
基于神经网络的车辆交通协调性评价模型
2021-02-27 04:50:06陈君毅蒙昊蓝
同济大学学报(自然科学版) 2021年1期
陈君毅,陈 磊,蒙昊蓝,熊 璐
(同济大学汽车学院,上海201804)
自动驾驶技术近年来受到了汽车行业和学术界的广泛关注,在自动驾驶技术开发和应用的过程中,智能性评价是其中重要的环节。自动驾驶汽车智能性不仅体现在车辆自身的行驶智能性,同时也体现在与其他交通参与者的交互质量上[1]。例如Wei等[2]在研究决策规划算法时考虑了社会合作行为,其内涵是本车估计其他交通参与者意图并做出相应的应对策略和控制行为,从而实现更被人类驾驶员接受的协同驾驶。Meng等[3]提出了一种多维度行驶智能性综合评价框架,从车辆交通协调性、行驶自治性、学习进化性3个方面进行智能性评价,其中交通协调性用来刻画车辆交互时的社会合作能力。
交通协调性作为自动驾驶汽车智能性的一个维度,其评价方法与其他智能性表现的评价方法类似。在自动驾驶汽车智能性评价方法研究方面,国内外已开展的研究多以主观评价为主。王越超等[4]利用专家的经验知识和判断构建了智能性评价的蜘蛛网模型;Zhang等[5]提出了结合专家主观权重评判和指标评分的基于层次分析法的综合评价法;蒙昊蓝等[6]采用模糊综合评价法,结合定性指标的专家主观评分和定量指标实际测量值,实现对自主泊车系统的量化评价;Gao等[7]采用模糊综合评价法构建了智能汽车行驶智能性评价模型。然而,主观评价方法存在无法支持自动化评价、评价效率低,且对新样本进行重新评价时,由于评判标准无法保证统一而导致评价结果不稳定的问题。因此,有必要建立一种通过客观表征指标数据来描述主观评价结果的主客观映射模型,从而实现自动化评价且保证模型输出评价结果的稳定。
主客观映射模型的构建方法主要有神经网络、支持向量机、回归模型等。由于神经网络的非线性映射能力、对噪声数据的鲁棒性和容错性强等特点[8],研究人员针对基于神经网络的主客观映射模型做了较为广泛的研究。Du等[9]基于BP神经网络构建了自主泊车系统性能主观评价的客观表征模型;孙慧慧[10]基于GA-BP神经网络构建了汽车声品质主客观评价模型;Liu等[11]基于PSO-BP神经网络构建了汽车操纵舒适性主客观评价模型;Su等[12]基于BP神经网络、径向基函数神经网络等构建了视觉舒适性主客观映射模型,并分析了不同神经网络模型的评价效果差异;张昊等[13]针对基于BP神经网络的GPS高程拟合模型,分析了不同数据预处理方法对映射模型精度造成的影响。由此可见,不同的神经网络类型和不同的样本数据预处理方法均会对模型精度造成影响。
综上,选取高速公路匝道汇入场景,开展车辆交通协调性评价模型研究。首先,基于自然驾驶数据的交互样本数据,采用不同样本数据预处理方法和神经网络类型构建不同的映射评价模型;然后通过对模型的训练及测试结果进行交叉对比,分析样本数据预处理方法和神经网络类型对车辆交通协调性映射评价模型评价效果的影响。
1 样本数据预处理方法
为保证模型构建的质量,一般需要对原始客观指标数据进行预处理以消除数据间数量级差异,使其具有可比性。采用了2种不同的数据处理方法对客观指标数据进行预处理,分别是线性函数归一化处理和阶梯函数归一化处理。
(1)线性函数归一化处理。线性函数归一化处理是将原始客观数据通过线性化的方法转换到0~1的范围,其中最大值变为1,最小值变为0,计算式如式(1)所示:?
