
基于网络行为的人物心理刻画方法
2021-02-03 08:47张文凯李卫巍
无线互联科技 2021年1期
耿 琦,张文凯,李卫巍
(江苏金盾检测技术有限公司, 江苏 南京 210042)
1 引言
用户画像又称用户角色,是根据用户在网络上留下的各种个人信息而制作的由词汇组成的画像。作为一种描述用户自身情况、了解用户诉求与其思考方向的工具,用户画像在各种互联网服务业中得到了广泛的应用。在实际绘制过程中,画像者往往会以最为简洁明了与接近现实的语言将用户的各种心理上的属性与实际行为形成映射。作为用户的虚拟形象,用户画像会根据用户社交状态、日常习惯以及消费偏好等信息描绘出一个由标签组成的用户形象。标签,是对某一类指定群体或个体其中的某种特征进行分类概括所得的文字。用户画像的核心与基础组成就是标签。通过标签,用户画像能够对用户的特征进行具体又多样的描述,同时又具有对指定特征的针对性,从而以此作为心理分析的一种依据。标签的定义需要对用户的数据进行分析与筛选而得到。
用户画像主要用于对用户的网络行为进行心理分析。网络行为是指人们直接或间接借助互联网所做出的现实行为。用户在进行自己的个人网络行为时会在运行这些功能的网络应用上留下自己的使用痕迹,即行为记录。包括购买记录、支付记录、观看记录等。这些记录能够充分反映个人的起居习惯、工作习惯、娱乐习惯等个人心理的展示媒介,用户画像对他们的总结与分析能允许研究者进一步对用户的心理进行充分的了解。
用户画像的关键就是标签,通过对个人形象的标签化处理,它可以描摹出一个用户的信息“轮廓”,来大致了解用户的行为、消费习惯等可以用于分析用户心理的重要个人信息。且易于及时修改,无须在出现重大变动后重新对用户进行实际调查,而是在用户数据中修改变动后重新绘制即可。同时,用户画像的标签是由用户的海量历史数据中分析所得的,可以较为准确地反映不同的时间与空间下用户的属性与行为,受用户个体的自身当前喜恶、心情等精神状态影响较小(如问卷受此影响就较大),使得心理刻画更为准确。此外,用户本身的标签“画像”是心理刻画的优秀媒介,它能够较为直观地展示用户的需求与行为,成功刻画用户心理。
同时,在对个人用户进行心理分析时,若采用传统的问卷调查等人工方式,不仅因为纸质媒介的局限性而使搜集到的个人数据有限,而且由于个人对他人了解自己日常生活行为或多或少的抵触感,被调查者往往不会对自己的个人行为进行完全详细且准确的描述,从而使得个人心理分析出现一定量的偏差。而用户画像是对用户自己独自进行的网络行为进行分析,能够在用户不产生抵触感的情况下真实反映其心理情况,并且由于行为记录的多渠道与多方面,网络行为对个人心理情况的反馈是多样的,因此用户画像的心理分析能够更加全面且准确。除此之外,用户画像的研究是基于计算机的,计算机的强大处理能力使得它进行数据处理的效率大大提高,从而在心理分析方面具有更大优势。
