
基于BP神经网络的汽车外观设计评价方法
2021-02-27 04:49:32李彦龙孙久康
同济大学学报(自然科学版) 2021年1期
李彦龙,蔡 谦,孙久康,高 想
(1.同济大学汽车学院,上海201804;2.上汽大众汽车有限公司设计部,上海201804)
随着汽车技术的日益成熟,消费者选购汽车的因素逐渐转向审美、情感等方面[1],而汽车外观能直观地体现消费者的审美品味以及身份地位,成为消费者重点关注的对象。但是,目前关于汽车外观评价的研究大多是针对企业内部的方案评审[2],而在面向消费者使用的汽车评价实践中,如汽车门户网站的车主评论系统,汽车外观只是众多评价指标中的一个[3],并且以消费者的主观评价居多,不同的人会有不同的评价观点,从而造成评价结果各异,不能够客观地评价一款汽车外观设计。如何结合定量评价与定性评价得到更为可靠、真实的评价结果,为汽车外观设计的发展和应用提供可靠支撑,是当前汽车外观设计领域面临的重要问题。
1 BP神经网络简介
人工神经网络模仿了人脑认识事物过程中针对事物进行判断分析的学习状态,最终解决不同领域所出现的问题。人工神经网络具有较好容错性,可以通过其良好的非线性迫近能力对描述变量与目标之间的非线性关系进行研究[4]。
常用的用来解决非线性问题的一种人工神经网络算法是BP神经网络。BP神经网络由输入层、中间层和输出层构成。中间层也就是隐含层,可以是一层或者多层。BP神经网络的工作过程分为信息流的正向传播和误差的反向传播。正向传播时数据的传递方向为输入层→中间层→输出层,每一层神经元只受上一层影响。如果输出的数据与期望的数据误差大于期望误差,则进入误差的反向传播。这2个过程交替进行,神经网络在权向量空间进行误差函数梯度下降,动态迭代各层神经元权向量值,直到输出数据在误差范围内停止计算。人工神经网络使用激活函数在层与层之间加入非线性因素,以解决线性模型所不能解决的问题。
本采用了3层BP神经网络。确定一个BP神经网络模型的结构需要设置BP神经网络层数、隐含层数、各层神经元个数以及各层网络激活函数。3层BP神经网络的多指标综合评价模型的拓扑结构如图1。图中,Xn为评价指标的各项输入值;Xpn为经过数据预处理的评价指标值,同时也是神经网络的输入;ωij为神经网络输入层的输出值,同时也是隐含层的输入值;ωj为隐含层的输出值,同时也是输出层的输入值;Op为输出层的输出值,即评价结果。
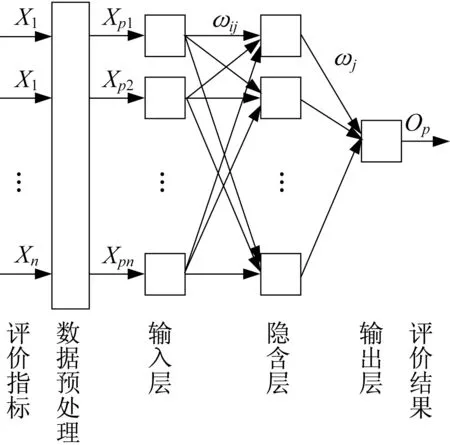
