
基于云模式的微机械传感器个性化推荐算法研究
2021-02-24 10:13:44刘红英
制造业自动化 2021年12期
刘红英
(广州工商学院,广州 510850)
0 引言
微电子技术不断提高的背景下,微机械传感器也取得了较为优秀的成果。目前微机械传感器被深入研究,截止到目前,微机械传感器的类型大致分为七种,分别为微机械陀螺、微气体传感器、微机械温度传感器、微机械压力传感器、微加速度传感器、微流量传感器和其他微机械传感器[1]。这些传感器被广泛应用到化学以及医学等行业当中,通过应用到材料、设备等环节上,优化数据传输与技术控制效果,具有极大的应用前景。为了进一步掌握微机械传感器的应用方法,针对微机械传感器提出不同的个性化推荐算法[2]。这些现有的推荐算法被应用到各大网络以及设备中,尽管能够取得一定成果,但在及时性上还不够完善,需要进一步优化。云模式是将云计算与搜索引擎结合使用的新技术,具有一站式解决问题的综合能力,针对云模式的特点研究全新的微机械传感器个性化推荐算法。
1 基于云模式的微机械传感器个性化推荐算法
1.1 设置特征项标签
标准的特征项标签能够以更加全面的方式表达传递信息,能够让无线传感器网络中的节点之间快速识别,建立不同关联度的邻居关系。当微机械传感器传输稳定的数据,也就是常规内容的数据时,设置常规内容与其对应的权重分别为xi和ωi,采用信息加权技术TF-IDF,衡量传感器中数据的重要程度。其中TF用于描述词频,该数值越大越能说明内容出现的次数越多,有较高的重要性;IDF用于描述反文档频率,也就是出现次数较少导致词频较低的内容。通过上述分析过程,将标签与TF-IDF方法融合,计算公式为:

式中:fij表示信息加权函数;M表示总文档数;mi表示出现特征xi的文档数;Wj表示文本。设置某一特征项信息的标签为xj,根据上述公式融合特征项标签,得到对应的权重为:
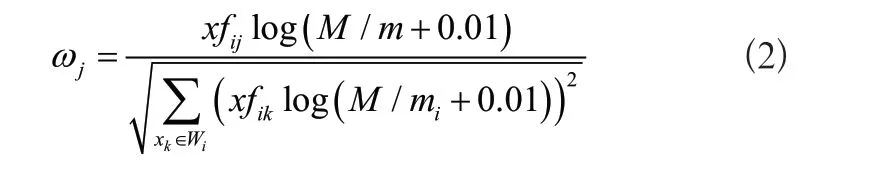
式中:xfij代表标签xj被使用的次数;M表示总数据量;m表示触发过标签的数据量;Wi表示标签集合。标签的权重取值范围在[0,1]内,当标签被频繁触发,说明传感器传输过大量同类内容,对于该标签下的数据相当熟悉。但在整个网络大环境中,传感器还会面对即时性的信息,此类信息传感器接触的相对较少,甚至有的没有接触过,那么无线传感器网络中的节点,对于此类数据没有对应的邻居关系,无法接收邻居消息,增大邻居发现延迟,所以针对即时数据也需要计算对应的权重,加快对所有节点的唤醒速度,快速建立邻居关系从而减少推荐延迟[3]。根据传感器产生的浏览行为,针对收藏页面、保存页面、打印页面、停留时间四项内容建立行为函数,公式为:

公式中:p表示传感器接触过的网络页面;其他函数与上述四项内容按顺序一一对应。当这些函数的值为0时,说明没有对该页面执行数据记录,反之则记录了该页面的数据。结合以上公式,得到特征项xj的权重为:

公式中:P表示包含特征项xj的页面集合。将权重标签的大小控制在[0,1]内,归一化处理后的特征项标签对应的权重为:

公式中:X表示特征项的集合。通过上述方法对稳定性数据与即时性数据建立标签,让传感器通信范围内的节点间快速建立邻居关系,从而为个性化推荐提供更大的主动性。
1.2 云计算模式融合与实时更新标签
无线传感器网络执行庞大的数据传输工作,尽管设置了不同的特征项标签,也还是会影响节点之间建立邻居关系的速度,利用云计算模式融合同属性标签并实时更新。已知云数据信息交互过程中,每一个簇头节点具备初始数据感知能力,根据标签实施分派,而后通过数据采集、相邻节点身份认证、多通道通信等步骤实现数据的传输工作。假设簇头节点的信息导码通过下列公式获得:
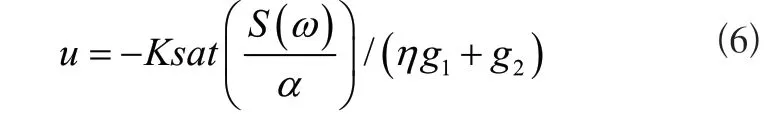
公式中:K表示簇头总数;sat表示阶段函数;S(ω)表示权重为ω的Sink节点;α表示邻居标签的特征相似度;η表示信息流特征;g1、g2分别表示稳定和即时数据数量。假设定量论域是精准的,则任意一个连通的云数据可通过G=(V,E,S)描述,其中V表示全部节点的总和;E表示期望、熵等参数的全局定义;S表示Sink节点[4]。整合云数据特征项,通过提取云数据的熵融合特征、分区预处理熵融合特征,实现云计算模式对海量标签的融合。定义信息数据节点的信息为(ai,bi),以空间采样分簇重构的方式得到X的空间结构,式为:

按照间隔粒度划分空间结构,针对分区特征集提取同一类节点的信息熵,式为:
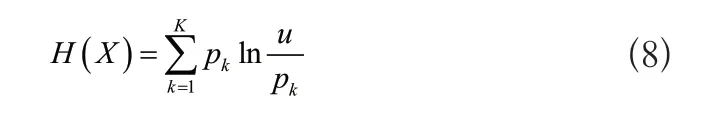
通过上述公式得到信息熵,实现对标签的融合。同样根据空间结构对特征进行混合匹配,从而达到实时更显标签的目的。云计算模式构建的簇头相异粒度数据矩阵为:
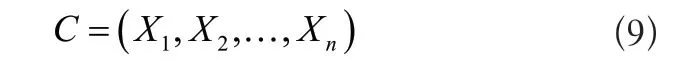
综合云自身的特殊性以及数据的相似性,以模糊计算为原则,设置标签匹配模式,实时更新标签,帮助邻居节点之间快速识别与关联。式为:

通过上述融合与匹配过程,实时更新特征项标签,加快节点之间建立关联,强化对节点的唤醒操作。
1.3 考虑时序性的个性化推荐
在获得实时标签的基础上,利用聚类技术按照位置的远近处理标签,将位置近的标签和位置远的标签划分到不同的簇中,这样在个性化推荐过程中能缩减项目搜索范围,在考虑时序性的条件下,能改进算法的推荐效率。聚类过程如图1所示。
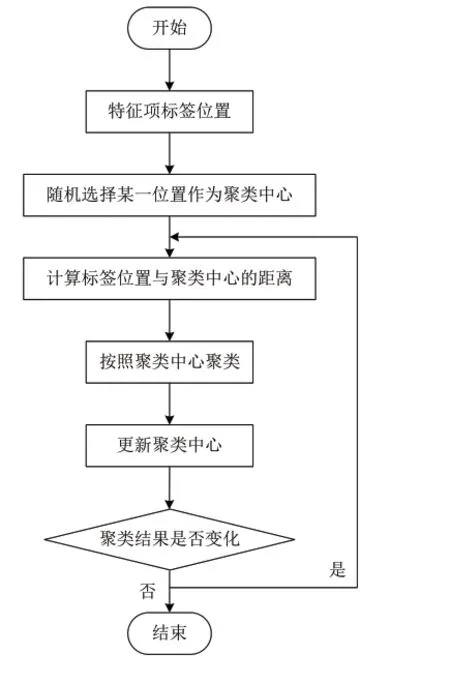
图1 聚类流程
根据实时标签的聚类结果,将BP模型与RNN模型融合使用,解决个性化推荐过程中产生的时间序列问题。假设用户行为在短期内发生频繁变化,此时的特征项标签也随之改变,利用反向传播算法(BP)在接收输入数据与产生输出数据之间,根据一定程度的误差反向传播,更新网络内部的各种参数,该误差值为:

公式中:J表示损失函数,用来描述误差;R表示隐藏层;c表示神经元的偏置。循环神经网络(RNN)具有可多次交互数据的能力,可以根据交互次数设置网络空间层次,每一空间层代表一次交互过程。将二者融合使用,建立混合推荐模型。已知网络的输入是实际值,输出是预测值,输入向量的长度等于项目总数,所以让BP与RNN分享相同的输出层,合并输出层后产生单一结果。则存在:

式中:b(J)i、b(J)0i分别表示合并输出层和随机输出层的产出结果[5]。假设RNN的单元数为E,则传感器推荐某一内容的概率为:

上述公式无需手动操作,而是通过神经网络训练实现,通过网络层对数据的不断采集、更新、匹配,实现微机械传感器的个性化推荐工作。
2 测试与分析
2.1 测试环境
本次测试选用的设备配置Intel Pentium 4处理器,操作系统为Windows XP,包括200G硬盘和4G内存。利用Java语言模拟实现,将带有微机械传感器的设备与互联网平台之间建立连接,检查网络是否稳定。利用SimPy设计一个针对离散事件的仿真框架,该软件以生成器为基础模拟实体,也就是将微机械传感器的节点看作生成器,仿真个性化推荐操作。
2.2 评价标准
根据推荐质量评价结果,判断本文算法是否具有实用性;根据响应时间评价结果,判断本文算法是否在短时间内能唤醒网络通信节点;根据平均发现延迟评价结果,判断本文算法是否能够快速建立邻居关系;根据节点能耗评价结果,判断本文算法是否能够主动唤醒更多节点,将额外能量开销降至最低。推荐质量的评价将平均绝对偏差MAE作为衡量指标,所得的值越小越能说明算法具有较高的推荐质量。该值的计算公式为:

式中:Ai、Bi分别表示用户评分的预测集合和实际集合。响应时间用RT表示,也就是目标发出推荐请求与传感器产生推荐的时刻差值,计算式为:

式中:t1表示发出推荐请求的时刻;t2表示产生推荐结果的时刻。平均发现延迟用RTT表示,计算公式如下:
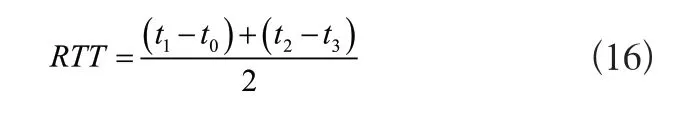
式中:t0、t3表示客户端的发包与收包时间;t1、t2表示节点的发包与收包时间。设置每个节点平均能耗为E,则式为:

公式中:k为常数;d表示一跳的距离;i表示节点数,且i>2。测试设置2个对照组,分别为协同推荐算法和混合推荐算法。以对比测试的方法比较三组方法在四组指标上的评价差异,根据测试结果比较不同算法的性能。
2.3 云模式的应用
本文方法根据推荐者、被推荐者和推荐目标三项参数,在特征项标签的基础上,利用云计算模式融合与实时更新标签,如图2所示。
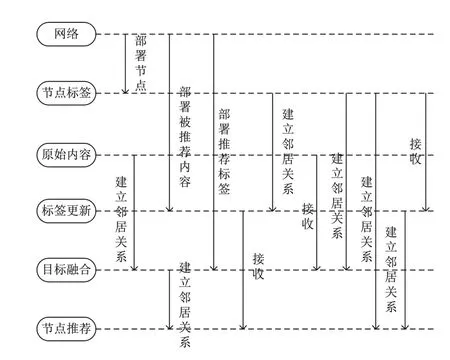
图2 云模式的应用
在融合同类型标签的基础上,通过实时更新标签获取实时数据,保证标签都是不重叠的。本文研究的算法在此基础上推荐个性化数据。
2.4 结果与分析
2.4.1 推荐质量测试
将本文算法与两组传统算法分别应用到同一型号的设备中,已知设备的微机械传感器型号相同。利用该设备查询信息,利用式(14)评价三组算法的推荐质量,结果如图3所示。

图3 推荐质量测试结果
根据上图显示的结果可知,三组方法的平均绝对偏差MAE均处于0.5以下,但本文算法的评价结果比两组算法分别低了0.21和0.19,说明本文算法的个性化推荐质量更高。
2.4.2 响应时间测试
根据式(15)计算三组算法的响应时间,结果如图4所示。

图4 响应时间测试结果
根据图4显示的结果可知,本文算法的响应时间RT最短,面对500个通信网络节点时,平均响应时间比协同推荐算法和混合推荐算法分别减少了24.1s和19.8s,说明本文算法在短时间内,能快速唤醒更多传感器网络通信节点。
2.4.3 延迟对比
已知传感器网络的能量有限,通常情况下的网络节点会随时进入睡眠状态,比较三组算法的平均发现延迟,根据式(16)得到的结果,绘制图5所示的实验结果。

图5 平均延迟测试结果
根据上述评价结果可知,在同样的测试条件下,随着节点数量的增加,本文算法的平均发现延迟RTT稳定在31~33s之间,协同推荐算法和混合推荐算法的平均发现延迟,分别在31~38s和31~40s之间,说明本文算法在快速响应的基础上,将通信节点之间迅速建立邻居关系,能够以最快速度进入到工作状态。
2.4.4 能耗对比
利用式(17)评价节点能耗并绘制实验图,如图6所示。

图6 节点能耗测试结果
根据图6显示的评价结果可知,面对越来越多的节点数目,本文算法能够将节点能耗E始终控制在2.0×103以下,而协同推荐算法和混合推荐算法的节点能耗,随着节点数目的增加而逐渐增多,说明本文方法能够用最小的能耗唤醒更多的节点,将额外能量开销降至最低。
3 结语
随着互联网、互联网技术的飞速发展,网络资源变得更加复杂、多样,如何从海量的数据中快速获取目标信息,满足不同使用用户的需求,是现阶段研究的重点问题。面对信息过载这一现状,本文算法以推荐的及时性为研究目标,利用更多智能技术实现了对现有推荐算法的优化。但此次研究还存在不足,这种算法的及时性能得到提升,但对于推荐数据的准确性还有待验证。今后在时间充沛的情况下,可以评价推荐内容的准确性,完善该算法的其他性能。
猜你喜欢
文苑(2020年4期)2020-05-30 12:35:12
当代工人(2020年8期)2020-05-25 09:07:38
新闻传播(2018年12期)2018-09-19 06:27:10
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
小溪流(画刊)(2017年12期)2018-01-10 16:07:29
汽车与新动力(2016年6期)2017-01-04 10:50:48
科技知识动漫(2016年8期)2016-07-29 20:40:09
公民与法治(2016年10期)2016-05-17 04:12:58
儿童故事画报·发现号趣味百科(2015年12期)2016-01-25 00:41:49