在用户画像的定义与构成方面,国外研究者D. Travis[1]提出了7个用户画像的基本特征: 基本性、情感性、真实性、独特性、目标性、数量性和应用性,并将这7个特性的英文首字母组合后即成为“用户画像”这个名称。而T. Lafouge[2]等认为用于对用户的特征信息进行分析的因素主要包括两个方面:与用户个人相关的静态因素(如该用户的个人基本信息、日常行为以及习惯等不易改变的因素) 与用户外部的动态因素(如机进行分析时所处的网络环境、搜索的目标等可变的因素)。国内研究者中,曾建勋[3]提出从用户的专业知识、兴趣、工作等方面提取用户画像标签。李映坤[4]对用户画像的基本构成进行了拓展,提出了基于自然属性、关系属性、兴趣属性、能力属性、行为属性与信用属性的用户画像构建方法。刘海鸥等[5]在研究中对用户自身的情境要素进行了探究,将用户画像的构成划分为自然属性、社交属性、兴趣属性和能力属性。
在用户画像的具体方法上,国外研究者Nasraoui.O等[6]提出可以利用数据挖掘技术从网站日志中发现用户的行为模式,并采用K-Means聚类算法将用户分成不同的集群,构建集群的用户画像;而Q. Liu 等[7]通过隐含狄利克雷分布模型对用户社交中感兴趣的话题进行分析,由此构建融合了用户的兴趣的画像模型。而在国内研究者中,王洋等[8]通过广泛研究发现,可将用户在互联网上的访问记录以及用爬虫获取的数据作为用户画像构建的基础,并通过大数据技术对用户网络行为数据进行处理,以此构建的用户画像在准确度方面得到了明显改善。
尽管目前的用户画像方法已经在用户心理分析方面取得显著效果并被广泛应用于实际推荐系统中,这些方法仍然存在一定的缺陷:首先,这些已有的方法大多数都基于人工抽选的较为分散且不相关的特征,这些特征无法对用户数据的相关联信息一起进行刻画,因此对于被画像者的形象描述程度有限。其次,现有的用户画像方法通常基于较简单的线性回归或分类模型,无法在处理数据的过程中学习到更高级的特征分析,因此不能对各特征之间的关系进行更深层次的描述。
用户画像虽然能够通过标签较为精确地反映用户个体的属性与行为,但其以标签为基础的性质使得其只能对一个人的性格进行碎片化处理,研究者从用户画像中得到的是也只能是个人心理属性的一种概括,并不能完全从一个人的各方面描述其情感与习惯。“贴标签”的心理分析,在强调个人属性的一方面的同时,也掩盖了此属性的其他潜在衍生部分,忽略了更多的分析可能性。而且,用户画像其中包含的无关数据与冗杂数据也相对于人工方式来说更多,从而使数据的处理变得更加复杂和充满可变性,个人的心理分析偏差度甚至会超过人工分析方式。且无法收集用户的一般现实社会日常行为的记录,而一般现实行为对用户更加基础的心理反应也因此被忽略,整个个体心理分析的实际程度会打折扣[9-10]。
1 用户画像基本理论与技术
