
基于Worker 权重差分进化与Top-k排序的结果汇聚算法
2021-02-28 04:45邢玉萍詹永照
通信学报 2021年1期
邢玉萍,詹永照
(1.江苏大学计算机科学与通信工程学院,江苏 镇江 212013;2.江苏省工业网络安全技术重点实验室,江苏 镇江 212013)
1 引言
众包[1]利用群体Worker 的智慧解决问题,已成为数据处理的有力机制,特别是非结构化数据,如图像、视频和文本,出现了使用人工完成数据处理的任务,包括排序[2]、聚类[3]、最大值求解[4]、过滤[5]和去重[6]等。
目前,传统的数据库管理系统和搜索引擎难以较好地完成排序任务,例如对全球大学排名排序、某领域权威论文排序,原因有以下几点。1) 相对封闭世界的假设,即数据都已存储在数据库里,不在数据库里的数据就是不存在的,并且数据库中缺少明确标注的相关信息,不能根据模糊标准进行匹配、排序或聚合结果。但是互联网环境下信息量急剧增加,未存储在数据库的数据并不意味着不存在,人们有能力在多个搜索引擎和参考资料等工具的帮助下,找到目前没有的信息。2) 缺乏对语义的理解,特别是排序任务,并不能很好地从数据库中将相关信息提取出来自动排序。但是,人们却比较擅长这些计算机很难或者不可能完成的任务。
快速获得高质量的解决方案是众包请求者的目的。完成任务的Worker 主要来自普通大众,一般不具有提供高质量解决方案的特征,因此请求者通常采用任务冗余发放的算法,将相同任务发放给多个Worker,然后对Worker 的提交结果进行汇聚得到合适的解决方案。发布排序任务一般有2 种形式:1) 将任务拆分成微任务,以成对比较的形式进行分发,利用推理减少任务量,这种方式在任务量大时任务拆分困难、代价大、完成时间和完成质量难以保证[7];2) 直接发布该排序任务,由不同Worker 独立完成。由于不同Worker 在不同专业领域可能具有不同水平,有的甚至无法完成某些任务,为了得到高质量的汇聚结果,需要从有噪声的答案中推断出高质量的结果。结果汇聚算法的优劣直接决定任务的完成质量,一般以二次众包或者统计算法自动完成。常用的基于统计的结果汇聚算法包括Listwise 算法和数据融合算法,这2 类算法都考虑了待排序对象的排名/位置信息。
Listwise 算法将一个任务下的所有数据项的排序结果列表作为一个训练样例,全面考虑一个任务下不同数据项之间的序列关系,优化目标是输出的汇聚结果和输入的提交结果损失函数最小或者性能最优。文献[8]指出,合适的众包Worker 约占Worker 总数的55%,其平均准确率约为75%,因此,基于Listwise 的结果汇聚算法容易受到不合格Worker(如恶意Worker 和搭便车Worker[9])提交结果的影响,从而降低汇聚结果的质量。Listwise算法的模型复杂度和训练时间的长短依赖于待排序数据项的数量阶乘,训练复杂度很高[2]。
数据融合算法的优化目标是汇聚结果的性能最大化。线性组合(LC,linear combination)算法是一类有监督的数据融合算法,其一般流程为:首先多个Worker 给出训练任务中待排序数据项的全排序结果,然后选择模型依据标注信息训练出所有Worker 的优化权重向量,最后用该权重向量对测试排序任务进行结果汇聚。文献[10-11]分别使用遗传算法和差分进化算法获得优化的权重向量,但是这类基于演化计算的算法解决众包结果汇聚任务存在以下2 个问题。
1) 即使是合格的Worker,也很难给出所有数据项的准确全排序,排序结果会存在很多噪声,并且增加Worker 的额外负担。实际应用中,Worker能够很快给出Top-k数据项,例如,在图像检索任务中,给定1 000 张餐馆的照片,希望找到最吸引人和最能描述该餐馆的Top-k照片。使用基于Top-k的排序可以降低任务难度,Worker 能在给出更准确的排序结果的同时,甄别出不合格的Worker。如果Worker 在训练任务的Top-k排序上是不合格的,那么该Worker 在测试任务上依然是不合格的。
2) 基于演化计算的算法即使在排序列表很短的情况下,在解空间寻优依然是NP-hard 问题,存在耗时过长的问题,不能有效应用于实时性要求较高的结果汇聚场合。相比全排序,基于Top-k能快速学习出各Worker 的权重。
针对上述2 个问题,本文提出基于Worker 权重的差分进化和Top-k排序的结果汇聚算法。该算法更合理地考虑各个Worker 的差异性和不确定性,且快速有效地提高汇聚结果的质量。这项研究具有较好的理论意义和现实价值。
本文主要的研究工作如下。
