)
对比度:表征图像清晰度和纹理沟纹的深浅,值越大则图像中灰度值差异大的像素对越多。
Con=∑i∑j(i,j)2P(i,j)
(7)
相关性:度量图像的灰度级在行或列方向上的相似程度,值越大则图片局部灰度相关性越大。
(8)
式(8)中,ui,uj为矩阵在行或列方向上的均值;σi,σj为对应的方差。
将式(2)—式(8)的特征量组合,构成代表图像特征的6维数据向量[M,…,Corr],所有图像的特征向量构成样本集I,如式(9)所示,其中n为样本集中包含的图像总数。
(9)
1.3 研究方法
Python自带的Scikit-Learn算法库集成了多种机器学习算法,算法的选择与样本形态和问题类型密切相关。本文对雾的识别属于监督式分类学习问题,常用算法包括逻辑回归、支持向量机、神经网络、决策树、随机森林等[11-13]。
(1)K最近邻(K-Nearest Neighbor,KNN),是通过判断新加入样本在特征空间中与各个初始中心的距离,以最邻近样本所属的类别决定新样本类别的分类方法。KNN算法通常用于解决非监督式分类问题,但因其原理简单,易于实现,无需估计参数等特点,在监督式分类中也得到广泛应用[14-15]。
(2)支持向量机(Support Vector Machines,SVM),原理是利用核函数使低维的非线性问题映射到高维特征空间中,建立超平面作为决策曲面,使得正例和反例的隔离边界最大化从而实现分类[15-18]。本文利用SVM算法训练时,核函数设为高斯核,分类参数设置为OvO(One vs One),即对类别两两之间进行划分,用二分类的方法模拟多分类的结果。
(3)BP神经网络(Back Propagation Neural Network),是一种按照误差逆向传播算法训练的多层前馈神经网络。输入层与输出层之间包含若干隐层,误差信号在输入层与隐层、隐层与隐层、隐层与输出层之间正反向传播,不断调整连接权值和阈值,找出传递函数的最佳权值矩阵和阈值矩阵,从而建立起两者之间的映射关系[19-21]。此类算法预测精确,但计算量巨大,需设置合理的隐层数和迭代次数。
