
科研主题演化中三种典型社区发现算法对比研究
——以植物甾醇信号为例①
2021-02-11 05:01:28韩红旗张均胜
高技术通讯 2021年11期
薛 陕 董 诚 韩红旗 张均胜 高 雄 王 力
(中国科学技术信息研究所 北京100038)
0 引言
科研主题演化是衡量科研主题随时间推移表现出的动态性、发展性和差异性的研究。科研主题演化一般包含两方面含义:其一是科研主题内容随着时间推移而发生变化,其二是不同科研主题之间复杂的承继关系。其中,主题识别是演化分析的基础和关键因素。目前主题识别的主流方法可分为基于语言模型的方法[1-2]和基于网络社区发现的方法[3-4]。基于网络社区发现的主题识别方法由于速度快、社区划分比较准确,目前已经成为科研主题识别的主要方法[5-7]。
社区(community) 是社会网络中的常见现象,由一群高度聚集、联系紧密的节点聚集组成,在各种知识网络中普遍存在社区结构[8-10]。社区结构研究可以追溯到1977 年Zachary[11]对空手道俱乐部成员关系网络的研究。Girvan 和Newman[12]在对社会网络的研究中提出了著名的(Girvan-Newman)GN社区发现算法,随后的研究发现在物理学家合作网络中同样存在社区现象[13]。Boyack 等人[14]在利用7121 种期刊数据集绘制科学景观鸟瞰图的研究中也发现了类似的社区结构。Lambiotte 等人[15]发现存在于知识网络层面的社区,是一种划分知识领域和学科前沿的新视角。
由于构成网络的数据集的不同,网络中的社区结构往往存在不同特点,不同社区算法对特定网络社区识别效果存在差异[16]。社区发现算法对主题识别效果直接影响了主题演化结果和路径的判断。因此,有必要对当前主要社区发现算法的效果进行对比研究,了解其效果以及适用性能。本研究以植物甾醇信号相关文献关键词共现网络为实例,选取3 种典型社区发现算法对其主题发现和演化追踪效果进行了对比,并结合专家知识对植物甾醇信号主题研究现状和演化趋势进行了分析解释。
1 相关研究