1) 建立众包排序任务结果汇聚的Worker 权重优化模型,实现Worker 权重与任务对结果性能需求匹配的最大化。针对多任务分配中众包Workrer完成排序任务存在差异性问题,基于目标函数和约束条件中Worker 完成任务的不确定性和差异性影响,建立基于差分进化算法的Worker 权重优化模型,获取多数据项场景下候选结果最优权重。该模型是一个非凸、非线性、多元优化问题,很难直接获得最优解。
2) 提出基于Top-k排序的优化模型求解算法。针对多数据项场景下候选结果的Top-k排序选取,在合适的k值下可快速对1)中模型求解,获得各Worker 的优化权重。所提算法可实现结果汇聚的匹配性与匹配速度优化,即在提升结果汇聚速度的同时,具有优化的汇聚结果性能。通过定性分析证明算法的正确性。
3) 仿真实验结果表明,所提算法在大幅提升结果汇聚速度的同时,具有优化的汇聚结果性能。与相关算法对比,所提算法综合性能最优。
2 相关工作
近20 多年来,数据融合在物联网[12]、信息检索/Web 搜索、众包[13]、推荐[14]等多个不同的研究领域和应用中得到了广泛的研究和应用。研究者致力于数据融合算法的研究,提出了一系列算法,如无监督的CombSUM[15]和CombMNZ[15]算法,有监督的LC 算法[16]。权重分配是影响LC 算法汇聚结果性能的最主要的因素。
文献[17]首先提出将LC 算法用于文本数据融合,将各个提交结果的性能作为LC 算法的权重,然而实验结果表明该权重分配策略并不优于使用相同权重的CombSUM 算法。文献[18]使用共轭梯度优化各个提交结果的权重,最大化汇聚结果性能,该算法的不足在于非常耗时、仅能够汇聚2~3 个提交结果、针对指定任务各个提交结果仅返回前15 个数据项。文献[19-20]基于多元线性回归模型优化各个提交结果的权值,实现汇聚结果性能的最大化。文献[21]提出ProbFuse 算法,该算法根据数据项在排序列表中的位置估计数据项的相关概率。文献[22]利用各个提交结果性能的幂函数作为权重分配策略优化汇聚结果的性能,并提出混合权重分配权重模式(权重是性能和差异性的乘积)优化汇聚结果的性能,该算法的不足在于数据项更新快的环境下效率较低。文献[23]提出基于神经网络的权重分配策略。文献[24]基于聚类算法提出ClustFuse 算法。文献[25]基于期望最大化算法提出MixModel 算法。文献[26]基于深度神经网络提出Lambda-Merge 算法。文献[27]基于无监督的RRF 和Condorcet 算法提出具有低复杂度的融合算法。文献[28]基于数据项的相似性,使用CombSUM 和CombMNZ 算法进行结果汇聚。
文献[10]提出GA-Fusion,采用遗传算法在权重空间寻找各个提交结果的最优权值,实验结果表明,GA-Gusion 的性能优于前面所提的数据融合算法,包括CombSUM、CombMNZ、Z-score、LC、LC2、多元线性回归、MixModel、ClustFuse、LambdaMerge 等。文献[11]采用基于差分进化算法寻找最优权值提高汇聚结果性能。文献[29]提出面向多样性任务基于性能、差异性和互补性的线性加权融合算法,实验结果表明所提算法并不优于DE 和GA 算法。
文献[10-11]采用基于演化学习的算法,通过不断地迭代优化权值提高汇聚结果的性能,然而,这种基于演化学习算法的不足在于求解时需要在解空间进行大规模的探索,运行时间很长,不能满足一些实时性要求高的应用场景的要求。本文研究众包排序任务实时结果汇聚问题,能够既快又好地获得汇聚结果。
3 系统模型和框架
LC 算法按各Worker 提交结果的贡献度赋予权重,将2 个或多个排序列表进行线性组合融合在一起,生成一个单一排序列表[28]。因此,如果一个提交结果具有良好的性能,或者对最终汇聚结果性能的提升起到了重要作用,那么在结果汇聚时被赋予较大的权重;反之,则被赋予较小的权重。
假设有m个Worker 节点,分别用w1,w2,…,wm表示,对于给定任务q,各Worker 节点wi提交一个结果列表,对所有提交结果进行汇聚得到汇聚结果πq。由于各个Worker 排序具有不确定性,各个Worker 的排序质量有好有差,因此引入衡量多Worker 排序质量的权重xi(1≤i≤m)表示数据项的排序结果更确定的得分。在多个Worker 参与的众包排序任务q中,对数据项(1≤j≤mq)的融合排序应以多个Worker 对数据项的排序得分进行加权考虑,从而得到更确定的排序结果。因此数据项融合排序得分可表示为

