
基于无监督生成对抗网络的人脸素描图像真实化*
2021-02-03 04:08陈金龙刘雄飞
计算机工程与科学 2021年1期
陈金龙,刘雄飞,詹 曙
(合肥工业大学计算机与信息学院,安徽 合肥 231009)
1 引言
近十年来,随着显卡的升级和卷积神经网络的迅速崛起,人脸素描图像与真实人脸图像的转换与识别在执法机构和数字娱乐行业中起着至关重要的作用[1]。在执法和刑事案件中,嫌疑人的照片并不总是有效,因为实时监控摄像头在远处捕捉到的面部图像分辨率很低。另一种办法是在目击者的帮助下,由艺术家画出面部素描。这是逮捕罪犯的2个重要证据,后一种方法成功地帮助公安部门逮捕了一些罪犯。然而,由于人脸素描与人脸图像在纹理、形状等方面存在显著差异,使得使用嫌疑人素描进行人脸识别的识别率较低,但是可以通过将人脸素描转换成与真实人脸图像相同的模态来提高对嫌疑犯的识别率。
一些相关工作的成果已经被应用到了公安系统、身份认证、视频监控等公共安全领域和图片编辑、银行安保、计算机艺术、数字娱乐等领域中,并得到了相当不错的反馈。然而到目前为止,异质人脸图像转换合成过程中网络训练阶段缺乏配对的图像数据,并且想要获得配对数据往往要付出大量的精力和成本,再加上人脸素描图像与真实人脸图像之间存在着明显的模态差异,现有的方法仍然存在不可解决的局限性。本文提出了一个新的框架以解决上述问题。本文提出的人脸素描图像到真实人脸图像的转换合成模型总体思路如下:首先,为了解决缺乏配对的图像数据问题,所提出的框架结合无监督学习将人脸素描图像转换为真实的人脸图像,这样在测试和应用中可以不使用配对的数据。再与目前的无监督方式下的图像到图像的转换模型相比,本文模型采用了额外的语义一致性损失函数,这样可以使输入图像的语义信息保持在最终的生成图像中。为了得到高质量的生成图像,模型还将像素级的循环一致性损失函数替换为感知损失函数来生成更清晰的图像。由于在生成对抗网络的训练过程中容易发生模式崩塌等问题,使得网络训练变得非常耗时且极其不稳定,因此本文采PGGAN(Progressive Growing of GANs for improved quality, stability, and variation)[2]生成器的架构,然后将它作为镜像对称,也就原来框架的2个生成器合并成本文框架,并将它与生成对抗网络的目标损失函数一起训练从而得到更加真实的输出图像, 同时,循环一致性损失函数驱动相同域的输入图像和输出图像保持一致。最后在香港中文大学人脸素描数据集CUFS[3]和CUFSF[3,4]2个流行的基准数据集上与其他4种相关模型的大量对比实验表明,本文提出的模型在定量和定性上都取得了显著的改善。
2 相关工作
21世纪以来,随着图像数据的逐渐增加和计算机计算能力的显著提升,人脸图像的合成技术越来越完善,人脸图像合成的质量也越来越好。目前异质人脸图像合成的方法主要分为以下2大类:
(1)基于特征表达的传统合成方法。特征表达就是将图像表达为许多特征块的过程,其逆过程即将特征在特定情况下进行合并得到图像的过程就是图像合成。主成分分析方法[5]可以将人脸图像表达为特征矩阵与特征向量,反过来,可以间接地利用特征向量合成各种各样的目标人脸图像。同主成分分析相似的原理,稀疏表达[6]也是图像表达的重要手段之一,人们可以从稀疏表示中合成人脸图像。利用提取的不同局部特征进行异质人脸合成可以解决异质人脸图像与数据集中真实人脸图像之间的结构形态差异问题。以往的研究多采用成对的素描数据集和受控条件下拍摄的照片来解决基于素描的图像合成问题。