
Intel Cascade Lake架构CPU SPEC CPU2017评测*
2021-02-03 07:24刘新娃
计算机工程与科学 2021年1期
杜 琦,黄 卉,龚 盛,刘新娃,黄 春
(1.国防科技大学计算机学院,湖南 长沙 410073;2.中南林业科技大学环境科学与工程学院,湖南 长沙 410004)
1 引言
在高性能计算(HPC)领域,处理器的性能时刻影响着作业计算的效率,过去的几年中,高性能计算领域受到来自不同厂商的关注,导致芯片架构数量急剧上升,例如Marvell、华为和ARM等更多供应商进入了HPC相关领域,这种趋势在未来预计仍会继续。这些芯片具有不同的性能、功耗和特征,对新处理器架构进行基准测试是了解其特性、获取处理器真实性能最有效的途径,对后续开展有针对性的代码优化至关重要[1]。
Cascade Lake是由Intel在2019年4月推出的微处理器体系架构,采用14 nm制程,该架构是在Skylake架构的基础上优化而来的[2],为了分析此新架构,近来,我们使用SPEC CPU2017基准测试工具对基于Cascade Lake架构的Intel Xeon Gold 6252N处理器进行了系统评测。Intel至强系列处理器共分为4种,分别是用于专家级工作站的Intel至强可扩展处理器、用于空间和功耗受限环境的片上系统的D系列处理器、用于主流工作站的W系列处理器和用于入门级工作站的E系列处理器[3]。本文选择评测的处理器6252N为Intel至强金牌可扩展处理器,它可以支持更高的内存速度、更多的内存容量和4路可扩展性,拥有较高的可靠性和安全性,并且这款处理器针对要求苛刻的主流数据中心、多云计算以及网络和存储工作负载进行了优化,适用于高性能计算机。当前随着ARM和AMD 处理器的不断完善,高性能计算处理器市场有了更多选择,Intel难以避免其他架构处理器带来的竞争。但是,就目前形势而言,Intel处理器仍在高性能计算领域占有举足轻重的地位,市场份额并不会迅速变化[4],并且,英特针对高性能计算还附带提供了大量的软件与技术支持,使其处理器能最大程度地提高计算性能。对6252N处理器的评测有利于了解Cascade Lake架构,也有利于获取该款处理器的真实性能与特征。
评测之前本文对市面上部分处理器基准测试工具进行了选型工作,在GNU Linux平台,多选择使用SPEC(Standard Performance Evaluation Corporation) CPU[5]与HPL(High-Performance Linpack) Linpack[6]评测处理器性能。
SPEC CPU是一款开源跨平台的处理器性能基准测试套件,包括CPU89、CPU92、CPU95、CPU2000、CPU2006和CPU2017共6个版本,由SPEC发布。SPEC是由全球数十所大学、芯片厂商、科研团体等组成的非营利性组织,致力于构建一套标准化的基准测试工具[7]。SPEC CPU基准测试套件由多个应用程序组成,这些程序分别来自不同的特定领域[8],其每一项基准测试都可以获取对应的测试评分,测试结果在高性能计算机的处理器评测领域具有较高的认可度。常用版本为CPU2006与CPU2017,但是随着CPU2017的发布,CPU2006即将淘汰,官方推荐使用CPU2017[9],关于SPEC CPU2017的具体细节,将在第2节介绍。
Linpack是国际上使用最广泛的高性能计算机系统浮点性能基准测试,其实际测试结果受到包括处理器的架构、数量与效率、内存大小、算法相关的参数设置以及网络连通性等多方面因素的影响[10],因此可以作为衡量机器整体性能的标准之一。测试包括3类,Linpack100、Linpack1000和HPL,前2种由于测试运行规模较小,已不是很适合现代计算机的发展,当前主要使用HPL测试。HPL是针对现代并行计算机提出的测试方式,允许用户在不修改任意测试程序的基础上,通过调节问题规模大小(矩阵大小)、使用CPU数目、使用各种优化等方法来执行该测试程序,以获取最佳的性能。HPL的测试结果是全球超级计算机TOP500排行榜中的排名依据,在国际上广受认可[11]。
