
基于FMS算法的多元LDPC码的译码器设计
2021-02-26 03:26卢泳兵袁瑞敏
无线电通信技术 2021年1期
卢泳兵,袁瑞敏,朱 敏
(1.中国电子科技集团公司第五十四研究所,河北 石家庄 050081;2.西安电子科技大学ISN国家重点实验室,陕西 西安 710075)
0 引言
多元LDPC码定义在有限域GF(q=2r)上。相比于二元LDPC码,多元LDPC码在中短码长上具有更高的编码增益和更强的抗突发错误能力,并且非常适宜与高阶调制方案结合。因此,多元LDPC码可应用于空间通信等功率受限系统以及高阶调制、MIMO等高吞吐量传输系统。北斗三号卫星导航系统就采用了定义在GF(64)上的LDPC码[1-2]。多元LDPC码的经典译码算法是多元和积算法(QSPA)[3]。QSPA算法具有近似最优的译码性能,它的译码复杂度为O(ρq2),其中ρ为校验节点的度。但是,过高的译码复杂度阻碍了多元LDPC码在实际系统中的应用。如何在纠错性能损失可忽略的前提下降低译码复杂度成为一个研究难点。
QSPA的复杂度主要由校验节点的更新过程决定。简化译码算法根据校验节点的更新方式大致可以分为两类。第一类译码算法采用了前向后向更新策略,如扩展最小和算法[4]。EMS算法在因子图上传递消息时只保留前nm(nm≪q)个最可靠的消息,其译码复杂度为O(ρnmlog2nm)。文献[5-8]针对EMS算法给出了简化策略。对于EMS算法,前向后向策略由于其串行本质而使译码器的吞吐量受限,同时存储中间结果又需要占用存储空间。因此在ρ较大时,EMS算法的表现不是很好。第二类译码算法基于网格图进行译码,如基于网格图的EMS(Trellis Based EMS,T-EMS)[9]算法。T-EMS算法在网格图上选取部分节点用于构造可靠路径,能够并行更新消息。T-EMS算法在高吞吐量方面具有潜力,同时由于只需要存储部分节点,降低了存储需求。文献[10]对T-EMS算法进行改进,提出了FMS算法。FMS算法不仅保留了T-EMS高并行度的优势,而且具有很低的计算复杂度以及良好的纠错性能。文献[11]针对多元LDPC码提出了分层译码算法。在分层译码算法中,校验节点被划分成几层。层与层之间的校验节点串行更新,层内的校验节点采用简化算法并行更新。分层译码的好处是能够加快收敛速度。
