
双轮铣槽机工作地层识别研究
2021-02-18 01:22:06涂同珩朱明清程茂林
中国工程机械学报 2021年6期
涂同珩,朱明清,程茂林
(中交第二航务工程局有限公司技术中心,湖北 武汉 430040)
双轮铣槽机是一种大型桩工机械设备,主要应用于地下连续墙的成槽施工,该设备能适用于多种地层的开挖,其开挖效率比传统地连墙施工中所用的液压抓斗、冲击循环钻等成槽施工设备高出数倍,同时,其施工精度高、可成槽深度大。因此,该设备对于成槽深度大、垂直度要求高以及岩层抗压强度较大的地连墙工程的施工具有突出优势[1]。
BC40 双轮铣槽机通过2 个铣轮向内转动对岩土体进行铣削破碎,铣削产生的碎渣混合在泥浆中通过中间的泥浆泵输送到槽外。该设备数字化程度高,自身安装有多部传感器,并通过设备终端实时显示关键施工数据[2]。
在成槽深度较大的工程施工中,铣槽机会穿越多种地层,需要机手根据地层的差异对设备进行调整,甚至还需要针对某些地层更换特定齿具。因此,在大型地连墙施工过程中,探明铣槽机的工作地层对提升成槽效率和质量十分重要。
在铣槽机施工前,施工人员一般会根据地勘资料对成槽断面的地层分布进行大致分析。地质勘探可以得到探孔地质情况的准确信息,但探孔通常分布稀疏,大多数成槽部位与探孔相隔甚远,依赖地勘资料分析得到的地连墙槽段地层信息和实际情况往往存在较大差异。
在铣削过程中,铣槽机会实时显示铣轮转速、驱动马达液压油压力、钢丝绳牵引力等数据,不难推想,铣槽机工作地层的变化会影响到这些设备参数,如果这种影响足够明显,那这些设备参数的变化也许能反映铣槽机工作的地层的变化。本文将对采集到的铣槽机施工数据进行分析,通过多种数据处理和有监督学习方法,对铣槽机工作地层的识别进行系统研究,旨在得到一种能根据铣槽机施工数据对工作地层进行识别的预测模型,实现对铣槽机工作地层的实时识别,为工程计量、设备状态调节,甚至设备智能辅助决策提供依据。
本文以南京仙新路过江通道南锚碇地连墙工程为背景,研究该工程中双轮铣槽机的工作地层识别方法。该项目地连墙深约60 m,壁厚1.5 m,基础规模大,施工难度高。成槽部位自上而下地层分布有杂填土、淤泥质粉质黏土、粉质黏土、强风化砾岩、中风化砾岩、微风化砾岩等。
如图1 所示,该工程地勘探孔分布较为稀疏,绝大部分槽段与探孔相距较远,对施工人员掌握槽段地层分布十分不利。探孔均不在地连墙成槽范围内,意味着数据样本的地层标记会有一定的误差,要求训练模型要具备较强的鲁棒性。该项目具有一定代表性,可以丰富铣槽机工作地层识别方法的研究层次与深度。

图1 南京仙新路过江通道南锚碇地连墙地勘探孔分布Fig.1 Exploration holes floor plan of the diaphragm wall in the south anchorage of Nanjing Xianxin Road Bridge
1 铣槽机数据分析
铣槽机施工数据采样频率为1 Hz,采集数据包括左右轮液压油压力、转速、进给速度、附加载荷等22项参数。
1.1 地层标记
地连墙开挖槽段与项目地勘探孔接近的区域较少,且没有一处重叠区域,直接根据地勘资料对地层进行标记必然存在较大误差。为尽可能提高地层标记的精度,本文仅选取了距离地勘探孔最近的槽段进行标记,并且将地勘资料中地层交界处上下深度0.5 m范围内的样本剔除。
根据地勘资料,槽段入岩部分为强风化砾岩、中风化砾岩和微风化砾岩,岩层以上的地层包括杂填土、淤泥质粉质黏土、粉质黏土等。对铣槽机施工而言,岩层以上的地层相对岩层开挖较为容易,设备调整难度低[3],因此,本文将岩层以上部分统一标记为覆盖层。
1.2 特征选择
铣槽机各类数据具有实际物理意义,其中,有部分数据不适合作为地层识别的特征。
不同区域的地层深度分布情况存在差异,因此与深度相关的数据属于无关特征。齿轮箱油压用于和外部环境水压保持平衡,此2 类特征值变化趋势几乎相同。据分析,此2 类特征与深度近似成线性关系,因此,左齿轮箱油压、右齿轮箱油压、环境压力都属于无关特征。
齿轮箱温度与环境温度、齿轮速度、润滑情况等多种因素有关,其分布特性与地层关联程度低,方位数据与地层无关,这些参数都被作为无关特征弃用。
1.3 特征分析
本文利用Orange3 数据可视化平台对铣槽机样本数据进行分析。图2所示为4类地层样本的二维特征分布图,图中的坐标轴变量是经过可预测性分析选出的分离度最高的1 组二维特征。可以看出,覆盖层样本与其他3 类岩层样本之间界限较为明显,而3 类风化程度不同的岩层样本存在大量重叠。说明覆盖层与岩层样本的二分类比较容易,而岩层分类难度较大。