1.1 用户画像基本理论与绘制流程
1.1.1 目标确定
构建用户画像之前,需要确定构建者的目的,用户画像服务于何种对象,以及对象的具体数目,以便选择合适的构建方法。用户画像分为个人画像与群体画像,由构建对象的数目来决定。对于心理刻画与性格确定,一般偏向选择个人画像,使用Python与网络爬虫进行实现。而对于商品推荐、精准营销等商业用途,则更偏向于群体画像,需借助大数据技术进行数据收集与分析,再根据数据完成画像。本文采用个人画像进行实验。
1.1.2 确定并寻找数据源
用户画像的来源是用户数据,而用户数据的来源一般来自互联网上的各种网络应用。不同应用中的用户使用记录会反映用户的不同属性。因此通过多种渠道搜集用户数据是进行用户画像的前提,同时搜集到的数据与画像目的的关联性能够直接反应用户画像的准确性。
若搜集数据的对象为个人,则不仅可以在网络上获取相关用户数据,也可以将用户个体实际调研作为一种补充数据的备选方案,因其操作难度相对于大众调研来说降低很多。同时要务必注意在搜集他人私密数据时需要获得他人许可。
1.1.3 数据分析
确定了数据源并搜集到数据后,需要对各种数据进行分析,去掉其中相对不关联的数据与冗杂、重复数据,为后续的画像做好准备。数据的分析通常需要相应的算法来实现,算法需要提前确定来及时完成分析。可参考相关文献与类似设计来了解算法,或对现有算法进行一定程度上的优化,使其更符合自己程序的目标。用户画像如今一般使用的数据分析算法为K-means算法与TF-IDF算法。K-means算法一般用于对数值文本所反映的用户属性进行总结,而TF-IDF算法会对用户的文本记录进行其中的关键字提取。
K-means聚类算法,又称k均值聚类算法。它是聚类算法中的一种,因其实现方法较简单,且聚类效果显著,因此在进行数据聚类时经常采用的算法之一。它基于数据均值来对各样本点进行聚类,K表示将数据分成k个聚类,又称簇,means表示均值,是指取每一个簇中的数据值的均值作为该簇的中心,又称为聚类中心或质心,它可以视为整个簇的代表。K-means算法基于这些变量进行聚类分析,让簇内的点尽量紧密地连接在一起,而簇间的距离要保证尽量的大。means算法的基本流程图如图1所示。
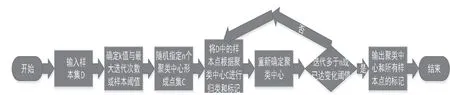
图1 K-means算法流程图
TF-IDF算法,也称词频-逆文本频率算法。是一种常用于数据信息检索的算法,用于评估一个字或词对于一份普通文件或语料库(指经过科学分类的电子文本库)中的一份文件的重要性。图2为TF-IDF算法流程图。

图2 TF-IDF算法流程图
1.1.4 标签构建
