
车载边缘计算中任务卸载和服务缓存的联合智能优化
2021-02-28 04:45刘雷陈晨冯杰裴庆祺何辞窦志斌
通信学报 2021年1期
刘雷,陈晨,冯杰,裴庆祺,何辞,窦志斌
(1.西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2.中国电子科技集团公司第54 研究所,河北 石家庄 050081)
1 引言
作为交通强国的重要抓手,车联网在国家发展战略中起着举足轻重的作用[1-3]。随着车联网的飞速发展,车辆变得愈发普及和智能化。由此,催生了一大批车载应用,涵盖信息服务、行驶安全和交通效率各个方面[4-6]。这些应用服务在给人们生活带来便利的同时,将会造成数据的几何增长,增加了网络的负荷,对网络带宽提出了更高的需求。车载边缘计算通过把移动边缘计算应用在车联网,可以实现计算和存储能力的下沉,能够极大缓解网络的带宽压力,有效降低任务的响应时延[7-8]。
在复杂的车载网络环境下,为了保障大量用户多样化的服务需求,亟须设计有效的车载边缘计算机制[9]。利用计算卸载技术,用户可以把任务卸载给具有丰富资源的边缘节点计算,有助于响应时延的减少。然而,现有的车载计算卸载工作,在用户端往往集中在本地处理,未能充分发掘邻居车辆的资源,而在边缘端大多侧重于计算资源的管理,忽视了其与服务缓存之间的关系。特别地,边缘端服务器为了计算用户卸载的任务,需要具备一定的计算资源,也需要提前缓存相应的服务应用。换言之,计算卸载和服务缓存彼此关联,相互耦合。考虑到路边设施存储资源的限制,如何通过服务缓存的决策保障计算卸载的质量是要解决的重要问题。鉴于车联网的动态、随机和时变特性,需要引入更加智能的算法实现网络通信、计算和缓存资源的有效管理,以应对传统数学方法的不足[10]。
针对以上问题,本文首先设计了纵向和横向协同的智能车载边缘计算网络架构,然后通过分析网络通信、计算和服务缓存资源之间相互作用的机理,提出了通信、计算和服务缓存资源的联合优化模型,进而利用异步分布式强化学习实现了任务的灵活卸载和资源的智能管理。
2 相关工作
区别于一般的移动网络[11],车联网的典型特点在于车辆的快速移动。车辆的移动会导致网络拓扑的动态变化,决定车间的连通特性,从而影响任务的正常卸载。为此,车载边缘计算需要和车辆的移动性密切结合。文献[12]考虑网络负荷和任务卸载,研究了多服务器多用户场景下的资源管理。每辆车通过移动可以将任务选择性地卸载给期望的边缘服务器。文献[13]呈现了一个移动模型用于设计链路稳定性指标。基于该指标可以发现任务车辆周边可用的服务车辆,从中可以挑选满足任务车辆偏好和服务需求的车辆作为最优的服务提供者。不同于传统计算卸载工作主要考虑通信和计算资源的调度,文献[14]设计的基于车辆移动的卸载机制同时也考虑了任务卸载时间的决策。特别地,任务车辆与服务器之间的数据传输速率随两者之间的距离动态变化,由此影响了任务的卸载时间。
在车载环境下,路边单元广泛部署于路测,通常作为主要的边缘服务器节点参与用户任务的处理。文献[15]考虑车辆的移动及其与关联的边缘服务器的连接时间,研究了负载卸载和任务调度问题。文献[16]提出的双端优化问题旨在同时保障用户端和服务器端的利益。以上工作主要侧重于单服务器场景,文献[17-18]则聚焦于多服务场景。文献[17]提出了具有高可靠性、低时延的车–设施通信架构,优化了车和基站的耦合及无线资源的管理。文献[18]的任务卸载机制则同时优化了服务器和传输模式的选择。
鉴于车联网的复杂特性,人工智能算法以其巨大的优势也被用于车载边缘计算,以实现资源的智能管理。文献[19]利用Q–学习算法实现闲置车辆资源和服务器资源的管理,以加强用户的服务质量。文献[20-21]均通过深度Q–学习联合优化了网络的通信、计算和缓存资源,旨在提升系统的整体收益。文献[22]则利用深度确定性策略梯度算法实现任务的调度和资源的管理,最大程度保障移动运营商的收益。
以上工作主要集中在车载计算卸载方面,忽视了车辆资源的发掘和服务缓存对计算卸载的影响。相比于文献[12-18],文献[19-22]虽然采用智能方法实现任务的调度,但依然存在一定的局限性。为此,本文提出了计算卸载和服务缓存智能联合优化算法。
3 系统模型
本文构建了一个边缘智能驱动的车载网络架构,如图1 所示。该架构包括三层,即用户层、边缘层和云层,特点介绍如下。
纵向协作。用户层位于网络的最底端,主要由车辆组成。部署于道路一侧的路边单元配置相应的边缘服务器,作为边缘层的关键节点。特别地,在边缘层引入智能模块,协助实现资源的有效管理和任务的灵活决策。云层位于网络的最上端,具有丰富的计算和存储资源。在用户和边缘服务器资源受限的情况下,云层可提供必要的资源支持。
横向协作。当车辆有任务处理时,可以选择本地执行并通过邻居车辆计算任务,还可利用车–设施通信方式交由路边单元协助处理。路边单元的资源往往在空时维度分布不均:轻负载的服务器资源会呈现闲置状态造成浪费,过负载的服务器则对应接不暇的任务捉襟见肘。为此路边单元之间可以加强横向协作,通过任务迁移的策略,最大化网络资源的利用率。
移动感知。由于高速的移动性,车辆可能频繁地在不同的路边单元之间切换。所以,需要能够基于对车辆移动行为的分析对车辆的轨迹准确定位,以便路边单元将计算结果顺利反馈给车辆。
假设M个路边单元均匀分布于道路一侧,组成集合M。每个路边单元配备一个计算能力为Fj、存储资源为Sj的服务器。N个车辆自由移动在道路上,组成集合N 。每个车辆i携带一个任务,该任务可以表征为{di,ci},其中,di表示输入数据的大小,ci表示该任务的计算量。路边单元通过有线方式互联。用户与路边通过无线通信方式进行交互。车辆本地的卸载决策用xi0表示,其中,xi0=1表示车辆在用户侧处理任务;车辆边缘的卸载决策用xij表示,其中,xij=1表示车辆将任务卸载给路边单元j处理。特别地,当车辆执行边缘卸载处理时,优先邻近关联的路边单元。如果当前关联的路边单元负荷较重,则可以由该服务器将任务迁移至周边的路边单元。这样有利于负载均衡,提升资源的利用率,从而加强用户的服务体验。对于每个路边单元,为了实现任务的处理,需要安装相应的服务应用。换言之,当其存储了相应的服务应用,即缓存决策wij=1时,路边单元j能够处理车辆i卸载的任务;否则它需要从云端下载该应用,从而带来了额外的时延开销。
3.1 移动模型
定义δab为相邻车辆a 和b 的连通时间,R为车辆的通信范围。令va(t)和vb(t)分别为两车在t时刻的速度,(xa(t),(ya(t))和(xb(t),(yb(t))分别为两车在t时刻的坐标。那么,两车的连通时间可以表示[23]为

