
一种基于注意力机制的小目标检测深度学习模型*
2021-02-03 04:08吴湘宁邓中港李佳琪
计算机工程与科学 2021年1期
吴湘宁,贺 鹏,邓中港,李佳琪,王 稳,陈 苗
(中国地质大学(武汉)计算机学院,湖北 武汉 430078)
1 引言
在目标检测领域,小目标通常指尺寸小于32×32像素的目标[1]。小目标检测的难点在于图像中目标的分辨率低、图像模糊、信息量少,能提取到的特征信息少。传统目标检测常用的特征提取算法有SIFT[2]、HOG[3]和图像金字塔[4]等,这类算法难以从海量的数据集中学习出一个有效的分类器来充分挖掘数据之间的关联,不适合解决图像的小目标检测问题。
近年来,深度卷积神经网络ConvNet(Convolutional neural Network)[5]用于目标检测并取得了很大的进展,ConvNet实现了特征、候选区域、边界框的提取以及对象类别的判别,然而ConvNet检测器不太适合检测小目标,这是因为在卷积神经网络中,特征图的分辨率比原始输入图像的分辨率要低得多,分辨率会变为原始输入图像的1/16,这使得分类和边界框回归非常困难[6]。因此,不论是一段式的YOLO[7]和SSD[8],还是两段式的FasterR-CNN[9],对小目标检测效果都不理想。此后深度学习领域出现了专门针对小目标检测的改进方法,如多尺度融合、尺度不变性等方法。特征金字塔网络FPN(Feature Pyramid Network)[10]将低层位置信息与高层语义信息融合,解决了以往的深度学习目标检测算法只采用顶层特征映射进行分类预测,而忽略了低层特征的位置信息的问题。图像金字塔尺度归一化模型SNIP(Scale Normalization for Image Pyramids)[11]实现了多尺寸图像输入,提高了预选框精度,对提升小目标检测效果有一定的促进作用。