而在微软Windows平台多使用CPU-Z[12]与CineBench[13]进行基准测试。CPU-Z是一款由CPUID公司开发的免费处理器评测工具,可收集机器中处理器、缓存、主板和内存等主要设备的信息,也可对处理器进行单线程和多线程的基准测试评分。CineBench是一款由Maxon公司开发的跨平台免费测试套件,用于评测计算机处理器与GPU的性能,常用版本为R15,可以通过渲染图形测试,获取处理器的性能评分。
本文测试基于RedHat Enterprise Linux Server 7.6平台,鉴于平台支持性,未选择使用CPU-Z与CineBench。由于HPL Linpack中使用的Intel MKL(Math Kernel Library)数学库针对CPU特性做过专门指令级手工优化,体现的是机器的极值计算性能,不能代表典型应用在机器上的表现,而SEPC中的基准测试程序来源于不同的大型应用项目,能很好地体现典型应用在机器上的表现,且SPEC官网的测试结果页面[14]提供了大量CPU2017评测结果以及配置文件可供参考对比,因而采用SPEC CPU2017作为本文评测的基准测试工具。本文主要研究通过SPEC CPU2017对Intel Cascade Lake架构CPU做评测,主要贡献如下:
(1)在Intel Cascade Lake架构CPU平台,进行不同内存频率、副本数与打开/关闭Turbo的组合测试;
(2)选择Intel Ivy Bridge和Intel Haswell 2种架构的CPU作为对比测试平台,对比分析3种架构的SPEC CPU2017表现;
(3)引入计算访存跑分比PBR(Performance Bandwidth Ratio)的概念,分析3种架构的硬件功能部件的增加对应用程序的性能影响。
2 相关背景及基准程序的介绍
本节简要介绍SPEC CPU2017基准程序,以及STREAM微基准测试和性能评测相关的背景知识。
2.1 SPEC CPU2017
在SPEC CPU2017推出之前,SPEC CPU2006已使用10余年,而这10多年中,计算机领域已发生了重大变革,例如处理器架构的更新、制作工艺的提升以及不断增长的内存容量。为了跟上技术进步和新兴领域发展的步伐,SPEC推出第6代基准测试SEPC CPU2017[15]。
经过SPEC CPU的版本迭代更新,相比于CPU2006,CPU2017进行了大量的更新和修改,包括添加来自新兴领域的基准测试项[16]。首先在测试套件方面,CPU2017由2006版本的2个测试套件Int和Rate升级为4个套件,这4个套件分别是用于测试整型运算速度的Int Speed、用于测试浮点运算速度的FP Speed、用于测试整型并发速率的Int Rate和用于测试浮点并发速率的FP Rate;在测试项方面,CPU2017测试项由CPU2006的29项升级为43项,测试程序集也相应修改,其中Int类别保留CPU2006原有的perlbench、gcc、mcf、omnetpp和xalancbmk 5项,新增人工智能领域的exchange2测试项,有4项测试项修改了名称,即bzip2、gobmk、sjeng和h254ref分别修改为xz、leela、deepsjeng和x264,删除了原有的2项测试项hmmer和astar;FP类别保留了原有的bwaves、namd、provray、lbm和wrf 5项测试项,新增8项基准测试项,分别是生物医学领域的parest、三维渲染和动画领域的blender、大气建模领域的cam4、图像处理领域的imagick、分子动力学领域的nab、计算电磁学领域的fotonik3d、区域海洋模拟领域的roms和海洋气候模拟领域的pop2,修改cacusADM为cactuBSSN,同时删除CPU2006原有的gamess、milc、zeusmp、gromacs、leslie3d、dealⅡ、soplex、calculix、GemsFDTD、tonto和sphinx3等10项测试项。与前几代版本相同,CPU2017的基准测试程序依然使用C/C++和FORTRAN语言编写,因此可移植到多种CPU架构以及包括UNIX和Windows在内的多种操作系统中,同时,CPU2017在测试中将强制收集来自sysinfo程序的数据,因此生成的报告也更加准确完整。
