
深度学习的图像实例分割方法综述
2021-02-04 13:51张继凯吕晓琪聂俊岚
小型微型计算机系统 2021年1期
张继凯,赵 君,张 然,吕晓琪,聂俊岚
1(内蒙古科技大学 信息工程学院,内蒙古 包头 014010) 2(内蒙古工业大学,呼和浩特 010051) 3(燕山大学 信息科学与工程学院,河北 秦皇岛,066004)
1 概 述
实例分割是计算机视觉领域的一个经典任务,它将整个图像分成一个个像素组,然后对其进行标记和分类.分类任务就是识别单个对象的图像是什么,而分割需要确定对象的边界、差异和彼此之间的联系.所以,实例分割既具备语义分割的特点,对图像中的每一个像素进行分类,也具备目标检测的一部分特点,定位出图像中同一类的不同实例.通常实例分割要面对多个物体重叠和复杂的背景,这也是为什么实例分割一直是一项挑战性的任务.以往,实例分割方法的思路可大体分为两大类,一类是自上而下的基于检测的方法,在边界框中处理实例分割,即在边界框中分割对象.另一类是自下而上的基于语义分割的方法,此类方法可概括为对像素进行标签预测然后聚类.而SOLO算法[1]的出现,创造了第3类实例分割方法,直接实例分割方法,通过掩膜标签,对实例分割进行端到端的优化,突破传统的局部边框检测和像素点聚合方法,直接进行像素级别的实例分割.综上所述,本文针对近几年基于深度学习的实例分割方法进行分类梳理,整理如图1所示.
实例分割和物体检测非常相关,在物体检测的基础上,要求分割出物体的像素,所以在一定意义上,目标检测的发展也影响着实例分割的性能.目前基于深度学习的目标检测算法可分为包含两次目标检测过程的两阶段检测算法和包含一次目标检测过程的单阶段检测算法,两阶段检测算法的精度普遍高于单阶段检测算法的原因是经过两次目标检测提升了算法的准确性,但同时也增加了模型复杂度,制约了模型计算效率的提高.单阶段检测算法结构简单、计算效率高,能够方便地进行端到端的训练,在实时目标检测领域中有很大的应用潜力.最近的一些为实现实时的实例分割方法进而选择单阶段检测器作为目标检测框架,推动了单阶段实例分割方法的发展.本文首先介绍了实例分割方法的分类,然后介绍了图2所示的典型算法,并对其模型进行了深入分析,最后对实例分割方法的发展趋势进行了展望和总结.

图1 基于深度学习的图像实例分割方法Fig.1 Image instance segmentation method based on deep learning

图2 本文重点阐述的图像实例分割方法Fig.2 This article focuses on the image instance segmentation method
2 自上而下的基于检测的方法
自上而下的基于检测的方法是先检测再分割,先利用先进的检测器如Faster R-CNN[2]检测每个实例的区域,然后在每个区域内分割出实例掩膜.基于检测的方法通常精度较高且依赖于准确的边界框检测,计算量很大.
2.1 Mask R-CNN
实例分割不仅要求能准确识别所有目标,还需要分割出单个实例.2017年He等提出 Mask R-CNN[3]算法,该算法是在Faster R-CNN的基础上添加一个与分类和边界框回归分支并行的掩膜分支来预测分割掩膜.Faster R-CNN是在R-CNN[4]系列算法的基础上提出RPN网络来得到准确的候选区域,是一个实现多物体分类与定位的端到端检测模型.由于Faster R-CNN的输入输出网络采用的是ROIPool,在计算映射坐标时进行了四舍五入,导致ROI与提取的特征不对齐,这对预测像素级的掩膜有很大影响.针对取整误差,Mask R-CNN提出RoIAlign层来消除RoIPool的量化误差,使用双线性插值来更精确地找到每个块对应的特征,从而正确地将提取的特征与输入对齐.
继Mask R-CNN之后,Masklab[5]加入了方向特征用于分割同一类别的实例,利用方向预测估计每个像素与其对应的实例中心的方向,实现分割同一语义类的实例.PANet[6]引入了自底向上的路径增强、动态特征池化和全连接层融合,以提高实例分割的性能.Yan等使用Mask R-CNN模型提取目标肺结节边缘像素坐标,并引入Sobel算子来加强边缘像素点的检测,然后使用阈值分割的方法进行降噪,增强了模型对细小肺结节的分割效果[7].针对复杂物体分割缺失严重,边缘不清晰等问题,Zhan等提出一种结合多种图像分割算法的实例分割方案,得到更加精细的分割掩膜[8].虽然Mask R-CNN及其改进在实例分割和检测精度方面具有很好的效果,该类算法最大缺陷是检测速度难以满足实时的需要,其次mask分支的分辨率被固定在一定的尺寸导致其产生的掩膜较粗糙,难以应用在实际中.