以所有任务汇聚结果π={πq|1≤q≤|Q|}的平均精度均值(MAP,mean average precision)性能最优原则进行融合排序优化,建立目标优化函数为

其中,X=[x1,x2,…,xm]T表示各个Worker 的权重向量;D={τi|i∈[1,m]}表示各个Worker 的提交结果集合,Dq表示所有Worker 第q个子任务的提交结果集合,rk(X,Dq,t)函数返回汇聚结果排序为t的数据项,汇聚结果排序以式(1)由X对Dq得分加权融合得到;ldt表示数据项dt标注得分,正确为1,否则为0;I{·}表示指示函数,I{true}=1,I{false}=0;M q表示任务q汇聚结果中相关数据项总数,mq表示该任务汇聚结果数据项总数,|Q|表示子任务q的数量。
式(2)的任务是找到权重向量X*使汇聚结果π的MAP 性能最优,由于π根据权重向量X加权得分降序排序,而优化目标使用π中数据项的位置信息,因此该优化函数是一个非凸、非线性、多元优化问题,无法直接对X求导,也不能使用基于梯度下降的相关算法求最优值,因此,采用基于差分进化算法(DE,differential evolution)和Top-k排序的结果汇聚算法计算式(2)的最优值,将优化目标映射为DE 算法的适应度函数f(X)的最大值,即

其中,mq的取值需依据Top-k中的k值设定。利用DE 良好的寻优性能求解最优权重向量X*和最优汇聚结果π。
利用上述模型以及已有m个Worker 在|Q|个任务的提交结果,按照式(2)的优化模型训练出各个Worker 的权重,根据式(1)得分降序排序获得汇聚结果。基于DE 和Top-k排序的结果汇聚框架如图1所示。请求者将训练排序任务嵌入真实排序任务发布到众包平台,平台将任务分配给多个Worker 独立完成,Worker 努力工作后向平台提交结果。平台收到所有提交结果后通过训练任务学习优化的Worker 权重向量X,将X用于真实任务的结果汇聚,得到优化的汇聚结果。平台向请求者提交汇聚结果后,请求者向各个Worker 支付相应报酬。
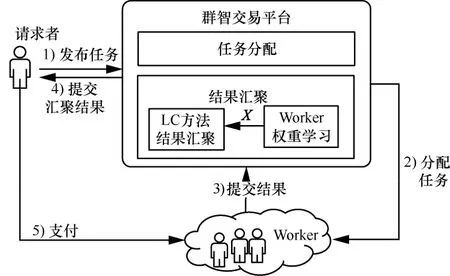
图1 基于DE 和Top-k排序的结果汇聚框架
4 算法设计
训练任务中使用差分进化算法基于Top-k排序相比全排序进行Worker 权重学习优点明显,其潜在假设是:1) Top-k排序上的训练和全排序上的训练一样好;2) Top-k排序上的运行速度相比全排序上的运行速度有显著提高。因此,为了验证假设的正确性,对Top-k排序和全排序的基于差分进化的结果汇聚算法进行理论和实验分析。在分析之前,首先介绍基于Worker 权重差分进化与Top-k排序的结果汇聚算法。
DE 是一种基于向量的适者生存、优胜劣汰算法[30],由NP(种群规模)个m(参与汇聚的Worker人数)维参数个体X(权重向量)在搜索空间进行并行搜索,基本操作包括变异、交叉和选择。假设工作者wt(1≤t≤m)的提交结果为τ t,则τ t的Top-k排序表示为=
算法1DE-k算法