图2 4地层样本二维特征分布Fig.2 Two-dimensional feature distribution of samples from four types of stratum
利用Free Viz 模块对强风化、中风化、微风化岩层多维特征进行分析,如图3 所示,3 类岩层样本的多维特征依然存在大量重叠,尤其是中风化岩层。其样本分布几乎与另外2 类岩层全部重叠。归一化后计算样本类内距离Sw为9.703,类间距离Sb为1.314,Sw比Sb大得多,可分性较差。

图3 岩层样本特征多维分布Fig.3 Multi-dimensional feature distribution of samples from rock stratum
2 预处理分析
2.1 数据集划分
预处理之前划分训练集和测试集。在实际施工过程中,各槽段一般是分开成槽的,因此测试集与训练集应取不同槽段数据。本文为贴近工程实际,在与地勘探孔最接近的几个槽段中选取了部分槽段的样本作为训练集,其他槽段样本作为测试集。为减少样本不均衡带来的影响,训练集和测试集中各地层样本数量相同。
2.2 平滑处理
图4 为某槽段左轮转速的部分时间序列,该槽段左轮转速方差为2.711,可以看出曲线呈现剧烈波动,除了转速,铣槽机数据中还有许多特征都存在明显波动,这种波动可能会严重影响地层识别效果。

图4 左轮转速时间序列Fig.4 Time series of left wheel rotating speed
2.2.1 移动平均滤波
移动平均(Moving Average,MA)是在指定时间段内,对时间序列取平均值,移动平均滤波可以减少时间序列的变动,减少信号噪声,使数据更平滑。移动平均包括简单移动平均、加权移动平均和指数移动平均等,本文采用5 期简单移动平均,其数值计算式如下:

式中:MA(n)t为时间序列t时刻的n期移动平均数;yt-i为时间序列t-i时刻的值。
2.2.2 时间序列矩阵
各类特征的变动可能有其内部规律,将各类特征在一段时间内的时间序列组成时间序列矩阵,也许可以提升地层识别效果。本节取11 类特征的近5期特征值组成11×5特征矩阵。
2.2.3 处理方法对比
本节采用随机森林分类器对移动平均滤波和时间序列特征矩阵两种处理方法得到的样本数据进行对比识别。随机森林是一种集成学习方法,其内部包括多个决策树,每个决策树对样本进行随机抽样,各自独立学习,对于每个决策树的识别结果以投票形式得到随机森林的预测结果。该方法可集成大量决策树,适用分类场景广泛[4]。
本节对比了几种平滑处理方法下随机森林的识别效果。由于覆盖层样本特征分布与3 类岩层样本明显不同,3类岩层的识别难度更大,因此仅测试对3类岩层的识别效果。如表1所示,5期移动平均相对于无平滑处理的方法对3 类岩层的识别正确率提高17.7个百分点,而以时间序列矩阵作为特征的模型正确率仅提高2.55 个百分点,此外,无平滑处理的随机森林模型识别正确率极低,说明样本特征值的剧烈变动严重影响了地层识别效果。
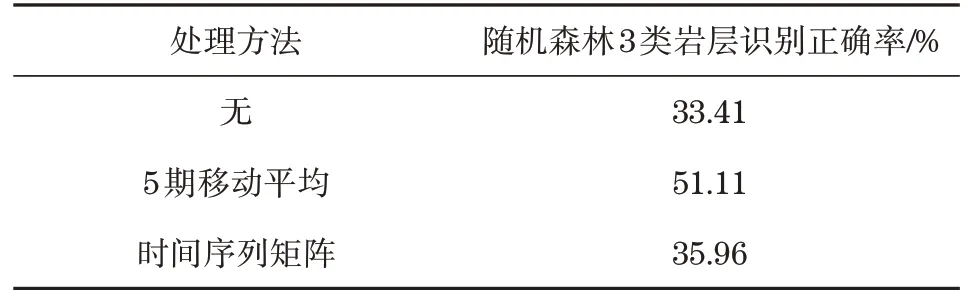
表1 平滑处理方法效果对比Tab.1 Effects of smoothing methods
2.3 离群点检测
离群点是指在同一场景的样本数据中,极端远离样本一般分布区域的样本,具体到特征,则反映为离群点特征值极端偏离特征值的期望或中位数,这在盒须图中能得到直观反映[5]。
以如图5 盒须图所示的特征为例,样本左液压油压力极端值偏离上下四分位较远,除了液压油压力,还有很多特征存在类似分布特点,样本应进行离群点检测过滤。

