
基于YOLOv5的医用外科手套左右手识别
2021-02-24 10:13:46琚恭伟焦慧敏张佳明暴泰焚蔡吉飞
制造业自动化 2021年12期
琚恭伟,焦慧敏,张佳明,暴泰焚,蔡吉飞
(北京印刷学院 机电工程学院,北京 102600)
0 引言
全球新冠疫情蔓延,使得医用外科手套需求量激增。医用外科手套具有左右手之分,包装过程中,依靠人工识别和手动分拣,但是长时间人工分拣,容易产生错检、漏检。为了提高生产效率,急需采用自动化方式代替人工分拣,实现左右手套识别问题。本文使用深度学习技术,搭载相应的图像采集装置,完成医用外科手套的左右手识别,提高分拣过程中的自动化程度。
随着计算机视觉和深度学习的快速发展,使得自动化和智能化包装方式取得巨大进步。Hinton[1]等人使用卷积神经网络(CNN)参加ILSVRC(ImageNet Large Scale Visual Recognition Challenge)图像分类大赛,证明了深度学习的潜力。目前,基于CNN的目标检测算法大致可以分为两类,一类为“two-stage detection”(两步骤检测),另一类为“one-stage detection”(单步骤检测)[2]。“twostage detection”即基于候选区域的目标检测算法,这是一个“从粗到细”的过程,先根据不同的区域选择算法从图像中选择多个感兴趣的领域,然后通过深度学习提取特征并分类检测。T.-Y.Lin[3]等人提出的FPN(feature pyramid networks)算法,采用了特征金字塔网络结构,在检测各种尺度的目标方面取得巨大的进步。“one-stage detection”即基于回归的目标检测算法,在将一张图像进行分割操作,使其成为多个候选区域的同时,被分割出来的区域的边界框和目标的概率也会被预测出来,这样就可以在牺牲部分定位精度的情况下,大大提升检测速度。YOLO(You Only Look Once)v5被Jocher[4]提出,作为目前较为领先的目标检测技术,YOLOv5在推理速度上表现优异。
外科手套在充气状态下进行品质检测和左右手的识别。由于上道工序对手套的夹持位置不同,导致充气后的手套状态各异,使得对目标定位困难。郭[5]利用肤色检测和背景差分方法相结合的方式实现人手的定位和跟踪。张[6]提出基于梯度方向直方图特征的主成份分析方法,对视频中单手或者双手的手部分割和跟踪具有较好的辅助作用。Bao[7]对卷积神经网络模型的反向传播过程进行分析,采用不同的损失函数在模型中学习相同次数,分析比较学习结果,优化了反向传播过程,并应用于人手的左右手识别,提高了识别正确率。
本文提出在YOLOv5目标检测算法的前提下,使用复制多份数据集的方法,减少人工labelimg标注的时间,提高数据的有效性和模型的准确性。
1 YOLOv5算法原理
YOLOv5模型集成了FPN多尺度检测及Mosaic数据增强和SPP结构,整体结构可以分为四个模块,具体为:输入端(Input)、主干特征提取网络(Backbone)、Neck与输出层(Prediction)。
第一部分是Input,包括Mosaic数据增强、自适应锚框计算、自适应图片缩放三大部分。Mosaic数据增强是将数据集图片以随机缩放、随机裁剪、随机排布的方式进行拼接。自适应锚框计算是指在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向迭代,更新网络参数。自适应图片缩放常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。

