
资源描述标准的国际最新进展及对我国资源描述工作的影响
2021-02-14 03:52宋文
数字图书馆论坛 2021年11期
宋文
(1. 中国科学院文献情报中心,北京 100190;2. 中国科学院大学,北京 100049)
20世纪90年代开始,随着数字资源的发展,国际编目界开始对延续了半个世纪的国际编目规则进行系统性的反思和研究,其标志性的研究成果是1998年国际图书馆协会联合会(International Federation of Library Associations and Institutions,IFLA)发布的《书目记录的功能需求》(Functional Requirements for Bibliographic Records,FRBR)。随着2010年《资源描述与检索》(Resource Description and Access,RDA)和2011年《国际标准书目著录(统一版)》(International Standard Bibliographic Description.Consolidated Edition,ISBD统一版)的发布,文献编目领域酝酿已久的翻天覆地的变化开始显露。从文献著录向全资源谱系的资源描述,从书目数据的MARC格式向基于RDF资源描述框架和W3C知识表示语言的关联数据及语义描述发展,是国际资源描述领域当前正在实施和努力推进的工作。
1 资源描述标准的国际发展概述
在图书馆的传统上,把资源描述称为编目或著录,把资源描述标准称为编目标准、编目条例、编目规则或著录规则。国际编目标准发展大致经历了3个阶段:编目规则的萌芽阶段(19世纪40年代至20世纪50年代)、国际编目标准的形成和自动化阶段(20世纪60年代至90年代)、数字化和语义化的资源描述阶段(20世纪90年代末至今)。
1.1 编目规则的萌芽阶段
虽然最早的图书馆目录可以追溯到公元前7世纪的美索不达米亚的图书馆目录[1],但真正意义上的编目规则出现在1841年。
1841年,大英博物馆图书馆部(the British Museum Library),大英图书馆(the British Library)的前身[2],制定了国际上第一个编目规则《目录编辑规则》(Rules for the Compilation of the Catalogue)[3],该编目规则制定了91条建立图书馆目录的规则,因此它又称为“91 Rules”[4]。
1883年美国图书馆学会(American Library Association,ALA)发布了《简明著者和题名目录规则》(Condensed Rules for an Author and Title Catalog)[5]。1893年英国图书馆学会(Library Association,LA)对“91 Rules”进行修订,发布了《大英博物馆、博德利图书馆、英国图书馆学会编目规则》(Cataloguing Rules of the British Museum,of the Bodleian Library,of the LibraryAssociation)。
随着1901年美国国会图书馆发行卡片目录,对统一编目规则的呼声越来越强烈。美国图书馆学会与英国图书馆学会合作,协调两国的编目规则,于1908年制定了第一个国际性的编目规则《编目规则:著者和题名款目》(Catalog Rules:Author and Title Entries)。该规则分北美版(American Edition)和大英版(British Edition),两个版本的内容基本一致[6]。该编目规则很快被美国和英国及其他英语国家的图书馆采纳。
1.2 国际编目标准的形成和自动化阶段
1.2.1 国际编目规则的标准化
《编目规则:著者和题名款目》主要被英语国家所采纳,它还不是一个国际著录标准。随着20世纪开始集中化的书目服务网络的增长,以及各国家图书馆之间书目交换的发展,催生了国际统一编目规则的发展。
IFLA在1961年召开国际编目专家会议,会议采纳了美国编目专家Seymour Lubetzky向大会提出的工作报告和他的“不仅要有规则,而且要有原则”的指导思想。会议制订并通过了“原则声明”(《巴黎原则声明》),该声明包括:目录的职能和结构;款目的种类、使用和功能;统一题名;著者标目、书名标目;个人名称的款目词等,从而形成一个完整的编目原则体系。《巴黎原则声明》成为各国制定编目规则的一致遵守的基本原则。从那时起,世界范围内发展的大多数编目规则严格或至少在很大程度上遵守了这些原则[7]。《巴黎原则声明》为建立统一的国际编目标准奠定了基础。
