
融合k均值聚类与LSTM网络的半监督词义消歧
2021-02-21 02:57张春祥周雪松高雪瑶
西安电子科技大学学报 2021年6期
张春祥,周雪松,高雪瑶,刘 欢
(哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080)
提高词义消歧的准确率是自然语言处理中的一个重要课题。通常,使用图来描述词义消歧问题。利用图中的结点来表示词,使用图中的边来表示词之间的关联关系。此时,词义消歧过程将转化为图的求解问题。文献[1-4]使用图的思想,将词汇单元作为图中的结点,利用边来描述上下文语义距离及关系,达到词义消歧的目的。TRIPODI等[5]提出了一种基于进化博弈论的词义消歧模型。利用分布信息来衡量每个单词对其它单词的影响,利用语义相似性来度量不同选择之间的兼容性。ERK等[6]提出了两种新的注释方案,词义相似度(Word Sense SIMilarity,WSSIM)注释和使用相似度(Usage SIMilarity,USIM)注释,在上下文中以分级的方式来描述词义。LOPEZ等[7]描述了一种通过选择歧义词最佳词义来实现特定领域的词义消歧(Word Sense Disambiguation,WSD)方法。文献[8-9]利用Web搜索引擎来获取词典资源,通过计算语义相似度来完成词义消歧任务。目前,神经网络在自然语言处理相关领域有着广泛的应用[10-12]。PESARANGHADER等[13]利用深度学习算法来提取语料中的关键特征,从而确定歧义词汇的语义类别。CALVO等[14]提出了一种不限制固定语料集的深层神经网络词义消歧方法。RUAS等[15]根据歧义词的多种语义和歧义词所在上下文中的特定语义,建立多语义嵌入模型来进行消歧和标注。文献[16-17]利用WordNet和HowNet中的语义注释和语义关系,挖掘了义原之间的深度和密度对语义相似度的影响。唐善成等[18]提出了基于Seq2Seq模型的非受限词义消歧方法。杨安等[19]利用无标注文本构建词向量模型,结合特定领域的关键词信息,提出了一种新的词义消歧方法。通过引入不同的领域知识,证明该方法也可用于其它领域的文本消歧任务。LI等[20]给出了一种基于双向长短期记忆网络的语言模型用于抽取高质量的上下文表示,并将其应用于生物医药领域的词义消歧。
笔者提出了一种结合k均值聚类与长短期记忆网络的半监督词义消歧模型。以歧义词汇为中心,从左右邻接的4个词汇单元中提取词形和语义类作为聚类特征,利用k均值聚类方法对无标注语料进行聚类。将聚类得到的无标注语料添加到SemEval-2007:Task#5的训练语料中,提取词形、词性、语义类、英文译文和消歧距离作为消歧特征,利用长短期记忆网络来确定歧义词汇的正确含义。
1 消歧特征提取
在歧义词汇的上下文中,包含了很多有效的信息,可以用于文本聚类和确定歧义词汇的正确含义。每一个词汇单元都包含了若干种特征。这些特征可以用于文本的加工处理。在歧义词汇的上下文中,主要包括词法、语义和句法等语言学知识。其中,词法知识主要包括词汇的词形和词性。这是一种比较容易获取也比较精确的知识。语义知识主要以语义类和同义词的形式体现。词汇单元的语义知识可以从语义词典中获取。因此,语义知识也是一种比较可靠的语言学信息。句法知识主要描述构成成分之间关联关系。因为现有的句法分析工具的性能较差,所以获取的句法知识不够准确。以歧义词汇为中心,从其左右邻接的4个词汇单元中,提取了5种特征用于无标注语料聚类和词义消歧。
词形:指词的形态。在汉语中,单个字或词语的形态即为词形。
语义类:按照语义关系,可以将词分类。在不同语境中,歧义词汇被划分的语义类有所不同。
词性:指词的特点。汉语共有14种词性,如名词和动词等。在不同的语境下,歧义词汇具有不同的词性。
英文译文:根据语义环境,可将歧义词汇翻译成不同的英语译文。
消歧距离:以歧义词汇为中心,能够计算出其它词汇与歧义词汇之间的距离。距离越远,对歧义词汇的消歧影响就越小。
在特征提取过程中,对汉语句子进行分词、词性标注、语义类标注、译文翻译并计算消歧距离。根据停用词表去掉“了”“的”等无实际意义的词汇,得到了包含各种语言学信息的语料。
以包含歧义词汇“成立”的汉语句子为例,其特征提取过程如下所示:
汉语句子:上月,日本成立了“美林证券公司”
分词结果:上月,日本 成立 了 “美林 证券 公司”
词性标注结果:上月/nt,/wp 日本/ns 成立/v 了/u “/wp 美林/nz 证券/n 公司/n”/wp
语义类标注结果:上月/nt/C,/wp/-1 日本/ns/-1 成立/v/H 了/u/K “/wp/-1 美林/nz/-1 证券/n/-1 公司/n/D”/wp/-1
去停用词结果:上月/nt/C 日本/ns/-1 成立/v/H 美林/nz/-1 证券/n/-1 公司/n/D
如图1所示,以“成立”为中心,选取其左侧第二个词汇单元UL2=“上月”;左侧第一个词汇单元UL1=“日本”;右侧第一个词汇单元UR1=“美林”;右侧第二个词汇单元UR2=“证券”。