2.2 Mask Scroing R-CNN
针对Mask R-CNN算法中采用分类置信度作为评价掩膜的质量分数,但掩膜的分割质量与分类置信度没有太强的关联,所以Mask Scroing R-CNN[9]采用预测掩膜与标注掩膜的交并比MaskIoU来描述掩膜的分割质量,并添加一个新的分支MaskIoU Head,将预测的MaskIoU和分类的分数相乘得到掩膜分数,该分数既能识别语义类别,又能识别实例掩膜的完整性.通过掩膜打分从而预测出实际掩膜的质量分数,使网络优先输出更完整的掩膜,进而提高实例分割的性能.Mask Scroing R-CNN简称MS RCNN,网络框架如图3所示.
该方法的改进不同于之前对实例定位或分割掩膜的改进,而是侧重于对掩膜进行打分,通过校正掩膜质量和掩膜评分之间的偏差,使网络优先考虑更准确的掩膜预测.缺点是具有较高分类分数的低质量掩膜会影响重叠对象的分割性能,因为网络会将重叠部分分配给分类得分较高的掩膜.Liu等受到Mask Scoring RCNN的启发,设计了一个简洁的掩膜质量分支,将前景得分图与ROI特征图融合来预测掩膜的质量,减轻了预测掩膜质量与分类分数之间的不一致,提高了分割精度[10].Kang等提出了评分掩模,通过假边界和真边界之间填充不同值来更有效地学习边界以提高实例分割的性能[11].虽然给掩膜打分比较新颖,对后续工作也有一定的启发意义,但新增的打分分支导致掩膜与检测分支相关,使掩膜受限于box.
2.3 PolarMask
两阶段的实例分割方法精度高但速度较慢,为提高分割速度,单阶段的实例分割方法相继提出.InstanceFCN[12]网络通过一组实例敏感的得分图,使用组装模块在滑动窗口中生成实例.TensorMask[13]使用结构化的4D张量表示空间域上的掩膜,研究了密集滑动窗口的实例分割范式.相较于逐像素的密集回归方法,利用极坐标的方法预测轮廓的点来分割实例的方法更简洁,Schmidt等利用极坐标表示法检测显微图像中的细胞[14],ESESeg[15]方法使用极坐标对实例进行建模.受其上的两种方法的启发,Xie等提出单阶段实例分割方法PolarMask[16],在无锚框的目标检测算法FCOS[17]的基础上进一步细化边界轮廓,使其适用于掩膜分割任务.该算法基于极坐标系对轮廓进行建模,且轮廓上的点由距离和角度确定,由于预先设置了角度间隔,网络仅需要预测出射线长度,根据样本中心和射线长度,计算出相应轮廓点的坐标,然后由样本中心从0°出发,连接每一个轮廓点,最终得到目标的轮廓及其掩膜如图4所示.

图3 Mask Scroing R-CNN网络结构Fig.3 Mask Scroing R-CNN network structure
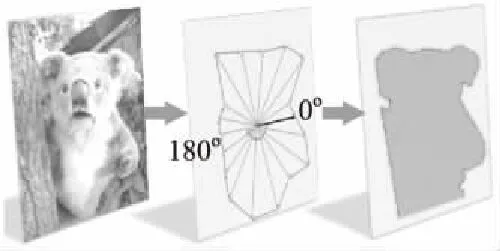
图4 PolarMask轮廓及掩码生成Fig.4 PolarMask contour and mask generation
该方法是将实例分割转化为两个并行任务:实例中心点分类和密集距离回归来共同预测实例轮廓.为了进一步优化正样本采样和密集距离损失函数,提出Polar CenterNess和Polar IoU Loss.Polar CenterNess为预测的极中心点分配权重,权重乘以分类分数来挑选出高质量的正样本,使射线的回归距离更加准确.Polar IoU Loss近似计算出预测掩膜与标注掩膜的交并比来优化掩膜的回归,使掩膜分支快速且稳定收敛.虽然构思巧妙,对后续的实例分割研究有启发意义,但缺点是使用极坐标预测的多边形掩膜比真实掩膜要粗糙,且只能描绘出单个实例的轮廓.针对PolarMask对非圆形物体预测的中心居中度低的问题,Benbarka等提出归一化中心度来保留非圆形物体的位置并增加被预测的可能性[18].受到Polarmask多边形分割的启发,Hurtik等提出在特定的边界框中学习与大小无关的多边形轮廓,并且多边形顶点的数量可以动态调整以便精确分割形状复杂的物体[19].
