
面向数据匮乏城市的下一个POI 推荐方法①
2021-02-11 08:15谭海宁毕经平
高技术通讯 2021年12期
谭海宁 姚 迪 毕经平③ 向 徐 杨 啸
(*中国科学院大学 北京100049)
(**中国科学院计算技术研究所 北京100190)
(***盲信号处理国家级重点实验室 成都610041)
0 引言
随着各种具有定位服务的移动设备的普及,基于位置服务的移动社交网络(location-based social network,LBSN)发展迅速,具有位置信息的用户数据呈爆发式增长,如Foursqure、Yelp、美团等电商服务平台[1-2]。有效地利用具有位置信息的用户数据,探索用户兴趣点(point of interest,POI)已经成为移动社交网络数据挖掘领域的重要研究方向。其中,由于推荐系统是解决信息过滤和个性化服务问题的主要手段之一,其在用户位置挖掘服务中发挥着重要作用,面向用户兴趣点的推荐方法研究也成为移动社交网络挖掘领域的重中之重[3-5]。
兴趣点表示用户感兴趣的已经访问或将会访问的地理位置[1-2,6-7]。推荐的潜在兴趣点表示用户在将来某个时间点可能会访问的地理位置。作为面向位置服务的移动社交网络数据挖掘领域的重要分支,POI 推荐可以预测用户行为和兴趣演化趋势,对城市交通的规划和商业模式的探索具有重要的现实意义。POI 推荐有着广泛的应用,例如大众点评网站的餐厅推荐[4]、旅游路线规划[5]、城市交通事件预警[8-9]等。
当前大多数的POI 推荐方法都假设POI 数据是同分布的,将POI 数据看成一个整体进行用户POI兴趣的挖掘工作,比如STRNN[1]、DeepMove[10]、STLSTM[11]等。这些方法将用户的签到POI 数据看成一个整体,没有考虑轨迹数据的城市不均衡特性,缺乏对城市之间共性信息和城市本身特殊性信息进行区分的个性化建模,这样导致在数据匮乏的城市,由于POI 历史记录少,对用户进行推荐难度大、效率低。本文分析了Foursqure 收集的截止到2014 年1月的用户签到POI 数据的全球位置数据。从数据分布可以看出受到采集手段、隐私保护等因素的影响,用户POI 签到数据在城市之间分布极其不均衡。北美、欧洲及各大洲沿海发达城市POI 数据分布比较集中,其他城市POI 数据分布非常稀疏。
因此,亟需探索如何在数据匮乏的城市进行POI 推荐的有效方法[12-14]。针对如何解决数据匮乏的问题,有少量的工作通过关联相关用户在目标城市外的历史信息进行推荐,比如JIM[15]和JFT[16]。这些工作都是基于源城市和目标城市之间存在共同用户的前提下,将关联用户在源城市的行为信息进行迁移,完成关联用户在目标城市的POI 兴趣发现和推荐任务。这类方法受限于事先设定的影响因素,无法对隐含因素进行建模,并且在城市之间的信息共享受共同用户这一假设制约,导致推荐方法应用范围受限,推荐效果不佳。
本文为了缓解数据分布不均衡等因素给POI 推荐带来的影响,借助于元学习[17]的思想,通过将数据丰富城市的泛化共性移动知识进行学习并迁移应用到数据匮乏城市的POI 推荐任务中。与此同时,由于采集的POI 数据的时间点并不是严格规整的,即并不是按照固定的时间间隔进行采集,这就造成POI 数据之间时间间隔的不确定性。传统的序列化建模方法将时间间隔分割成不同的时间槽或者直接按照先后顺序进行建模,忽略了POI 序列之间的连续时间信息,因此序列推荐效果受到严重制约。文献[18]在其工作Neural-ODE 中指出了在序列化推荐任务中,连续时间建模对推荐效果的性能有明显提升,并提出了可以进行连续时间建模的新的深度网络,即神经常微分方程。神经常微分方程使用神经网络参数化隐藏状态的导数,而不是直接参数化隐藏状态。这里参数化隐藏状态的导数就类似构建了连续性的层级与参数,而不再是离散的层级。因此参数也是一个连续的空间,不需要再分层传播梯度与更新参数,这样可以更加高效地进行连续时间建模。本文受神经常微分方程[18]的启发,提出了基于元学习的时空神经常微分方程(meta-learning based ordinary differential nural network,ML-ODE)进行有效的POI 推荐。
本文的主要贡献如下。
