
一种新的引入MFCC的语音去噪模型
2021-02-23 02:46靳华中徐雨东李晴晴李文萱
湖北工业大学学报 2021年1期
靳华中,徐雨东,李晴晴,李文萱
(湖北工业大学计算机学院,湖北 武汉 430068)
语音信号作为人类获取和传播信息的重要手段,是人类最重要、最有效、最常用和最方便的通讯方式。但是,在进行语音通信的过程中,周围环境、传输介质、通信设备的干扰,使接收到的语音信号成为被噪声污染的语音信号。语音去噪就是抑制和降低噪声干扰,从带噪语音信号中获得纯净语音信号的过程。
语音去噪通常需要针对语音和噪声信号的特性进行相应的分析处理。例如,基于语音信号的短时平稳特性,处理时通常对语音信号进行分段独立处理。由于人耳掩蔽特性,需要考虑不同频率信号间的影响。由于语音中周期性的浊音是高能量部分,可以使用滤波器提取语音分量。而由于噪声特性与噪声来源相关,针对不同的噪声通常采取不同的去噪方法。
传统的语音去噪方法谱减法[1]、维纳滤波法[2]、基于统计模型的方法[3]、子空间算法[4-5]等长期以来被广泛使用。谱减法从信号的功率谱中减去估计噪声的功率谱,原理简单,实现容易,但是不适合处理信噪比较低和噪声不平稳的信号。维纳滤波法要求输入的信号不但是广义平稳的,而且统计特性已知,通常的噪声很难满足这两个要求。基于统计模型的方法在假定语音和噪声服从某种概率分布的基础上进行建模,但无论瑞利分布还是高斯分布都不能精确地描述语音信号。子空间算法复杂度较高,无法用于需要实时处理的场景。由分析可知,传统去噪方法通常只适用于语音服从高斯分布或噪声是平稳的简单场景,在复杂场景下效果较差。
基于神经网络的优秀语音去噪算法 包括深度神经网络[6]、全卷积神经网络[7]、空洞卷积神经网络[8]、循环神经网络[9-10]、生成对抗网络[11-12]等语音算法。这些算法不仅去噪效果好,而且根据训练集的不同,通常可以去除不同类型或不同强度的噪声,且对噪声的平稳性要求不高。目前比较成熟的算法和传统方法一样,只使用语音的频谱进行去噪,认为相位谱对去噪工作没有帮助。但是有研究表明[13],使用语音的相位谱或许能显著改善去噪效果,而直接作用于原始音频的神经网络能使用包括相位的更多有效信息。如果将语音的音频直接输入,对于一个采样率为16 kHz的音频,每秒有16000个采样点,普通的神经网络无法胜任。目前直接使用原始音频输入的结构主要是基于生成对抗网络的,把生成器当作增强网络,用判别器区分干净语音和去噪语音,例如SEGAN[11]。同时还出现了其它直接使用原始音频的方法,例如基于空洞卷积的端到端结构,也就是Wavenet[14]中所使用的结构。