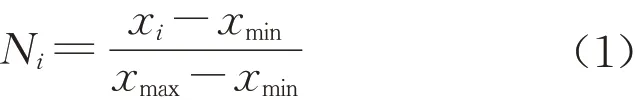
式中,Ni为第i个客观指标数据归一化处理结果,xi为第i个客观指标数据;xmax、xmin分别是客观数据的理论最大值和理论最小值。
(2)阶梯函数归一化处理。阶梯函数归一化处理是先对原始客观数据进行分级处理,即将同质区域作为一个等级,来消除数据间的数量级差异和减小样本数据分散度。计算式如式(2)所示。进而再利用式(1)对分级后的数据进行归一化处理。
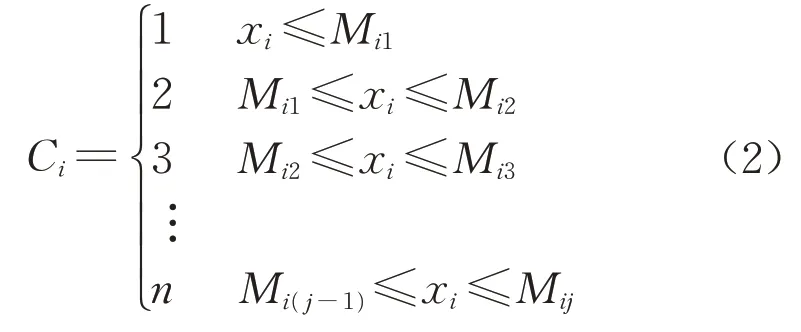
式中,Ci为第i个客观指标数据等级;n为客观指标的分级数量;Mij(j=1,2,3,…,n)为第i个客观指标数据的第j个等级的划分临界值。
2 基于神经网络的映射模型
人工神经网络是由大量处理单元互联组成的非线性、自适用信息处理系统。它可以模拟人体大脑神经系统的功能,从已知数据中自动地归纳规则进而获得数据的内在规律。神经网络具有很强的非线性映射能力,能很好地应用于分类和回归等问题。因此,为了分析基于不同神经网络类型的映射评价模型的表现差异,选用标准BP神经网络和Dropout神经网络构建主客观映射评价模型。
2.1 模型输入输出
为了得到模型输入,根据自动驾驶汽车交通协调性内涵,从自车和对手车的评判角度分别提出自车行为合理性和对手车受影响程度2项评价准则。对于本文匝道汇入而言,其中自车为匝道汇入车辆,对手车为背景车辆中与自车发生最直接交互的车辆,如图1所示。

图1 匝道汇入区车辆运行示意Fig.1 Schematic diagram of vehicle driving
在自车行为合理性方面,自动驾驶汽车智能性评价相关研究中通常考察车辆决策合理度、行为控制合理度和路径合理度[14]。对于本文匝道汇入场景而言,在车辆决策合理度方面,以自车是否违反交规、自车追及时间、自车并行时间、自车车头最小间距、自车车尾最小间距、自车左侧最小间距和自车右侧最小间距作为表征指标。其中是否违反交规用数字0和1表示;自车追及时间是指汇入前自车与主路前方对手车的纵向间距与速度差的比值,正值表示自车速度大于对手车,负值表示自车速度小于对手车;自车并行时间是指汇入前自车与对手车并行行驶的时间。在车辆行为控制方面,以自车匝道行驶平均速度、自车行车道行驶平均速度、并线时刻的自车侧向速度和自车车头碰撞时间(time to collision,TTC)作为表征指标。在汇入路径合理度方面,以自车汇入位置作为表征指标,其中汇入位置指自车汇入点到加速车道起始端的距离与加速车道总长的比值。