(1) 借助于神经常微分方程实现了对POI 数据的连续时间序列建模,可以忽略传统方法对输入数据的时间间隔的约束。
(2) 在神经常微分方程中融入时空注意力机制,借助注意力机制衡量不同时刻的签到行为与用户偏好的相关性,进而获得不同签到行为的权重系数。
(3) 提出了基于元学习机制的POI 序列推荐框架,实现了将泛在共性移动知识从数据丰富城市迁移到数据匮乏城市。
(4) 在真实数据集上进行了大量实验,实验结果表明,本文提出的POI 推荐算法可以有效地对数据匮乏城市的目标用户进行POI 推荐。
本文结构如下:第1 节介绍了面向位置社交网络POI 推荐的相关工作,包括基于矩阵分解和基于深度学习的相关方法;第2 节介绍了本文使用的基本符号和相关问题定义,并详细描述了本文提出的POI 推荐框架ML-ODE;第3 节通过实验对本研究中提出的方法进行了有效验证,并报告相关的实验结果;第4 节对本文的工作进行了总结并展望该技术的未来发展方向。
1 相关工作
本节详细介绍了目前主流的面向位置社交网络的POI 推荐方法以及与神经常微分方程相关的最新研究成果。目前,POI 推荐方法主要可以分为面向单城市的POI 推荐方法和跨城市的POI 推荐方法。
面向单城市的POI 推荐方法,主要有FPMC[19]、STRNN[1]、DeepMove[10]、AT-LSTM[20]等。FPMC 通过引入基于马尔可夫链的个性化转移矩阵,进行时间信息和用户的长期兴趣偏好的捕捉,同时为了解决转移矩阵的稀疏局限性,引入了矩阵分解模型,可以减少参数并提高POI 推荐效果。但是由于马尔可夫链的不同影响因素之间的独立性假设,并且受矩阵分解类方法冷启动的影响,该类方法具有一定的局限性。STRNN 通过扩展循环神经网络(recurrent neural network,RNN)[21]提出了一种时空循环神经网络模型,该方法通过引入时间转移矩阵和空间距离转移矩阵分别建模局部时间上下文和空间上下文,通过设置不同的窗口确定恰当的时空上下文邻居,分别计算时间距离tdis和空间距离ldis来作为转移矩阵的输入,规整后统一输入循环神经网络。DeepMove 提出了一种基于注意力机制的多模态循环神经网络,首先通过门控循环单元(gated recurrent unit,GRU)层建模用户即时偏好;其次通过历史注意力机制模块对用户的历史偏好进行建模;最后通过整合多层注意力机制提升用户移动模式预测效果。AT-LSTM 在长短期记忆网络(long short-term memory,LSTM)的基础上借助注意力机制进行时空信息长期偏好和短期偏好的捕捉,提升了推荐效果。
该类方法将用户的签到POI 数据看成一个整体,没有考虑轨迹数据的城市不均衡特性,缺乏对城市之间共性和城市本身特殊性的区分性建模,这导致在数据匮乏的城市POI 推荐效率低下。
面向跨城市POI 推荐的方法主要有JIM[15]、STLDA[22]、CTLM[23]等。文献[15]提出了一种可以用于跨城市的POI 推荐的图模型JIM,通过联合考虑POI 内容、check-in 时间、POI 地理位置以及POI 的流行度等因素,实现跨城市推荐。ST-LDA 是JIM 工作的扩展,增加了对用户在不同城市的兴趣漂移因素的建模,通过叠加用户的自身兴趣偏好和用户在某城市的兴趣偏移实现对目标用户的个性化POI 推荐。文献[23]提出了一种基于共同话题迁移学习模型的跨城市POI 推荐模型,该方法将城市的POI按照各自属性信息分为城市间共有类(common topics)和城市内私有类(city-specific topics),将用户在别的城市与共有类的交互信息迁移到目标城市。
该类方法都是基于源城市和目标城市之间存在共同用户的前提下,将关联用户在源城市的行为信息进行迁移,导致推荐方法应用范围受限,推荐效果不佳。
神经常微分方程在模型训练的过程中,不使用其他RNN 以及卷积神经网络(convolutional neural network,CNN)等直接参数化隐藏状态的处理方式,直接使用神经网络参数化隐藏状态的导数。因此,神经常微分方程的参数可以看成一个连续的空间,不再需要分层进行梯度传播并更新参数。目前针对神经常微分方程的工作还相对较少,主要有面向时序序列建模的Neural-ODE[18,24]、GRU-ODE[25]等。文献[18]提出神经常微分方程Neural-ODE,这是一种新的深度神经网络,借助于常微分方程实现对序列数据的连续建模。GRU-ODE 结合Neural-ODE 和GRU 进行时间序列的连续性建模,根据输入离散的时间点观察值,通过GRU-Bayes 模块更新Neural-ODE 之间的隐状态向量。
