
基于BeautifulSoup+requests和selenium爬虫网页自动化处理的实现和性能对比
2021-02-28 07:30:09李晨昊
现代信息科技 2021年16期




摘 要:网络爬虫是一种按照一定的规则,自动地抓取网页信息的程序或者脚本,因此编写特定的网络爬虫可以用来对网页进行自动化处理,从而达到提升工作效率的目的。文章针对同一个任务清单系统,分别使用BeautifulSoup + requests和selenium两种不同的爬虫方法实现了网页自动化处理功能。并且通过对两种方法的实现原理和运行结果进行分析,对两种爬虫方法进行对比。
关键词:爬虫;网页自动化;BeautifulSoup+requests;selenium
中图分类号:TP391 文献标识码:A文章编号:2096-4706(2021)16-0010-04
Implementation and Performance Comparison of Crawler Web Page Automatic Processing Based on BeautifulSoup + requests and selenium
LI Chenhao
(Wuhan Branch of China Mobile Hubei Co., Ltd., Wuhan 430000, China)
Abstract: Web crawler is a program or script that automatically grabs web page information according to certain rules. Therefore, a specific web crawler can be written to process web pages automatically, which provides efficiency improvement. The paper uses two different crawler methods: BeautifulSoup + requests and selenium to implement webpage automatic processing function for the same task list system. By analyzing the implementation principle and operation results of the two methods, the two crawler methods are compared.
Keywords: crawler; webpage automation; BeautifulSoup+requests; selenium
0 引 言
网络爬虫是一种按照一定的规则,自动地抓取网页信息的程序或者脚本。它的基本工作方式是模拟人工的操作去访问网站,并且在网站查找数据或者发送数据。因此爬虫不但能够用来快速获取网页信息,而且能够对网页进行自动化处理。
在实际工作中,碰到了一类任务清单系统,需要对系统里的任务进行处理。处理这些任务的操作大同小异,平均处理一条任务大约需要30秒到1分钟。如果全程依靠人工来完成,不但耗费时间长,而且还存在着人为误差。因此,为了加快任务处理速度、提高任务处理准确率、提升工作效率,编写了python爬虫脚本来对这些任务进行自动化处理。
最初版本的爬虫是基于BeautifulSoup + requests库的方法设计实现的,并且达到了预期的效果。后期由于新系统使用了远程访问模式,网址发生了变更,使得无法用原有方法进行自动化处理。因此重新編写了一个新的基于selenium实现的爬虫。两种爬虫方式虽然最终的都能达到相同的运行效果,但是实现和性能上存在着不小的差异。
1 基于BeautifulSoup + Requests的网页自动化脚本的设计与实现
1.1 设计原理和思路
BeautifulSoup能够从html/xml中通过标签很方便地提取数据[1]。Requests能够向目标网址发送http请求[2]。通过使用BeautifulSoup + requests的模式:先分析网页源码,再提取目标网址,并发送http请求进行数据传输,就能够实现网页自动化处理的功能。
1.2 实现过程
1.2.1 基本流程图
该实现方法如图1所示,首先使用requests包模拟用户登录,并用BeautifulSoup获取页面源码。再使用循环对所有任务进行遍历,判断当前任务是否需要自动处理。当任务需要自动处理的时候,使用requests跳转到任务页面链接,用BeautifulSoup获取页面源码,再用requests的post方法模拟任务提交。
1.2.2 模拟登录