用户画像的核心就是标签。标签的构建是整个用户画像构建的重中之重。根据数据分析中得到的结果形成关键字,而关键字就是标签的原型。对关键字进行适当的处理后就会形成标签。标签代表了用户画像的主体各属性。若标签较多,也可以将标签组成标签树,形成分层结构,从而对不同属性值进行再一次分类,使属性分类更加详细。同时可以制作一张标签表,便于对所有标签进行总览,进行增删改查。在用户画像中,标签表一般会存储在文本文件中。
标签一般会采用能够最直观反映用户的基本信息或内心需求的相关词语,如生日,常听的音乐,购买的商品等。对它们的选择倾向即是用户画像侧重点的选择。如多选择用户的购买喜好和商品价格就是偏向对用户的购物心理进行画像,而多选择用户体重、健身卡办理次数和行动距离就是偏向对用户的运动心理进行画像。
此外,确定标签的权重也是在创建标签中的一个重要步骤。标签权重表示此标签对应属性在整个用户属性集中的占比,因为不同标签所对应的属性重要性不同,而不同属性对用户的心理反应全面程度也是不同的。而标签的权重,就是对这种反映全面程度的量化表示。权重可以是不同的计算单位,由具体研究情况决定,通常情况下是标签或其代表关键字的出现概率,此值可由TF-IDF算法确定。画像时可以将其附加在标签自身属性上,形成映射,凸显不同标签的重要性大小。而凸显的方式也是各异,大多数选择体现在标签字体大小上。
1.1.5 绘制画像
在获得所有需要的标签后,需要的就是将标签按顺序填充进用户指定的图片中,组成一个人形。这个人形,就是由用户画像构建的用户个体的虚拟形象,个体的大部分属性均可以在此幅图像上体现出来,在之前计算出的标签的权重在此幅图中会根据画像者的需求来表示。若有需要,可以在用户画像旁进行属性的总结,以显示用户个体的一些更加贴近现实生活的细节。
绘制出的用户画像可以充分展示用户个体的内心倾向、喜恶、性格等心理元素,是心理刻画的优秀产物。借助计算机的计算能力,人们可以仅仅利用自己的“历史记录”就能勾勒出自己或者他人的基本性格外框,为了解他人乃至以此获得商业利益奠定了基础,在这个信息时代开辟了一块全新领域。
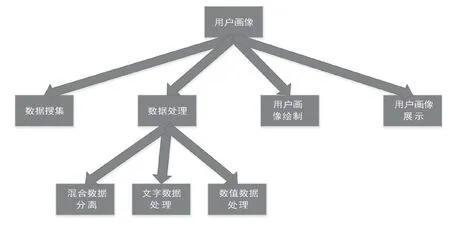
图3 用户画像算法需要实现的主要功能
2 用户画像具体算法实现
在本文中,用户画像算法要实现数据搜集、数据处理、用户画像绘制、用户画像显示4个功能。其中数据处理功能又分为混合数据分离、文字数据处理与数值数据处理3个子功能。算法的主要功能如图3所示。
2.1 数据搜集
为了保证数据的真实、全面与可获得性,数据搜集模块中使用的网络爬虫软件为“八爪鱼采集器”,通过它的自定义采集数据功能,可以搜集到较为全面的网络用户数据,如淘宝购买记录、微博关注列表、个人音乐歌单等。而对于需要用户登录才能进行数据采集的情况也能很好地进行解决。并且搜集到的数据会作为csv文件导出,供用户画像程序使用。
2.2 数据处理
数据处理部分主要完成3个工作:混合数据分离,数值文本处理和文字文本处理。通过这3个过程,可以从搜集到的数据中提取出关键字并加工成标签,是整个用户画像中的核心。