在对手车受影响程度方面,过高的相对速度和过近的车间距等相对运动状态会直接对对手车的通行造成阻碍[15],也会对车内人员心理上的舒适度产生负面影响[16]。在对手车行为上受影响程度方面,以对手车减速程度和对手车位置偏移作为表征指标。其中对手车减速程度指自车并线过程中对手车初始速度和最小车速的差值与最大速度的比值;对手车位置偏移是指对手车保持原方向、让道或变道3种行为,分别以0、1和2表示。在对手车心理上的受影响程度方面,以对手车车头TTC、自车与对手车侧向相对速度作为表征指标。
基于此,建立了如表1所示的客观表征指标集,并基于车辆基本行驶状态数据计算得到各指标数值,进而作为模型输入。
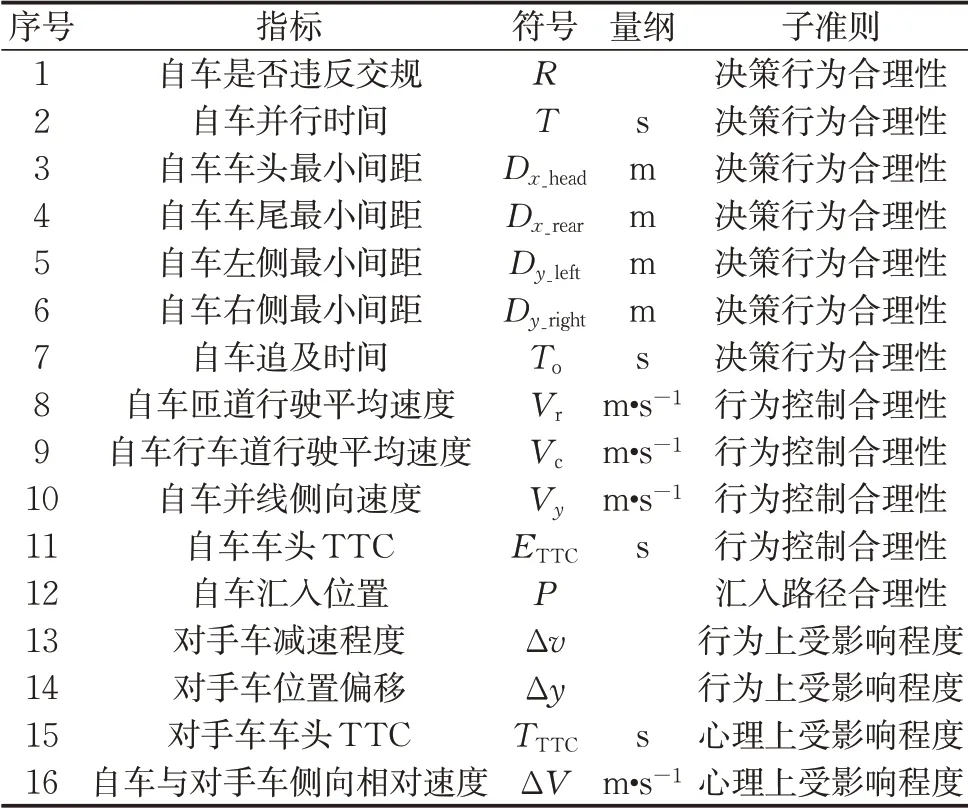
表1 客观表征指标集Tab.1 Objective index set
为得到模型输出,多个专家组成的评价组通过自车乘员视角、对手车驾驶员视角以及全局俯视视角观察交互情况;然后基于自车行为合理性和对手车受自车行驶行为影响的程度2个准则,从差、较差、中等、较好、好共5个等级对车辆交通协调性表现进行主观评级,分别用数字1~5表示,用符号S表示;最后计算所有专家的主观评分的平均值作为模型输出。
2.2 神经网络模型
(1)BP神经网络模型。BP神经网络由于其良好的非线性逼近能力而得到了广泛的应用。基于BP神经网络构建了如图2所示的映射评价模型,可通过客观指标实测数据自动输出车辆交通协调性表现得分。
理论分析[17]证明,具有单隐含层的网络可以映射所有的连续函数。而增加隐含层虽然可以一定程度上降低网络误差、提高精度,但会使网络复杂化,且易出现过拟合现象,所以一般优先考虑3层BP神经网络(即1个隐含层)。
隐含层神经元个数的选择对网络模型的训练也是非常重要的,与研究问题、输入输出的指标数都有关系[8],大致范围可由式(3)得到:
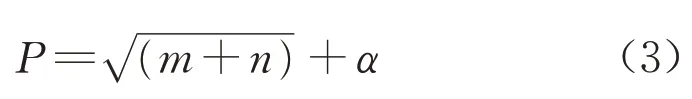
式中,P为隐含层神经元个数;m为输入层神经元个数;n为输出层神经元个数;α为0~10之间的整数。
根据式(3),隐含层神经元个数取为P(P=1,2,…,15)分别进行模型训练和测试,其中模型精度最高的一组的隐含层神经元个数为8。故BP神经网络隐含层神经元个数取8。
(2)Dropout神经网络模型。Dropout在深度学习中是一种能够改善训练复杂神经网络产生的过拟合现象的手段,具有很好的容错能力[18]。基于Dropout的神经网络在训练阶段的每轮前向传播过程中,让某个神经元的激活值以一定的概率停止工作,从而使模型泛化能力更强。因此,采用Dropout神经网络建立车辆交通协调性的映射评价模型,模型拓扑结构如图3所示。