本文将FMS译码算法和分层译码算法结合来设计多元LDPC译码器。译码器使用的是北斗三号卫星导航系统的GF(64)LDPC(88,44)码。
1 多元LDPC码的译码
1.1 基本概念
多元LDPC码由定义在GF(q)上的M×N的奇偶校验矩阵H的零空间给出。H每一行的非零元个数称为行重,用ρ表示。H每一列的非零元个数称为列重,用v表示。对于规则LDPC码,ρ和v都是常数。用c=[c0,c1,c2,…,cN-1]表示多元LDPC码的一个码字。码字经过BPSK调制在AWGN信道上传输,在接收端得到y=[y0,y1,y2,…,yN-1],其中yj是一个r元向量,j=0,1,2,…,N-1。用al,l=0,1,2,…,q-1表示GF(q)上的一个元素。假设码字等概发送,对于码字的第j个符号,可以得到对数似然比(Log-Likelihood-Ratio,LLR)形式的消息向量Lj。式(1)给出了每个消息的计算方式。
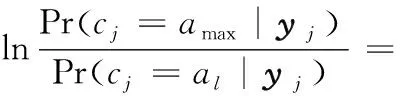
(1)
式中,amax为cj最可能的有限域元素。这种度量方式确保了消息的度量值是非负数,而且值越小,消息越可靠。
1.2 FMS译码算法
FMS算法和EMS算法具有相似性,它们只传递前nm个最可靠的消息。消息向量中的元素按照可靠度由高到低的顺序排列。消息采用了分布存储,一方面存储消息的可靠度,另一方面存储相应的有限域元素。在多元LDPC码的因子图中,变量节点和校验节点之间有置换节点。置换节点将变量节点消息的有限域元素和H中相应的非零元相乘(置换过程),将校验节点消息的有限域元素和H中相应的非零元相除(逆置换过程)。对某个度为ρ的校验节点,用Rl,c和Yc,l(0≤l<ρ)分别表示置换后的输入可靠度向量和逆置换前的输出可靠度向量,相应的有限域元素向量记为Rsl,c和Ysc,l。将Rl,c(0≤l<ρ)按照向量中第2个LLR值由小到大的顺序重新排列。假设排列后的结果为:
R0,c[1]≤R1,c[1]≤R2,c[1],…,Rρ-1,c[1]。
(2)

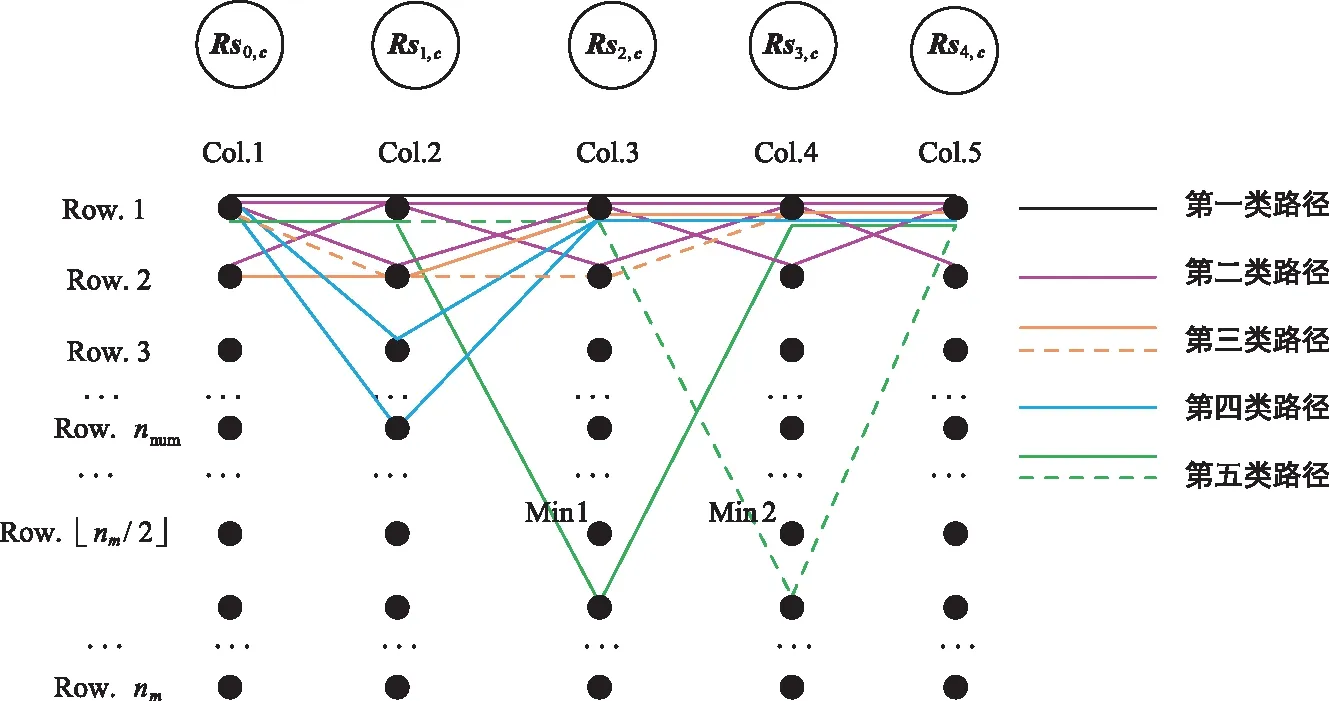
图1 度为5的校验节点的网格图Fig.1 Trellis for a check node of degree 5
