
基于Python的网上购物数据爬取
2021-02-28 07:30高雅婷刘雅举
现代信息科技 2021年16期
关键词:网购
高雅婷 刘雅举













摘 要:随着网上购物的盛行,淘宝、京东、拼多多等互联网商业巨头也展开了激烈的竞争。收集商品、评论及销量数据以及对各种商品及用户的消费场景进行分析成了必不可少的环节。然而传统的人工收集并整理数据显然效率不足以满足当下各大公司以及其他相关产业对这些数据的需要。近年来Python爬虫技术的逐渐成熟,给网购数据收集并整理带来了极大的便利。
关键词:网购;Python;pip;爬虫技术
中图分类号:TP311.1 文献标识码:A文章编号:2096-4706(2021)16-0026-06
Online Shopping Data Crawling Based on Python
GAO Yating, LIU Yaju
(Hebei Agricultural University, Cangzhou 061000, China)
Abstract: With the popularity of online shopping, Taobao, Jingdong, Pinduoduo and other internet business giants also launches a fierce competition. Collecting product, review, and sales data, as well as analyzing the consumption scenarios of various products and users, has become an essential links. However, the traditional manual collection and sorting of data is obviously not efficient enough to meet the needs of companies and other related industries. In recent years, the gradual maturity of Python crawler technology has brought great convenience to the collection and sorting of online shopping data.
Keywords: online shopping; Python; pip; crawler technology
0 引 言
我们会发现我们常用的购物软件如:淘宝、京东等总是能给我们推荐符合我们兴趣的商品。这就是因为他们收集了消费者的POI(兴趣点)[1],通过调用数据库来分析到每个消费者的消费偏好,进而给消费之提供感兴趣的商品。各大网购公司,以及相关产业都需要消费者的消费数据如某商品的销量以及评论信息、各种商品及用户的消费场景等数据来进行数据分析。本文将以基于Python的網上购物数据-淘宝商品销量数据爬取为例进行分析。
1 Pyhton爬虫技术概述
爬虫的概念就是一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息[2],其根本原理是递归算法。爬虫技术原本是应用于搜索引擎的,随着程序员前辈们的改进,目前已经成为一项非常通用且实用的数据抓取技术了。能开发爬虫技术的语言有很多种,但是由于Python语言的简单高效,人们更习惯用Python来开发爬虫技术,所以Python爬虫技术已经成为当下主流的爬虫技术。
python语言具有非常高的可行性和有效性,不仅保证了网络爬虫框架实现效果,还提高了网络爬虫系统的运行性能,为用户带来良好的使用体验[3]。
Python爬虫架构主要由5个部分构成,分别是:调度器、URL管理器、网页下载器、网页解析器、应用程序等,如图1所示。
2 实现过程
2.1 基础环境配置
Python爬取淘宝销量数据涉及使用selenium库中的Webdriver操作GOOGLE浏览器进行登陆、搜索、点击按销量从高到低排序、获取页面内容并使用beautiful库解析的过程[4]。
本机环境概述:Pyhton版本为Python3.10.0;编辑器为PyCharm;浏览器使用Google Chrome 95.0.4638.54;驱动器版本为95.0.4638.17;
Python爬虫技术的前期准备是非常烦琐的,但是任何一个环节出现问题,都会导致后期无法顺利运行我们的爬虫代码。
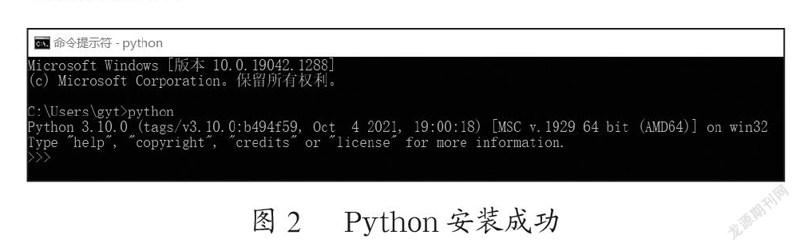
首先是检查我们的Python3.10是否安装完成并且配置好了路径PATH。最简单的方式就是通过cmd命令行来查看,我们在命令行中输入python回车。如出现python的版本号信息,则证明安装配置成功(图2为本机配置成功显示),否则未成功。
一般错误就是未配置路径PATH。可以在“此电脑”右键,选择“属性”,然后选择“高级系统设置”进行手动配置PATH。;亦可卸载,重新安装时勾选 “Add Python 3.10 to PATH”选项。
在Python中需要运用多种多样的函数就得下载相应的库。下载库便需要用到“pipinstall [库名称]”的命令。这便首先需要pip文件配置成功。pip文件的在最新版本的python中是已经配置好了的,在python的安装路径下的script文件夹内。我们可以通过打开python的安装路径的script文件夹查看,我们也可以通过cmd命令行来查询,如果我们输入pip回车,出现如图3所示的界面,则证明我们已经完成pip的安装。
我们不仅需要python的命令行程序,还要安装python的图形化软件PyCharm来方便我们编译运行我们的代码,PyCharm如图4所示。
