
融合多种特征的舆情时序文本情感分类方法
2021-03-03 06:47王素格杨文琦张文跃
山西大学学报(自然科学版) 2021年6期
王素格,杨文琦,张文跃
(山西大学 计算机与信息技术学院,山西 太原 030006)
0 引言
随着互联网的快速发展,人们在网络上发表各种观点和言论,这些观点和言论大部分带有发帖者的主观感情色彩和发帖时间,若获取这些富含时间和情感的信息,将有助于对包含时间信息的主观时序文本的情感倾向性判断。时序情感分类任务与传统的情感分类任务的不同之处是人们的情感可能会随时间的变化而变化,导致情感分布具有不稳定性。例如,2019新型冠状病毒(COVID-19)感染的肺炎疫情的话题,众多网民参与疫情相关话题的讨论。表1为新浪微博中关于疫情的几条真实数据,它反映了人们情感的变化。疫情初期,由于不明原因的肺炎患者在武汉出现,舆论以负面情绪居多。随着中央全力部署、政府防控措施出台(实时数据的公布、武汉实行封城管控)、专家学者释疑解惑(钟南山院士、张文宏医生等对疫情的判断),舆论的走向开始出现变化,人们对战胜疫情充满希望,舆论中的负面情绪开始消退。

表1 情感变化示例Table 1 Cases of sentiment changes
为了有效处理情感分布不断变化的舆情时序文本数据,本文借鉴He等人[1]的方法,并将其与一个领域自适应方法[2]相结合,提出了一个基于特征融合的舆情时序文本情感分类模型TTSCM(Temporal Text Sentiment Classification Model based on Feature Fusion)。该模型利用半监督学习方法[3]得到当前时刻的特征,并与历史特征相融合,丰富了文本的特征表示。在真实的数据集上的实验结果表明,本文的方法与传统的文本情感分类方法相比,在舆情时序文本情感分类任务上取得了较好的效果。
1 相关工作
按照文本是否带有时间标签,将文本分类任务分为静态的文本情感分类和动态的时序文本情感分类。
静态的文本情感分类任务主要采用有监督、无监督和半监督的机器学习方法。Pang等人[4]采用有监督分类方法对电影评论进行情感分类,Turney[5]采用基于语义倾向的无监督情感分类方法。在有监督的情感分类任务中,训练集和测试集的数据分布往往存在差异,导致在训练集上训练的模型在测试集上效果不佳。为此,研究者使用领域自适应的方法去解决。DANN(Domain—Adversarial Training of Neural Networks)模型[6]是一种被广泛使用领域自适应的模型,该模型使用了对抗网络学习源领域和目标领域的公共特征,用于提升目标领域分类的泛化效果。在跨领域的情感分类任务上,Whitehead等人[7]通过各领域的词典来计算领域之间的相似度,并基于领域相似度,集成若干来自不同源领域的分类器。Bollegala等人[8]通过在所有可用数据上构建情感敏感性词典,用于扩展在训练和测试时的特征向量,丰富文本的特征表示。Sanju等人[9]通过加入维基词典,构建了增强的情感敏感性词典来拓展特征向量。Du等人[10]改进了最先进的BERT(Bidirectional Encoder Representations from Transformers)模型[11],额外添加了一个领域分类任务,为模型注入了目标领域的知识。
