
基于BiLSTM-ATT的微博用户情感分类研究*
2021-03-05 07:15:26谢思雅施一萍胡佳玲
传感器与微系统 2021年2期
谢思雅,施一萍,胡佳玲,陈 藩,刘 瑾
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引 言
随着移动互联网的迅速发展,新浪微博已成为广大群众抒发情感发表观点的重要平台。了解其言论情感就能了解用户该时间段内的情感倾向,从而获得更多信息。
传统的文本情感分析方法主要有:基于情感词典、基于表情符号等。如文献[1]使用情感词典的方法,文献[2]利用表情符号进行情感分类。但这些方法需要花费大量的时间提取文本数据中的特征。因此,利用机器学习和深度学习进行情感分类的方法应运而生。针对微博短文本,张英[3]提出了一种基于深度卷积神经网络的情感分类方法,并与 支持向量机(support vector machine,SVM) 算法和卷积神经网络(convolutional neural network,CNN)方法进行比较,验证该模型的有效性。李鸣等人[4]应用Apriori算法和情感词典匹配算法进行了较准确的文本情感分析。袁磊[5]利用改进的卡方统计量算法进行特征提取,提高了情感文本分类的准确率。
本文针对用户自身的情感倾向提出了一种使用词向量结合深度学习的方式去学习文本中的情感信息,在NLPCC2013语料集的基础上构建一个新的带有微博用户情感信息的数据集进行测试,最终实现了更准确的用户情感倾向分类。这些结果对政府了解群众的情感动态以及企业了解用户喜好有重要价值。
1 相关工作
长短期记忆(long short-term memory,LSTM)网络是一种较特殊的循环神经网络(RNN),可以做到长期依赖信息。Sundermeyer M等人解释了怎样使用LSTM构造语言模型[6]。Zou H等人[7]使用LSTM模型对文档进行处理,解决了跨语言的文本情感分类问题。Tang D等人[8]利用 CNN结合LSTM构建的神经网络进行文档分类,判断情感性质。但LSTM模型存在单向传输且存储过小的问题。因此,金宸等人[9]将双向的LSTM模型运用到中文情感分类中,并构建了完整的模型。
注意力机制(attention mechanism,ATT)最早是在计算机视觉领域被提出来的。Bahdanau D等人[10]将注意力机制和神经网络相结合,证明了注意力机制与深度学习相结合的有效性。Liang B等人[11]将多注意力机制和CNN相结合用于处理文本情感分析的任务,其分析准确性比单一神经网络模型更高。
2 基于BiLSTM-ATT的模型
2.1 整体模型
如图1所示为本文提出的整体模型结构。
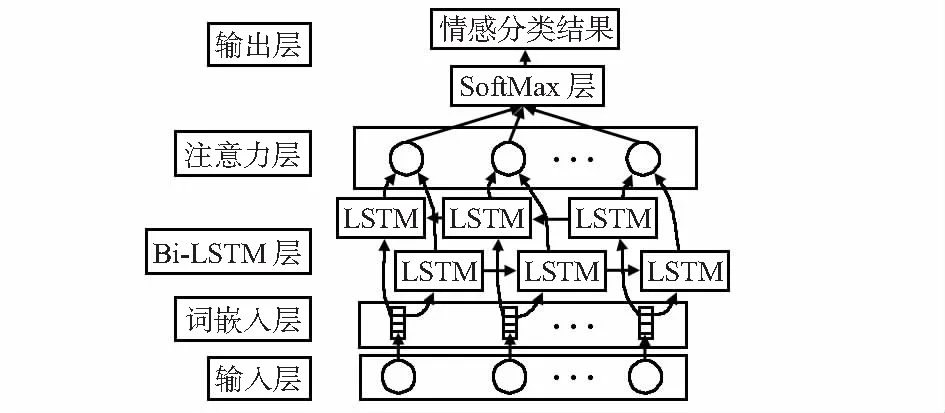
图1 BiLSTM-ATT模型结构
首先,将经过预处理的中文文本经过词嵌入层训练成词向量形式,作为BiLSTM层的输入,提取出全局特征,利用注意力机制重点关注文本中的情感信息,最后经过SoftMax层进行分类,完成微博用户的情感分类。
2.2 文本预处理
本文采用Jieba分词对文本进行分词,然后基于哈工大提供的停用词表对其进行去停用词处理。
2.3 词向量
将经过预处理后的文本利用Word2Vec模型训练成词向量。Word2Vec包含两种神经网络语言模型:CBOW 和 Skip-Gram模型。文献[12]采用的CBOW模型,但考虑到与CBOW模型相比,Skip-Gram模型对于中心词的预测和调整,能使词向量相对更准确,所以本文选择了Skip-Gram模型,并利用负采样减少计算量,优化算法。Skip-Gram模型图如图2所示。