Wavenet是由Google提出的基于原始音频的自回归生成模型,能够用于多人语音生成、语音转文本、音乐建模等任务,通过Wavenet生成的语音更接近人的声音。而Speech-denoising Wavenet[8]能够克服使用频谱等高级特征作为前端的固有局限性,而且其语音去噪的效果优于SEGAN。受此启发,本文将Wavenet和梅尔频率倒谱系数(MFCC)结合起来,在网络输入端同时使用原始音频及其频谱中的高级信息,以进一步提升去噪效果。为验证本文提出算法的效果,实验过程采用和基于神经网络的语音去噪算法相同的训练集和测试集。虽然在实际使用时会因为计算语音的MFCC而降低处理速度,但在相同训练集中训练时,该方法的收敛速度更快,在相同测试集中测试时,该方法的去噪效果更好。
1 引入梅尔频率倒谱系数的Speech-denoising Wavenet
1.1 Speech-denoising Wavenet
Wavenet是根据PixelCNN[15]提出的音频生成模型,使用了因果卷积和空洞卷积的结构。空洞卷积使得感受能随着网络深度的增加而倍增,可以直接对原始音频进行建模,而由于因果卷积没有使用递归连接,模型训练速度比RNN更快。和语音生成模型不同,语音去噪不需要因果卷积的方法,网络的输出不是下一个采样点,而是已经去噪的采样点。因此,Speech-denoising Wavenet将空洞卷积的卷积核大小由2×1改为3×1,利用带去噪语音前后的一段语音对当前采样点进行去噪,如图1所示。这样,修改后的模型就不再是自回归生成模型,也就没有了Wavenet中的时间复杂度问题。
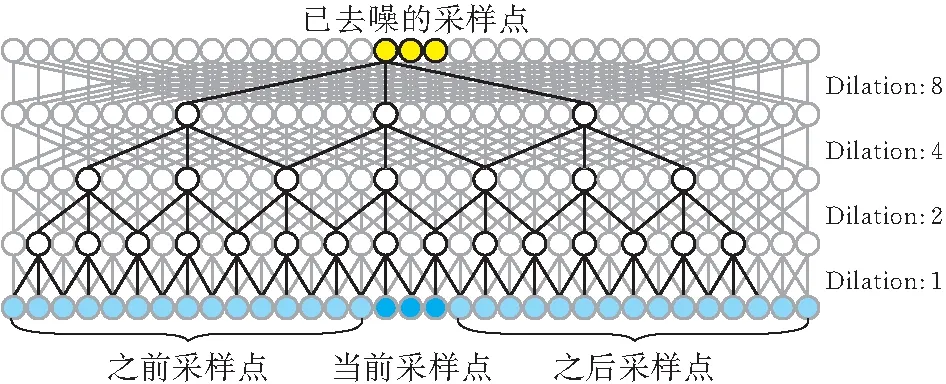
图 1 Speech-denoising Wavenet的空洞卷积网络
1.2 引入梅尔频率倒谱系数