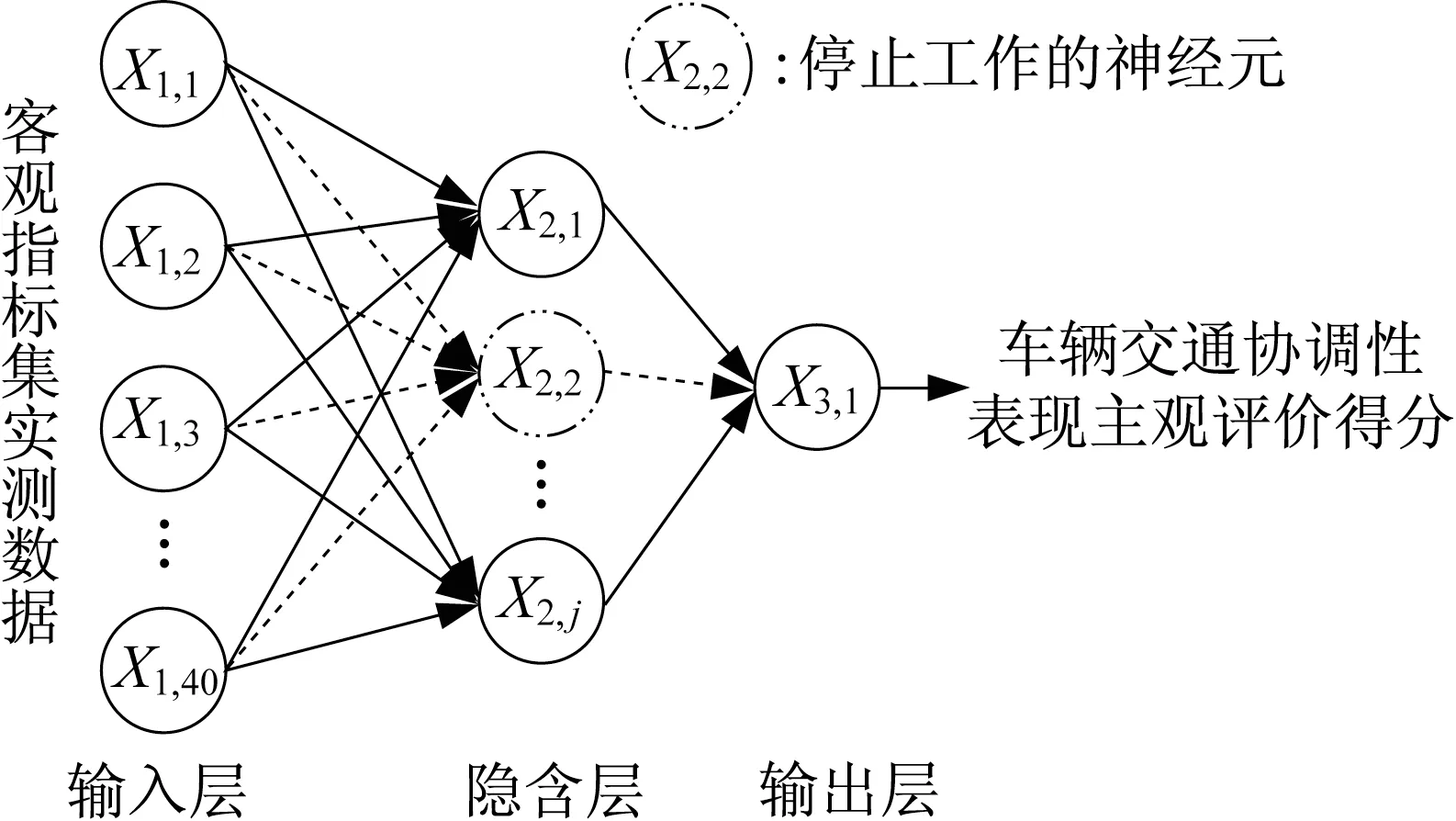
图3 Dropout神经网络拓扑结构Fig.3 Topology of Dropout neural network
神经网络每层的激活函数不尽相同,基于相关文献的研究基础[19],本文Dropout神经网络模型的隐含层激活函数选用tanh_opt函数,输出层激活函数选用sigm函数。
3 映射模型构建方案对比分析
3.1 模型训练及测试样本
交互样本数据来自于上海市G50沪渝高速某匝道汇入路段的自然驾驶数据。为了获得用于计算客观指标的车辆基本行驶状态数据和用于主观评价的不同视角视频数据,将交互样本数据复现到虚拟仿真环境中运行。真实交通流场景和虚拟仿真复现场景如图4a和4b所示。

图4 高速公路匝道汇入场景Fig.4 Scenario of ramp
基于虚拟仿真复现结果,可得到每个样本的车辆行驶状态数据,并经过数据后处理获得客观表征指标集的实测数据。同时,评价专家通过仿真复现场景中自车乘员视角、对手车驾驶员视角以及全局俯视视角观察交互情况,对每个交互样本中车辆交通协调性表现进行主观评级,从而获得主观评分结果。交互样本数据包含基于汇入过程中交互对象的行为和汇入表现两大原则选取的自车合理避让、自车伺机汇入、自车抢先汇入、自车强迫汇入、自车犹豫不决以及自车正常汇入等45组典型的匝道汇入处交互情况,其中40组作为模型训练样本,5组作为模型测试样本。样本数据描述性统计结果如表2所示。
3.2 模型构建方案对比实验设计
为了分析不同样本数据预处理方法及不同神经网络类型对映射模型评价效果的影响,设计了2×2模型构建方案交叉对比实验,如表3所示。利用线性函数归一化和阶梯函数归一化方法对客观指标数据进行预处理,基于BP神经网络和Dropout神经网络构建映射评价模型。
3.3 模型评价结果及对比分析
为了分析模型评价结果以及样本数据预处理方法和不同神经网络类型对映射评价模型评价效果的影响,对方案1、方案2、方案3和方案4的映射评价模型在训练和测试样本上的拟合效果、模型评价精度进行交叉对比分析。一方面,利用各映射评价模型输出值与主观评价结果之间的残差来对模型在训练样本上的拟合结果进行统计。另一方面,基于映射评价模型输出结果与主观评价结果的相对误差计算模型在各测试样本下的评价精度,且将各测试样本评价精度的平均值作为模型总精度并进行对比,计算式如式(4)所示:
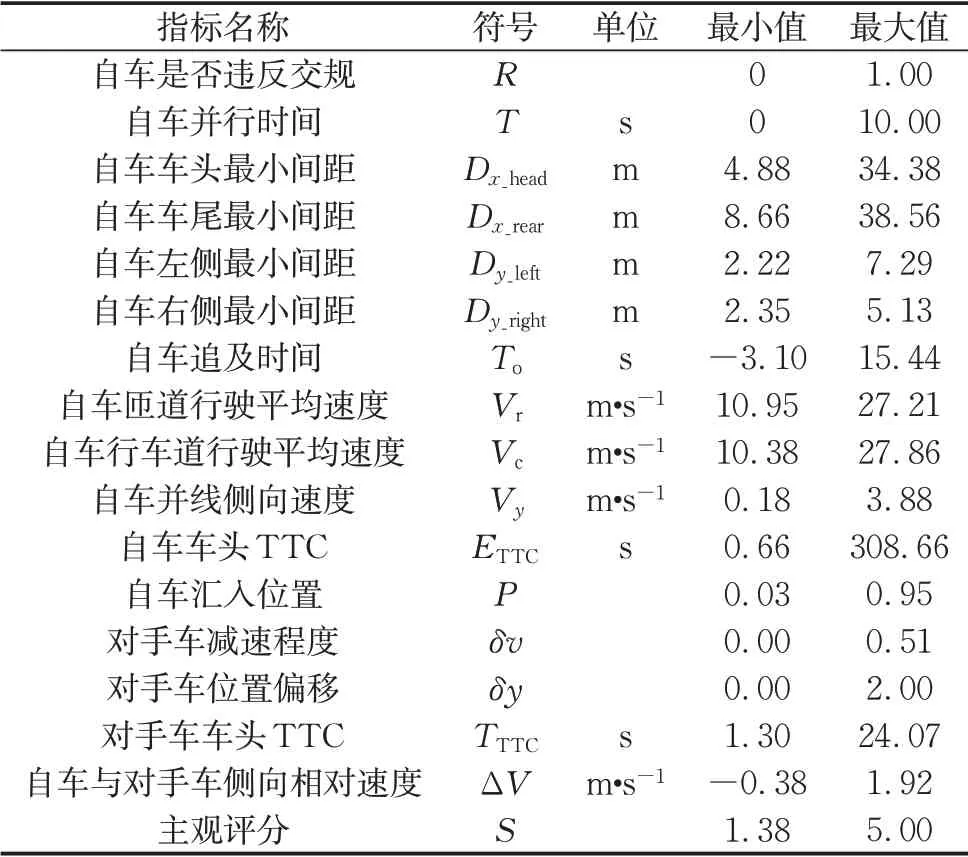
表2 样本数据描述性统计结果Tab.2 Descriptive statistics of sample data

表3 模型构建方案Tab.3 Plan for model construction
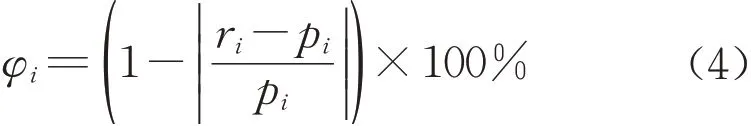
其中,φi为模型在第i个测试样本下的评价精度,ri为第i个测试样本的模型输出值,pi为第i个测试样本的主观评价结果。不同映射评价模型构建方案的训练和测试结果如表4所示。
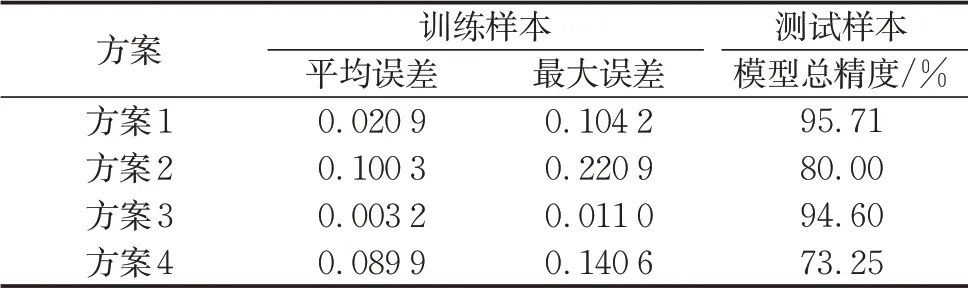
表4 各模型构建方案的训练与测试结果Tab.4 Training and test results of each model
根据表4的训练和测试统计结果可知,模型评价效果均较好,模型精度最高为95.71%。结果表明:基于神经网络的评价模型能够较好地实现客观指标数据到主观评价结果的映射,本文所建立的包括自车平均行驶速度、并线时刻侧向速度、并线时刻车头TTC、并线时刻两车侧向相对速度和对手车减速程度等指标的客观表征指标集能够较好地表达专家对车辆交通协调性表现的评价。进一步,为了分析神经网络类型和样本数据预处理方法对映射模型评价效果的影响,将结合表4统计结果分别对不同模型构建方案的训练及测试结果进行对比分析。
3.3.1 神经网络类型对映射模型评价效果的影响
结合表4的数据统计结果,分别对方案1和方案2、方案3和方案4在训练样本的拟合效果和测试样本上的模型评价精度进行对比分析。结果表明:在训练样本上的拟合效果方面,相较于Dropout神经网络模型,基于同一种样本数据预处理方式的BP神经网络映射模型的拟合效果更佳;在测试样本上的模型评价精度方面,对于线性函数归一化方法和阶梯函数归一化方法,Dropout神经网络模型总精度分别80.00%和73.25%,BP神经网络模型总精度分别为95.71%和94.60%,相比于Dropout神经网络,分别提高了15.7%和21.4%。可见,BP神经网络模型的评价精度更高。