图1 3层神经网络的多指标综合评价模型Fig.1 Multi-index comprehensive evaluation model of three-layer neural network
2 汽车外观设计多指标综合评价方法
多指标综合评价方法包括4个步骤:①建立评价指标体系,即确定神经网络输入层指标的个数;②BP神经网络样本数据的获取,包括对原始样本的异常值剔除及归一化处理;③确定BP神经网络模型的结构,在MATLAB中编程,将样本数据输入网络进行模型训练;④模型的学习能力和预测能力检验。
2.1 建立评价指标体系
采取网络问卷调查的方式进行产品设计评价。评价的目的是确定外饰造型的评价指标,即确定神经网络输入层指标的个数。问卷的设计、发放与问卷数据的处理、获取主要分为以下几个步骤:
(1)明确评价问题。本阶段中需要调查的是消费者对外饰中不同造型要素的关注程度。问卷设计的关键在于:如何向被调查者解释“造型”这一相对抽象的概念。很多相关研究都是根据汽车的特征面和特征线对汽车设计要素进行分类,但这些特征面和特征线的名称比较学术,消费者不易理解[5]。因此,将汽车外观要素分解为3个方面的信息,即前视造型、侧视造型和后视造型,以少量相对抽象的整体指标结合一些具体的局部指标作为设计要素,并使用清晰的语言、图片描述帮助消费者理解并进行针对性评价。
(2)确定评价方式。采用百分制打分,分数越高,表示该消费者对该设计要素的关注程度越高。
(3)实施评价活动。问卷填写者主要面向18岁至60岁的用车群体与潜在购车群体。问卷收回后应舍去无效问卷,保留有效问卷。
(4)数据处理。统计各个设计要素所得分数的平均值。
(5)评价指标的筛选。汽车外饰造型有大量设计要素,若将所有要素都作为神经网络输入层的评价指标的话,后续工作量过大,且一些评价要素并不是消费者关注的重点。因此,根据得分筛选出一些消费者关注较多的外观设计要素作为评价指标。
2.2 BP神经网络样本数据的获取及处理
首先选取一系列样本车型,采取网络问卷的形式,让被调查者对一系列车型的各项评价指标的设计以及车型的总体设计进行百分制打分,得到原始的样本数据。为防止部分受访者对相关评价指标不熟悉,在调研前采用文字以及图片的方式告诉其各个评价指标的具体指代,并要求在打分时尽量不考虑汽车品牌及价格,而仅仅关注其外观设计本身。