2.4 YOLACT
计算机视觉中学习模板的方法应用广泛,文献[20,21]设计了表示特征的原型模板进行目标检测,而在实例分割领域中YOLACT[22]也利用不同模板组合进行实例分割.YOLACT类似于SSD[23]和YOLO[24]系列对弥补目标检测无单阶网络所做的工作,致力于填补实例分割单阶段网络的空白.YOLACT在单阶段检测器上添加一个掩膜分支来分割实例,且不添加特征定位步骤如repooling,得到更为精细的分割掩膜.
YOLACT为每张图片生成k个原型掩膜并预测k个掩膜系数,一个系数对应于一个原型掩膜.将正/负掩膜系数线性组合原型掩膜得到最后的预测结果.YOLACT网络结构如图5所示.为了提高并行分支的运算速度,YOLACT提出了一种Fast NMS算法代替传统的NMS,使用矩阵表示候选框的得分并同时能删除多个低于阈值的候选框,对精度影响较小的同时加快了NMS的计算速度.
由于YOLACT的实时性和通用性,Bak等采用YOLACT对电影中的视频帧先进行语义分割,然后使用CNN[25,26]对镜头分类,实现对各种电影的分析与分类[27].Konya等通过YOLACT技术对X射线的腰锥骨进行分割,其分割的准确性较高且视觉效果好并能分割重叠的椎骨,为临床医学决策提供支持[28].Zheng等提出完全IoU损失和Cluster-NMS来增强边界框回归和非最大抑制中的几何因素,并在实时分割框架YOLACT中应用,进一步提高平均精度和平均召回率的同时保持实时的推理速度[29].
2.5 YOLACT++
为进一步提高YOLACT的实时精度,作者又提出了YOLACT++方法[30],在进一步提高检测精度的同时降低了一点速度.从3个方面进行改进:a)主干网络中引入可变形卷积[31],通过与目标实例对齐来增强网络对不同尺度、旋转角度和纵横比实例的处理能力,实现网络对特征的灵活采样;b)优化预测头,当画面某个位置存在多个重叠的实例时,为准确地进行实例分割,引入覆盖更多比例的anchor,以获得更大的召回率;c)受到Mask Scoring R-CNN的启发,在网络中引入了图6所示的6个卷积层和一个全局池化层构成的fast mask re-scoring分支,将框的质量和掩膜质量结合.来对预测的掩膜进行综合排序,得到按分割质量排序的掩膜,消除了预测掩膜的排序仅仅依靠于关联不大的分类置信度.
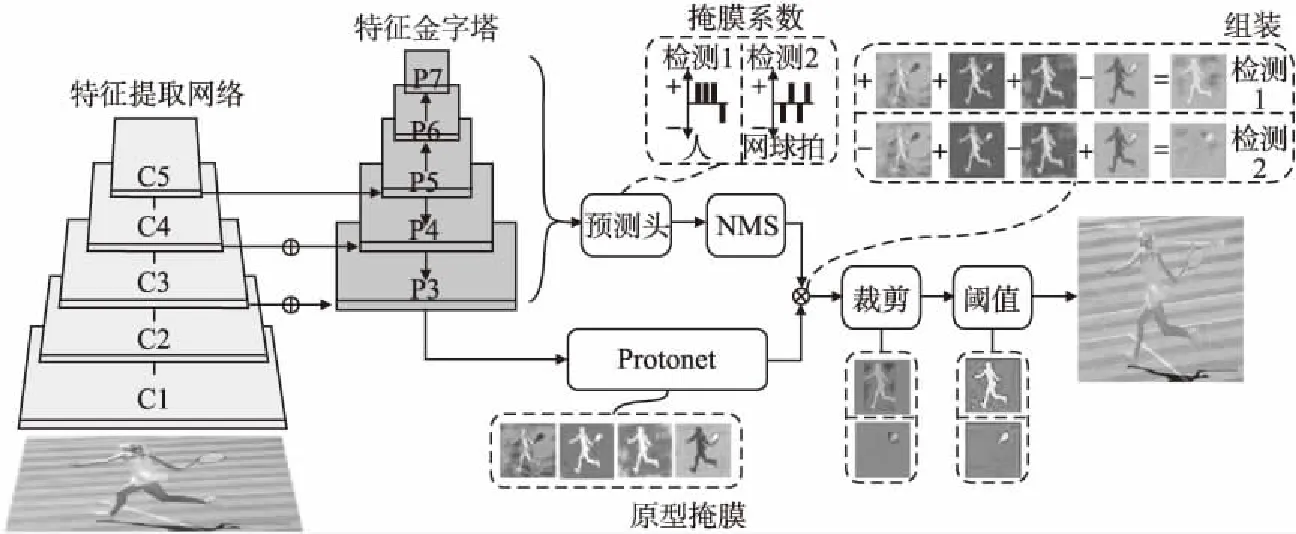
图5 YOLACT网络结构Fig.5 YOLACT network structure

图6 Fast mask re-scoring网络结构Fig.6 Fast mask re-scoring network structure
前两种改进使得YOLACT ++受定位失败的影响较小,第3种改进使得掩膜的排序更为合适,保证了输出的目标掩膜具有最佳的质量.在COCO数据集上,该模型以33.5fps的速度达到34.1mAP,达到实时的同时较YOLACT提升了性能.
