
量子线路模拟器QuEST在多GPU平台上的性能优化*
2021-02-03 07:23秦志楷
计算机工程与科学 2021年1期
张 亮,常 旭,秦志楷,沈 立
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
量子计算是一种全新的计算模式,它以量子位为信息单元,遵循量子力学的规律,通过调控量子信息单元来进行计算[1]。量子计算机以量子力学为基础,其理论模型是量子图灵机。由于量子力学态存在叠加原理,量子信息的处理更加迅速,与通用电子计算机相比具有更强大的信息处理能力[2],在合适的量子算法支持下,能够以很低的时间开销来完成密码学、多体系统量子力学和量子机器学习[3]等领域的诸多复杂算法。
然而,量子计算机的实现非常困难,目前仍没有实用化的量子计算机可以用来求解大规模的科学计算问题[4],因此使用电子计算机来模拟量子计算系统成为最常用的研究手段。许多量子线路模拟器应运而生,用来支撑量子领域复杂计算问题的模拟,如ProjectQ、qHiPSTER和QuEST等。这些模拟器作为重要的研究工具,受到了量子计算研究者的高度重视。但是,目前开发出的量子线路模拟器往往会消耗更多的存储资源,带来更多的计算成本。
ProjectQ[5]是一款用于模拟量子计算的开源软件,它的初始版本就具有针对不同硬件的编译器框架,该框架可以对量子算法进行仿真测试,并可以连接到IBM Quantum Experience云服务的后端,在已有的量子硬件上运行。
qHiPSTER[6]是一款在电子计算机上实现的高性能分布式量子线路模拟器,可以模拟常规的单量子位门和双量子位控制门,并针对单CPU和多CPU做出了优化,包括向量化、多线程和高速缓存等。该模拟器既可以实现高性能模拟,又可以达到较高的硬件利用率,仅受到内存的限制[7]。
QuEST量子线路模拟器[8]的全称为量子精确模拟工具包(the Quantum Exact Simulation Toolkit),是第1款开源、采用OpenMP和MPI混合编程开发、支持单GPU加速的通用量子线路模拟器;从日常生活中的笔记本电脑到世界上功能最强大的超级计算机,它在这些经典计算平台上都可以实现量子计算的模拟。QuEST能够在纯态和混合态上、在有退相干的情况下,用状态向量和密度矩阵表示量子状态,模拟由一般的单量子位门、双量子位门和多量子位控制门组成的通用量子线路[9]。
虽然目前已经有了几款开源的量子线路模拟器,但它们普遍都存在资源开销大、模拟时间长等问题,而且不能很好地利用GPU等计算加速器,有的完全没有GPU版本,有的只能在单GPU[10]上运行,有的虽然有多GPU版本,但不具有扩展性和多平台移植性[11]。本文以QuEST为例,分析了其代码结构和性能特性,并实现了QuEST模拟器在多GPU平台上的性能优化。测试结果表明,在4块NIVIDIA V100 GPU构成的平台上,相较于单CPU版本可获得7~9倍的性能加速,相较于多CPU版本可获得3倍的性能加速。
2 QuEST分析
在量子系统中,量子状态不仅可以是二进制1或0,而且可以是同时持有1和0的多种组合,从而形成一个“量子位”。如式(1)和式(2)所示,一个量子位的状态可以用一个二维的状态向量来表示,其中α和β都是复数。多个量子位的表示同理,只要增加状态向量的维数即可。
|φ〉=α|0〉+β|1〉
(1)

(2)
量子门是在一组量子位之间进行操作的基本量子线路,是量子线路的基础[12]。在进行量子线路模拟时,多个量子门的运算是串行完成的,每个量子门都会对全部的状态向量进行一次遍历,完成状态向量的更新计算。QuEST模拟器实现了tGate、sGate、hadamard、RotateX/Y/Z和PauliX/Y/Z等14种量子门。
2.1 算法分析
QuEST模拟器记录了被模拟量子系统的状态,以及各个进程的相关信息。它用一个复数数组来存放全部状态向量,每个状态向量由2个double类型的浮点数构成,分别表示状态向量的实部和虚部,是QuEST模拟器进行计算的基本数据单元。状态向量的总数与被模拟的量子位数有关,假设对拥有N个量子位的量子系统进行模拟,就需要使用2N个状态向量来进行表示。例如,当N=30时,2N个状态向量共需要16 GB内存空间。被模拟的量子系统每增加1个量子位,状态向量需要的存储空间就会随之翻1倍,可见QuEST模拟器的内存消耗很大。
