
基于遗传算法的动态轨迹匿名算法*
2021-02-03 07:24贾俊杰秦海涛
计算机工程与科学 2021年1期
贾俊杰,秦海涛
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
无线定位技术的不断发展和移动智能终端设备的不断普及,使得基于位置的服务LBS(Location-Based Services)[1]成为了一个新兴产业。移动对象在获得多样化位置服务的同时也面临着诸多隐私信息暴露的风险。例如,移动对象为获得更好的位置服务需要向位置服务器发送自身的精确位置信息,这些位置信息将会被位置服务器以日志的形式记录下来,一旦攻击者以某种方式获得移动对象的轨迹数据,对其进行分析便可从中推断出与移动对象相关的隐私信息,例如工作单位、收入情况和兴趣爱好等。攻击者进一步通过其他关联信息还可能获得移动对象的社交关系,这就为移动对象的安全造成了极大的隐患。
近年来,为解决移动对象的轨迹隐私保护问题,已有许多方法被相继提出。其中,轨迹K-匿名技术[1]的使用最为广泛。轨迹K-匿名技术采用K-匿名原理[2,3],将轨迹信息与移动对象之间1∶1的关系转换为1∶K的关系,从而达到保护移动对象隐私信息的目的[4]。Gruteser等[5]最先将K-匿名技术应用于位置隐私保护服务中,用一个包含至少K-1个移动对象的匿名区域代替移动对象的精确位置发送给位置服务器,使得攻击者从匿名数据集中识别出真实移动对象的概率不大于1/K。该方法在一定程度上保护了移动对象的隐私信息,但不能满足移动对象的个性化隐私需求。针对此问题,文献[6]提出一种个性化隐私保护轨迹发布算法。该算法采用贪心聚类的等价类划分思想对含有不同隐私需求的轨迹集合进行个性化处理,在一定条件下满足了移动对象的个性化隐私需求,但却忽略了二次聚类攻击依然会导致移动对象隐私信息泄露的问题。因此,文献[7]提出了一种基于聚类杂交的隐私保护轨迹数据发布算法。该算法采用聚类杂交策略,对聚类分组后先进行组间杂交,再进行组内扰乱,从而达到预防二次聚类攻击的目的。但是,因轨迹进行聚类杂交时存在一定的随机性,会产生一些随机轨迹,攻击者通过已掌握的背景知识,便可以从匿名集中轻易识别出这些轨迹。针对文献[7]的问题,文献[8]提出一种基于移动对象真实轨迹的虚假轨迹生成方法。该方法采用聚类,选择出具有相同行为模式的轨迹构建虚假轨迹,解决轨迹随机性问题,并通过构建马尔科夫模型减小背景知识对轨迹隐私的影响。文献[8]方法在一定程度上解决了轨迹随机性问题以及减小背景知识对隐私保护的影响,但却不能对移动对象的动态移动轨迹进行隐私保护。
现有的动态轨迹匿名算法大多从移动对象的单个轨迹出发进行轨迹隐私保护,在寻找最优解的过程中容易陷入局部最优。而且在进行轨迹匿名时大多采用随机方法来生成虚假轨迹,使得生成的虚假轨迹具有一定的随机性。针对此问题,基于遗传算法GA(Genetic Algorithm)具有搜索全局最优解的特性,本文提出基于遗传算法的动态轨迹匿名算法,利用遗传算法对当前时间段内的历史轨迹建立轨迹行为模式,通过该模式对移动对象进行轨迹预测,根据轨迹K-匿名技术对预测轨迹进行虚假轨迹生成,以达到匿名的效果。在轨迹预测阶段,根据预测轨迹实时更新轨迹行为模式,提高轨迹预测的准确性,在一定程度上避免了随机轨迹的出现,在对移动对象轨迹隐私保护的同时保证匿名数据的发布质量。
2 相关技术
2.1 轨迹