对于时序文本数据,由于文本数据的类别分布不断变化,传统的机器学习方法无法对时序数据保持较高的鲁棒性。对于无监督学习,Wang等人[12]提出了一种用于处理时序数据的低秩核矩阵分解的聚类通用模型。Xu等人[13]提出了一种自适应聚类方法,通过跟踪目标之间随时间变化的相似性再进行静态聚类。对于有监督学习,Huang等人[14]将不同时间段的数据看作不同领域的数据,将训练数据所在的历史时刻视为源领域,测试数据所在的当前时刻视为目标领域,借鉴领域自适应的方法,从词语的语义变化[15]入手,训练不同历史时刻的词嵌入,将一个句子表示为多个时刻的词向量输入Bi—LSTM(Bidirectional Long Short—Term Memory)模型,最终得到句子的向量表示。Zhu等人[16]还利用了霍克斯过程[17—18]对时序文本数据进行建模,并融入了用户和主题信息,用于预测下一条文本的标签和其出现的时间。He等人[1]在不同的历史时刻上训练文本分类器,并将它们的参数固定,作为一个特征抽取器来抽取句子在该时刻的特征,并将这些特征进行融合,以丰富当前时刻的句子特征表示。但该方法忽略了目标域中的数据信息,无法利用目标域中大量无标注数据。因此,本文尝试利用半监督学习,将目标域上的无标注文本数据融入文本情感分类模型中,以提升文本情感分类模型在目标域上的性能。按照先前的工作[6—8,10,14],本文将训练集视为源领域,测试集视为目标领域。
2 融合特征的时序文本情感分类模型
假设有一组序列数据X={X1,X2,…,Xt},其中,Xi表示在第i时刻的数据集合,,x表示第i个时刻的第j条数据,y表示第i个时刻的第j条数据对应的标签,Ni表示第i个时刻的数据大小。我们的目标是利用t时刻之前的数据{X1,X2,…,Xt-1},训练一个在t时刻数据Xt上表现较好的分类模型。
一般情况下,我们需要利用历史文本数据训练文本情感分类模型,并在未来文本数据上测试情感分类的效果。然而,在舆情时序文本数据中,人们的情感会随着时间的推移发生变化,导致历史数据(训练集)和未来数据(测试集)的分布不一致,进而使模型的泛化能力下降,这种分布不一致现象也体现在训练集内部。当训练集包含多个历史时刻的数据,它们的情感分布随时间的变化是缓慢的,相近时刻之间的数据分布相似度较高,反之,则越低。为了使模型学习到文本情感分布的变化过程,并在时间顺序上逐步逼近未来文本数据(测试集)的情感分布,本文设计的融合特征的时序文本情感分类模型TTSCM包含两个部分:特征扩充和特征融合。
2.1 特征扩充
本文受 Hal[2]在序列标注任务和 Huang 等人[14]在时序文本上所做工作的启发,将时序文本情感分类任务等价于一个多源域的跨领域学习问题,将领域分为源域、目标域和综合域。其中,源域是训练集所在的领域,目标域是测试集所在的领域,而综合域则是两者的结合。在时序情感分类任务中,1到t—1时刻的数据对应多个源域,t时刻的数据对应目标域,所有时刻的数据都对应综合域。如图1所示,图中的圆代表对应时刻的数据集。
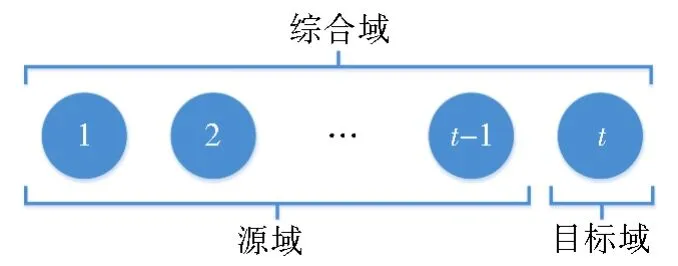
