
面向6G的雾无线接入网内生安全数据共享机制研究
2021-02-28 04:45刘杨李珺陈文韵彭木根
通信学报 2021年1期
刘杨,李珺,陈文韵,彭木根
(1.北京邮电大学信息与通信工程学院,北京 100876;2.北京邮电大学网络与交换技术国家重点实验室,北京 100876)
1 引言
随着第五代移动通信系统(5G,the fifth generation mobile communication system)的落地和商用,学术界和产业界共同开启了对第六代移动通信系统(6G,the sixth generation mobile communication system)的研究。5G 的主要目标是实现大连接、高带宽和低时延,并实现“万物互联”,从传统移动通信行业渗透至工业物联网等垂直行业,满足未来10 年(2020—2030 年)的无线通信需求[1]。对于6G 而言,随着人工智能(AI,artificial intelligence)不断渗透到各行各业,6G 也将与AI 深度结合,更多的智能化感知设备、人机接口将接入网络,“智慧连接”“深度连接”将成为新一代移动通信系统的重要特征[2]。
6G 中网络空间和运行的业务将会变得愈发复杂,无线终端数据流量的消耗也将大大增加。由于带宽和频谱的不足,传统的无线接入网络(RAN,radio access network)无法满足移动用户和运营商日益增长的需求。为了支持新的移动通信和服务,产业界先后提出了云无线接入网(CRAN,cloud radio access network)、异构云无线接入网(H-CRAN,heterogeneous cloud radio access network)、基于雾计算的无线接入网(F-RAN,fog radio access network)等架构作为新的无线接入网解决方案[3]。与传统基于集中式云计算的网络架构C-RAN 和H-CRAN 相比,F-RAN 充分利用无线远端射频单元(RRH,remote radio head)、雾无线接入点(F-AP,fog access point)和雾用户设备(F-UE,fog user equipment)等边缘设备,将协作无线信号处理(CRSP,collaboration radio signal processing)、协同无线资源管理(CRMM,cooperative radio resource management)和缓存、计算等功能在网络边缘实现,有效减少了前传约束、资源浪费和处理时延,并降低泄露用户隐私数据的风险[4-5],因此成了6G 中无线接入网的解决方案。
越来越多的科研机构、社会机构和企业通过收集数据来达成希望完成的任务。数据收集者通过对用户设备上传的数据进行统计分析,能够从真实世界中获得更多知识,从而辅助决策。目前6G 中热门的应用场景有智能电网、智能家居、智慧医疗、智能汽车等。然而,共享数据中通常包含许多人们不愿意透露给他人的隐私信息,如个人用电习惯、消费习惯、位置信息、医学诊断结果等私密性较强、较能反映个人特征的数据。在数据共享过程中,这些信息不可避免地会被泄露,甚至因此威胁到用户的生命财产安全。此外,数据的完整性也需要得到保证,数据只有正确、完整地存储下来,才能发挥作用。因此,数据完整性审计也是必不可少的一环。雾节点具有数据缓存功能,可以为用户提供共享数据的缓存服务。然而,尽管雾节点距离用户更近、与用户交互时延更低,但由于靠近网络边缘,它们难于管理,易于破坏。
因此,部署在F-RAN 上的数据共享应用面临2个主要的问题:1) 共享数据可能包含不应该暴露给他人的敏感信息,需要一个方案在保护用户隐私的同时保证数据可用性;2) 存储在雾节点的数据必须保证完整性,由于存在软硬件损坏、人为错误等风险,需要对雾节点上的文件定期进行远程数据完整性审计。
对于传统的C-RAN 架构,文献[6]采用同态可认证环签名,在隐藏用户身份的同时进行数据完整性审计,并支持无块验证。文献[7]使用类似的同态可认证群签名,并在签名前使用基于公钥的编码技术将数据编码成数据块以保护数据隐私。文献[8]在同态可认证环签名的基础上,采用覆盖树算法来确保数据隐私和新鲜度。文献[9]提出的轻量级数据共享方案基于在线/离线签名,并使用Merkle 哈希树(MHT,Merkle hash tree)支持批量审计和数据动态操作。文献[10]提出的医疗数据共享方案采用基于身份的加密算法。文献[11]通过结合基于密钥同态加密的不经意伪随机函数和基于零知识证明的可验证性,实现数据集隐私保护聚合和共享。
现有网络设计之初缺乏架构级的安全考虑,安全防护依靠外挂式、补丁式的方案,因而无法实现全网的无缝安全通信保障[12]。构建安全可信的6G网络迫切需要内生的安全技术。目前,对于面向6G的F-RAN 架构,还没有提出解决数据隐私保护和完整性审计问题的内生安全数据共享机制。
为此,本文基于面向6G 的F-RAN 设计了一种具有本地化差分隐私保护和动态数据完整性审计功能的数据共享机制,该机制针对F-UE 向基带处理单元(BBU,baseband unit)池实现数据共享的过程。F-UE 负责采集或生成数据,以及数据隐私保护处理;F-AP 作为中间节点缓存并预处理共享数据;大功率节点(HPN,high power node)负责对F-AP 上的缓存数据进行完整性审计,并负责控制信令的分发;BBU 池负责统计推断被保护数据的原始分布。本文的主要贡献介绍如下。
1) 从内生安全的角度出发,根据F-RAN 的架构特点为机制进行保证数据安全的隐私保护和数据完整性审计技术选型,并对数据完整性审计技术进行了适当的改进,提高了签名和验证的性能。
2) 在F-RAN 架构的基础上,利用F-AP 缓存、计算的功能特点,提出了F-UE 与BBU 池间内生安全的数据共享机制。相比传统架构,基于F-RAN的机制降低了用户交互时延和远距离通信量,并保持了F-RAN 通信层面的功能优势。在数据共享过程中,F-UE 对数据运行 RAPPOR(randomized aggregatable privacy-preserving ordinal response)算法,接着F-AP 对数据进行缓存和预处理,HPN 对各雾节点上的暂存数据进行基于BLS 签名和MHT的动态完整性审计,最终BBU 池通过统计分析,对收集数据的原始分布进行推断。
3) 对所提机制进行了安全性分析,分析表明提出的数据共享机制能够实现用户本地化差分隐私,并实现安全的数据完整性审计。本文将所提机制与已有机制进行了功能比较,仿真结果表明,所提机制的时间、空间和通信效率较高,同时能够保证隐私保护处理后的数据可用性。
2 预备知识
2.1 本地化差分隐私技术RAPPOR
定义1本地化差分隐私。给定一种隐私算法L,定义域和值域分别为Dom(L) 和Ran(L),给定n个用户,每个用户对应一条记录。对于任意两条记录t∈Dom(L)和t′∈Dom(L),以及任意t*⊆Ran(L),若算法L满足式(1),则称算法L满足ε-本地化差分隐私[13-14]。