本文采用3层BP网络模型结构和梯度下降的训练方法,输入层、隐层和输出层之间的神经元以Sigmoid传递函数连接。迭代步数设置为100000,每10000步打印一次损失值,当损失值降低至0.5以下,并经过3—5次打印后仍保持稳定时,表明训练完成。
(4)随机森林(Random Forests)由决策树算法演变而来。基于自助法重采样技术原理,从大小为N的原始训练样本集中有放回地随机抽取样本,重复抽取过程k次,生成k个大小同样为N的新训练样本集合,每个新样本集生成1个分类树(决策树),然后由k个决策树组成随机森林。分类结果由个别树输出类别的众数而决定,分类误差取决于每棵树的分类能力和它们之间的相关性。
此外,机器学习准确率与样本的选择密切相关。本文采集的有雾图像中,存在来源于相同或相近时间段的样本,会对训练结果造成干扰。因此,按20—30 min的时间间隔将有雾样本集Ifog分为多个子集(I1,I2,…,Im),从每个子集中分别随机抽取100幅图像,构成新的有雾样本集Ifog′。 对无雾样本集Iclr进行同样处理,得到新的无雾样本集Iclr′。合并两个新样本集,最终得到容量3690的样本集I′。
2 结果分析
2.1 能见度与图像特征关系
在1.2节中,提取了饱和度和纹理两类共6个特征量用于训练。机器学习要求每个特征量相互独立,且尽可能多地代表图像的能见度特性。由于样本集I ′不包含能见度信息,本文根据视觉经验方法,对I ′当中的所有样本进行能见度区分及排序。图片首先分为“无雾”和“有雾”两类,定义能见度1500 m为分界线,之后结合大雾过程视频和视觉效果响应,对所有样本图片按能见度从大到小排序,最后分析不同能见度下的图像特征量变化。
由图1可见,无雾和有雾图像的饱和度特征差异显著,前者的均值及方差较大。对有雾天气而言,不同能见度的图像饱和度均值相近,但随着能见度下降,方差逐渐减小,表明图像各处视觉差异更小,体现浓雾或强浓雾特性。
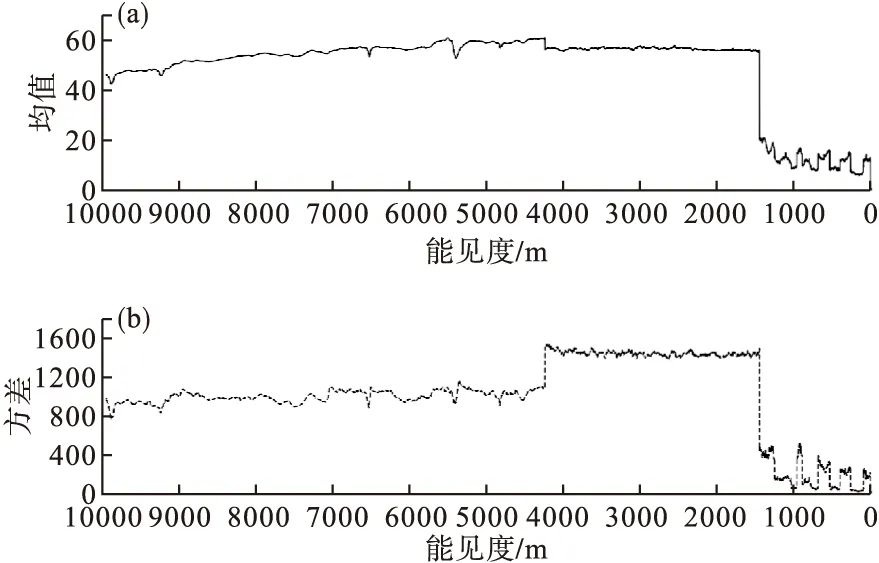