图1 特征提取过程
2 半监督词义消歧模型
笔者提出了一种半监督词义消歧方法,包括无标注语料聚类和词义消歧两个部分。消歧框架如图2所示。以歧义词汇w为中心,选取其左右各两个词汇单元,提取词形和语义类作为聚类特征。利用word2vec工具将聚类特征转换为二进制数。得到包含歧义词汇w的有标注聚类特征向量集合SCY和无标注聚类特征向量集合SCN。对于任意f∈SCY或f∈SCY,有f=(WL2,SL2,WL1,SL1,WR1,SR1,WR2,SR2)。
当数据规模较大时,k均值聚类方法保持了很好的可伸缩性和高效性。因此,以SCY为基础利用k均值聚类方法对SCN进行聚类。假设歧义词汇w有n个语义类S1,S2,…,Sn。在SCY中随机选取n个聚类中心Ci(i=1,2,…,n)。使用词形和语义类作为聚类特征,各个聚类特征彼此独立,不存在关联关系。因此,使用欧氏距离来度量两个特征向量之间的距离。对于任意无标注聚类实例f∈SCN,计算f到聚类中心Ck(k=1,2,…,n)的距离:
(1)
其中,|fj-Ck,j|为向量fj与Ck,j之间的欧氏距离。
计算f到n个聚类中心的最小距离dmin:
(2)
利用式(3)选出与f距离最小的第t个聚类中心:
(3)
若dmin<δ,则f的语义类别置为St,否则,f仍然是无标注聚类实例。其中,δ为设定的阈值。迭代上述过程,直到聚类中心不再发生变化或达到最大迭代次数为止。
在确定歧义词汇w语义类的过程中,提取w的消歧特征。利用word2vec工具将消歧特征转换为二进制数,得到消歧特征向量集合SWSD。对于任意f∈SWSD,有f=(WL2,SL2,PL2,TL2,GL2,WL1,SL1,PL1,TL1,GL1,WR1,SR1,PR1,TR1,GR1,WR2,SR2,PR2,TR2,GR2)。
将SWSD输入长短期记忆网络进行词义消歧。长短期记忆网络分为输入层、隐藏层和输出层。对于消歧实例f∈SWSD,输入层结点首先接受左侧第二个词汇单元的特征向量(WL2,SL2,PL2,TL2,GL2),并将其送入对应的隐藏层结点进行计算。隐藏层结点计算完毕后,将计算结果送入对应的输出层结点。输出层结点调用softmax函数,计算语义类分布向量O1。重复上述过程,直到输入层结点接受右侧第二个词汇单元的特征向量(WR2,SR2,PR2,TR2,GR2)进行计算,输出层结点输出最终语义类分布向量O4。
在图2中,U表示输入层结点与隐藏层结点之间的连接权值矩阵;D表示相邻两个隐藏层结点之间的连接权值矩阵;V表示隐藏层结点与输出层结点之间的连接权值矩阵。矩阵U、D和V是长短期记忆网络模型的训练参数。在开始训练之前,将矩阵U、D和V随机初始化为很小的数值。
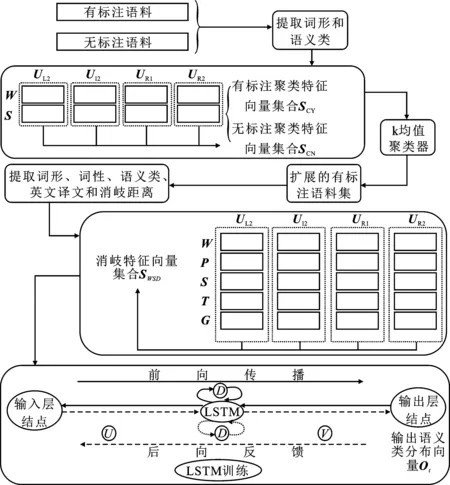
图2 半监督词义消歧框架
3 基于k均值聚类的无标注语料聚类
以有标注语料为基础,利用k均值聚类方法对无标注语料进行聚类,聚类过程如下所示。
输入:包含歧义词汇w的有标注聚类特征向量集合SCY=L1∪L2∪…∪Ln(Li为语义类为Si的有标注聚类特征向量集合,且La∩Lb=Ø,a≠b);包含歧义词汇w的无标注聚类特征向量集合SCN;聚类类别数n;阈值δ。
输出:聚类后的有标注聚类特征向量集合SCY。
(Ⅰ)初始化
从Li中随机选取一个特征向量作为Li的初始聚类中心Ci(i=1,2,…,n),初始化最大迭代次数T。
(Ⅱ)循环迭代聚类
fort=1,2,…,T{
(1)while(SCN≠Ø){
① 任选f∈SCN,利用式(2)计算f到n个聚类中心的最小距离dmin
② 利用公式(3)选出与f距离最小的第t个聚类
③ if(dmin<δ){
a.f的语义类别置为St;
b.SCN=SCN-{f};
c.Lt=Lt∪{f};
}
}
(2)利用式(4)计算更新聚类中心之前的向量与中心距离的累计Jbefore:
(4)
(3)利用式(5)更新聚类中心Ci(i=1,2,…,n):
(5)
(4)利用式(6)计算更新聚类中心之后的向量与中心距离的累计Jafter:
(6)
(5)利用式(7)计算两次迭代之间的误差ΔJ:
ΔJ=Jbefore-Jafter。
(7)
(6)if(|ΔJ|<δ)
输出SCY=L1∪L2∪…∪Ln;break
}
(Ⅲ)if(达到最大迭代次数T)
输出SCY=L1∪L2∪…∪Ln。
4 长短期记忆网络的训练
长短期记忆网络是一种基于时间维度的模型,其隐藏层可以在时间维度上展开。将长短期记忆网络的隐藏层层数设置为2。以包含歧义词汇“成立”的消歧实例为例,展开后的长短期记忆网络模型如图3所示。
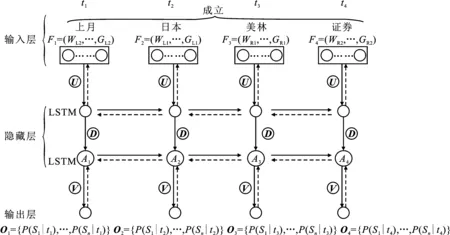
图3 长短期记忆网络网络隐藏层展开图
图3中,每个长短期记忆网络细胞都具有3个门:遗忘门、输入门和输出门,具体结构如图4所示。

