
基于神经网络和傅里叶描述子的残缺面部图像的识别与分析
2021-02-03 08:47张春阳
无线互联科技 2021年1期
吴 卓,梁 珂,张春阳
(北京信息科技大学,北京 100000)
0 引言
在医疗或者刑侦领域,有时会出现残缺的人脸正面图像无法与已存入系统中的完整人脸图片相对应的情况,基于此情况为更好的解决实际问题,采用图像识别的相关知识对人脸面部图像进行识别与分析,在一定程度上,能够协助警方或者医护人员对一些残缺图片进行匹配以便加以处理和推断,从而大大提升破案率和医疗协管水平。目前,在此项目方面的研究主要有以下成果:
(1)对完整的图像进行识别已经有比较成熟的技术,但是对于残缺的图片识别仍然存在着缺陷。
(2)彭正初[1]明确提到目前不变矩的傅里叶描述子能够很好地处理相关图像,但对于残缺图像,尤其如何针对小型图像块进行傅里叶描述子的特征提取和识别,具有重要研究意义和实际使用价值。
(3)Zhang K[2]提出了一种多任务卷积神经网络模型,能够很好地识别出人脸,甚至是鼻子、嘴等部位。
(4)在图像分割方面,何思雨[3]提到一种Canny边缘检测算法,同时结合图像生长分割算法和区域分割算法能够很好地完成一些图像的分割。
目前,对于完整图像的识别与分割是图像处理领域研究最多的课题之一,而对于残缺图像的识别也必将在研究的范围之内。图像识别技术属于模式识别的范畴,而近年来在该技术所发展起来的人工神经网络模式以及模糊模式识别分类在图像识别中受到越来越多的重视。傅里叶描述子,不仅是目前应用最广泛的描述子,而且是最具有发展潜力的形状表示算法之一。傅里叶描述子作为全局形状特征的一种描述方式,具有计算简单、较高的形状区分能力的显著优势。在完整图像的识别方面已经有了一定的成果,对于残缺图片方面的识别和分析也是未来发展需要突破的关键点之一。
1 项目原理
1.1 傅里叶描述子
傅里叶描述子(Fourier descriptor)是一种图像特征,具体来说,是一个用来描述轮廓的特征参数。其基本思想是用物体边界信息的傅里叶变换作为形状特征,将轮廓特征从空间域变换到频域内,提取频域信息作为图像的特征向量,即用一个向量代表一个轮廓,将轮廓数字化,从而能更好地区分不同的轮廓,进而达到识别物体的目的[4]。
一般来说,我们拿到的图像,是一个处在二维平面的图像,所以可以使用坐标表示的方法对图像的轮廓特征信息进行初步的表示。同时,因为数据维度的问题,可以采用复变函数的思想,将二维坐标系的x轴作为实轴,将二维坐标系的y轴作为虚轴,这样就能在二维的基础上将向量转化为一维空间的向量。具体公式为:

接下来,对公式(2)进行傅里叶展开得到公式(3—4):
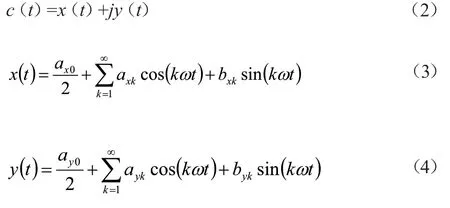
此时:

最后,将公式(5)axk,ayk,bxk,byk进行整合,就得到了最后的傅里叶描述子。
1.2 离散化的不变矩傅里叶描述子。
目前,对于傅里叶描述子有关方面的研究是将需要识别的形状算出区域矩阵特性,然后对特性使用傅里叶变换,从而对形状进行特征表达。因此,在识别形状之前需要先对目标区域实施图像预处理,具体包括:图像增强、图像分割、跟踪曲线轮廓;然后,由得到的物体的形状边界坐标序列,通过计算出划分的各个子区域的矩特征值得到一个特征值序列;最后对这个序列做傅里叶变换得到傅里叶描述子。在对物体形状的矩特征实施计算之前,应先确定物体对应的质心坐标,并把质心坐标当成中心点,以固定角度将物体划分为若干份扇形区域,再对扇形区域的矩特征值进行计算。计算时需要注意利用相同阶次的矩,将得到的矩特征值排列成矩值序列,从而实现对物体形状的特征表达。这种方法尽管弥补了容易受干扰和稳定性差的问题,但其作用在小型图片上尤其是一些残缺的分块图片时,极易产生边界不封闭的问题,大大影响了特征提取结果的准确性。
所以,本项目采用离散的傅里叶(Discrete Fourier Transform,DFT)变换对由坐标函数产生的复变函数进行处理。如公式(6):
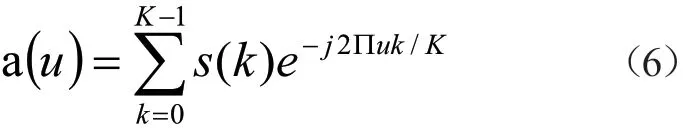
经过式(6),就可以将最初状态下的连续情况转化为离散的情况。同样,这也从一定程度上弥补了传统意义下的傅里叶描述子在边界不封闭这一方面的缺陷。而本项目也可以采用反向变换的形式,如公式(7):
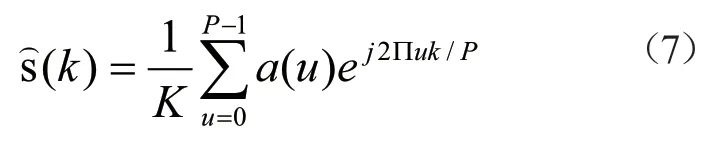
经过式(7),就可以从傅里叶描述子中得到相关的位置特征信息。
1.3 多任务卷积神经网络
多任务卷积神经网络(Multi-task Convolutional Neural Networks,MTCNN)是一种将人脸区域检测与人脸关键点检测相结合的一种方法。和opencv中的cascade类似,通常情况下分为3个部分,即:P-Net,R-Net,O-Net[5]。
1.3.1 P-Net
P-Net基本的构造是一个全卷积网络。对已经构造完成的图像金字塔,使用全卷积网络(Fully Convolutional Networks,FCN)进行初步特征提取与标定边框,并进行Bounding-Box Regression(边框回归)调整相应窗口尺寸与非极大值抑制(Non-Maximum Suppression,NMS)进行相关窗口的过滤,P-Net具体原理如图1所示。
1.3.2 R-Net
在P-Net的基础上增加了全连接层进行更加严格的筛选。所以图片在完成P-Net进入R-Net后,模型会将上一个阶段所得出的结果进行进一步的筛选,换句话说,相比于上一步,这一步的目的就是得出更加精确的结果。R-Net相应原理如图2所示。
1.3.3 O-Net
相比于R-Net,O-Net 增加了一个卷积层,同时其本身的模型是一个更大的256的全连接层,很好地将图像的特征等一系列信息进行了保存,大大提升了识别率与准确率。R-Net相应原理如图3所示。

图1 P-Net相应原理

图2 R-Net相应原理
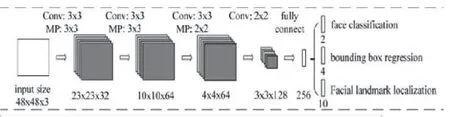
图3 R-Net相应原理
1.4 双峰阈值分割法
通俗来讲,双峰阈值就是分析人脸图像,得出灰度级直方图,如果图像呈现双峰状,就选取双峰之间的最低处作为阈值。同样的,可以通过人脸的灰度变化规律提取包含相关五官部分的标定区域(Region of Interest,ROI)图片,然后通过这种方法将图片按照五官定位的方式进行分割[6]。双峰阈值分割法相关原理如图4所示。可以看出,介于[40,60]之间的波谷位置,即为此方法所求的阈值。

图4 双峰阈值分割法原理
2 图像的特征提取与分析
2.1 数据来源
原始数据:ORL人脸数据库,由英国剑桥大学AT&T实验室创建,包含40人共400张面部图像,部分志愿者的图像包括了姿态、表情和面部饰物的变化。ORL人脸数据库中一个采集对象的全部样本库中每个采集对象包含10幅经过归一化处理的灰度图像,图像尺寸均为92×112,图像背景为黑色。其中,采集对象的面部表情和细节均有变化,例如笑与不笑、眼睛睁着或闭着以及戴或不戴眼镜等,不同人脸样本的姿态也有变化,其深度旋转和平面旋转可达20°。ORL数据集如图5所示。
2.2 算法整体结构与实验结果
总体来说,本项目使用多种算法相结合的方式进行。具体步骤如下:
首先,本团队对数据进行筛选,利用MTCNN算法,通过3个部分,即P-Net,R-Net,O-Net,对人脸和人脸的特征点进行识别,以根据特征点的数量以及图像的清晰程度对图像的进一步筛选,将不符合条件的数据很好地剔除,以提高实验的精确度。
其次,对上述筛选好的图6进行分割,考虑到实际情况下人的正面图片所展示的五官中,耳朵所占比例不大,且较为模糊,所以,只对眼睛、鼻子、嘴这3个比较清晰的部分进行区域分割。本项目采用两种方法进行分割。第一种,按照人体五官比例进行按距离切分,通过查阅资料可以得到,人的鼻子位于人脸的黄金分割点,所以可以以这个作为定位标签,对其范围进行切分。第二种,采用双峰阈值分割的方式进行分割,利用灰度直方图,提取包含五官部分的ROI图片,利用灰度直方图双峰之间的低谷作为阈值,能够在很大程度上保留分割以后图像的局域完整性,避免距离切分造成的分割不彻底或者分割区域不合适导致后续的准确率降低。当然,这两种方式一般是结合使用,如对于五官中的眼睛,眼睛和皮肤在灰度直方图上有明显的阶跃,明显的阶跃导致采用双峰阈值法时阈值的选取会很容易,并且分割的结果会很理想。而当同种方法应用于鼻子部位时,可能不同的图片就会有一些不同,导致结果产生偏差,影响最终实验结果。部分分割结果如图7所示。
最后,分割完成,将图片按照分割的结果进行存储,便于接下来的特征提取。特征提取的方式上,本项目采用改进后的离散化的不变矩傅里叶描述子,将分割后的图像送入到模型之中,得出离散的一些值。经过分析得到的值普遍波动较大,所以本团队采用归一化的方式,对这些特征结果进行规范化,以将结果统一在一个合适的范围。为了增强结果的可表示性,本团队将对应特征信息转化为对应特征图,具体实验结果如图8所示。