算法种群初始化操作中,种群个体Xi,g在可行解空间内随机取值,由于LC 算法赋给各个Worker的权重区间为[0,1],且参与汇聚的所有Worker 的权重和为1,因此各Worker 的权重初始取值为

其中,xi,j表示个体Xi,g中第j个Worker 的权重,rand()函数返回[0,1]的随机数。步骤1)~步骤5)根据随机生成的初始种群进行结果汇聚,生成最优权重向量初值。步骤8)~步骤15)对上一代种群中的每个个体执行差分变异和交叉操作。步骤16)为选择操作,选择原个体向量Xi,g和实验个体向量Ui,g+1中适应度值大的个体进入下一代种群,从而保证经过一次迭代后种群总体性能得到提升。为了保证解的有效性,即在进化过程中保证每个个体中的元素满足。步骤 17)对Xi,g+1中元素使用Sum-to-1[31]算法进行归一化处理,即
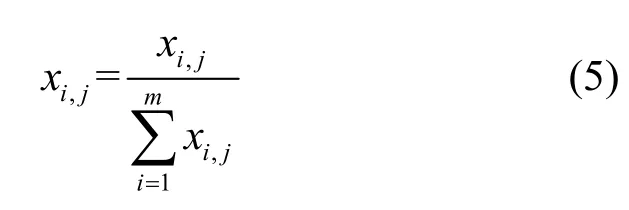
步骤18)更新最优权重向量X*。步骤21)利用最优权重向量X*使用LC 算法得到最优汇聚结果。
5 性能定性分析
5.1 汇聚结果性能分析
Top-k学习在信息检索、信息过滤、物联网、信息安全、众包[32]等领域均有广泛的应用。文献[33]从理论和实验2 个方面验证基于Top-k排序能够获得和全排序同样的训练效果,并指出随着k的增长,测试算法的性能迅速增加到一个稳定的值,例如,当k=10 时,Ranking SVM、RankNet 和ListMLE 这3 种算法性能达到稳定;当k=20 时,RankBoost 性能达到稳定。
文献[10]通过实验表明,Top-k包含了用户最关注的信息,仅用Top-k排序作为基于遗传算法的权重学习的训练集合,与全排序作为训练集合相比性能并没有显著降低。此外,Pal 等[34]发现,如果每个任务仅选择Top-k数据项作为实现TREC 评价池的依据,那么评估的质量不会受到影响,即排在Top-k的数据项含有丰富的信息,较好地代表了长列表形式结果的性能。当使用MAP 等位置相关的评价指标进行评估时,这一点会更加突出,并且,MAP 仍然是评价排序问题中重要的性能指标。
LC 算法按各个Worker 提交结果的重要性赋予该Worker 相应的权重,并未更合理地考虑各个权重的进一步优化。所提模型考虑Worker 完成排序任务存在不确定性和差异性问题,以目标函数和约束条件中Worker 完成任务的不确定性和差异性影响为基础,建立基于DE 算法和Top-k的Worker 权重优化模型。该模型综合权衡各个Worker 的提交结果,利用DE-k算法迭代求解,确定各个Worker的优化权重,提高汇聚结果的性能,使融合结果MAP 性能最优,因此DE-k算法求解后确定的优化权重向量能达到优化的汇聚结果。
综上所述,通过Top-k排序包含的丰富信息和DE 算法良好的寻优性能,DE-k算法可实现优化的汇聚结果性能。
5.2 时间耗费与汇聚性能权衡分析
基于DE-k的结果汇聚算法中,用m表示参与结果汇聚的Worker 人数,k表示提交结果列表的长度,NP 表示种群规模,G表示迭代次数。该算法的时间复杂度为O(mkNPG),其与变量m、k、NP、G都成正比关系。因此,降低m、k、NP、G能够降低结果汇聚的运行时间,但是参与汇聚的Worker 人数m和种群规模NP 选定之后不再发生变化,一般采用对DE 算法进行剪枝和降低G的迭代次数来减少结果汇聚的运行时间,而忽略了降低k减少权重向量的学习时间。全排序优化将花费大量的训练时间,而基于Top-k选择适当的k可加快速度。例如,Worker 提交结果τ的长度为1 000,取k=10 参与权重的训练,则理论上运行速度提升约1 000/10=100 倍,而汇聚结果性能接近高性能;若原提交结果列表越长,则结果汇聚运行时间降低越多,即DE-k算法可提升结果汇聚速度。
5.1节和5.2节的定性分析证明了DE-k算法在获得优化的汇聚结果性能的同时可提升结果汇聚的速度。
6 实验结果分析
6.1 数据集及对比算法
实验数据集为TREC-10 和TREC-11 的Routing filtering Task 的提交结果集。TREC-10 Routing filtering(简称TREC-10)共有84 个Topic。TREC-11 Routing filtering 共有100 个Topic(前50 个和后50个Topic),分别由专业和非专业评估人员评估,为了更准确地描述汇聚后结果的性能,将该结果集分成2 个结果集,标记为TREC-11A 和TREC-11B,每个结果集分别有50 个Topic。
仿真数据集包括TREC-10 的13 个提交结果和TREC-11 的8 个提交结果。详细信息如表1~表3所示,按照提交结果的MAP 值降序排列。评价指标为MAP、P@10 和召回率(RP,recall precision)。