由于Dropout神经网络的每批次训练仅仅使用其中一部分神经元,相当于使用了相同的数据训练了多个模型,通过多个模型集成达到防止过拟合的目的[20],所以Dropout神经网络模型的训练拟合效果通常劣于BP神经网络模型。在测试样本上的评价精度方面,一方面,Dropout神经网络改善过拟合现象的特性同样需要几千个训练样本才能有效果[20]。而对于本文匝道汇入场景的车辆交通协调性映射评价模型构建而言,基于自然驾驶数据的典型交互样本满足了交互形式覆盖率要求,同时减少了样本主观评价过程的工作量;但无法满足Dropout神经网络的大样本要求,从而限制了模型的评价效果。另一方面,Dropout神经网络在训练样本上的拟合效果不佳,将导致网络模型未能捕捉到某些数据特征,从而影响模型在某些样本上的评价精度。
因此,在小样本数据量下,基于BP神经网络的映射评价模型的表现更优,能够根据描述交互行为的客观指标数据更准确地得到符合专家评判标准的车辆交通协调性评价结果。
3.3.2 样本数据预处理方法对映射模型评价效果的影响
结合表4的数据统计结果,对方案1和方案3、方案2和方案4的训练和测试结果进行对比分析。结果表明:在训练样本的拟合效果方面,对于基于同一种神经网络类型的映射模型而言,基于线性函数归一化处理方法的映射模型的拟合效果比基于阶梯函数归一化处理方法的映射模型的拟合效果略差。在测试样本上的评价精度方面,对于BP神经网络和Dropout神经网络,基于阶梯函数归一化处理方法的映射模型总精度分别为94.60%和73.25%;基于线性函数归一化处理方法的映射模型总精度分别为95.71%和80.00%,相比于基于阶梯函数预处理方法的映射模型分别提高了1.1%和6.8%。可见,线性函数归一化处理方法能够提高神经网络映射评价模型的评价精度。
模型训练的输入变量的选择通常考虑变量是否发散、变量与目标的相关程度两方面,其中变量是否发散体现了样本在此变量上是否具有差异,会影响模型的精度[21]。本文的阶梯函数归一化处理需要先对客观指标数据进行分级处理,数据分级虽然通过将同质区域作为一个等级的方式消除了客观指标中某些区域内数据过于分散的问题[22];但数据分级同时也弱化了客观指标数据间的差异,进而造成数据中部分特征信息的损失,不利于模型的训练。对于车辆交通协调性而言,客观指标数据的差异反映了不同交互样本在自车行为控制合理性、自车汇入路径合理性、自车决策合理性或对手车受影响程度等方面的表现差异。而数据分级所带来的数据间差异弱化将会导致客观表征指标数据过分集中、差异性小、无法体现数据内在规律,从而影响车辆交通协调性映射评价模型在测试样本上的评价精度。因此,采用线性函数归一化方法对客观表征指标实测数据进行预处理能提高映射评价模型的评价精度。
4 结语