2.2 STREAM
STREAM[17]是一套综合性能测试程序集,通过FORTRAN和C 2种高级且高效的语言编写完成,由弗吉尼亚大学(University of Virginia)提供,通过数组的复制、尺度变换、矢量求和及符合矢量求和等4种不同模式下的双精度(8个字节)内存读写操作来测试高性能计算机的内存带宽。
2.3 超线程
超线程是Intel于2002年发布的一种技术,它把多线程处理器内部的2个逻辑内核模拟成2个物理芯片,使单个处理器就能使用线程级的并行计算,进而兼容多线程操作系统和软件。超线程技术充分利用空闲CPU资源,在相同时间内完成更多工作[18]。
虽然采用超线程技术能够同时执行2个线程,但当2个线程同时需要某个资源时,其中一个线程必须让出资源暂时挂起,直到这些资源空闲以后才能继续。因此,超线程的性能并不等于2个CPU的性能之和。而且,超线程技术的CPU需要芯片组、操作系统和应用软件的支持,才能比较理想地发挥该项技术的优势[18]。
2.4 Turbo模式
Intel睿频加速技术(Intel Turbo Boost)是Intel对其CPU的时钟频率自动加速技术的商业名称。当程序对CPU资源利用增加时,睿频加速技术自动开启,提高CPU频率,以满足算力需求[19]。该技术启动后,处理器将尝试提高其自身的时钟频率,并由处理器的功率、电流、温度限制、需要提高频率的处理器核心数量,以及最大睿频频率来决定具体频率的提高。此外,若睿频加速期间处理器的温度、功率等超过限制,则处理器的时钟频率会下降,以保护处理器[19]。
2.5 qkmalloc和jemalloc内存分配器
qkmalloc是Intel自定义内存分配器库,最早出现在Intel C++编译器19.0的更新版本1中。它提供了一个C级接口“qkmalloc()”用于替代经典内存分配器malloc分配内存[20]。
jemalloc是由Evans在2005年为FreeBSD开发的新一代内存分配器,用来替代原来的phkmalloc[21]。到目前为止,除了原版jemalloc,还有很多变种被用在各种项目里。
相对经典内存分配器,jemalloc最大的优势是其强大的多核/多线程分配能力。以现代计算机硬件架构来说,最大的瓶颈已经不再是内存容量或CPU计算速度,而是多核/多线程下的锁竞争(Lock Contention)。因为无论CPU核心数量如何多,通常情况下内存只有一份,可以说,如果内存足够大,CPU的核心数量越多,程序线程数越多,jemalloc的分配速度越快,而这一点是经典内存分配器所无法达到的。
3 测试平台与环境
从近几年TOP500发布的超级计算机500强榜单可以看出,Intel处理器的比重越来越大。本文采用Intel 3款不同架构的平台进行测试,即Intel Cascade Lake架构处理器Intel Xeon Gold 6252N、Intel Haswell架构处理器Intel Xeon E5-2620 v3和Intel Ivy Bridge架构处理器Intel Xeon E5-2692 v2。这3款不同架构处理器在TOP500中都占有一席之地。
3.1 硬件平台
本文用到的3款不同架构处理器的测试平台的主要性能参数如表1所示。
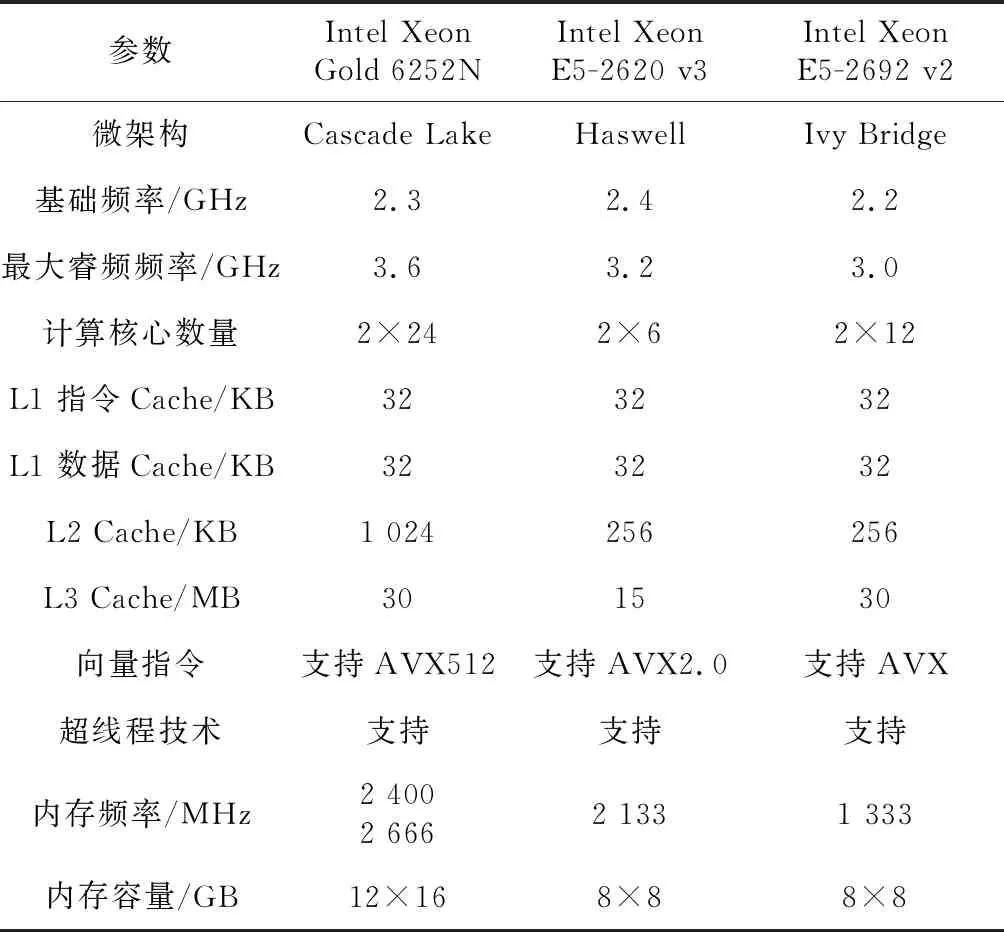
Table 1 Hardware configuration of the platforms表1 测试平台硬件配置
这3款不同架构处理器除在基础频率、Cache容量等存在差别外,对计算性能有较大影响的向量部件、指令集等也有较大的差别,如表2所示。
3.2 软件环境
在2个平台上,本文均采用Intel Parallel Studio XE套件来编译SPEC CPU2017的测试题,该