该类方法目前还没有用来建模POI 数据,并且不能直接迁移应用于跨城市POI 推荐应用中。
针对现存POI 推荐方法存在的问题,本文提出了基于神经常微分方程的跨城市POI 推荐方法,将数据丰富城市的泛化共性行为知识迁移到数据匮乏的目标城市,不仅缓解了目标城市的数据匮乏问题,也实现了对序列数据的连续性建模。
2 时空神经常微分方程
本节将介绍所提出的面向数据匮乏环境的下一个POI 推荐方法。
2.1 基本定义
对位置社交网络中的用户进行POI 推荐时,通常用数值或者向量来表示网络中的实体。例如,在描述用户签到数据时,签到地点用经纬度数值二元组进行记录,时间用数值进行记录,用户的属性信息也会转换成属性向量进行表示。本文研究的问题是如何构建一个合适的用户POI 兴趣学习模型,借助用户的历史签到记录,为其更好地进行POI 推荐。在详细描述POI 推荐算法之前,先给出一些基本的符号解释和定义。
定义1兴趣点(POI)[22]。在位置社交网络中,一个兴趣点表示某一地理位置,通常由一对地理经纬度坐标以及相关的属性信息表示。
定义2签到行为(check-in activity)[22]。在位置社交网络中,用户u的签到行为记录可以看成一个三元组,这里可以形式化为
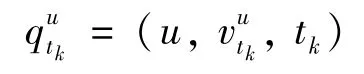
定义3签到序列(check-in sequence)。在位置社交网络中,某用户u的签到序列由该用户一系列的历史签到行为构成,可以形式化为
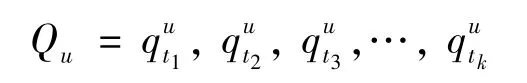
其中,k表示用户u的历史签到行为总数。为了方便,所有用户的历史签到序列可以形式化为
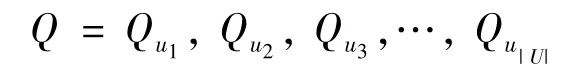
这里,U表示用户集合。
定义4下一个POI 推荐(next POI recommendation)。给定用户签到数据匮乏的目标城市集合D=,用户签到数据丰富的源城市集合S=S′1,S′2,S′3,…,S′N,满足:
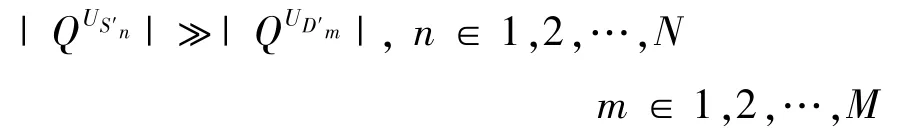
本文的目标是为目标城市D′m中的用户u推荐其下一个可能感兴趣的,可以将推荐过程形式化为
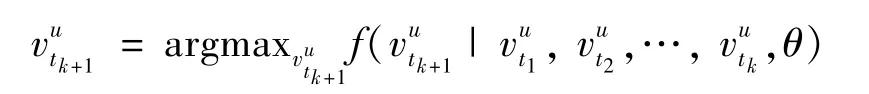
其中,f表示POI 推荐模型,θ表示模型相关参数,模型整体框架图如图1 所示。
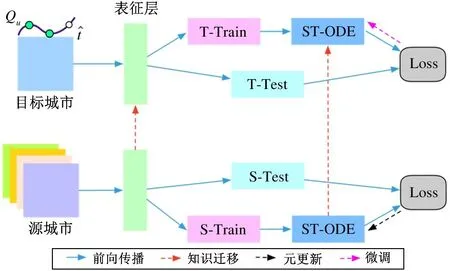
图1 面向数据匮乏环境的下一个POI 推荐框架
2.2 基于时空注意力机制的神经常微分方程
本小节将介绍提出的基于注意力机制的时空模型ST-ODE。如图2 所示,在给定用户u的一条轨迹,ST-ODE 首先获取每一条签到记录的表征向量,然后通过时空神经常微分方程建模轨迹序列的时空影响,最后通过时空注意力机制获取u在tk+1时刻的状态向量。接下来,将分别介绍签到行为表征、时空神经常微分方程以及时空注意力机制3 个模块。
2.2.1 签到行为表征
在表征模块中,利用一个嵌入层获取签到行为序列中每一个签到行为的表征向量,如图1 所示。在特征层面,仅考虑POI 的类别、POI 位置以及时间戳3 类特征,即(ck,lk,tk)。其中ck表示该签到行为所在POI 的所属类别,lk表示该POI 的所在位置,由经纬度坐标表示,tk表示发生该签到行为的时间点。
(1) 针对POI 类别属性ck,引入矩阵Ec∈,其中,N表示POI 的类别数,dc表示POI 类别表征向量的维度,这里矩阵Ec在多个城市之间进行共享。
(2) 针对POI 地理位置属性lk,引入矩阵El∈ℝM×dl,其中,M表示POI 的个数,dl表示POI 位置属性表征向量的维度,通过经纬度坐标位置的Geo-Hash 编码来初始化POI 矩阵El。