其中,当φ=−1、ϕ=1时,后车a 和前车b 同向行驶,且前车速度小于后车;当φ=1、ϕ=1时,后车a 和前车b 同向行驶,且前车速度大于后车;当φ=−1、ϕ=−1 时,车辆a 和车辆b 位于不同车道且相向行驶;当φ=1,ϕ=−1 时,车辆a 和车辆b位于相同车道,且反向行驶。
3.2 通信模型
车–车通信模型。车–车通信采用基于分布式协调功能(DCF,distributed coordination function)的IEEE 802.11p 协议。车辆利用CSMA/CA 机制竞争信道。令E[sn]表示成功传输一个数据所需要的平均时隙数目,E[sl]表示每个时隙的平均长度。那么,在车辆i和相邻车辆k之间成功传输一个数据所需的平均时延[24]为

车−设施通信模型。任务车辆在执行边缘卸载时,通过车−设施通信方式将任务上传给路边单元,其中通信采用LTE-V2X 协议。定义hi和Bi分别为车辆与路边单元之间的信道增益和信道带宽。令ρi表示用户的传输功率,σ2表示传输的噪声。那么,根据香农定理可得,数据的上传速率为

3.3 缓存模型
路边单元执行车辆卸载任务的前提在于其预先安装了所需要的服务应用。考虑到存储空间的有限性,路边单元不可能缓存所有需要的服务应用。定义路边单元j的存储大小为Cj,任务车辆i服务应用的大小为,则有式(4)成立。