由于轨迹数据在时间、空间上的特殊性,所以对移动对象轨迹数据进行轨迹预测或者隐私保护,大多是在时空模型上进行的。通过对移动对象的轨迹数据进行分析、挖掘,从而对移动对象周期性规律或实时运行轨迹进行预测以获得移动对象的相关个体信息[9,10]。
一般情况下,移动对象的轨迹T可以表示为T={(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)},其中,(xn,yn,tn)表示在tn时刻移动对象的地理信息(xn,yn)。而移动对象的轨迹又可以分为静态轨迹和动态轨迹。
(1)静态轨迹是指移动对象已经停止运行后,收集到的轨迹数据,即移动对象的历史轨迹。一般由第三方服务器或者移动对象通过收集、筛选后发布给相关研究机构。
(2)动态轨迹是指移动对象正在运行且不断增加新的位置序列的增量更新轨迹。一般是由移动对象通过移动终端设备向第三方服务器实时提供自身的位置信息,并获得相应的位置服务过程中发布的。
2.2 轨迹K-匿名
现有的轨迹K-匿名技术[1]采用K-匿名原理[2,3],将移动对象与轨迹之间的1∶1关系转换为一条轨迹信息与多个移动对象之间的1∶K关系。经轨迹K-匿名处理后的匿名数据表,每个匿名组中每条轨迹与其他至少K-1条轨迹不可区分,从而降低移动对象隐私泄露的概率,提高数据安全性。
2.3 遗传算法
轨迹数据是一种多特性、多变量共存的数据,因此对轨迹数据进行隐私保护时需要在多个变量中寻求一个最优解,而通用性强、鲁棒性高的遗传算法正好可以解决轨迹匿名寻求多变量最优解这一问题[11]。遗传算法是通过模拟自然界中生物的遗传进化过程并采用适者生存思想来搜索最优解的算法[11]。算法搜索全局最优解的过程是一个不断迭代的过程,每一次迭代相当于生物进化中的一次循环,直到满足算法的终止条件为止。但是,遗传算法在其搜索过程中采用随机搜索方法,因此通过遗传算法得出的搜索结果存在一定的不确定性。通过一些相应的改进方法,可以有效地改善遗传算法的局限性,在可控范围的代价之内取得最优解[11]。
在遗传算法中,问题的每一个有效解被称为一条“染色体”,染色体的具体形式是一个使用特定编码方式生成的编码序列,编码序列中的每一个编码单元称为“基因”。在本文中,遗传算法的染色体就是移动对象的轨迹,基因则是移动对象轨迹中的位置点。
3 动态轨迹隐私保护
3.1 轨迹行为模式
移动对象的习惯性轨迹运动模式具有群体特征[12],通过对移动对象的历史轨迹数据进行分析和挖掘便可从中获得移动对象的轨迹行为模式,这种模式在一定程度上反映了移动对象在当前时间段的出行规律。例如,通过提取Thomas Brinkhoffs生成器[13]模拟生成的某移动对象在一个月内的轨迹数据,提取字段包括:移动对象ID、日期、轨迹起止时间、轨迹数据和语义数据,得到该移动对象的历史轨迹数据,如表1所示。

Table 1 Example of trajectory data of moving object 表1 移动对象轨迹数据示例
在对移动对象的历史轨迹数据进行轨迹行为模式构建时,为使得模式尽可能符合轨迹群体的特征,降低冗余数据对模式的影响,需要先对历史轨迹数据进行预处理。
(1)数据预处理。
为了建立遗传算法的初始种群,首先,从移动对象的历史信息中选择某一段时间内的轨迹;其次,利用混合编码方式[14]将所选历史轨迹进行编码。例如表1中移动对象1在时间段0821~0825(起始时间ti=01:00,结束时间tn=07:00)的一条轨迹T={(3,4),(2,2),(4,3),(5,4),(3,1),(5,6)},由于位置属性是整数,采用混合编码后得到轨迹编码序列F=(1,2,3,4,5,6)。
