
基于高斯混合模型的Web代理服务器缓存替换策略
2021-03-04 13:52:26杨福军
计算机测量与控制 2021年2期
唐 榜,吴 珏,杨福军,杨 雷
(1.西南科技大学 计算机科学与技术学院,四川 绵阳 621000; 2.中国空气动力研究与发展中心 计算空气动力研究所,四川 绵阳 621000)
0 引言
Web缓存技术通过将Web资源保存在缓存中,减少了网络拥塞和服务器资源的负载,有效地提高了网站的响应能力[1]。Web缓存技术充分利用了时间局部性原理,通过代理服务器缓存用户经常访问的 Web 资源,降低了用户访问时的页面响应延迟,属于主动缓存技术的一种。而缓存替换技术通过设定缓存阈值,当缓存的大小达到阈值时就会触发缓存替换策略,对缓存中的内容进行替换。因此,能够预测用户未来可能访问的资源,并提前将其放入缓存中的缓存预取技术得到了广泛的应用[2]。在仅使用缓存替换机制的服务器中,缓存的容量是制约Web响应速度的关键因素,面对大量Web访问时的缓存命中率一般都比较低。面对有限的缓存空间和大量的Web访问,基于空间局部性原理的缓存预取技术能够很好地弥补缓存替换算法的局限性,显著提高了缓存命中率,极大地降低了访问延迟。
缓存替换算法的准确性是决定缓存替换性能的关键。学者们对Web访问数据的很多特征进行了广泛研究,并利用这些特征和特性对Web缓存替换方法进行改进。文献[3]调研发现基于频率(过去对象的引用次数)、新近度(距最后一次引用所经过的时间)、大小(对象的大小)和成本(从服务器获取对象的延迟和带宽成本)的缓存替换方案效果更为理想。
目前,缓存替换算法一般分为两大类:一类是基于特征统计的方法,典型的有最近最少使用算法(LRU)、最少使用频次算法(LFU)、贪婪对偶大小算法[4](GDS,greedy dual size)和贪婪对偶大小频率算法[5](GDSF,GDS-frequency)等。其中,LRU算法会删除最近最少使用的对象,并将新的对象填入空出的缓存中。LFU算法会使用一个计数器来计算对象的使用频率,并删除最近最不频繁使用的对象。以上两种方法只考虑了对象的其中一个数据特征来进行缓存替换,适用场景单一,因此准确度较低。而GDS算法考虑了对象的局域性、大小、延迟、替换代价等因素,综合替换权值最小的对象。GDSF算法在GDS算法的基础上加入了频率因素,改进了GDS算法的性能。另一类是基于预测的方法,通过机器学习模型来预测会被再次访问的对象,并提前将其放入缓存中。文献[6]使用树朴素贝叶斯分类器对Web数据进行分类,预测可能被再次访问的Web对象,结合LRU算法提高了缓存替换的效率。文献[7]根据用户的访问日志提取多种特征作为训练数据集,通过训练SVM分类器将预测为不会再次访问的缓存对象删除以留出缓存空间。文献[8]提出了一种结合GDSF算法和支持向量机(SVM)重新访问概率预测的Web缓存替换策略。文献[9]提出了一种用来评估Web对象访问的空间局部性算法,提高了缓存替换策略的性能。文献[10]使用随机索引方法和权重分配策略机制的Web对象聚类的方法增强Web代理缓存的性能。
而高斯混合模型(GMM,gaussian mixed model)由多个高斯分布函数线性组合而成,理论上高斯混合模型可以拟合出任意类型的分布,因此在诸多领域都有应用。文献[11]使用神经网络与GMM相结合,学习点云的生成空间来生成新颖的点云形状。文献[12]使用GMM对医疗文本数据进行聚类分析,实现帕金森病的早期预测。
尽管一些工作使用机器学习模型通过固定窗口内的访问频率等特征对缓存替换模型进行训练,但是由于Web访问存在较高的时间相关性,将长时间内的访问频率及访问新近性作为特征进行缓存替换的方法,无法较好地捕获时间序列数据所拥有的时间相关性。而循环滑动窗口机制在处理时间序列数据上能够起到能够降低运算量、划分时间周期的作用[13-14],提高对时间序列数据的处理效果。