在《巴黎原则声明》基础上,美国图书馆学会和英国图书馆学会以及美国国会图书馆、加拿大图书馆合作制定了Anglo-American Cataloguing Rules(AACR),即《英美编目条例》第一版。AACR于1967年正式出版[8],仍然分为北美版和大英版。
1967年AACR出版后,IFLA编目委员会于1969年在哥本哈根组织了一次国际编目专家会议。这导致了ISBD的发展。ISBD是实现国际统一书目控制的里程碑事件。ISBD专著著录规则ISBD(M)发布于1974年,标志着书目著录规则走向国际标准化的开始。随后,IFLA编目委员会又陆续制定了ISBD(G)、ISBD(CM)、ISBD(ER)等8个系列的国际标准书目著录规则。
1974年3月,美国图书馆学会在芝加哥总部举行了一次三国会议,由英美编目条例的3个制定国家各派一名代表参加。会议成立了AACR联合修订委员会(Joint Steering Committee for Revision of AACR,JSC),并完成AACR第二版项目的规划[9]。1978年AACR2第一版正式出版。
《巴黎原则声明》、ISBDs和AACR2是编目领域的里程碑事件,这些国际编目标准主导国际标准的书目著录和书目数据交换长达半个世纪之久。
1.2.2 计算机可读目录的发展
书目数据的标准化,为机读目录的发展提供了基础保障。机读目录的发展又对书目数据的标准化提出了更高的要求。
20世纪60年代,计算机应用开始进入图书馆领域。1965—1966年,美国国会图书馆启动计算机可读目录(Machine-Readable Cataloging,MARC)试点项目MARC pilot project[10]。该项目的成果是全球第一个机读目录格式MARC I,经过改进后称为MARC II。因为MARC II是美国国会图书馆研制的,所以后来称MARC II为LCMARC(the Library of Congress MARC)。LCMARC是一个标记系统,通过定义标记书目著录各元素的字段和子字段标识符,使计算机可理解和处理书目信息。LCMARC的产生标志着图书馆从卡片目录时代向自动化时代的转变。LCMARC修订后的第二版改名为USMARC(United States MARC),成为美国国家标准。1999年,美国国会图书馆和加拿大国家图书馆将USMARC和CAN/MARC(Canada MARC)进行合并,将新的MARC命名为MARC21,成为面向21世纪的机读目录格式。
在USMARC发展的同时,英国国家书目委员会启动BNBMARC(the British National Bibliography Machine Readable Cataloguing)项目,其成果是英国机读目录格式UKMARC(United Kingdom MARC)。20世纪70年代,国际上有20多个MARC,并且这一数字还在不断增长。
由于各国定义的MARC在内容表达、结构和字段定义等方面都有很大差异,为达到国际范围的书目信息共享和交换,IFLA提出一个解决方案,即定义一个中间MARC,如果20多种MARC间需要进行数据交换,那么只需每种MARC都编制与中间MARC的转换程序,便可达到与任何MARC进行数据交换的目的。1977年,IFLA发布UNIMARC(Universal MARC)后,其作用不仅是作为一个中间桥,很多国家都基于UNIMARC来制定本国的MARC格式[11]。
中国机读目录格式(China MARC,CNMARC)是依据UNIMARC制定的,1990年中国国家图书馆首次发布中国机读目录格式。CNMARC的发布为推动我国图书馆卡片目录转换成计算机可读目录发挥了巨大作用[12]。
1.3 数字化和语义化的资源描述阶段
20世纪90年代初,网络信息资源和各种类型的数字资源迅猛增加,对数字资源和网络信息资源的组织和描述的研究也迅速增加。
1994年,万维网的发明者Tim Berners-Lee创立万维网联盟(the World Wide Web Consortium,W3C)。W3C的目标是通过制定协议、标准和指南,领导万维网的发展[13]。1996年,W3C发布XML草案,XML成为了万维网结构化信息的基石。2001年,Tim Berners-Lee在《科学美国人》(Scientific American)上发表了论文Semantic Web。万维网向语义网发展由此拉开序幕。2002年,W3C发布RDF(Resource Description Frame)草案和OWL(Web Ontology Language)草案。这些标准都已经成为语义网核心的资源描述和组织标准。
1995年,在美国国家超级计算机应用中心(the National Center for Supercomputing Applications,NCSA)和联机计算机图书馆中心(Online Computer Library Center,OCLC)联合举办的研讨会上,与会专家讨论并提出了“Dublin Core元数据”。Dublin Core元数据是一组基于Web资源的核心语义集,用于对Web资源进行描述和分类,以方便检索。