2.6 BlendMask
BlendMask[32]借鉴了YOLACT方法中的掩码bases加权求和,结合了自上而下和自下而上的方法的思路,设计了一个blender模块,将高层特征提供的全局语义信息和较低层特征提供的位置信息融合,使网络学到了更加丰富的特征表示.在COCO数据集上BlendMask达到了41.3mAP,在精度和速度上都超越了Mask R-CNN.
BlendMask架构包括检测网络和mask分支,网络结构如图7所示,检测网络是采用的基于anchor-free的FCOS目标检测模型,mask分支包括:底部模块提取底层的细节特征,预测score maps;top layer用于预测实例的attentions,学习一些实例级信息,指导score maps捕获位置敏感信息并抑制外部区域,起到实例感知指导的作用;blender module整合分数以及attentions,融合特征以得到高质量的分割掩膜.该方法的优点是简化了全局特征图表示,减少了所需的通道数,输出分辨率不受顶层采样的限制,产生高质量的掩膜.

图7 BlendMask 网络结构Fig.7 BlendMask network structure
3 自下而上的基于语义分割的方法
自下而上的基于分割的方法是先对每个像素的类别标签进行预测,然后将其分组形成实例分割结果.此类方法是学习一个关联程度,对每个像素点都赋予一个embedding 向量,该向量能将不同实例的像素点拉开,相同实例的像素点拉近,然后使用聚类后处理方法,将实例区分开来.通常基于分割的方法依赖于逐像素点的embedding学习和聚类后处理.
3.1 SGN 用于实例分割的序列分组网络
针对实例分割任务的复杂性,SGN[33]将实例分割分解为一系列的子任务,由一系列神经网络来完成特定的子任务,然后将这些任务组合生成最终的分割掩膜.借鉴分水岭算法[34]产生与目标实例相对应的连通分量和Kirillov等提出的边缘轮廓来分割物体[35]的想法,将SGN网络设计为3个部分,第一个网络在水平和垂直方向上扫描图片,将行列的断点像素连接成水平和垂直分割线.LineNet网络将水平和垂直分割线合并到属于同一个标注实例内部连通的实例组件上.MergerNet网络将线组成的实例部件组合成最终的实例掩膜,对于遮挡造成的实例的切割,将碎片实例合并成目标实例,解决了某一实例的零散碎片被当成单独实例的分裂问题.网络结构如图8所示.
该方法的优点是实现了任务分解,缺点是没有实现端到端的训练且每一个子任务都是顺序执行,再进行合并生成最终的实例,花费时间的开销较大.受到任务分解思路的影响,WISE网络[36]将实例分割分为定位分支和嵌入分支,分别得到每个对象的位置和其属于的实例,并将像素分组形成完整的实例掩膜.与SGN通过几个子网分别学习并依靠独立的步骤来获得最终结果不同,Gong等提出一个部位分组网络[37]来分析图像中的人员,通过语义部位分割来识别像素属于的人体部位,实例边缘检测将分割的人体部位分配给对应的人体,使用统一的网络以端到端的方式共同优化了两个相关的任务.