已知扰动概率p和总样本量n,根据定义1,隐私预算ε为

要实现定义1 描述的ε-本地化差分隐私,需要数据扰动机制的介入。本文采用Google 已经投入实际使用的RAPPOR[15]技术,该技术是一种保护隐私的数据收集技术,可以利用随机性来保证每个用户报告满足本地化差分隐私。
RAPPOR 技术的核心数据结构是Bloom Filter。Bloom Filter 是一种随机数据结构,使用数组表示集合,数组的每一位只取0 或1,它能够确定元素是否属于此集合[16-17]。在没有元素加入时,Bloom Filter 的所有位都置为0,令其长度为k。Bloom Filter 使用h个相互独立的哈希函数来表示一个集合A={a1,a2,…,an},并分别将集合中的每个元素映射到{1,…,k}的范围中。对任意一个元素a,第i个哈希函数映射的位置H i(a)(1≤i≤h)就会被置为1。在判断一个元素a*是否属于这个集合时,对a*应用上述h个哈希函数,若所有H i(a)的位置都是1,那么认为a*是集合中的元素,否则认为a*不是集合中的元素。
RAPPOR 基本算法在客户机上本地执行,用来保护数据隐私,具体如算法1 所示。
算法1RAPPOR 基本算法
输入客户机的真实值a0,客户机所属群组编号cid,系统公共参数(f,p0,p1,nB,nH,HB)
1) 初始化Bloom Filter。拼接真实值a0与群组编号cid,得到a=a0||cid,给定一长度为nB的Bloom Filter,记作B,以哈希函数集合HB中的前nH个哈希函数作为B 的哈希函数,并将值a加入B表示的集合。
2) 生成永久随机响应。对于每个客户端的值a和B 中的位i(0≤i≤k),创建一个二进制报告值为