图1 不同能见度条件下图像饱和度均值(a)和方差(b)变化Fig.1 Variation of saturation mean value (a) and variance (b) of images under different visibility conditions
图2和图3表明,随着能见度逐渐降低,图像能量略微增加、熵明显减少、对比度略微下降、相关性明显增加。这是因为在有雾天气条件下,图像中原有的不规则地物要素被雾覆盖,大部分像素点表现为相似的白色或灰白色,图像纹理结构发生改变,从而在灰度共生矩阵的4个分量中体现出与无雾天气不同的特征。
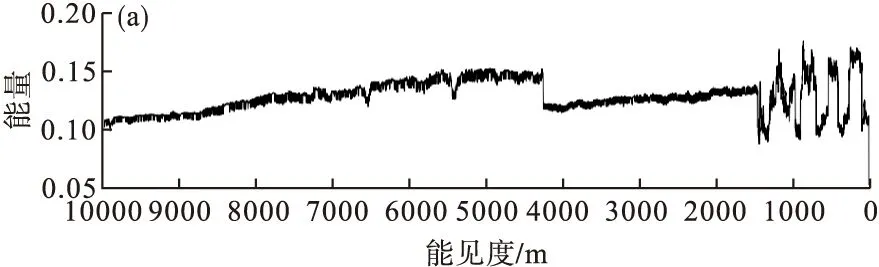
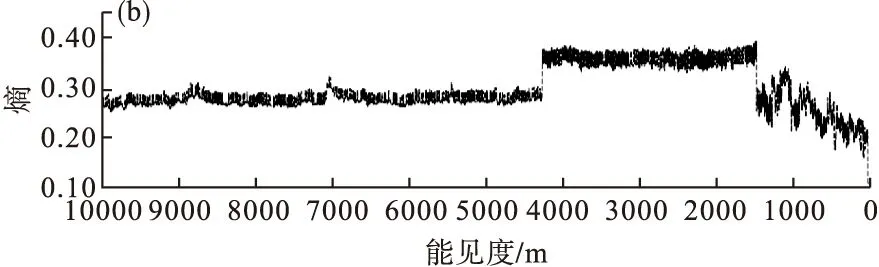
图2 不同能见度条件下图像能量(a)和熵(b)特征分布Fig.2 Characteristic distributions of energy (a) and entropy (b) of images under different visibility conditions

图3 不同能见度条件下图像对比度(a)和相关性(b)变化Fig.3 Variation of contrast (a) and correlation (b) of images under different visibility conditions
2.2 能见度等级预分类
按照气象学定义,能见度低于10 km则为有雾天气,进一步分为轻雾、雾、大雾、浓雾、强浓雾,分别以能见度1000 m、500 m、200 m、50 m、50 m以下作为分类标准。然而对航运管理部门而言,能见度在1000—1500 m之间的雾也对水上交通运输的安全产生重要影响。
综合考虑研究及应用需求,本文拟将样本分为6类,能见度大于1500 m的个例记为“无雾”类型,以数值0表征;能见度大于1000 m且不超过1500 m的个例记为“轻雾”类型,以数值1表征;能见度大于500 m且不超过1000 m的个例记为“雾”类型,以数值2表征;能见度大于200 m且不超过500 m的个例记为“大雾”类型,以数值3表征;能见度大于50 m且不超过200 m的个例记为“浓雾”类型,以数值4表征;能见度不超过50 m的个例记为“强浓雾”类型,以数值5表征。这样就将不同种类雾的识别问题转化为对6类数值输出的预测问题。