图2 Skip-Gram模型
Skip-Gram模型包含三层:输入层、投影层和输出层。其中,输入层是从词向量矩阵中取出一行,通过中间投影层将输入层输出的词向量传递到输出层[13],预测输出wk的上下文wk-1,wk-2,wk+1,wk+2。
2.4 BiLSTM
LSTM具有输入门、遗忘门、输出门结构,可以解决当预测位置和相关信息之间的文本间隔很大时,RNN学习不到的问题。周瑛等人[14]提出的基于注意力机制的LSTM模型在情感分析任务中效果甚好,但无法体现词与词之间的关系。这是因为在LSTM中,状态传输是单向的。但在某些微博用户文本信息中,当前时刻的状态不仅和之前的状态有关,也和之后的状态有关。因此,本文采用双向LSTM来充分利用上下文关系。
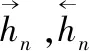
自前向后LSTM的更新公式为
(1)
自后向前LSTM的更新公式为
(2)
两层LSTM叠加后输出层
(3)
2.5 注意力机制
在微博语料集中,并不是所有词都对子句的语义表达有作用。因此,本文引入注意力机制来提取重要的信息,并选择性忽略无用的信息,最后将这些信息的向量组合在一起作为输出,起到重点词关注的作用。其中,Ww,bw是注意力模型的权重和偏置,ht是BiLSTM层的输出;uw也是权重值,计算结果φt表示文本中每个词的重要度信息;V是经过注意力模型计算后的输出向量。具体计算公式如下
ut=tanh(Wwht+bw)
(4)
(5)
(6)
2.6 SoftMax层
将经过模型处理的文本信息通过SoftMax层输出情感类别判定结果。采用反向传播算法对模型参数进行梯度更新。其中,Vi是分类器的输出,C是总类别个数,Si是当前元素与所有元素的比值,即判断为每个类别的概率
(7)
SoftMax的损失函数
(8)
式中Syi为正确类别对应的函数,Sj为正确类别对应的 SoftMax输出。为防止模型过拟合,本文在SoftMax 层中采用了Dropout训练。
3 实验结果与分析
3.1 实验语料
为确保选取用户发表的言论能够更好地反映该用户在一段时间内所处的情感状态,随机挑选了200位微博用户,爬取了约5 000条微博语句,结合NLPCC2013语料构建了一个新的带有微博用户文本信息的数据集,如表1。
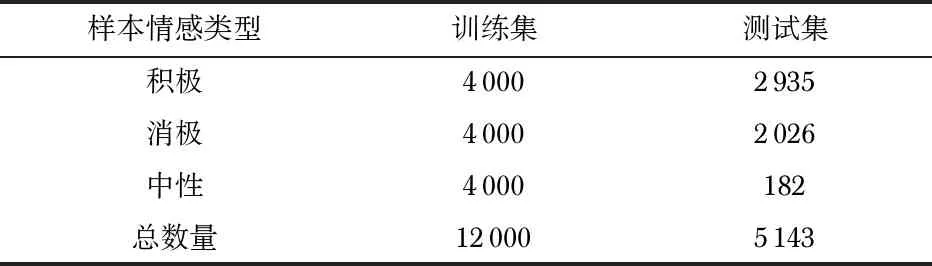
表1 实验数据集语料分布
选取训练集时使3种情感类别的样本数量相同,是为防止因训练样本数量不同而造成误差。
3.2 实验环境
Windows 10操作系统,Intel Core i7—8550U,8GB内存,Python编程语言,Tensorflow框架,PyCharm开发环境。
3.3 评价指标
本文所采用的评价标准如表2所示。

表2 评价标准表
精确率P:分类器做出的正确预测为类别A占所有预测为类别A的比例。召回率R:分类器在类别A中做出的正确分类占实际为类别A的比例。F1值:精确率和召回率的加权平均
P=TP/(TP+FP),R=TP/(TP+FN),F1=2×P×RP/(P+R)
(9)
由于本文实现的是三分类,在计算出用户情感倾向为积极、消极和中性对应的精确率P,召回率R及F1值后,取三个类别的平均值作为评价标准,即AVP,AVR和AVF1。
3.4 参数设置
BiLSTM-ATT模型采用Tanh激活函数,窗口长度设置为5,即取中心词左右两边各5个字,Dropout为0.5,词向量维度取150,负采样中的批处理个数为64,隐含层节点数取200。