图5 各地层左液压油压力分布Fig.5 Distribution of left hydraulic oil pressure in each stratum
本文采用单分类支持向量机(One Class SVM)对样本进行离群点检测,One Class SVM 的基本思想是在样本特征映射的高维空间寻找1 个超球面,超球面尽可能多地包裹样本,同时球面半径尽可能小,球面外的样本就被检测为离群点。
一般在实际的样本识别中,待测样本都是实时产生的,因此,本文仅对训练集进行离群点检测过滤,然后在过滤后的训练集上训练分类器,对测试集直接测试。
为了测试离群点过滤对地层识别的影响,采用上节中表现最优的5 期移动平均预处理方法和随机森林分类器,分别在未经过离群点过滤和经过离群点过滤的训练集上训练识别模型。模型测试效果如表2 所示,One Class SVM 离群点检测有效提高了模型在3类岩层上的识别正确率。

表2 离群点过滤效果Tab.2 Outlier filtering effect
3 地层分类
本文确定了移动平均滤波和离群点过滤的数据预处理方法,在基础的随机森林分类器上测试的岩层识别正确率为57.69%,这种性能显然是不能满足需求的,因此对于分类器的设计还需要更深入的研究。
本文在地层特征分布特性的研究中,发现覆盖层样本特征相较于3 类岩层具有突出的分布特性,这说明覆盖层样本具有很好的可分性,并且覆盖层与3 种风化层程度不同的岩层的样本训练过程会有明显差别,因此本文先对3 类岩层进行分类研究,再研究覆盖层的分类。
3.1 3类岩层的分类
岩层样本特征分布较为复杂,3 种风化程度的样本重叠程度很高,因此,除了随机森林,本文还研究了其他多种分类方法,旨在尽可能提高地层识别的表现。
3.1.1 降噪自动编码器
降噪自动编码器(Denoising Autoencoder,DAE)是一种深度学习模型,网络结构分为输入层、隐含层和输出层,如图6所示。DAE 通过对输入特征随机置零的方式加入人工噪声,并对其编码成隐含层,再对隐含层译码得到输出层,通过迭代不断减小输出层与输入层的重构误差来训练模型[6]。经测试优化,确定了如表3所示的训练参数。

图6 DAE训练过程Fig.6 Training process of DAE model

表3 DAE主要训练参数Tab.3 Main training parameters of DAE
本文训练DAE 模型,得到样本的隐含层特征,再利用简单的神经网络分类器对DAE 隐含层特征进行分类。
3.1.2 基于树结构的机器学习管道优化工具
基于树结构的机器学习管道优化工具(Treebased Pipeline Optimization Tool,TPOT)是一种能自动优化模型集成结构和超参数的自动机器学习工具,旨在面对多种应用场景时,替代繁琐的人工模型设计和参数调优过程,自动提供机器学习解决方案。该工具采用树形结构实现学习模型的集成,作为树结构的节点,模型之间可以并联、级联,节点模型的选择、树结构的优化和模型超参数的优化则通过遗传编程实现[7]。TPOT 遗传编程参数设置如表4所示。

表4 遗传编程参数Tab.4 Parameters of genetic programming
3.1.3 支持向量机
支持向量机(Support Vector Machine,SVM)是一种二分类模型,其基本思想是在特征空间中找到一个能将两类样本分隔开的超平面,并且使得超平面与样本距离最大化[8]。在原始特征空间中,样本往往线性不可分,因此,SVM 通过核函数将特征映射到高维空间。理论上,在足够高维的空间,是一定能找到这样的超平面的。
为了满足多分类场景,需要建立集成SVM 学习模型,本文采用一对一SVM模型。
经测试优化,本文选择多项式核函数对特征进行高维映射:

3.1.4 测试结果对比
分别采用以上3种分类方法对3种风化地层进行分类,在测试集上的识别正确率如表5 所示。可以看出,多项式核函数SVM 分类正确率最高,达到78.30%,而其中强风化和微风化岩层的分类正确率在90.00%左右,精度损失主要来自中风化岩层样本,这和前文所述中风化岩层样本重叠程度最高的分析是相符的。