本文采用监督学习方法,需要对参与训练的样本预分类,设置初始类型标签(label)。但一方面由于航运部门雷达站未配备能见度检测仪,另一方面长江航道重庆段的沿江气象观测站也较为稀少,能见度数据难以使用。因此,本文根据2.1节中图像特征量的分布趋势,选择对能见度变化最为敏感的饱和度方差和熵2个因子,定义经验分类方法,如表1所示。

表1 无雾及有雾天气类型的经验分类方法Table 1 Empirical classification method of non-fog events and fog events
根据经验分类方法,初步确定了图片样本的标签。无雾天气及5类有雾天气样本集的特征量平均值分布见表2。
由表2可见,无雾样本的饱和度均值和饱和度方差的特征平均值明显高于有雾样本,有雾样本的饱和度特征量平均值随能见度降低而降低;样本集的熵平均值随能见度降低而降低,相关性平均值随能见度降低而升高,与2.1节的结论一致。
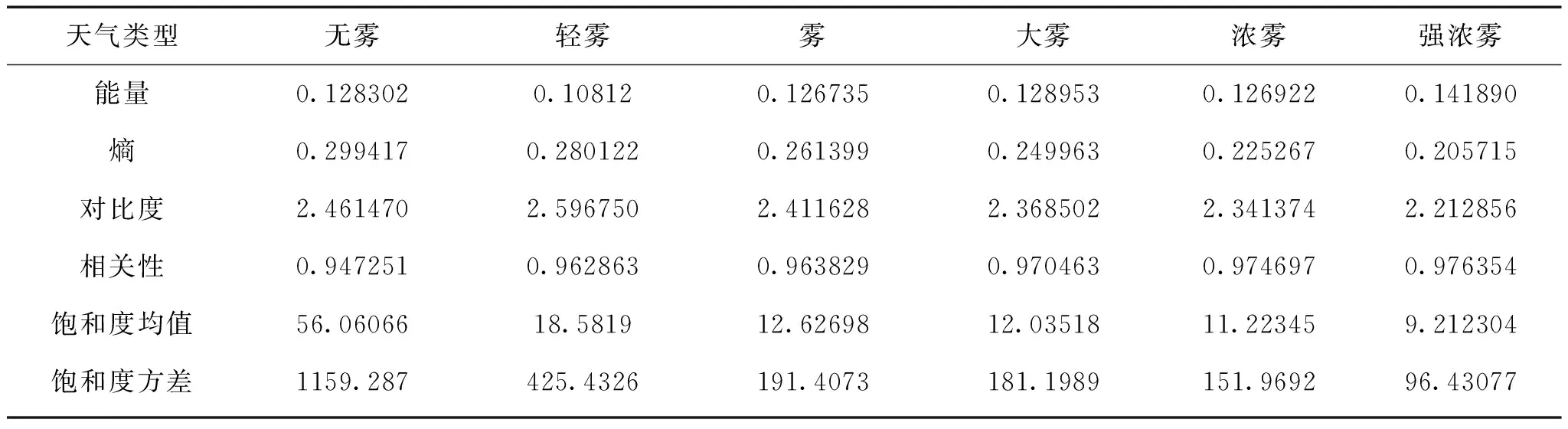
表2 无雾及有雾天气类型的特征量平均值Table 2 Mean value of characteristic variables of non-fog events and fog events
2.3 样本训练与检验
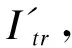
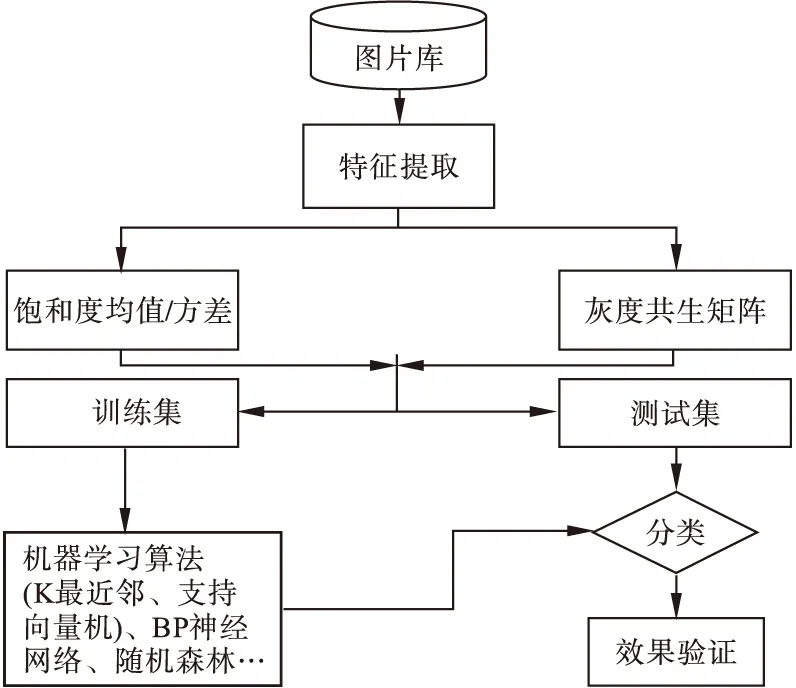
图4 机器学习算法识别雾的流程图 Fig.4 Flow chart of fog identification using a machine learning algorithm
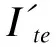
(10)
式(10)中,k为类型;Nk为该类型的测试样本总数;nk为对Nk个样本训练后,输出类型为k的样本个数。根据式(10),计算2.3节所述的机器学习算法对无雾天气和5种有雾天气的识别率,见表3。