Table 2 Test platform vector parts,FMA parts and deep learning instructions表2 测试平台的向量部件、FMA部件和深度学习指令
套件包含本次测试必需的C/C++编译器ICC与FORTRAN编译器IFort,并且对于x86处理器,Intel编译器通常可以优化程序代码,提高应用程序性能,具有较高的兼容性和易用性。测试依赖的GCC编译器采用9.3.0版本,GCC 9.3.0是由GNU开源组织于2020年3月21日发布的,较早期9代GCC版本相比,修复了众多已知错误,具有较高的稳定性。详细软件环境如表3所示。

Table 3 Software configuration of the platforms表3 测试平台软件环境
4 测试及结果分析
本文采用实测方法测试Intel Xeon Gold 6252N型号CPU。通过SPEC CPU2017测试集,分不同内存频率、打开/关闭Turbo Boost和打开/关闭超线程等配置组合对该型号CPU进行全面测试,并分析不同配置组合下表现出的性能差异。本节还对比测试了Intel Ivy Bridge和Intel Haswell 2种架构的CPU,根据SPEC CPU2017的测试结果讨论了3种架构的差异及其表现。本节使用的测试集为intrate(SPECrate 2017 Integer)和fprate(SPECrate 2017 Floating Point)。
4.1 测试方法
在本文的测试中,3个平台使用的编译器都为Intel编译器,具体软件环境配置如表3所示。
在Intel Xeon Gold 6252N平台,SPEC CPU2017的配置文件中使用的编译选项主要包括“-O3”“-xCORE-AVX512”“-qopt-prefetch”“-iop”“-ljemalloc”和“-lqkmalloc”等,其中“-ljemalloc”和“-lqkmalloc”分别对应jemalloc和qkmalloc内存分配器。
在Intel Xeon E5-2620 v3平台,SPEC CPU2017的配置文件中使用的编译选项主要包括“-O3”“-qopt-prefetch”“-iop”“-xCORE-AVX2”等。
在Intel Xeon E5-2692 v2平台,SPEC CPU2017的配置文件中使用的编译选项主要包括“-O3”“-qopt-prefetch”“-iop”等。
3个平台的测试都是采用numactl来绑定CPU核,并使用interleave的方式分配内存。
4.2 Intel Xeon Gold 6252N
本节分别测试讨论intrate和fprate的单副本、48副本和96副本在内存频率为2 400 MHz和2 666 MHz、Turbo Boost打开或关闭情况下的性能表现。
4.2.1 单副本
图1和图2分别为单副本intrate和fprate的性能表现结果。从图中可以看出,在Turbo Boost打开或关闭的情况下,内存频率的差异对单副本的测试性能没有明显的影响。