其中,f是控制纵向隐私保护级别的用户可调参数。随后,这个被记录下来并被重用,作为以后所有关于值a的报告的基础。
3) 生成瞬时随机响应。分配大小为nB的位数组S,并将每一位初始化为0。用概率设置每一位,即

4) 报告。将瞬时随机响应S发送到服务器。
在数据收集之前,设置nC个群组,并将每个用户随机分配到nC个群组之一。群组内部成员使用相同的nH个哈希函数来实现Bloom Filter,每个群组选择的nH个哈希函数各不相同。
采用RAPPOR 边缘解码算法从收集的RAPPOR报告中学习原始数据的边缘分布,如算法2 所示。
算法2RAPPOR 边缘解码算法
1) 创建大小为nBnC×M的设计矩阵X,其中,M为候选字符串数目(如图1 所示,为nC个群组各初始化M个大小为nB的Bloom Filter,Bi,j为第i个候选字符串加入第j个群组的Bloom Filter 后的位数组)。
2) 令cij为群组j中每个位i在一组Nj个报告中设置为1 的次数,则群组j中每个位i在每个群组中真正设置在Bloom Filter 中的次数为

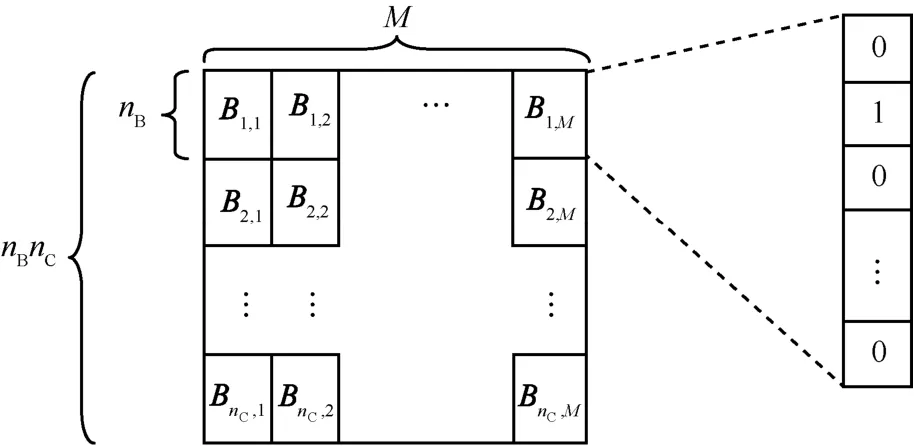
图1 设计矩阵X示意
3) 设Y是tij的向量,i∈[1,nB],j∈[1,nC]。选择候选字符串使用Lasso 回归[18]拟合模型Y~X,并选择对应于非零系数的候选字符串。然后使用所选候选字符串拟合正则最小二乘回归,以估计各字符串的计数、标准误差和P值。
4) 确定哪些字符串出现的频率是从0 开始的有统计学意义,将P值与Bonferroni 校正后的α/M=0.05/M进行比较,或者使用Benjamini-Hochberg 法将伪发现率(FDR,false discovery rate)控制在水平α。
2.2 BLS 签名