3.4 计算模型
任务车辆可以通过用户层计算和边缘层卸载2 种方式处理任务。下面,对两者的时延性能分别进行分析。
3.4.1 用户层计算
为了充分利用车辆资源,任务车辆除了可以在本地处理任务外,还可以借助其通信范围内的邻居车辆实现任务的计算。定义fi为任务车辆i自身的计算能力。那么,车辆i通过本地计算方式处理自己任务所需要的时间可表示为

定义Ni为车辆i通信范围内的车辆集合。当任务车辆利用其邻居车辆k∈Ni计算任务时,时延包括任务在两车之间的传输时延、任务在邻居车辆的计算时延和结果的反馈时延。这里,本文忽略结果的反馈时延。对于传输时延而言,根据式(2)可求得平均传输时延tik;对于计算时延来说,通过式(5)可以求得平均计算时延。
综上可得,完成任务车辆任务计算所需要的最小时延为

约束条件为

其中,约束条件是为了保障选定的邻居车辆能够在两车有效通信时间δik内完成任务的处理和反馈。
3.4.2 边缘层卸载
当任务车辆执行边缘卸载时,一般包括以下阶段:任务上传、任务执行和结果反馈。本文忽略结果反馈的时延假设任务车辆i选择卸载的路边单位为j,分别对不同阶段的时延进行分析。
任务上传阶段。车辆i首先把任务上传给当前关联的路边单元si,该过程的传输时延取决于任务的大小和数据的传输速率。由式(3)可得

任务执行阶段。根据所选定卸载服务器的位置,任务执行分为以下2 种情况。
情况1路边单元si和j相同。该情况下,任务在当前路边单元计算。如果路边单元存储了计算该任务所需的服务应用,则可以直接计算任务,所需时延取决于任务的算力需求和路边单元分配的计算资源;否则,还要考虑从云端下载相应服务应用的额外时延。综上,完成任务计算所需要的时间为

其中,fij表示路边单元给车辆分配的算力。
情况2路边单元si和j不同。该情况下,需要考虑任务在两者之间的迁移时延。路边单元之间通过有线链路连接。假设si和j之间存在个链路,而每个链路的平均传输时延为tone-link,那么,任务在2个路边单元之间的迁移时间为。结合式(8),可得完成任务处理所需要的时间为
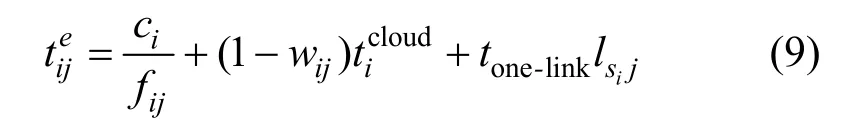
结果反馈阶段。一旦选定的路边单元完成任务的处理,就需要将结果反馈给车辆。由于移动性,需要考虑车辆此时是否可能驶出了起初关联的路边单元。因此,可将任务在上传和执行阶段的时间Tij与车辆在起初关联服务器传输范围内的时间做比较。其中,取决于用户驶出服务器通信范围的时间和移动速度的比值。如果,可将结果首先传输给该路边单元,然后反馈给车辆;否则,需要对车辆的移动定位,判断当前位于哪个路边单元,以便将结果传输给该服务器,进而反馈给车辆。
3.5 计算卸载和服务缓存联合优化模型
本文旨在动态、随机和时变的车载环境下,面对有限网络资源和不同用户需求之间的矛盾,通过计算卸载和服务缓存资源联合优化,在保障用户服务需求的前提下,最小化系统整体的处理时延。鉴于此,设计目标函数如下
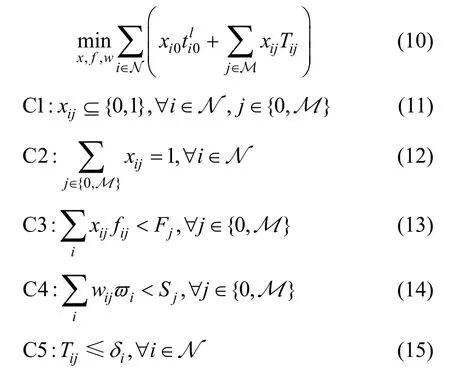
其中,x={xij},w={wij},f={fij}。根据式(6)~式(9),可分别得到和Tij。这里,假设车辆分配的带宽资源一样。限制性条件C1 表示每个任务有用户层处理和边缘层卸载2 种处理方式;C2 表示每个任务仅在一个地方执行;C3 表示服务器的计算资源限制;C4 表示服务器的缓存资源限制,其中,ϖ i表示执行任务所需要的服务应用的大小;C5 表示车辆卸载给路边单位的任务应该在其离开关联的服务器传输范围之前完成,其中,δ i表示用户和其关联的服务器的连接时间,取决于用户驶出服务器通信范围的时间和移动速度的比值。
4 基于异步分布式强化学习的问题求解
鉴于车载网络的动态性、随机性和时变性,人工智能算法相比于传统数学方法更适合资源的管理和任务的调度。相比较而言,Q–学习需要维护Q表格,不适应于具有较多状态的网络。深度确定性策略梯度算法需要利用经验回放机制消除训练数据间的相关性。对于经验回放机制来说,代理在与环境的每次交互都需耗费较多的资源,而所采用的离策略学习方法只能基于旧策略生成的数据进行更新。所以,考虑利用异步优势的actor-critic 算法减少算法执行所需的开销,同时基于实时的网络环境提供最优的卸载决策和资源管理。
利用异步优势的actor-critic 算法对系统环境建模,需要确定其状态空间、动作空间和奖励函数,具体如下。
状态空间。状态空间S由车载网络的计算资源和缓存资源组成,S={F1,F2,…,FM,S1,S2,…,SM}。其中,Fi和Si分别表示路边单元i的计算能力和存储能力。
动作空间。动作空间由车辆的卸载决策、路边单元的缓存和计算资源管理组成,A=(xi,wi,fi)。其中,xi、wi和fi分别代表车辆i的卸载决策、路边单元存储和计算资源管理的集合,xi={xi0,xi1,…,xiM},wi={wi1,wi2,…,wiM},fi={f i1,fi2,…,fiM}。
异步优势的actor-critic 算法中的公共神经网络包括多个线程,每个线程具有和公共神经网络一样的2 个模块:策略(actor)网络和评价(critic)网络。actor 网络用于优化参数为θ策略π(at|st;θ);critic 网络尝试估计参数为θ v的价值函数V(s t;θ)。在时刻t,actor 网络基于当前状态st执行动作at,得到奖赏rt并进入下一个状态st+1。
利用优势函数A(at,st)表示动作价值函数Q(at,st)和状态价值函数V(st)的差值,如式(16)所示。