原系统登录页面采用的是“用户名+密码”的验证模式,验证通过后直接跳转到系统内部页面。通过对系统登录时发送的http请求进行分析,发现当前用户的用户名和密码每次都以相同的密文保存在Request Headers的Cookie属性中,并直接使用get方法发送。因此可以将此cookie作为固定值,传入到get请求的header参数中,这样就能够模拟用户进行登录。
1.2.3 遍历任务清单
通过分析网页源码,可以获取任务清单的页数,而根据页数就能够构造任务清单每一页的URL。当前页中的每一条任务也都有一个链接。因此可以通过构造每一页的URL,先对页进行遍历;再对每一页中的任务进行遍历,达到对整个任务清单中的任务进行遍历的效果。
1.2.4 模拟任务提交
经过对任务页面的源码分析测试,发现页面中填写的所有信息都以json形式保存在form data表单中,并通过post方法提交给系统。因此可以根据实际要求制定逻辑,构造一个提交表单form data,传入到post请求的data参数中。这样就能够模拟用户进行任务提交。
1.3 运行结果
脚本中运行后会显示每次运行处理的任务数量和总处理时间。其中处理任务较多的2次运行结果如表1所示。
可以看出,平均每条任务处理时间在5~6秒。而人工处理一条任务所需要的时间大约在30秒,因此可以该脚本达到了提高工作效率的目的。
2 基于selenium的网页自动化脚本的设计与实现
2.1 设计原理思路
Selenium是一种基于浏览器驱动的爬虫方式,能够直接识别动态页面加载后的网页[3-5]。Selenium可以通过对浏览器调试,模拟鼠标点击等、键盘输入等操作,让浏览器产生响应。因此可使用将人工操作步骤直接使用selenium进行模拟,从而达到自动化处理的功能。
2.2 设计过程
2.2.1 基本流程图
该实现方法如图2所示,首先手动登录外部系统,再使用selenium模拟浏览器登录内部系统;登录之后遍历所有任务,判断当前任务是否需要自动处理。当任务需要自动处理的时候,使用selenium对任务页面中各个元素进行定位和填写。
2.2.2 模拟登录
新系统需要从一个外部系统跳转之后进入,不能直接登录。跳转后的URL有一个ticket参数,这个参数每次跳转都会发生变化,因此也无法获取准确的登陆页面URL。外部管控系统采用的是“用户名+密码+滑动验证码+短信验证码”的验证模式;新系统采用的是“用户名+密码+图形验证码”的验证模式。
这种登录模式下,由于有滑动验证码和短信验证码的存在,如果还使用BeautifulSoup + requests模式的话,是无法获取到相关信息的。因此最后决定使用selenium,并采用“手动准备+自动填写+键盘输入”的对模拟系统登录,步骤为:
(1)用户手动进行“用户名+密码+滑动验证码+短信验证码”验证登录外部系统,跳转到新系统登录页面,并将登录页URL保存到本地文件。
(2)使用selenium读取本地文件中的URL,填入预设的用户名和密码。
(3)在命令行输入键盘图形验证码。
(4)模拟登录。
2.2.3 遍历任务清单
Selenium遍历的任务清单的方法比较直接。模拟鼠标点击最后一页,然后不断点击“上一页”,直到访问到第1页。在每一页中,也都能够通过分析网页源码,定位到任务链接所在的元素,模拟鼠标点击,来进入到具体的任务。
2.2.4 模拟任务提交
Selenium模拟任务提交的方法也很直接。直接从源码中定位到对应元素,根据元素类型不同调用不同方法进行填写。如果是下拉框就调用click方法选中下拉元素,如果是输入框就通过send_key方法进行文本填写。填写完成后再定位到提交按钮调用click方法模拟鼠标点击,就能够模拟任务提交。
2.3 运行结果
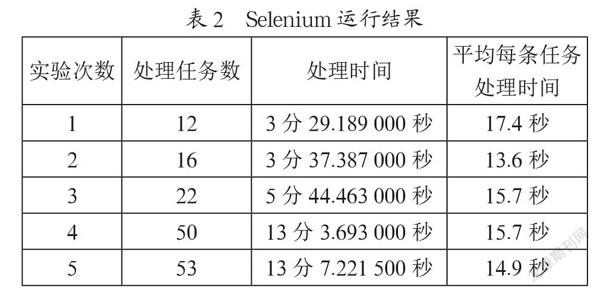
脚本中运行后会显示每次运行处理的任务数量和总处理时间。挑选其中5次处理任务数不同的运行结果如表2所示。
可以看出,平均每条任务的处理时间在10~20秒,相对前面一种方法的运行速度较慢,但是仍然比人工操作的速度要快。
3 兩种自动化脚本特性分析
3.1 BeautifulSoup+requests自动化脚本特点
3.1.1 非可视化
BeautifulSoup + requests脚本本质上是通过构造HTTP请求方法来模拟网页访问的,获取到的网页源码只是以变量形式存在于脚本中,对用户来说是“看不见”的,整个过程没有可视化界面出现。
3.1.2 无法获取动态网页源码
在使用BeautifulSoup + requests调试期间发现,使用requests访问任务清单系统主页URL时,获取到的网页源码中只有标题和用户信息,并没有其他网页元素。这是因为BeautifulSoup + requests只能获取静态网页的代码,而无法获取通过动态加载才能出现的网页源码。因此在代码编写中,必须要跳过动态生成的页面,直接定位到目标信息出现的页面,而这个页面往往不会是主页,因此这也是这种实现方式的难点。
3.1.3 构造数据包
