
面向金融云的超高吞吐新型金融DMZ网络
2021-02-25 07:48涂晓军蔡立志
计算机应用与软件 2021年2期
涂晓军 孙 权,2 蔡立志
1(中国银联股份有限公司 上海 201201)2(复旦大学 上海 200433)3(上海计算机软件技术开发中心上海市计算机软件评测重点实验室 上海 201112)
0 引 言
近年来,随着金融云建设的深入以及金融科技的发展,金融云的组网面临着转型与升级的可能。其中的驱动力主要由业务与技术的双重因素所决定[1-3]。
随着断直连监管措施的落地,银联接入了大量小额高频的交易,对信息系统的并发度提出了很高的要求。银联核心的互联网产品云闪付也发展迅猛,带来了巨大的互联网流量[4]。整个金融行业的整合正在加速,尤其在金融科技的技术栈越做越深之后,头部金融机构主导的行业化服务正在兴起,大型的金融行业云逐步形成,互联网流量将大量接入。DMZ网络区域是金融行业非常典型的一个网络区域,用于隔离不可信外网与可信内网之间的网络流量。如何构建架构简单、高吞吐量,以支撑海量的互联网入口流量是金融机构普遍关注的一个问题。
1 当前金融DMZ区实现方案
通常,金融数据中心的外网流量通过DMZ区进行接入。DMZ网络区域是金融行业非常典型的一个区域,它的主要作用是隔离、代理不可信外网与可信内网之间的网络流量。针对当前DMZ区的实现存在吞吐不足、成本高的问题,普遍的做法是采用昂贵的F5专用负载均衡设备,数十台交换机用于流量转发,上千台服务器做Web反向代理,如图1所示。该方案存在如下问题:

图1 基于F5的DMZ网络方案
1) 成本高昂:构建一个DMZ区需要用到大量的设备,包括昂贵的F5专用负载均衡设备、数十台交换机和上千台服务器。
2) 吞吐能力不足:即使采用了上述大量的设备,DMZ区的吞吐能力仍然较低,通常小于100 Gbit·s-1。这对于银行业大流量的互联网业务(例如云闪付、融e联等)来说,在开展商业促销活动时会遇到瓶颈,无法满足未来的需求。
3) 无法水平扩展:整个集群的最大吞吐能力受限于最前端的F5负载均衡设备,扩容量只能更换新型号设备,无法水平扩展。
2 网络设计
2.1 方案设计
本节针对现有DMZ区域成本高昂、吞吐性能无法水平扩展等问题,提出一种极简架构、超高吞吐的金融DMZ区实现方法,在大幅减小DMZ区部署设备数量与复杂度的同时能够极大地提升吞吐性能,如图2所示。
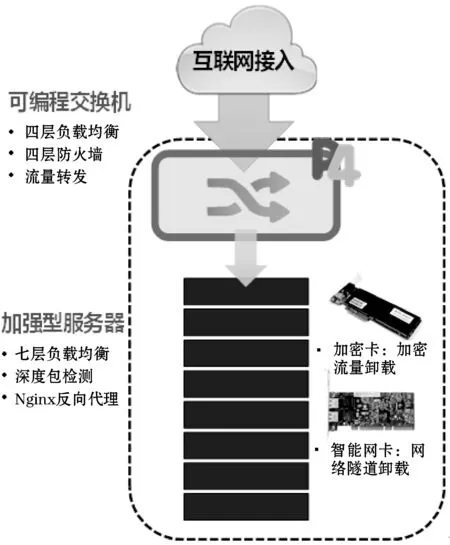
图2 新型DMZ网络架构图
整个DMZ区仅由一台可编程交换机和一个加强型服务器集群构成。可编程交换机侧主要负责入口流量的四层报文的处理,其中涉及的功能如下:
1) 四层的防火墙:依据黑白名单的地址以及内置检测DDoS的算法,对一部分非法流量进行预清理。
2) 四层的负载均衡:依据所访问的服务目的地址(通常是一个服务的IP),通过查找表项以及Hash算法将目的地址转换为实际的服务实例。
3) 流量转发:将流量导入至服务器进行更高层的报文处理。
在加强型服务器集群中,为了使服务器端七层的报文处理达到更高的性能,需要配置加解密卡和25 Gbit智能网卡,以便于将部分的工作从CPU卸载至专用硬件上。加解密卡用于卸载HTTPS加解密的流量处理,例如Intel QAT卡;25 Gbit智能网卡用于实现25 Gbit·s-1的高吞吐,同时其还具备Vxlan、UDP分片、TCP校验等硬件处理功能,从而可以最大限度地降低CPU的处理负担,并且使得报文的处理延时能够有确定性的保障。软件层面采用Nginx服务器做七层的负载均衡、http反向代理、深度包检测过滤等工作。
2.2 工作流程
本文方法流程如图3所示,Internet流量进入后,包括3个步骤:

图3 新型DMZ网络流向示意图
1) 交换机先处理四层的流量,包括四层DDoS防护、四层负载均衡。
2) 服务器集群负责七层报文解析,包括DPI深度包检测、HTTPS加密流量卸载、HTTP反向代理。
3) 将清洗过后的流量引到核心App区。
2.3 DMZ网关技术原理
本文方案在网关处采用了P4 SDN可编程交换的技术以及可编程交换芯片实现超高的吞吐量级[5-7]。P4的可编程模型是相对于传统固定流水线的交换芯片而言的,它的架构是基于PISA(Protocol Independent Switch Arch)全流水线可编程的架构。可编程交换芯片示意图如图4所示。

图4 可编程交换芯片示意图
该架构的基本单元是match-action table,其中match单元可以匹配任意报文的偏移与字段长度;action单元则有相对比较丰富的报文编辑功能;此外,片上的存储资源SRAM与TCAM也可以进行全局灵活的配置。
整个P4的控制过程包括包头解析、可编程入流水线、可配置缓存管理TM,以及可编程出流水线的处理。对应的编程框架包括:自定义报文头,match-action表项的定义、全流水线控制流的串接。可以看出,P4模型的核心特征仍然是基于网络包处理的高速交换,它可以实现Packet通信相关事件的处理,灵活匹配,灵活编辑,以及小容量的高速存储查找。
2015年Facebook利用Tofino商用芯片的P4可编程技术实现了能够存储1 000万条表项的有状态四层负载均衡,单交换芯片的能力相当于一百台服务器的软负载均衡性能。本文方案也是借助于P4的可编程模型,实现有状态的四层负载均衡,其流水线如图5所示。

图5 负载均衡流水线示意图
负载均衡方案的实现难点是PCC(Per Connection Consistency)有状态连接保持,需要控制面参与配合,并且在流表中记录下每个新建连接的状态。此外,为了实现负载均衡的地址池,以及来回报文的原路处理,在去程还需要实现DNAT,回程需要实现SNAT,并且定期需要广播或者响应虚地址的ARP请求。
3 关键技术目标设计实现
3.1 吞吐容量设计实现
吞吐量和DMZ网关的重要指标。我们以6.4 Tbit·s-1规格的可编程交换机(采用Barefoot Tofino交换芯片)为例,设计和规划整个系统的吞吐容量。
6.4 Tbit·s-1规格的可编程交换机有64个100 Gbit·s-1的端口,其中:
(1) 10个端口用于接收外部进入的流量(100 Gbit·s-1×10=1 Tbit·s-1)。
(2) 50个端口用于挂载服务器,每个服务器配置25 Gbit·s-1网卡,因此可以挂载100 Gbit/25 Gbit×50=200台的服务器用于处理。
(3) 剩余4个端口用于流量的输出(100 Gbit·s-1×4=400 Gbit·s-1),输出到最终的App区。
(4) 交换机的片上资源(SRAM+TCAM)可用于存储表项,约可以存储100万条的有状态四层连接。
通过64个端口的规划设计,整个DMZ集群的吞吐量可以达到Tbit·s-1级别,并且在交换机中可以实现高达100万条有状态流表的负载均衡,性能已经远超市场上现有的四层负载均衡设备。
3.2 高可用设计实现
前述的原型设计中,前端只有一台可编程交换机设备,在实际的生产应用中,必须有高可用的保障。
由于单台交换机已经能够达到很高的吞吐性能,利用2台可编程交换机,实现主备高可用,所有的服务器均双联至两台交换机,同时出入口的链路也进行双联,如图6所示。