(2)轨迹行为模式构建。
在本文中,利用遗传算法寻找全局最优解的特性,对移动对象的轨迹行为模式进行构建时,首先将某一固定时间段内的历史轨迹信息作为初始种群;其次从历史轨迹中选择出满足适应度策略的最优相似轨迹进行选择、交叉、变异操作,迭代此过程直到选择出轨迹片段重复率最大的n条轨迹(n≥1),这n条轨迹在一定程度上反映了移动对象在该历史时间段内的出行规律,即轨迹行为模式。令Ti表示第i条轨迹,Tij表示第i条轨迹中第j个位置。轨迹行为模式构建过程如下所示:
(1)将移动对象固定历史时间段内的轨迹数据进行编码作为染色体,生成初始种群,其中基因表示轨迹中的位置点。
(2)适应度策略。在本文中,若轨迹Tr和轨迹Ts的轨迹片段重复的概率大于阈值τ,则认为轨迹Tr和Ts相似,这样的相似轨迹即为所选择个体。
(3)选择。通过轮盘赌方式选择群体中满足适应策略的父代个体。
(4)交叉。利用交叉算子形成新的子代个体,并按照适应度策略进行筛选。
(5)变异。利用变异算子形成新的子代个体,并按照适应度策略进行筛选。
(6)重复(3)~(5),直到收敛得到最优个体,即代表移动对象行为规律的轨迹。
例如,根据表1,设定重复概率阈值τ≤3,利用算法得到最终轨迹T1={(3,4),(2,2),(4,3),(5,4),(3,1),(5,6)},T2={(3,2),(4,1),(2,3),(1,4),(2,1),(5,2)},T3={(2,2),(5,2),(1,3),(4,3),(5,4),(5,1)},T4={(1,4),(3,2),(4,1),(3,1),(5,1),(4,2)},T5={(5,1),(1,4),(2,3),(1,4),(5,1),(2,6)},进行轨迹网构建后得到如图1所示的轨迹网状结构,该轨迹网表示固定时间段内的所有频繁轨迹片段(边),除了起止时间,轨迹片段之间不考虑时序。

Figure 1 network图1 轨迹网
为了得到移动对象轨迹行为模式,通过位置点所体现的语义信息,将图1转换为轨迹语义[15]网络,如图2所示,各位置点对应的语义在移动对象轨迹(如表1所示)中出现的频数如表2所示。

Figure 2 Trajectory semantic network图2 轨迹语义网络
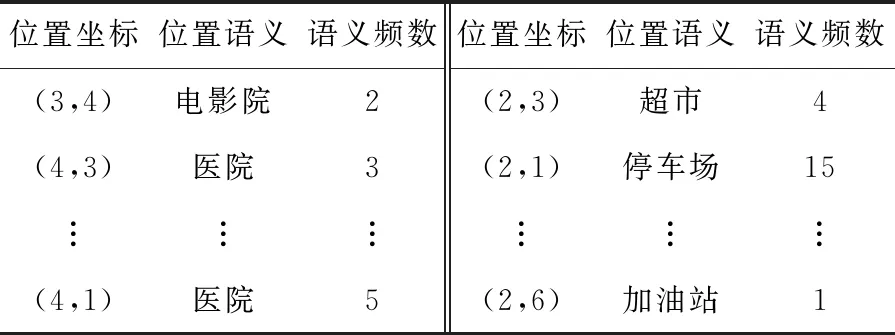
Table 2 Semantic frequency table
设定轨迹语义频数阈值3≤ρ≤5,得到移动对象在当前时间段内的轨迹语义网络如图3所示。

Figure 3 Trajectory semantic network (3≤ρ≤5)图3 轨迹语义网络(3≤ρ≤5)
根据图3得到移动对象在该时间段内的轨迹行为模式为(超市,医院,工作单位,星巴克,加油站,医院,超市,家),“超市”和“家”分别为起止时间移动对象的位置语义,则图1中的轨迹为该轨迹行为模式所蕴含的轨迹。假设轨迹T1,T2,T3为移动对象在某一时间段内的3条轨迹,则可以把它们按时序归为一个轨迹组TRi,轨迹行为模式构建如算法1所示。
算法1移动对象轨迹行为模式构建(Modeal_Tra)
输入:移动对象历史轨迹数据D={T1,T2,…,Tn}。
输出:移动对象轨迹行为模式T。