基于以上分析,本文采用基于循环滑动窗口的GMM模型对Web日志数据进行聚类分析,结合LRU缓存替换算法对缓存对象进行替换。利用循环滑动窗口策略学习一段时间内的Web访问数据特征,可以更好地捕获Web访问数据的时间相关性,从而使模型获得更好的预测结果。在进行缓存替换时,将GMM聚类分析预测的结果与LRU算法进行结合,在保证了较好的计算性能的同时,缓存替换的命中率也比传统算法更佳。实验结果证明了本文方法的有效性。
1 模型概述
高斯混合模型可以看作是由K个单高斯模型组合而成的模型。由于高斯分布具有良好的数学性质和优秀的计算性能,能够很好地刻画参数空间中数据的分布及其特性,在拟合数据分布时有很强的建模能力,因此在数据科学界被广泛使用。高斯混合模型结合了参数估计法和非参数估计法的优点,并使用了期望最大(EM,expectation maximization)算法进行训练。由于高斯混合模型使用多个高斯分布的组合来刻画数据的分布,在模型中的样本点足够丰富的情况下,任意精度上的连续分布都能被高斯混合模型所拟合。
当样本数据是一维数据时,高斯混合模型为每个类别下的特征分布都假设了一个服从高斯分布的概率密度函数如公式(1)所示:
(1)
其中:μ为数据均值(期望),σ为数据标准差(Standard deviation)。
当样本数据是多维数据(Multivariate)时,高斯分布遵从的概率密度函数如公式(2)所示:
(2)
其中:μ为数据均值(期望),∑为协方差(Covariance),D为数据维度。
高斯混合模型包含的K个子模型就是混合模型的隐变量(hidden variable,α1,α2,…,αk)。一般来说,一个混合模型可以使用任何概率分布,这里使用高斯混合模型是因为高斯分布具备很好的数学性质以及良好的计算性能。因此高斯混合模型的概率分布表示如公式(3)所示:
(3)
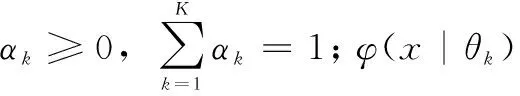
对于多维数据的每个观测点来说,由于事先不知道它所属的分布,因此无法使用最大似然法来求导获得使最大似然函数最大的参数。最大期望算法(expectation maximization algorithm, EM算法)是一种常用的高斯混合模型参数估计方法, 由Dempster等人于1977年提出,用于求解含有隐变量(Hidden variable)的概率模型参数的最大似然估计。在初始时随机生成K个高斯分布,然后不断地迭代EM算法,直至似然函数变化不再明显或者达到了最大迭代次数为止。因此,本文选择EM算法作为迭代算法对高斯混合模型的参数进行求解。
EM算法的迭代更新过程分为如下几步:
1)初始化参数:定义分量数目K,对每个分量k设置αk,μk和∑k的初始值。
2)E-step:在给定的多维高斯分布下,根据参数初始值或上一轮的迭代值来计算对数似然函数的期望及后验概率,计算每个数据j来自子模型k的可能性,如式(4)所示:
k=1,2,...,K
(4)
3)M-step:根据E-step中得到的后验概率计算新一轮迭代的模型参数,将似然函数最大化以获得新的参数值。计算过程如下:
(5)
(6)
(7)
4)计算对数似然函数:
(8)
5)检查参数或者对数似然函数是否收敛,若不收敛则返回第2)步。
2 基于GMM的缓存替换策略
2.1 Web缓存框架
图1展示了基于高斯混合模型的Web缓存替换算法框架。当代理服务器收到用户的访问请求后,用户与代理服务器进行通信,并将请求记录保存到日志文件中。代理服务器将收集的日志构建成数据集发送到预测模块进行数据预处理和预测[15]。文献[16]展示了高斯混合模型结合时间序列方法在处理具有时间特征的数据上有较好的效果。