Liu等人[7]在2007年提出了一种统计推理方法,即贝叶斯张量推理法,用于研究人脸图像与素描图像之间的风格转换。Tang等人[8 - 10]在2002~2009年对异质人脸的转换和识别进行了广泛且深入的研究,提出了一种基于多尺度马尔可夫随机域模型的人脸图像合成与识别方法。为了合成人脸素描/照片图像,将人脸区域分割成重叠的小块进行学习,利用多尺度模型在多个尺度上学习联合图像模型,通过将人脸图像转化为素描(或将素描转化为图像),大大减小了图像与素描之间的差异,从而使两者在人脸素描识别中进行有效匹配。

Figure 1 Network based on PGGAN generator and shared-latent space assumption图1 基于PGGAN生成器和共享潜空间假设的网络框架
(2)基于卷积神经网络的合成方法。近年来,由于计算能力的巨大提升,深度学习又再度成为各大科研领域的研究热点,一些研究成功地利用了卷积神经网络CNN(Convolutional Neural Network)端到端的学习机制来解决不同的图像到图像的转换问题。Zhang等人[10]在2015年提出了一种新颖的神经网络框架,利用6层卷积神经网络(CNN)自动转换图像,保留了素描图像的细节, 与传统的基于范例字典综合素描的模型不同,其开发了一个全卷积网络来学习端到端的素描的映射,将整幅人脸图像作为输入,通过有效的推理和学习直接生成相应的素描图像。Gatys等人[11]提出了一种艺术风格的神经算法,使用来自卷积神经网络的图像表示来优化目标识别,使高层次的图像信息显式化。该算法可以对自然图像的内容和风格进行分离和重组,利用GRAMMA矩阵将任意一幅图像的内容与众多著名艺术品的外观结合起来生成高感知质量的新图像。然而,该框架从开始逐步优化到最佳的结果是一个缓慢迭代的过程, 这限制了其实际应用,并且这样的框架通常只能处理一组固定的图像样式,不能适应任意的新样式。为此,Huang等人[12]提出了一种简单而有效的方法,首次实现了任意样式的实时转换。此方法的核心是一个新的自适应实例标准化(AdaIN)层,它将内容特征的均值和方差与风格特征的均值和方差对齐,可以获得与当时最快的方法相当的速度,并且不受预定义样式集的限制。在图像生成任务中,欧氏距离常被定义为卷积神经网络的主要目标函数,但是生成的图像通常都很模糊。近年来,生成对抗网络(GANs)[13]和变分自动编码器[14]等生成模型因其强大的生成能力在图像到图像的转换应用中取得了巨大的成功。特别是GANs和cGANs在图像编辑、图像修复、妆容迁移、图像超分辨率重建、图像生成等方面取得了令人印象深刻的成果,包括人脸素描图像到真实照片转换的任务[15,16]。
尽管上述方法在图像生成任务中取得了成功,但它们在训练网络时,往往需要来自源域和目标域的对应图像对进行监督学习。
3 本文网络框架

3.1 基于监督和无监督学习的异质图像转换
监督学习是最常见的一种机器学习,其学习模型会尝试学习之前给定的有标签的样本,训练目标是将测试数据标为正确的标签。深度学习再度崛起的前期,一些基于监督学习进行异质图像转换的算法取得了不错的效果。Isola等人[19]提出了被称为“Pix2Pix”的集成框架,该框架使用成对的样本来完成多个图像到图像的转换任务,实现了语义标签到街景图像、自然照片到其素描的转换以及图像的编辑和修复。“Pix2Pix”的集成框架还采用了U-Net结构[20],它在编码器和解码器栈中的镜像层之间增加跳连接(Skip Connection),帮助输出结果保留大量的图像结构信息。