当Web社区网络资源的组织技术和方法演进时,图书馆社区也面临数字资源数量的快速增长,以及新的文献类型快速出现的挑战。传统的编目标准已经无法应付这种挑战。在这个形势下,1990年IFLA召开了书目记录研讨会,会议的成果是成立一个研究小组,对书目记录的功能及需求进行全面研究。该小组的研究报告FRBR于1998年发布[14]。FRBR彻底改变了人们对编目的传统认识。它构建了高层实体关系模型,使人们对图书馆编目涉及的实体和实体之间的逻辑关系有了清晰的认识。FRBR成为国际编目领域的里程碑文献,指导新一代的编目标准的开发。
按照FRBR的成果,IFLA编目委员会和JSC开始研制全新的资源描述标准。2010年,RDA发布,2011年ISBD统一版发布。
RDA完全采用了FRBR的实体关系模型构建资源描述标准。RDA包括10个部分,第1~4部分是FRBR和IFLA后来发布的FRAD(Functional Requirements for Authority Data)模型中的作品、内容表达、个人、团体等实体的描述。第5~10部分是这些实体之间的关系描述。可以看出,今后的资源描述中,关系描述已经成为资源描述的主要内容,与语义网时代的关联数据达成高度一致。
ISBD统一版稍微保守一点,因为IFLA作为一个国际标准需要考虑到不同国家的不同发展水平。ISBD统一版将已经发布的ISBDs 8个分册的著录规则统一到一个版本中,建立了统一的资源描述标准,今后各种类型的资源描述在一个标准的指导下进行。这也可以说是一个非常大的成果。
2 我国文献著录国家标准的历史和现状
我国文献著录标准的制定是在全国信息与文献标准化技术委员会(以下简称“文标会”)的领导下,具体由识别与描述分技术委员会负责。
中国文献著录国家标准是在修改采纳ISBDs系列标准的基础上研制的。1983年,我国第一部文献著录标准《文献著录总则》发布。到1987年,我国共研制了《文献著录总则》(1983年)、《普通图书著录规则》(1985年)、《连续出版物著录规则》(1985年)、《非书资料著录规则》(1985年)、《古籍著录规则》(1987年)、《地图资料著录规则》(1986年)6个文献著录国家标准。
在文献著录系列标准发布10年后,文标会识别与描述分技术委员会在2007年召开分技术委员会会议,就我国文献著录规则发展方向的问题进行讨论。委员们看到国际标准正在发生的变化,但由于ISBD统一版和RDA还在研制中,而我国的文献著录标准已经到了需要重新修订的时候。会议决定,密切跟踪国际标准的进展,我国仍然按分册对系列文献著录规则进行修订。这次修订或新制定了如下8个标准即《文献著录 第1部分:总则》(GB/T 3792.1—2009)、《普通图书著录规则》(GB/T 3792.2—2006)、《文献著录 第3部分:连续性资源》(GB/T 3792.3—2009)、《文献著录 第4部分:非书资料》(GB/T 3792.4—2009)、《测绘制图资料著录规则》(GB/T 3792.6—2005)、《古籍著录规则》(GB/T 3792.7—2008)、《文献著录 第9部分:电子资源》(GB/T 3792.9—2009)、《信息资源的内容形式和媒体类型标识》(GB/T 3469—2013)。
2012年,文标会组织召开我国文献著录规则发展的第2次讨论,全国主要图书馆的编目专家参加了研讨会。会议决定启动我国统一的文献著录规则的研制,并将新的标准定名为《资源描述》。
2013年,《资源描述》项目获得国家标准化委员会批准并正式启动。因为《资源描述》将各种类型资源描述规则集中在一个标准中,文标会组建了有史以来最强大的标准研制组,考虑到各种类型图书馆的需要,研制组成员来自不同类型、不同地区的图书馆,同时也吸收特殊资源类型的专家,如古籍专家参与到标准研制中。
《资源描述》国家标准2016年完成报批稿并提交到国家标准化委员会,2021年正式发布。《资源描述》标准是在对上述8个分册标准进行合并和修改的基础上制定的,因此《资源描述》标准替代了上述8个标准。《资源描述》标准依据ISBD统一版,并参考RDA的载体描述部分,将上述8个著录规则合并成一个统一的标准,并在原来的资源类型基础上,增加了学位论文、拓片、手稿、乐谱等资源。《资源描述》标准是一个面向各种类型资源的通用资源描述标准[15]。
3 资源描述领域的国际最新进展
3.1 书目模型的研究
书目模型是书目数据涉及的实体及其关系的高层语义模型。书目模型提供人们对书目数据逻辑结构的认识,基于书目模型制定资源描述标准,使得书目数据具有语义表达能力,促进用户的资源发现。书目模型也促进图书馆书目数据与其他领域信息的互操作,促进书目数据成为语义网信息的有机组成部分。