(3) 针对时间戳tk,引入矩阵,其中168 表示将一周分成168 个时间槽(7 ×24 h),每一个时间槽的表征向量维度为dt。
针对每一条签到记录,将3 类特征的表征向量进行拼接,可以获得长度为d的表征向量rk,其中,d=dc+dl+dt作为后续时空神经常微分方程的输入。
2.2.2 时空神经常微分方程
在进行连续时间序列建模方面,本文借鉴文献[25]中的GRU-ODE 方法,如图2 所示。针对输入的签到记录表征向量rk,通过基于GRU 的ODE层进行签到行为之间的连续时间状态传播(传播层,Prop-ODE),即将隐状态hk-1从时刻tk-1转移到时刻tk,可以形式化为
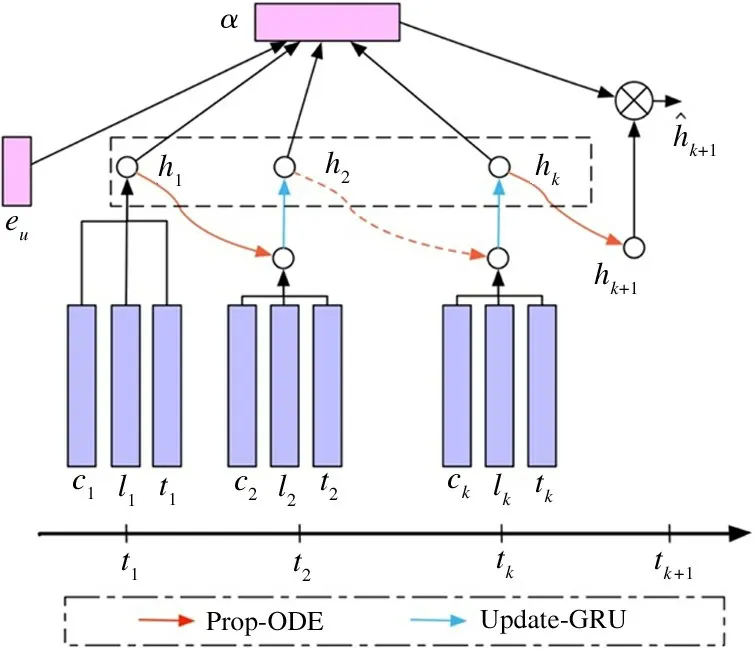
图2 基于时空注意力机制的神经常微分方程框架图
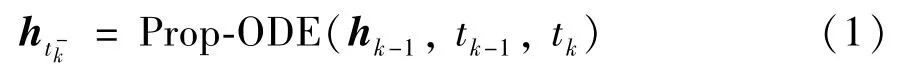
通过一层GRU 层在观察点进行签到行为的更新(更新层,Update-GRU)。针对用户断断续续的签到行为,需要在观察到签到行为的时间点对隐状态进行更新。在本更新层中,针对给定的签到行为的表征向量rk,在时间点tk,可以通过式(2)进行更新。
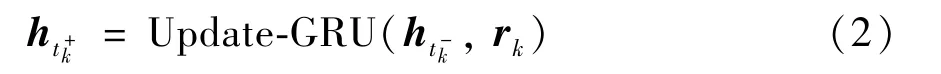
其中,ht-k和ht+k表示在时刻tk经历更新层前后的隐状态。在本文中,GRU 沿用文献[26]的工作,具体的公式推导过程在这里不再赘述。
由上述时空神经常微分方程可以看出,构造目标函数时主要分为两部分。在Prop-ODE 层,需要考虑经过传播后的隐状态与观察值之间的分布差异,这里损失函数可以表示为
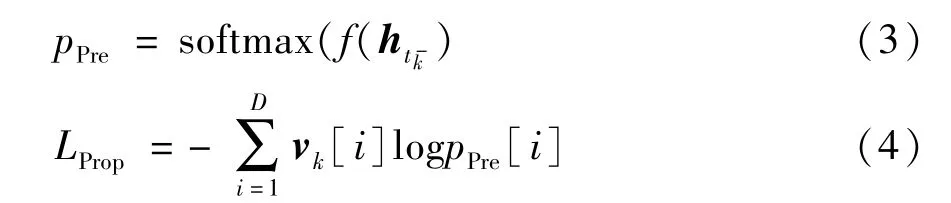
其中,f表示一个全连接层将隐状态向量hk转换成一个D维向量,pPre表示根据隐状态向量推断的该时刻在所有POI 上的概率分布,vk∈ℝD×1表示当前观察点的的one-hot 表征向量。

用ppost表示在应用Update-GRU 之后预测的概率分布,则损失函数可以定义为
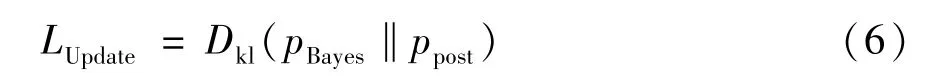
2.2.3 时空注意力机制
从直觉上来说,并非所有的历史签到都与用户的下一步行为密切相关,即需要更加注意用户信息偏好。但是,标准的神经常微分方程GRU-ODE 网络无法检测其输入的哪一部分对下一个POI 推荐至关重要。因此本文引入注意力机制,并提出了一种基于时空注意力的神经常微分网络来解决上述问题。时空注意力机制旨在捕获下一步用户行为与过去签到行为之间的不同关联度。通过使用注意力机制,ST-ODE 还可以帮助选择用户喜好的代表性签到行为,并为他们分配不同的权重。因此,可以更好地集成用户的历史签到行为表征,以有效地描述用户的兴趣偏好。
如图2 所示,引入矩阵H∈ℝd×k包含ST-ODE在所有评估点的隐状态向量,这里d表示隐状态向量的维度,k表示用户签到序列的长度。ST-ODE 借助于注意力权重向量α来进行历史轨迹隐状态向量{ht+i} 的整合,可以形式化为

其中,αi表示第i条记录与下一步的签到行为的匹配程度,可以通过下式进行权重矩阵的计算:
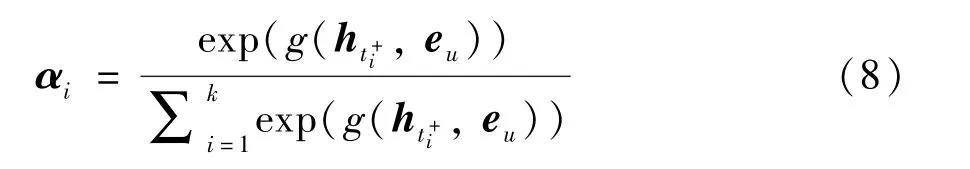
其中,g(ht+i,eu) 为注意力函数,本文使用点积注意力来进行注意力的计算,可以形式化为
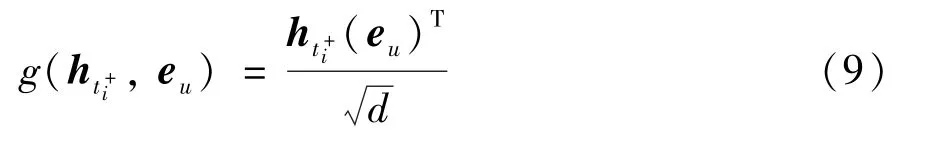
式中,eu表示用户u的上下文向量。本文根据用户访问过的POI 的类别(category)信息进行eu的初始化,,wi表示类别权重,ei,c表示在第i条签到行为所在POI 的类别表征向量。在训练过程中,将其和参数进行同步更新。这里损失函数的构建与在2.3 节中的在目标城市进行调优的损失函数一样,可以形式化为
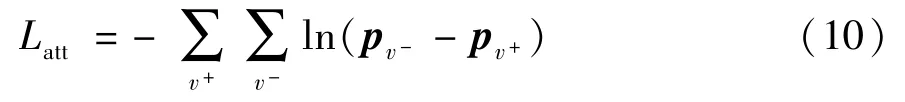
具体推导过程参照2.3 节,对一个含有K条记录的用户u来说,ST-ODE 的整体损失可以定义为
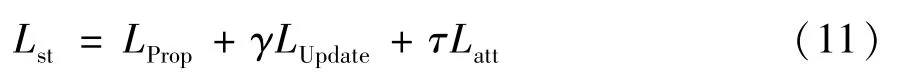
其中,γ和τ表示加权目标函数的权重参数。
将ST-ODE 模型整体算法总结如算法1 所示。