为了提高模拟速度,QuEST模拟器实现了CPU分布式版本,可以使用多个进程在CPU平台上进行量子系统的并行模拟。在并行模拟的初始化阶段会对状态向量分组,组数与进程数相同,每个进程维护1组私有状态向量,并负责它们的更新。对于分布式版本,每个进程还需要1个额外的状态向量数组,专门用于进程间的数据通信,其大小与进程私有的状态向量数组相同,这就导致使用多个进程进行并行量子线路模拟时,存储空间消耗更加巨大。
QuEST源码的核心部分是实现了14个基本量子门的模拟函数,这些模拟函数是基于2个模板实现的。tGate、sGate和PauliZ使用了同一个模板,其特点在于根据输入参数来决定要更新的数据,不存在进程间数据交换。其余函数使用另一种模板,根据输入参数找到对应的进程,先进行数据交换,再完成数据更新。
函数statevec_compactUnitary()是RotateX/Y/Z、PauliX/Y等量子门的核心函数,下面以该函数为例来分析QuEST模拟器的核心计算过程,找出其性能上的不足。
该函数的工作是先将所有状态向量划分为2部分,索引标记分别为a和b,二者之间的差值由输入参数t决定(满足关系:2t=a-b),然后利用a与b对应的状态向量值,使用规定的算法进行更新后得到新的状态向量值,每个状态向量值的更新都需要同时使用到a与b对应的向量数据。
当使用多个进程进行分布式模拟时,如果a与b对应的状态向量属于不同进程,那么先要找到与本地对应的进程(这个过程称为进程配对),配对的进程间进行通信,将对方的状态向量拷贝到本地,然后再继续状态向量的更新工作;如果a与b对应的状态向量都在本地,那么就不需要配对和通信,直接进行状态向量的更新工作。该计算过程的时间开销很大,原因在于每个门函数的计算都需要将所有状态向量遍历1次,数据局部性很差;同时,进程间的通信也会带来很大的时间开销。
值得一提的是,在执行具体的门函数时,同一门函数的核心计算部分循环内部并没有数据相关,可以将循环完全并行化处理,这正是使用单GPU版本可以获得明显加速效果的原因。但是,由于显存限制,单GPU版本并不能满足量子位更多的(例如N>30时)量子系统的模拟。
2.2 QuEST的性能特征
通过对QuEST源码的算法分析,可以发现QuEST是一款计算密集型的应用软件,具有良好的可扩展性和并行性,并且内存消耗巨大。本节以30个量子位的量子系统为例,使用Random与GHZ_QFT 2个量子线路作为测试算例,分别选取单CPU、多CPU和单GPU这几种不同的测试平台,对QuEST模拟器的性能进行测试。
Random测试算例是随机生成的,从Random测试算例的部分代码中可以看出,Random程序调用的门函数是无序、随机的,而GHZ_QFT测试算例模拟的是实际量子线路。
Random测试算例的部分代码如下所示:
Quregq=createQureg(30,Env);
floatq_measure[30];
tGate(q,25);
controlledNot(q,28,21);
controlledRotateX(q,17,5,0.3293660327520663);
rotateX(q,27,3.9207427542347926);
tGate(q,3);
controlledRotateZ(q,27,19,5.459935259485407);
controlledRotateX(q,26,3,4.736990305652013);
controlledRotateZ(q,8,11,3.594728080156504);
rotateX(q,10,4.734238389048838);
rotateY(q,8,4.959946047271496);
rotateZ(q,5,1.0427019597472071);
⋮
对比Random测试算例的代码与GHZ_QFT测试算例的代码可以发现,GHZ_QFT程序中的门函数更加规整,相较于Random测试算例更具有实际的研究意义。