(1)K最近邻。KNN算法对无雾和轻雾天气的识别准确率达到100%,强浓雾的识别也有较好表现(接近90%),对能见度在50—1000 m区间的雾、大雾和浓雾天气识别效果稍差,在70%—80%之间。
(2)支持向量机。SVM算法对无雾天气可实现100%识别,轻雾的识别率也接近100%,但对能见度低于1000 m的4种有雾天气识别率均低于85%,其中雾和浓雾的识别率明显低于其他3种算法,仅在50%左右或以下。这是由于SVM算法适用于二元分类,对多元分类问题的模拟能力较差导致的。
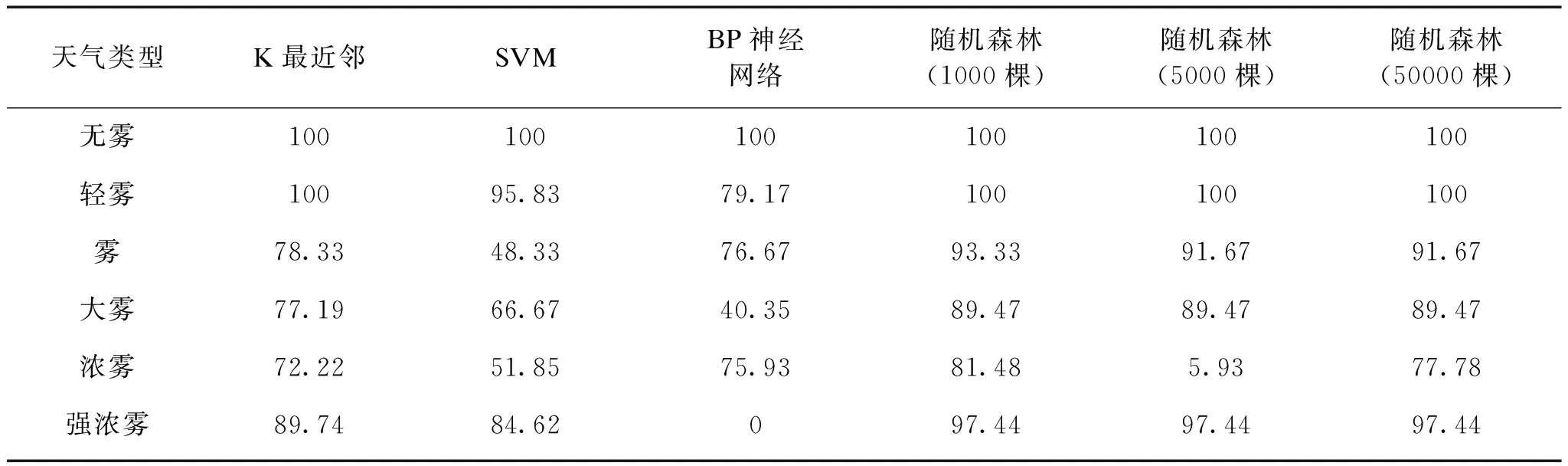
表3 无雾及有雾天气类型的机器学习算法识别率对比Table 3 Comparison of identification rate of machine learning algorithm of non-fog events and fog events %
(3)BP神经网络。BP神经网络算法对无雾天气可达100%识别;轻雾和大雾的识别率低于其他3种算法,分别为79%,40%;雾和浓雾的识别率在75%—80%之间;强浓雾则基本无法识别:39个强浓雾样本中,18个被判断为大雾,21个被判断为浓雾,这是由算法的过拟合现象引起的。当BP神经网络的训练进行到一定程度之后,随着学习能力的提高,模型学习的样本细节过多,对一类或几类样本(强浓雾)的特征概括能力下降,从而错误地将其归为相近或相邻样本所属的类别(大雾或浓雾)。
(4)随机森林。分别以1000、5000、50000棵决策树(树的棵数代表随机采样次数)测试算法,结果表明。当决策树数量从1000增加至5000时,识别效果非但没有提高,反而略有下降;而继续增至50000时,识别率仍未明显提高,且由于复杂度增加,计算速度大幅降低,比前两次训练平均多耗时1—2 s左右。因此,包含1000棵决策树的随机森林算法即可高效精确地解决问题,除浓雾以外,其他所有天气类型的识别率均在90%左右或以上,浓雾的识别率为81%.