3.1.1 FRBRoo模型
FR家族包括3个模型:FRBR(1998年)、FRAD(2009年,Functional Requirements for Authority Data)、FRSAD(2011年,Functional Requirements for Subject Authority Data),这3个模型用实体关系分析法,分别构建了书目数据模型、规范数据模型和主题数据模型。
CIDOC CRM(Comité International de Documentation [International Committee on Documentation] Conceptual Reference Model)是博物馆领域信息的概念参考模型。它由国际博物馆委员会(International Council of Museums,ICOM)的国际文献委员会(CIDOC)研制,2006年CIDOC CRM被采纳为国际标准。
2003年,IFLA编目委员会的FRBR评估组与CIDOC CRM SIG(CIDOC CRM Special Interest Group)合作,开始构建一个面向对象的、与CIDOC CRM兼容的FRBR扩展模型FRBRoo(Object-Oriented Formulation of FRBR)。FRBRoo 2.4版于2016年成为IFLA正式标准。
FRBRoo借用了CIDOC CRM模型的结构,包括CIDOC CRM的建模方法、属性和类,与FR家族模型的类和属性通过对齐、匹配等方法进行融合。
由于篇幅所限,无法把FRBRoo与FR家族所有的改变一一列举。本文仅以FRBR的兼容性改变为例,以窥一斑。
FRBRoo与FRBR的最大不同是引入了时间实体(temporal entities)。时间实体在CIDOC CRM模型中发挥中央核心作用。FRBRoo时间实体的两个类是F27 Work Conception和F28 Expression Creation。时间类在FRBRoo中被定义为CIDOC CRM的时间类:E65 Creation、E12 Production、E7 Activity和E13 Attribute Assignment的子类。
图1中,F27 Work Conception和F28 Expression Creation是FRBRoo中的两个时间类,F1 Work、F2 Expression和F4 Manifestation Singleton是来自FRBR模型的类,E39 Actor、E52 Time-Span和E53 Place是来自CIDOC CRM的类。FRBRoo模型用F27 Work Conception和F28 Expression Creation两个时间类,将E39 Actor、E52 Time-Span和E53 Place与F1 Work、F2 Expression和F4 Manifestation Singleton关联起来[16]。
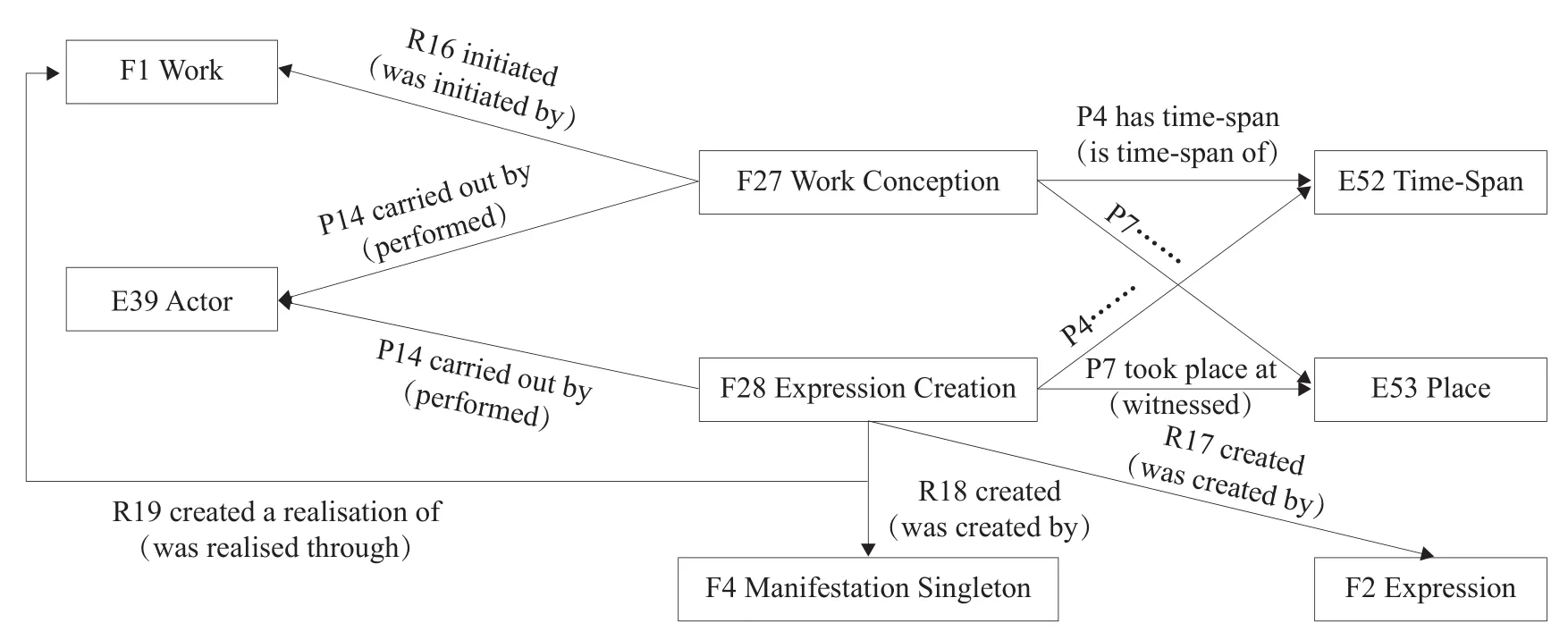
图1 作品和时间概念模型
3.1.2 IFLA LRM模型
由于FR家族的3个模型(FRBR、FRAD和FRSAD)分别由不同的小组研制。虽然这3个模型都是在实体-关系建模框架下创建的,但不可避免地,它们对共同问题采用了不同的视角和不同的解决方案。这3个模型都是书目系统中必须采纳的模型,因此有必要将FR家族的3个模型合并为一个统一的模型,以达到共同的理解[17]。LRM(Library Reference Model)由FRBR评估组负责研制,初版发布于2017年。
LRM模型不是简单地将FR家族3个模型的合并。研制组从最初的用户任务出发,审视书目数据中的实体、关系和属性。LRM仍然采用实体关系法,构建了一个一般化的高层书目信息逻辑结构。
LRM提供了扩展机制,允许在实际应用时对实体、关系和属性进行扩展,也允许LRM与其他领域本体进行对齐映射。
由于篇幅关系,FRBR、FRAD、FRSAD的概念模型请分别参见IFLA发布的3个报告:Functional Requirements for Bibliographic Records,Functional Requirements for Authority Data,Functional Requirements for Subject Authority Data。
LRM将FRBR、FRAD和FRSAD的模型整合后的高层模型如图2所示[18]。
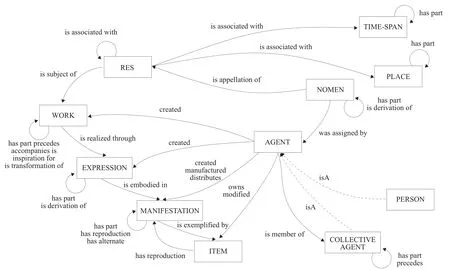