梅尔频率倒谱系数(MFCC)是语音识别等领域被广泛使用的音频特征,传统语音识别算法非常依赖MFCC,并且已经有非常成熟的算法能通过MFCC进行语音识别[16-18]。要得到一段音频的MFCC,需要经过预加重、分帧、加窗、快速傅立叶变换(FFT)、Mel滤波器组和离散余弦变换(DCT)这几个步骤[19]。
对于固定长度的音频,其得到的MFCC数量相同,但不适合直接作为网络的输入,需要先进行归一化。考虑到MFCC值的大小,将其值除以50之后通过tanh函数映射到-1至1。接着,使用一个全连接层和一个卷积层使数据维度与残差层中的数据维度一致,以便和每一层空洞卷积的结果直接相加(图2)。
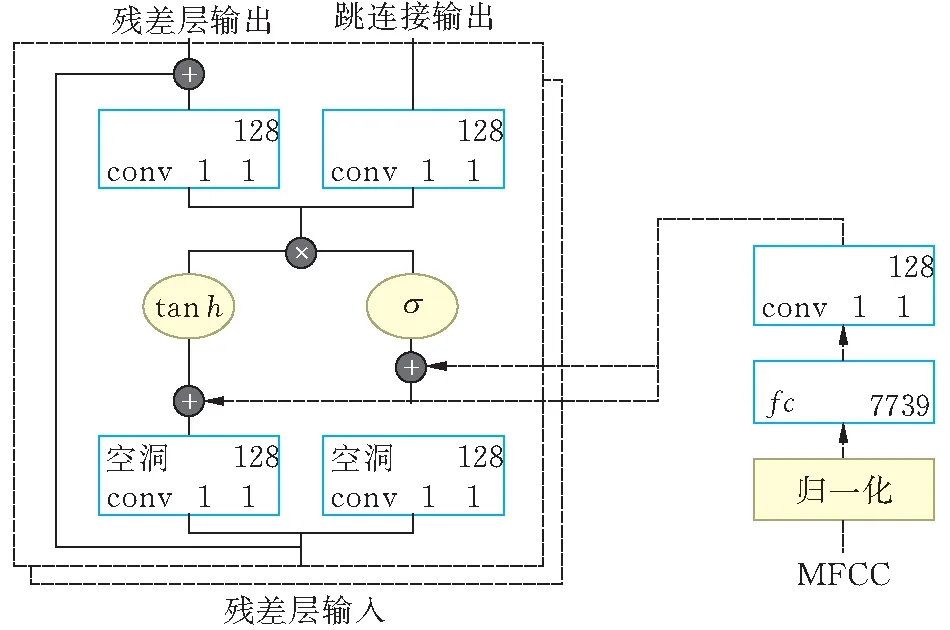
图 2 将语音的MFCC引入Speech-denoising Wavenet
残差层中的数据维度是7739×128。先使用一个全连接层将数据映射到7739×1,然后使用一个有128个卷积核的卷积层将数据映射为7739×128,每个卷积核大小为1×1。网络其它部分的结构保持和Speech-denoising Wavenet一致。
2 实验结果与分析
在训练和测试时所有的语音数据由Voice Bank语料库[20]提供,环境噪音由Demand数据库[21]提供。其中训练集有11574条长度不超过15 s的语音,信噪比分为0、5 dB、10 dB和15 dB四类。测试集也有824条类似的语音,信噪比分为2.5 dB、7.5 dB、12.5 dB和17.5 dB四类。训练和测试时会把所有语音统一重采样至16 kHz。本文模型和Speech-denoising Wavenet一样有30层残差层,网络每次对1601个采样点进行去噪。
信噪比(SNR)是通用的评价标准:
SNR=10×lg(Ps/Pn)
(1)
式(1)中Ps和Pn分别代表信号和噪声的有效功率,SNR越高表示音频中所含的噪声越少。和Speech-denoising Wavenet相比,测试集中71.2%的语音的SNR有所提升,平均提高了3.60%。实验结果见表1和图3。
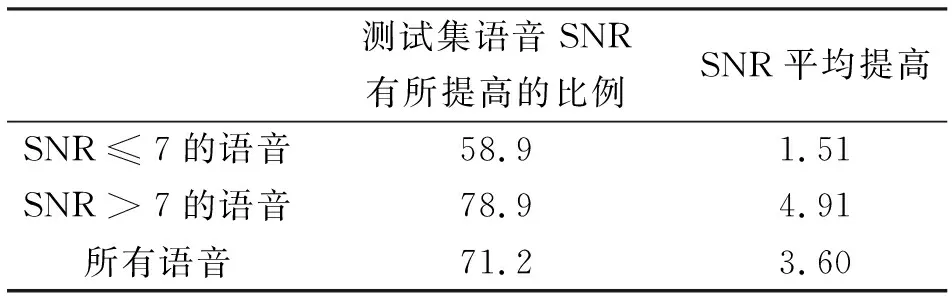
表1 低信噪比、高信噪比和全部语音的去噪效果对比 %
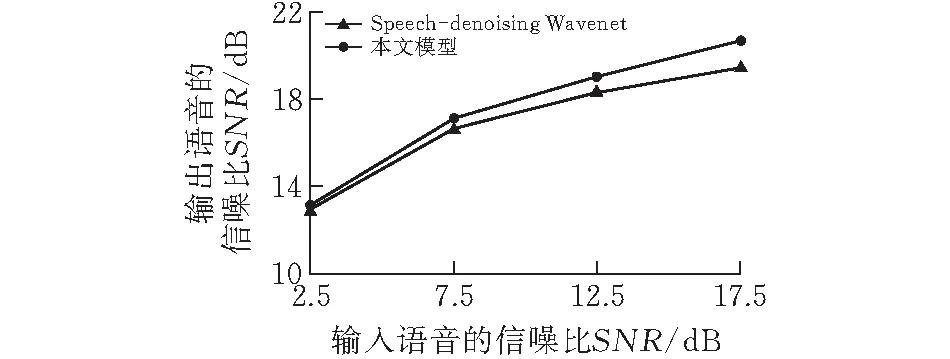
图 3 四种不同信噪比语音的去噪效果对比