图6 高可用设计示意图
正常状态下,备用交换机的链路上没有流量。当有新的流创建时,控制平面同时写入两台交换机的表项之中,使得备用交换机可以与主交换机拥有相同的流状态表项。当主交换机异常时(通过监控其指标状态),则控制服务器立刻切换出入口的流量到备用交换机。由于备用交换机与主交换机拥有相同的流状态表项,因此连接的出口依旧能够保持,所有的流并不会中断,由此实现平滑切换。
3.3 可扩展设计实现
在实际的生产应用中,还需要考虑未来的容量可扩展方案。在此提出两种可扩展的方式:
一是纵向扩展方法(scale up),即换用更高规格的交换机。当前12.8 Tbit·s-1规格的交换机也已经出现(交换机的规格一般2~3年可以增长一倍),所对应的吞吐能力可以翻番。
二是横向扩展方法(scale out),需要两层的交换机,如图7所示。第一层交换机先依据IP前缀等简单规则对报文先做一次分流到下一级的交换机,下一级的交换机再实现严格的四层负载均衡,由此可以实现整个集群最高十倍以上的横向吞吐扩展。

图7 横向扩展示意图
4 实现对比与效果
图8展现了传统DMZ网络方案与本文所提出的新型DMZ网络方案的实现对比。

(a) 传统DMZ方案 (b) 本文方案图8 实现对比示意图
本文方案主要有以下优势:
1) 单对交换机+服务器集群的极简架构。相较于F5方案,本文方案将F5四层与七层的负载均衡功能分别下沉到交换机与服务器的位置进行处理,构成了单对交换机+服务器集群的极简架构,极大提升了系统的可维护性。
2) 使用更少的硬件资源。相比传统的方案昂贵的F5专用负载均衡设备,数十台交换机用于流量转发,大量服务器做Web反向代理,本文方案硬件成本仅为F5实现方案的20%。
3) 实现更好的网络性能。根据实测结果对比,新型DMZ方案达到10倍以上的吞吐量提升,达到Tbit·s-1级别,能有效应对互联网入口的巨大流量。
表1对比了本文方案与基于软件转发的实现和专用硬件实现的技术参数与成本[8-10]。
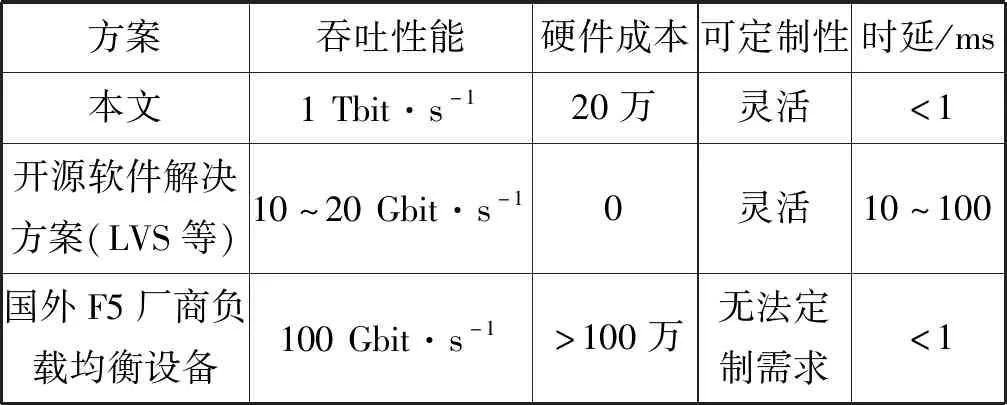
表1 DMZ区方案实现对比
5 结 语
本文针对现有金融DMZ区域成本高昂、吞吐性能无法水平扩展等问题,提出一种精简架构、超高吞吐的金融DMZ区实现方法,在大幅减小DMZ区部署设备数量与复杂度的同时可以极大地提升吞吐性能;通过一对可编程交换机加服务器集群的精简设备组,实现原有10倍以上的吞吐能力。本文方案中交换机同时负责转发流程和四层负载均衡,服务器负责七层负载均衡,将原有F5负载均衡的能力分布到了交换机与服务器集群中。同时,还充分利用加密卡、25 Gbit智能网卡等硬件设备的加速特性以提升整体集群的性能。
猜你喜欢
汽车电器(2022年9期)2022-11-07
电子技术与软件工程(2022年11期)2022-09-09
农业工程学报(2022年11期)2022-08-22
北京航空航天大学学报(2021年4期)2021-11-24
汽车电器(2021年6期)2021-07-05
科学家(2021年24期)2021-04-25
科学与财富(2016年24期)2017-03-29
知识就是力量(2017年2期)2017-01-21
智能制造(2015年10期)2015-11-04
城市建设理论研究(2011年28期)2011-12-31