表1 TREC-11A 提交结果性能

表2 TREC-11B 提交结果性能

表3 TREC-10 提交结果性能
对比算法为CombSUM[14]、CombMNZ[14]、基于DE 的结果汇聚算法[11]、基于粒子群优化的结果汇聚算法、基于粒子群优化和Top-k排序的结果汇聚算法、基于遗传算法的结果汇聚算法[10]、基于遗传算法和Top-k排序的结果汇聚算法[10]。
6.2 实验结果和分析
下面,分别在 TREC-11A、TREC-11B 和TREC-10 数据集对不同算法的汇聚结果进行分析和比较,并从3 个方面验证所提算法在数据集上综合性能最优:相同迭代次数下不同算法结果汇聚的性能和运行时间的分析与对比、不同迭代次数下不同算法结果汇聚性能和运行时间的分析与对比,以及高性能系统的比较。
6.2.1 相同迭代次数下不同算法结果汇聚的性能和运行时间的分析与对比
本节实验中,训练在每个子任务的提交结果Top-k分别为10、25、50、100 和1 000(全排序)处进行,而测试在汇聚结果排序深度为1 000(全排序)处进行。使用5 折交叉验证,迭代次数都为200。PSO-k和GA-k(k∈{10,25,50,100})分别表示使用基于粒子群优化算法和Top-k排序的结果汇聚算法以及基于遗传算法和Top-k排序的结果汇聚算法。DE、PSO 和GA 表示使用提交结果的全排序作为训练集,分别基于差分进化算法、粒子群优化算法和遗传算法的结果汇聚算法。BR 表示所有Worker 中MAP 性能最优的提交结果。CombSUM和 CombMNZ 分别表示使用 CombSUM 和CombMNZ 算法进行结果汇聚。除了BR、CombSUM和CombMNZ,表4 中的数据都是8 次单独实验结果的平均值,其中加粗数据表示该列最优的3 个值。
表4 数据表明,以MAP 为性能评价指标,所有结果汇聚算法的性能都优于最优Worker 的提交结果(BR);DE-k和PSO-k性能相似,优于GA、GA-k、CombMNZ、CombSUM;DE-k、PSO-k和GA-k算法分别与DE、PSO 和GA 算法相比,性能损失分别为[0.98%,4.01%]、[0.15%,3.42%]和[0,9.65%],这些数据表明,基于Top-k的结果汇聚相比全排序性能损失不明显;DE-k性能优于PSO-k、GA-k,具有较好的稳定性,且在其他性能指标P@10 和RP 下也具有上述相似的结论。
运行时间包括数据装载、权重学习和结果汇聚的运行时间。表5 中数据为表4 中不同算法对应的运行时间。以运行时间为评价指标,全排序下,DE、PSO 和GA 完成一次结果汇聚至少需要3 h 以上,且数据集越大,运行时间越长,不能满足实时结果汇聚的要求;DE 算法和GA 算法运行时间相似,远低于PSO 算法的运行时间;CombSUM 算法和CombMNZ 算法不需要权重学习,运行时间最短。当k=10 时,在TREC11-A 和TREC11-B 数据集中,DE-10、PSO-10 和GA-10 在51~64 s 内完成结果汇聚,相比全排序速度提升191~380倍;在TREC-10数据集中,3 种算法分别在16.4 min、19.7 min 和17.6 min 完成结果汇聚,相比全排序速度分别提升20 倍、38 倍和18 倍,偏离预计的100 倍左右(1 000/10)。通过对CombSUM 和CombMNZ 算法运行时间分析发现,这2 种算法的运行时间分别是3.1 min 和6.5 min,原因在于较大的数据集数据装载耗费时间较多。当k分别为25、50 和100 时,具有相似的结论。实验结果表明,DE-k运行时间相比PSO-k、GA-k运行时间少;随着k值的减小,运行时间显著减少,当k=10 时,DE-10 的运行时间在3 个数据集上相比全排序分别降低了98.6%、99.6%、95%,大幅降低了运行时间。
上述实验结果表明,基于Top-k排序的优化模型求解算法,在合适的k值下可快速得到性能好的汇聚结果,但是性能略有损失,原因在于使用较少的基本事实进行训练评估。其中,DE-k算法从性能和运行时间两方面在3 个数据集上具有显著的优势,综合性能最优。