图1 源域、目标域和综合域的关系图Fig.1 Relationship among source domain,target domain and general domain
基于神经网络的分类器可分为两个部分[6]:特征抽取层(Extraction Layer)和标签预测层(Prediction Layer)。特征抽取层对输入数据进行特征变换,抽取出深层的特征表示;标签预测层再对这些特征表示的样本进行预测,得到该样本属于每一类的标签概率。
BERT作为最近被广泛使用的预训练语言表征模型,它可以生成一定深度的语言表示,并用于多种下游任务中。本文使用BERT模型外加一个输出层作为基线分类器,称之为基于BERT的文本情感分类模型,该模型的多层Transformer结构为特征抽取层,额外的输出层为标签预测层。特别地,基于BERT的文本情感分类模型的输入序列第一个字符为特殊分类嵌入为[CLS],它是模型的最终隐藏状态的聚合序列表示,可以作为输入句子的表示向量送入输出层,用于预测句子的标签。
由于源域中多个时刻的数据之间往往并不是相互独立的,它们在时间上存在一种递进关系。因此,不能简单地将所有时刻数据整合,仅训练一个基于BERT的文本情感分类器。由于基于BERT构建的分类器可以在特定任务数据上进行微调,并将数据信息融入模型中,使输入的文本表示适应特定任务的向量表示。因此,我们在多个源域中的每个时刻i的数据上训练一个基于BERT的文本情感分类器,共训练t—1个分类器,记为BERTi(i=1,2,…,t—1)。这些分类器在结构上完全相同、参数上不同。第i时刻的文本数据可以保存到对应时刻的BERTi中。与简单地训练一个单一的分类器相比,通过训练多个分类器,使其更充分地利用历史数据,并使不同时刻的文本数据保存在对应时刻的模型中。
目标域是模型最终进行分类的领域,如果能够利用目标域中的信息,将有助于提升模型在目标域中的分类性能。因此,我们借鉴了半监督学习的思想,利用t时刻之前的数据{X1,X2,…,Xt-1}去训练一个分类器BERT<t。首先使用分类器BERT<t为目标域数据Xt打上伪标签,得到目标域伪数据Xt’后,再在Xt’上训练一个分类器 BERTt,用于获取目标域的文本表示。此外,将源域数据和目标域伪数据结合,构建综合域数据{X1,X2,…,Xt-1,Xt’},其目标是在一定程度上扩充综合域的数据。在综合域的数据上训练一个综合域的文本情感分类器,记为BERTg,用于获取更全面的数据特征。至此,我们共训练了t+1个分类器,分别为t—1个源域分类器{BERT1,BERT2,…,BERTt-1}、1个目标域分类器BERTt和1个综合域分类器BERTg。
2.2 特征融合
由于时序数据本身在时间上存在一种递进关系,我们认为在第2.1节中训练的t+1个分类器之间也应存在一种时序上的关系。而GRU[19](Gate Recurrent Unit)是一种用于处理序列数据的神经网络,它在序列数据的演进方向上可以递归计算所有节点,这符合我们处理t+1个分类器的初衷,即在时间维度上连接所有分类器中的特征抽取层。同时,GRU也是LSTM的一个变体,二者在多数情况下表现比较相近,但GRU相较于LSTM更易训练和计算,因此,本文选用了GRU建模这种时序上的关系。模型结构如图2所示。