2.3 移动行为知识迁移机制
本小节将介绍提出的基于元学习的移动知识迁移方法,借助于元学习将数据丰富城市的移动行为知识迁移到数据匮乏城市。
城市的移动行为模式随着时间的推移而发生变化,并且城市与城市之间也各不相同。但是,不同城市之间的用户也存在着诸多的共性,比如大家在上午都习惯于打卡咖啡店,在打卡完运动场之后可能更喜欢打卡餐厅。所以,可以将来自于多个城市的共性行为知识,比如空间邻近性和时间依赖性等,迁移到目标城市。
图3 为基于元学习的时空常微分方程的参数更新过程。将Ø 作为时空神经常微分方程的参数集合,因此Ø 的相关参数中便隐含了时空移动知识。所以只需要传递更新参数Ø 便可以实现共性行为知识的迁移。这里沿用元学习的思想来进行ST-ODE 的参数学习,针对式(11),可以通过式(12)进行初始参数的更新。
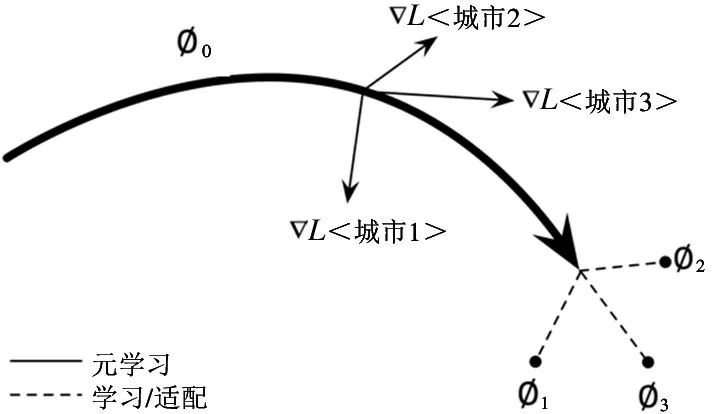
图3 基于元学习的参数优化框架图
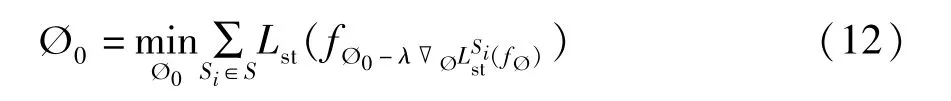
其中,Ø0为ST-ODE 的参数初始值,Lsi(fØ) 表示ST-ODE 在源城市数据集Si上的训练损失值。如在框架图中的每个源城市中,本文将会迭代更新参数。比如在数据集Si中,按照式(13) 进行参数更新。
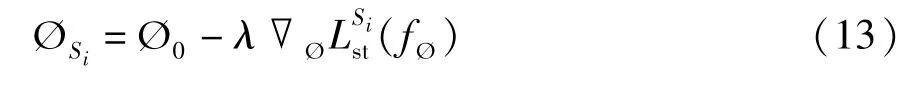
由于模型的目标是为数据匮乏城市的用户进行POI 推荐,所以需要针对目标城市进行参数优化。首先直接将在基于元学习的初始参数学习机制中学习到的初始参数Ø0迁移到目标城市Di;其次,在参数优化过程中,根据ST-ODE 的输出时刻tk+1的状态向量hk+1,可以通过式(14)计算用户下一时刻tk+1会访问某候选POIvi的概率。
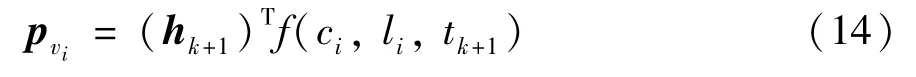
其中,f() 表示表征函数,获取POI 的相关特征的表征向量,pvi表示用户在POIvi上的概率值。
在推荐过程中,通过argmaxv(p) 为用户推荐最有可能访问的POIv。在训练过程中,参照BPR-Loss的个性化排名损失训练方式[27]进行推荐任务损失函数的构建:
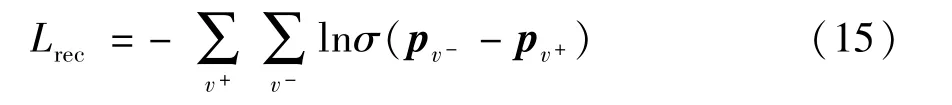
其中,v+表示用户访问过的POI;v-表示到目前为止用户没有访问过的POI;σ表示非线性函数,即σ(x)=1/(1+e-x)。因此在目标城市的参数训练过程中,损失函数可以重新定义为
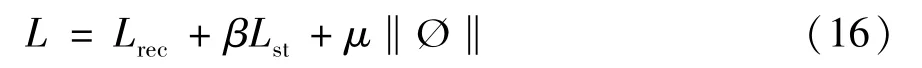
同时,在目标城市中,参数ØDi的更新过程可以改写为
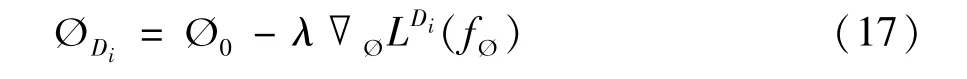
在实际的更新参数过程中根据情况进行多次迭代,最终获得具有普适性的初始参数。知识迁移部分算法如算法2 所示。


2.4 复杂度分析
基于时空神经常微分方程的推荐方法是否能够进行实际应用的关键在于算法的时间复杂度,在这里对ML-ODE 的时间复杂度进行详细分析。在对多个时间序列进行批处理过程中,对所有时间序列的观测时间进行排序,对于每个唯一时间点tk,创建一个具有观测值的时间序列的列表用于后续模块。ML-ODE 的时空开销主要存在于表征向量获取以及推荐排名两部分。在表征向量获取方面,MLODE 的主循环在时序列表唯一的时间点上进行迭代,在Prop-ODE 步骤中,针对单个列表,传播所有隐藏状态,时间复杂度为O(|ØProp-ODE|),这里|ØProp-ODE| 表示Prop-ODE 模块的参数量,Update-GRU 更新和损失计算也是仅对在特定具有观测值的时间序列执行,时间复杂度为O(|ØUpdate-GRU|),| ØUpdate-GRU| 表示Update-GRU 模块的参数量;在推荐排名部分,时间复杂度为O(d2),这里d表示表征向量的维度为常量,因此ML-ODE 的整体时间复杂度为O(|Ø|),|Ø|表示状态向量获取模块的整体参数量,可以应用于较大规模POI 推荐任务中。
3 实验与结果分析
本节将详细介绍实验的数据集及相关实验过程,对比不同推荐模型和方法在公开数据集上的POI 推荐效果,并详细分析各类模型的性能表现。