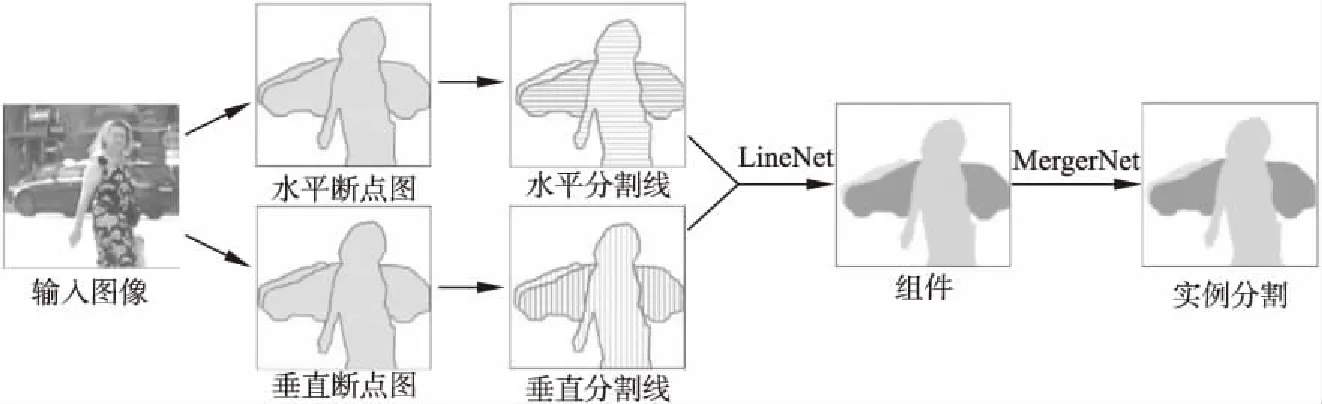
图8 顺序分组网络Fig.8 Sequential grouping networks
3.2 基于判别损失函数的语义实例分割
在实例分割任务中,度量学习在图像分类任务中经常用于判断两个样本之间的相似性,如Chopra等通过学习相似性度量来对新样本进行分类[38],Schroff等提出三元组损失函数[39],该函数利用特征空间上的点的距离对样本分类.文献[40-43]使用度量学习来学习嵌入,以确保来自同一实例的像素具有相似的嵌入,对学习到的嵌入执行聚类以获得最终的实例标签.其中代表性的是Brabandere等提出一种基于度量学习原理的判别损失函数[43]来代替语义分割中softmax损失,使同实例物体中的像素映射到高维空间后得到的embedding 向量之间的距离相近,不同实例的embedding 向量之间的距离较远.该损失函数包括:拉力,将同一实例中的所有像素点拉近到嵌入空间中的同一个点,惩罚同一实例中所有元素与其平均值之间的距离;推力,将每一个聚类的中心点推的更远;正则化,将各聚类的中心点尽可能靠近原点.
该方法的优点是通过对损失函数的优化,使属于同一实例的像素靠在一起,而不同的实例以较大的间距分开,并可以处理复杂的遮挡且不依赖目标候选区域或递归机制.但该方法的缺点是,与一张图片中只含同一类别的多个实例相比,一张图片包含多个类别的实例分割效果不佳.随后,Kulikov等提出训练着色网络进行实例分割,同一对象的像素着相同颜色,不同但相邻实例的像素着不同颜色[44],与文献[43]相比,使用分类学习和基于连接组件的后处理代替了度量学习和基于聚类的后处理,简化了流程.Neven等提出聚类损失函数[45]使属于该对象的像素指向该对象中心周围的特定区域,并共同学习特定实例的聚类带宽,从而最大程度地提高了所得实例掩膜的交并比.
3.3 SSAP
基于提议的方法易受边框预测的准确性的影响,文献[41,45]采用基于语义分割的无提议方法通过实例嵌入来区分实例,使属于同一实例的点在嵌入空间中是较接近的,而属于不同类别的点在嵌入空间中是远离的,避免了基于提议的方法中的边界框对实例分割框架的影响.受到Liu等提出的学习实例感知的亲和力并通过聚类将像素分组为实例[46]的启发,Gao等提出一种单阶段的无提议实例分割方法SSAP[47],通过学习像素对的亲和力金字塔来学习两个像素属于同一实例的概率,使用语义分割和亲和力金字塔联合学习生成多尺度实例预测,然后通过级联图分区顺序生成实例,将两阶段合并为一阶段,有效减少计算成本,加快运行速度.网络结构如图9所示.

图9 SSAP网络结构Fig.9 SSAP network structure
亲和力分支学习亲和力金字塔,语义分支沿着解码器网络的层次结构进行语义分割.亲和力金字塔从较高的分辨率图像中学习近距离的亲和力,即学习小实例的预测或大实例的局部预测;从较低分辨率图像中学习远距离的亲和力,即学习较大实例的预测,进而在不同分辨率下生成的多尺度亲和力金字塔.级联图分区模块将图分区机制与金字塔的层次方法结合,利用亲和力金字塔和语义分割联合学习的多尺度预测,图分区从亲和力金字塔及其相应的语义分割特征图的最顶层开始逐步完善实例预测,高层的低分辨率特征图生成的候选区指导低层的高分辨率的实例预测,顺序生成实例预测.该方法实现了单阶段实例分割,速度和精度都有提升,但每一个分辨率下都产生多尺度预测较占用内存.
