
基于运动学动态图的人体动作识别方法
2021-02-28 04:00:26肖志涛
天津工业大学学报 2021年1期
肖志涛,张 曌,王 雯
(天津工业大学电子与信息工程学院,天津 300387)
基于RGB-D数据人体动作识别已成为计算机视觉中重要的研究方向。RGB-D数据包括由RGB相机拍摄的RGB数据和由深度相机拍摄的包含物体和相机之间距离信息的深度图像组成。此外,RGB-D数据不受照明、阴影的影响,所以基于RGB-D数据的人体动作识别方法具有更出色的性能。
为了获得RGB-D视频中的运动信息,文献[1-3]提出了场景流的方法,但是场景流仅提供场景中运动目标的速度信息,因此场景流提供的运动信息并不充分。文献[4]提出了基于散度、旋度、错切运动学特征的描述符,增强了运动目标的局部运动。文献[5]使用散度、旋度等运动学特征,证明了运动学特征有尺度不变性,并且此特征可以逐帧计算。文献[6]使用排序池化算法把视频映射为外观动态图,并利用外观动态图和CaffeNet进行动作分类。
人体动作的执行时间只占视频中的一部分帧,视频中含有与动作无关的冗余帧,只对视频逐帧计算运动学特征会受到冗余帧的干扰。本文提出了一种基于运动学动态图和双流卷积网络的人体动作识别方法。通过视频的场景流向量计算视频的散度、旋度、错切运动学特征图序列。使用分层排序池化[7]把运动学特征图序列映射为运动学动态图,得到视频的运动信息。把原始视频对应的外观动态图[6]和运动学动态图输入到双流卷积网络中以实现人体动作识别。基于运动学动态图和双流卷积网络的人体动作识别方法融合了外观信息和运动信息,不仅充分表征了视频的动态,而且使用了视频中具有丰富运动信息的运动学特征。
1 视频的运动学动态图和网络训练
1.1 运动学特征图序列
将RGB-D视频中的2个连续的RGB帧和对应的2个连续的深度图输入到初级对偶算法[2]中,得到实时的稠密场景流 s=(u,v,w)T,其中 u、v、w 分别为任意一个像素点在水平、垂直和深度3个方向上的瞬时速度。与RGB彩色图像类似,场景流向量s可看作RGB彩色图像,3个分量u、v、w可以看作s的3个通道,s称为场景流特征图。视频中每对相邻帧和其对应的相邻的深度图均计算出一幅场景流特征图s,得到视频的场景流特征图序列。
运动学是描述和研究物体位置随时间变化规律的力学分支,不涉及物体本身的物理性质和作用于物体无关的力,仅捕捉运动信息。因此,运动学特征有助于人体动作识别。受到DCS(divergence-curl-shear)描述符[4]的启发,本文基于视频的场景流特征图计算运动学特征。这里计算的运动学特征包括通过散度、旋度和错切特征计算得到的散度运动学特征图序列、旋度运动学特征图序列和错切运动学特征图序列,分别描述了视频中的尺度变化、旋转变化和错切运动。通过这3种运动学特征图,计算振幅运动学特征图序列以表征这3种运动学特征之间的关系[8]。
(1)散度运动学特征图序列。散度是场景流的局部一阶微分标量,能很好地描述场景流的物理模式并获取场景流中局部扩张的运动信息。定义场景流向量s=(u,v,w)T,则在第 t帧的像素 pt处的散度为:

计算视频中单帧图像中所有像素点的散度,得到散度运动学特征图。然后计算视频中每帧场景流的每个点的散度,就构成了一组散度运动学特征图序列。
(2)旋度运动学特征图序列。旋度表示场景流场中某个点的旋转程度,能够突出视频中人体的圆周运动。点pt在场景流s中的旋度curl为:

式中:curl(pt)x、curl(pt)y、curl(pt)z分别为旋度在水平、垂直、深度3个方向的分量,该点的旋度幅值为:
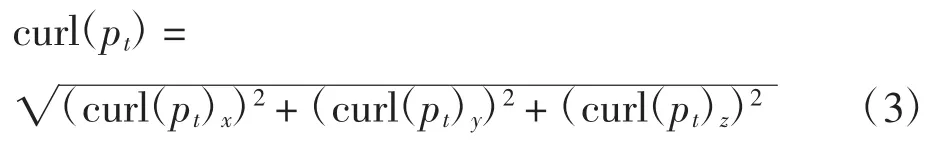
计算s中所有帧的旋度幅值得到旋度运动学特征图序列。
(3)错切运动学特征图序列。为了更加全面对视频中的运动信息进行描述,本文在场景流的基础上提取错切特征,从而捕获动作视频中人体运动在场景流中产生的形变程度。首先计算点pt在场景流的双曲项hyper1和hyper2
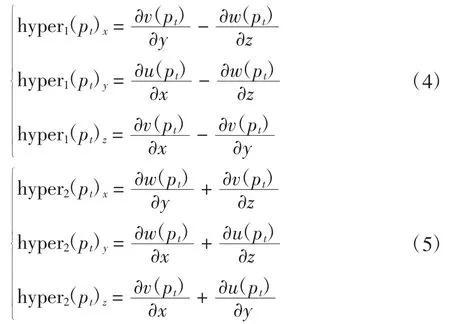
式(4)、式(5)分别为双曲项在水平、垂直和深度方向上的分量。双曲项的幅值分别为:

双曲项能够描述场景流中更为复杂结构的错切,然后计算点pt的错切特征
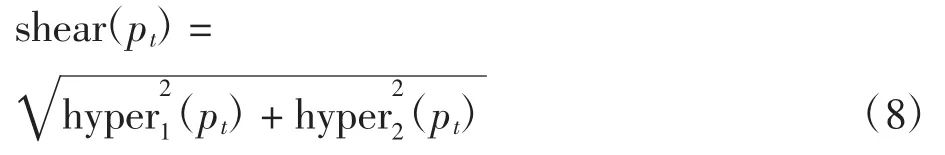
式中:shear(pt)表示点pt处场景流对应的错切特征。根据式(8)计算视频中所有像素点的错切特征得到错切运动学特征图序列。
(4)振幅运动学特征图序列。为了描述散度、旋度和错切运动学特征之间的关系,计算振幅运动学特征图AM:
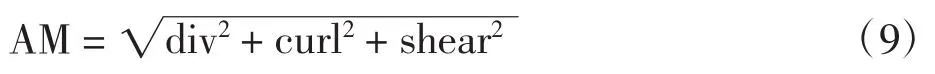
将同一视频的散度、旋度和错切运动学特征图序列通过式(9)计算得到振幅运动学特征图序列。
1.2 分层排序池化方法
排序池化是一种时间编码方法,将视频序列的动态映射为一个动态图[6]。首先使用时变平均向量平滑视频 X=[x1,x2,…,xt],x1,x2,…,xt表示序列中在第t帧。视频序列关于时间t的均值向量为:

平滑结果为:

式中:

式中:vt表示均值向量在时间t的方向,平滑后的序列为V=[v1,v2,…,vt]。然后对序列V的动态D进行编码。动态D反映在时间t变为t+1的时间段内序列的改变。假设序列V足够平滑,则可以通过参数向量u的线性函数来逼近D,即