① 第一类只有1条路径,为最可靠路径,记作Ⅰ类路径。
② 第二类有ρ条路径,每条路径仅有1个偏移节点,来自网格图的第2行,记作Ⅱ类路径。
③ 第三类有2ρ-3条路径,这类路径分为两个小类:第一小类包含ρ-1条路径,每条路径的第1个偏移节点是网格图的第2行第1列节点,第2个偏移节点来自网格图第2行的其余列,记作Ⅲ类路径;第二小类包含ρ-2条路径,每条路径的第1个偏移节点是网格图的第2行第2列节点,第2个偏移节点来自网格图第2行的第3到第ρ列,记作Ⅳ类路径。
④ 第四类有ρ(nnum-2)条路径,每条路径仅有1个偏移节点,偏移节点来自网格图第3行到第nnum行的节点,记作V类路径。
⑤ 第五类有2(nm-nnum)条路径,每条路径仅有一个偏移节点,这类路径分为2个小类:第一小类的偏移节点来自Si1,记作VI类路径;第二小类的偏移节点来自Si2,记作VII类路径。
定义ΔRs和ΔR,分别存储路径校验值和可靠度。可根据文献[10]中的式(16)和式(17)对ΔRs和ΔR进行更新,输出向量Yc,l和Ysc,l(0≤l<ρ)可根据文献[10]中的式(18)和式(19)对进行更新。
1.3 分层译码算法
在传统的泛洪式调度策略中,所有的校验节点更新结束后才进行变量节点的更新。实际上,考虑到硬件资源消耗的问题,LDPC译码器一般不会设计成全并行结构。为了能够在部分并行结构下加快译码器的收敛速度,有学者提出了分层译码的调度策略[11-12]。分层策略对CPM-QC-LDPC(Circulant-Permutation-Matrix Quasi-Cyclic LDPC)码最为合适。一个CPM内的校验节点为一层,层内的校验节点并行更新。但本文使用的多元LDPC码非零元呈现随机分布,因此以单个校验节点为一层。下面介绍下分层译码算法。

② 检验节点和变量节点更新:
第一步:对于第m层的校验节点i,根据式(3)更新变量节点消息(或者叫先验信息),其中j∈Ni。
(3)

第三步:根据式(4)计算变量节点j∈Ni的后验消息。
(4)
③ 判决得到码字。如果码字满足校验方程,则停止迭代,输出码字,否则m=m+1。
④ 如果m>T,则l=l+1,m=1。如果l>Imax,则宣告译码失败,终止迭代;否则转至步骤②。