其中,a表示动量,Δθ表示损失函数的累计梯度。
RMSProp 算法可以通过式(23)进行梯度下降的更新。
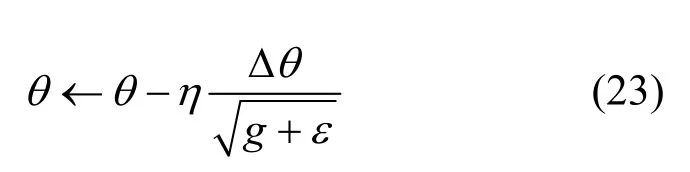
其中,η表示学习速率,ε表示一个正数。
单个线程独立地与环境交互并获取经验,彼此之间互不干扰。经过一定的交互之后,每个线程独立地使用累计的梯度更新公共神经网络模型参数,如图2 所示。进而,公共神经网络会分发自己的参数更新每个线程的神经网络参数,指导线程与环境的交互。本文算法详细描述如下。

图2 本文算法网络模型
算法1基于异步分布式强化学习的计算卸载和服务缓存联合优化机制
输入车辆的任务属性和需求
输出车辆的卸载决策,路边单元计算和缓存资源管理决策
初始化定义ϑ和ϑ v为全局网络中actor 网络和critic 网络的参数;定义为局部网络中actor 网络和critic 网络的参数;设置全局计数器T=0,设置局部步进计数器t=1,设置Tmax、tg、γ、ε、tmax、学习的速率η和代理的数目W
迭代:


5 仿真分析
本节利用Python 对车载边缘计算卸载算法进行仿真验证,通过比较各算法随车辆数目、路边单元计算能力和存储能力的变化在时延和奖赏方面展现的性能,来评估不同算法的优劣。其中,实现的算法除了本文算法之外,还包括基于随机卸载策略random processing 和完全卸载策略的offloading processing。在车载环境下,设置一个云中心和3 个路边单元。仿真参数如表1 所示。车辆的计算能力分布于[100,500]Mcycle/s,边缘服务器计算能力分布于[2,6]Gcycle/s,边缘服务器缓存能力分布于[200,1 000]MB,车辆计算能力分布于[100,500]Mcycle/s,每个任务的计算强度为297.62 cycle/bit。
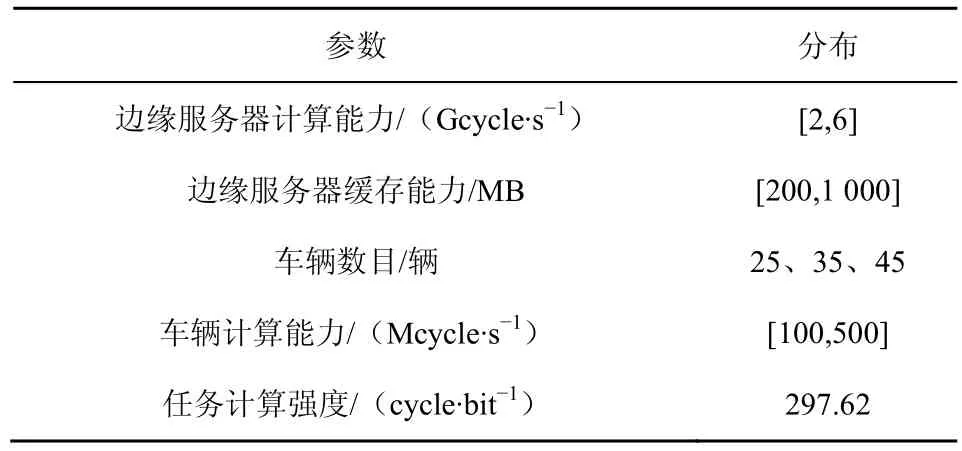
表1 仿真参数
图3 显示了车辆数目对不同算法时延的影响。此时,设置每个路边单元的计算能力为 2 GHz,存储大小为300 MB。从图3 中可以发现,系统任务处理的时延随着车辆数目的增多而增加。这一方面是因为处理任务的增多,另外一方面是因为有限计算资源的竞争。在所有的算法中,random processing的时延最大。相对于offloading processing 和本文算法,当采用random processing 时,车辆会承担较多任务的计算。由于车辆自身计算资源的限制,单独处理任务会造成较大的时延。offloading processing取得了比random processing 更好的性能。这主要归因于边缘服务器具有丰富的计算资源。边缘服务器参与任务的计算,会加快任务的处理,降低任务的处理时延。本文算法相对于以上2 种算法,完成任务处理所需的时延最小,这是因为本文算法考虑了纵向的端、边和云的协作。为此,所有可用的资源均可以通过协同用于处理任务,提升了资源的利用效率,促进了时延的减少。特别地,在端侧,任务的处理不仅考虑了本地资源,也充分发掘了任务车辆一跳的邻居车辆资源。本文算法的目标在于最小化任务的处理时延,而所在用的深度强化学习策略能够适应车载网络的动态、随机和时变特性获取相应的最优解。