从表1和图3中可以看到,本文模型在高SNR下提升更明显,即引入MFCC能显著提升噪音较少情况下的去噪效果。在训练时本文提出的模型大约只需要遍历训练集7次左右,而Speech-denoising Wavenet需要遍历约10次,说明MFCC的加入能加速收敛,节省近30%的训练时间。当然,MFCC的加入也会导致处理速度降低。对测试集的前100条语音进行去噪,平均耗时90 s,和Speech-denoising Wavenet的平均76 s相比增加了18.42%。以上所有实验均使用相同环境,机器配置为NVIDIA GeForce RTX 2070。
图4和图5展示了对测试集中某一段语音去噪前后的第0.43 s到第0.46 s的波形图对比,带噪语音SNR为11.8 dB,使用原模型去噪得到的音频SNR为18.7 dB,而使用本文模型去噪得到的SNR为20.5 dB。
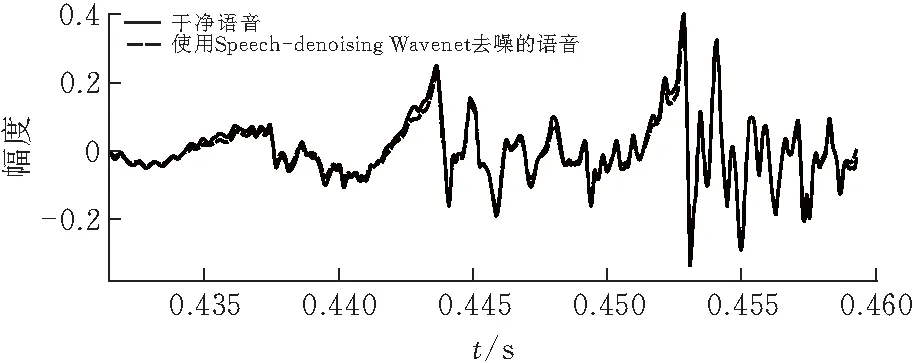
图 4 原模型干净语音与去噪后语音波形图对比
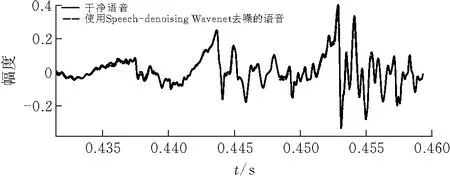
图 5 本文模型干净语音与去噪后语音波形图对比
可以看到本文提出的模型和Speech-denoising Wavenet相比,与干净语音波形图的重叠度更高,即去噪效果更好。
3 结论
本文在阐述Speech-denoising Wavenet网络结构的基础上,提出了一种基于Speech-denoising Wavenet的改进模型,通过加入语音的MFCC特征来提升去噪效果。实验表明,新模型相比原模型去噪效果更好,测试集语音的SNR平均提高3.60%,对于噪音较少的情况提升更明显。尽管计算MFCC会降低18.42%的去噪速度,但该方法可以节省近30%的训练时间。
猜你喜欢
英语学习(2022年9期)2022-10-25
农业工程学报(2022年12期)2022-09-09
英语学习(2022年8期)2022-08-26
现代仪器与医疗(2022年1期)2022-04-19
北京理工大学学报(2021年12期)2022-01-13
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京理工大学学报(2021年8期)2021-09-14
家庭影院技术(2021年1期)2021-03-19