Figure 1 Architecture of AM-R-CNN model图1 AM-R-CNN模型的体系结构
此外,在计算视觉领域出现了注意力思想,注意力机制可以有效捕捉图像中有用的区域,通过给关键特征标识权重,使模型能学习到需要关注的区域。视觉注意力分为软注意力(Soft Attention)和强注意力(Hard Attention)。软注意力关注的是区域和通道,是一个完全可微的确定性机制,可以通过网络模型求出梯度并反向转播学习到注意力的权重。而强注意力则更关注图像中的点,具有不确定性。软注意力可分为空间域注意力、通道域注意力和混合域注意力。空间域注意力的代表有空间转换网络模型STN(Spatial Transformer Network)[12]。通道域注意力的代表有挤压及激励网络模型SENet(Squeeze and Excitaton Network)[13],该模型通过学习每个通道的权重产生通道域的注意力。混合域注意力的代表有剩余注意网络模型模型[14],使用注意力掩码,对空间域或通道域以及每个特征元素找出其对应的注意力权重。这些模型被证明可有效捕捉关键区域。
本文提出了一种基于注意力的掩码区域卷积神经网络AM-R-CNN(Attention based Mask R-CNN)模型,该模型使用数据增强技术和多尺度特征融合技术,保证小目标的特征得到加强且不易流失,并在卷积神经网络中引入注意力感知机制,使得不同模块的特征会随着网络的加深产生适应性改变。实验结果表明,本文所提模型提高了遥感影像中船只目标识别的准确性。
2 AM-R-CNN模型实现及在遥感影像小目标识别中的应用
2.1 模型结构
AM-R-CNN模型采用了Mask R-CNN[15]作为基本框架,这是因为Mask R-CNN是一个灵活的目标检测框架,它是对Faster R-CNN的扩展,在预测分支和边界框分支上添加了一个用于预测目标掩码的分支,适用于目标检测、语义分割和人体姿态识别等领域。
AM-R-CNN模型整体结构如图1所示,分为以下几个主要部分:
(1)数据预处理模块:对原始图像进行预处理和数据增强。
(2)ResNet101骨干(Backbone)网络:将ResNet101和特征金字塔结合后构成ResNet101 FPN,负责从输入的数据中提取特征,输出为特征图集合。
(3)候选区域推荐网络RPN(Region Proposal Network):从特征图中提取候选区域。
(4)混合注意力模块:为ResNet101和RPN提供通道域注意力和空间域注意力机制。
(5)头部网络:是对Faster R-CNN进行改进和扩展的网络,包含ROI (Region Of Interest,感兴趣区域) Align和3个分支网络。ROI Align使用双线性插值来更精确地找到每个块对应的特征,它从特征图中提取出固定长度的特征向量和并列的掩码。每个特征向量都会被输送到全连接FC(Full Connection)层序列中,FC层又分为2个同级输出分支,一个是分类分支,用来产生Softmax概率分布,以对目标进行分类,输出每一个ROI中的目标关于K个分类(包括背景类)的概率分布。另一个分支是边框回归分支,可输出K个类的精确边界框位置(4个实数编码值)。而掩码分支采用掩码编码来识别目标的空间布局。每一个ROI定义了多任务损失:L=Lclass+Lboxes+Lmask,3个损失参数分别对应3个分支。
2.2 特征金字塔网络ResNet101 FPN的实现
模型将特征金字塔与ResNet101有效地结合,构成了一个特征金字塔网络FPN,用于提取8×8~64×64像素的小目标的语义特征。
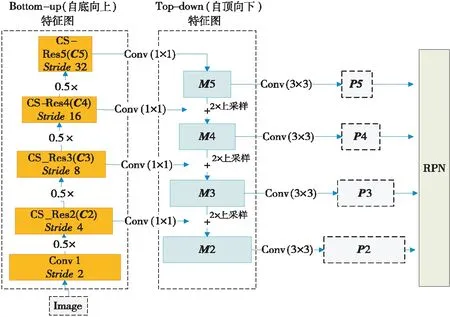
Figure 2 Structrue of ResNet101 FPN图2 ResNet101 FPN的结构
FPN实现过程如图2所示,左边“自底向上”路径是卷积网络的前馈计算,计算由不同比例的特征映射组成的特征图,其缩放步长为2,ResNet块Conv1、CS-Res2、CS-Res3、CS-Res4和CS-Res5的步距(Stride)分别设置为2,4,8,16,32,输出的特征图为{C2,C3,C4,C5}。而右边的“自顶向下”路径,通过对更抽象但语义更强的高层特征图进行上采样来减轻高分辨率特征对检测的影响。对于上层邻近的特征空间做2倍最近邻上采样,然后将“自底向上”路径中的特征图经过1×1的卷积变换后的结果与上层的上采样结果相加合并,再对合并结果{M2,M3,M4,M5}使用3×3的卷积,以减少上采样带来的混叠效应,最终得到多尺度特征图集合{P2,P3,P4,P5},这些特征图与{C2,C3,C4,C5}中对应的特征图有相同的尺寸。
2.3 注意力机制的实现
在AM-R-CNN模型中,ResNet101和RPN 均使用了混合注意力,包含通道域注意力和空间域注意力,其中通道域注意力思想借鉴了Inception[16]和MobileNet[17]网络。
通道域注意力的原理是首先将一个通道上整个空间特征编码聚合为一个全局特征,再通过另一种运算提取通道之间的关系。假设V=[v1,v2,…,vC]表示学习到的卷积核矩阵,其中vc表示第c个卷积核的参数,卷积核vc在原图上进行卷积生成的特征图输出为U=[u1,u2,…,uC],计算公式如式(1)所示:
(1)
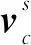
通道域注意力的计算公式如式(2)所示:
Mc(F)=σ(MLP(AvgPool(F))+
MLP(MaxPool(F)))=
(2)
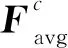
通道域注意力模块的实现过程如图3所示。AM-R-CNN模型借鉴了SENet模型[13]的方法,选用全局平均池化来实现简单的聚合运算,单一的全局平均池化聚合的特征信息对特征图中每个像素都有反馈,引入全局最大值进行梯度反向传播,计算特征图中响应最大的区域,并将2个池化得到的一维矢量相加,丰富全局平均池化提取的信息。