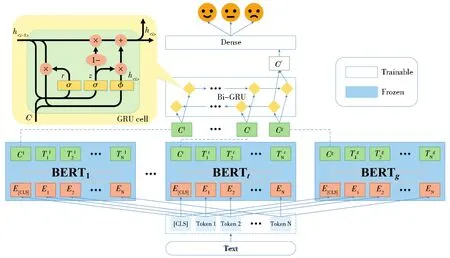
图2 基于特征融合的时序情感分类模型Fig.2 Temporal sentiment classification model based on feature fusion
为了获取一个句子在t时刻精确的向量表示,可以利用在t时刻之前的历史文本数据预测句子在t时刻的向量表示。即利用2.1节中分类器的特征抽取层(BERTi),获得句子在多个历史时刻的向量表示{C1,C2,…,Ct—1},再利用 GRU预测出t时刻的向量表示Cf。特别地,为了全面的预测Cf,我们加入目标域分类器BERTt和综合域分类器BERTg,获取句子在目标域的伪特征Ct以及综合域特征Cg。最后一个句子被表示成t+1种向量表示{C1,C2,…,Ct—1,Ct,Cg},并将其输入一个双向GRU中,以获取句子的最终向量表示Cf。
在图2中,每一个时间步BERTi输出的聚合序列表示Ci和上一个时间步的隐藏状态h<i—1>被输入到一个GRU节点中。节点中包含重置门控单元rj(Reset Gate)和更新门控单元zj(Update Gate),门控状态的计算方式如下:
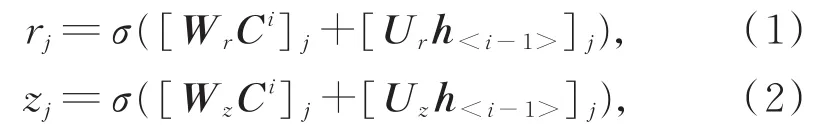
其中,σ是sigmoid函数,[.]j表示一个向量的第j个元素,Wr、Ur、Wz和Uz是权重矩阵。
计算候选隐藏状态h͂<i>j:

公式(3)中使用重置门rj控制保留了前一个时间步的信息。最后,通过更新门zj更新隐藏状态:

需要说明的是更新门zj可以控制遗忘前一时间步的信息,并记忆当前时间步的信息。
我们将双向GRU网络中的最后一个时间步中两个方向上的隐藏状态<t+1>和<t+1>拼接,作为文本的最终向量表示Cf,见公式(5):


最终,Cf被输入一个全连接层,用于预测句子的情感极性,见公式(6):需要说明的是,双向GRU和最后一层全连接层中的参数是固定所有BERTi参数之后,在所有历史数据上训练所得,而所有分类器BERTi在2.1节中已经训练完毕。
上述提到的所有需要训练的模型都使用交叉熵作为损失函数。
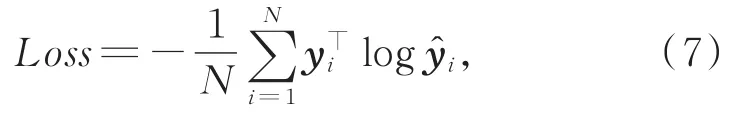
其中,N表示数据个数,K表示标签个数,y表示数据的真实标签,表示模型预测的标签。
3 实验
3.1 实验数据及设置
本文使用的数据集是北京市经济和信息化局、中国计算机学会大数据专家委员会联合主办的大数据公益挑战赛(疫情期间网民情绪识别)公开的与“新冠肺炎”相关的微博数据。赛方没有公开测试集,我们使用公开的10万条有标注的训练集作为实验数据集。数据集中含有三种情感标签,分别为正面、中性和负面情感。数据集的时间跨度是从2020年1月1日到2020年2月19日,我们将数据集按照时间平均分成5个组,每组数据的时间跨度是10天。为了消除不同时间段之间由于数据量不同而造成的实验差异,我们统一了所有时间段的数据量,并按照8∶1∶1的比例把每个时间段的数据划分为训练集、验证集和测试集。
划分数据集是为了模拟一种可能的现实应用场景,即利用t时刻之前的数据去预测t时刻的数据的标签,记为{1,2,…,t—1}→t。我们共设计了 4组实验:{1}→2、{1,2}→3、{1,2,3}→4 和{1,2,3,4}→5。划分后的数据集概况如表2所示。