预测模块的作用是将数据集中的数据进行预处理,经过数据过滤和特征提取等方式将得到的数据放入GMM预测模型进行学习,预测数据是否应该被放入缓存中。而替换模块的作用是统一管理缓存中的对象,根据缓存的请求命中情况,对缓存的内容进行替换。当代理服务器接收到用户的访问请求后,首先在缓存中检索是否存在用户请求的对象。若该对象存在,则直接返回给用户。若该对象不存在,则将请求转发至源服务器,获取到请求对象后由源服务器将该对象返回给用户。通过获取预测模块中GMM模型的预测结果,结合LRU缓存替换策略判断是否将用户请求的对象拷贝到代理服务器的缓存中,以提高缓存中Web对象的访问效率。
本文使用的GMM模型在获得日志数据后通过聚类分析计算每个Web对象被重新访问的概率,将可能被再次访问的数据替换到代理缓存中。当Web对象被标记为可访问时,结合其文件大小等特征将其分别放置在替换队列的不同位置,直到缓存未命中时通过LRU算法进行缓存替换。通过GMM对Web对象的预测结果来决定将其放在缓存队列的位置,以实现更为高效的缓存替换。算法1显示了基于高斯混合模型的缓存替换算法的具体流程。
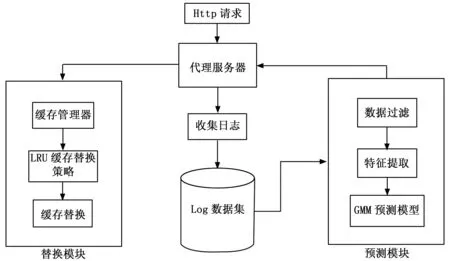
图1 基于GMM的缓存替换模块架构图
算法1:缓存替换算法
参数:Size为目标大小,Object为目标地址,CachedSeq为缓存队列,Capacity为缓存大小,Used_capacity为已使用的缓存大小,Will_visit为是否会再次访问。
1. If (Size > Capacity)
2.缓存未命中
3. Get Object // 从代理服务器获取Object
4. If (Object存在于缓存中)
5.缓存命中
6.将Object移动至CachedSeq的头部位置
7. End if
8. If (Object不存在于缓存中)
9.缓存未命中
10. End if
11. While (Size + Used_capacity > Capacity)
12.获取CachedSeq尾部节点
13.从缓存中删除尾节点存储的Web对象
14.更新CachedSeq
15. End While
16.通过GMM预测得到Object的Will_visit
17. If (Will_visit=1 && Size < Capacity*0.3)
18.将Object移动至CachedSeq的头部位置
19. Else if (Will_visit = 1 && Size >=Capacity*0.3)
20.将Object移动至CachedSeq的中间位置
21. End if
22. If (Will_visit=0)
23.将Object移动至CachedSeq的尾部位置
24. End if
2.2 特征提取
在代理服务器中, 用户访问信息会记录在代理日志中。Web日志文件中包含了多种访问信息,如用户IP地址、访问的URL及端口、请求方式、请求时间,访问对象字节大小等。但是数据中包含一定数量的无效数据(访问失败、地址失效等),因此需要对数据集进行预处理。一方面,将Web日志文件数据集进行了过滤, 去除不相关的访问及错误的Web请求,抽取有用的数据来进行特征提取。另一方面,Web数据集的构建是从日志代理文件中提取所需的信息,考虑到访问具有时序性,使用了循环滑动窗口机制对数据集进行了分段处理,从中提取并计算出可以用作聚类分析的特征。经过预处理后的具体参数如表1所示。

表1 预处理后的参数列表