给定一组稳定的函数组Ψ,相同类别的不同视频的动态函数Ψ(·;ui)是相似的。因此,可将不同类别视频的动态函数的差异作为动作识别的判别依据。虽然不同的视频序列动态变化不同,但序列排序保持不变,而且具有相同形式的动态函数。因此,本文采用动态参数ui表示视频的动态信息。
视频中如果vt+1在vt后一帧,则在这里标记为vt+1>vt。可得顺序约束vn>vt>…>v1。为了利用排序池化来编码视频的外观动态,求解满足最小约束条件的组合学习排序方程[9],使其满足帧顺序的约束。组合排序函数即动态函数Ψ(vt;u)通过参数u学习t时刻的排序分数函数为:
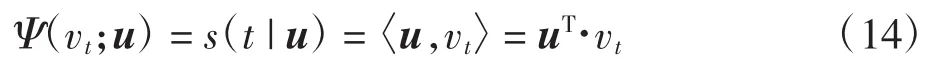
(·)是向量的点乘运算,通过参数u使排序分数反映了视频中每帧的排序。排序分数以较大的边界满足组合条件vt+1>vt。排在后面的帧排序分数越大[10],即
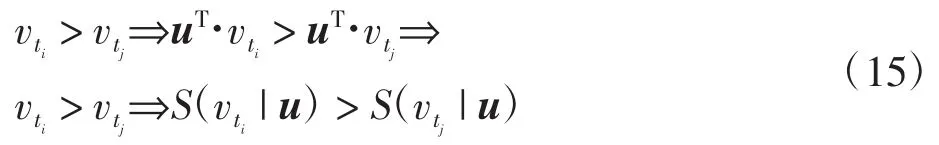
参数u可采用RankSVM[11]进行求解如下:

式中:u*的第1项是SVM的二次正则化,用于对权值进行惩罚,第2项是SVM的Hinge损失函数,参数向量u*编码视频中的所有帧的外观或运动信息,可以描述序列中外观或运动信息随时间变化的动态过程。参数向量u*的元素个数等于视频帧的像素数,把参数向量调整为原视频帧的大小,得到视频的动态图。
排序池化操作将视频里的外观编码成一个动态图。但对于动作执行时间较长的视频,对整个序列直接使用排序池化算法无法捕获动作中更精细的运动信息,导致动态图无法准确地描述视频随时间演变,降低了动态图对动作识别的判别性。为了解决这个问题,本文采用了分层排序池化[7]。
1.3 网络训练
本文采用双流卷积网络框架[12]进行动作分类,其中外观动态图输入到空间通道的网络中,将三通道运动学动态图和振幅运动学动态图输入到时间通道的网络中。外观动态图和运动学动态图分别描述视频中的外观信息和运动信息,特征表达能力强。本文方法框架如图1所示。

图1 基于运动学动态图的人体动作识别方法Fig.1 Framework of action recognition using kinematic dynamic image
具体步骤如下:
(1)首先使用初级对偶算法计算帧数为N的RGB-D视频的场景流向量,初步提取视频的运动信息。
(2)利用场景流向量计算散度、旋度、错切运动学特征图序列,合并为三通道运动学特征图序列,同时计算振幅运动学特征图序列。
(3)利用分层排序池化算法把原始RGB视频映射为外观动态图,将三通道运动学特征图序列编码为三通道运动学动态图,将振幅运动学特征图序列编码为振幅运动学动态图。
(4)使用双流卷积网络进行训练和分类,将各通道的结果融合实现人体动作识别。
2 实验结果与分析
采用M2I数据集[13]和SBU Kinect Interaction数据集[14]验证本文方法性能。M2I数据集有22类动作,分为3种:双人交互、双人与物体交互和单人与物体交互,其中双人交互有9类、双人物体交互有3类、单人物体交互有10类,共1 760个视频,包含前向和侧向2个视角的视频。SBU Kinect Interaction数据集有8类双人交互动作,共336个视频、6 614帧。
由于动作序列是随时间由过去到未来变化的[10],因此在计算运动学动态图时仅考虑正向动作序列。对M2I数据集中“双人鞠躬”动作中的散度、旋度、错切、三通道和振幅运动学动态图如图2所示。
散度、旋度、错切运动学动态图是散度、旋度、错切运动学特征图序列分别由分层排序池化映射得到的。
分层排序池化步长为1、窗口大小为20、层数为3,适合人体动作视频[7]。本文训练过程使用Caffe框架[15]完成训练及测试过程。网络的动量设置为0.9,权重衰减为0.001,初始学习率设置为0.001,每经过10万次迭代学习率变为原来的1/10。随机失活率设置为0.6。本文训练的过程微调自预训练模型ILSVRC-2012[16],为了减少过拟合,本文采用图像翻转、图像旋转、对比度增强、线性对比度增强、高斯滤波和随机裁剪多种数据增广方法,增加数据集的多样性。
在M2I数据集上,本文在前向和侧向2个视角中使用不同形式的动态图,包括外观动态图、散度运动学动态图、旋度运动学动态图、错切运动学动态图、三通道运动学动态图、振幅运动学动态图。在AlexNet[16]上的实验结果如表1所示。
图2 M2I数据集中“双人鞠躬”动作序列的散度、旋度、错切、三通道和振幅动态图Fig.2KDI-D,KDI-C,KDI-S,KDI-DCS,KDI-AM on video "bow" in M2I dataset