图1 YOLOv5s网络结构图
第二部分是Backbone,由Focus结构和CSP结构组成。Focus结构中,切片操作是最为重要的。例如,输入一个原始图像,其大小为608×608×3,对其进行切片操作,这样就能使其成为一个304×304×12的特征图,之后经过32个卷积核进行一次卷积操作,这样就可以得到一个304×304×32的特征图。CSPDarknet53是借鉴了CSPNet并在Yolov3所使用的主干特征提取网络Darknet53的基础上,将resblock_body的结构进行修改并使用CSPnet结构,而产生的主干特征提取网络Backbone结构。这样可以有效的增强卷积神经网络的学习能力,在保证其运行准确性的同时,使CNN更加的小,这样就可以有效降低计算瓶颈,也可以减小内存成本。YOLOv5中分别设计和使用了两种不同的CSP结构,其中CSP1_X结构应用于主干特征提取网络中,同时在Neck中使用了另一种CSP2_X结构。
第三部分是Neck,由FPN和PAN组成,FPN是通过向上采样的方法将上层的特征进行传输融合,从而得到预测特征图,其中含有两个PAN结构。FPN采用了自顶向下的结构,这样就可以进行对于强语义特征的传输,特征金字塔采用了自底向上的结构,这样就可以进行对于强定位特征的传输,这两者经过练手结合后,就可以将每一个检测层做到特征聚合,这样就成功提高了特征提取的能力。
第四部分是Prediction,Generalized Intersection over Union(GIOU_Loss)与Complete Intersection over Union(CIOU_Loss)目标检测任务往往都使用损失函数,损失函数一般由两大部分构成:回归损失函数和分类损失函数。GIOU_Loss与CIOU_Loss都是以IOU_Loss为基础发展的回归损失函数。所需要识别的目标框和检测框之间的重叠面积是IOU_Loss主要考虑的问题,但是它有时会存在所需要识别的目标的框和检测框的边界不重合的问题,GIOU_Loss解决了这个问题,但是这两个损失函数依旧存在着没有考虑到所需要识别的目标的框和检测框中心点距离的信息的问题,DIOU_Loss解决了这个问题,但是DIOU_Loss存在没有考虑所需要识别的目标的框和检测框的宽高比的尺度信息的问题,而CIOU_Loss解决了这个问题。
2 YOLOv5目标检测算法的实现
本次实验首先搭建YOLOv5环境,然后采集数据构建数据集,通过labelimg工具对数据集做标签标定,将做好的数据集放到YOLOv5上进行训练,产生训练模型,最后使用生成的训练模型对同一测试集进行识别,得到识别结果,分析多次对测试集识别产生的结果,得出结论。实验流程如图2所示。

图2 实验流程图
2.1 实验环境
本文的实验环境搭建在工作站上,服务器配置使用Ubuntu 18.04版本,CUDA Toolkit 10.1版本,深度学习框架平台为Pytorch 1.6 版本。
2.2 数据收集及标注
在收集数据时,使用固定式相机进行拍摄,为模拟生产医用外科手套现场,采集到的图片为同一背景。在医用外科手套充满气的状态下,从底部对其进行拍照,充分考虑实际医用外科手套的气密性检测状态,从其正下方拍照,通过旋转、平移、俯仰手套等实际情况,收集手套在各个角度下的图片数据,同时删除数据集中人眼识别较低的图片,共收集2378张照片,以此来增强数据的真实性,之后将收集到的数据分为三组,分别为训练集、验证集和测试集,比例为3∶2∶1。
针对数据集中的图片,采用labelimg工具进行框选标注,将医用外科手套左手的图片标注为left,右手为right,标注范例如图3所示。

图3 labelimg软件标注图
2.3 初始参数
将收集到的数据集和相对应的标签文件,按照训练集、验证集、测试集的顺序放到相对应的文件夹中,然后配置训练模型的参数,通过终端输入训练命令,模型的训练次数Epochs设为500;批次大小Batch size是指训练时一次性输入网络的图片数目,与显卡的显存大小有关,将其设为16;提高输入分辨率在一定程度上会提高小目标检测精度,所以输入分辨率img-size的原始值为640。
2.4 实验过程及结果
为验证复制训练集和验证集的方法对系统识别准确率的影响,本实验通过使用YOLOv5s训练框架对数据集进行训练,对同一组训练集和验证集,复制一份到十份,对其逐一进行训练,得到训练模型,将训练出来的模型,对相同的测试集进行测试,得到平均得分、错识别率、漏识别率以及准确率,结果如表1所示,结果趋势如图4所示。