3.1 数据来源
本文使用的数据集来自于Foursqure[28]。Foursqure 是在位置社交网络领域的一个大规模的社交网站,允许用户在不同的地理位置进行签到行为(check-ins),本文使用2012 年9 月到2013 年9 月之间Foursqure 公开的去隐私化的用户全球规模签到数据集。据统计,这个数据集包含33 278 683 条用户签到数据,涵盖用户量为266 909,POI 数量为3 680 126(涉及全球77 个国家中的415 个城市)。在这415 个城市中,每个城市至少包含10 000 以上的签到数据。本文列举了几个在实验过程中整理的城市签到数据样例,如表1 所示。图4 和图5 展示了数据集统计表中东京和旧金山(SF)的城市POI分布热力图,可以看出城市间之间POI 分布极不均衡。
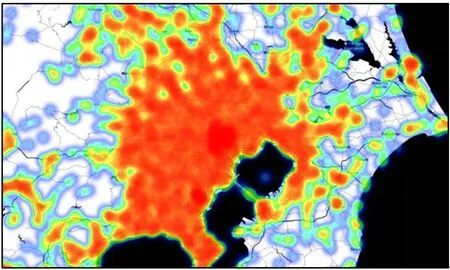
图4 东京POI 分布热力图
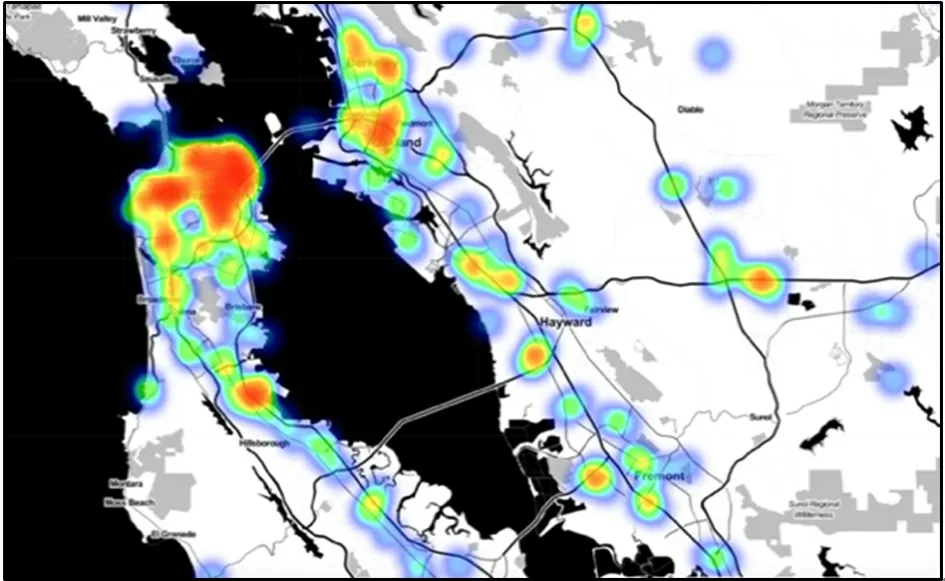
图5 旧金山POI 分布热力图
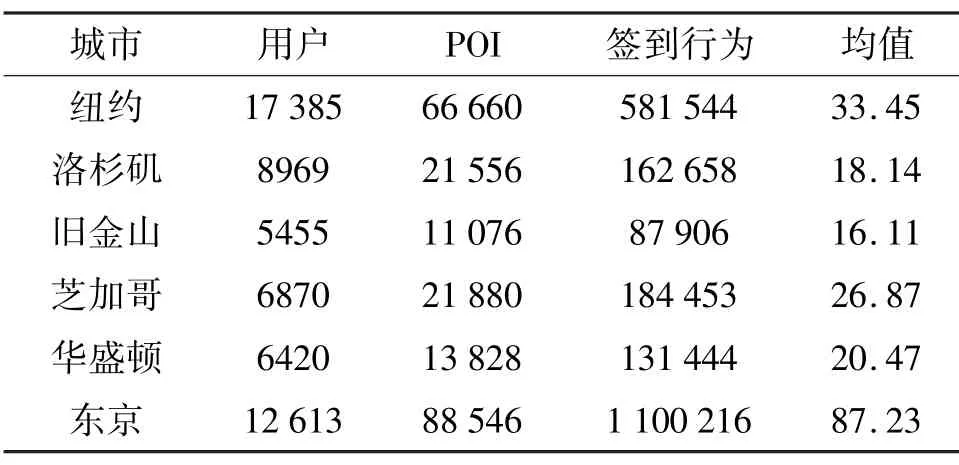
表1 城市签到数据统计
在实验评估过程中,按照用户的平均签到条目数来区分数据丰富城市和数据匮乏城市,在这里分别指定洛杉矶(LA)和旧金山为数据匮乏城市,其余城市划分为数据丰富城市。为了验证本文方法在数据匮乏区域的效果,在数据匮乏城市只使用1 个月的POI 数据进行实验。除此之外,在实际评估过程中,按照7 ∶1 ∶2 的比例划分训练集、验证集和测试集。
3.2 对比方法
本文实验中选取了目前比较流行的效果较好的POI 推荐模型,主要通过命中率(HR)和归一化折损累计收益(NDCG)等指标来进行各类算法的实验对比,下面概述在本文中对比的主流算法。
MF-BPR[27]:该算法提出了一种基于贝叶斯的改进矩阵分解模型,主要是通过贝叶斯的个性化排序来优化MF[29],通过建模用户访问过的POI 数据来建模用户与POI 的隐式关系。
CML[30]:该算法将度量学习(metric learning)与协同过滤(collaborative filltering)进行结合来解决用户物品推荐的问题,提出了协同度量学习模型,学习用户和物品之间潜在关系的同时评估用户和用户、物品和物品之间的相似性,借助用户隐式评价进行Top-K 推荐。
PRME[15]:该算法使用针对推荐的排序度量嵌入方法对用户的个性化签到序列进行建模,此模型整合了签到的序列信息、个人偏好和地理影响,以提高推荐性能。
STRNN[1]:该算法在循环神经网络的基础上增加了时间敏感性,捕捉在签到行为之间的时间和空间位置信息变化。
DeepMove[10]:该算法在循环神经网络的基础上增加了用户兴趣注意力机制,考虑用户签到序列时序关系的基础上还考虑了用户的长期兴趣。
ST-LSTM[11]:该算法是LSTM 的变式,在LSTM中增加了时间和距离两种门限机制来捕捉用户签到行为序列之间的时空关系进行POI 推荐。
GRU[26]:该算法也是循环神经网络的一种,可以看成是LSTM 变体,结构更加简单,主要解决了RNN 网络中的长依赖问题。
ST-ODE:该算法是ML-ODE 的弱化版本,在不使用元学习机制下,应用时空神经网络常微分方程进行推荐,旨在比较分析元学习机制在该任务中是否有效。
Single-FT:该算法是ML-ODE 的变式,与MLODE 参数优化机制不同的是,Single-FT 利用单个源城市对目标城市时空模型的初始化参数进行更新。
Multi-FT:该算法也是ML-ODE 的变式,与MLODE 参数优化机制不同的是,Multi-FT 将多个源城市的数据进行混合之后无差别地对目标城市的时空模型进行初始化参数更新。
No-ATT:该算法也是ML-ODE 的变式,与MLODE 不同的是,No-ATT 不使用时空注意力机制进行隐状态的聚合,直接使用ST-ODE 的最后输出隐状态作为推荐模块的输入。
ML-ODE:该算法是本文提出的基于元学习的神经网络常微分方程,将神经网络常微分方程用于时空关系挖掘。除此之外,借助元学习进行初始参数的优化和学习,实现在数据匮乏城市的POI 推荐任务。