图2 IFLA LRM高层概念模型
从FR家族模型与LRM模型对比可以看出,LRM模型引入了3个实体“Res”“Agent”和“Time-span”,“Res”是顶级实体,也称为顶级类。LRM继承了FRBR模型的10个实体(Work、Expression、Manifestation、Item、Person、Corporate Body、Concept、Object、Event、Place)中的7个,没有继承FRBR中的“Concept””Event”和“Object”,其中FRBR中的“Corporate Body”改称为“Collecitve Agent”。LRM继承了FRSAD的“Nomen”,并将“Nomen”应用扩大到可以指称所有实体的名称。LRM模型用“isA”关系构建这些实体的等级关系如表1所示。
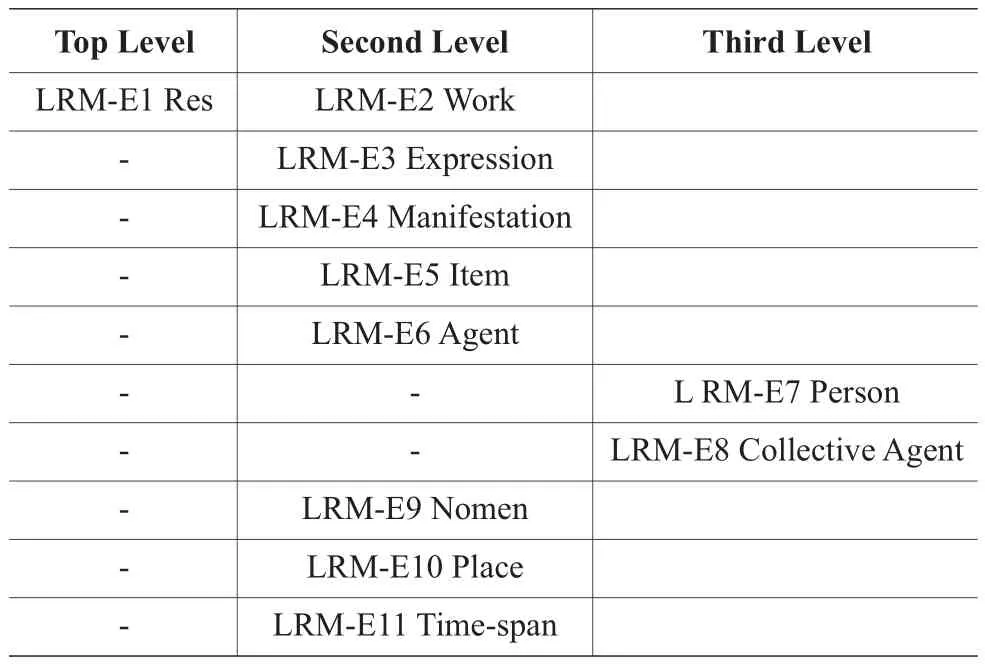
表1 IFLA LRM模型实体等级关系
LRM模型没有保留FRBR和FRSAD中的关于主题的实体“Concept”和“Thema”。虽然主题属于知识组织领域,但在书目模型中保留“Concept”或“Thema”实体,便于书目实体与知识组织概念模型关联是非常重要的。
3.1.3 LRMoo模型
继FRBRoo模型和LRM模型之后,IFLA启动了LRMoo模型研究。LRMoo模型旨在构建与博物馆领域信息模型CIDOC CRM相兼容的书目信息模型,以促进两个领域的互操作。LRMoo模型目前正在研制中,笔者认为LRMoo模型将取代FRBRoo模型。
3.1.4 BIBFRAME模型
BIBFRMAE模型是美国国会图书馆书目框架计划的基础成果。BIBFRAME是一个基于Web和关联数据技术的网络世界的书目信息本体模型。BIBFRAME2.0于2016年发布[19],BIBFRAME高层概念模型见图3。

图3 BIBFRAME 2.0高层概念框架
BIBFRAME2.0的核心类是“Work”“Instance”“Item”。
BIBFRAME2.0的“Work”合并了FRBR组1的“Work”和“Expression”。这是一个非常绝美的合并。在FRBR组1实体中,“Work”和“Expression”都是抽象实体,在书目实践中,编目员很难区分“Work”和“Expression”,把这两个抽象实体合并为一个,并没有给用户使用带来太大不便,但它大大简化了从描述、组织到服务的整个书目信息流。
BIBFRAME2.0中的“Instance”与FRBR的“Manifestation”实体的含义相同,但实体名称稍作改变,使用者更容易理解。
BIBFRAME中一部作品可能“关于”一个或多个概念。这样一个概念被称为作品的一个“subject”。可能的“subject”包括FRBR中的实体Object、Place、Event、Topics、Agent、Work、Expression、Manifestation、Item,还增加了Temporal Expressions。
这些改动,使得BIBFRAME2.0成为一个结构清晰、容易理解的概念模型,最重要的是BIBFRAME的简洁结构,使得在书目数据中的应用变得更加简单,易于实施,对于促进书目数据结构化、关联化的转变是非常重要的。
3.2 资源描述标准和书目模型的关联数据表示
3.2.1 关联数据表示的意义和方法
对资源描述标准和模型中的实体、关系、属性、元素以及属性值等术语按照W3C RDF标准进行表示,使其能够作为开放关联数据(Linked Open Data,LOD)使用,使得图书馆社区定义的术语成为被更广泛的语义网社区接受、能被机器理解的语义数据,并增强语义Web书目工具和服务的开发。基于资源描述标准进行编目的图书馆,也能够以LOD形式发布它们的书目数据。书目关联数据发布能够促进书目数据的互操作,促进语义Web中书目数据的重用和检索。
资源描述标准和模型中的实体在RDF中表示为类(Class),关系、属性和元素在RDF中表示为属性(Property)。所有经RDF表示的类和属性术语的集合称为术语表(Vocabulary)。
每个术语的定义包括命名空间的定义、给每个术语赋予一个统一资源标识符URI和一个标签(Label)、术语的自然语言的定义、类的上下等级结构、属性的定义域和值域等。RDF定义的结果一般按如下4种方法表示:①表格式;②N-Triples表示;③RDF/XML;④JSON-LD(JSON的关联数据表示)。其中第1种表格形式供人阅读,后面3种表示方法都是用于发布和机器阅读。
3.2.2 国际资源描述标准和模型的RDF表示
目前IFLA和RSC都对其资源描述标准和书目模型进行了RDF关联数据表示。
3.2.2.1 ISBD和书目模型的术语表