2.3 MHT
MHT 是经过充分研究并用于认证的数据结构,其目标是有效、安全地证明一组元素没有损坏和变化。它被构造为二叉树,其中MHT 中的叶子是真实数据值的哈希值[20]。
数据元素的MHT 身份验证如图2 所示。首先,具有真实根节点hr的验证者请求数据块{x3,x6},并要求对接收到的块进行身份验证。证明者除了向验证者提供块{x3,x6}外,还向验证者提供辅助认证信息(AAI,auxiliary authentication information)Ω3=
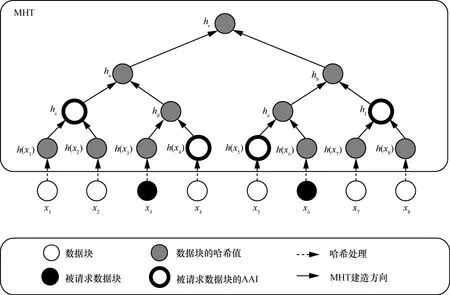
图2 数据元素的MHT 身份验证
MHT 通常用于验证数据块的值,而本文进一步采用MHT 来验证数据块的值和位置。将叶子节点视为从左到右的有序序列,因此可以通过遵循此序列以及MHT 中计算根的方式来唯一确定任何叶子节点。
3 数据共享机制
3.1 系统模型
本文设计的数据共享机制的系统模型如图3 所示,它基于面向6G 的F-RAN 架构。F-RAN 具有全局C-RAN 模式、本地分布式协作模式、D2D 模式与HPN 模式。本文主要关注F-RAN 的本地分布式协作模式,涉及如下几类网络实体。
1) BBU 池。BBU 池可被视为中心机房,内部集中了大量基带处理单元。BBU 池具有集中式CRSP 和CRMM,减少了分散部署BBU 带来的管理和维护成本,提高了网络频谱效率和能量效率。BBU 池通过多点协调(CoMP,coordinated multiple points)功能来抑制HPN 和F-AP 的跨层干扰。
2) F-AP。在RRH 的射频处理功能基础上,F-AP还具有CRSP 和CRMM 功能,以及额外的存储、计算功能。
3) F-UE。F-UE 是具有CRSP 和CRMM 以及存储功能的用户设备,但功能弱于F-AP。
4) HPN。HPN 负责为所有的F-UE 提供控制信令和小区特定参考信号,并为移动速率高的用户提供基本比特速率的无缝信号覆盖。
在F-RAN 中,F-AP 具有一定的计算和缓存功能。通过将F-UE 共享的数据文件缓存在网络边缘的F-AP,并由F-AP 对共享数据进行预处理后交付给BBU 池,能够有效降低F-UE 在数据共享过程中的交互时延,并减少F-AP 与BBU 池间的通信量。

图3 基于面向6G 的F-RAN 网络架构的系统模型
在本文设定的数据共享过程中,F-RAN 工作在本地分布式协作模式,此时F-UE 处于低速移动或静止状态。数据收集方委托BBU 池收集F-UE 上传的数据。各实体协商公共参数后,F-UE 生成共享数据,进行隐私保护处理后将数据共享给邻近的F-AP。F-AP 负责为F-UE 缓存数据。在此期间,出于应用目的,F-UE 可以与F-AP 进行交互,以访问或检索其预存储的数据,F-UE 还可以对已上传的数据进行修改、插入和删除。HPN 负责对缓存在F-AP 上的数据进行数据完整性审计。待BBU 池通过负责控制信令分发的HPN下达上传指令后,F-AP首先停止收集数据,并停止响应用户数据更新的请求,然后对收到的数据集进行一定的数据预处理后上传到BBU 池。在BBU 池获得数据后,统计推断得到数据实际的分布,交付给数据收集方进行科学研究等。
在上述数据共享过程的通信层面,各实体仍保持其通信功能,包括F-UE、F-AP 的CRSP 和CRMM功能,BBU 池的基带处理、集中式CRSP、CRMM和CoMP 功能,HPN 的控制信令分发功能等。
3.2 数据共享机制设计
本节介绍数据共享机制的详细设计,记F-UE数量为nU,F-AP 数量为nA,且nU>>nA,BBU 池与HPN 数量均为1。
阶段1系统设定

阶段2数据发布


阶段3数据完整性审计

BatchVerifyProof(pks,chals,Ps)。为了提高效率,HPN 可以对不同F-AP 给出的关于不同F-UE数据文件的证明P进行批量验证,pks、chals 和Ps分别为参与批量验证的公钥集合、挑战集合和数据