可以看出,在比较的方法中,MF-BPR 和CML是推荐系统领域比较通用(general)的模型,应用比较广泛。而STRNN、DeepMove 和ST-LSTM,都是要根据签到序列的上下文信息(context-aware)进行时空关系挖掘的推荐模型。在后期的实验评估过程中将会详细地分析各类模型在POI 推荐任务上的表现。
3.3 评价指标
在性能对比实验中,采用两种推荐指标来评估推荐模型的性能:命中率(HR@N) 和 归一化累计增益(NDCG@N)。
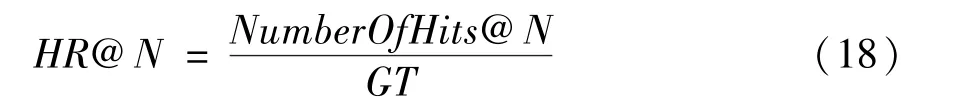
其中,GT表示所有的测试集合,NumberOfHits@N表示推荐列表的Top-N 子集中属于测试集合个数的总和。
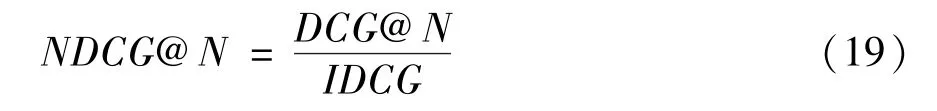
这里DCG表示折损累计增益,是在累计增益CG的基础上引入了位置影响因素,计算公式如下:
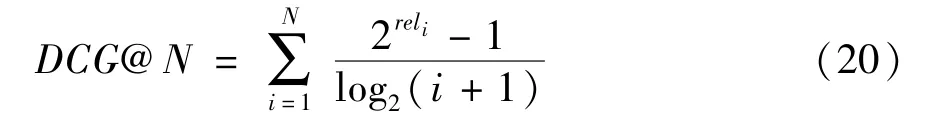
可以看出,推荐的相关性越多,DCG值越大,相关性强的排在推荐列表前面的话,推荐效果越好,DCG值越大。在式(19)中,IDCG表示推荐系统针对某一用户返回的最好推荐列表,即假设返回结果按照相关性排序,最相关的结果排在最前面的情况下的DCG值。由定义可以看出NDCG的值为(0,1]。
3.4 推荐任务
表2 是各种对比方法在HR@5、HR@10、NDCG@5 以及NDCG@10 指标上的实验结果。可以看出本文方法与其他对比方法相比在推荐任务方面表现更佳,下面对实验结果进行详细分析。
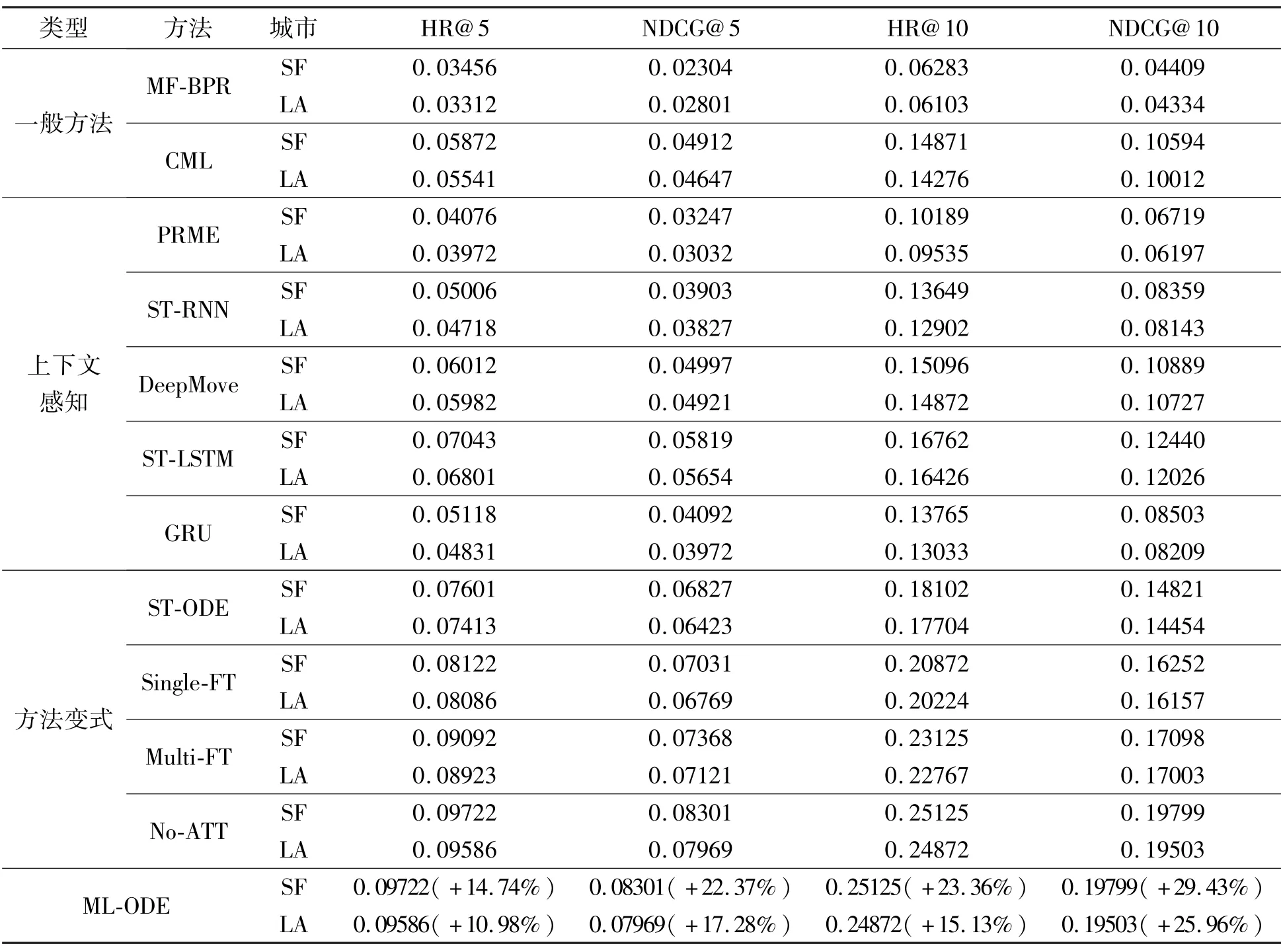
表2 各类方法在POI 推荐任务上的结果统计
(1)上下文信息的重要性。由实验结果可以看出,利用时空上下文信息的方法(如PRMF、STRNN、DeepMove、ST-LSTM、ST-ODE 等)在推荐任务上要优于没有利用上下文信息的方法(MF-BPR 和CML)。可以看出上下文信息在推荐任务中起着至关重要的作用,有助于模型捕捉用户签到行为时空上的序列关系,提升推荐效果。文献[31]也通过大量的实验论证了上下文信息对POI 推荐的重要性。
(2)神经网络的优势。由实验结果可以看出,基于矩阵分解的方法(如MF-BPR 和PRME)在推荐效果上欠佳,而基于神经网络的方法(如STRNN、GRU、DeepMove、ST-LSTM、ST-ODE 等)在推荐任务上要更好。可以看出单纯的矩阵分解方法在捕捉用户的高阶关系上效果较差,而神经网络由于可以建模用户更高阶的潜在关系,推荐效果要优于传统的矩阵分解方法。
(3)连续时间建模的优势。由实验结果可以看出,将签到行为序列看成等间隔进行建模的方法(如STRNN 和DeepMove)在推荐效果上要略逊于时间敏感的推荐方法(如ST-LSTM 和ST-ODE),签到行为的时间依赖也是用户兴趣点推荐不可忽视的因素。并且本文提出的基于Neural ODEs 的方法可以建模连续时间序列,从实验结果可以看出,ST-ODE进一步提升了时间敏感类方法在POI 推荐上的性能。
(4)时空注意力机制的优势。由实验结果可以看出,借助于时空注意力机制的ML-ODE 在推荐效果上要优于不使用注意力机制的No-ATT 方法,主要原因在于时空注意力机制对用户偏好的权重进行了更好地建模,并克服了在长时间序列传播过程中的知识损失,提升了POI 推荐效果。
(5)知识迁移的必要性。根据表2 针对知识迁移的必要性进行实验论证,通过ML-ODE 的几个进阶版本进行对比实验。ST-ODE 仅利用目标城市的数据进行训练,即没有基于元学习机制进行参数的初始化。Single-FT 是利用单个源城市对目标城市的参数进行更新。Multi-FT 是将多个源城市的数据进行混合之后无差别地对目标城市的时空模型进行初始化更新。由实验结果可以看出,将多个城市视为不同的推荐任务来借助元学习进行初始参数学习的ML-ODE 方法具有更加优异的表现,NDCG@10在两个城市的性能提升均超过了25%。Multi-FT 的方法较Single-FT 表现更好,可能是由于多个城市数据混合之后在一定程度上缓解了由于数据分布差异性对学习移动知识的通用性的影响。除此之外,ML-ODE比Multi-FT 表现更佳,说明了元学习框架在知识迁移方面的优势,通过多任务的分解可以更好地学习模型的初始化参数。