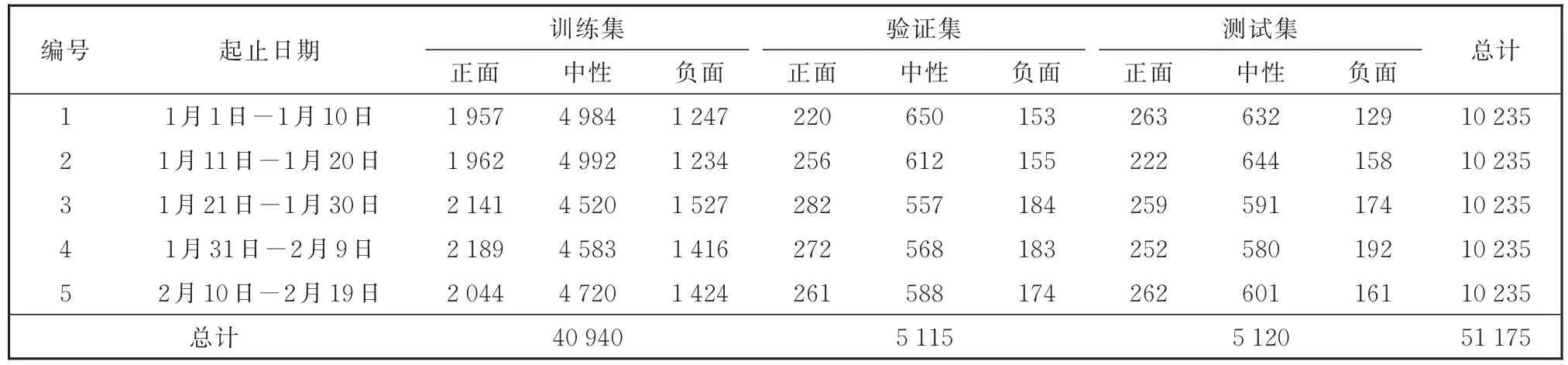
表2 数据集概况Table 2 Overview of dataset
在本实验中,BERT模型部分既是初始化词向量的工具,也是我们模型中特征抽取层。实验中的主要参数设置为最大句子长度为100;GRU隐藏层维度为 300;Dropout参数为 0.1;Batch大小为 64;学习率为0.000 05。模型的评价指标采用准确率(Accuracy),即预测正确的样本数和总样本数之比。
3.2 基线方法
为了验证本文所提方法的有效性,我们选择如下的基线方法进行比较。
·BERT:直接在BERT后加一层输出层,建立基于BERT的文本情感分类模型。该模型在所有可用的数据上训练模型,忽略时间信息。
·NTAM[15]:该模型在文本中每一个词末尾添加时间标签作为后缀,并利用fastText[20]将时间信息融入词向量中,通过一个BiLSTM网络学习了历史的文档表示。
·NTAMBERT:由于NTAM使用fastText作为词向量,为了公平起见,以便和本文模型进行比较,我们对NTAM进行了修改,将模型词向量的部分由fastText改为BERT,称之为NTAM—BERT。
·BERTDP:DP[1](Diachronic Propagation)框架将一组在连续时间步上训练的分类器进行串联,把历史时刻上数据的信息传递到当前时刻,并与当前时刻的特征结合。本文将基于BERT的文本情感分类器放入到DP框架中,称之为BERTDP。
3.3 不同时间片段的文本情感分类实验结果
本实验利用方法BERT、NTAMBERT、BERTDP与本文的方法TTSCM,在5个时间段{1,2,3,4,5}中,选择{1}→2、{1,2}→3、{1,2,3}→4 和{1,2,3,4}→5四种时间段的变化情况进行对比实验,实验结果如表3所示。
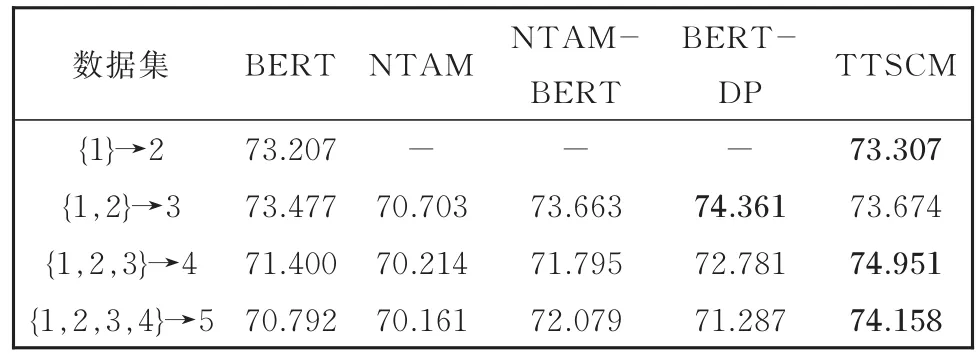
表3 四种方法的比较实验结果Table 3 Results of comparative experiment for four kinds of methods
由表3可以看出:
(1)除了在{1,2}→3数据集上的BERT—DP方法,在多个数据上,本文的方法TTSCM均超过其他基线方法。
(2)随着历史时刻数量的增加,本文方法TTSCM在分类性能上均有明显提升,说明TTSCM较好地利用了多个历史时刻的数据来提升模型在未来时刻的表现。NTAM—BERT的实验结果与TTSCM类似,也是随着历史时刻数据的增加,提高愈显著。
(3)TTSCM与NTAM模型结构类似,其结果优于NTAM—BERT和NTAM,表明TTSCM的优越性不仅来源于BERT,也体现在TTSCM模型本身。
(4)BERT—DP方法在第二组数据集上效果最好,而当历史时刻增多时,该方法的提升效果不够明显,这表明DP框架在传递较远时刻的信息时,效果不佳,而TTSCM则克服了这一缺点。
3.4 消融实验
为了分析模型对不同领域数据分类影响,我们设计了TTSCM—源域、TTSCM—目标域和TTSCM—综合域方法进行消融实验,它们分别是去掉了源域、目标域和综合域的BERT模型,也去掉相关的特征表示部分,得到各个特征表示下的实验结果如表4所示。