表1 不同组合形式动态图的动作分类结果Tab.1 Recognition results using dynamic image with different forms
由表1可知,不同类型的动态图代表不同方面的动态,外观动态图表示了视频外观随时间的变化,散度运动学动态图、旋度运动学动态图和错切运动学动态图分别代表视频的散度、旋度和错切运动信息随时间的变化,振幅运动学动态图表示了散度、旋度和错切这3种运动信息的关系。因此,同时输入以上外观动态图和运动学动态图,可以描述视频多种信息,融合了外观动态图和运动学动态图识别的结果,验证了实验效果。
在双流卷积网络同时输入外观动态图、三通道运动学动态图和振幅运动学动态图。在不同CNN(包括AlexNet、VGG16[17]、VGG19[17]、Resnet-50[18]、GoogLeNet Inception V3[19])中的实验结果如表2所示。
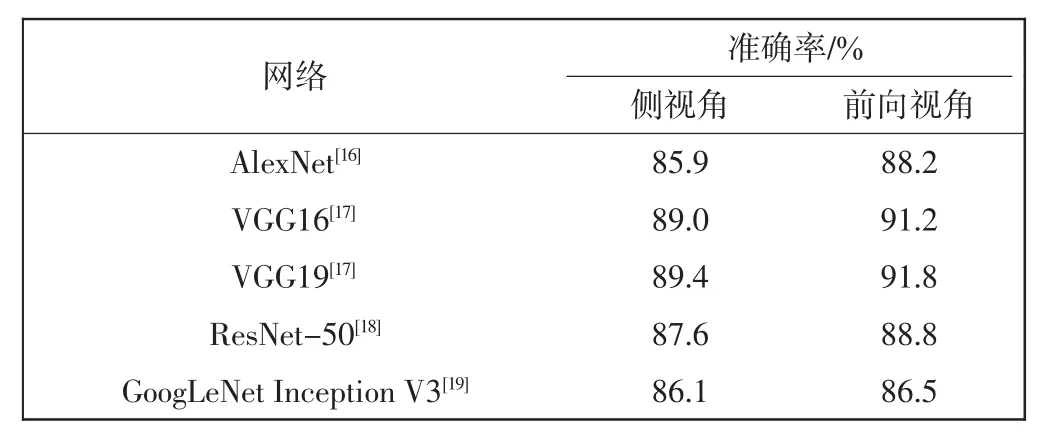
表2 采用不同CNN的人体动作分类结果Tab.2 Recognition results of using different CNN
VGG相对于其他网络扩展性较强,泛化性较好,VGG19的分类结果最好。
图3和图4分别是以外观动态图、三通道运动学动态图和振幅运动学动态图同时作为输入得到的结果,用VGG19网络训练在前向和侧向视角的识别混淆矩阵。