2.4 图形用户界面
利用Python语言的Tkinter模块编写图形用户界面(简称GUI,下同),对雾识别模型的样本训练及建模过程进行封装和展示。该模型包括图像读取、雾识别、结果打印3部分功能,结构如图5所示。
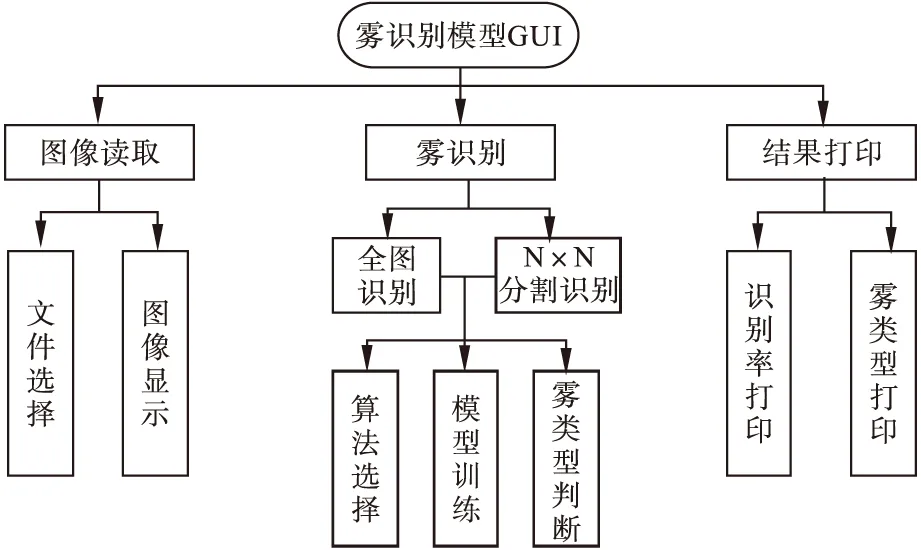
图5 雾识别模型功能结构Fig.5 Functional structure of fog identification model
通过雾识别模型GUI,用户首先选择需要识别的雾天气图像;图像经过预处理后进入后台,由各种算法构建的模型对其进行雾类型判断,计算全图或分图雾识别结果;之后在前台打印对应算法模型的识别率,输出该图片的雾类型,GUI展示效果参考图6。

图6 雾识别模型图形用户界面Fig.6 Graphical user interface of fog identification model
3 结论与讨论
(1)K最近邻和随机森林算法在本文的雾识别问题中表现较优,前者对5种有雾天气的识别率均超过70%,后者超过80%。
(2)4种算法均能够以100%的准确率识别能见度超过1500 m的无雾天气。除BP神经网络以外,其他算法对能见度在1000—1500 m之间的轻雾天气,和能见度低于50 m的强浓雾天气识别能力较强,前者识别率>95%,后者≥85%。
(3)能见度位于50—1000 m区间内的浓雾、大雾和雾识别难度较大。以表现最优的随机森林算法为例,上述3类有雾天气的识别率分别为81%、89%、93%,表现较差的支持向量机和BP神经网络则更低。造成该问题的原因,一方面是该区间内的雾特征较为相似,训练过程中特征量相互叠加,造成混淆;二是由于算法本身局限性,对样本特征学习能力下降而产生的过拟合现象。
(4)本文提出的雾识别模型以计算机图像识别原理为基础,识别准确性明显高于传统方法,对长江水上交通安全保障服务具有重要意义。在实际应用中,拟将该模型接入重庆海事局系统平台,可更加直接地读取雷达站的摄像头图片,实时识别雾天气类型并输出结果,为海事部门应对大雾天气提供决策支撑。
(5)为使模型更具实用性,还需进行优化设计。本文构建的模型主要存在以下不足:一是计算效率不高,以随机森林为例,包含1000棵树的模型训练时间约为2—3 s,后期考虑在不损失识别率的前提下进一步减少决策树数量,以提高速度;二是部分算法对雾的识别准确性不高,后期拟增加卷积神经网络(CNN)、递归神经网络(RNN)等深度学习算法,若其在雾识别问题中表现优异,则能够进一步优化当前模型,提高准确性。
猜你喜欢
VOGUE服饰与美容(2022年1期)2022-02-19
气象水文海洋仪器(2021年4期)2021-12-11
天津科技(2021年4期)2021-05-13
环球时报(2019-11-01)2019-11-01
扬子江(2019年3期)2019-05-24
农业与技术(2017年13期)2017-08-23
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