在统计数据时,偶然误差、人为误差、抽样误差等常常导致异常值的出现[6]。一般情况下,可以认为受访者对各个车型不同评价指标的打分符合正态分布,为了避免极少数人存在较强的主观情绪或者调研过程中出现的记录错误,需要对各个车型各个评价指标所得分数及总分进行异常值检验。利用格鲁布斯检验法双尾检验剔除异常值。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱了数值较低的指标的作用。因此为了保证分析结果的可靠性,还需要对原始数据进行归一化处理。
最常用的归一化方法有min-max标准化与zscore标准化方法。本文采用min-max标准化方法。该标准化又称0-1标准化,即对原始数据进行线性变换,使结果落到[0,1]区间,转换函数如下:
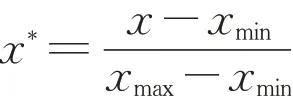
式中,xmax为样本最大值,xmin为样本最小值,x为样本值,x*为标准化结果。
对原始样本数据进行上述处理后,对各项评价指标的打分即为神经网络的输入数据,车型的总体设计打分作为输出数据。
2.3 模型训练
BP神经网络可以实现从输入到输出的任意非线性映射。BP神经网络算法流程如下[7]:①初始化神经元之间的权重;②通过预处理对应问题的样本数据得到训练样本以及期望输出集;③获取神经网络中各层的输出;④获取神经网络中各层的误差;⑤通过反向传播修正神经网络权重以及阈值;⑥重新得到训练样本、输出集,返回②,计算结果直至满足预先设定精度要求;⑦如不满足设定的精度要求或最低训练次数,重新返回⑥。具体流程图如图2所示。
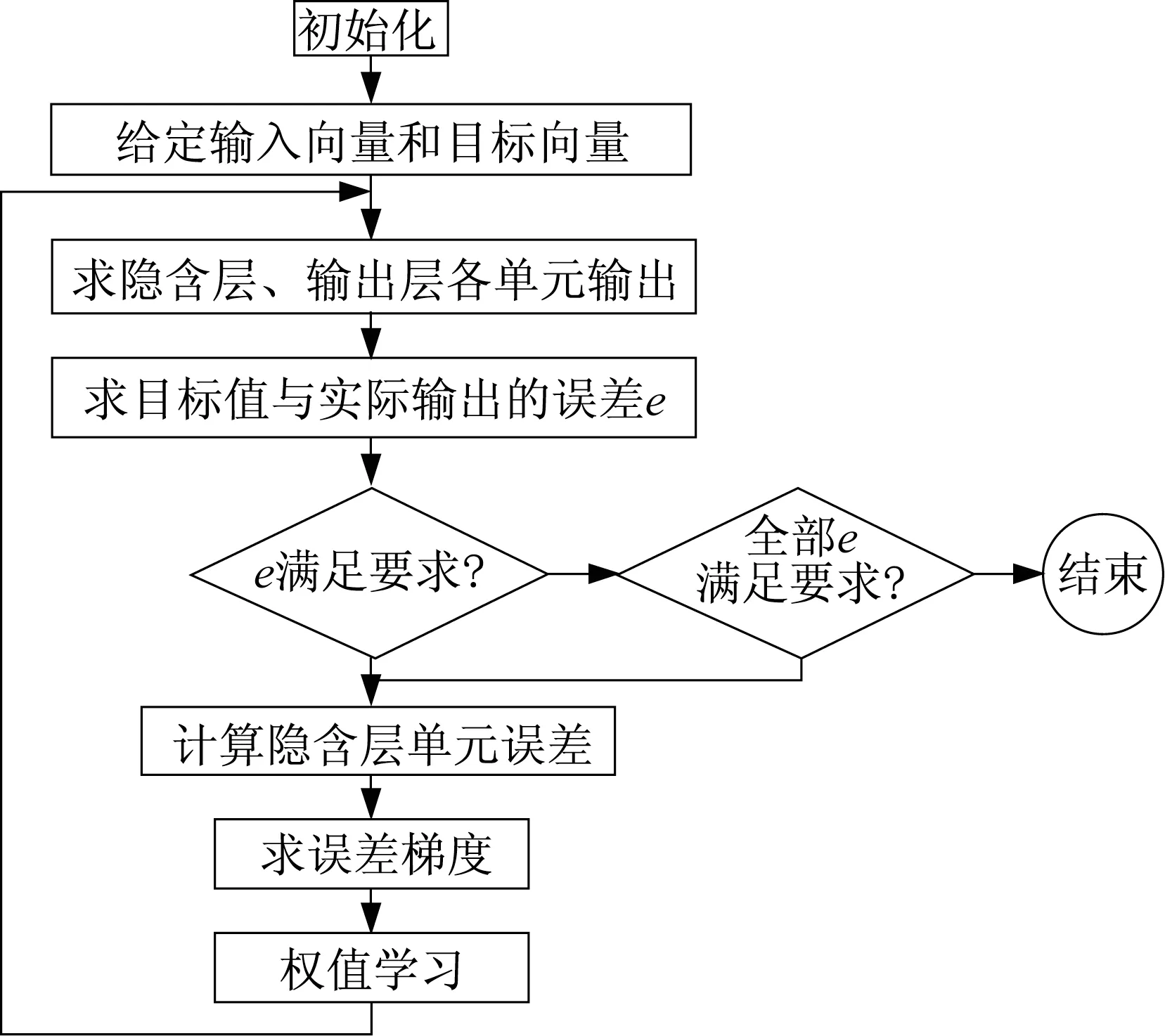
图2 BP算法框图Fig.2 Block diagram of BP algorithm
2.4 模型检验
一个训练完成的神经网络最理想的状态是网络的实际输出与期望输出完全一致。事实上,这种情况基本不可能出现,也没有必要。在实际操作中,训练精度过高,神经网络会学习到一些本身并不存在的规律,降低网络的泛化能力,导致网络在预测非训练样本时误差较大。因此在学习能力的检验中,往往允许在一定的误差范围内的训练误差。预测能力是指训练完成的模型对非训练样本的输出也具有较好的预测能力。选取非训练样本输入模型,如果模型的预测输出与期望输出在合理的误差范围内,则可认为所建立的神经网络模型具有较好的泛化能力,是实际可靠的。
3 汽车外观评价模型的建立与分析
3.1 建立汽车外观设计评价指标