3.5 模型参数设置
本小节将详细描述ML-ODE 各种参数的设置情况并分析其对模型性能的影响。在ML-ODE 对比实验中,对所有方法都是采用5 折交叉验证,并且中间状态传播过程中的隐状态维度均设置为50。在参数训练过程中,dropout 的取值范围为[0,0.1,0.2,0.3],weight decay 的取值范围为[0.1,0.03,0.01,0.003,0.001,0.0001,0],learning rate 的取值范围为[0.001,0.003,0.0001]。通过5 折交叉验证,每次留20%的验证数据集对上述参数训练的ML-ODE 参数进行评估,模型表现最优时的dropout值为0.2,weight decay 的值为0.001,learning rate 的值为0.003。
除此之外,在进行Top-N 推荐任务的过程中,通过将参数N在取值范围[1,5,10,15,20,25,30,35,40,45,50]内进行变化,观察不同模型的表现情况,实验结果如图6~图9 所示。可以看出模型在N的取值范围内表现均优于其他对比实验方法。同时,相较于HR@ N 指标,ML-ODE 在NDCG@ N 上的提升效果更加明显。将图8 和图9 进行对比发现,在旧金山数据集上,ML-ODE的NDCG@N的提升效果更加明显。在洛杉矶数据集上也发现了类似现象,说明在排序结果中,高关联度的结果出现在更靠前的位置,具有更高的累计增益值。
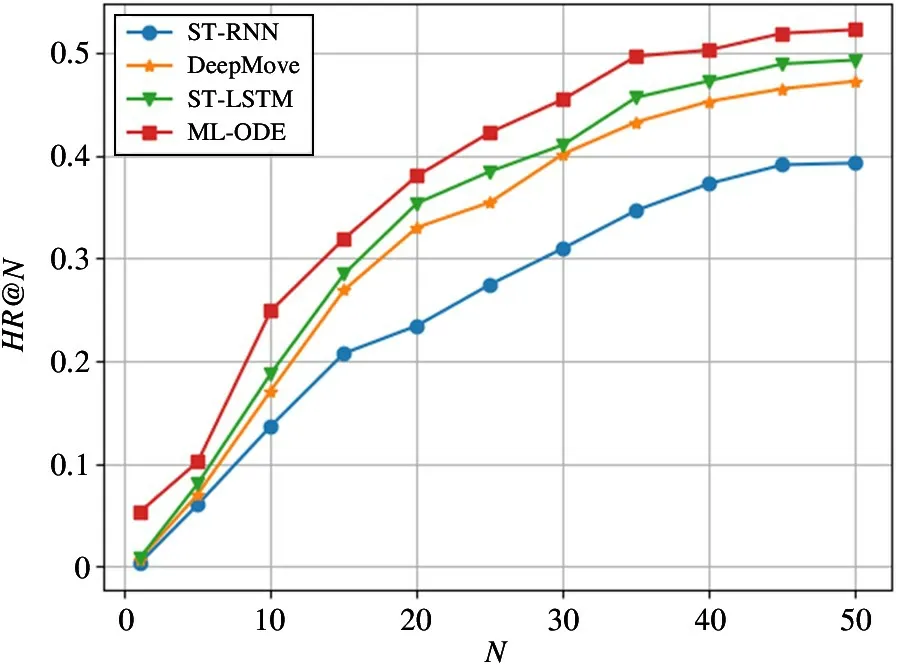
图6 在旧金山数据集上的HR@N 结果
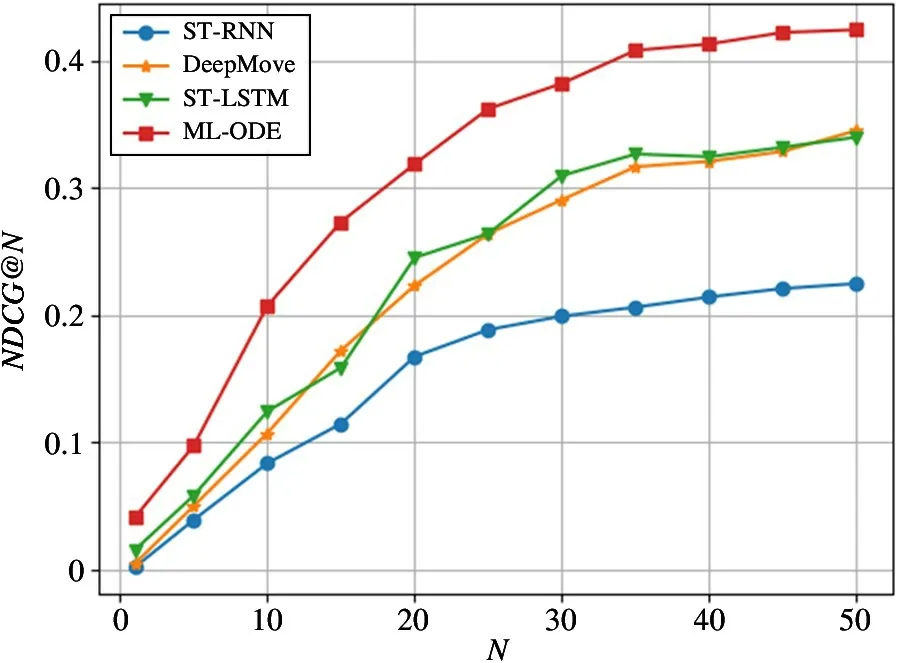
图7 在旧金山数据集上的NDCG@N 结果
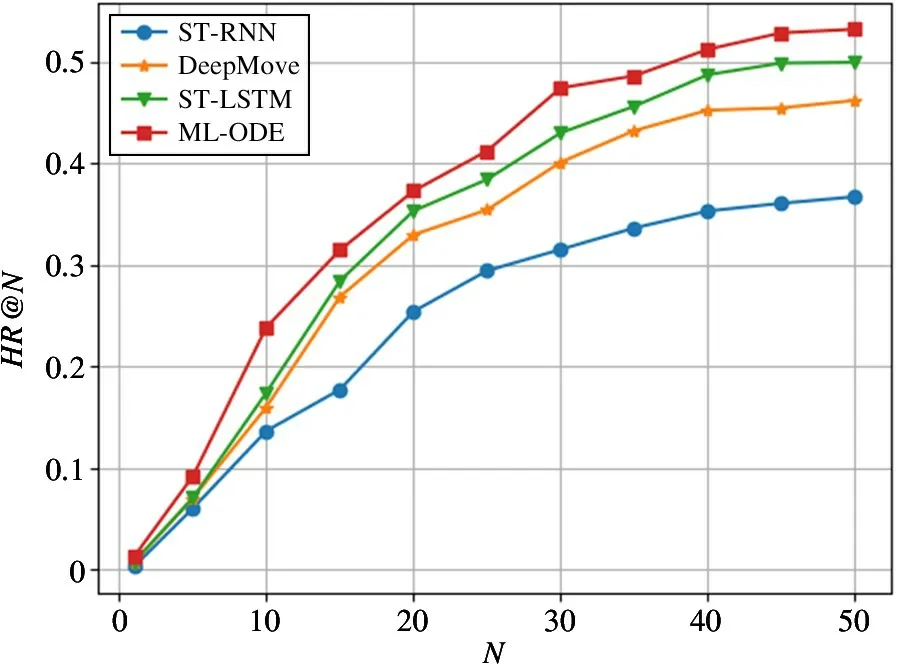
图8 在洛杉矶数据集上的HR@N 结果
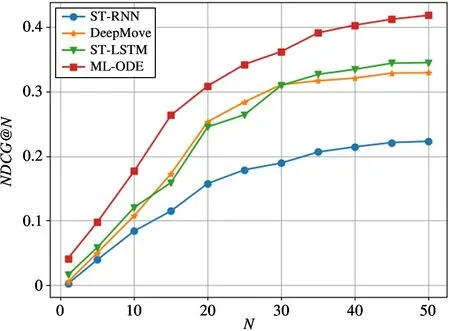
图9 在洛杉矶数据集上的NDCG@N 结果
4 结论
针对兴趣点推荐,本文提出了一种基于元学习的时空Neural ODEs 模型(ML-ODE)。首先,利用基于时空神经常微分方程的时空关系学习模块进行用户的时空兴趣建模。其次,在模型中借助基于贝叶斯的更新模块根据用户的签到记录对时空神经常微分方程预测的用户隐状态进行更新,更好地学习用户签到行为的时空序列依赖。除此之外,借助于元学习机制进行时空神经常微分方程的参数初始化学习,在进行参数初始化的过程中,有效地将数据丰富城市的移动行为知识进行迁移,提升模型在数据匮乏城市的POI 推荐效果。最后,在真实的公开LBSNs 数据集上进行实验,实验结果有效地验证该方法的推荐效果,并证明了ML-ODE 在HR@N 和NDCG@N 指标上相比当前先进的兴趣点推荐技术有了明显提高。
在未来的工作中,将进一步考虑高效的面向稀疏POI 签到数据的POI 推荐方法,并将从以下几个方面进行尝试:(1)结合分布式机器学习技术,将ML-ODE 进行分布式算法扩展,结合GPU、TPU 等高效计算方式,让分析超大规模POI 数据成为可能;(2)解决ML-ODE 动态更新问题,在实际应用场景中,用户的签到行为是动态变化的,而目前大多数的推荐方法都是建立在离线静态POI 签到数据上,所以对网络中动态POI 签到行为进行合理化建模,实现合理的在线参数更新机制,值得更多的关注;(3)计划引入用户的长期兴趣偏好,或者结合主题模型等用户长期兴趣建模方法,进一步提升兴趣点推荐系统的性能。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
小学生学习指导(低年级)(2020年11期)2020-12-14
作文大王·低年级(2018年10期)2018-12-06
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
小猕猴智力画刊(2016年5期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