3.4 Deep Snake
基于轮廓的图像分割方法利用对象边界的顶点组成物体形状,利用轮廓进行对象分割.传统的蛇算法如文献[48-51]通过人工设计的能量函数优化轮廓坐标,将初始轮廓变形到对象边界.文献[15,52]提出基于学习的方法不同于迭代优化轮廓的传统蛇算法,而是尝试从RGB图像中回归轮廓点的坐标,提高了轮廓分割的速度.由于已有的基于轮廓的方法不受到bbox准确性的限制且含有更少的参数量,但无法完整地探索轮廓的空间拓扑结构.Peng等受到Kass传统蛇算法[48]及蛇算法改进[53]的启发,提出Deep snake[54]算法提取图像顶点的特征,回归出每个顶点处的偏移量以逐步调整轮廓来逼近物体边界.该算法引入了循环卷积来处理轮廓顶点,基于学习到的特征得到每个顶点需要调整的偏移量以尽可能准确地包围实例,而后通过迭代得到更为精确的轮廓边界来提高目标边缘的预测精度.虽然基于轮廓的方法实现了32.3 fps实时性能,但要迭代3次才能预测出准确的偏移量来提高预测的精度.

图10 Deep snake 算法分割过程Fig.10 Deep snake algorithm segmentation process
4 直接实例分割法
不像自上而下的方法依赖于准确的边框检测,受到锚边框位置与尺度的限制,也不像自下而上的方法依赖于嵌入学习,需后处理流程,直接实例分割法是直接分割例的掩膜,直接学习实例掩膜的标签,端到端地预测实例的掩膜与语义类别,无需边框和聚类操作,实现端到端地优化.
4.1 SOLO算法
不同于自上而下的方法学习边框中的掩膜和自上而下的方法学习像素对之间的关系,SOLO网络一次性地对物体进行预测而不需要先用RPN来对建议区域进行提取,预测每个像素所在物体的实例类别,实例类别是量化后的物体中心位置和物体的尺寸,将回归问题转化为分类问题,通过固定个数的通道对不同数量的实例进行建模,且不依赖于后处理方法如聚类操作或 embedding 学习,算法更简单、灵活.
SOLO模型的思想是将图片划分成S×S的网格,如果物体的中心落在了某个网格中,那该网格就有两个任务:a)由分类分支负责预测该物体的语义类别;b)掩膜分支负责预测该物体的实例掩膜.模型框架如图11所示.SOLO在骨干网络后面使用了FPN[55],FPN的每一层后都接上述两个并行分支,进行类别和位置的预测.每个分支的网格数目因实例大小也相应不同,小的实例对应更多的的网格,将所有网格的结果汇总得到该图像的实例分割结果.该算法的实验结果也非常可观,在 COCO 测试集上AP达到了37.8%,在精度上超越了两阶段算法Mask R-CNN和之前所有的一阶段算法.针对SOLO算法仅使用2D位置区分不同的实例,对重叠物体的分割性能不佳,Zeng等提出通过预测实例重心和以重心为中心的4D向量来区分对象的重叠部分[56],利用两物体4D向量表示的边框不同,通过计算候选对象边界框的IoU,实现重叠部分的像素分类.

图11 SOLO模型的框架Fig.11 Framework of SOLO
4.2 SOLOv2
SOLOv2[57]在SOLO算法的基础上进行了两点改进,一个是mask分支,另一个是提出了NMS矩阵代替了SOLO算法中的NMS.在SOLO算法中即使将mask 分支头部解耦,但仍然存在头部信息参数数量较大且预测结果冗余的问题.所以SOLOv2提出将mask头部分解为内核分支和特征分支,mask头部结构如图12所示.内核分支和特征分支进行卷积提取特征,生成掩膜,掩膜数最多的时候是每个网格都有目标出现.这种卷积方法初步过滤掉一些没有目标的网格,为后续减少了计算.极大值抑制矩阵计算预测掩膜之间的交并比,根据阈值利用交并比矩阵删除掩膜分数低的重叠率高的掩膜,并行对多个掩膜进行计算,提高了极大值抑制算法的速度.