首先,通过问卷调研的方式,筛选出消费者关注较多的设计要素。选取27个汽车外观部件作为局部要素,它们在车身上的位置如图3所示。此外,考虑到局部部件的造型好坏并不能完全反映出一款汽车外观设计的整体水平,因此还需要设置一些相对抽象的整体要素。根据前人对汽车外观设计美学规律的研究,设置了8个整体要素:比例姿态、体量、色彩设计、光影效果、线面特征、品牌语言、整体气质、形状特征。
此次问卷主要调研对象为本科生、研究生同学及其家人。大学生群体属于潜在消费者,而其家人往往是用车群体或潜在消费者。共发放问卷50份,收回有效问卷46份。
统计上述各个局部、整体设计要素所得分数的平均值,从中选取了消费者关注最多的15个局部部件作为最终的局部指标、3个整体要素作为最终的整体指标。上述18个指标共同组成评价指标体系,见表1。
3.2 获取汽车外观样本数据
确定表1的汽车外观设计评价指标后,选取了28款车型,通过问卷调查的方式让50名受访者对这28款汽车的外观的各个评价指标及总体设计以百分制进行打分,得到原始的样本数据。其中,编号1-20车型的数据用于神经网络的训练,编号21-28车型的数据用于神经网络的检验。
调研时让受访者观察的28款汽车,每款车使用5张不同角度的照片进行展示,如图4。
为防止打分中的异常值对最后的结果产生影响,利用格鲁布斯检验法剔除异常值。格鲁布斯检验法的统计量为
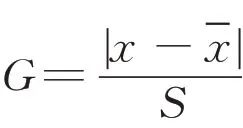
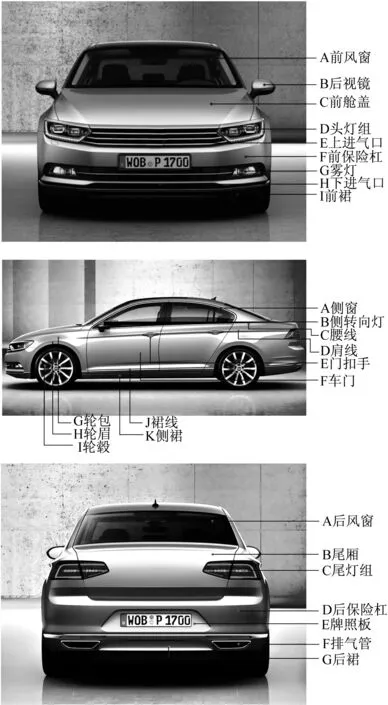
图3 27个局部设计要素在车身上的位置Fig.3 Location of 27 local design elements
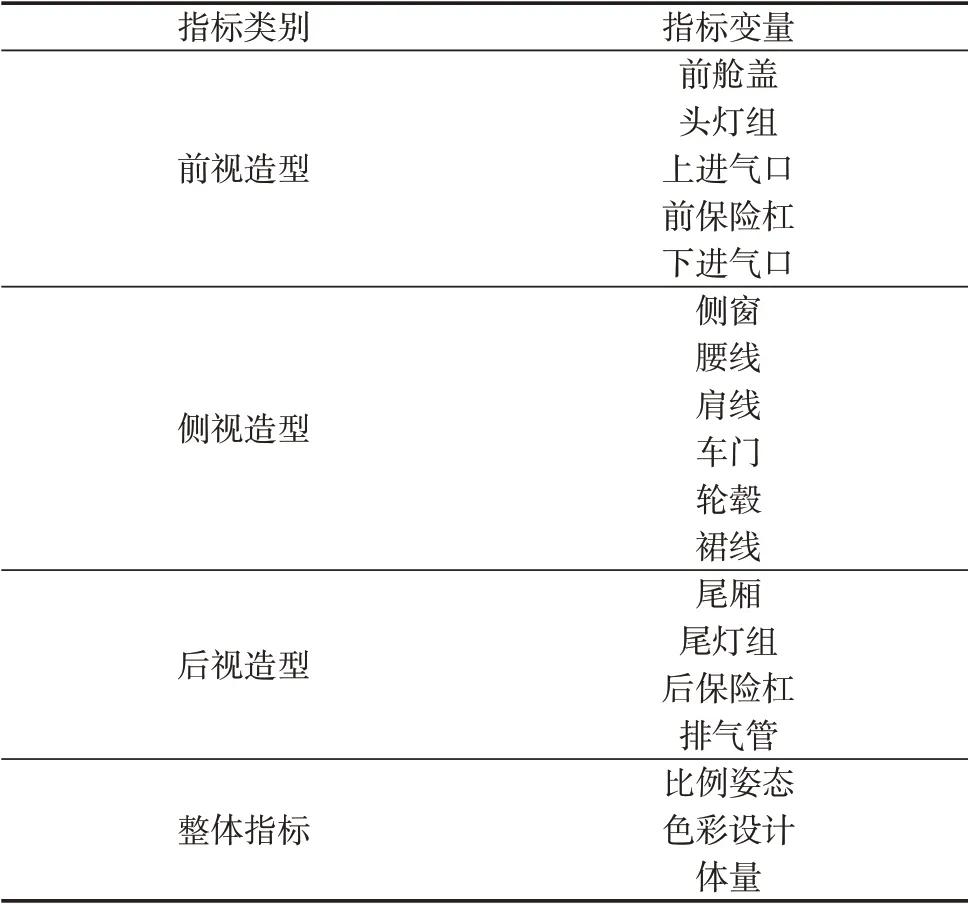
表1 汽车外观的18个评价指标Tab.1 18 evaluation indicators of car exterior
经过检验,共去除异常值67个,其中记录错误的数据19个(例如出现超出给定打分范围的数据),其余48个数据一般是部分受访者对部分车型的一些指标存在较强的主观情绪导致的极端数据。此处列出去除异常值后部分样本车型各个评价指标的得分,由于50名受访者的调研数据过多,所以这里的结果为取平均数的结果,也就是神经网络模型输入层的数据,见表3。

图4 问卷中某款汽车外饰造型展示方式示例Fig.4 An example of exterior styling display of a certain car in the questionnaire