Figure 3 Channel attention module图3 通道域注意力模块
除了通道间存在相关注意力信息,图像在空间层面上也存在着注意力信息。空间域的注意力用于准确定位空间中的目标特征,在目标检测数据集中,小目标像素的占比很小,添加空间域注意力能准确定位小目标,提高检测的准确率。空间域注意力模块的计算公式如式(3)所示:
MS(F)=σ(f7*7([AvgPool(F);MaxPool(F)]))=
(3)
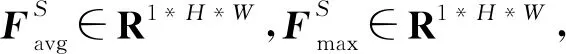
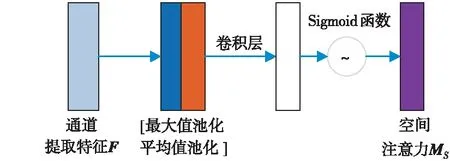
Figure 4 Spatial attention module图4 空间域注意力模块
空间域注意力模块的实现如图4所示。首先,使用全局平均池化和全局最大值池化对输入的特征图F进行压缩操作,对输入特征分别在通道维度上做平均值和最大值操作。然后将得到的2个特征图按通道维度拼接,再经过一个卷积操作,降维为1个通道,保证得到的特征图在空间维度上与输入的特征图一致。最后经过Sigmoid函数生成空间域注意力特征MS。
在ResNet101网络的ResNet块中添加混合注意力的方法如图5所示。将上一个模块产生的特征图做一次卷积计算产生输入特征图F,F经过通道域注意力模块后得到通道域注意力特征Mc,将F与Mc进行逐元素乘法操作得到新的特征图F′,然后将F′输入到空间域注意力模块得到空间域注意力特征MS,再将MS与F′进行逐元素乘法操作,得到的混合注意力特征图F″与F进行相加操作,保留ResNet的残差模块,最后生成的特征图F‴作为下一个模块的输入。