我们需要用到的很多函数都要来源于不同的库,本次简单的爬虫代码要用到的库有selenium库、requests库。安装指令分别为:
(1)1pip install selenium
(2)pip install requests
图5为安装selenium示例(安装requests库同理)。
Selenium库安超时现象时常出现,因为selenium库较为庞大,建立连接时间过长而未安装成功的现象比较常见,所以我们可以选择安装时指定超时时间例如指令:pip --default-timeout=100 install -U selenium==2.53.6[5] 。
注意:上面指定了selenium的版本号为2.53.6,可以不指定版本号,直接写:
pip --default-timeout=100 install -U selenium即可。
图6是本次实验所需的所有库。
2.2 确定访问接口
我们以淘宝网搜索手机为例,如图7所示。
我们可以看到非常丰富的信息,比如商品价格、店铺名称、手机型号等诸多信息我们本次实验想要提取的信息是商品销量信息。第一步就是确定访问接口。
我们进行翻页处理操作,如图8~图10所示。
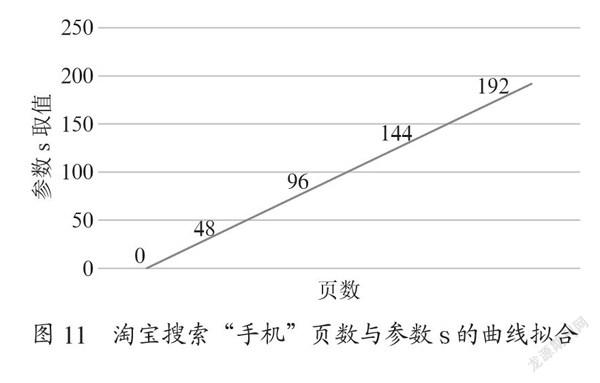
我们观察规律易发现淘宝的搜索接口为:https://s.taobao.com/search?q=。由曲线拟合可得:页数的跳转与参数s呈正相关,s=(页数-1)×48。
我们预测,第五页的地址为:https://s.taobao.com/search?q=手机&p4ppushleft=5%2C48&s=192,进行测试可正确到达第五页,如图12所示,证明我们曲线拟合结果正确。
2.3 代码编写
编辑器使用Python编辑器PC最新版。爬虫代码的核心就是要抓取页面源码的关键字信息,页面源码一般都为HTML格式,所以抓取页面关键字的任务交给getHTMLText()函数最合适不过了,如图13所示。但是使用getHTMLText()函数是需要安装requests库的,我们在上文中已经解释过了requests库的安装方法,在cmd命令行中输入pipinstallrequests指令即可。
完整的代码截图以及运行结果如图14与图15所示。
3 研究过程中遇到的困难
3.1 pipinstall指令失效
当我利用pipinstallelenium命令来在下载elenium插件的时候,遇到问题全片红色警告问题,在网上查阅了好多资料说可能是安装版本过高的原因,但是我安装了较低较稳定的版本也无法成功解决此报错警告。于是拖延了好几天进度,终于有一天在某论坛上看到了有任何我遇到了同样的问题,改作者将本机的代理系统关闭就解决了情况此参照实验,发现果然是代理服务器的问题。关闭即可用“pip install **”指令来进行安装库或者插件了,如图16所示。
3.2 import requests导包出错
导致问题的原因:未安装requests库,想要安装,但是一直安装失败。后来发现是自己断网了,需要在联网状态下安装。解决办法:联网下安装成功。
4 结 论
本次研究,仅仅以python爬虫爬取淘宝“手机”首页销量数据的简单案例展示了python爬虫技术的强大。Python爬虫技术在网上购物数据爬取方面的技术已经趋于成熟,但是我们也只能爬取网站上这些公示的信息数据,不可以爬取消费者或者商家的隐私数据,除此之外我们亦不能爬取更多敏感非法数据。
爬虫技术的逐步成熟,给人们带来便利的同时,也引来了一些争论。有些不法分子利用爬虫技术非法搜集私密信息也对社会造成一定影响;国家知识产权局官网2020年發布的关于知识产权保护文本就完全可以应用Python爬虫技术进行爬取数据保护知识产权。现在看来只对以对爬虫技术的使用加以约束,其造福社会的力度是远远大于其带来的负面影响的。Python爬虫技术的应用已经越来越广泛,现在已经应用于商品销量数据爬取、消费者消费场景收集分析、知识产权保护、招聘信息汇总、国家社科基金项目爬虫等多项领域,接下来必将会渗透到我们生活的各个领域,成为我们解放传统手工信息整理的救星。但是无论如何我们都应当时刻谨记:互联网并非法外之地。
参考文献:
[1] 李霖,杨蕾.公众参与的兴趣点数据有效性效验方法 [J].测绘科学,2015,40(7): 98-103.
[2] 菜鸟教程.Python 爬虫介绍 [EB/OL].[2021-04-26].https://www.runoob.com/w3cnote/python-spider-intro.html.
[3] 吴道君. 大数据背景python在网络爬虫框架中的应用 [J]. 科学技术创新,2021(21): 97-99.
[4] pennykoon.python爬取淘宝销量数据 [EB/OL].[2021-04-26].https://blog.csdn.net/pennykoon/article/details/112150688.
[5] weixin_34199405.windows使用pip安装selenium报错问题 [EB/OL].[2021-04-26].https://blog.csdn.net/weixin_34199405.
作者简介:高雅婷(2000—),女,汉族,河北保定人,本科在读,研究方向:Python爬虫。
猜你喜欢
当代陕西(2022年7期)2022-04-26
小天使·一年级语数英综合(2021年8期)2021-08-17
作文大王·低年级(2020年2期)2020-03-13
数学大王·低年级(2020年2期)2020-03-13
今古传奇·故事版(2017年5期)2017-04-08
知识就是力量(2015年6期)2015-06-09