Figure 1 Performance results of single intrate copy图1 单副本intrate的性能表现结果

Figure 2 Performance results of single fprate copy图2 单副本fprate的性能表现结果
4.2.2 48副本
图3和图4分别为48副本intrate和fprate的性能表现结果。从图中可以看出,在Turbo Boost打开或关闭的情况下,内存频率的差异对48副本intrate的测试性能没有明显的影响,但对48副本fprate的测试性能影响明显。相较于2 400 MHz内存频率,使用2 666 MHz频率的内存,在48副本fprate的测试中有9个题目的性能有所提高,其中503.bwaves_r、519.lbm_r、521.wrf_r、549.fotonik3d_r 和554.roms_r 等5个题目的性能提升在9%左右;3个题目的性能下降,其中508.namd_r和538.imagick_r 等2个题目分别下降2%和4%;1个题目544.nab_r对内存频率差异不敏感。
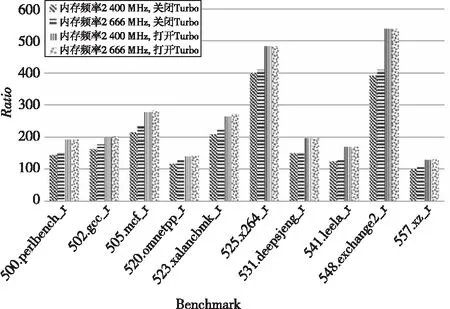
Figure 3 Performance results of 48 intrate copies图3 48副本intrate的性能表现结果

Figure 4 Performance results of 48 fprate copies图4 48副本fprate的性能表现结果
4.2.3 96副本
图5和图6分别为96副本intrate和fprate的性能表现结果。从图中可以看出,在Turbo Boost关闭的情况下,内存频率的差异对96副本intrate的测试性能有一定的影响,而在Turbo Boost打开时则不明显;在Turbo Boost打开或关闭的情况下,内存频率的差异对96副本fprate的测试性能影响明显,与48副本的对比分析基本一致。

Figure 5 Performance results of 96 intrate copies图5 96副本intrate的性能表现结果

Figure 6 Performance results of 96 fprate copies图6 96副本fprate的性能表现结果
4.3 对比测试分析
本节讨论测试了Intel Xeon E5-2692 v2和Intel Xeon E5-2620 v3 2种架构CPU的SPEC CPU2017的单副本和多副本,通过不同副本的跑分值来对比分析3种架构的差别。

Figure 7 Comparison of intrate run scores of three CPU architectures图7 3种架构CPU的intrate跑分值对比