阶段4数据收集

HashCandidates(nB,nH,nC,HB,candidatesi) 。BBU 池根据第i个数据块对应的参数(nB,nH,nC,HB)和候选字符串列表candidatesi生成设计矩阵mapi(详见2.1 节算法2 的步骤1))。
Decode(mapi,finalcountsi,pubi)。BBU 池根据设计矩阵mapi,比特数组按群组编号求和的列表finalcountsi,公共参数pubi,构造模型Y~X并对其进行Lasso 回归,以选择对应于非零系数的候选字符串,对选择的候选字符串进一步进行正则最小二乘回归,统计出数据块mi的真实分布Distri(详见2.1 节算法2 步骤2)~步骤5))。
4 安全性
本文提出的数据共享机制的安全性基于RAPPOR 基本算法和数据完整性审计机制。RAPPOR 算法的安全性分析在文献[15]已经有完整的阐述,本节只关注数据完整性审计部分。
4.1 安全模型
对于数据完整性审计方案来说,数据安全的关键在于审计者HPN 是否能切实判断数据在F-AP 上存储的实际情况。
根据文献[20]中的安全模型定义,本文给出形式化的安全模型,主要关注4 种算法,KeyGen()、SigGen()、GenProof()和VerifyProof(),它们的行为如3.2 节所述。将执行GenProof()与VerifyProof()两台机器的运行表示为{TRUE,FALSE}←(VerifyProof(pk,chal,P,tag) ⇌GenProof(F,tag,Φ,chal))。
本文希望数据完整性审计协议是正确且可靠的。正确性要求对于KeyGen()输出的所有(pk,sk),以及SigGen()输出的所有(F,tag,Φ,sigsk(H(R))),VerifyProof()在与有效GenProof()交互时接受式(8)。

将具有审计能力的HPN 和F-UE 看作共同的挑战者C,将不受信任的F-AP 看作对手A。考虑对手A 和挑战者C 之间的博弈:挑战者C 通过运行KeyGen()生成密钥对(pk,sk),并向A 提供pk。现在对手A 可以与挑战者C 交互,也可以向SigGen()进行查询,为每个查询提供一些文件F。挑战者C计算SigGen(sk,F),并返回所有输出(F,tag,Φ,sigsk(H(R)))给对手A。对于之前对手A向挑战者C 进行查询的任何文件F,对手A 可以扮演验证者,通过指定相应的标记 tag 来执行VerifyProof(pk,chal,P,tag)⇌ A,即执行数据完整性审计协议。当协议执行完成时,对手A 向对方提供VerifyProof()的输出。这些协议执行可以相互任意交错,并与文件F的查询同时进行。最后,对手A 输出从某个查询返回的标签tag,以及证明算法GenPro of*()。
如果作弊证明者能令人信服地回答挑战chal的δ部分,即如果满足式(9),则它是δ-可接受的。

定义3 和定义4 描述数据完整性审计协议的可靠性要求。令F为查询中输入的文件,查询返回(F,tag,Φ,sigsk(H(R)))。
定义3如果存在一个提取算法Extr(),对于每一个δ-可接受的作弊证明算法GenPro of*(),满足个对手A,每当A运行上述博弈,为文件F输出Extr(pk,Φ,chal,tag,GenProof*())=F,即 Extr() 从GenPr oof*()中恢复F,那么就说一个可检索性证明方案是δ-完备的,除非式(9)可以忽略不计。
定义4如果不存在能够以不可忽略的概率欺骗验证者的多项式时间算法,则数据完整性审计协议是安全的。
4.2 安全性分析
根据上述安全模型来评估本文提出的数据完整性审计方案的安全性,由于该方案基于文献[20],因此证明过程除了审计细节外,大体上与其相似。BLS 签名的安全性证明在文献[19]中已经给出。
定理1如果签名方案在本质上是不可伪造的,并且在双线性群中CDH 问题很难解决,那么任何反对本文公开审计方案合理性的对手都不能导致验证者以不可忽略的概率接受可检索性协议实例,除非对手使用正确计算的值做出响应。
证明在文献[19]中的BLS 签名方案是安全的前提下,容易证明本文的数据完整性审计方案所要求的数据完整性证明是不可伪造的。


表1 相关方案功能比较
5 仿真与评价
5.1 功能比较
由于目前对F-RAN 的数据共享机制研究还很少,表1 给出本文提出的数据共享方案(以下简称本文方案)和已有的传统云架构上的几个数据共享方案进行对比。如表1 所示,本文方案是唯一支持数据共享、远程数据完整性审计、公共审计、动态审计、批量审计、隐私保护、隐私保护数据可用性和本地化隐私保护的方案。注意,文献[6]、文献[10]、文献[11]均不支持本地化隐私保护,且均需要由用户之外的第三方完成隐私保护处理。表1 中√表示支持,×表示不支持。
5.2 性能分析与比较
本文方案主要是基于BLS 签名和MHT 的动态审计方案[20],由于其在聚合签名和批量验证时有一定的缺陷,因此本文结合Dan Boneh 在2018 年提出的公钥聚合BLS 多签名方案对其进行了改进,并优化了MHT 在动态操作时的响应方式。表2 展示了文献[20]方案的细节。