Figure 5 ResNet module with attention图5 添加了注意力的ResNet模块
在RPN中添加混合注意力机制的方法如图6所示。F表示从FPN输出的多尺度特征图,F通过一层卷积计算和ReLu激活函数后得到特征图F1,将F1输入通道域注意力模块后得到通道域注意力特征Mc,F1与Mc进行逐元素乘法操作后得到F′,将F′输入到空间域注意力模块后得到空间域注意力特征MS,再将MS与F′进行逐元素乘法操作,得到混合注意力特征图F″,然后再通过一批归一化和池化层后得到最终的混合注意力特征图F‴。
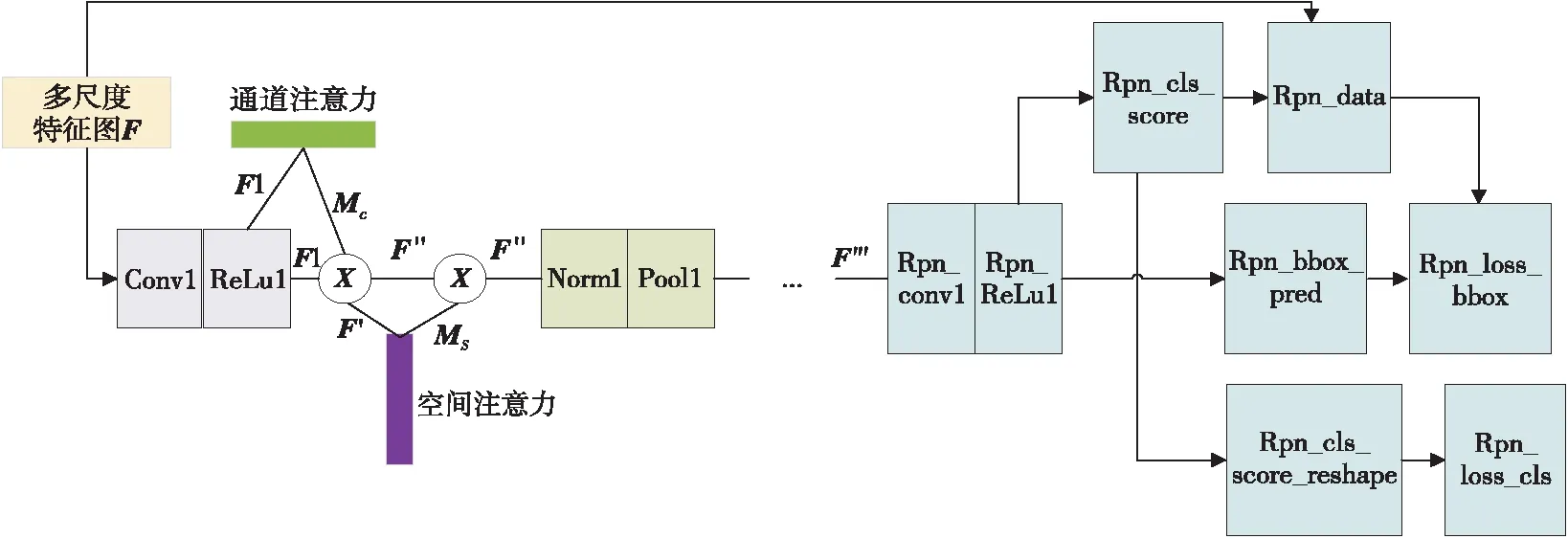
Figure 6 Attention in RPN图6 RPN的注意力结构示意图
RPN实现了一个滑动窗口式的目标检测器,RPN将输入由单一尺寸的特征图替换成了FPN生成的具有多尺度的金字塔特征图,在特征金字塔的每一层添加与RPN相同的头部结构(3*3 卷积和2个并列的1*1 卷积)。由于头部会在特征金字塔中所有层级的所有位置上滑动,因此不需要在每个层级上使用多尺度的锚框。RPN依靠一个在共享特征图上滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的锚框。这9种初始锚框包含3种面积(128×128,256×256,512×512),每种面积又包含3种长宽比(1∶1,1∶2,2∶1)。
2.4 数据增强
本文使用遥感影像海洋船只检测数据集,遥感影像已进行去噪、平滑和滤波等预处理,数据集包含训练集和测试集,训练集有1 925 526 幅图像,测试集有15 606幅图像。csv文件为训练图像提供行程长度编码,用来定位船只,并生成图像的掩码和边界框。
根据不同的交并比IoU(Intersection over Union)阈值下的F2分值对模型进行评估,IoU用于预测区域目标像素个数和真实的目标像素个数的重叠度,计算公式如式(4)所示:
(4)
其中,A和B分别表示预测区域和真实区域。IoU阈值为0.5~0.95,步长为0.05,在预测阈值为0.5时,预测目标与真实目标的IoU大于0.5时表示“命中”。根据预测目标与所有真实目标比较得到的真阳性(TP)、假阴性(FN)和假阳性(FP)共3个指标来计算F2分值。F2分值的计算公式如式(5)所示:
β=2
(5)
其中,Fβ(t)表示精确率和召回率的调和值,β表示召回率的重要程度相对于精准率的重要程度的倍数,当β为1时,精确率和召回率都很重要,权重相同,得数被称为F1分值。本文认为召回率更重要些,因此将β设为2,因而得数被称为F2分值。t表示数据样本,TP指单个预测目标与真值目标匹配时的IoU高于阈值的样本个数,FP表示有预测目标却没有相关真实目标的样本个数,FN表示存在真实目标却没有相关联预测目标的样本个数。
训练集图像的编码信息和船只统计结果如表1所示。表1中编码表示一些矩形框,用来框定图像中的船只,若编码为NaN表示图像中没有船只。编码的字符串格式为:起点,长度,起点,长度,…,其中每对(起点,长度) 表示从起点开始绘制一定长度的像素线。起始位置不是二维坐标,而是一维数组的索引,从而将二维图像压缩为一维像素序列。读取行程长度编码,解码后数组中的1表示掩码,0表示背景,将得到的掩码信息覆盖到对应的图像中,并使用透明的颜色实现可视化。处理后的结果如图7所示。

Table 1 Encoded information of the training set images表1 训练集中图像的编码信息

Figure 7 Parts of ships in training sets图7 训练集中的船只示意图
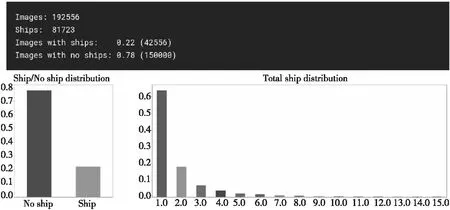
Figure 8 Statistics of ships in training set图8 训练集船只个数统计图
图8是训练集中图像的统计图,可以看出有船只的图像占比为78%,所有图像中包含的船只数量为81 723。由于样本存在类别不平衡的问题,因此,本文对没有船只的图像进行了下采样处理,以防止模型训练时引入过多噪声。在有船只的图像中,出现1~2只船的图像占绝大多数,小目标的数量太少意味着小目标信息量很少,可能导致训练出的模型更加关注其他信息特征。因此,本文针对包含某些数量船只的样本进行过采样,以保证样本种类相对平衡。
图9是从训练集的掩码中提取的船只边界框(bbox)。bbox用于后续模型的训练,格式为(min_row,min_col,max_row,max_col)。