Figure 8 Comparison of fprate run scores of three CPU architectures图8 3种架构CPU的fprate跑分值对比
图7和图8分别为3种CPU架构的intrate和fprate的跑分值对比结果。从图中可以看出,Intel Xeon Gold 6252N平台的跑分值明显优于其他2个平台的,说明在硬件资源增加的情况下,SPEC CPU2017的跑分值会相应有所提高,但提高的比率是否与硬件资源增加的比率呈相应倍数关系则无法从图7和图8中看出来。为了定量分析,本文引入计算访存跑分比PBR的概念,即:
其中,BenchmarkRatio表示SPEC CPU2017中测试题的跑分值,CPUComputingPerformance表示对应副本数的CPU理论峰值,MemoryBandwidth表示内存带宽。PBR值越低,说明在单位时间内硬件资源的利用率越高。
4.3.1 理论峰值性能与理论访存带宽计算
根据表1和表2给定的参数可以得到3个平台的理论峰值性能(按基础频率计算)和理论访存带宽。本文使用的Intel Xeon Gold 6252N平台拥有2个socket,每个socket有24个计算核心,每个核心的基础频率是2.3 GHz,向量宽度是512 bit,有2个FMA部件,故单核心的双精度浮点理论峰值性能为:
全平台48核心的双精度浮点理论峰值性能为3 532.8 GFlops。单核心的32位定点理论峰值性能为:
全平台48核心的32位定点理论峰值性能为7065.6×109ops。该平台使用DDR4类型的内存,内存频率为2 400 MHz,有12个访存通道,故而最大访存带宽为:
本文使用的Intel Xeon E5-2620 v3平台拥有2个socket,每个socket有6个计算核心,每个核心的基础频率是2.4 GHz,向量宽度是256 bit,有2个FMA部件,故单核心的双精度浮点理论峰值性能为:
全平台12核心的双精度浮点理论峰值性能为460.8 GFlops。单核心的32位定点理论峰值性能为:
全平台12核心的32位定点理论峰值性能为921.6×109ops。该平台使用DDR4类型的内存,内存频率为2 133 MHz,有8个访存通道,故而最大访存带宽为:
本文使用的Intel Xeon E5-2692 v2平台拥有2个socket,每个socket有12个计算核心,每个核心的基础频率是2.2 GHz,向量宽度是256 bit,有1个FMA部件,故单核心的双精度浮点理论峰值性能为:
全平台24核心的双精度浮点理论峰值性能为422.4 GFlops。单核心的32位定点理论峰值性能为:
全平台24核心的32位定点理论峰值性能为844.8×109ops。该平台使用DDR4类型的内存,内存频率为2 133 MHz,有8个访存通道,故而最大访存带宽为:
4.3.2 Intel Xeon E5-2692 v2和Intel Xeon E5-2620 v3
本节给出了在打开Turbo、关闭超线程的情况下,2种架构CPU的SPEC CPU2017的单副本和多副本的跑分值。图9为单副本和多副本intrate的性能表现结果。图10为单副本和多副本fprate的性能表现结果。

Figure 9 Performance results of single intrate copy and multiple intrate copies图9 单副本和多副本intrate的性能表现结果

Figure 10 Performance results of single fprate copy and multiple fprate copies图10 单副本和多副本fprate的性能表现结果
4.3.3 对比分析
本节在打开Turbo、关闭超线程的情况下,根据计算访存跑分比PBR来分析3种CPU架构的差别。
图11所示为3种架构的fprate单副本PBR的表现结果。Intel Xeon E5-2692 v2和Intel Xeon E5-2620 v3 2款CPU在向量长度上都是256 bit,后者有2个FMA部件,而前者只有1个。从图11中可以看出,Intel Xeon E5-2620 v3型号CPU测试平台在多1个FMA部件、内存频率提高60%的情况下,单副本的PBR值并没有相应地按比例降低,且部分题目的PBR值还高于Intel Xeon E5-2692 v2的,这说明增加的FMA部件并没有得到充分的利用。比较Intel Xeon Gold 6252N和Intel Xeon E5-2620 v3 2款CPU,前者的向量长度为512 bit,后者为256 bit,两者都有2个FMA部件。从图11中可以看出,在单副本时增加向量长度并没有降低题目的PBR值,说明向量部件没有得到充分的利用。特别地,增加FMA部件或者向量长度使得538.imagick_r题目的PBR值降低。