无监督学习通常用于数据挖掘,其学习模型会尝试直接从给定的样本中发现某种特征或联系,与监督学习相比其训练数据是无标签的,训练目标是希望能对观察值进行分类或者区分。由于配对的数据集通常很难得到,往往需要花费大量的成本和精力去获取,所以无监督学习在异质人脸图像的转换任务中发挥着越来越重要的作用。DTN[15]首次在无监督设置下完成带标记数据的域转换任务,并解决了将源域中的样本转换成目标域中保留了其特征标签的模拟样本的问题。CycleGAN[16]应用了循环一致性约束假设:如果将源域中的样本x映射到目标域中的样本y,则可以将其映射回源域中的原始样本。即x→G(x)→F(G(x))≈x和y→F(y)→G(F(x))≈y,G和F表示的映射函数分别为:x→y和y→x。Wang等人[21]提出了一个真实照片到人脸素描图像转换合成的框架,通过多个对抗网络将输入的素描图像转换成高质量的真实照片,反之亦然。在并行工作中,Kazemi等人[17]利用一种新的感知鉴别器来学习素描几何图形和相应的真实感图像之间的鲁棒映射,并提出了一个基于条件CycleGAN的网络,它可以选取几个主观想要的面部特征合成在目标照片上。
3.2 共享潜空间(shared-latent space)假设
基于无监督学习的图像到图像转换的目的是利用图像在各个区域的边缘分布学习图像在不同区域的联合分布,但如果没有额外的假设,将无法从边缘分布中推断出联合分布。为了解决这一问题,UNIT[21]提出了共享潜空间的假设,使得2个不同域中对应的图像可以映射到共同的隐码(Latent Code),而所谓的隐空间(Latent Space)即输入噪声z(也称为隐变量z)的一个特征空间,也可以理解为一种有效的信息表示。隐空间将循环一致性约束与UNIT的框架相结合,进一步地规范了病态的无监督下图像到图像的转换问题。
很多相关研究[23,24]都是基于这一假设来执行不同的图像跨域转换合成任务。然而,这一假设并不总是适用于所有数据集,特别是对于2个域的图像在外观上有显著差异的数据集,因此将其强加于系统可能会导致模型崩溃或者输出图像中存在大量伪影。
3.3 U型网络(U-net)和编码器
由于在图像之间的转换合成任务中,下采样过程可能会导致丢失一些空间信息和特征细节,所以本文采用了前人提出的U-net结构[15,25],通过跳连接的操作来保留一些重要的图像信息,比如面部的结构信息。U-net网络其实是一个基于全连接卷积神经网络的图像分割网络,最早主要用于医学图像的分割,因为在图像的特征提取方面有着出色的表现,被越来越多地应用在图像处理的其他方向上,并且取得了很好的成效。
在生成对抗网络出现的早期,许多图像处理工作中生成图像的分辨率通常都比较低,而且主观上看起来非常不真实。PGGAN[2]首次提出了一种从低分辨率逐级训练提升到高分辨率的图像合成训练方法,最终合成图像的分辨率可以达到1024×1024。因此,为了更好地实现高分辨率的人脸素描图像到真实人脸图像的图像转换,本文将PGGAN生成器的镜像结构作为网络的编码器,该结构使生成器和判别器逐步优化,并使优化阶段和增强阶段交替进行,即先生成4×4分辨率的图像;然后利用生成网络G进行一次上采样操作,再利用判别网络D进行一次下采样操作,这样生成分辨率为8×8的图像;循环执行上采样和下采样操作,这样每次输出图像的分辨率就可以提高一倍,最终输出分辨率为256×256的图像。PGGAN的逐层优化策略虽然使生成图像的分辨率得到了一定的提升,但是往往是以训练时间为代价的。而在本文提出的编码器-解码器结构中,输入图像在编码器中逐步向下采样,在解码器中逐步向上采样,跳连接操作则将下采样之前的编码器层与上采样之后的生成器层连接在一起。此外,在人脸素描图像和真实人脸图像之间共享编码器和生成器的主要目的是使神经网络能够识别到,尽管人脸素描图像和真实人脸图像在外观模态上有显著的差异,但它们都描绘了相同的图像结构信息。这对于本节的任务至关重要,而批再归一化(Batch Renormalization)[24]的参数决定了是输出人脸素描图像还是输出真实人脸图像。