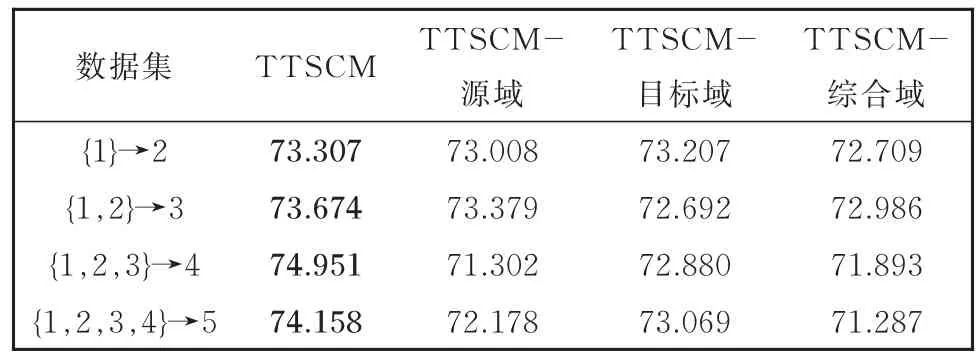
表4 消融实验结果Table 4 Results of ablation experiment
由表4可知:
(1)在各组数据集上文本情感分类结果显示,TTSCM—源域、TTSCM—目标域和TTSCM—综合域,移除任一领域的特征后模型的分类效果都有所下降。可见,所有领域的特征对于模型的性能均有一定支持作用。
(2)移除综合域的特征后,TTSCM—综合域的文本情感分类模型的效果下降是最大的,说明综合域中包含的特征是最全面和最丰富的。移除源域后,文本情感分类模型的效果有所下降,说明除了直接利用所有数据,利用历史时间的特征以及分段重复利用各时段数据,可以提升文本情感分类模型的性能。移除目标域会造成文本情感分类模型性能下降明显,从而也验证了利用半监督学习方法引入目标域的信息对文本情感分类是有效的。
3.5 不同时段数据训练模型的性能分析
为了验证舆情时序数据的情感分布是否随着时间变化而变化,且这种变化又是否会影响到文本情感分类模型的性能。根据先前对于数据集的划分,将各时段的分类模型训练的样本数量保持一致,以避免训练集大小影响第5时段的分类结果。我们在5个时间段的数据上进行了对比实验,在第1到第5时段数据的训练集上分别训练一个BERT分类模型,在对应时段的测试集和第5时段的测试集上进行测试。实验结果如图3所示,其中,图3中的横轴表示在对应时刻的数据上训练的模型编号。

图3 各模型在各时段数据上的表现Fig.3 Performance of each model on the data of each period
从图3中可以看到,各模型在对应时段上测试的性能都优于在第5时段上测试的性能,且各模型在第5时段上的准确率是不一致的,且随着时间接近目标时刻的时间而增加。这表明舆情数据中存在着数据漂移的现象,这种现象会在一定程度上影响模型的性能。TTSCM模型利用了舆情数据中的时间信息,并按照时间顺序融合了各阶段特征,相较于忽略时间信息而简单整合历史数据的方法(例如,基线方法中的BERT方法),在测试集上可以获得更好的性能表现。因此,时间信息在建立情感类别漂移检测模型时是必不可少的,可在一定程度上提升文本情感分类模型对舆情数据的鲁棒性。
4 结论
本文提出一个面向舆情数据的时序文本情感分类模型,该模型利用在多段时间连续的数据上训练多个BERT模型,并使用了一个GRU网络按照时间顺序融合文本表示。我们的方法借鉴了半监督学习的思想,获得了部分目标域的伪数据,并将目标域信息和更丰富的综合域信息引入分类模型中,同时,也利用了舆情数据中的时间信息。通过多组实验结果验证了我们的方法在性能上优于多个先进的文本情感分类模型。此外,该方法也可以扩展到其他类似的且与时间信息关联的分类任务中。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
计算机系统应用(2021年2期)2021-02-23
意林·作文素材(2021年23期)2021-01-22
软件导刊(2017年4期)2017-06-20