构造数据包分为两种,一个是构造header包,一个是构造form表单。header包是用来模拟浏览器和传递cookie值的;form表单是用来将提交给目标网页用作下一步操作的。这两种数据包都需要在编写代码时手动进行构造,只有当这两种数据包构造正确时,才会生成正确的HTTP请求。因此正确地构造header和form表单是这中实现方式成功的关键。
3.1.4 难以使用键盘输入辅助
通过观察HTTP包发现,数据包中传输的某些字段是使用的密文。例如在模拟用户登录时,在HTTP包中传输的对应字段并不是登陆所使用的用户名和密码的原始字符串,而是经过加密的字符串,并且而这种加密方式不能够确定。这种特性导致了这种实现方式很难利用键盘输入信息进行辅助。
3.2 Selenium自动化脚本特性
3.2.1 驱动程序依赖
Selenium是需要对浏览器进行调试的,因此需要另行下载当前浏览器当前版本的驱动程序,并且不同浏览器所需要的驱动程序也不一样。
3.2.2 可视化
Selenium启动时会运行打开一个浏览器,并且整个页面的操作都是可视化的。能够清楚的看到网页上的元素变化,包括按键点击、文本填写、页面跳转等。
3.2.3 可获取动态网页
Selenium最终获取的是网页加载完毕时候的源码,因此动态加载对selenium没有任何影响。
3.2.4 模拟操作事件
基于Selenium的自动化基本可以分为两步:首先要定位到网页上的某一个元素;然后再模拟这一元素上发生的事件(例如鼠标点击和文本填写)。因此准确地定位到对的网页元素是这种实现方式成功的关键。
3.2.5 等待加载
使用selenium调试时,经常会出现这种状况:由于浏览器UI的加载速度遠远慢于代码的执行速度,当某条代码让网页加载新元素时,下一条代码需要读取新元素的信息;然而当代码运行到下一句的时候,目标新元素并没有及时加载出来,使得后一句的代码实际上读取了一个不存在的元素,从而导致报错。
为了避免这种情况的出现,脚本在各种操作之间加上了被动的等待语句,使得脚本能够在浏览器完成加载之后再进行读取。
3.2.6 可以使用键盘输入辅助
因为selenium是在浏览器中模拟各种操作的,因此可以使用键盘输入信息进行辅助。2.2.2中模拟登录就是采用了键盘辅助的方式进行的。
3.3 两种实现方式对比
以上两种实现方式都能够达到让网页自动化处理的效果,但是可以看出两者在实现机制、关键步骤、执行速度上有着明显的区别。
从表3中可以看出,BeautifulSoup + requests自动化脚本运行速度快,但是实现难度较大,适用于登录验证简单,并且容易获得静态页面的网页。Selenium实现方式因为有浏览器的可视化运行,以及被动等待操作,运行速度相对较慢(仍快于人工操作);但是实现方式较为简单,相对适用于登陆验证复杂,需要获取动态加载内容的网页。
4 结 论
本文分别使用BeautifulSoup + requests和selenium两种爬虫方法对不同登陆验证模式下的同一个任务系统进行自动化处理功能实现,并且通过对两种自动化实现方式的特性分析进行比较,总结了两种爬虫方法的使用场景。下一步期望能够将两种爬虫方法混合,既具有BeautifulSoup + requests的快速运行特性,也具有selenium的模拟复杂登陆特性。
参考文献:
[1] 欧阳元东.基于Python的网站数据爬取与分析的技术实现策略 [J].电脑知识与技术,2020,16(13):262-263.
[2] 王鑫.基于Python的微信公众平台数据爬虫 [J].福建质量管理,2019(17):270-271.
[3] 高艳.基于Selenium框架的大数据岗位数据爬取与分析 [J].工业控制计算机,2020,33(2):109-111.
[4] 刘军.基于Selenium的网页自动化测试系统设计与实现 [D].武汉:华中科技大学,2014.
[5] 沈承放,莫达隆.beautifulsoup库在网络爬虫中的使用技巧及应用 [J].电脑知识与技术,2019,15(28):13-16.
作者简介:李晨昊(1990.06—),男,汉族,湖北武汉人,中级通信工程师,硕士研究生,研究方向:计算机。
猜你喜欢
计算机应用(2023年6期)2023-07-03 14:11:56
计算机时代(2023年6期)2023-06-15 17:49:09
作文小学中年级(2022年11期)2022-11-25 09:52:08
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
课堂内外(小学版)(2020年11期)2020-12-04 06:38:44
计算机与网络(2020年17期)2020-10-12 14:46:34
电子测试(2018年14期)2018-09-26 06:04:24
电子测试(2018年1期)2018-04-18 11:53:04
中学生(2017年19期)2017-09-03 10:39:07