图4 长短期记忆网络的细胞结构
长短期记忆网络的训练过程分为前向传播过程和后向反馈过程。具体训练过程如下所示。
4.1 前向传播过程
在前向传播过程中,根据t时刻所接受的特征向量Ft和t-1时刻的隐藏层结点状态At-1来计算t时刻的语义类概率分布向量Ot。具体步骤如下:
输入:歧义词汇w的消歧特征向量集合SWSD,隐藏层数m=2。
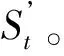
(Ⅰ)将f=(WL2,SL2,PL2,TL2,GL2,WL1,SL1,PL1,TL1,GL1,WR1,SR1,PR1,TR1,GR1,WR2,SR2,PR2,TR2,GR2)的子向量分别赋值给时序向量,f∈SWSD;
F1=(WL2,SL2,PL2,TL2,GL2);F2=(WL1,SL1,PL1,TL1,GL1)F3=(WR1,SR1,PR1,TR1,GR1);F4=(WR2,SR2,PR2,TR2,GR2)
(Ⅱ)初始化隐藏层结点,状态为A0,输出门为h0;
(Ⅲ)输入层结点将时序向量Ft(t=1,2,3,4)送入隐藏层进行计算:
for(t=1;t≤4;t++){
(1)for(n=1;n≤m;n++){
① 遗忘门计算需要保留的有效信息ft,如式(8)所示:
ft=sig mod(U·[ht-1,Ft]+bf) ,
(8)
其中,ht-1为t-1时刻隐藏层结点输出门的输出,bf为偏移向量。
② 输入门接受有效信息ft,进行以下运算:
a.计算t时刻隐藏层结点需要接受的新信息it:
it=sig mod(U·[ht-1,Ft]+bi) ,
(9)
其中,bi为偏移向量。