表2 文献[20]方案的数据完整性审计方案细节
文献[20]方案中签名和验证的计算量比本文方案要大,分别具有额外项,且在聚合签名时,对于所有数据块均需要计算指数,本文方案只有发生碰撞的数据块需要计算指数。此外,文献[20]方案的通信量也比本文方案大,其传输每个数据块时均需要额外传输随机值wi。
对于MHT,文献[20]方案采用结构体实现,而本文方案采用不定长二维数组实现。一方面,使用二维数组能够减少树占用的存储空间。结构体表示的节点需要存储本节点的值以及父节点、孩子节点的地址,而二维数组中每个节点仅需存储本节点的值。另一方面,使用二维数组可以直接使用索引访问MHT 的底层节点,时间复杂度为O(1),而结构体实现的MHT 所需的时间复杂度最坏取决于MHT的深度和底层节点的个数。
在更新操作时,需要先查找到MHT 对应的节点,再更新底层节点,并计算出顶层根节点。例如,在底层节点后插入一个新节点,令n为MHT 节点总数,k为底层节点个数。文献[20]方案访问目标节点的时间复杂度最坏为O(logn)或O(k),插入操作的时间复杂度为O(1),自底向上计算根节点的时间复杂度为O(logn)。本文方案访问底层节点的时间复杂度为O(1),插入操作的时间复杂度为O(k),自底向上重建MHT 并计算根节点的时间复杂度为O(logn)。因此,在进行树的更新时,2 种方案的时间复杂度相差不大,均取O(logn)与O(k)中的较大值,但在访问特定节点的值时本文方案更具有优势。
尽管本文方案与文献[20]方案的时间复杂度持平,但考虑到F-UE 对已上传的数据进行动态操作并不会很频繁,节省本就有限的存储空间显得更加重要。因此,在本文方案的系统设定下,选择不定长二维数组更佳。
5.3 仿真分析
通过仿真来评估本文方案的时间性能。本文采用的仿真机器为Intel Core i5-8250U 1.60 GHz 处理器,16 GB 内存,Windows 10 操作系统。仿真采用Python 语言和R 语言编程,IDE 分别采用Spyder和RStudio,Python 版本为3.6.10,R 版本为3.6.3。需要使用额外的Python 依赖库pandas、pysha3 1.0b1;额外的R 依赖库glmnet、limSolve。在仿真中,设置基本数据块mi∈M(i∈[1,n],n为文件数据块数量)所占内存大小为28 B,MHT 的各个节点大小为49 B,ℤq中一个元素的大小为1 056 B。
1) 签名方案的性能
首先对密钥生成算法进行仿真。重复运行100 次KeyGen(),得到100 次运行的平均值为0.05 s。运行100 次KeyGen()每次耗时情况如图4 所示。

图4 运行100 次KeyGen()每次耗时情况
接着对签名生成算法进行仿真,生成从0 到1 000 个不同数据块数的签名,每次运行数据块增加100 个。仿真结果如图5 所示,数据块数量x和SigGen()的运行时间y基本呈线性关系,拟合的线性关系式为y=0.438 9x+0.727 3,R2=0.999 3,这表明拟合接近实际情况。从拟合的线性关系式中可以看出,每增加一个数据块,SigGen()的运行时间将增加约0.44 s。

图5 数据块数量对SigGen()算法运行时间的影响
2) 批量审计性能
分别运行若干次VerifyProof()和BatchVerify Proof(),探究随着签名数目的增加,逐个验证签名和批量验证签名的耗时变化以及二者之间的对比。仿真生成从0 到100 个来自不同F-UE 的单个数据块签名,每次运行F-UE 数目增加10 个。仿真结果如图6 所示。