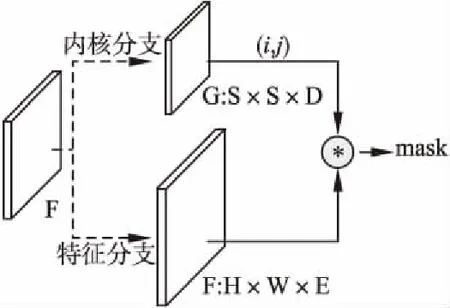
图12 SOLOv2 mask 头部Fig.12 SOLOv2 mask head
SOLOv2提出的根据输入动态地学习内核权重的动态头部和同时处理多个掩膜进而更新多个掩膜分数的矩阵运算,使得SOLOv2在ResNet-101主干网络中掩膜mAP达到了39.7%.
5 实例分割算法的实验对比
本节首先介绍一下实例分割算法常用的公开数据集,然后对当前算法常用的性能评估指标进行阐述,最后对比分析当前实例分割算法及其改进算法的性能.
5.1 实例分割相关数据集
在图像分割领域中,2D数据集数据量丰富、应用广泛,并带有像素级标签,大多数研究也主要使用2D数据集,表1列举了实例分割算法中广泛使用的数据集,以便读者快速浏览.但在数据量较小的领域如医学,常使用数据增强来增加样本的数量,通过对图像进行平移、反转、变形、色彩空间转换等增加训练样本的数量.事实证明,在有限的数据集中(如医学图像分析中的数据集)数据增强可以提高模型的性能,有利于加快收敛速度,减少过拟合以及增强泛化能力.表1展示了实例分割算法中常用的公共数据集.

表1 常用的图像实例分割公共数据集Table 1 Commonly datasets for instance segmentation
5.2 实验结果分析与对比
目前,实例分割算法的实验性能可以从多个方面进行评估,比如精度、速度和内存占用.在精度方面采用AP作为评价指标,AP表示掩膜平均精度,取IoU阈值的平均值,不同下标表示在不同计算条件下得到的计算结果,如AP50和AP75分别表示以 IoU 阈值为50%和75%时的计算结果,APS、APM和APL分别表示针对小、中、大物体的计算结果.速度是决定实时应用的重要条件,通常取决于硬件和实验条件,表2采用fps衡量算法每秒分割图像的帧数.如果模型用于内存容量有限的设备,则内存占用空间也很重要.

表2 不同算法的分割速度比较Table 2 Speed analysis of algorithms
表2列举了具有代表性算法的精度和速度,通过对比发现,自上而下的方法的分割精度相对较高,但分割速度有较大差异.硬件设备影响着实验的速度,为了对各硬件的性能有大致的了解,本文以V100为基准,与其他显卡进行性能比率的换算,以便读者了解硬件对速度的影响.通过分析,发现Mask R-CNN及其改进算法、TensorMask、RetinaMask的分割精度较高但其实时性不强,YOLACT和BlendMask算法在保持较高精度的同时加强了网络的实时性,Box2Pix和EOLO 方法采用了简洁轻巧的特征提取网络加快了分割速度但没有实现高效的分割效果.而自下而上的方法大多采用了后处理技术,其实时性能和精度较差,但最近推出的Deep snake和EmbedMask算法进一步追求精度的同时兼顾速度.直接实例分割方法使用特征图的通道来直接预测实例蒙版且不依赖于后处理方法,精度和速度具佳.随着进一步研究的发展,在保持精度的同时其实时性也成为进一步追求的目标.

表3 不同实例分割算法的性能Table 3 Performance of different instance segmentation algorithms
表3展示了实例分割算法在常用数据集上的分割精度,通过对比,在分割大物体方面,算法的分割效果差异不大.在分割小物体方面,由于小物体比大物体更难检测,算法分割效果不尽相同,其中PANet和BlendMask的精度优于其他算法,主要原因是利用了特征融合来加强了细节特征的表示.综合来看,Mask R-CNN及其改进算法MS R-CNN、PANet在精度方面依旧保持领先位置,BlendMask使用了多次信息融合进一步提高了准确性,超越了实例分割基准Mask R-CNN.文献[33]和文献[43-45]相比于自上而下的方法在精度方面不占优势,主要原因是过度依赖密集预测的质量,对于类别较多的复杂场景泛化能力有限,需要复杂的后处理技术,但该方面的研究仍在进一步的探索来提高准确率且其构思一直启发着后续的研究.SOLO系列算法不受锚的位置的影响,引入“实例类别”的概念将实例掩膜分割问题转换为一个分类问题,在精度方面超越了Mask R-CNN的同时速度也达到了实时,SOLO算法是目前在分割性能和实时性之间达到均衡的最先进的算法.为了更直观的表述典型算法的核心,表4对典型算法的网络特点进行了描述,并根据应用场景对算法进行了对比分析,详细介绍如表4所示.