(10)
其中,bc为偏移向量。
c.更新t时刻隐藏层结点的状态,如式(11)所示:
(11)
③ 输出门计算t时刻隐藏层结点需要遗忘的信息ht,如式(12)和式(13)所示:
ot=sig mod(U·[ht-1,Ft]+bo) ,
(12)
ht=ottanh(At) ,
(13)
其中,bo为偏移向量。
④At进入下一邻接层。
}
(2)计算t时刻输出层结点的语义类概率分布向量Ot:
(14)
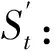
(15)

}
4.2 反向传播过程

(16)
(17)
(3)更新权值矩阵θ={U,V,D}:
(18)
(19)
(4)循环执行步骤(1)~(3)来更新参数θ。如果参数θ收敛,那么长短期记忆网络训练结束。
5 实 验
5.1 隐藏层数对词义消歧的影响
长短期记忆网络隐藏层的层数将直接影响到模型训练的效果。为了探究隐藏层数对消歧正确率的影响,此处共进行了3组对比实验。采用SemEval-2007:Task#5的训练语料和测试语料来进行实验。选取2类歧义词汇16个,3类歧义词汇10个,4类歧义词汇3个。训练语料和测试语料的分布情况如图5所示。
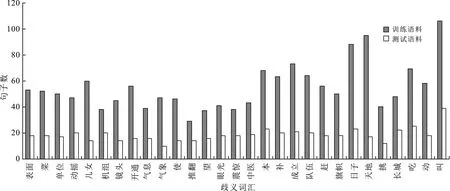
图5 训练语料和测试语料的分布
隐藏层数分别设置为2层、3层和4层。采用SemEval-2007提供的评测指标平均消歧准确率(macro average accuracy)对实验结果进行评测,其计算过程如式(20)所示:
(20)
pi=mi/ni,
(21)
其中,N为所有歧义词汇的数目;mi是第i个歧义词汇正确分类的测试句子数;ni是包含第i个歧义词的所有测试句子数;pi为第i个歧义词的消歧准确率;pmar为词义消歧的平均准确率。
测试语料的消歧准确率如表1所示。由表1可以发现,随着隐藏层数增加,许多歧义词汇的消歧准确率降低,部分歧义词汇的消歧准确率上升,平均消歧准确率下降。当隐藏层数为2时,平均消歧准确率最高。
根据表1可以计算出在隐藏层数分别为2、3、4层时,二类、三类和四类歧义词汇的平均消歧准确率,如图6所示。