3.5 实验结果与分析
实验1 对比实验。为了更好体现出本文方法的优势,做了5组对比实验:1)SVM:使用TF-IDF( term frequency-inverse document frequency)[15]来表示微博语句,使用SVM算法进行情感分类;2)LSTM:使用Word2Vec构建词向量后,通过LSTM模型,再用SVM进行情感分类;3)LSTM+ATT:使用Word2Vec构建词向量后,通过引入注意力机制的LSTM模型,再用SoftMax进行情感分类;4)BiLSTM:使用Word2Vec构建词向量后,利用BiLSTM模型来提取文本的深度词向量特征,再用SoftMax进行情感分类;5)BiLSTM+CNN:使用Word2Vec构建词向量后,通过BiLSTM-CNN模型提取文本信息,最后使用全连接层进行分类[16]。实验结果如表3所示。
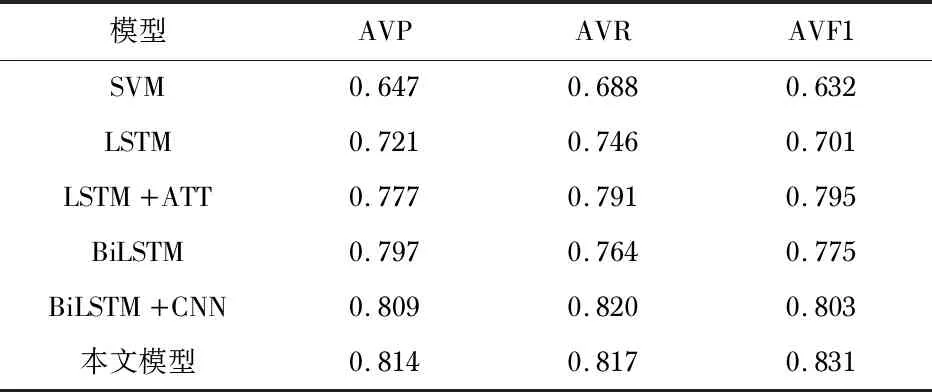
表3 NLPCC2013语料集不同模型比较
根据表3可以看出:方法(1)的分类效果最差,其AVP只有0.647,AVR只有0.688,AVF1更低只有0.632,这主要是因为TF-IDF算法提取关键词太依赖语料库。与方法(1)相比,方法(2)的各项指标要更高些。BiLSTM可以双向传输,显而易见,方法(4)比方法(2)在AVP上提升了7.6 %,在AVR上提升了1.8 %,在AVF1上提升了7.4 %。为了更好与本文方法进行比较,进行了方法(3)的实验,除了模型中LSTM的区别外,其它结构一样。实验结果表明,本文模型实现的各项指标高于方法(3),其中AVF1提升最高为3.6 %。方法(5)是在BiLSTM模型的基础上,将提取到的文本信息传入CNN中,得到比BiLSTM更好的分类性能,AVP,AVR,AVF1分别达到0.809,0.820,0.803。在所有的模型方法中,本文方法取得最高的平均精确率,达到了0.814,且AVF1值也是最高,达到0.831。
实验2 不同词向量维度。为确保参数最优化,另做了当词向量维度不同时AVP,AVR,AVF1值为多少的实验,结果如图3所示。
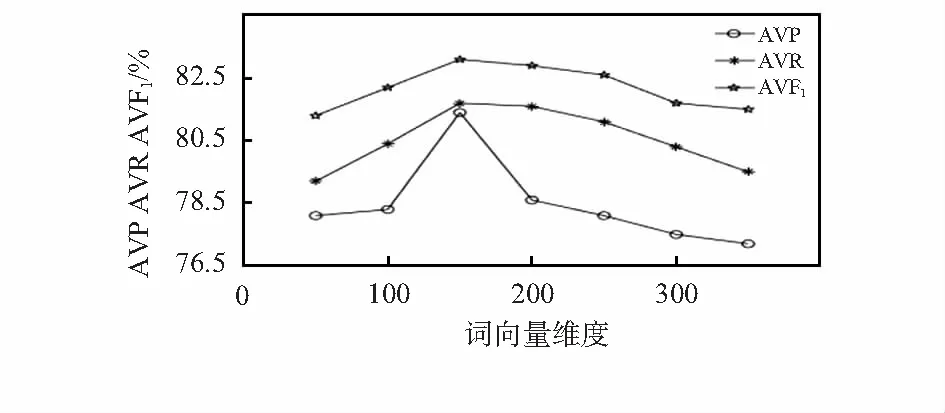
图3 不同词向量维度AVP,AVR,AVF1比较
从图3中可以看出:在词向量维度为150左右时变化趋势较大,150之后变化较为缓慢。AVP,AVR,AVF1在词向量维度变化时整体呈现出先增大后减小的趋势。当词向量维度达到150时,AVP,AVR,AVF1值最大,总体性能指标较好。
4 结束语
本文针对微博用户提出了一种新的文本情感分类方法,经过预处理后,使用Word2Vec词向量结合深度学习的方法,对微博用户的情感倾向进行分类,词向量维度达到150时,效果最好。本文还在NLPCC2013语料集的基础上,构建了一个新的带有微博用户情感信息的数据集。实验结果表明,本文提出的模型在NLPCC2013语料集上实现效果更好。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新校长(2016年8期)2016-01-10 06:43:59
新高考·高二数学(2015年11期)2015-12-23 18:17:44
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
商事法论集(2014年1期)2014-06-27 01:20:42
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