IFLA对其制定的ISBD统一版和模型进行了RDF关联数据定义,已经定义的术语表如下。
(1)书目模型的术语表:①The FR家族术语表,包括FRBR模型术语表、FRAD模型术语表、FRSAD模型术语表;②FRBRoo术语表;③LRM模型术语表。
(2)ISBD统一版术语表:ISBD element(ISBD元素术语表)、ISBD Value Vocabularies(ISBD值术语表)。ISBD值术语表又包括ISBD Content Form(ISBD内容形式值术语表)、ISBD Content Form Qualified Base(ISBD内容形式限制词术语表)和ISBD Media Type(ISBD媒介类型术语表)。
2016年,ISBD关联数据研究组发布了《ISBD作为关联数据应用指南》(Guidelines for Use of ISBD as Linked Data,以下简称《指南》)。《指南》不是元素集,《指南》主要针对书目数据的应用开发者,指导应用开发人员如何使用ISBD的命名空间,如何应用RDF定义的元素、元素映射和对齐,将ISBD数据暴露在关联数据环境下。《指南》为书目数据发布为关联数据提供了规范性的指导[20]。
3.2.2.2 RDA和BIBFRAME模型的术语表
RDA元素的关联数据表示发布在一个专门的网站RDA Registry[21]。RDA Registry定义了基于RDF和语义Web标准的RDA元素和元素值。
RDA元素定义包括Classes(类)、RDA Entity properties(RDA实体属性)、Work properties(作品属性)、Expression properties(内容表达属性)、Manifestation properties(载体表现属性)、Item properties(单件属性)、Agent properties(代理属性)、Nomen properties(名称属性)、Place properties(地点属性)、Time-span properties(时间属性)、Unconstrained properties(非必备属性,表示该属性来自RDA,但不是IFLA LRM模型的属性、LRM语义不是必备的属性)共11个术语表的RDF表示。
RDA属性值的RDF定义包括RDA Aspect Ratio Designation(RDA长宽比率)、RDA Bibliographic Format(RDA书目格式)、RDA Carrier Extent Unit(RDA资源数量和单位)等共46个值术语表的RDF表示。
BIBFRAME项目对BIBFRAME模型术语表(BIBFRAME vocabulary)[22]进行定义。定义的术语包括类、类的属性。定义的术语用图表格式和RDF文档两种方式表示。
3.3 术语表的互操作
当前国际资源描述标准两大体系是IFLA制定的ISBD统一版和RSC制定的RDA。两个体系都各自有书目模型,也都定义了RDF关联数据的术语表。两个体系的互操作尤其重要,可以提供用不同标准制作的书目数据之间的重用、转换、整合检索以及其他语义互操作。同时,图书馆社区的书目数据与相关信息,如出版信息互操作,能够促进图书馆社区与其他语义Web社区的关联、集成和其他语义互操作。
术语互操作是书目数据互操作的基础。术语互操作一般通过两个术语表的映射、链接、对齐来实现。IFLA、RSC、LC等机构合作,发布了各标准之间的类和属性术语表、值术语表的对齐、映射表。由于各种标准术语之间的映射表数量非常多,本文列举如下。
①Alignment of ISBD element set with FRBR element set(ISBD元素集与FRBR元素集的对齐,最后报告2016年完成)[23]。②Alignment of the ISBD element set with RDA element set(ISBD元素集与RDA元素集的对齐,3.1版完成于2015年)[24]。③Map from ISBD properties to unconstrained RDA properties(ISBD属性与RDA非必备属性的映射)[25]。④Map from unconstrained RDA properties to unconstrained ISBD properties(从RDA非必备属性到ISBD非必备属性的映射)[26]。⑤Mapping from ISBD to IFLA LRM(从ISBD到IFLA LRM模型的映射)[27]。
3.4 BIBFRAME书目数据转换项目