表1 不同隐藏层下的消歧准确率

图6 不同类别和隐藏层数下的平均消歧准确率
从图6中可以发现,当歧义词汇的语义类为二类或三类且隐藏层层数为2时,平均消歧准确率较高。当歧义词汇的语义类为四类且隐藏层的层数为3时,平均消歧准确率较高。长短期记忆网络根据当前时刻所接受的特征向量和上一时刻隐藏层结点的状态来计算当前时刻的语义类概率分布。语义类概率分布的计算是一个多次迭代的过程。对二类和三类歧义词汇而言,其分类过程比较简单。2层长短期记忆网络的分类效果最好。如果层数增多,那么迭代次数变大,会出现过拟合现象。此时,分类准确率将下降。当歧义词汇的语义类别数比较大时,使用2层长短期记忆网络不能进行准确的消歧,需要增加长短期记忆网络的层数,加大迭代次数来提高消歧准确率。对四类歧义词汇而言,3层长短期记忆网络的消歧性能最好。当长短期记忆网络的层数再继续增大时,消歧准确率反而下降。
结合表1和图6可知,设置恰当的隐藏层数可以提高词义消歧的准确率。通过对比,将隐藏层数设置为2。
5.2 训练语料规模对消歧准确率的影响
在k均值聚类算法中,阈值δ为0.000 001,最大迭代次数T=50。为了探究训练语料的规模对词义消歧的影响,将聚类得到的无标注语料按20%、40%、60%、80%和100%的比例添加到SemEval-2007:Task#5的训练语料之中。分别对长短期记忆网络进行训练。用优化后的长短期记忆网络分别对SemEval-2007:Task#5的测试语料进行词义消歧,消歧准确率如表2所示。
从表2可以发现,在加入经过聚类的无标注语料之后,除了部分歧义词汇之外,大多数歧义词汇的消歧准确率都有所提升。其原因是:在无标注语料的聚类过程中会产生一些噪声,降低了词义消歧准确率。聚类后的无标注语料会为词义消歧过程提供更多的语言学知识。因此,大多数歧义词汇的平均消歧准确率有所提高。由此可知,训练语料的规模对词义消歧性能具有一定影响。

表2 训练语料规模对词义消歧的影响
5.3 与贝叶斯分类器和深度信念网络的对比实验
为了度量所提出方法的性能,共进行了3组对比实验。
实验1选取歧义词汇左右两个词汇单元的词形、词性和语义类作为消歧特征,使用贝叶斯分类器作为词义消歧模型。使用SemEval-2007:Task#5的训练语料来优化贝叶斯分类器。使用优化后的贝叶斯分类器对SemEval-2007:Task#5的测试语料进行消歧。
实验2选取歧义词汇左右两个词汇单元的词形、词性和语义类作为消歧特征,使用深度信念网络作为词义消歧模型。利用SemEval-2007:Task#5的训练语料来优化深度信念网络。使用优化后的深度信念网络对SemEval-2007:Task#5的测试语料进行消歧。
实验3将聚类得到的无标注语料添加到SemEval-2007:Task#5的训练语料中用于优化长短期记忆网络。使用优化后的长短期记忆网络对SemEval-2007:Task#5的测试语料进行消歧。
测试语料的消歧准确率如表3所示。
从表3可以看出,实验3的平均准确率要高于实验1和实验2。其原因是在深度信念网络消歧模型和贝叶斯分类器中,仅采用了歧义词汇左右两个词汇单元的词形、词性和语义类作为消歧特征。在所提出方法中,采用了歧义词汇左右两个词汇单元的词形、词性、语义类、英语译文和消歧距离作为消歧特征,具有更强的语言现象覆盖能力和判别消歧能力。此外,所提出的方法是以SemEval-2007:Task#5的训练语料为基础,使用k均值聚类方法对大量无标注语料进行聚类来优化长短期记忆网络。从而使长短期记忆网络具有更好的词义消歧性能,能够覆盖更多的语言学现象。在对比实验中,仅使用SemEval-2007:Task#5的训练语料来优化深度信念网络和贝叶斯分类器。实验2的平均准确率要高于实验1的,其原因是深度信念网络的消歧性能要好于贝叶斯分类器。由此可知,所提出的方法更适合于词义消歧问题。

表3 测试语料的消歧准确率
6 总 结
选取歧义词汇左右邻接的4个词汇单元的词形和语义类作为聚类特征,利用k均值聚类方法对无标注语料聚类。将聚类得到的无标注语料添加到有标注语料中。提取歧义词汇左右邻接的4个词汇单元的词形、词性、语义类、英文译文和消歧距离作为消歧特征来优化长短期记忆网络。实验结果表明,相对于贝叶斯分类器和深度信念网络而言,所提出方法的平均消歧准确率有所提升。
猜你喜欢
电子制作(2022年1期)2022-01-28
现代计算机(2021年33期)2022-01-21
电子制作(2021年14期)2021-08-21
暨南学报(哲学社会科学版)(2020年5期)2020-05-15
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
中国外汇(2019年12期)2019-10-10
语文教学与研究(综合天地)(2018年10期)2018-12-24
校园英语·下旬(2016年3期)2016-04-18
教学与管理(理论版)(2009年9期)2009-11-04