3.4 权值共享和批再归一化
权值共享其实就是对图像用同样的卷积核进行卷积操作,这样就能检测到图像不同位置的同一类型特征,参数共享还可以减少不同神经元之间需要求解的参数,加快训练速度。UNIT[22]中提出的权值共享策略隐含了循环一致性约束,该约束假设2个不同域中的任何匹配的图像对都可以映射到共享潜空间中的相同潜在表示(Latent Presentation)。然而,仅使用权值共享约束并不能保证2个域中对应的图像具有相同的隐码,更不用说未配对的样本了。具体来说,本文工作采用了权值共享策略,共享编码器E1和编码器E2的最后几层的权值,它们负责在这2个域中提取输入图像的高级特征。反之亦然,同时还共享了生成器G1和生成器G2的前几层的权重,G1和G2负责解码用于重建输入图像的高级特征。
在生成模型中使用不同的归一化参数集可以在相同的输入条件下输出多种不同风格的图像。在文献[24]中,单个风格迁移网络甚至可以通过使用条件下实例正则化同时捕获32种风格。大量实验表明,当mini-batch很小时,在推理过程中使用批再归一化能比使用批归一化BN(Batch Norma- lization)取得更好的性能,因此本文通过2组批再归一化[23]的参数来捕获源域X1和目标域X2之间的风格差异。编码器E1和编码器E2的目的则是用不同的风格对相同的语义信息进行编码,通过共享除了批再归一化层之外的所有卷积层的权值,鼓励编码器E1和E2使用相同的隐码来表示这2个视觉上不同的域。因此,与以往的工作[17,24,26]只在较高层共享权值参数不同,本文倾向于共享除批再归一化层之外的所有卷积层的参数,网络中的2个生成器G1和G2也使用这种权值共享策略。这是本文提出的网络框架的关键,它使网络框架能够捕获共享的高级语义特征,并使用更少的参数来训练网络,可以加强网络训练的稳定性,并在一定程度上加速了训练速度。
3.5 训练损失函数
(1)对抗损失函数。
给定输入域Xi∈{X1,X2}和输出域Xo∈{X1,X2},则人脸素描图像转换合成真实人脸图像的原始GAN的目标函数可以表示为:
Lvanilla_GAN=Εxo~Pdata(Xo)[logDo(xo)]+
Εxi~Pdata(Xi)[log(1-Do(Go(Ei(xi))))]
(1)
其中,xo~Pdata(Xo)是指xo的分布,xi~Pdata(Xi)是指xi的分布。
DRAGAN[25]是对生成对抗网络模型的一种改进,由于在判别函数拟合的图像中的真实数据周围局部平衡总是会表现出尖锐的梯度,会使多个矢量映射到单个输出,从而造成博弈的退化平衡(即多组输入变量都会产生一样的结果),为了减少这种现象,DRAGAN对判别器添加惩罚项以避免局部平衡。因此,本文将目标函数加入到对抗性损失中,以提高生成对抗网络模型的稳定性。DRAGAN中添加的判别器惩罚项如式(2)所示:
LDRA=λDRAΕxo~Pdata,δ~Nd(o,cI)‖ΔxDo(x+δ)‖-k
(2)
其中,δ~Nd(o,cI)是指δ服从正态分布,δ表示偏移量,k是指惩罚项。