分层译码的算法框图如图2所示。从图中可以看出,校验节点在上一次迭代中产生的消息需要存起来,直到在下一次迭代对本层进行更新时才会用到。每个校验节点都需要一个RAM来存储在本层产生的校验节点消息。
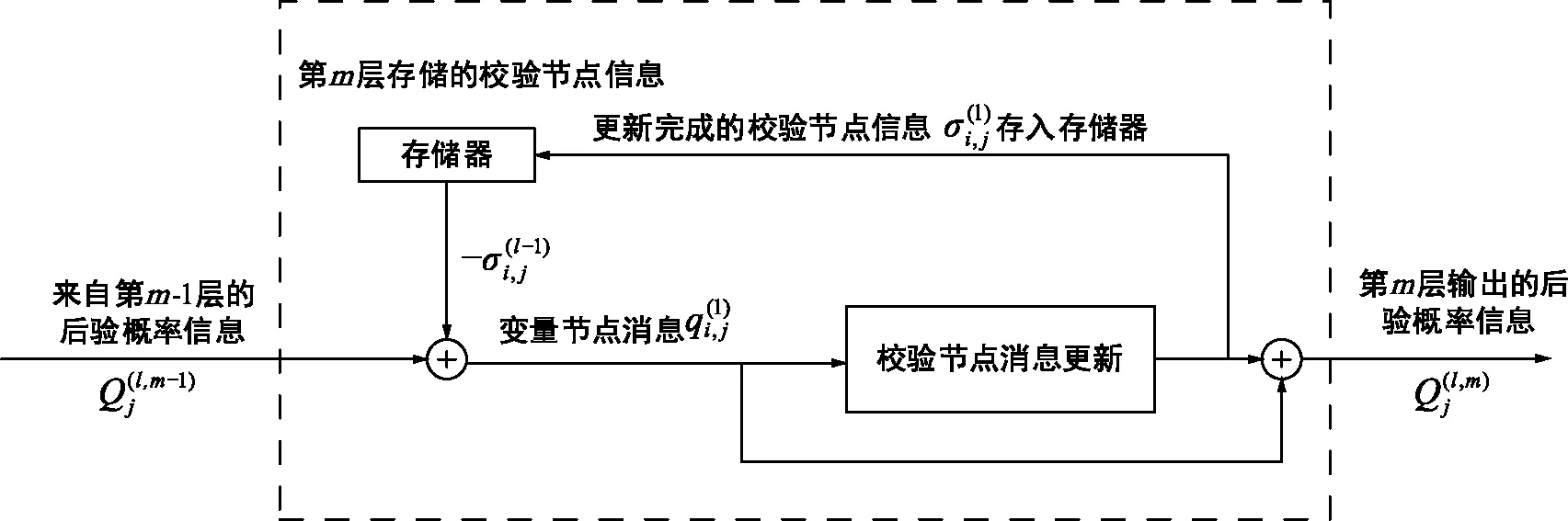
图2 分层译码的算法框图Fig.2 Block diagram of layer decoding algorithm
1.4 性能比较与复杂度分析
图3针对LDPC(88,44)码给出了译码算法的性能。图例中“EMS”和“FMS”的下标表示nm,“FMS”的上标表示nnum。如图3所示,当nm=16时,EMS算法相比于QSPA算法约有0.1 dB的性能损失;当nm=16,nnum=3时,FMS算法相比于QSPA算法约有0.35 dB的性能损失;当nm=16,nnum=6时,FMS算法相比于QSPA算法约有0.3 dB的性能损失。对于FMS算法,分层策略下最大15次迭代的性能和泛洪策略下最大50次迭代的性能几乎相同。
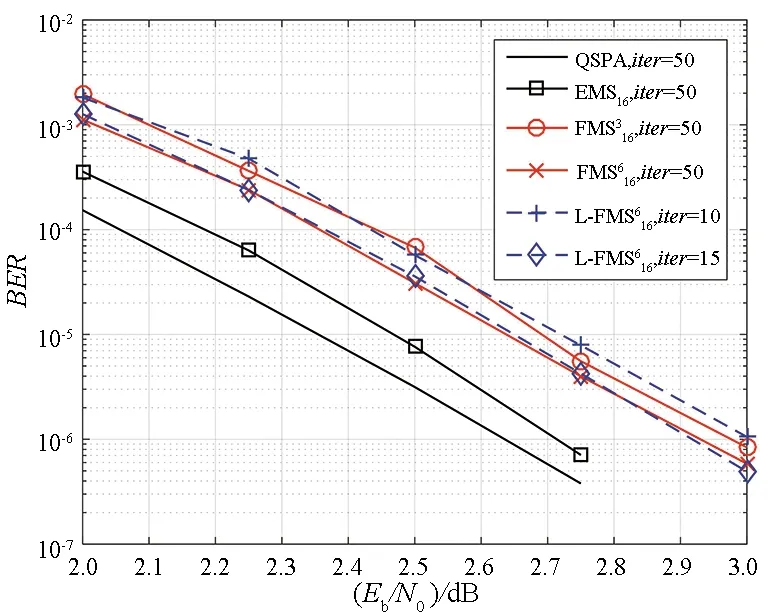
图3 GF(64) LDPC (88,44)码采用多种译码算法的BER性能Fig.3 BER performance of a (88,44) LDPC code over GF(64) using various decoding algorithms
译码算法的复杂度主要体现在实数加法(Real Addition,RA)、实数比较(Real Comparison,RC)以及有限域加法(Galois field Addition,GA)上。由于对于FPGA实现来说,实数加法和实数比较的复杂度相当,所以本文将这两个复杂度结合在一起分析。图4比较了EMS和FMS两种译码算法在泛洪策略和分层策略下的复杂度,仿真参数为nm=16,nnum=6,泛洪策略的最大迭代次数为50,分层策略的最大迭代次数为15。可以看出,FMS算法的复杂度明显低于EMS算法,并且对于同样的校验节点更新算法,使用分层策略相比于使用泛洪策略,计算量降低约一半。

图4 EMS算法和FMS算法的复杂度比较Fig.4 Comparison of complexity between the EMS algorithm and the FMS algorithm