其中:x1表示访问Web对象的时间,x2表示访问Web对象的地址,x3表示访问Web对象的大小,x4表示Web对象被访问的频次,x5表示Web对象上一次访问距离现在的时间差,若Web对象首次被访问,x5会被初始化为-1。以上参数均从原始数据集计算获得。而x6表示循环滑动窗口内Web对象最近一次访问的时间间隔 (Recency),x7表示循环滑动窗口内Web对象的访问频次。若Web对象在滑动窗口内首次出现,则x6初始化为滑动窗口的长度,x7初始化为1。x6和x7的计算方式如式(9)和式(10)所示:

(9)
x7=max[x7+1,1],ΔT≤SWL
(10)
其中:循环滑动窗口的长度设置为SWL,距离上次请求Web对象的时间间隔设置为ΔT。
3 实验结果与分析
在本文的实验中,采用了由实验室代理服务器收集的不同时段的用户访问日志数据。数据集1包含了该站点从17∶00到24∶00收集的约300 000条访问数据,数据集2包含了该站点从6∶00到13∶00收集的约130 000条访问数据。在这两个真实数据集上对本文提出的算法与4种传统缓存替换算法在对象命中率和字节命中率上进行了比较,验证了该算法的性能。在聚类算法的选择上,比较了几种聚类算法在对本文数据集进行聚类时所耗费的时间,证明了GMM模型在进行聚类分析时具有较好的计算性能。
3.1 实验设置
用户的访问请求被记录在代理服务器的日志文件中。当到达指定时间后,通过统计用户访问在缓存空间中的命中次数来获取访问成功的缓存副本。代理服务器的日志文件中包含了每条访问记录的条目,包括以下8个字段:日志标记、客户端端口号、请求时间戳、HTTP状代码、请求和响应报文的大小、URL地址、主机名和内容类型。本文通过循环滑动窗口机制对日志数据集进行了预处理,再去除掉非法访问、无效访问后的数据集。
为了探究循环滑动窗口的长度对不同时间段获取的数据特征的影响,使用本文的替换算法在1 M的缓存空间下对两个数据集进行了验证实验。实验将滑动窗口长度设置为0~1 000 s,0 s表示不设置滑动窗口,即使用全局时间长度来提取数据特征。实验结果如图2所示,可以发现,循环滑动窗口的设置在一定程度上提高了缓存替换的对象命中率。而由于时间段不同,用户访问频率也不同,在两个数据集上的滑动窗口长度分别设置为50 s和200 s时获得最高的对象命中率。本文在综合两个数据集的实验结果之后,决定统一选择100 s作为循环滑动窗口长度来进行后续实验。

图2 循环滑动窗口大小对对象命中率的影响
3.2 性能指标
对象请求命中率(HR,hit ratio)和字节命中率(BHR,byte hit ratio)是两个最常用的用来评估不同算法的缓存性能的测试指标。对象请求命中率是指缓存命中的请求次数占总请求次数的百分比,提高对象请求命中率的目的在于减少用户的响应时间。字节命中率是指缓存命中的请求对象字节数占请求对象总字节数的百分比。提高字节命中率的目的则侧重于降低网络通讯量,减少网络带宽开销。对象请求命中率和字节命中率的计算公式如下:
(11)
(12)
其中:Si为对象i的大小,Qi为命中对象i的请求数量,N为被访问的对象集合。
3.3 性能评估
在聚类算法的选择上,本文综合比较了K-Means聚类算法、Mini Batch K-Means算法、DBSCAN算法、GMM和Birch[17]算法的计算性能,实验结果如表2所示。可以发现GMM聚类算法在面对较大的数据集时,计算性能仅次于K-Means算法和Mini Batch K-Means算法。K-Means算法选择的初始聚类中心是随机的,在不同实验中可能产生不同的结果,不具备可重复性,因此并不适用于大型Web日志数据。Mini Batch K-means算法是K-Means算法的优化变种,训练时从数据集中随机抽取数据子集来减少计算时间,但是聚类效果也比K-Means算法稍差。