对抗损失函数的整体目标函数定义如下:
(3)
(2)跨域语义一致性损失函数。
为保证生成图像与输入图像具有相同的高级语义信息,编码器应该分别在2个不同域的输入和输出图像中提取出相同的高级特征。由于循环一致性已经体现了相同域中输入和输出的语义一致性,本文将重点讨论跨不同域的语义一致性。与XGAN[26]相似,定义语义一致性损失函数如式(4)所示:
Lsem(E,G)=
Εx1~Pdata(X1)[‖E2(G2(E1(x1)))-E1(x1)‖1]+
Εx2~Pdata(X2)[‖E1(G1(E2(x2)))-E2(x2)‖1]
(4)
其中,x1~Pdata(X1)和x2~Pdata(X2)表示数据分布。事实上,大多数工作[23,24]都证明了2个域之间没有严格的一对一映射,这种强制在像素级上的2个域之间的一对一映射可能会导致输出模糊化或者不匹配的情况。因此,本文决定将语义一致性损失函数仅应用于嵌入层,从而对跨域共享的语义信息进行编码。
(3)循环一致性损失函数。
在处理不同模式的图像时,像素级的约束可能会降低网络的灵活性,甚至使其无法收敛[27]。因此,本文使用感知缺失[28]作为循环一致性的替代定义,从而更好地学习复杂的跨域之间的关系。将高级特征空间上的欧氏距离定义为循环一致性,即感知损失,利用VGG-16网络Ф来度量图像之间高级特征的差异。图像x和y之间的jth层感知损失函数定义如式(5)所示:
(5)
其中,Φj(x)表示VGG网络中输入图像x的jth层的特征映射,Nj表示jth层中感知器的数量。
本文中循环一致性损失函数定义如式(6)所示:
(6)

综上所述,整体目标函数定义如下:
Ltotal=λGANLGAN+λsemLsem+λcycLcyc
(7)
其中,超参数λGAN、λsem和λcyc是控制3个损失函数相关重要性的权重因子。
4 实验方案和结果分析
本节在2个最常用的开源数据集CUFS[3]和CUFSF[3,4]上展示本文提出的模型在人脸素描图像到真实人脸图像转换合成任务中的定性和定量的结果,并将可视化和定量结果与其他4种模型进行比较,即Pix2Pix[19]、CycleGAN[16]、UNIT[22]和基于合成辅助生成对抗网络来重建真实人脸图像的CA-GAN模型[29]。

Figure 2 Comparison of sketch to photo synthesis results on the CUHK database图2 CUHK数据集上的对比结果
4.1 数据集
香港中文大学人脸素描数据集(CUFS)[3],其子集CUHK数据集中包含188对香港中文大学不同学生的真实人脸图像和对应的人脸素描图像(遵循先前的工作[21],本文将此数据集划分为60对学生人脸图像的训练集、22对学生人脸图像的验证集和100对学生人脸图像的测试集);数据集中的图像都是在正常的光线条件下采集的,由艺术家根据每一张正面人脸照片画出其中性表情的人脸素描图像。
为了进行更全面的评估,本文还使用了CUFSF数据库[3,4],其中包括来自FERET数据库[30]的1 194对灰色真实人脸图像和对应的人脸素描图像。本文将其中190对灰色真实人脸图像和对应的人脸素描图像用于训练,60对灰色真实人脸图像和对应的人脸素描图像用于验证,944对灰色真实人脸图像和对应的人脸素描图像用于测试。由于此数据集中的人脸素描图像具有更为夸张的表情,而且很多真实人脸图像都是在不同的照明条件下拍摄采集的,因此这个数据集特别具有挑战性,但同时更接近现实情况中的法医场景。
4.2 实验设置