以高速匝道汇入场景下的车辆交通协调性评价为例,基于2种样本数据预处理方法、2种神经网络类型构建了不同的映射评价模型,并通过交叉对比实验分析了数据预处理方法及神经网络类型对车辆交通协调性映射评价模型效果的影响。总结如下:
(1)在模型评价效果方面,模型精度最高为95.71%。评价模型能够较好地实现客观数据到主观评价结果的映射,所建立的包括自车平均行驶速度、并线时刻侧向速度、并线时刻车头TTC、并线时刻两车侧向相对速度和对手车减速程度等指标的客观表征指标集能够较好地表达专家对车辆交通协调性表现的评价。
(2)在建模方法方面,对于线性函数归一化和阶梯函数归一化,BP神经网络映射模型评价精度分别为95.71%和94.60%,Dropout神经网络映射模型评价精度分别为80.00%和73.25%。基于BP神经网络的评价模型能够根据客观指标数据更准确地得到符合专家评判标准的车辆交通协调性评价结果。
(3)在样本数据预处理方法方面,对于BP神经网络模型和Dropout神经网络模型,基于线性函数归一化的映射模型评价精度分别为95.71%和80.00%,基于阶梯函数归一化的映射模型评价精度分别为94.60%和73.25%。线性函数归一化处理方法能够在消除数据间数量级差异的同时保留客观表征指标数据在不同样本之间的差异,提高了映射评价模型的评价精度。
综上,在小样本数据量下,基于线性函数归一化预处理方法和BP神经网络的主客观映射评价模型构建方案的评价效果更优。
在后续研究中,一方面将在现有的映射模型构建方案的基础上,研究针对车辆交通协调性问题的最优客观表征指标集合,以构建最优的映射评价模型;另一方面将基于更多场景的样本数据对基于神经网络的主客观映射评价模型的外推性进行研究。
作者贡献申明:
陈君毅:研究命题的提出及设计,论文修订。
陈 磊:模型构建分析,论文撰写。
蒙昊蓝:样本数据收集,论文修订。
熊 璐:负责最终版本的修订。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
四川环境(2019年6期)2019-03-04 09:48:54
电子制作(2018年11期)2018-08-04 03:25:38
信息安全与通信保密(2016年3期)2016-08-23 01:23:52
测绘科学与工程(2016年5期)2016-04-17 06:51:15
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
电子设计工程(2015年3期)2015-02-27 12:03:45
中国中医药现代远程教育(2014年15期)2014-03-01 04:28:18