GHZ_QFT测试算例的部分代码如下所示:
/* QFT starts */
hadamard(q,0);
controlledRotateZ(q,0,1,1.5708);
hadamard(q,1);
controlledRotateZ(q,0,2,0.785398);
controlledRotateZ(q,1,2,1.5708);
hadamard(q,2);
controlledRotateZ(q,0,3,0.392699);
⋮
测试环境如表1所示,每个计算结点有2块Intel Xeon E5-2692 V2处理器(内存64 GB)和2块GPU。GPU分别选用NVIDIA Tesla K80(显存12 GB)与NVIDIA Tesla V100(显存32 GB)2种型号。测试结果分别如图1与图2所示。
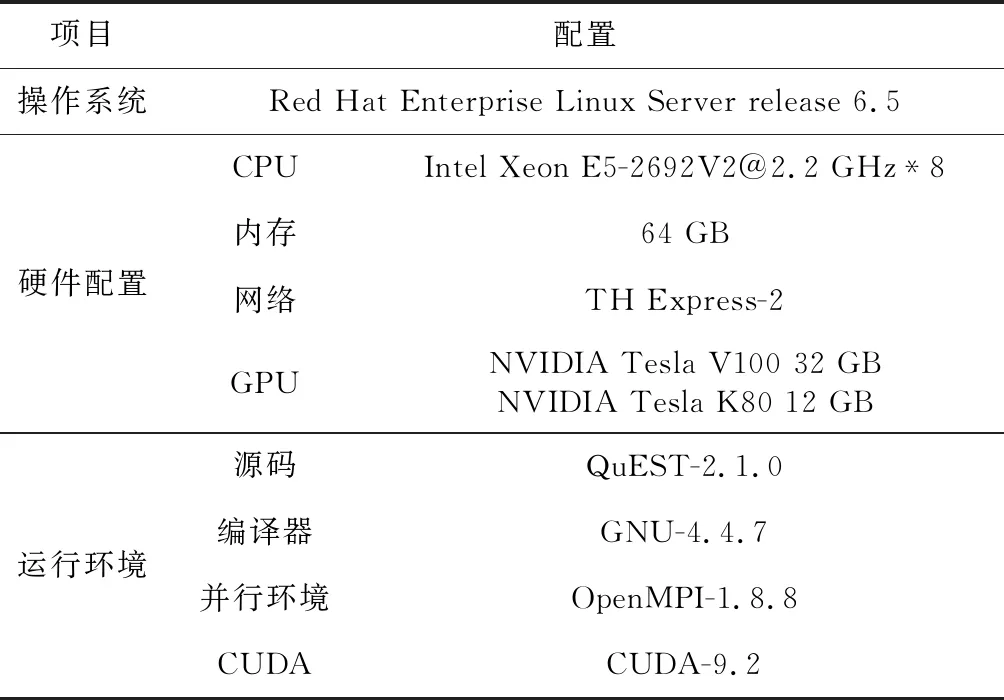
Table 1 Hardware and environment of test experiment表1 测试实验的硬件配置与运行环境

Figure 1 QUEST simulation time (30 bits)图1 30位QUEST模拟时间

Figure 2 QUEST performance speedup (30 bits)图2 30位QUEST性能加速比
图1中横轴表示每组测试所使用的计算平台,纵轴表示每组测试的运行时间,单位为秒。
图2中横轴表示每组测试的加速比(以单CPU性能为基准),纵轴表示每组测试所使用的计算平台。
测试结果表明,对比单CPU与多CPU版本代码的运行时间,可以确认QuEST可扩展性良好。受GPU内存限制,30个量子位的量子系统无法在显存仅有12 GB的NVIDIA Tesla K80上完成模拟,而使用32 GB显存的NVIDIA Tesla V100运行单GPU版本,相较于单CPU版本可以获得高达10.79倍和18.24倍的性能加速比,加速效果明显。这说明QuEST的并行性极好,十分契合GPU的单指令多线程体系结构,使用GPU设备来模拟运行再合适不过,但是对单个GPU的显存容量要求很高。因此,本文设计并实现了QuEST模拟器的多GPU版本,突破了单个GPU内存容量对QuEST模拟器的限制,并大大提高了模拟速度。
3 多GPU版本的实现
3.1 总体框架
1个计算结点通常包含多个GPU设备,QuEST模拟器在MPI启动时可以指定结点数和每个结点的进程数,如果采用每个GPU设备绑定1个MPI进程的设置,当程序处理的数据规模变大,需要增加GPU时,只需要在程序启动时修改MPI的初始化参数即可,这样程序就具有较强的可扩展性。反之,如果每个结点绑定1个MPI进程,即1个MPI进程管理多个GPU设备,程序的可扩展性就会大幅度下降。当结点内的GPU数量变化时,需要对应地修改程序,程序的可扩展性较差。
本文对QuEST的单GPU实现进行了修改。首先为每个GPU设备绑定1个MPI进程;其次在初始化阶段根据模拟的量子位数为GPU分配相应的内存空间,状态向量按照从前至后的顺序分配到多个GPU设备上;然后将单GPU版本的量子门模拟函数修改为多GPU版本;最后完成多GPU之间的数据规约操作,得到正确的计算结果。
门函数的多GPU版本实现参考了CPU分布式版本的代码框架,这里仍旧以statevec_compactUnitary()这个核心计算函数为例,当使用多个GPU时,初始化阶段完成状态向量的分组,组数与进程数一致;核心函数将状态向量分为α与β2部分,并判断2部分数据是否属于同一进程;若是,直接进行状态向量的更新计算;若否,进程配对后进行GPU间通信,将彼此的数据拷贝到对方的GPU显存中,然后进行更新计算。其他门函数的实现过程与此类似,不再赘述。
3.2 多GPU通信
使用多个GPU并行执行应用程序时,需要合理地选择GPU间的通信方式(或组合),这对GPU间的数据传输效率具有非常大的影响[13]。多GPU系统提供了2种GPU连接方式:(1)单个结点内的所有GPU连接到该结点的PCIe总线上;(2)结点间的多个GPU通过集群中的网络交换机连接在一起。这2种连接方式并不互斥,其拓扑结构如图3所示。