实验设备配有2块NVIDIA 1080Ti图像处理器,操作系统为Linux下Ubuntu16.04版本,实验工具平台为TensorFlow 1.8。在模型训练过程中,首先将每个输入图像的尺寸调整为256×256。与CycleGAN中的网络初始化设置类似,从零开始训练网络,并将前100次迭代的学习率设置为0.000 2,然后在接下来的100次迭代中将学习率线性衰减为0。对于超参数,设置λGAN=1,λsem=0.1和λcyc=1。遵循之前的工作[2],使用Adam算法[31]进行优化,将α设置为0.001,β1设置为0.5,β2设置为0.99,将ε设置为10-8。最后,将转换合成的输出图像的尺寸裁剪为200×250。
4.3 实验结果评估
4.3.1 定性评估
图2所示为在香港中文大学数据集(CUFS)[3]上的定性比较结果。从左到右依次为原始输入的人脸素描图像、真实人脸图像(Ground Truth)、CycleGAN的输出结果、Pix2Pix的输出结果、UNIT的输出结果、CA-GAN的输出结果和本文模型的结果。从图2中可以看出,UNIT的输出图像是模糊的,甚至缺少了很多面部结构信息并且存在大量的伪影。而生成模型Pix2Pix和CycleGAN通过对抗损失避免了模糊效果。然而,在生成高分辨率的图像时,由于训练阶段不稳定,容易产生不期望得到的伪影。通过比较发现,本文提出的模型可以减少这些伪影,同时保留了高级的细节。此外,CycleGAN生成的图像可以媲美人工着色的图像,但同时也生成了不真实的纹理。CA-GAN生成的图像相比于前3种模型得到了更平滑的边缘结构,伪影也大大减少,相比本文模型则在灰度显示上更接近Ground Truth的,但是在一些面部细节结构(比如嘴巴、眼睛)上,本文模型更接近Ground Truth。本文模型使用感知缺失代替了像素级的循环一致性,从而可以生成更真实、更清晰的纹理,这使得网络能够通过释放一直保持的像素级信息的约束,在输出图像中生成更高质量的纹理。

Figure 3 Comparison of sketch to photo synthesis results on CUFSF database图3 CUFSF数据集上的对比结果
图3展示了5种模型分别在CUFSF数据集[3,4]上的示例照片上的合成结果。从左到右依次为原始输入的人脸素描图像、真实灰色人脸图像(Ground Truth)、CycleGAN的输出结果、Pix2Pix的输出结果、UNIT的输出结果、CA-GAN的输出结果和本文模型的结果。因为与真实人脸图像相比,CUFSF数据集中的素描人脸图像的特征被过分夸大了,非常接近现实,所以对于很多在此数据库上进行的工作都特别具有挑战性。从图3中可以看出,前3种基准生成模型(CycleGAN、Pix2Pix和UNIT)产生了不良的伪影,尤其是在面部特征上。对比CA-GAN在发型、眼睛的面部结构生成结果上,Pix2Pix、UNIT和本文模型的生成结果都更加接近Ground Truth的,但CA-GAN的生成结果在灰度显示上的还原度最高。综上所述,与其他4种模型相比,本文模型能够在生成更加真实的人脸图像的同时最小化伪影。
4.3.2 定量评估
表1分别列出了5种模型生成的输出图像和相应的原始真实图像(Ground Truth)之间的平均结构相似度指数SSIM[32]。本文计算了香港中文大学的数据集CUHK[3]中100个样本的平均SSIM,结果表明,在保证输入图像保真度的前提下,本文模型可以大大提高转换合成的真实人脸图像与人脸素描图像的匹配精度。