表4 汇聚结果的性能
6.2.2 不同迭代次数下不同算法结果汇聚的性能和运行时间的分析与对比
表4 和表5 中数据表明,基于Top-k排序是加快结果汇聚运行时间的有效算法,但是该算法的运行时间仍远高于不需要权重训练的CombSUM 和CombMNZ 算法的运行时间。

表5 结果汇聚的运行时间
图2~图4 和表6 中数据都是采用5 折交叉验证、8 次实验的平均值,迭代次数分别为25、50、100、150 和200,观察迭代次数对不种算法的汇聚结果的性能和运行时间的影响。

图2 TREC-11A 中不同算法在不同迭代次数下汇聚结果性能
图2~图4 表明,①不同迭代次数下,以MAP为性能评价指标,DE、PSO、DE-10 和PSO-10 始终优于GA、GA-10、BR、CombSUM 和CombMNZ;DE-10 和DE 稳定性最好,随着迭代次数的增加,性能越来越好;当迭代次数达到100 时,DE 超过所有算法的性能,DE-10 优于PSO-10、GA-10、BR、CombSUM 和CombMNZ。②不同算法的性能折线波动不明显,说明迭代次数从200 次减少到25 次的过程中,性能变化不大,而DE-10 变化最小;DE-10 在3 个数据集、迭代次数为25 次的汇聚结果的性能分别是200 次迭代汇聚结果性能的99.98%、99.93%和99.33%。其他算法也具有相似的结论。上述结果表明,随着迭代次数的减少,DE-10 的性能下降不显著。