Figure 9 Bounding boxes extracted from masks of ships in training set图9 从训练集中船只的掩码提取的边界框

Figure 10 Positive samples after data augmentation图10 增强后的正样本数据
遥感图像中被检测目标存在角度的多样性,例如遥感图像中船、汽车的方向都可能与常规目标检测算法使用的检测框的方向存在较大的差别[18],这会增加检测的难度,因此需要对遥感图像进行尺度变换、旋转等数据增强操作。同时,使用过采样来解决包含小目标的图像较少的问题,将小目标从原始位置复制后粘贴到不同的位置,通过人为增加小目标的数量,使匹配的锚数增加,从而有效提高对小目标检测的性能。图10所示为如何对有船只的图像进行随机90°倍数旋转,以增加样本的数量和提高方位多样性。
2.5 模型训练及评估
遥感图像经过数据增强处理后被划分为训练数据集和验证数据集,训练数据集用于训练得到AM-R-CNN模型验证数据集作为输入来验证和评估AM-R-CNN模型。
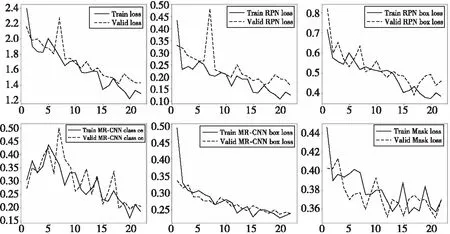
Figure 11 Records of training loss图11 训练损失记录图
AM-R-CNN模型采用添加注意力模块后的ResNet101作为骨干网络,训练过程使用随机梯度下降进行优化。RPN边框的尺度分别为4,8,16,32,64。Batch-size设置为8,掩码的尺寸为28×28,类别个数为2,权重衰减系数为0.000 1,权重损失初始化为[‘rpn class loss’:30.0,‘rpn bbox loss’:0.8,‘mrcnn class loss’:6.0,‘mrcnn bbox loss’:1.0,‘mrcnn mask loss’:1.2],输入图像大小为800×800,学习率为0.001,图像的通道数为3,每幅图像的ROI数为200,验证步数为50,Top-Down金字塔尺寸为256。代码采用Python实现,实验平台为NVIDIA Telsa K40C,Intel Xeon E5 CPU,32 GB RAM。
训练模型时,先加载上下文通用对象COCO(Common Objects in COntext)的预训练权重,使用预训练模型可使模型训练收敛更快,效果更好,训练更少的轮数,而且有可能获得低误差模型,避免陷入局部最优点。
随着训练的深入,模型的各项损失逐渐降低并最终收敛。模型的损失曲线如图11所示。实线表示训练集上的损失,虚线表示测试集上的损失。图中记录的损失包括整体损失、RPN分类损失、RPN边界框回归损失、mrcnn分类损失、mrcnn边界框回归损失和mrcnn的掩码损失。由图11可以看出,所有损失呈整体下降的趋势,训练过程中,最好的轮数为18,验证集的整体损失达到最小值,值为1.410 276 660 442 352 2。
图12显示了不同卷积层的图像特征表示,从左到右分别为原始图像、图像掩码和ResNet的Layer25、Layer35和Layer45卷积层的输出特征图。从图12中可以看出,随着模型越来越深,图像的空间信息逐渐模糊,而背景的位置信息逐渐明显。
图13是FPN到RPN的训练过程,将FPN输出的特征图P2,P3,P4和P5输入到RPN中,对应锚框大小分别为322,642,1 282和2 562,每一层锚框宽高比例为{1∶2,1∶1,2∶1},共有12个锚框,锚框通过ROI Align层后分别得到Mask分支和特征向量,特征向量再分支为分类和边界框回归。训练时根据IoU的大小为每个锚框贴上正负样本的浅标签。头部的参数在特征金字塔各层级中共享,可以使用一个通用的头部分类在任意图像尺寸中进行预测[10]。