图6 验证签名数目对VerifyProof()与BatchVerifyProof()算法运行时间的影响
图6 中,两组散点分别表示对x个签名进行一次批量验证和逐个验证花费时间ys,连线是对散点图的线性拟合。可以看到,无论是批量验证还是逐个验证,两条直线拟合的R2均非常接近1,可以认为随着签名数目的增加,算法运行时间大致上呈线性增长。且二者线性拟合表达式的斜率相差较大,随着x增加,Δy=y1−y2=3.154 9x+2.8508。这表明逐个验证与批量验证的耗时差距将随着签名数目的增加而增大,批量验证效率更高。
3) 动态审计性能
对修改、插入、删除这3 种操作分别模拟10 次动态操作执行ExecUpdate()和10 次动态操作验证VerifyUpdate(),原文件数据块数量为110,进行动态操作的数据块数量从0 到100,每一次仿真数据块数量增加10 个,仿真结果分别如图7 和图8 所示。

图7 数据块数量对算法ExecUpdate()的修改、插入、删除操作耗时的影响
从图7 可以看到,对于修改、插入和删除这3种操作,ExecUpdate()的耗时均随着动态操作的数据块的增加而增大,二者大致呈线性关系,且当动态操作的数据块数量相同时,3 种操作的耗时比较接近。从图8 可以看到,对于修改、插入和删除这3 种操作,除了数据块数量为 0 时,其余VerifyUpdate()的耗时均与动态操作的数据块数量没有明显关系,随着动态操作数据块数量的增加,耗时几乎保持不变。除去数据块数量为0 的点外,修改、插入和删除3 种操作的平均耗时分别为4.18 s、4.19 s 和4.20 s,非常接近。
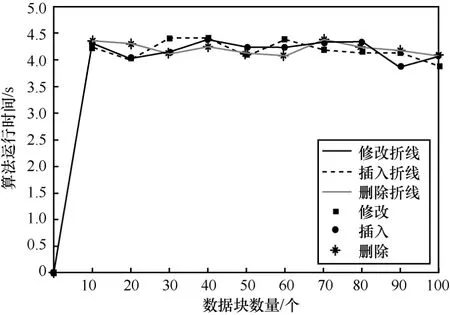
图8 数据块数量对算法VerifyUpdate()的修改、插入、删除操作耗时的影响
4) 隐私保护性能
对RAPPOR()进行仿真,数据块数量从0 到50 000 变化,每次迭代数据块数量增加1 000,仿真结果如图9 所示。从图9 可以看到,RAPPOR 算法的耗时与数据块数量呈线性关系,每增加一个数据块,时间大约增加7×10−4s,因此对于F-UE 来说,进行隐私保护所花费的时间成本较低。
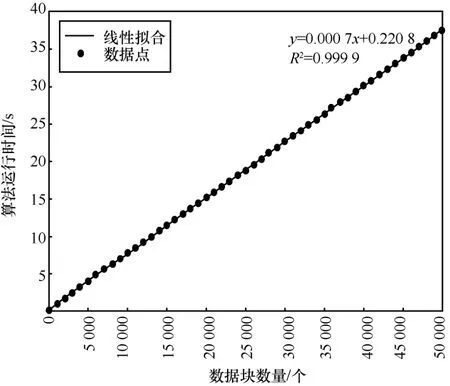
图9 数据块数量对RAPPOR()隐私保护处理耗时的影响
对于边缘解码算法Decode()的统计推断效果,文献[15]中已经给出了详细的仿真结果和分析,本文不再赘述。
6 结束语
本文针对6G 时代发展前景广阔的F-RAN 架构,提出一种具有本地化差分隐私保护和动态数据完整性审计功能的内生安全数据共享机制。基于F-RAN 的本地分布式协作模式,建立机制运行的系统模型。数据共享时,F-UE 本地对数据运行RAPPOR 隐私保护算法;F-AP 对数据暂时存储和预处理;HPN 对各F-AP 上暂存数据进行基于BLS和MHT 的完整性审计,F-UE 可对F-AP 上数据进行动态操作与相应审计;最终BBU 池通过统计分析,对收集数据的原始分布进行推断。理论分析与仿真结果表明,本文提出的内生安全数据共享机制能够在保持较高时间、空间和通信效率的同时,实现内生安全的动态审计和多客户端批量审计,并在实现用户本地化差分隐私的同时保证数据可用性。
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
自动化学报(2022年4期)2022-05-28
速读·下旬(2021年11期)2021-10-12
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
大东方(2019年12期)2019-10-20
网络安全技术与应用(2019年5期)2019-06-05
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