1.按时间顺序对D进行分组,得到m个轨迹组Dt={TR1,TR2,TR3,…,TRm};
2.T=∅;
3.for(i=1 tom)
4.{
5. 初始化第i个轨迹组TRi:Initialize(TRi);
6. 根据遗传算法选择TRi中满足适应度策略的父代轨迹组TR′i:Fitness(TR′i);
7. 当存在不满足适应度策略的轨迹TRi-TR′i时
8. {进行交叉、变异:GA-operation(TRi-TR′i);
9. 选择满足适应度策略的子代:Fitness(TR″i);
10. 将父代与子代合并,即TR′i+ =TR″i;}
11. 从TR′i中选择出一条最优个体T′i作为该轨迹组TRi的行为模式;
12.T+=T′i;
13.}
14.返回T。
3.2 动态轨迹预测
移动对象的动态轨迹是依赖于当前轨迹或位置点而实时变化的,对下一时段轨迹进行预测具有一定的现实意义。针对预测出的下一时段轨迹中的敏感信息进行有效保护可避免移动对象的隐私泄露,而轨迹的敏感信息一般蕴含在轨迹的语义信息中。
轨迹预测过程就是根据当前移动对象已走的轨迹语义信息,去预测下一时段轨迹语义,利用下一时段轨迹语义可预测出轨迹行为模式中所蕴含的轨迹。再将新增的预测轨迹加入历史轨迹中,重新利用遗传算法更新轨迹行为模式。文献[8,16]将历史轨迹信息作为背景知识,缺少对背景知识的动态更新。本文算法通过实时动态更新轨迹行为模式,不断地充实背景知识,可提高轨迹预测的准确性。
假设移动对象1某时间段的轨迹行为模式如图3所示,其所蕴含的轨迹如图1所示,该时间段移动对象已走轨迹为{(2,2),(4,3),(5,4),(3,1)},根据轨迹模式可以预测移动对象下一时段轨迹语义为(工作单位,医院,超市),根据图1可知该轨迹语义所蕴含的轨迹为T1={(3,1),(4,1),(2,3),(4,3),(5,1)},T2={(3,1),(5,4),(4,3),(2,2)},T3={(3,1),(5,1),(4,3),(2,3),(4,1)},移动对象的预测轨迹如图4所示。

Figure 4 Trajectory prediction图4 轨迹预测
对移动对象的动态轨迹进行预测时,一般会采用均方根误差RMSE判定移动对象真实轨迹点与预测轨迹点之间的误差[9],如式(1)所示:
(1)
其中,(xi,yi)为移动对象的真实位置,(x′i,y′i)为移动对象的预测位置,k表示轨迹中的位置点个数。
3.3 隐私保护
轨迹隐私是一种特殊的个体隐私,是指移动对象运行的轨迹本身就包含有敏感信息或者由轨迹信息可推导出与移动对象相关的个体隐私[1]。假设移动对象轨迹行为模式发生泄漏,攻击者结合背景知识可对其接下来的行为轨迹进行预测,进而可能推断移动对象轨迹隐私。因此,要保证预测轨迹中的敏感位置不被泄露,进而保证轨迹模式中的敏感语义信息不被泄露。
表1中移动对象位置点(4,3)和(4,1)对应的语义信息为医院,攻击者一旦获得该信息后,通过事先获知移动对象有不舒服的表现,便可大概率推断出该移动对象生病的信息,因此,“医院”作为敏感信息需要对其所蕴含的敏感位置所处的轨迹进行隐匿。
本文在对移动对象的动态轨迹进行隐私保护时,根据预测轨迹间的最大距离为带宽,按照轨迹K-匿名的方式从该带宽内选择K条轨迹,使得预测轨迹被识别出的概率不大于1/K,以达到隐匿真实动态轨迹的目的。
轨迹间的距离如式(2)所示:
(2)
其中,(xi,yi)为移动对象的坐标点,t1,t2表示对应时刻,Dis为位置点间的距离。