采用min-max标准化方法对28个样本的“总分”项数据进行归一化处理。该标准化又称0-1标准化,为了使结果分布在0~1之间,使用函数对原始数据进行线性处理,转换函数如下:
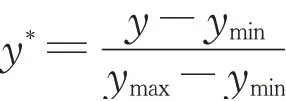
式中,y*为标准化结果,y为的某个样本的总分分值,ymax为所有样本总分中的最大值,ymin为最小值。
用于训练的1-20号样本和用于检验的21-28号样本的“总分”项的原始数据、归一化数据分别如表4、表5所示,也就是神经网络模型输出层的数据。

表2 格鲁布斯检验法临界值检验Tab.2 Critical value test of Grubbs test
4 模型训练与测试结果
4.1 BP神经网络的算法与训练
4.1.1 学习算法的选择
标准BP算法对于一些较复杂或者数据量较大的模型,运行效率较低,收敛速度慢,所需要的训练时间较长。针对标准BP算法可能出现的问题,学者们研究出了各种改进的BP算法。LM算法是高斯牛顿法与梯度下降法的结合,实质是二阶梯度算法[8]。其结合了标准梯度下降法和牛顿法二者的优点,不仅能够使得任意的二次函数获得较快的收敛速度,同时对非二次函数也同样有效,在提高了网络精度的同时也缩短了训练时间。在MATLAB神经网络工具箱中,使用trainlm函数即可实现LM算法。
4.1.2 其他函数及参数的确定
(1)输入、输出神经元个数的确定。根据汽车外观评价指标的个数可以确定神经网络模型中输入层共有18个神经元,评价结果只有“总分”一项,决定了输出层神经元数为1。
(2)隐含层神经元个数的确定。如何确定令神经网络输出最精确的隐含层神经元数,直到如今在理论上也没有给出一个确定的规定。在大多数情况下确定隐含层节点数还是利用试凑法[9]。在采用试凑法时,可以利用经验公式计算所得的结果作为试凑的初始值。
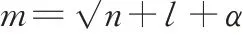
式中,m为隐含层节点数,l为输出层节点数,n为输入层节点数,α为1~10之间的常数。
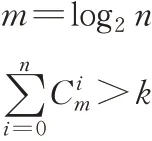
式中,i为0~n之间的常数,n,k为样本数。根据初步试验,本模型隐含层节点数为4时网络收敛,从而确定隐含层节点数为4到14。接下来利用试凑法确定最佳隐层神经元个数,分别对隐层数为3和4的BP神经网络进行不同隐含层节点数的训练,训练结果误差如表6、表7所示。