网络社区结构的聚类方法与计算机科学中的图形分割(graph partition) 和社会学中的分级聚类(hierarchical clustering)[17-18]有着密切联系。复杂网络社区识别方法按照聚类算法的不同可以分为以下几类:基于谱平均法的聚类算法、基于分裂的聚类算法、基于凝聚的聚类算法以及基于重叠社区的聚类算法。计算复杂度以及准确性是分析复杂网络社区结构面临的主要问题。如表1 所示,谱平均法难以适用于社区结构复杂的网络结构,而以GN 算法[12]为代表的分裂算法由于运算复杂不适用于大型网络,因此本文不再选用这两种算法进行研究。目前已有的研究发现基于凝聚的方法[19]和基于重叠社区[9]的方法在处理复杂网络社区划分中具有较好的效果[20]。因此本文选取基于凝聚的聚类算法中具有代表性的Newman MM 算法[13,19]、Blondel算法[21]以及基于重叠社区发现的Ball Overlapping算法[22]作为研究对象。以植物油菜素甾醇研究领域的关键词共现网络为例,对这几种社区发现算法的社区划分速度、准确性以及在演化分析过程中的适用性进行了对比,揭示了它们在主题演化研究中的优点与不足。
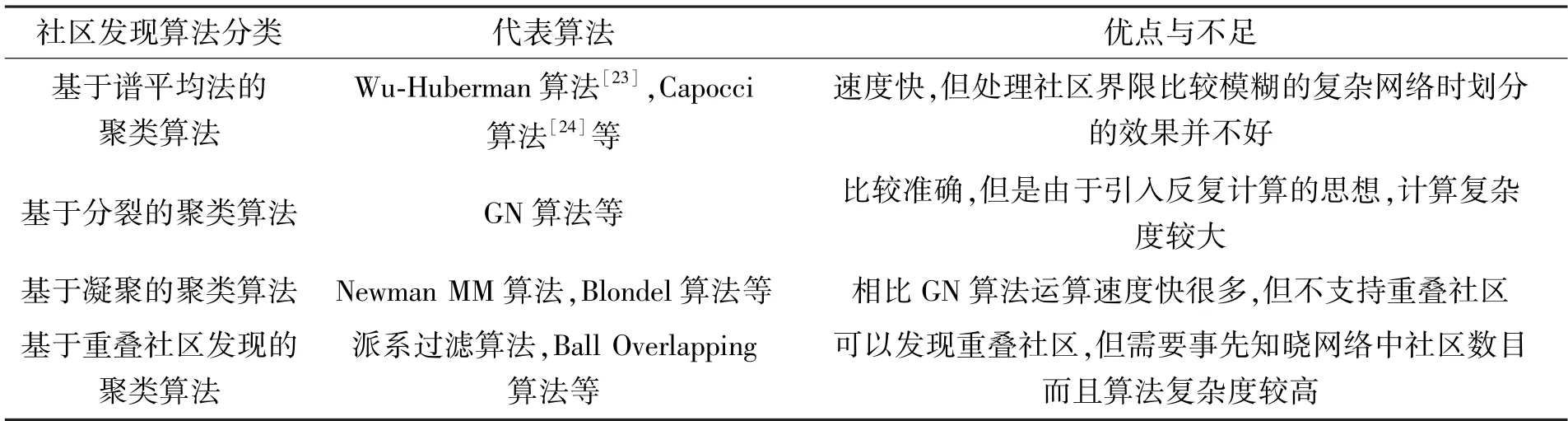
表1 常用社区发现算法的分类与优缺点对比
2 实验方法设计
2.1 实验数据
以2010 年为分界点,2010 年之前每年关于植物甾醇信号的研究不到50 篇,2010 年之后每年文献的数量迅速增长,到2017 年到达顶峰,有141 篇文献。因此将文献检索时间限定为2010 -2017 年,以检索式“Brassinosteroids”[MeSH Terms] or“Brassinosteroids”[AllFields] or“Brassinosteroid”[All Fields]从Pubmed 数据库检索,获得关于植物油菜素甾醇研究文献962 篇。
2.2 关键词共现网络的构建
对收集到的962 篇文献进行处理,按年份为尺度对文献进行分割。以关键词为节点,关键词的共现关系为边,构建了每年的关键词共现网络,各关键词网络指标见表2。

表2 2010 -2017 年植物甾醇激素领域关键词共现网络部分指标
2.3 科研主题演化的计算和可视化展现