如图5所示,假设K=3,根据轨迹行为模式,在一定带宽内选择K-1=2条轨迹,形成轨迹3-匿名组。

Figure 5 Trajectory 3-anonymous图5 轨迹3-匿名
4 基于遗传算法的动态轨迹匿名算法
4.1 算法描述
为防止移动对象动态运行轨迹泄露导致的自身隐私泄露问题,本文提出基于遗传算法的动态轨迹匿名算法,随着移动对象的动态移动,将预测轨迹实时加入初始轨迹种群,反复执行下面3个步骤:
(1)以移动对象的真实历史轨迹信息为基础,通过遗传算法从历史轨迹信息中选择出移动对象的轨迹行为模式;
(2)通过轨迹行为模式预测当前移动对象的下一时段轨迹,将预测轨迹加入初始种群;
(3)对预测出的轨迹利用轨迹K-匿名技术隐匿轨迹,以达到隐匿移动对象实时位置或实时运行轨迹的目的。
算法2移动对象的动态轨迹匿名(Hidden_Tra)算法
输入:历史轨迹数据集D={T1,T2,…,Tn},动态更新的轨迹数据Tg。
输出:满足轨迹K-匿名的轨迹数据D′。
1.D′←∅;
2.将Tg加入到D中;
3.调用Modeal_Tra(D)返回轨迹行为模式T;
4.if(T包含敏感信息)
5. 根据遗传算法从D中选择出与T相似的K-1条轨迹并将T加入到D′中;
6.else不进行隐匿,即D′ =D;
7.endif
8.返回D′。
4.2 准确性度量
为检测本文算法的性能,结合轨迹相似度[17]和匹配查询结果来对预测轨迹进行准确性和隐匿效果的评价。轨迹相似度主要衡量移动对象的真实轨迹与预测轨迹之间的差异性,用于算法中轨迹预测阶段。匹配查询结果主要衡量移动对象的真实轨迹从匿名集中被识别出的概率,用于轨迹匿名阶段。
定义1(轨迹相似度) 预测轨迹T′内的任意位置点s,计算与s对应的真实轨迹T内的位置点的距离Dis,若Dis<φ(φ为轨迹相似距离阈值)且该2条轨迹的轨迹片段重复的概率大于阈值τ,则称预测轨迹T′与真实轨迹T相似。
定义2(匹配查询结果) 匿名表内任一轨迹记录Ts,计算Ts到真实轨迹T的轨迹距离Dis,若Dis大于相似距离阈值ξ,并且重合位置点个数小于给定阈值,则认为该匿名轨迹存在隐私泄露。
由于本文采用先对移动对象的轨迹进行预测,然后再对预测的轨迹进行隐私保护的策略,所以需要结合轨迹相似度和匹配查询结果来对轨迹匿名的不同阶段进行数据评价。
5 实验结果与分析
本节将从轨迹命中率、轨迹误差率、隐私保护有效性、轨迹相似度和匿名数据质量几个角度出发,对本文算法进行验证。通过轨迹命中率和轨迹误差率来评测本文算法预测轨迹的有效性。隐私保护有效性和轨迹相似度用来评测经过本文算法进行轨迹隐匿后的移动对象隐私信息泄露的概率。匿名数据质量用来衡量发布的匿名数据的有效性。
5.1 实验数据与环境
实验采用的数据由Thomas Brinkhoffs生成器[13]模拟德国奥尔登堡地图生成。本文选取50 km×50 km区域内1 000个时间片内的10 000条轨迹构成实验数据集,其轨迹中相邻轨迹点间的时间差为20 min。表3为实验数据集参数。
实验环境为Intel i5 3.4 GHz,4 GB内存,Windows 64位操作系统,算法由eclipse 8.1和Matlab 2016a编写。

Table 3 Experimental parameter setting表3 实验参数设置
5.2 轨迹命中率