由表6、表7可以得出随着隐含层神经元数的增加,BP神经网络的训练误差呈下降趋势,但当隐含层神经元数大于等于8时,训练误差已经趋于稳定,改善效果并不明显,为了防止出现隐含层节点数过多可能产生过度训练的情况,该BP神经网络隐含层节点数取8。
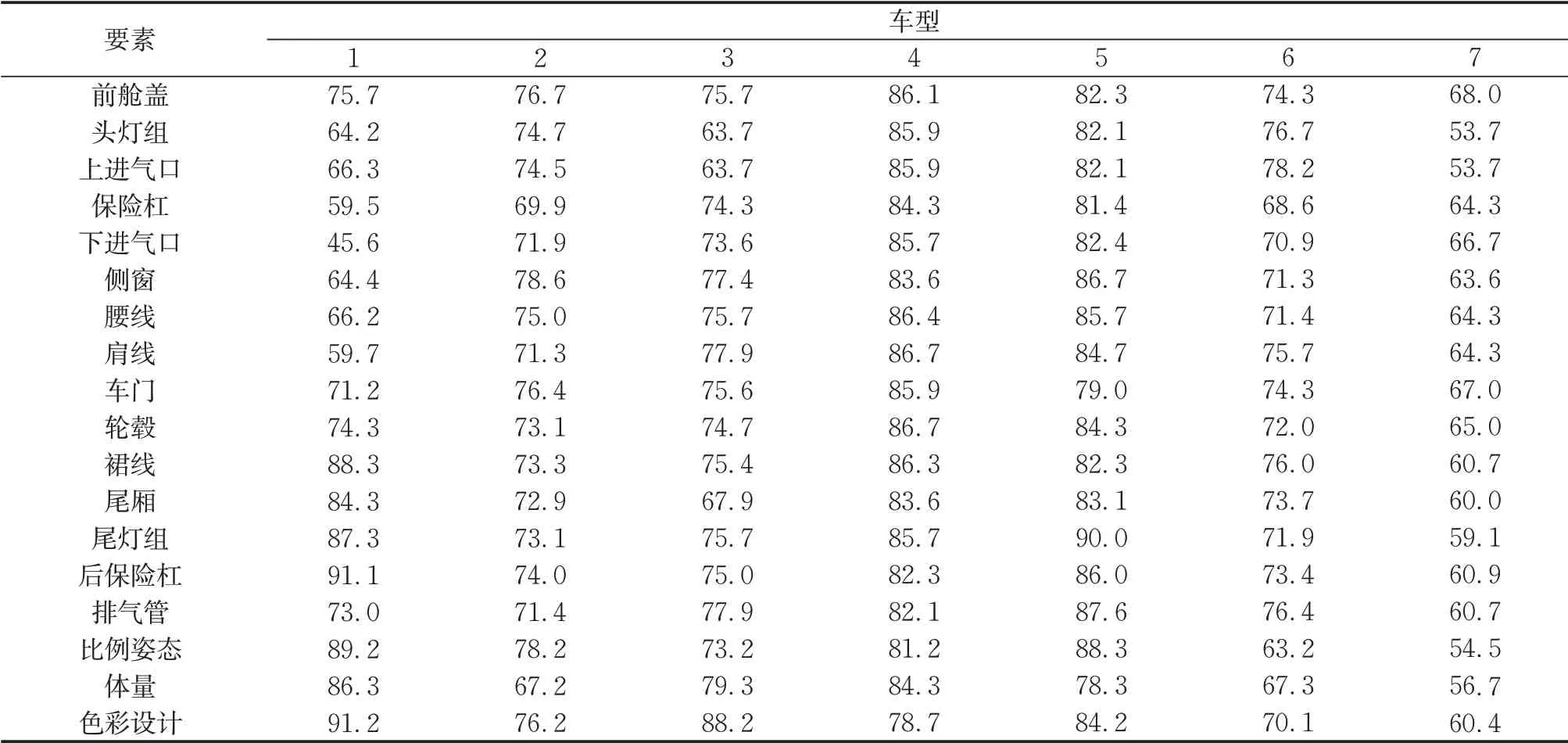
表3 神经网络模型输入层数据(部分)Tab.3 Data of input layer of neural network model(partial)
(3)激活函数的选择。BP神经网络的激活函数有对数S型函(Log-sigmoid)、双曲正切函数(Tansigmoid)和线性函数(Purelin)3种类型,其取值范围分别为(0,1),(—1,1),(—∞,+∞),本文所建立的网络模型的输入和输出都在(0,1)之内,且对数S型函数容错性较好,分类更准确合理,故选择对数S型函数(Log-sigmoid)作为输入及输出层的激活函数,其在MATLAB软件中用logsig函数表示。
(4)其他参数的选择。目标收敛误差设置为1×10-5,最大训练次数设置为2 000,误差函数选择为方差性能分析函数(MSE),其表达式为
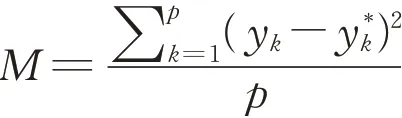

表4 训练样本总分的原始数据及其归一化数据Tab.4 Original and normalized data of total score of training samples
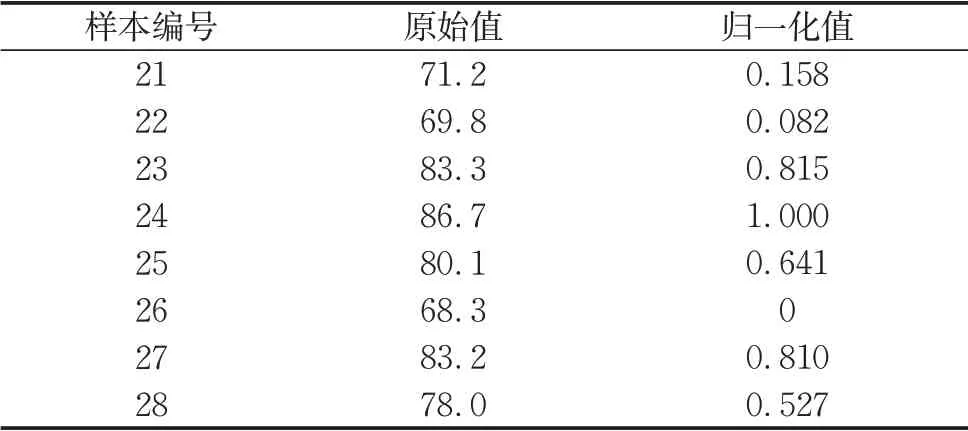
表5 检验样本总体得分的原始数据及其归一化数据Tab.5 Original and normalized data of overall score of test samples
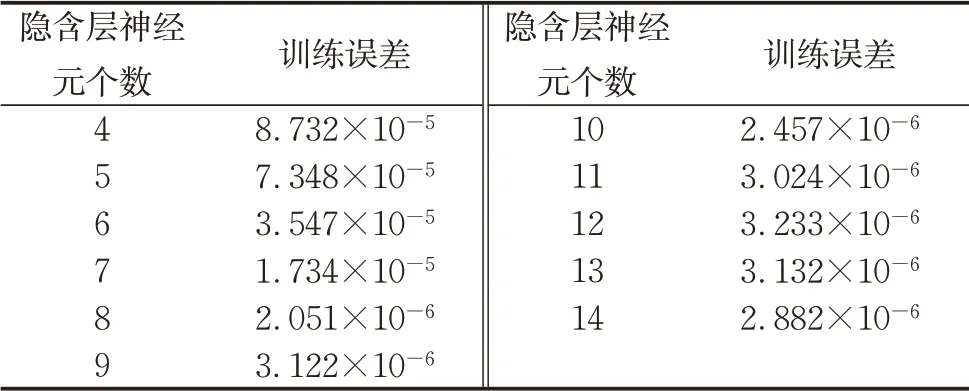
表6 3层BP神经网络不同隐含层神经元数的训练误差Tab.6 Training error of different neurons in hidden layers of three-layer BP neural network
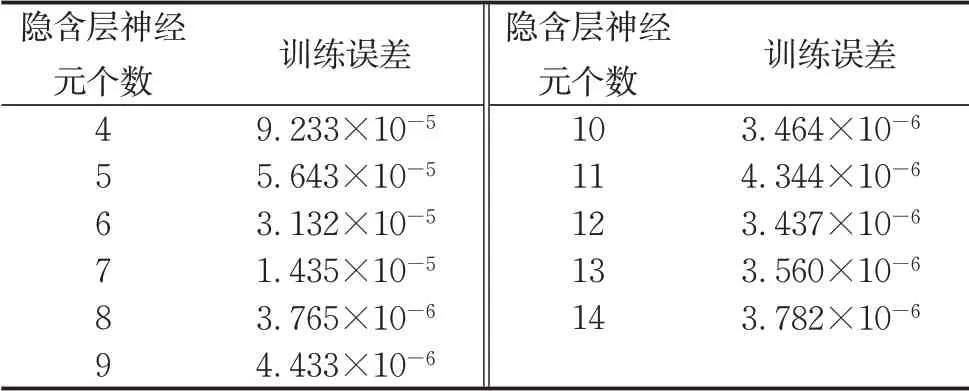