图5 ORL数据集

图6 对人脸和人脸的特征点进行识别

图7 部?分分割结果

图8 分割的具体实验结果
通过以上的步骤,得到了有关于人脸五官的特征信息。本团队使用由两个卷积层,一个全连接层组成的卷积神经网络,将人脸五官的特征信息与已经存在与系统中的某些数据信息进行对比,按照合适的置信度进行加权,得出最终的相似度。各个部分对应模型识别结果如表1所示。
为了避免出现偶然性,采用交叉验证的思想,每个模型训练两次,得到4个相关模型。同时两两组合,分别进行4次识别,得到的相似度结果如表2所示。最终,按照3∶3∶2∶2的数据集拆分比例对上述相似度进行加权求和,得到最终的相似度结果为93.13%。经过统计得出实验次数与相似度的折线图如图9所示。综上所述,本实验的总体流程如图10所示。

表1 模型识别结果
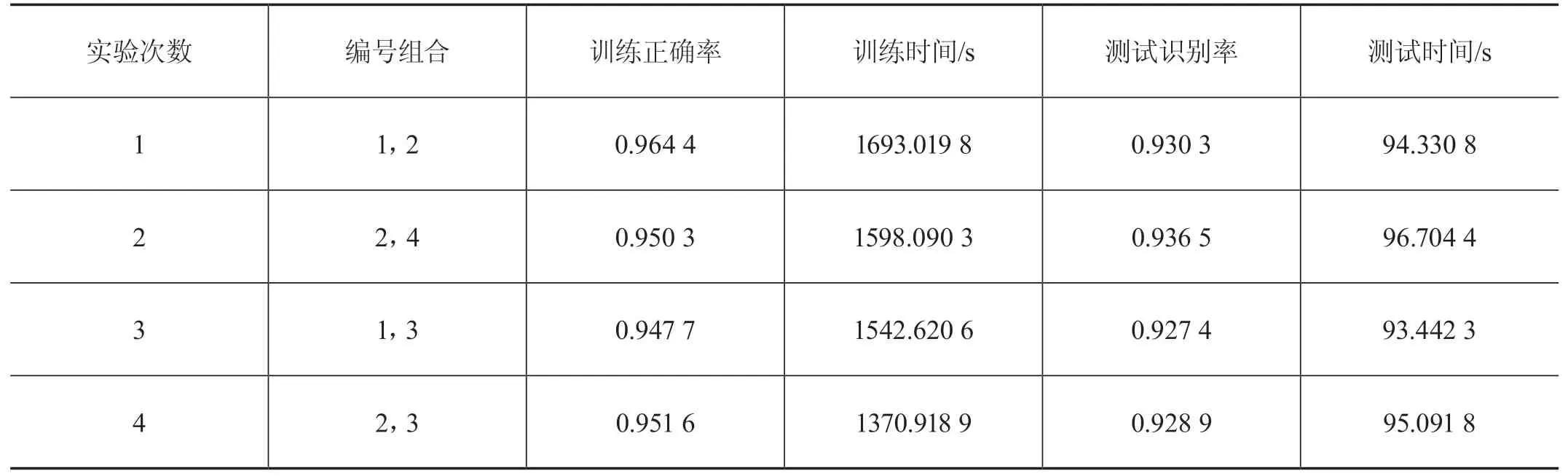
表2 两两组合的识别结果

图10 本实验的总体流程
3 结语
本文提出了基于神经网络和傅里叶描述子对残缺面部图像的识别与分析的方法,在传统的傅里叶描述子的基础上进行了改进,主要有以下3点:(1)结合了离散化的思想,将傅里叶描述子进行离散化,以避免传统傅里叶描述子的边界不封闭问题。(2)在离散化的基础上同样采用了不变矩的思想,三者进行结合,提高了傅里叶描述子在图像特征提取方面的鲁棒性。(3)能够将傅里叶描述子应用于残缺图像的特征提取上,结合MTCNN等一系列算法,对残缺图像进行整理和分析。实验表明,改进后的方法将更好的实现残缺图像与完整图像的匹配与识别,具有很高的实用意义。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
宝藏(2021年5期)2021-06-14
数学物理学报(2019年2期)2019-05-10
文化交流(2019年3期)2019-03-18
测控技术(2018年7期)2018-12-09
金融服务法评论(2018年0期)2018-12-06
动漫星空(2018年9期)2018-10-26
中国工运(2018年8期)2018-08-24
舰船科学技术(2016年1期)2016-02-27
电测与仪表(2015年5期)2015-04-09