经过调研,选择文献[25]提出的相似度计算公式作为不同时间窗口的主题相似度的测度。该公式基于节点重合度计算两个社区的相似度,能够较好地反映两个主题之间的相似性。给定社区Mx和社区My,各自对应的词汇集合为Cx、Cy,它们的相似度按式(1)定义为
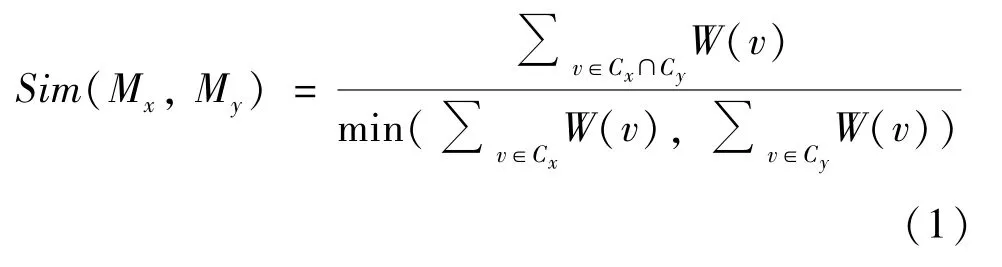
其中,W(v) 表示节点的频次,min(x,y) 为x和y中较小的值。如果前后两个连续时间段中的社区相似度超过设定的阈值,则认为两个社区存在演化关系。社区M(T+1)j的前驱定义见式(2)。
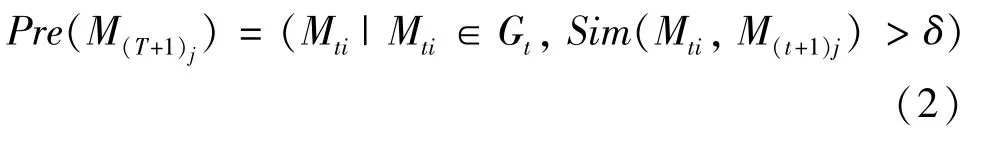
其中,δ是可调节的阈值,根据经验取值为0.3。为了判断社区的演化形式,本研究参考了文献[9,26]所提出的方法,将网络社区的演化过程定义为6 种形式,分别是产生、消亡、分裂、融合、扩张和收缩。主题演化的可视化则采用可视化软件NEViewer 以河流图形式展现。
2.4 基于专家知识的社区发现算法效果的比较
由于在复杂网络的社区分割中不存在有效的精确解法(该问题是一个NP 难题)[27-29],因此很难定义一个量化指标并从准确性的角度评价不同算法的优劣。为了比较社区发现算法的聚类识别性能,以确定效果最好的主题识别算法,本研究邀请领域专家对收集的文献集进行了主题标引,结合专家标引的结果对Newman MM 算法和Blondel 算法的社区划分以及主题演化分析效果进行了对比。
3 结果及分析
3.1 三种典型社区发现算法社区划分效果的比较
目前基于复杂网络理论的主题聚类算法有很多,经过调研,选取其中使用较多、有代表性的3 种算法:Newman MM 算法、Ball Overlapping 算法和Blondel 算法,对文献关键词所组成的共词网络进行了社区划分,并对这3 种算法的社区划分性能进行了比较。从运算速度上看,Blondel 算法最快,仅用21 s;Ball Overlapping 算法次之,用时139 s;Newman MM 算法最慢,用时977 s,约是Blondel 算法的46倍,Ball 算法的7 倍。