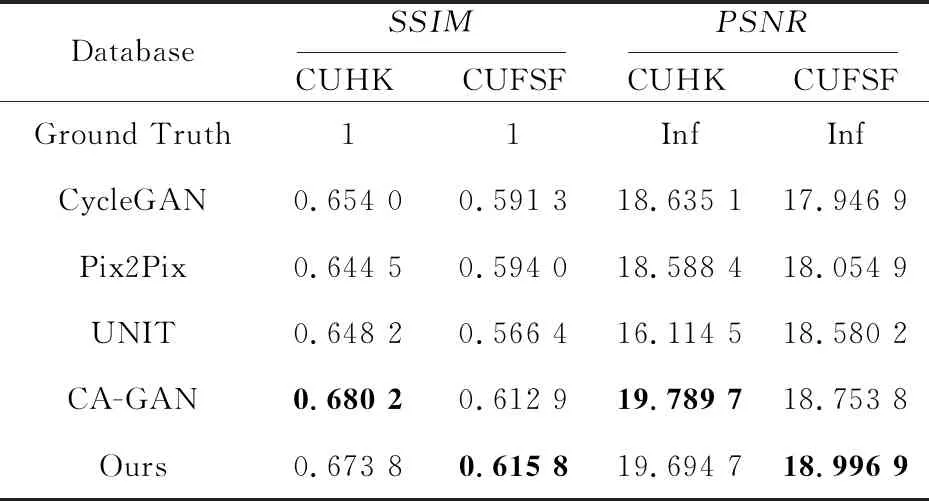
Table 1 SSIM and PSNR comparison of our framework with four baseline models on CUHK and CUFSF 表1 5种模型在CUHK和CHFSF数据集上的性能比较
由表1可知,本文模型比前3种模型在人脸生成图像的质量上有所提升。相比CA-GAN,本文模型在CUSFS数据集上的客观指标更高,在CUHK数据集上的2项指标则相差不多。
由于本文的最终目标是将由人脸素描图像生成的真实人脸图像分发给公安机关进行嫌疑犯的验证,在之前工作[17]的基础上,本文进行了另外2个实验,一个是基于人类主观判断的视觉真实感,另一个是使用预先训练好的人脸验证器对本文模型的输出结果进行人脸识别准确性的验证。但是,与文献[17]不同,对于前者,在基于香港中文大学数据集[3]中的100个样本的测试集上,对于每一个样本,以随机的顺序向受试者展示由5种不同模型生成的图像和一幅原始的真实图像,并给每位受试者一秒钟的时间来判断哪一幅图像最接近原始的真实图像。然后计算出5种模型的平均“愚弄”率并将其展示在表2中。对于后者,本文使用一个预先训练好的VGG16人脸验证器来评估本文模型对人脸验证准确性的影响。对于每张输入的素描,得到分别使用4种不同模型生成的输出图像,再将生成得到的图像与总测试库进行人脸验证,表2中显示了每个模型的验证精度。可以看出,本文模型的验证精度明显优于前3种的,与CA-GAN模型分别在2个数据集上交替领先。在定量和定性评价上,CA-GAN模型在数据集CUSFS上的效果不如本文模型的,在CUHK数据集上则占有些许优势。综上所述,本文模型在伪影移除和识别性能改进方面具有一定的优越性。

Table 2 Fooling rate and verification accuracy of our model with four baseline models on CUHK and CUFSF 表2 5种模型在CUHK和CHFSF数据集上的“愚弄”率与验证精度比较
5 结束语
本文提出了一种基于人脸素描图像到真实人脸图像转换合成任务的无监督学习模型,并对框架结构的相关理论基础进行了详细说明。基于PGGAN生成器结构和UNIT的共享潜空间假设设计了一个具有跳连接的生成对抗网络,成功地将素描人脸图像转换成真实的人脸图像,并取得了更好的效果。与目前相关的无监督方法相比,本文利用了额外的语义一致性损失,将输入的语义信息保留在输出中,并将像素级的循环一致性损失替换为感知损失,生成了更清晰的图像。使用PGGAN生成器的镜像架构来生成高分辨率的图像。在2个流行的开源数据集CUFS和CUFSF上的实验表明,本文模型在图像生成质量和主观指标上都取得了显著的提高。在未来的工作中,将继续重点优化网络结构,以期更高效地生成高质量的图像,并将继续探索本文模型在其他图像转换合成任务中的应用。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
江苏安全生产(2021年6期)2021-08-05
歌剧(2020年4期)2020-08-06
雨露风(2020年8期)2020-04-26
动漫星空(2018年9期)2018-10-26
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
读者(2016年23期)2016-11-16
电子器件(2015年5期)2015-12-29