DBSCAN算法是一种基于密度的聚类算法,其优点是对噪声鲁棒,能很好地拟合不同形状的数据。但是DBSCAN算法的聚类速度较慢,无法满足Web缓存替换的高效性需求。Birch算法只需一遍扫描数据集就能建立CF Tree,并且对噪声鲁棒,聚类速度也比较快。但是对数据集的分布要求较高,不适合具有高维特征的数据集。而GMM使用均值和标准差进行计算,使得簇的形状更加灵活。而且GMM给出的是数据集中的项分布在不同簇的概率,因此可以对从Web日志数据中得到的概率进行进一步的处理,得到更好的预测效果。因此,综合考虑了计算速度和Web日志数据的特点,本文决定采用GMM来对已访问的Web日志数据进行聚类划分。
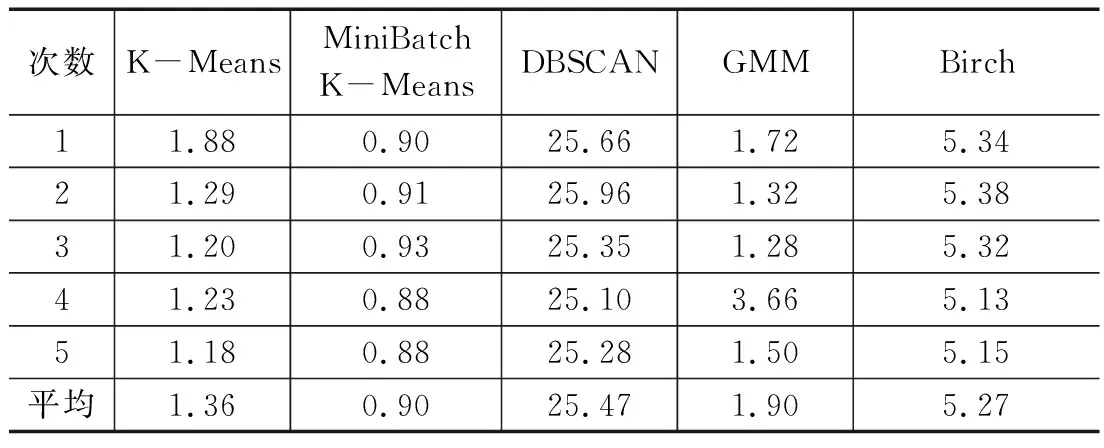
表2 不同聚类算法的训练时间对比 s
本文在两个数据集上使用了LRU、LFU、FIFO和GDSF作为对比算法,与本文提出的缓存替换算法在不同的缓存大小上进行了对比试验。实验结果如图3、图4所示。其中,图3显示了在数据集1上不同缓存大小下,各种替换策略的HR值和BHR值。图4显示了数据集2上不同缓存大小下,各种替换策略的HR值和BHR值。
观察模型在两个数据集上的实验结果,不难发现随着缓存大小的增加,缓存对象命中率和字节命中率也呈上升态势。当缓存较小时,各种替换策略的表现相差不大,缓存命中率都比较低。这是因为在缓存较小时,所能承载的缓存对象较少,在面对大量的用户访问时经常需要进行缓存替换的操作,因此缓存的命中率较低。当缓存大小增大时,由于FIFO、LRU和LFU在进行缓存替换时,使用的数据特征较为单一,因此即使使用了更多的缓存,其缓存命中率与使用多种特征进行缓存替换的GDSF相比始终处于劣势。与传统方法相比,本文提出的基于GMM的缓存替换算法始终有着较高的HR值和BHR值,这说明使用了基于GMM的聚类分析后得到的预测结果对缓存内容进行替换,有效地提高了缓存的命中率,显著地改善了Web代理服务器的缓存效果。
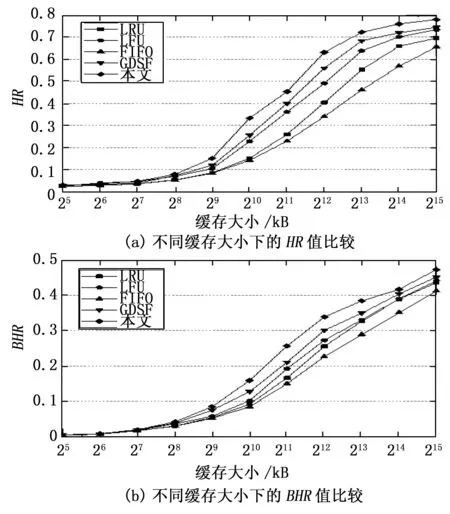
图3 数据集1上的HR值和BHR值
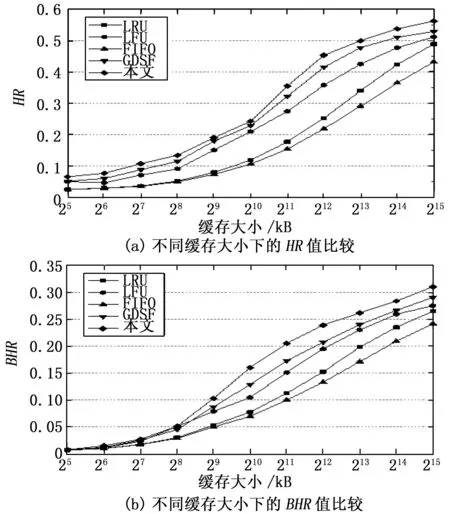
图4 数据集2上的HR值和BHR值比较
4 结束语
本文提出了一种基于GMM访问预测机制的Web缓存替换策略。在原有数据的基础上,使用循环滑动窗口机制提取时序特征,根据用户之前的访问日志构建包含多项特征的数据集,利用GMM对数据进行聚类分析,预测当前缓存对象是否会再次被访问。实验结果表明,本文提出的缓存替换策略相比于传统方法具有较高的命中率, 显著提高了Web服务器的缓存效果,缓解了网络访问延迟和网络拥塞问题。在接下来的研究中,将在本文的基础上,根据用户的访问行为构建用户兴趣模型, 从而得到更全面、更有效的预测算法。
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
铁道通信信号(2018年11期)2019-01-19 01:15:06
中国生殖健康(2019年11期)2019-01-07 01:27:44
长江丛刊(2018年31期)2018-12-05 06:34:20
网络安全和信息化(2018年4期)2018-03-04 00:20:39
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
NBA特刊(2017年8期)2017-06-05 15:00:13
梧州学院学报(2015年3期)2015-02-28 17:55:16
电子设计工程(2014年19期)2014-02-27 12:00:42