社区具体内容如表3 所示,在社区识别结果上,因为Ball Overlapping 算法是支持重叠社区识别的,因此产生了很多重复的社区关键词。以识别到的10 个社区为例,其中有8 个社区的关键词都是重复的,表明该算法对该数据集的支持性不好。Blondel 算法和Newman MM 算法在社区识别效果上比较接近,Blondel 算法发现了12 个社区,Newman MM 算法发现了10 个社区。这2 种算法发现的社区的代表性关键词也具有较好的解释性,如Mutation(突变体)、Plants、Genetically modified(转基因植物)、Signal Transduction(信号传导)等都是植物甾醇激素领域研究的热点主题,而且基本没有产生重复的关键词。因此之后的研究中可着重针对这2 种算法作对比。
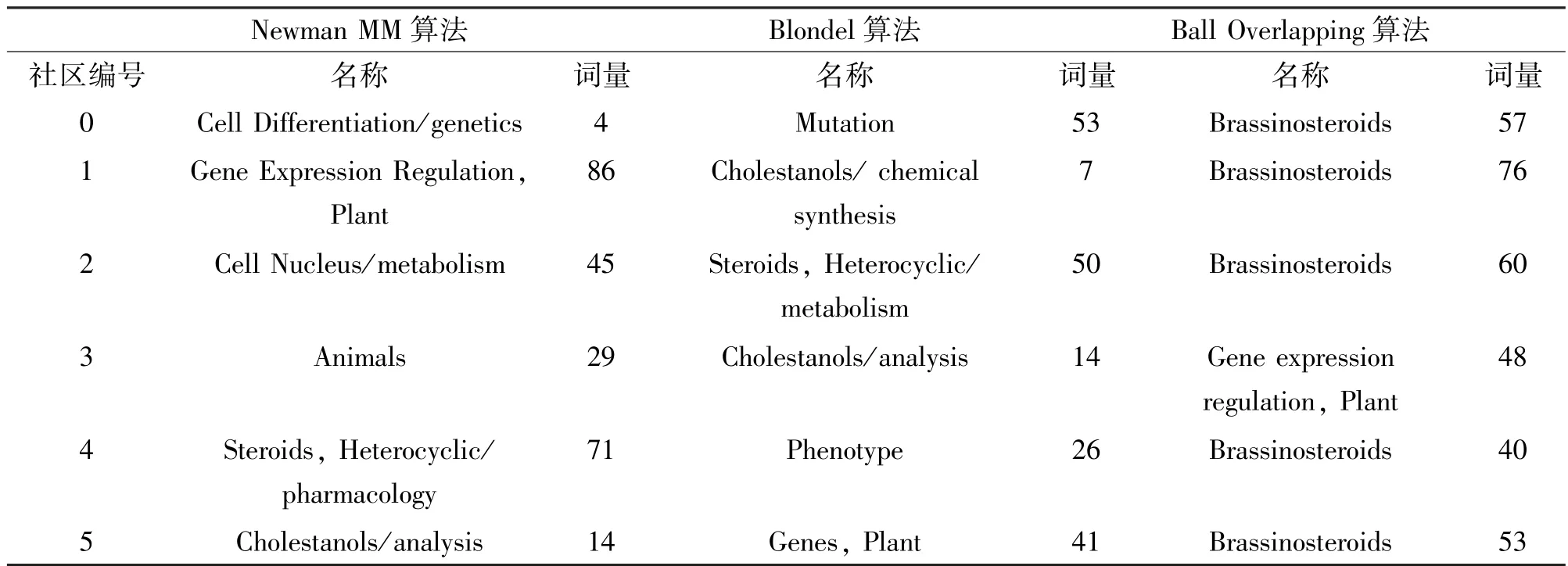
表3 3 种社区发现算法的社区内容

续表3
3.2 科研主题演化的计算和可视化
由于2010 -2017 年间的文献总共有926 篇,如果这些文献都由专家进行主题标注的话,专家的工作量会很大。因此本文只选取了2010 -2014 年的文献集为例。采用2.3 节所述方法,对这5 年的植物甾醇激素领域相关文献的主题进行了识别和演化追踪,并通过可视化软件NEViewer 将主题的演化结果进行可视化展现。图1 展示了采用Blondel 算法绘制的主题演化河流图,图2 展示了采用Newman MM 算法绘制的主题演化河流图。
如图1 和图2 所示,在河流图中将侦测到具有演化关系的主题用相同颜色的条带表示,而条带的粗细则代表组成该主题关键词的多少。对比2 种算法绘制的河流图可以发现,通过Blondel 算法划分的社区侦测到的主题演化状态更为丰富,社区的6 种演化状态(产生、消亡、分裂、融合、扩张和收缩)都有发现。而基于Newman MM 算法划分的社区演化状态比较单一,没有发现融合状态的社区,这与专家判断的实际情况不符。
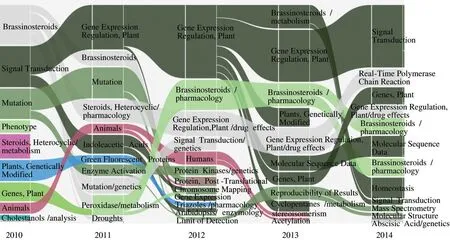
图1 植物甾醇激素领域的主题演化河流图(Blondel 算法)