Figure 11 Single fprate copy PBR results of three architectures图11 3种架构的fprate单副本PBR的表现结果
图12为3种架构的fprate多副本PBR的表现结果。从图12中可知,Intel Xeon E5-2692 v2的PBR值明显高于Intel Xeon E5-2620 v3的,在硬件配置上后者较前者多了1个FMA部件,但L3 Cache大小只有前者的一半,CPU核数是前者的一半。从前文单副本的PBR分析知道,增加FMA部件对PBR值影响较小,且从图8可知两者的多副本得分接近,从而可知L3 Cache的大小对PBR值影响较大。Intel Xeon Gold 6252N与Intel Xeon E5-2692 v2的L3 Cache大小一致,L2 Cache大小是其4倍,前者PBR值明显低于后者,从而可知L2 Cache的大小对PBR值影响较大。

Figure 12 Multi fprate copies PBR results of three architectures图12 3种架构的fprate多副本PBR的表现结果
图13为3种架构的intrate单副本PBR的表现结果。从图13中可以看出,在单副本时,523.xalancbmk_r和525.x264_r 2个题目的表现在Intel Xeon Gold 6252N平台较其他2个平台好,剩余的8个题目的PBR值并没有因为Intel Xeon Gold 6252N平台硬件部件的增强而表现更好。从另一个角度说明,在单副本时,Intel Xeon Gold 6252N平台的硬件资源是相对过剩的,特别地,对于AI领域的531.deepsjeng_r和541.leela_r 2个题目尤为明显。

Figure 13 Single intrate copy PBR results of three architectures图13 3种架构的intrate单副本PBR的表现结果
图14为3种架构的intrate多副本PBR的表现结果。从图14中可以得知,在多副本的情况下,Intel Xeon Gold 6252N平台的PBR值明显优于其他2个平台的,Intel Xeon E5-2620 v3平台的PBR值优于Intel Xeon E5-2692 v2平台的,说明增加FMA部件或者向量长度可以有效地提高定点应用的性能。特别地,在多副本时,AI领域的531.deepsjeng_r、541.leela_r和548.exchange2_r在Intel Xeon Gold 6252N平台的PBR值优于其他2个平台的。

Figure 14 Multi intrate copies PBR results of three architectures图14 3种架构的intrate多副本PBR的表现结果
5 结束语
本文采用SPEC CPU2017对Intel Cascade Lake架构的Intel Xeon Gold 6252N型号CPU进行了不同内存频率、不同副本数、打开/关闭Turbo的组合测试,总结了不同应用程序在该型号上不同软硬件配置的性能表现。同时,本文还对比测试了Intel Ivy Bridge架构的Intel Xeon E5-2692 v2型号CPU和Intel Haswell架构的Intel Xeon E5-2620 v3型号CPU,通过引入计算访存跑分比PBR的概念,分析了3种架构的硬件功能部件的增加对应用程序的性能影响。通过对比测试分析发现,对于浮点应用题目,增加CPU的FMA部件不能显著提高应用程序的性能;向量长度从256 bit增加到512 bit,对高度向量化的应用具有较好的效果,如图像处理领域的imagick应用程序;增加L2 Cache和L3 Cache的大小,在多副本的情况下,表现出较好的效果。对于定点应用题目,增加FMA部件或者向量长度可以有效地提高其性能,特别在多副本的情况下效果明显。
猜你喜欢
当代陕西(2019年13期)2019-08-20
计算机系统应用(2019年2期)2019-04-10
计算机与生活(2016年11期)2016-11-22
公民与法治(2016年19期)2016-05-17
现代电子技术(2015年2期)2015-09-18
电脑爱好者(2015年21期)2015-09-10
读者·校园版(2015年7期)2015-05-14
河南科技(2014年15期)2014-02-27
电子设计工程(2014年6期)2014-02-27
测绘科学与工程(2014年5期)2014-02-27