轨迹命中率指通过算法预测出的预测轨迹与移动对象真实运行轨迹匹配度达到一定阈值的次数。作为衡量一个轨迹预测算法准确性的标准,通常命中率越高,则表示该轨迹预测算法准确性越好。在本文中,选择相同时间段内具有相同背景信息的3 500条轨迹作为初始轨迹数据集,选择文献[9,10]中的算法作为参考,并与本文算法做对比实验。实验结果如图6所示。
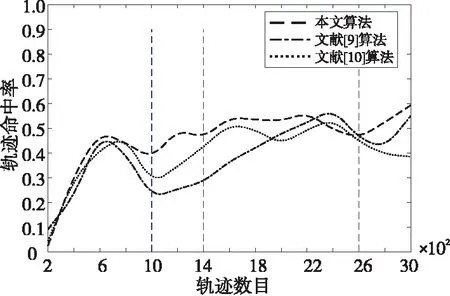
Figure 6 Trajectory hit rate图6 轨迹命中率
如图6所示,随着轨迹数目的不断增加,3种算法对移动对象的真实轨迹运行的命中率也呈现出不同的变化效果。在轨迹数目为0~1000时,本文的轨迹预测算法的轨迹命中率相比于其它2种算法的更高,这是因为本文算法是以移动对象的历史运行轨迹为基础,并结合遗传算法寻找全局最优解的特性可以较为快速地从轨迹数据集中预测出移动对象将要到达的轨迹位置点。但是,在起始区间内,由于起始区间内的轨迹数目较少,轨迹预测时的初始种群就会比较小,所以本文算法相比于文献[9,10]中的算法的轨迹命中率就低一些。轨迹数目达到一定值时,移动对象历史轨迹之间的关联性也在逐渐增加,轨迹命中率也会出现一个短暂的下降趋势。随着轨迹数目逐渐增加,本文算法会结合移动对象轨迹之间的关联性,调整历史轨迹划分规则,从而提高预测轨迹命中真实运行轨迹的概率。
5.3 轨迹相似度
轨迹相似度主要是用来评判移动对象真实运行轨迹与算法生成的轨迹之间的差异性。为验证不同算法在相同条件下的移动对象预测轨迹、通过算法生成的匿名轨迹与真实运行轨迹之间的相似度,将本文算法与文献[9,10,16]中的算法进行对比。
首先,将从预测轨迹与移动对象真实运行轨迹这个角度出发,验证不同轨迹预测算法在相同时间段内预测轨迹之间的差异性,结果如图7所示。

Figure 7 Similarity of predicted trajectory图7 预测轨迹相似度
从图7中可以看出,相比于其他3种算法,本文算法预测出的预测轨迹与移动对象真实运行轨迹的相似度较高。这是因为本文算法采用了遗传算法寻找全局最优解的特性,可以快速从移动对象历史轨迹数据集中得到轨迹行为模式,从而预测出当前时间段内移动对象将要到达的位置点,并根据移动对象实时新增的轨迹位置点动态更新移动对象的轨迹行为模式,进一步提高预测轨迹与移动对象真实运行轨迹之间的相似性。而文献[9,10,16]中的算法却没有考虑移动对象实时新增位置点这一因素对预测轨迹的影响,从而使得预测出的预测轨迹与移动对象真实运行轨迹之间的相似性较低。
将本文算法与文献[8,16]中的算法进行实验对比,在设定相同轨迹数目、长度和隐私需求的情况下,评测不同算法生成的匿名轨迹与真实运行轨迹之间的相似度,结果如图8所示。
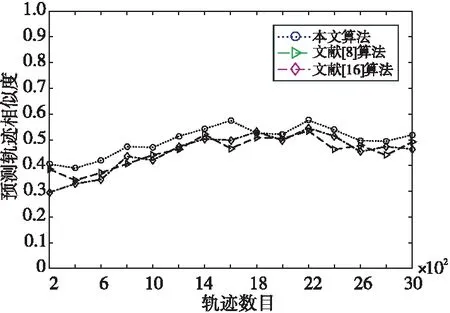
Figure 8 Similarity between anonymous trajectory and real trajectory图8 匿名轨迹与真实轨迹相似度
如图8所示,比较不同算法在相同匿名条件下生成的匿名轨迹与真实轨迹之间的相似性,本文算法在起始阶段生成的匿名轨迹与移动对象真实轨迹相似性较低,这是因为在轨迹数目为200~800时,轨迹数目较少,遗传算法进行匿名轨迹构建时的初始种群较小,因此本文算法的相似性较小,但随着轨迹数目的不断增加,初始种群不断增大,相似性也逐渐上升。而当轨迹数目达到一定阈值时,本文算法相比于其他几种算法呈现出一定的优势,这是因为文献[8,16]中的算法大多先对移动对象的历史轨迹进行聚类,然后进行匿名轨迹构建,没有考虑对历史轨迹信息的实时更新。