图3 TREC-11B 中不同算法在不同迭代次数下汇聚结果性能

图4 TREC-10 中不同算法在不同迭代次数下汇聚结果性能
表6 数据表明,所有算法的运行时间和迭代次数呈线性关系,运行时间随着迭代次数的减少而线性减少。基于Top-k的DE-10、PSO-10 和GA-10进行 25 次迭代的运行时间在 TREC-11A 和TREC-11B 数据集中为9~12 s,在TREC-10 数据集中为9.6~12 min,相比200 次迭代的运行时间得到显著下降,满足任务结果汇聚实时性的要求。
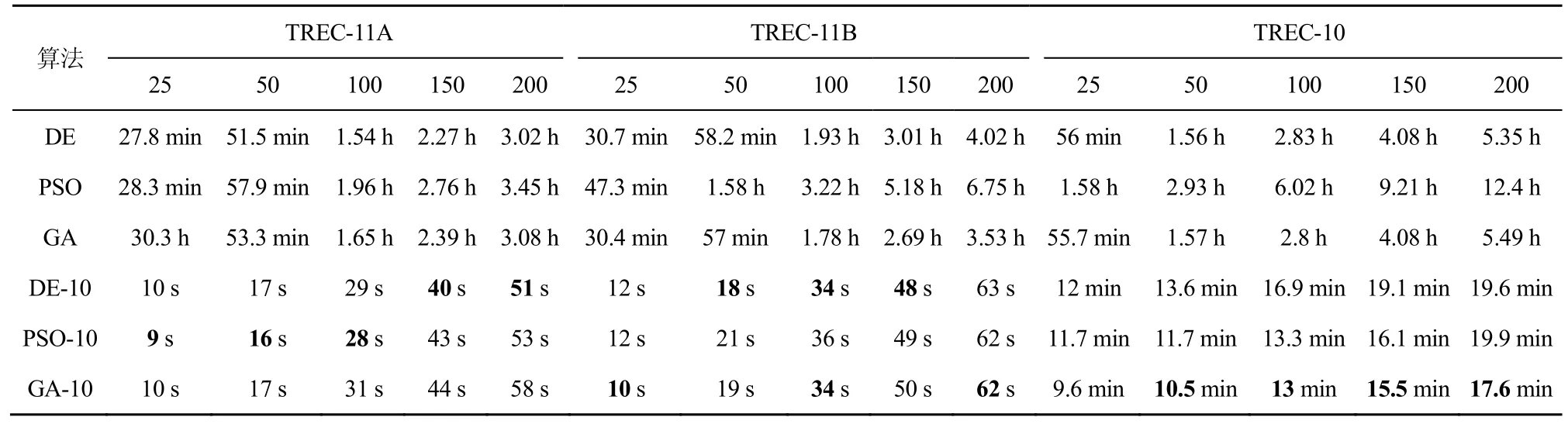
表6 不同迭代次数下不同算法结果汇聚的运行时间
综上所述,DE-10 通过降低迭代次数,以性能轻微损失为代价,显著降低运行时间。相比PSO-10和GA-10,DE-10 在保证高质量的汇聚结果的前提下达到了实时结果汇聚的要求。
6.2.3 和高质量提交结果的性能分析与对比
自2002 年TREC-11 会议以来,信息过滤技术飞速发展,目前查到的最新关于使用TREC-11 数据集进行实验的文献是2015 年Yang 等[35]发表的。该文献使用最大匹配模式主题模型MPBTM 大幅提高系统的MAP 性能。将MPBTM 作为高质量专家提交结果,并与本文算法进行对比,如图5 所示。
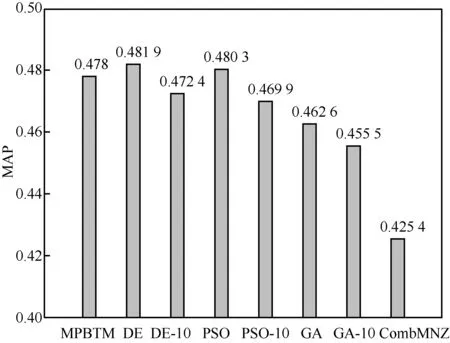
图5 高性能系统和文中算法性能对比
以MAP 为性能评价指标,MPBTM 的性能是0.478,优于BR 的0.369,相比BR 提高29.54%,也优于CombSUM、CombMNZ、GA、GA-10 和PSO-10 的性能,低于DE 和PSO 的性能,略高于DE-10 的性能,即DE-10 相比MPBTM 性能下降不显著。但是DE 和PSO 耗时过长,而基于Top-k训练的DE-10 却能够实现实时结果汇聚,即通过汇聚多个低质量的提交结果能够达到高质量专家提交结果的性能。
综上,本节验证了DE-k能够实现对多个低质量提交结果进行结果汇聚得到高质量的提交结果,同时满足实时性要求,相比其他算法,综合性能最优。
7 结束语
本文针对众包Worker 完成任务存在一定的不确定性和差异性,并考虑在提升结果汇聚质量的同时又具有较快的汇聚速度,提出了基于Worker 权重的差分进化和Top-k排序的结果汇聚算法。该算法首先对训练任务所有结交结果的Top-k排序通过基于差分进化算法的优化模型学习Worker 优化的权重向量,然后基于优化的权重向量使用LC 算法对真实任务进行结果汇聚。该算法在权重学习阶段,仅在信息足够丰富且更确定的Top-k数据项集合中进行,相比全排序,可以减少训练噪声,大幅减少运算量,提升权重学习的速度。结果汇聚阶段利用优化的权重向量进行加权汇聚,可避免Worker的差异性而提升结果汇聚质量。所提算法在获得优化的汇聚结果性能的同时,能够提升结果汇聚速度。定性分析证明了所提算法的正确性,仿真实验结果也验证了所提算法效果,与相关算法对比,所提算法的综合性能最优。
猜你喜欢
小型内燃机与车辆技术(2022年3期)2022-08-11
心理学报(2022年5期)2022-05-16
计算机与数字工程(2021年6期)2021-06-29
名家名作(2021年4期)2021-05-12
当代陕西(2020年17期)2020-10-28
科普童话·学霸日记(2020年1期)2020-05-08
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
小天使·一年级语数英综合(2019年2期)2019-01-10
人大建设(2018年5期)2018-08-16