相较于EMS算法,FMS算法虽然在BER性能方面略有不及,但是在复杂度方面的增益却非常高。为保证良好的性能同时又要有很低的复杂度,本文采用FMS算法结合分层策略设计译码器,FMS算法参数为:nm=16,nnum=6。
2 多元LDPC译码器的结构
2.1 FMS算法的量化
译码算法的量化性能是译码器所能实现的性能。量化的动态范围会影响译码器性能的好坏和资源占用的高低。图5给出了分层结构的FMS算法的量化性能。量化方案用(bi,bf)表示,其中bi表示整数部分的量化比特数,bf表示小数部分的量化比特数。为了兼顾性能和复杂度,本文对LLR进行5 bit量化,其中整数部分用4 bit表示,小数部分用1 bit表示。
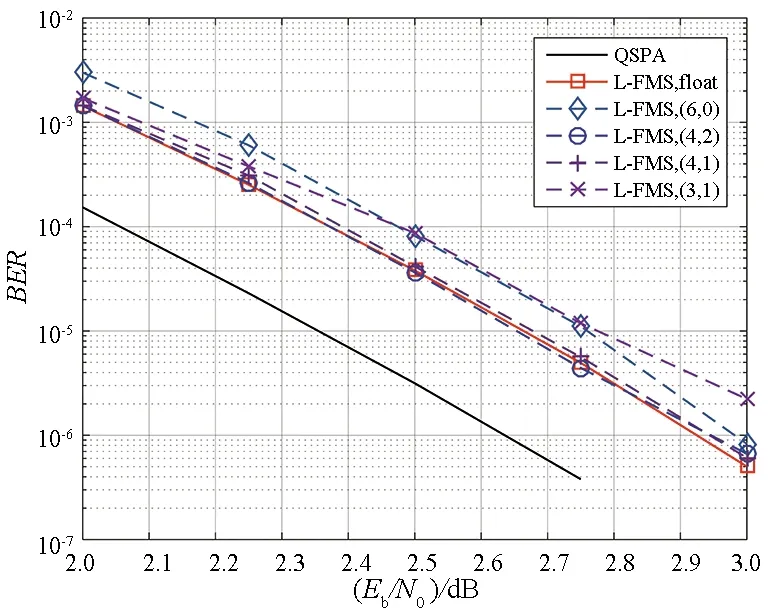
图5 GF(64) LDPC (88,44)码在分层FMS算法下采用不同量化方案的BER性能Fig.5 BER of a (88,44) LDPC code over GF(64), using layered FMS algorithm with different fixed-point implementations
2.2 译码器总体结构
译码器主要由校验节点单元、变量节点单元及奇偶校验单元组成。本文使用的多元LDPC码,它的奇偶校验矩阵H的非零元呈现随机分布。因此分层结构以H的一行作为一层,仅使用一个校验节点单元。将H从中间分为左右两块,即H=[H1|H2]。对于任意一行的4个非零元素,前两个位于H1中,后两个位于H2中。因此译码器使用两个变量节点单元,每个变量节点单元串行处理两个变量节点。下面分别对这几个模块进行介绍。
2.3 校验节点单元

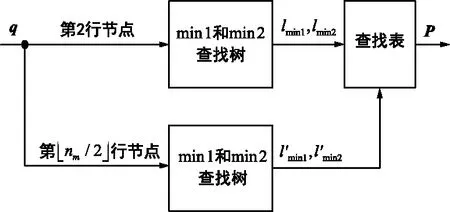
图6 映射器的结构Fig.6 Structure of the mapper
变量节点传来的消息需要经过一个交换网络来产生网格图。交换网络的本质就是一组数据选择器。为获得网格图的前两列和后两列,需要四选一的数据选择器。下面通过分析来说明,对于网格图第3~ρ列,可使用输入更少的数据选择器来降低硬件的复杂度。对于网格图第k列,k∈{3,…,ρ},如果满足P(k)