表7 4层BP神经网络不同隐含层神经元数的训练误差Tab.7 Training error of different neurons in hidden layers of four-layer BP neural network
其中,yk为神经网络的实际输出,y*k为期望输出,p为神经网络输出层神经元个数。
4.1.3 网络的训练
所建立的神经网络为输入层神经元数为18、中间层神经元数为8、输出层神经元数为1的3层BP神经网络,MATLAB模型如图5。将1-20号训练数据输入网络进行训练,训练完成。如图6所示,经过152次迭代后输出误差小于收敛误差。

图5 BP神经网络MATLAB模型Fig.5 MATLAB model of BP neural network
4.2 BP神经网络的检验
(1)BP神经网络学习能力的检验。如表8所示,期望输出为1-20号车型的总体设计得分,可以反映其整体造型设计的好坏,训练结果为神经网络模型经过使用这20组数据进行训练后的输出,相对误差为网络的对20款车型的评价学习结果与实际得分的相对误差。如图7,BP神经网络模型训练结果与期望输出的最大相对误差为5.15%,最小相对误差为零,平均相对误差为1.82%,预测结果相对较准确,说明该模型的学习能力以及可靠性较好。
(2)BP神经网络预测能力的检验。如表9所示,期望输出为这21-28号共8款车型的总体得分,可以反映其总体造型设计的好坏,网络输出为训练成熟的神经网络模型对这8款车型总体设计的预测分数。如果模型的预测输出与期望输出在合理的误差范围内,则可认为所建立的神经网络模型具有较好的泛化能力,是实际可靠的。
如图8,本文构建的基于BP神经网络的汽车外观设计评价模型预测结果的最大误差为7.92%,最小误差为1.43%,平均相对误差为3.54%,小于5%,说明评价模型较可靠,具有较好的泛化能力和容错性。这说明经过训练的神经网络对汽车外观评价具有一定的参考意义,为汽车外观设计评价提供了一个相对客观的方法,对工程应用具有一定的参考价值。
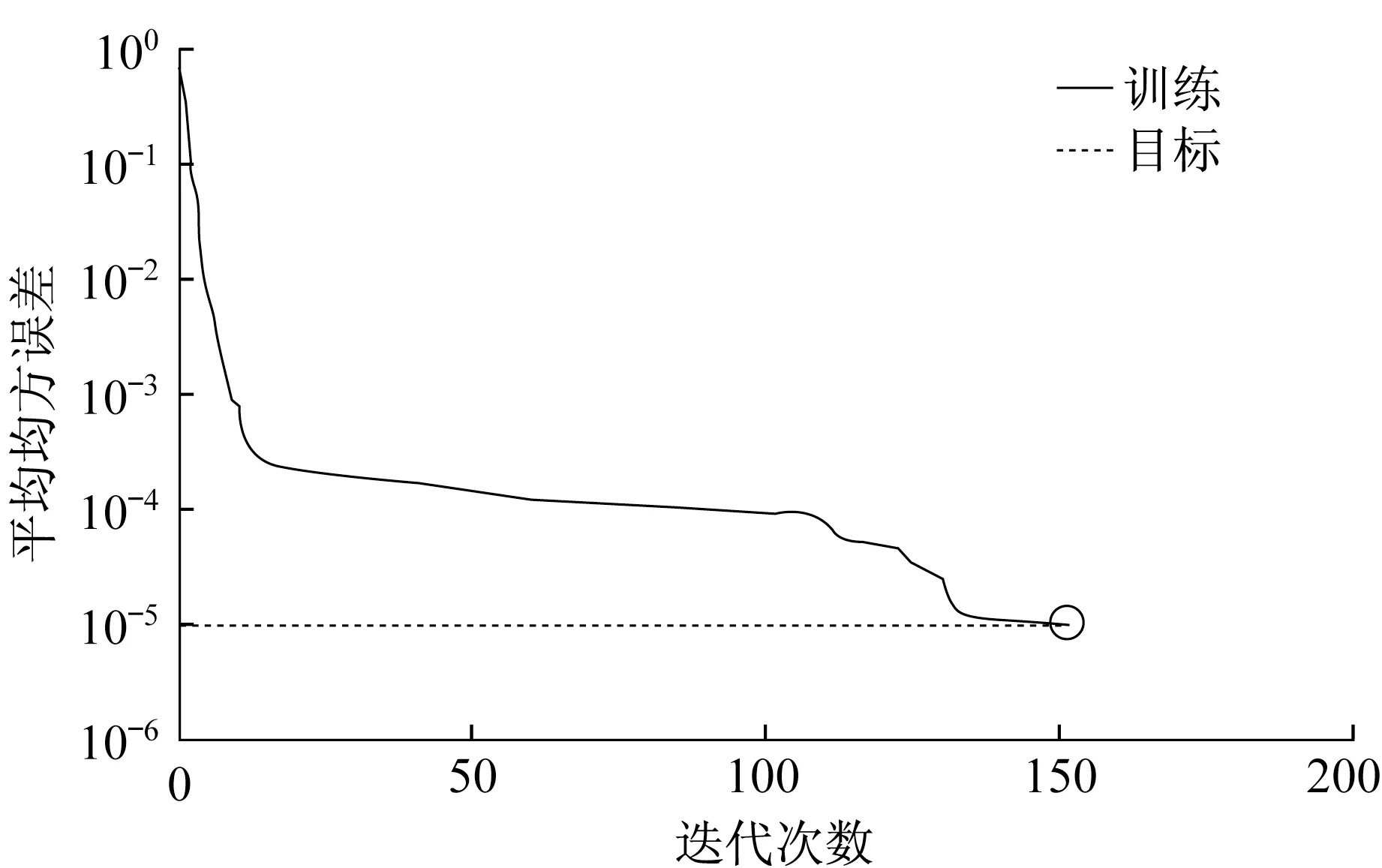
图6 BP神经网络输出误差变化图Fig.6 Variation of output error of BP neural network

表8 神经网络训练结果Tab.8 Training results of neural network
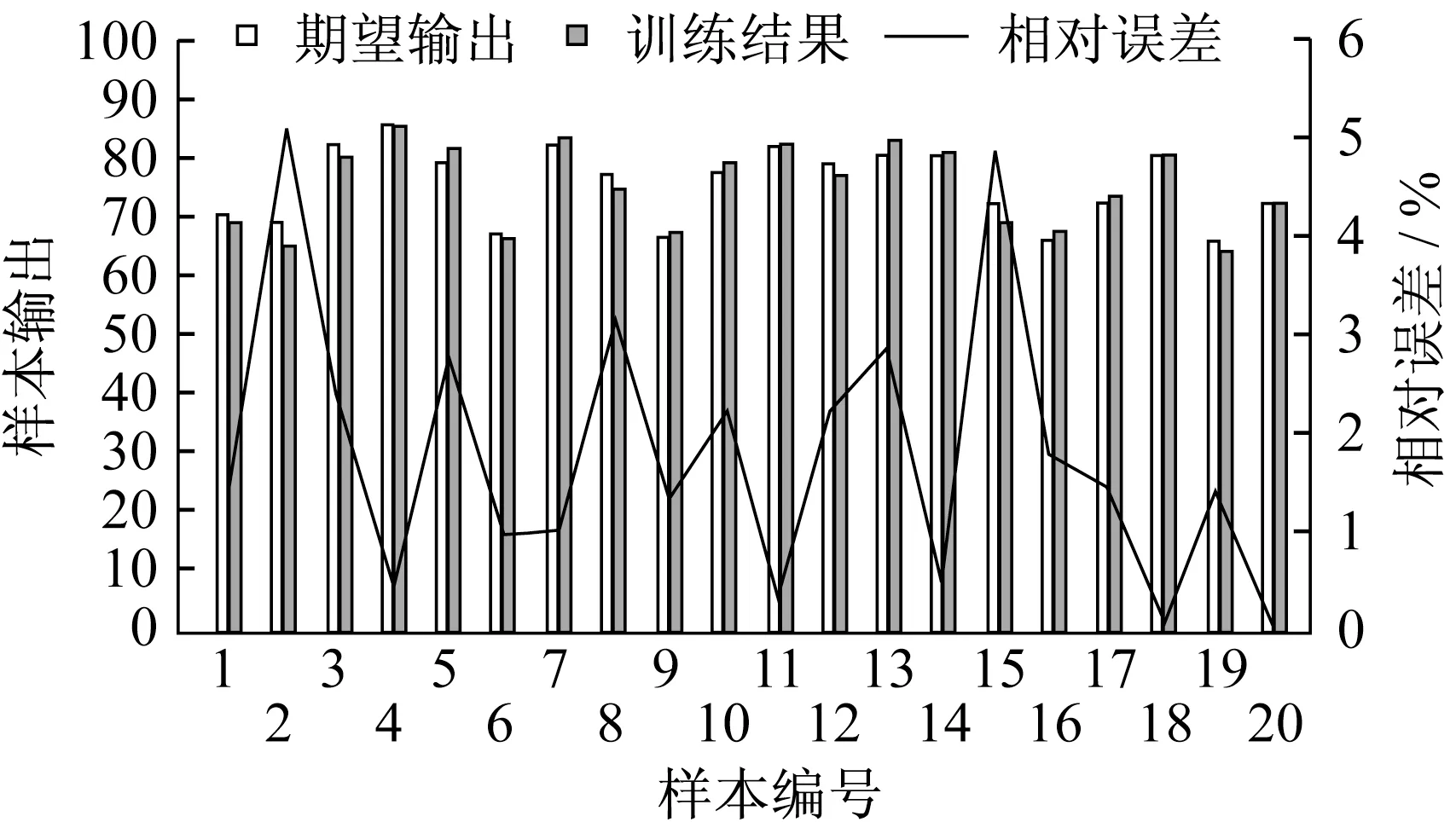