表5 3类岩层分类测试结果Tab.5 Classification test results of three types of rock stratum
3.2 覆盖层分类
3.2.1 4地层直接分类
4 地层直接分类的思路很简单,就是在3 类岩层样本分类的基础上,加入同样比例的覆盖层样本,采用同样的预处理和分类方法。在3 类地层的分类研究中,SVM 和DAE 方法的分类正确率较高,因此,这里同样采用这2种方法。
如表 6 所示,不论是 DAE 还是 SVM,对 4 地层的分类效果都很差。理论上,覆盖层分类精度应高于3 类岩层,则加入覆盖层样本的分类结果应好于3 类地层分类,而这一结果反映了差异性较大的覆盖层样本对4地层分类造成了一定的干扰。

表6 4地层直接分类测试结果Tab.6 Direct classification test results of four types of stratum
3.2.2 覆盖层与岩层的二分类
由于4 地层直接分类的效果较差,本文将3 类岩层作为同一地层,与覆盖层样本一起进行二分类。为了避免样本不均衡带来的影响,本文将3 类岩层样本均等抽样,使岩层样本总数与覆盖层一致。分别采取了DAE、SVM、TPOT 对覆盖层和岩层样本进行分类,在测试集上的分类结果如表7所示。

表7 覆盖层与岩层二分类测试结果Tab.7 Binary classification test results of cover stratum and rock stratum
从结果中可以看出,3 种方法的识别正确率都高于90.00%,这与特征分析中覆盖层样本特征可分性好的特点相符。TPOT 生成的学习管道识别正确率最高,该管道包含1 个节点分类器:梯度提升决策树。
最后,本文利用以上研究成果对某槽段铣槽机施工完整数据进行预处理,并开展两级分类测试。首先利用梯度提升决策树模型分出覆盖层和岩层,然后通过多项式SVM 模型对识别为岩层的样本进行风化程度识别,识别结果如表8混淆矩阵所示。

表8 4地层分类混淆矩阵Tab.8 Classification confusion matrix of four types of stratum
从混淆矩阵可以看出,误差主要来自中风化砾岩的漏检,覆盖层漏检率和误检率都比较低,强风化砾岩和微风化砾岩识别灵敏度较好,且此2 类地层的误检主要来自中风化砾岩样本。从地质特性上来说,中风化砾岩力学特性介于强风化砾岩和微风化砾岩之间,该地层部分样本的漏检说明这些样本与被识别的地层相似性较高,因此,中风化砾岩的漏检和误检对铣槽机依据预测地层进行设备调整的效果影响有限。
4 结语
双轮铣槽机是一种可适用于多种软硬地层的先进成槽设备,其设备调整状态与地层的适应程度对成槽效率影响较大,因此,地层信息的掌握对铣槽机施工效率的提升非常重要。本文针对铣槽机提升功效的需求和地层信息难以掌握的问题,依托南京仙新路过江通道南锚碇地连墙工程,对双轮铣槽机工作地层识别方法进行了研究。首先结合地勘资料和地勘探孔分布特点对槽段地层进行分析,并通过铣槽机施工数据分析出各地层特征分布特点。然后针对样本特征时间序列变动剧烈和极端值偏离的特点,分别采用了几种平滑处理和离群点检测方法,并通过随机森林对几种方法的效果进行对比分析。最后对地层分类器进行研究,分别研究了降噪自编码器、TPOT 和SVM 在岩层样本数据上的训练和识别,并在岩层分类的基础上研究包含覆盖层样本的4 地层分类方法。从对实际完整槽段数据的识别结果可以看出,除中风化砾岩漏检和误检较明显外,总体识别正确率较高。
猜你喜欢
疯狂英语·读写版(2023年12期)2023-02-20 18:41:06
商品与质量(2021年43期)2022-01-18 05:28:30
铁道建筑技术(2021年3期)2021-07-21 08:29:54
舰船科学技术(2021年12期)2021-03-29 01:28:40
少儿美术(快乐历史地理)(2020年2期)2020-06-22 08:18:30
震灾防御技术(2019年3期)2019-06-02 08:25:14
中国港湾建设(2017年11期)2017-12-19 12:27:09
中国房地产业(2016年9期)2016-03-01 01:26:47
作文评点报·低幼版(2015年5期)2015-05-30 10:48:04
西安交通大学学报(2014年8期)2014-04-16 05:07:06