图7给出了路径构造器的结构。交换网络Π用于生成网格图,Π-1用于恢复校验节点消息的顺序,配置方法如前文所述。用αsum表示最可靠路径的校验和。对于某一条路径,记路径节点的列号为e(0),e(1), …,e(ρ-1),用z={z(k)}表示路径的零节点的有限域元素,用α={α(k)}表示偏移节点的有限域元素,用x={x(k)}表示偏移节点的LLR,0≤k<ρ,用Szero表示零节点的列号集合,用Snon-zero表示偏移节点的列号集合。那么任一条路径的可靠度L以及校验值α可以根据式(5)~式(7)计算。当ρ较大时,如果直接计算路径的可靠度会有ρ-1个域元素加法。而在FMS译码算法中,每条路径的偏移节点最多有两个,因而采用式(7)的计算方法,每条路径最多有4个域元素加法。
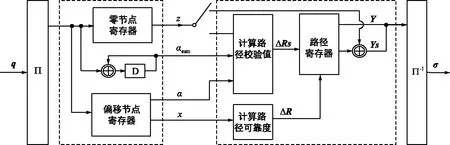
图7 路径构造器的结构Fig.7 Architecture of the path builder
(5)
(6)
(7)
2.4 变量节点单元
本文所用的LDPC码具有列重为2的特征。基于这一特点,本文使用了一种改进的分层策略,能够降低存储需求。对于列重为2的变量节点,接收到的消息可以分为三类,分别是两个校验节点的消息和信道的消息。对于当前校验节点,图2通过减操作得到的变量节点消息可以由信道消息和另一个校验节点消息相加得到。那么其中一个校验节点更新结束后,校验节点消息可以写到一个C2V(Check Nodes to Variable Nodes)存储单元中。当更新另一个校验节点时,通过访问这个C2V存储单元和信道消息存储单元来计算先验信息。在校验节点输出端,输出消息一方面将被写到C2V存储单元,另一方面和先验信息求和,计算后验信息。通过以上描述,连接到同一个变量节点的两个校验节点,可以共用同一个C2V存储单元。因此相比于图2给出的结构,针对列重为2的改进可以节省一半校验节点消息的存储。变量节点单元的基本操作是完成两个输入消息的求和,这个硬件结构可以参考文献[14]。
2.5 奇偶校验单元
在完成每层的更新后,变量节点单元会将本层变量节点的判决结果传递给奇偶校验单元。如果当前得到的判决结果能够满足所有的奇偶校验方程,译码过程就可以停止了。计算所有的校验方程需要M×ρ次有限域乘法和M×(ρ-1)次有限域加法,复杂度比较高。本文给出了一种低复杂度的实现方式,每完成一层的更新,能够得到ρ个变量节点的判决结果。对于每个变量节点,最多影响v个奇偶校验方程。因此,每完成一层更新,最多需要计算ρ×(v-1)+1个奇偶校验方程。本文使用的LDPC(88,44)码,ρ=4,v=2,每完成一层更新,需要计算5个校验方程。