图3 M2I数据集使用VGG19网络的前视角混淆矩阵Fig.3 Confuse matrix of used VGG19 network on front view in M2I dataset
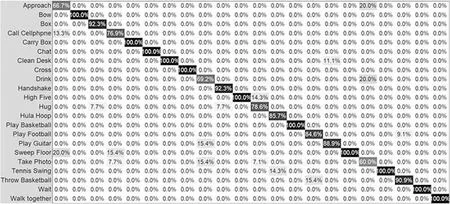
图4 M2I数据集使用VGG19网络侧视角混淆矩阵Fig.4 Confuse matrix of used VGG19 network on side view in M2I dataset
从图3和图4的混淆矩阵可以看出,本文方法在多人交互动作和多人物体交互动作中识别的效果更好,除了“拥抱”、“握手”、“踢足球”以外,其他双人交互动作和双人物体交互动作识别准确率均达到了100%。此外,“弹吉他”、“打电话”、“照相”等单人物体交互动作识别率较低,易被错分为其他动作。
表3为本文方法与现有方法(改进稠密轨迹(IDT)[20]和场景流动作特征图(SFAM)[8])。

表3 本文方法与其他方法的比较Tab.3 Comparison with other methods
表3使用AlexNet在M2I数据集上进行动作识别率的比较。IDT级联了包括HOG、HOF和MBH的所有特征,记作IDT-COM,并使用词袋(Bow)和Fisher Vector(FV)的特征编码方法后的动作识别结果。在与场景流动作特征图的比较中,本文分别比较了4种场景流动作特征图,包括差分场景流动作特征图(SFAM-D)、求和场景流动作特征图(SFAM-S)、动态场景流动作特征图(SFAM-RP)和振幅动态场景流动作特征图(SFAM-AMRP)。从表3可见,由于本文提出的运动学动态图不仅描述了运动随视频的变化,而且运动信息也比轨迹和场景流动作特征图更丰富,提高了动作识别准确率。融合了4种场景流动作特征图方法的动作识别率比本文方法识别率高,这是因为场景流动作特征图比本文方法多融合了一个通道的信息,即差分场景流动作特征图和求和场景流动作特征图,这两种场景流动作特征图表征了累积运动差分能量的分布。
同时在SBU Kinect Interaction数据集上进行了实验。表4给出了不同形式的动态图以及不同训练网络下的识别结果。表4比较了原始骨架(Raw skeleton)[14]、分层循环神经网络(Hierarchical RNN)[21]、时空长短时间记忆网络(ST-LSTM)[22]、多任务学习网络(MTLN)[23]和全局上下文长注意力短时间记忆网络(GCA-LSTM)[24]等方法的识别结果。实验结果表明,本文方法的识别率更高,这是因为上述5种方法仅用了RGB-D视频中的骨架信息,以单通道的骨架信息或者双通道的骨架信息输入到网络中,缺乏对动作的描述。而本文方法使用了RGB视频和深度图两个模态的特征,并且使用外观动态图和运动学动态图。分析可见,本文方法对两人交互动作的识别率相对较高。

表4 在SBU Kinect Interaction数据集上的实验结果Tab.4 Experimental results on SBU Kinect Interaction dataset
3 结语
本文研究了一种基于运动学动态图和双流卷积网络的人体动作识别方法。采用了由视频序列产生的外观动态图和由运动学特征图序列产生的运动学动态图来描述RGB-D视频中外观和运动信息随时间的变化。融合三通道运动学动态图和振幅运动学动态图并与外观动态图共同作为双流卷积网络的输入。在M2I数据集和SBU Kinect Interaction数据集上的实验结果分别为91.8%和95.2%,验证了本文方法的性能。
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20 08:50:04
老年教育(2021年11期)2021-12-12 12:10:46
老年教育(2021年10期)2021-11-10 09:45:28
老年教育(2021年8期)2021-08-21 09:15:16
老年教育(2021年3期)2021-03-22 06:23:06
河北省科学院学报(2020年1期)2020-05-25 06:57:18
数学物理学报(2019年6期)2020-01-13 06:08:08
制造技术与机床(2018年11期)2018-11-23 01:07:50
数学物理学报(2018年3期)2018-07-17 06:15:30
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:12