Figure 12 Convolutional feature maps of each layer in ResNet图12 ResNet各层的卷积特征图

Figure 13 Training process from FPN to RPN图13 FPN到RPN的训练过程
在图14中,从左到右特征图的输出尺度分别为391×391,548×548,768×768。小尺度的特征图像素信息更少,位置信息更明显,而大尺度的特征图像素信息更多,图像相对模糊。在训练阶段,如果ROI与真实框的IoU大于0.5,则样本被认为是正样本,否则为负样本,通过计算Lmask得到正样本上的掩码损失。在预测阶段,RPN从每个样本中提取的ROI数量为300,然后进行边框预测,并使用Soft-NMS算法[19]消除多余(交叉重复)的边框,找出目标最佳检测位置,本文选择得分最高的100个边框,再对这些边框应用掩码分支,每个ROI预测出K个掩码,并将其缩放到ROI的尺寸大小,然后依据阈值0.5对掩码的像素值进行二值化操作,将ROI分为前景和背景。

Figure 14 Multi-scale feature map图14 多尺度特征图

Figure 15 Comparison of real data and verification results图15 真实数据和验证结果的对比图
在验证阶段,本文加载训练第18轮所得到的权重来初始化注意力ResNet101-FPN,使用AM-R-CNN模型对验证集进行验证,样本数据在经过AM-R-CNN模型验证后,输出回归边界框、类别概率和掩码。图15所示是验证数据和预测结果的对比,左边的图表示原始图像和标注的船舶掩码前景及其边界框,而右边的图表示模型识别出的船舶掩码前景、边界框以及作为“ship”类的概率。从图15中可以看出,AM-R-CNN模型在验证数据集上的检测精度还是比较高的。
最后,将测试数据集加载到经过验证的模型中,用于预测真实遥感图像中的船舶目标,设置最大值抑制的阈值为0.45,最后得到的F2分值为0.817,预测结果如图16所示,其中左图是识别出的船只边框,右图是船只的灰度图掩码,掩码的可能性为0.985。

Figure 16 Result of predicting ship using testing set图16 测试集船只预测结果
为了验证注意力机制对小目标检测的有效性,将AM-R-CNN模型与Mask R-CNN、U-Net[20]、RetinaNet[21]和YOLOv3[22]这4个模型进行比较。这些模型所采用的主干网络均为ResNet101。各个模型采用相同的航拍遥感图像作为检测数据集。
不同模型的处理过程保持相同,在取不同阈值的情况下训练并测试,记录其F2分值,最后将F2分值的平均值作为该模型的最后F2分值。
表2是5种模型的评估结果。评估包括召回率、精确率、F2分值和评估时间。召回率表示实际正样本被预测为正样本的比例,定义为Recall=TP/(TP+FN),精确率表示被预测为正样本的实例中实际为正样本的比例,定义为Precision=TP/(TP+FP)。YOLOv3和RetinaNet的精确率和召回率不如其他2个模型的,是因为此类模型属一段式检测模型,本身更注重算法的实时性,模型的准确率比不上Mask R-CNN 等模型的。U-Net 模型结构虽然简单,但船只检测本身属于像素级特征检测,而U-Net模型的编码器-解码器结构更容易得到较高的准确率,实际上,U-Net与Mask R-CNN有融合的可能。Mask R-CNN有效利用了数据集中的掩码信息,因此其各项指标较其它3个对比模型都要好,但时间的消耗略高。AM-R-CNN模型在多个阶段添加了注意力机制,得到的推荐区域锚框更准确,因此各项指标明显优于其他模型,但是评估时间也略长一点。实验结果表明,将注意力机制与RPN相结合,可有效提高小目标检测效果。

Table 2 Evaluation results of each model表2 模型评估结果
3 结束语
基于注意力机制的小目标检测深度学习模型AM-R-CNN,在目标检测框架Mask R-CNN的基础上引入了混合注意力机制。AM-R-CNN模型在ResNet网络和RPN中添加了注意力模块,通过注意力掩码将图像中小目标的关键特征标识出来,从而帮助模型学习到需要关注的小目标区域。同时,AM-R-CNN模型设计了针对小目标的、可实现多尺度特征融合的FPN,可以更好地提取8×8~64×64像素的小目标的特征。在经过数据增强的遥感图像数据集上的实验对比表明,AM-R-CNN模型对船只的检测识别具有更好的表现。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
通信学报(2019年5期)2019-06-11
北京航空航天大学学报(2018年1期)2018-04-20
通信技术(2018年3期)2018-03-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