图4 实验趋势图
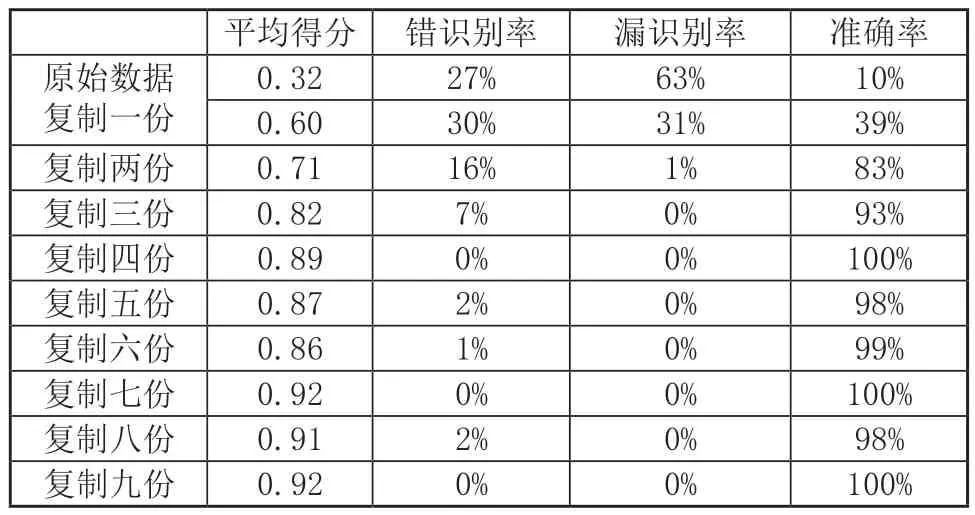
表1 实验结果对比
平均得分是测试之后产生具有识别标识部分得分的平均值,错识别率是测试之后产生具有标识部分医用外科手套左右手辨别错误占总数的比率,漏识别率是测试之后具有医用外科手套左右手但未检测出来的图片占总数的比率,准确率是测试之后正确识别医用外科手套左右手占所有测试图片总数的比率,仅对本文实验数据集的数据有效。错识别图:如图5(a)所示,第一轮原始数据右手的一张图,图5(b)所示,第六轮复制五份右手的一张图;识别得分低图:如图5(c)所示,第一轮原始数据右手的识别图,图5(d)所示,第三轮复制两份左手的一张图;漏识别图:如图5(e)所示,第一轮原始数据左手的一张图。本文测试结果,此处为第十轮识别结果部分数据结果截图,如图6所示。
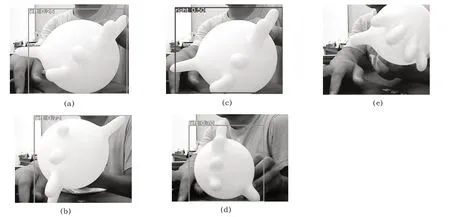
图5 错识别、低识别、漏识别示例图

图6 第十轮识别结果部分数据图
2.5 实验分析
实验过程中每一轮对测试集单张图片测试时间在0.004s到0.005s之间,训练速度基本一致。
通过对比实验过程中的数据,在第一轮原始数据和第二轮复制一份的时候,正确率较低,漏识别率和错误率较高。到第五轮复制四份的时候,训练模型的准确率满足实际生产需求。在第六轮复制五份、第七轮复制六份、第九轮、复制八份的实验中,出现对一部分图识别错误的情况,这些错误识别图是收集数据的时候光线较强烈,对于光线较强的时候,该模型还是具有缺陷。为满足工业生产识别需求,在生产过程中添加控制光照不变的装置,收集该状态下的数据集,以减少光照对识别的影响,进而减少错误率。
通过对比可得出结论:同一数据集使用复制训练集和验证集的方式可以增加准确率,本实验使用复制的方法和YOLOv5模型中的Mosaic数据增强不冲突,此方法是在Mosaic数据增强基础上进行实验。对于模型准确率,仍需要做多次实验,得到最优的训练模型,避免光照、色差等因素的影响。
3 结语
本文采用YOLOv5目标检测算法,研究了固定式摄像头对医用外科手套生产过程中左右手识别,收集同一背景、同一主体、不同状态的数据集,使用了复制数据集的方法,通过对比不同训练模型的测试结果,得出相同的数据集复制多份可以增加训练模型的准确性的结论,但数据集复制到一定的次数之后,训练模型对同一批测试集有很好的识别性,此时模型处于过拟合的一个状态。
由于本文数据集的单一性,出现过拟合状态,下一步解决过拟合状态的训练模型,增强模型的有效性。
猜你喜欢
大自然探索(2023年11期)2023-03-01 09:05:18
阅读与作文(小学高年级版)(2021年8期)2021-09-12 17:18:16
中学生数理化·高一版(2020年6期)2020-12-17 08:00:15
中学生数理化(高中版.高二数学)(2020年6期)2020-12-04 14:13:23
中华肩肘外科电子杂志(2020年1期)2020-08-24 07:03:26
小哥白尼·趣味科学画报(2019年12期)2019-02-28 11:55:02
消费导刊(2018年10期)2018-08-20 02:56:40
数位时尚(幼儿教育)(2018年3期)2018-04-12 05:32:49
阅读与作文(小学高年级版)(2017年7期)2017-08-04 09:29:11
小天使·六年级语数英综合(2017年3期)2017-04-25 21:55:29