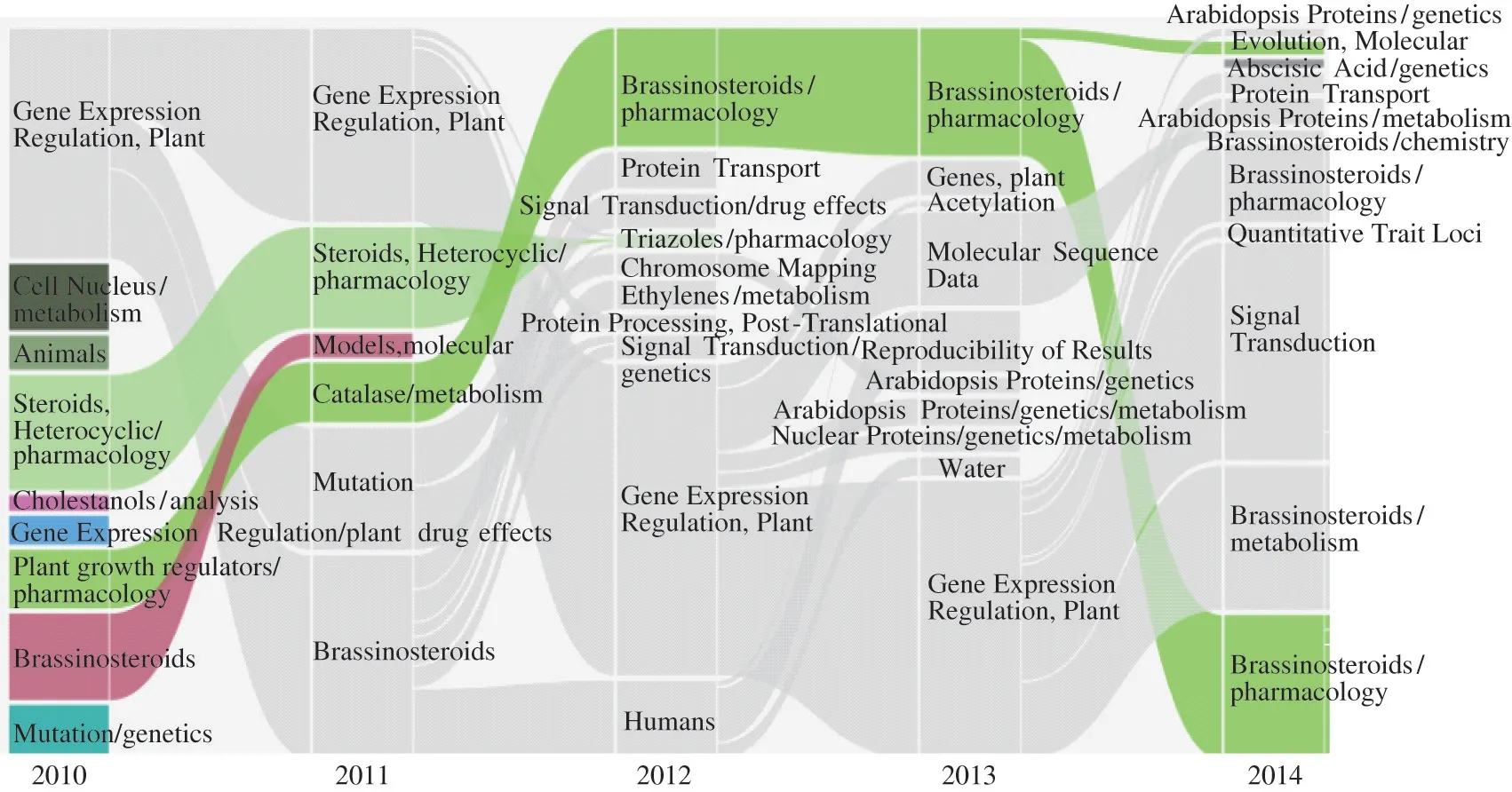
图2 植物甾醇激素领域的主题演化河流图(Newman MM 算法)
3.3 基于专家知识的社区发现算法准确性的比较
为了评价这2 种社区发现算法的演化分析结果的优劣,邀请了中科院植物所的专家,利用专家的知识对Newman MM 算法和Blondel 算法的社区划分效果进行对比。以Animals 这个主题为实例说明专家的判断结果。Animals 主题在2010 年的数据集中,Newman MM 算法和Blondel 算法都发现了此主题。不同的是,Blondel 算法在2011 年侦测到主题Animals 的后继主题状态为扩张,而Newman MM 分区算法没有侦测到主题Animals 的后继主题。将Blondel算法侦测到的主题Animals的演化网络从整体网络中单独提取出来,以河流图形式进行可视化展现,结果见图3。
如图3 所示,2010 年组成Animals 主题的关键词数量只有29 个。2011 年该主题发生扩张,关键词数量增加到31 个。2012 年该主题进一步扩张,关键词增加到71 个,并且中心度最高的关键词由Animals 演化为Humans。2013 年该主题发生分裂产生了2 个新生主题:Stereoisomerism(立体异构)和Acetylation(乙酰化)。

图3 主题Animals 的演化河流图(Blondel 算法)
为了验证Blondel 算法获得的Animals 主题演化路径的准确性,需要借助专家知识对2011 -2014年的文献主题进行标注和分析,如果发现有Animals相关研究组成的主题则说明Blondel 算法较为准确。如果没有发现Animals 相关研究组成的主题,则说明Newman MM 算法较为准确。因此中科院植物所的领域专家受邀对文献集进行了主题标注,标注结果如表4 所示。
由表4 可知,从2010 年开始到2013 年,与动物有关的Brassinosteroids 研究文献一直存在并呈上升趋势,2010 年4 篇,2011 年6 篇,2012 年7 篇,2013年9 篇。主题内容上可以分为Brassinosteroids 对动物细胞的毒理研究、植物甾醇与动物甾醇的功能比较、Brassinosteroids 的化学修饰。