图7 BP神经网络模型训练结果与期望输出对比Fig.7 Comparison of training results of BP neural network model and expected output
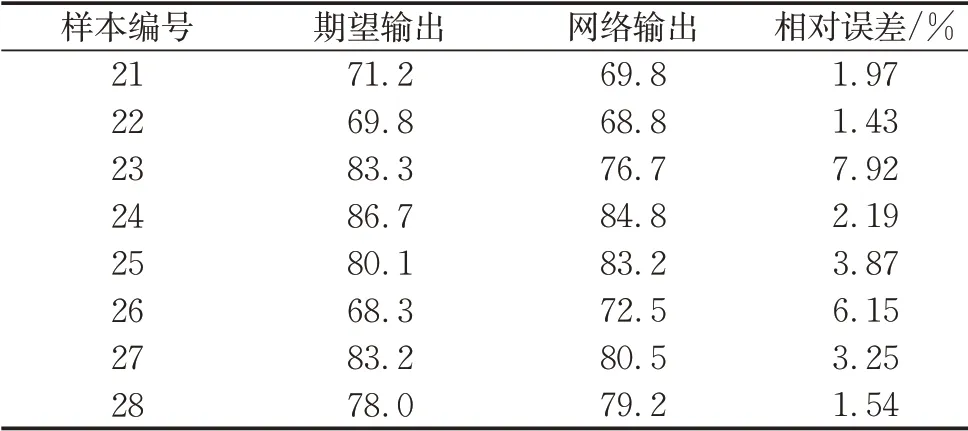
表9 神经网络测试结果Tab.9 Test results of neural network
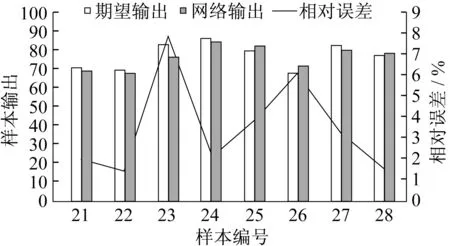
图8 BP神经网络模型预测值与期望输出对比Fig.8 Comparison of predicted value of BP neural network model and expected output
5 结语
应用人工神经网络对汽车外观造型设计进行评价是一种非线性的定量评价方法。本文的网络测试表明,网络具有良好的学习能力与预测能力。人工神经网络的非线性拟合能力可以很好地对汽车外观设计进行评价,为汽车外观设计的评价提供了一条新的路径。
作者贡献申明:
李彦龙:作为指导老师,负责管理和协调整个研究过程与论文撰写过程。具体包括对本文研究方向可行性的评估,BP神经网络建模的基本原理与建模流程的指导,论文架构的修改与调整等。
蔡 谦:作为企业专家,给予案例指导意见。具体包括提供车型评价样本,指导并评估本文汽车外观评价指标选择的科学性、调研问卷设计的合理性。同时,与工作实践相结合,评估本研究建模结果的实用性。
孙久康:负责文献资料调研整理、具体建模过程以及论文文字撰写与修改。
高 想:负责2份问卷的设计、发放,模型输入数据的预处理及图表制作。
猜你喜欢
自然杂志(2021年6期)2021-12-23 08:24:46
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
电子制作(2019年19期)2019-11-23 08:42:00
中国特种设备安全(2019年1期)2019-03-13 01:06:26
现代装饰(2018年5期)2018-05-26 09:09:01
重型机械(2016年1期)2016-03-01 03:42:04
山东青年(2016年2期)2016-02-28 14:25:41
大连工业大学学报(2015年4期)2015-12-11 04:06:52
电源技术(2015年5期)2015-08-22 11:18:38