5.4 轨迹数据质量
在轨迹数据发布中,既要保护移动对象的隐私信息不被泄露,又要保证通过算法匿名后的匿名数据集具有一定的可用性。根据这一特性,本文在对匿名数据集的数据质量进行评估时分为轨迹隐私泄露概率和匿名数据质量2部分,在评测轨迹数据质量优劣时,本文选择文献[16,18]中的算法来做对比实验。
(1)轨迹隐私泄露。
通过轨迹隐私泄露概率对不同算法生成的匿名轨迹进行验证,实验结果如图9所示。

Figure 9 Disclosure probability of trajectory privacy图9 轨迹隐私泄露概率
如图9所示,在K值相同且具有相同背景知识的轨迹匿名数据集上的实验结果中,本文算法相较于其它2种算法的轨迹隐私泄露概率较低。这是由于本文算法在进行轨迹隐匿时,依据移动对象轨迹行为模式,提前对移动对象的动态轨迹进行了预测,同时充分考虑了移动对象轨迹动态更新位置点这一因素对生成匿名轨迹的影响,提高了对预测轨迹匿名的具体指向,使得生成的匿名轨迹概化程度更好,降低了移动对象轨迹隐私泄露的风险。
(2)匿名数据质量。
对轨迹数据进行匿名后的匿名数据集可用性越高,则证明该匿名数据集的数据质量越好[1]。为评估不同算法生成的匿名数据集的可用性,随机选择匿名数据集中的N条轨迹,在设定同一K值的前提下,比较其匿名数据集的可用性。实验结果如图10所示。

Figure 10 Anonymous data quality图10 匿名数据质量
如图10所示,在同一匿名条件下,随着轨迹数目的不断增加,经过匿名后的匿名数据集的数据质量也在逐渐提高,相比于文献[16,18]中的算法,本文算法的匿名数据质量相对较高,这是因为文献[16,18]中的算法是以移动对象的历史轨迹信息为基础,没有考虑移动对象的轨迹动态更新这一因素对数据质量的影响。而本文算法在进行匿名轨迹构建时,充分考虑了动态轨迹实时更新这一因素对数据质量的影响,并结合与其相关的轨迹语义信息,进行轨迹K-匿名,这样既保护了移动对象的轨迹隐私信息,又保证了匿名数据集具有较高的可用性。
6 结束语
针对现有的动态轨迹隐私保护算法在对移动对象的动态轨迹进行隐私保护时,大多采用先对移动对象的历史轨迹进行聚类,而后进行轨迹隐匿,但没有考虑实时增加的新位置或者新轨迹对动态轨迹的影响问题,本文提出了一种基于遗传算法的动态轨迹匿名算法。该算法利用遗传算法对移动对象的轨迹行为模式进行构建,以该行为模式为基础,对移动对象的动态轨迹进行预测,通过轨迹K-匿名技术生成匿名轨迹对预测轨迹进行隐匿,从而达到保护移动对象动态轨迹隐私信息的目的。该算法在一定程度上解决了移动对象动态轨迹隐私泄露的问题,但因遗传算法中初始种群选择这一因素的影响,依然会导致本文算法在算法效率上有所欠缺,这将是下一步亟待解决的问题。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代装饰(2018年5期)2018-05-26
意林(2018年3期)2018-03-02
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中国三峡(2017年2期)2017-06-09
统计与决策(2017年2期)2017-03-20
厦门理工学院学报(2016年1期)2016-12-01