表4 专家对Animals 主题文献知的主题标注结果
2010 年主题Animals 的研究内容主要为Brassinosteroids 对动物细胞的毒理研究,其中有3 篇的研究对象为实验动物(小鼠、大鼠及牛),但也有1 篇关于人类胸腺肿瘤细胞的研究。2011 年研究该主题的文献扩大为6 篇,但研究还是以实验动物为主。到了2012 年研究该主题的文献扩大为7 篇,其中有6 篇是关于动物细胞的研究,当年关于人类细胞的研究共有5 篇文献,而关于小鼠的研究下降为1 篇。2013 年该主题进一步发生分裂产生了Brassinosteroids 的化学修饰这个研究主题,包括乙酰化修饰1篇,立体异构体3 篇。这与Blondel 算法获得的Animals 主题演化路径基本是一致的。
由以上结果可知,从2010 年开始到2013 年,Animals 这个主题是存在的,并且其研究内容发生了从以实验动物为主到以人类细胞研究为主的转变。结合专家知识绘制了该主题的演化模式图,证明Blondel 算法得到的Animals 主题演化路径是比较准确的。如图4 所示。
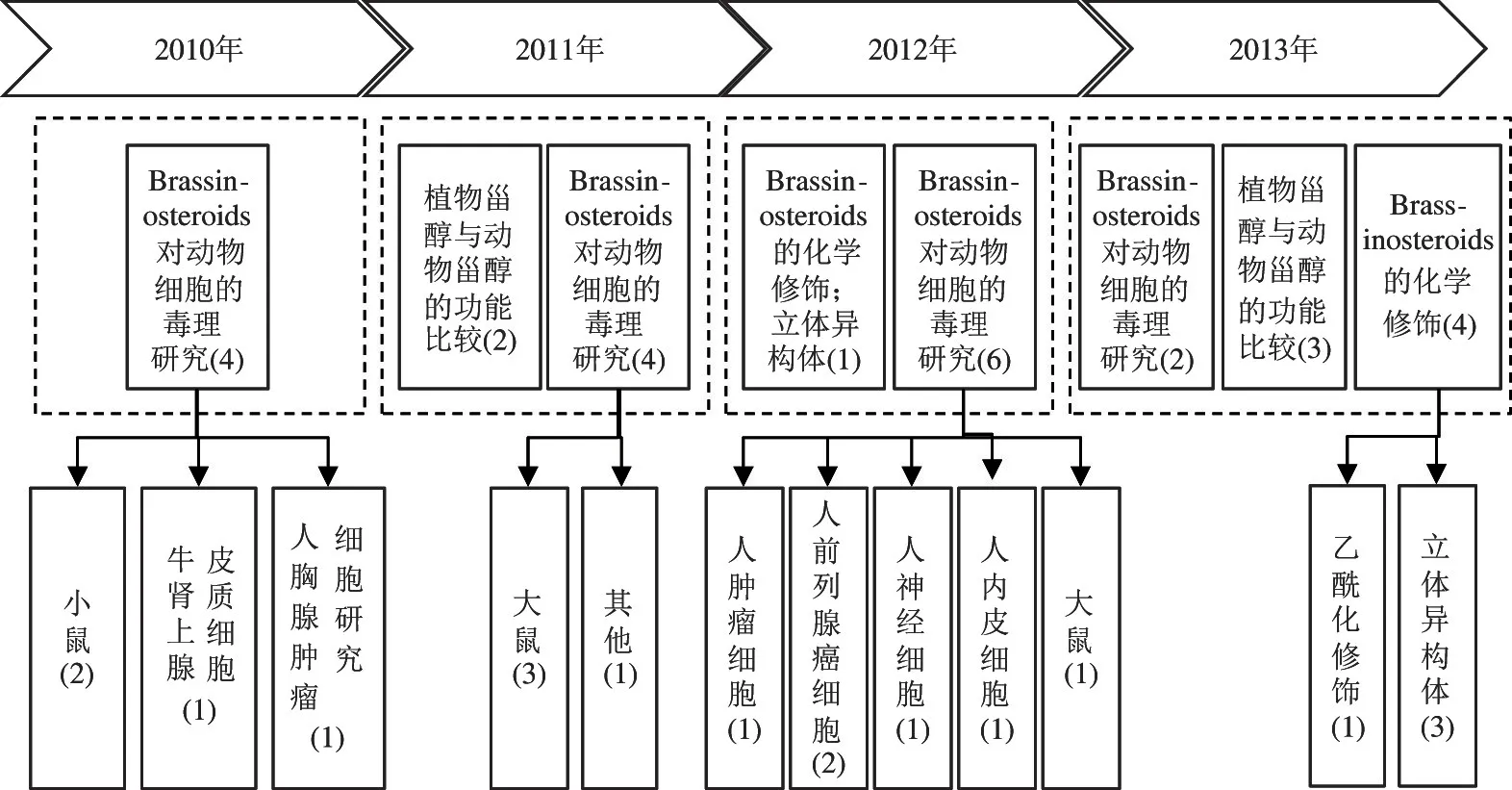
图4 专家解读绘制的Animals 主题演化图
4 结论
本研究对Blondel 算法、Newman MM 算法和Ball Overlapping 3 种典型的社区发现算法的社区划分效果和准确性进行了对比研究。在植物甾醇领域的实验研究总结如下。
(1)3 种社区发现算法的主题识别效果比较表明:在运算速度上Blondel 算法最快,Ball Overlapping 算法次之,Newman MM 算法最慢。而在社区识别效果上Blondel 算法和Newman MM 算法比较接近,识别到的社区其代表性关键词也具有较好的解释性。
(2)基于河流图的植物甾醇激素领域的主题演化可视化结果表明:采用同样的社区演化追踪方法,通过Blondel 算法划分的社区侦测到的主题演化状态更为丰富,而基于Newman MM 算法划分的社区演化状态比较单一。