2.2.1 混合数据分离
在进行数据处理时,可能会出现数值与文字结合在一起的混合数据文本。由于用户数据中的数值部分与文字部分分别会提取出不同性质的关键词,所以需要进行分离。此功能只需在通过网络爬虫获得的文件为混合数据文件时使用。
通过网络爬虫读取它们的混合方式一般是作为文件中前后两个不同的列出现,可以在使用Python中的文字处理模块pandas进行csv文件的读取后,利用loc方法再对读取到的文件进行逐列的读取。而csv模块中的writer方法可以创建新的csv文件并进行输入与输出,将读取到的各列按照读取到的不同数据,再通过pandas模块的逐行输入方法writerows分别输入进创建的新csv文件中,从而做到分离混合数据。
2.2.2 数值数据处理
在数值中提取出的关键词虽然不是用户标签的主要组成部分,但它们反映的用户属性往往更为直接且透彻,成功分析商品价格、使用次数等数值数据来得到用户关键词是用户画像流程的核心之一。
2.2.3 文字数据处理
在文字中提取出的关键词是用户标签的主要组成部分。用户使用、访问记录等文字数据广泛存在于各种网络应用中,对它们的分析是一个用户画像绘制程序的又一个核心。本文利用TF-IDF算法来计算关键词的出现频率,并可以根据用户数据中的每个词的出现频率进行关键词的提取。因此,文字数据处理能够提取的关键词非常多,虽然步骤较少,但获得关键字的速度较快。
2.3 用户画像绘制
在获得标签表后,就可以进行用户画像绘制工作。Python中的wordcloud词云模块算法是用户画像绘制功能的主要使用算法。它会根据用户提供的文本和图片自动将文本填充进图片轮廓内的空白处,形成非常直观的用户画像,且可设置多种自定义参数,如标签字体、标签大小、图片轮廓颜色、生成图片大小等,不同需求环境下的用户画像均可绘制。并且,在绘制完成后还可以将其保存为任何可用格式的图片文件。将基础图片、字体、背景、画像大小等必要参数设置完毕后就可进行绘制。
2.4 用户画像显示
绘制用户画像并以图片文件保存后,需要进行用户画像的展示。可以直接利用Python的图片处理模块PIL进行图片悬浮窗口展示。用PIL模块下的Image类中的open函数读取图像文件,再使用ImageTk类中的PhotoImage类形成可以被Python直接调用的图片数据,最后创建一个全新悬浮窗口,在其中创建一个标签控件,将其背景设置为需要展示的用户画像图片,即可进行展示,如图4所示。

图4 悬浮窗口示例
3 实验结果分析
3.1 实验过程
3.1.1 用户画像配置环境
操作系统:Windows 10
编程语言:Python 3.7.2
开发环境:PyCharm
网络爬虫软件:八爪鱼采集器
3.1.2 实验任务
