
一种基于YOLO的多尺度融合图像分割模型
2021-02-23 03:44陈沛鑫胡国清JahangirAlamSM
新技术新工艺 2021年1期
陈沛鑫,胡国清,Jahangir Alam SM
(华南理工大学 机械与汽车工程学院,广东 广州 510641)
图像分割是指根据一定的相似性准则将图像划分成不同区域的过程,是计算机视觉、图像处理等领域的基础性问题之一,是图像分类、场景解析、物体检测、图像3D重构等任务的预处理[1]。其研究从20世纪60年代开始,至今仍然是研究的热点之一,并且被广泛应用于医学影像分析、交通控制、气象预测、地质勘探、人脸与指纹识别等诸多领域。传统的图像分割方法主要包括阈值法、边界检测法、区域法等。这些方法的实现原理有所不同,但基本都是利用图像的低级语义,包括图像像素的颜色、纹理和形状等信息,遇到复杂场景时实际分割效果不尽理想。如何有效地利用图像自身包含的内容信息,结合图像中级、高级语义提升图像分割效果,成为近年来研究的热点。图像的中级语义是指将具有相似特征的相邻像素构成的图像块所具有的像素连成一体,如图像块的粗糙度、对比度、方向度、紧凑度等,以此辅助图像分割并提升效果。图像的高级语义是指图像或图像区域所包含的对象或实体的类别等语义信息,高级语义下的图像分割称为语义分割。
图像分割问题一直都是计算机视觉领域的热门话题之一,每年都有大量的新方法呈现。近年来,国内外学者主要研究基于图像内容的分割算法。图像分割算法基本分为基于图论的方法、基于像素聚类的方法和语义分割方法这3种类型。谱聚类方法建立在谱图理论的基础之上,通过构造关于原图的拉普拉斯矩阵并求解特征值和特征向量,对图中顶点进行前背景分离,以解决图像分割问题。Shi等[2]提出规范割(normalized cut:NCut)算法,而Sarkar等[3]改进了NCut算法,提出了平均割(average cut:ACut)算法。Li等[4]提出了线性谱聚类(linear spectral clustering:LSC)算法,该算法基于K路NCut(K-way NCut)算法的代价函数,使用核函数将像素值和坐标映射到高维特征空间,通过证明带权k-means(weighted k-menas)算法和K-way NCut算法的代价函数共享相同的最优点,迭代地使用k-means算法在高维特征空间聚类代替NCut算法中特征值和特征向量的求解,将算法复杂度降低到O(N)。基于像素聚类的分割方法包括基于Meanshift的方法、基于Turbopixels的方法和基于SLIC的方法。图像语义分割算法包括基于候选区域的方法和端到端的方法。
深度神经网络图像语义分割目前的基本研究思路是先进行编码与解码,也即下采样+上采样。再进行多尺度特征融合,也即特征逐点相加和特征维度拼接。最后获得像素级别的分割特征图,对每一个像素点进行判断类别。目前的模型结构在大目标表现比小目标更好,需要在细粒度特征上有针对性的强化。目前的分割精度仍然不能达到应用级别,需要在结构上进一步进行创新尝试,高效利用特征图表达。
1 YOLO框架及其原理