Figure 3 Topology of multi-GPU system图3 多GPU系统的拓扑结构
点对点(P2P)传输可以实现GPU设备间的直接通信,对于连接在同一条PCIe总线上的多个GPU而言,这要比使用主机内存中转的通信方式高效得多。不同结点上的GPU设备也可以通过互连网络来完成点对点通信,现有的MPI库支持CUDA-aware,实现了对GPU显存的直接访问。
由于采取1个进程绑定1个GPU的设计思想,所以进程间的通信问题就转换为GPU间的数据交换问题。为每个进程设置了2个数组:一个用来存放本地的状态向量数据;另一个用来存放从配对进程拷贝过来的状态向量数据。并直接使用MPI库中的消息传递函数,在互相配对的2个进程间传输向量数据,以这样的方式来实现多个GPU间的通信。
此外,在实际对源码修改的过程中,发现MPI库中的消息传递函数无法使用“指针+偏移量”的方式来直接访问GPU设备上的数据,因而无法在GPU间分段传输数据,因此本文做出了进一步改进,使用“以空间换时间”的方法解决了此问题。具体步骤为:(1)为每一个进程再分配2个缓冲区B1和B2,用于完成GPU间的消息传递,其中,B1用于向配对进程发送数据,B2用于接收来自配对进程的数据;(2)实现2个Kernel函数,一个将数组内的部分数据写入到B1内,另一个将B2内的数据写回到数组内,从而实现了本地与这2个缓冲区之间数据的分段传递。
4 性能测试与分析
本节仍然采用与第2节相同的环境和算例进行性能测试。
4.1 模拟时间
本节首先对30个量子位的量子系统设计了一组测试实验,对多GPU版本的模拟时间进行测试。仍使用Random与GHZ_QFT 2个测试算例,分别在单CPU、多CPU、单GPU和多GPU 4个平台上进行测试,多CPU和多GPU的数量均为4,实验结果分别如图4与图5所示。
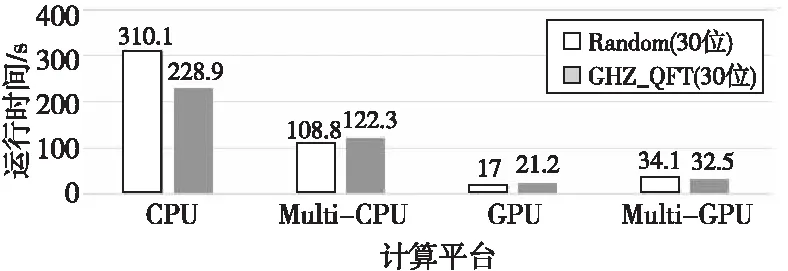
Figure 4 Comparison of simulation time between multi-GPU version and other versions (30 bits)图4 多GPU版本与其它版本模拟时间比较(30位)
图4中横轴表示每组测试所使用的计算平台,纵轴表示每组测试的运行时间,单位为s。

Figure 5 Comparison of performance speedup between multi-GPU version and other versions (30 bits)图5 多GPU版本与其它版本性能加速比比较(30位)
图5中横轴表示每组测试的加速比(以单CPU性能为基准),纵轴表示每组测试所使用的计算平台。
通过数据对比可以发现,对于2个测试算例而言,多GPU版本的代码均可以获得明显的加速效果。对于Random算例,多GPU版本的运行时间为34.1 s,相较于单CPU版本获得的加速比高达9.09倍,相较于多CPU版本获得的加速比大约为3.19倍;而对于GHZ_QFT算例,多GPU版本的运行时间为32.5 s,相较于单CPU版本获得的加速比高达7.04倍,相较于多CPU版本获得的加速比大约为3.76倍。
但是,对比单GPU版本与多GPU版本的运行时间可以发现,单GPU版本的加速效果要优于多GPU版本的。这主要是因为多GPU版本在运行时,GPU之间需要进行通信,从而产生了额外的开销,导致速度降低,这是不可避免的损失,而单GPU版本不涉及此类问题,所以加速效果更加明显。换句话说,在模拟的量子位较少,GPU显存充足的情况下,还是首选单GPU版本来进行量子系统的模拟。同时,虽然多CPU版本也存在通信问题,但其计算收益远远大于通信带来的额外开销,所以相较于单CPU版本可以获得明显的性能提升。
30个量子位的量子系统使用单GPU模拟需要消耗16 GB内存空间,多GPU版本的总内存消耗为48 GB,即每个GPU消耗12 GB。由于B1与B2缓冲区的实现,相较于单GPU版本,多GPU版本引入了4 GB的额外内存开销。