在RDA发布的2010年,美国国会图书馆发起了BIBFRAME项目。BIBFRAME项目的目的是建设面向基于未来关联数据和网络环境下的书目数据的描述框架,是图书馆使用了半个多世纪的MARC数据的替代格式。BIBFRAME重点放在书目数据与更广泛的信息社区进行整合并参与到其中的未来趋势,同时也兼顾图书馆社区书目数据交换以节约编目成本的需要。BIBFRAME项目需要为MARC书目数据转换到BIBFRAME数据设计转换路径、转换规则、转换工具,并进行实施试验。BIBFRAME项目已经完成BIBFRAME模型和BIBFRAME术语表的关联数据定义。
美国国会图书馆目前正在进行BIBFRAME2.0应用的试验。为进行试点应用,BIBFRAME项目制定了《MARC书目数据转换规范》(MARC Bibliographic Conversion Specifications)、《MARC名称规范数据转换规范》(MARC Title Authority Conversion Specifications)。这两个转换规范是将MARC数据转换为BIBFRAME数据的基础规则。
基于转换规则,项目开发了XSLT转换程序实施从MARC的XML表示向BIBFRAME转换和从BIBFRAME向MARC的XML转换。
项目又开发了查看器(viewer),查看器以双屏显示的方式,供人对MARC格式和BIBFRAME格式的数据进行对比,以检验转换结果。
美国和欧洲的许多图书馆参与了BIBFRAME项目和BIBFRAME的应用试点。基于在美国国会图书馆的试点应用,BIBFRAME项目全方位地测试和研究MARC数据向BIBFRAME转换中面临的问题,并对BIBFRAME模型和术语定义进行不断地改进,以使其更符合实际需要。试点应用也测试了用BIBFRAME进行编目的效率等相关问题。
2021年,美国国会图书馆更是将BIBFRAME应用试验扩大到国会图书馆的所有编目员。这意味着要扩大BIBFRAME和MARC的转换测试,同时在实用环境中测试基于这两种格式的图书馆系统的能力[28]。
4 对我国资源描述工作的思考
国际资源描述标准和资源描述工作正在发生巨变,我国的资源描述工作正站在从传统编目向基于语义网开放的资源描述转变的关键点。我们面临的挑战主要包括四方面:一是人才队伍建设,二是标准规范研制,三是MARC数据向关联数据转换,四是业务模式转变。每个方面的挑战都是极其巨大的。
4.1 人才队伍建设
应对资源描述领域的变革与发展,促进我国资源描述快步跟上国际发展的步伐,人才队伍建设是重中之重。
在人才队伍建设中,领域领军人才的发现和培养又是最关键的。能够推动这个行业发展的领军人才应该是复合型人才,具有丰富的资源描述经验,了解并掌握现代语义网信息和知识组织技术,有研究能力,跟踪国际发展趋势,推动我国新的标准体系的研究和开发,并能够为推动各自图书馆业务模式转型和工作流的重组提出建议、规划。
面对新的标准、新的数据要求、新的业务模式,各单位需要培养一支核心的资源描述业务骨干队伍。他们能理解语义网环境下书目数据的新要求,能够组织实施各图书馆业务转型,按照新的资源描述需要,促进书目数据在语义网环境下的开放服务。
4.2 标准规范研制
我国的文献著录规则一直是以ISBDs系列标准为依据,结合我国文献资源的特点制定的。虽然国际上一直有ISBDs和AACR2两大系列标准。但AACR2也是参考ISBDs研制的,在处理传统图书馆文献描述方面,两者并没有本质的差别。
然而,当前国际资源描述标准出现了复杂的局面。ISBDs系列标准合并为一个统一版的ISBD,是FRBR模型中的载体表现层的描述规则。而RDA包括FRBR和FRAD模型中的作品、内容表达、载体表现、单件、个人和团体的描述规则和这些实体之间的关系描述规则。
两个标准已经有相当大的不同。IFLA研制的标准被认为是等同的国际标准,允许和鼓励各国采纳。RDA不是国际标准,也不是美国国家标准,按商业机制运作,已经有非常多的国家采用,已经成为事实上的国际标准。我国一些图书馆的西文文献描述已经采纳RDA标准。未来IFLA标准会如何发展,我国的标准该如何选择方向,这是我们面临的艰难选择。
在国家标准开发方面,我们还面临一个标准开发机制的问题。标准的竞争已经成为技术的竞争,在大数据环境下,是数据优势的竞争。我们看到W3C和RSC开发的标准,它们已经不再申请成为ISO标准,甚至也不争取成为美国国家标准。它们研制的标准立刻在网上发布。由于标准的先进性和快速满足需求,这些标准的更新相当快。另外,目前国际标准的更新周期已经是无极更新。RDA标准直接发布为网络工具,2~4个月就有更新发布。W3C的标准也是根据需要随时发布新的版本。在标准开发机制方面,RDA建立了用发行收入支持标准研发的良性循环机制。
而我国的标准研制周期非常长,从申报项目,到批准,然后是研制,最后标准审批、出版,这个周期需要几年。标准发布后,按国标委规定,5年后才可以申请更新。另外,每个标准研制项目的经费非常少,在一定程度上也影响了标准研制人员的积极性。