YOLO是一种基于深度学习神经网络的对象识别和定位算法,其最大的特点是与运行速度很快,可用于实时系统[5]。它采用One-Stage策略,对输入的一张图片直接学习出特定对象的位置。对于输入图片,先进行一系列卷积池化操作。卷积的计算原理如下,设输入矩阵格式4个维度依次为:样本数、图像高度、图像宽度、图像通道数,输出矩阵格式与输出矩阵的维度顺序和含义相同,但是后三个维度的尺寸发生变化。权重矩阵(卷积核)格式同样是4个维度,但维度的含义与上面两者都不同,为卷积核高度、卷积核宽度、输入通道数、输出通道数(卷积核个数)。输入矩阵、权重矩阵、输出矩阵这三者之间的相互决定关系。卷积核的输入通道数(in depth)由输入矩阵的通道数所决定。输出矩阵的通道数(out depth)由卷积核的输出通道数所决定。输出矩阵的高度和宽度(height, width)这两个维度的尺寸由输入矩阵、卷积核、扫描方式所共同决定。计算式如下:
(1)
池化层的过滤器长宽设为kernel*kernel,池化层的输出维度也使用式1计算。
检测框架采用416×416的输入,经过一系列卷积池化操作,最后连接全连接层输出目标框大小位置及其类别。具体过程如图1所示。
YOLO框架的损失函数由边框中心误差、边框高宽误差、置信度误差(边框内有对象且对象为目标)、置信度误差(边框内无对象)、对象分类误差(边框内有对象)组成[6],具体函数为:
(2)
YOLO网络是目标检测的一个强大框架,使用已经在大型目标检测数据库预训练过的模型参数,在该参数下的模型已经学到了很多基本特征,与现有其他领域的做法一样,笔者在自己的检测对象继续训练模型进行微调,使参数空间偏向于所需目标,这样做可以达到很好的识别效果。
虽然训练过程存在训练速度较慢、收敛速度慢的特点,导致前期的训练可能需要花费较多时间,所以前期的训练优化可以在GPU上完成。训练完成后的检测阶段只需要进行网络的前向传播而不需要反向传播优化,前向传播是卷积计算,基本是矩阵乘法,这可以很快部署到相应硬件上,达到应用水准。
YOLO框架的缺点在于,对相互靠得很近的物体,还有很小的物体检测效果不好,因为1个网格只预测2个框且属于同一类。对测试图像中,同一类物体出现新的不常见的高宽比时效果不好。由于损失函数的问题,定位误差是检测效果的主要原因,尤其是对大小物体的处理上,定位误差大,召回率低。
2 改进的YOLO人像分割模型
YOLO框架是一种有效的深度学习方法,已被大量实验证明能很好地对目标进行标识和分类。深度学习框架学习都是由低级特征到高级特征、由简单特征到复杂特征进行,所有中间层都可以视为特征图,而不管该框架是用于何种图像处理技术,例如检测、 跟踪、 分割等。由于YOLO框架在目标识别领域的重要作用,其中间层很好地学习了物体的特征,笔者将YOLO框架其对物体的特征信息提取出来,其中间层可作为物体特征图进行研究。传统的网络架构以单一尺度进行前向传播和反向求导,往往导致不同分辨率下的误差率不一致,对于小分辨率的物体识别精度不高,大分辨率物体整体轮廓信息得以保存的同时丢失一部分边缘信息[7]。

图1 YOLO框架
本文将YOLO网络的前5层网络提取出来作为新网络的特征提取基础架构,提出将不同层的特征图加以整合形成一张新的特征图的方法,具体模型如图2所示。

图2 本文模型
使用一组因子将输入特征图显式降采样为小尺寸,然后独立进行卷积,从而得到不同比例的表示。最终将多尺图上采样到与输入特征图相同的分辨率,并将它们在通道维度上连接在一起。具体做法是,先使用一种CNN框架(本文使用YOLO)计算出一张特定的特征图,将其进行3次不同的池化下采样计算,然后分别进行卷积计算得到3张不同分辨率下的特征图,最后将3张图进行上采样得到相同的高宽进行拼接形成最后的输出,形成一种新的图像分割模型。前5层的采用式1进行计算。后面的特征图拼接需要使用上采样,上采样的方法有3种,分别是双线性拟合、反卷积、反池化,本文使用双线性插值。