4.2 量子位扩展
本节设计了另一组测试实验,仍旧使用Random与GHZ_QFT 2个测试算例,将被模拟系统的量子位提高到31位,同样分别在单CPU、多CPU、单GPU和多GPU 4个平台上进行测试,测试结果分别如图6与图7所示。

Figure 6 Comparison of simulation time between multi-GPU version and other versions (31 bits)图6 多GPU版本与其它版本模拟时间比较(31位)
图6中横轴表示每组测试所使用的计算平台,纵轴表示每组测试的运行时间,单位为s。

Figure 7 Comparison of performance speedup between multi-GPU version and other versions (31 bits)图7 多GPU版本与其它版本性能加速比比较(31位)
图7中横轴表示每组测试的加速比(以单CPU性能为基准),纵轴表示每组测试所使用的计算平台
通过数据对比可以发现,对于2个测试算例而言,多GPU版本的代码均可以获得明显的加速效果。对于Random算例,多GPU版本相较于单CPU版本获得的加速比高达13.45倍,相较于多CPU版本获得的加速比大约为5.04倍;而对于GHZ_QFT算例,多GPU版本的运行时间为10.7 s,相较于单CPU版本获得的加速比高达42.61倍,相较于多CPU版本获得的加速比大约为18.76倍。
然而,由于显存不足,对于这2个算例,单个同样型号的GPU均无法完成模拟测试,这说明改进后的多GPU版本代码不仅能够带来明显的性能加速,而且还确实解决了GPU显存不足的问题。此外,GHZ_QFT算例模拟的是更加规整的实际量子线路,相对于随机生成的Random算例,它取得的加速效果更加显著,也更加具有实际研究意义。
4.3 结论
通过上述实验,可以得出有关多GPU 版本QuEST量子线路模拟器的3个结论:
(1)多GPU版本代码相对于CPU代码能够大大加速程序运行,加速效果显著;
(2)多GPU版本代码能够模拟具有更多量子位的量子系统;
(3)多GPU版本代码在通信较少的情况下,能够得到比单GPU更好的加速效果。
5 结束语
本文首先详细分析了QuEST量子线路模拟器的算法和可扩展性设计。QuEST目前提供单CPU、多CPU和单GPU 3个版本,虽然单GPU版本的QuEST模拟速度非常快,但是当模拟的位数增加到31位时,模拟所需要的内存已经超过目前市面上内存最大的GPU,所以单GPU版本最多只能模拟30个量子位的系统。当量子位数超过30位时,只能使用多CPU版本进行模拟。为了使QuEST能够模拟更多的位数同时速度尽可能地快,本文开发了多GPU版本,能够模拟超过30位的量子算法,解决了单GPU内存不足的问题。测试结果表明,与多CPU版本相比,本文开发的多GPU版本相较于单CPU版本能够获取7~9倍的性能提升,相较于多CPU版本可以获得3倍的性能提升。
未来将把工作重点放在优化GPU代码上,比如使用各种CUDA的优化技术来对QuEST程序进行加速,使其获得更好的加速效果,也会尝试使用RDMA技术优化结点间的通信,使其通信效率更高;同时,本文工作并没有修改QuEST模拟器的框架,但目前已经有一些工作利用张量网络和张量积解决量子线路模拟器内存消耗过大的问题[14-17],如何使用这一方法优化QuEST将是接下来的一个研究方向。
猜你喜欢
小哥白尼(趣味科学)(2021年6期)2021-11-02
故事作文·高年级(2021年4期)2021-05-06
小哥白尼(神奇星球)(2021年11期)2021-03-08
中国外汇(2019年20期)2019-11-25
中国外汇(2019年8期)2019-07-13
中国学术期刊文摘(2016年2期)2016-02-13
新乡学院学报(2015年6期)2015-11-06
电网与清洁能源(2015年2期)2015-02-28
装备环境工程(2015年5期)2015-02-28
电力工程技术(2014年5期)2014-03-20