面对这些复杂的环境和严峻的挑战,需要在标准的研制机制上作出创新和变革。
(1)先研究,再制定标准。要建立图书馆间的合作研究机制,国家图书馆的地位和实力,当之无愧是标准研究和制定方面的“领头羊”。而文标会不仅应该支持标准的研制,更应该支持标准的前期研究。在国家图书馆、文标会的带领下,联合CALIS等多馆力量,开展研究、进行数据实验,测试各种标准对中文资源的适应性。标准规范的研制是在合作研究的基础上自然产生的成果。
(2)先制定标准、推广应用,再申请成为国家或行业标准。国家图书馆、CALIS、文标会在中国图书馆领域享有非常高的权威和认可度。如国家图书馆制定的《中国文献编目规则》[29]虽然不是国家标准,但被大多数图书馆作为编目标准采用。所以,今后在我国资源描述标准的制定上,可以在文标会、国家图书馆或CALIS的牵头下,联合国内主要图书馆先制定标准,推广应用,再申请成为国家标准。转变先申请成为国家标准再应用的模式。
(3)建立类似RSC这样的联合修订委员会,负责我国资源描述相关标准的制定,并建立标准的出版发行收入支持标准研发的机制,促进标准开发与应用的良性循环和持续维护更新。
4.3 MARC书目数据向关联数据转换
经历半个多世纪,图书馆积累了大量的MARC数据,如国家图书馆联合编目中心数据库的书目数据超过2 000万条,CALIS联合目录数据库记录超过800万条。将MARC数据转换为基于关联数据技术的新的书目格式,面临的任务和困难比美国国会图书馆BIBFRAME项目的更重、更大。因为中国的机读目录格式采用了两种格式。西文文献采用MARC21格式,中文文献采用CNMARC格式,两种格式并用,转换映射的难度和系统开发的难度都成倍增加。MARC数据的不规范、字段缺失,将是转换中会遇到的非常大的困难。
我国西文文献的MARC数据转换为关联数据格式,可以借用美国国会图书馆BIBFRAME的研究成果和今后BIBFRAME实施转换后的数据共享。但中文文献的CNMARC格式数据转换为关联数据,没有可借鉴的经验和工具。因此,需要国内图书馆的合作,需要一些编目实力强的图书馆(如国家图书馆、CALIS联合编目中心等)牵头。在国家图书馆等的牵头下,联合多个图书馆实施这个世纪性转换任务,也会避免各馆各自转换造成的人员、财力和时间的浪费,避免低水平的重复工作。
4.4 业务工作流和服务模式转变
未来的资源描述不仅仅是简单的描述标准的变化,新的资源描述标准是为了开创新的服务。由标准应用引发的业务工作流和服务模式变化将是巨大的。虽然这个变化才刚刚开始,国际上还没有一家图书馆已经完成这一转变,但我们根据已经大量涌现的语义Web的新型服务以及在图书馆社区的许多研究和探索项目,我们可以对未来的业务工作流和服务模式做些不太离谱的推断和设想。
4.4.1 资源描述方面
目前即使在一个图书馆内,各种资源的描述都有各自的规则,数据存储在各自的数据库中,都有自己的服务系统,在图书馆主页上链接各个服务。有些图书馆开发了整合检索,但是效果一直不是很好。未来图书馆内的一个个“信息孤岛”将被打破,基于全资源谱系的高层书目模型、基于全资源谱系的统一描述规则和一致的机器表示语言,将各种资源的描述和组织统一起来,图书馆内部的业务工作流、各部门之间的合作模式都相应会有调整。
未来的资源描述重点是在知识组织,而不是简单的属性描述。知识组织包括关联、主题深度揭示、分析描述、多层次描述等。未来的描述也需要站在语义网大数据环境下,考虑与外部语义信息资源的关联。
未来的描述将更多依靠语义工具,简单重复的工作交给AI完成,人的智力用在机器无法完成的,需要人的经验、判断的任务上。
4.4.2 服务方面
图书馆的整合服务将实现,而且这个整合服务是基于语义大数据的服务,也许图书馆会出现像Google知识图谱或比它更先进的语义服务。
图书馆的数据将以开放关联数据的形式发布到互联网,也许会发布到Wikidata、Wikipedia,或独立的图书馆语义数据库中,供网络语义搜索引擎和语义工具使用图书馆的数据,这些工具帮助用户发现资源后,又会将用户引导到图书馆来使用图书馆的服务。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
现代仪器与医疗(2022年2期)2022-08-11
都市人(2022年3期)2022-04-27
现代交际(2021年15期)2021-11-25
天一阁文丛(2020年0期)2020-11-05
河南图书馆学刊(2018年10期)2018-12-17
办公室业务(2015年23期)2015-11-26
科技传播(2015年13期)2015-09-16
中国民间疗法(2012年1期)2012-07-27
河南图书馆学刊(2009年6期)2009-05-31