图3 车辆数目对不同算法时延的影响
图4 显示了边缘服务器的计算能力对不同算法时延的影响。随着边缘服务器的计算能力的增加,不同算法处理任务的时延随之减少。这是因为任务的计算与边缘服务器的资源呈正相关的关系。对于random processing 而言,任务可以在端侧处理,也可以由边缘服务器计算。由于未能充分发掘边缘服务器的计算资源,random processing 所带来的时延最大。对于offloading processing 而言,任务全部交由边缘服务器处理。虽然可以充分发挥边缘服务器的计算资源,但是,未能考虑计算资源和服务缓存资源的相互关系。边缘服务器因为缓存资源不足将从云端下载任务计算所需的服务应用,带来额外的时延。对于本文算法而言,它联合考虑了计算卸载和服务缓存,通过本地处理和边缘处理的合理调度,促使了计算资源和缓存资源的充分利用,进一步减少了任务的处理时延。此外,深度强化学习算法有利于在动态的网络环境当中做出最优的卸载决策,有效地处理好计算资源和服务缓存资源之间的关系,进而保障任务的快速处理。
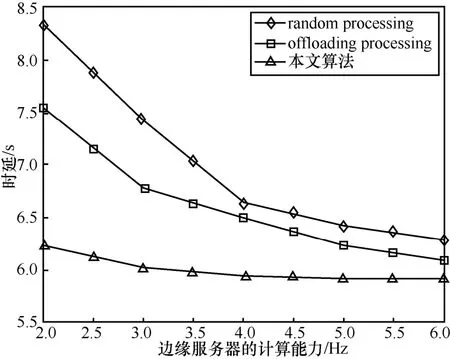
图4 边缘服务器的计算能力对不同算法时延的影响
图5 描述了边缘服务器的缓存能力对不同算法时延的影响。从图5 中可以发现,随着边缘服务器缓存能力的增加,不同算法处理任务的时延随之减少。这主要是因为边缘服务器为了执行任务,需要安装相应的服务应用,否则就需要从云端下载,从而带来了额外的开销。当边缘服务器的缓存能力增加时,可以缓存更多任务处理所需要的服务应用。这样方便任务卸载给边缘服务器之后直接计算,从而降低了时延。
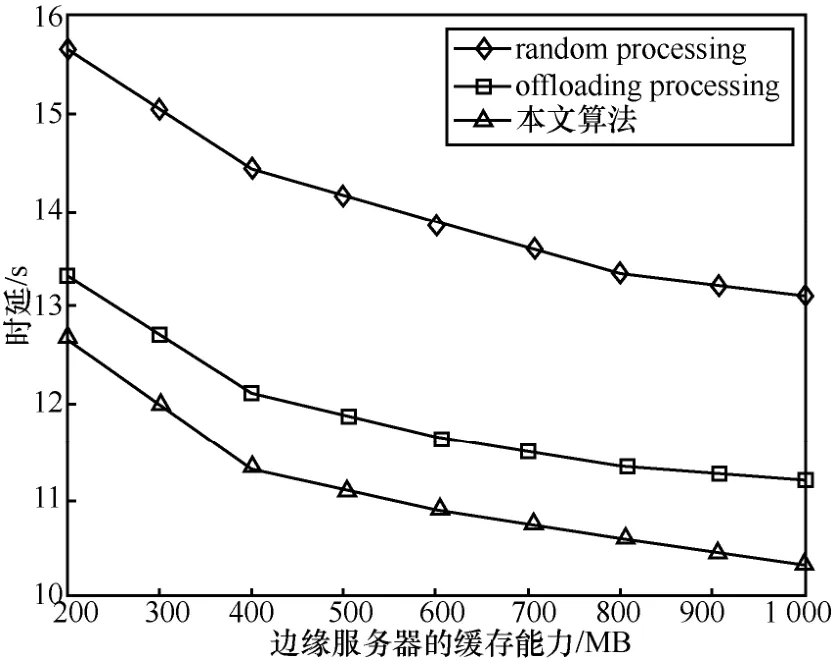
图5 边缘服务器的缓存能力对不同算法时延的影响
图6 描述了本文算法在不同学习速率场景下的收敛情况。其中,实线表示当actor 和critic 网络的学习速率分别为1×10−5和1×10−4时episode数目对奖励的影响。虚线表示当actor 和critic 网络的学习速率分别为1×10−4和1×10−3时episode数目对奖励的影响。从两者的比较可以发现,随着episode 的增加,奖赏将会趋于稳定。
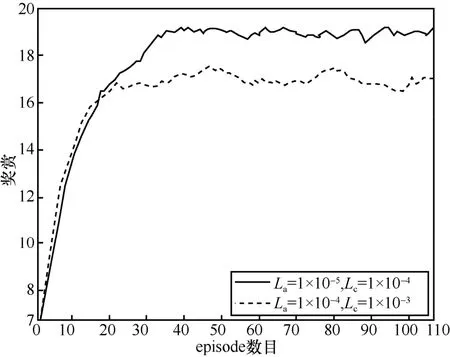
图6 本文算法在不同学习速率场景下的收敛情况
6 结束语
面对车联网中有限的网络资源,为了保障大量用户多样化的服务需求,本文提出了智能驱动的车载边缘计算架构。该架构实现了纵向端-边-云资源的协作和横向端侧、边侧资源的协同,有利于实现资源的最大化利用。基于该架构,探究了计算卸载和服务缓存相互作用的机理,进而提出了两者的联合优化模型。考虑到复杂的车载环境,利用异步优势的actor-critic 算法,给出了最优的任务卸载的策略和资源管理方案。实验结果表明,相对于对比算法,本文算法在任务处理时延方面取得了良好的性能提升。
猜你喜欢
科学技术创新(2021年18期)2021-06-23
通信电源技术(2020年8期)2020-07-21
微型电脑应用(2019年10期)2019-10-23
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
宇航计测技术(2018年3期)2018-09-08
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
通信产业报(2016年44期)2017-03-13
雕塑(1999年2期)1999-06-28