3 多元LDPC译码器的FPGA实现
本文基于Xilinx ZYNQ-7 ZC706评估板(xc7z045ffg900芯片)对多元LDPC译码器进行实现。表1给出了多元LDPC译码器的实现结果。译码器需要7 904个查找表、3 967个寄存器和73.5个块存储单元。在100 MHz译码时钟下,吞吐量为0.06 Mbit/s。
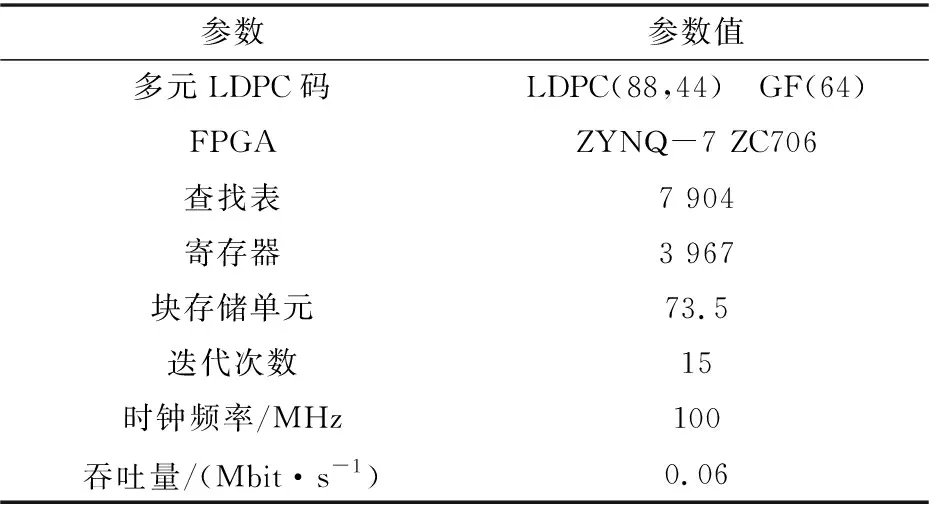
表1 译码器实现结果Tab.1 Implementation results of the decoder
4 结束语
本文设计了一种基于FMS译码算法的具有分层结构的多元LDPC译码器。译码器在吞吐量方面仍有很大提升空间,后续的工作就是对吞吐量进行优化。优化可以从以下两方面进行:一是采用流水线结构,将流水线每一级的处理时延设计成nm个时钟周期;二是充分利用空闲时间。这是因为分层译码器只有在前一层更新结束后才能更新下一层[15],这会导致流水线结构存在大量的空闲时间。针对这个问题,可以采用文献[16]的帧间流水结构,利用当前帧的空闲时间来处理其他帧。通过上述优化方式,译码器的吞吐量预期可达2.5 Mbit/s。除以上所述,另一个限制译码器吞吐量的因素是本文使用的多元LDPC码的并行度很低。如果采用具有准循环结构的LDPC码,译码器的吞吐量和CPM的大小成正比,但代价是资源占用也和CPM的大小成正比。
猜你喜欢
中学生学习报(2022年15期)2022-04-17
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
西北工业大学学报(2019年2期)2019-05-15
中国铸造装备与技术(2017年6期)2018-01-22
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
电子制作(2017年1期)2017-05-17
新闻传播(2016年3期)2016-07-12
遥测遥控(2015年2期)2015-04-23