6 结 语
6.1 总 结
本文从算法特点方面综述了一些较为突出的图像实例分割方法,对算法进行了分类、梳理并对比了其在常用数据集上的分割效果.分析结果表明,自下而上的方法的精度要落后于自上而下的方法,尤其当数据集的场景和语义类别非常多样时,而且自下而上的方法需要非常复杂的后处理技术,这也在一定程度上限制了自下而上的研究工作的发展.直接实例分割方法采用区分位置信息的方式,简化了实例分割的过程,提高了分割性能.直接实例分割方法未来有很大的进步空间,利用实例的位置信息和尺度信息,来区分出不同的实例,推动了实时实例分割方法的发展,会给物体检测与实例分割带来新的突破.面对未来应用需求更加丰富,对基于深度学习的图像实例分割的探索和研究仍有进一步提升的空间.

表4 不同网络模型的特点分析Table 4 Analysis of the characteristics of different network models
6.2 展 望
自上而下的实例分割研究比较多,由追求精度的两阶段向追求速度的单阶段发展,自下而上的实例分割方法在尽量减少后处理的同时也在追求速度,虽然自下而上的研究相对较少,但其提供了巧妙的思路,对后面的研究有启发性.直接方法的出现是一种新的思路,有很大的发展与探索空间.针对实例分割问题,仍有待解决的问题值得进一步探究和优化,未来的研究工作可参考如下几个方面:
1)针对重叠物体的分割
在一些挑战性的数据集上,图像中某一区域存在多个重叠的实例时,网络通过学习但没有将其正确的分割,尽管有些网络通过引入覆盖更多比例的锚点、在主干中应用可变形卷积等以更好地进行特征采样,但还是不够精确,所以如何改进网络对重叠物体的分割有很大的研究意义也是目前研究急需解决的难点之一.
2)针对遮挡而导致对象分裂的问题
由于遮挡使得一个物体被分成多个部分,造成实例的碎片化,比如在Cityscapes数据集上汽车被杆子遮挡造成汽车被分割的情况就很常见.目前的碎片合并方法计算量大,结构复杂又费时,准确性也没有达到预期的效果,所以针对遮挡造成实例分裂问题,如何提高网络对实例碎片化处理有进一步的研究价值.
3)针对边缘轮廓优化问题
针对一些轮廓复杂的特征实例,普遍对边界区域的分割较为模糊、不够精细.Alexander学者观察到分割不准确的部分大多物体的边缘,提出PointRend网络[69]对预测出来的mask中选择Top N个最模糊的点进行预测,以恢复更精细网格上的细节分割,细化了边缘轮廓的分割.虽然边缘只占了整个物体中非常小的一部分,但优化物体边缘对提高分割质量至关重要.精细的分割仍是实例分割所追求的目标,精细的边缘轮廓分割也是研究的重点之一.
4)针对单阶段目标检测算法性能优化
由于实例分割方法以目标检测算法为基础,准确的目标检测算法有利于实例分割性能的提高,所以目标检测算法的研究改善也在一定程度上促进了实例分割的发展.但近年来,anchor-free方法的目标检测网络容量更小、超参数更少、速度更快、准确率更高,选择和改进基于anchor-free单阶段检测器的实例分割方法来实现实时性是后续发展的重要方向.
5)信息融合
BlendMask将高层级粗糙的实例信息和低层级的细粒度信息融合起来,使网络学到了更加丰富的特征表示.高层感受野大,具有丰富的语义信息,低层有很多局部信息,能提供更多的细节信息.所以,信息融合使得分割结果更好.如何更好更简洁的进行信息融合,让网络学习到更好的特征值得进一步研究.
6)针对实例嵌入的优化
对于生成大量的逐像素点的嵌入特征,使用一些聚类等方法来组合特征的策略,优点是通过逐像素点的预测,局部一致性和位置信息很好地保留了下来.其缺点是过于依赖密集预测的质量,造成掩膜的割裂与错误连接,导致性能不佳.如何优化实例像素的嵌入进而提高自下而上的方法的精度,对提高模型的性能起重要作用.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
CHIP新电脑(2016年3期)2016-03-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
职业·中旬(2009年12期)2009-06-01
数码影像时代(2006年5期)2006-05-29