插值问题实际上是一种拟合问题。所谓插值就是用x′某个领域内的函数值按照一定规则拟合出一个函数,再在其中查找f(x′)的值,图3显示了这一计算过程。
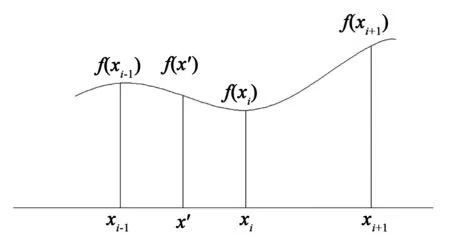
图3 线性插值
双线性插值过程如图4所示,D点的具体值计算如下:
f(D1)=(1-y)f(P00)+yf(P01)
f(D2)=(1-y)f(P10)+yf(P11)
f(Dx)=(1-x)f(D1)+xf(D2)
f(D3)=(1-y)f(P00)+yf(P10)
f(D4)=(1-y)f(P01)+yf(P11)
f(Dy)=(1-x)f(D3)+xf(D4)
(3)
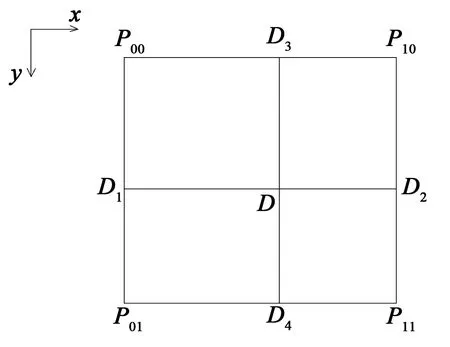
图4 双线性插值
由于进行的是分割,最后计算的是每一个像素点的类别,所以损失函数使用交叉熵[8],用以描述模型预测值与真实值的差距大小,交叉熵具体形式为:
(4)
式中,i是灰度图像的每一个像素的值,对于计算出的边缘图,将所有像素的值与ground truth进行损失函数计算,然后在网络中进行反向传播,即可更新网络参数。
3 试验结果与分析
本文采用VOC2007数据集进行试验,试验平台配置为Windows10、python3.6、gpu nvidia 940M和tensorflow1.10.0。在进行网络训练后,选择数据集的100张人像数据进行分割,并和经典的分割网络结果进行对比[9-10],部分试验结果如图5所示,最后使用平均分割精度统计,这里平均分割精度指的是模型分割结果和ground truth的像素重合比例(pixel accuracy),结果见表1。
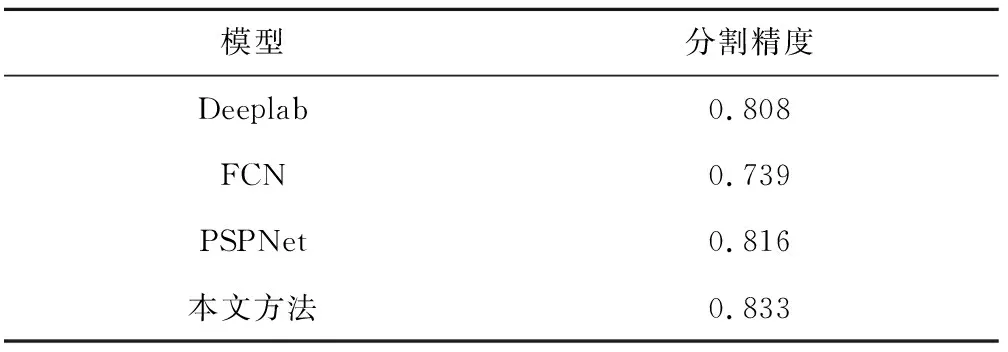
表1 平均分割精度

图5 部分试验结果
从试验结果来看,人像的大体框架都能被几种模型分割出来,但是细节部分各有不足的地方。第1张图人物手的部分在FCN和PSPNet模型中并没有分割出来,模型把背景的一部分当成手,小尺度下的分割准确度不高。第2张图在有物体遮挡时,前三种模型都识别不出人物的腿进行分割,导致人像分割不完整。第3张图所有模型都分割出了2个任务,但具体到像素级别进行比较,仍然是本文提出的方法更为准确。在试验绝大部分图像中,本文提出的方法与其他经典方法比较,精度都要更好。而在所有图像的分割精度上,本文方法达到了0.833,相较于传统的CNN分割图像模型有所提高。
4 结语
本文基于YOLO检测框架提出一种新的模型用于分割,使用检测网络的中间层作为分割模型的前段模型,省去了部分网络的训练过程,后半段模型是本文提出的多尺度卷积池化层,其中不同的层代表了不同的尺度下的特征,以此来解决以往网络在不同尺度下表现不一致的问题。同时,由于进行了下采样操作,使得计算效率更高,并且可以捕获更大的范围。本文提高了不同尺度下的分割精度,具有一定的应用价值。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2020年3期)2020-07-27
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
燕山大学学报(2015年4期)2015-12-25
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
大连民族大学学报(2015年2期)2015-02-27