(3)以Animals 主题作为实例,比较Newman 和Blondel 2 个算法发现主题的准确性可以看到:此主题在2010 年的数据集中Newman MM 算法和Blondel 算法都有发现。不同的是,Blondel 算法在2011年侦测到Animals 后继主题状态为扩张,并且到2013 年为止都有后续主题的发现;而Newman MM分区算法则没有侦测到Animals 的后继主题。以上为算法生成的演化路径。
(4)该领域专家解释的演化路径显示,从2010年开始到2013 年,Animals 这个主题是一直存在的。并且研究对象经历了以实验动物为主到以人类细胞为主的转变。这证明Blondel 算法得到的主题Animals 演化路径是比较准确的。
根据植物甾醇领域文献的实验结果可以得知,3种算法中Blondel 算法获得的主题和演化追踪最为准确,它不仅可以很好地实现关键词共现网络的社区划分,而且能更好地发现科研主题的演化。
基于复杂网络理论的社区发现和演化算法为研究科研主题演化追踪提供了一种新的思路。该方法得到的主题演化数据具有较好的解释性,但同时存在一些不足之处。其一是这种方法比较依赖于关键词数据,一般只适用于结构性比较强的文献数据;其二是有些文献关键词的选择存在随意性[30],不一定能很好地反映文献的内在特征,忽略了对文献内容的分析因而具有一定局限性。未来的工作可以尝试在该方法中融入基于文献内部特征提取的方法,以实现对非结构化数据主题演化的研究。
猜你喜欢
食品安全导刊(2022年32期)2022-12-07 05:36:08
速读·下旬(2021年11期)2021-10-12 01:10:43
大东方(2019年12期)2019-10-20 13:12:49
电子测试(2017年15期)2017-12-18 07:19:27
科学与财富(2017年22期)2017-09-10 13:20:02
商情(2017年1期)2017-03-22 16:56:36
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
中国粮油学报(2014年8期)2014-02-06 01:34:23