绘制用户画像需要对互联网上搜集到的数据根据其类型进行分类,之后分别进行分析,并对分析结果进行关键字提取。接着将关键字加工成为标签,并输入指定文本中形成标签表。最后根据标签表进行用户画像的绘制,并将其作为一般图片文件进行输出。全部任务可以整合至一个用户画像程序中完成。
3.1.3 程序流程图
用户画像的所有实现算法可以在一个程序中实现,此项程序的核心功能是绘制个人用户画像。其主要运行流程如图5所示。
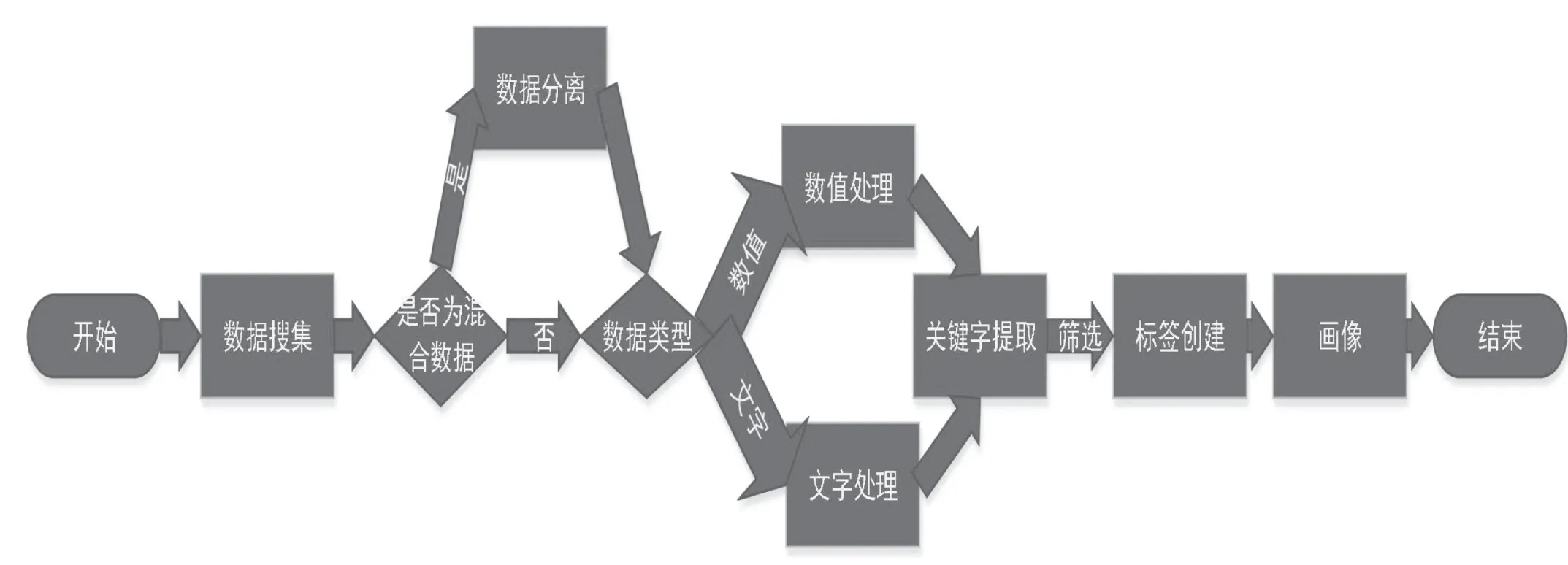
图5 程序流程图
3.1.4 基本窗口UI设计
对于一个用户画像程序,简单的操作是一个十分重要的要求。而简洁又实用的窗口UI就是实现这种功能的好方法。由于此用户画像程序的主要操作功能为文字数据处理、数值数据处理、混合数据分离、用户画像绘制、用户画像展示这五个,所以UI界面需要将这些功能在一个界面中直观地展示出来。Python中的tkinter模块可以进行基本的UI设计与编写,利用其中可以生成的标签、文本框和按钮等控件来实现所需要的UI。
3.1.5 程序具体运行流程
输入需要分离的混合数据文件名,点击“混合数据分离”按钮,进行混合数据分离工作,完成数据分离后会有提示框跳出并指出分离出的文件的名称。
输入需要进行文本数据处理的文件名,点击“关键字生成”按钮,进行文本数据处理,程序完成处理后会有提示框跳出。
输入需要进行数值数据处理的文件名和数值数据的主体名,点击“kmeans聚类”按钮。
会显示本数值数据进行K-means聚类适合的簇数k。
重复(2)、(3)步骤,直至将所有需要进行分析的数据文件进行处理后,点击“生成用户画像”按钮,会将文件中用户指定的肖像作为原材料进行画像,完成后会提示任务完成。
点击“显示用户画像按钮”,显示生成的用户画像,如图6所示。

图6 用户指定的肖像
经过用户画像的绘制与展示步骤后出现的图片为用户画像程序的结果。它由人物轮廓与标签组成,能够直接反映用户数据的大致信息与用户的心理情况,如图7所示。

图7 用户画像展示
3.2 实验结果与探讨
3.2.1 K-means算法实验结果分析
K-means聚类完成后,只使用其各属性进行结果展示十分难以理解,与Python代码可读性强的特性不符。为了使K-means聚类分析的结果更加简单易懂,可以使用Python中运算模块Matplotlib下的Scatter函数来绘制散点图。其绘图方式基于数组,是数值分析结果展示的绝佳选择。将获取的数值文件的序号与数据本体分别作为x、y轴,并辅以不同的标记点与颜色,使得数据本体一目了然。同时使用同属Matplotlib的plot函数进行单独样本点,在本实验中也就是聚类中心的添加,以凸显聚类结果。以下将不同K-means算法聚类结果用散点图表示出来(见图8—10)。
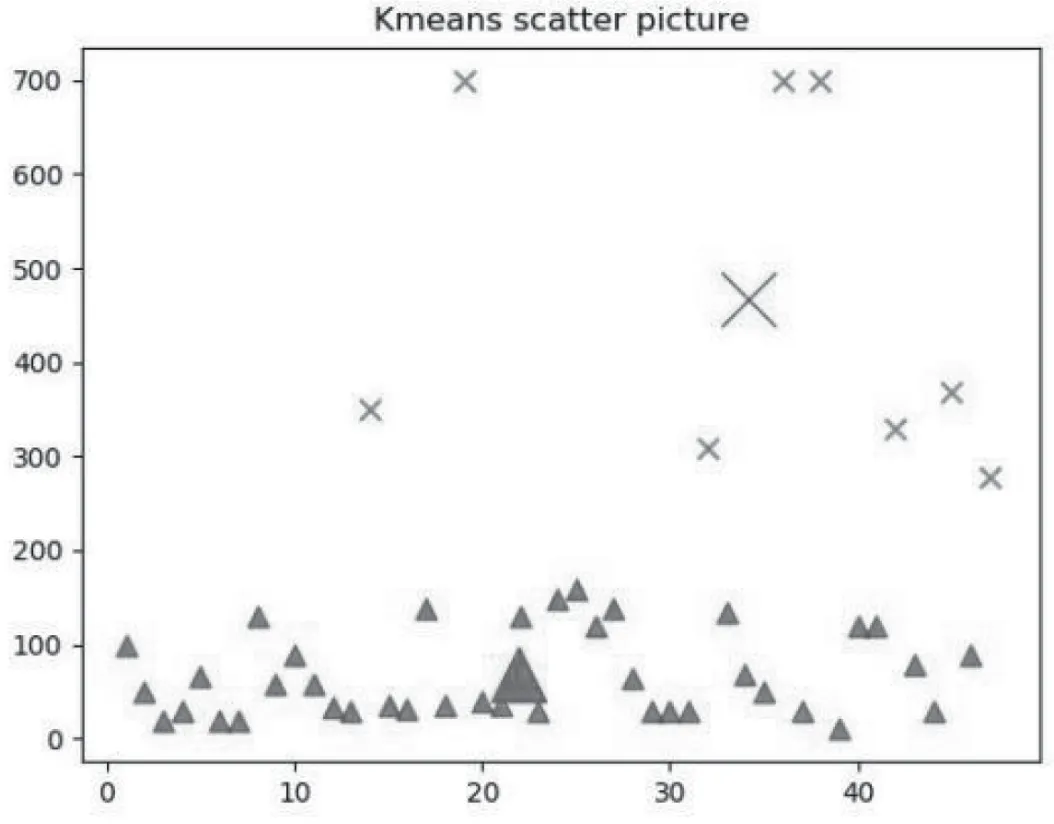
图8 k=2时数据聚类散点图
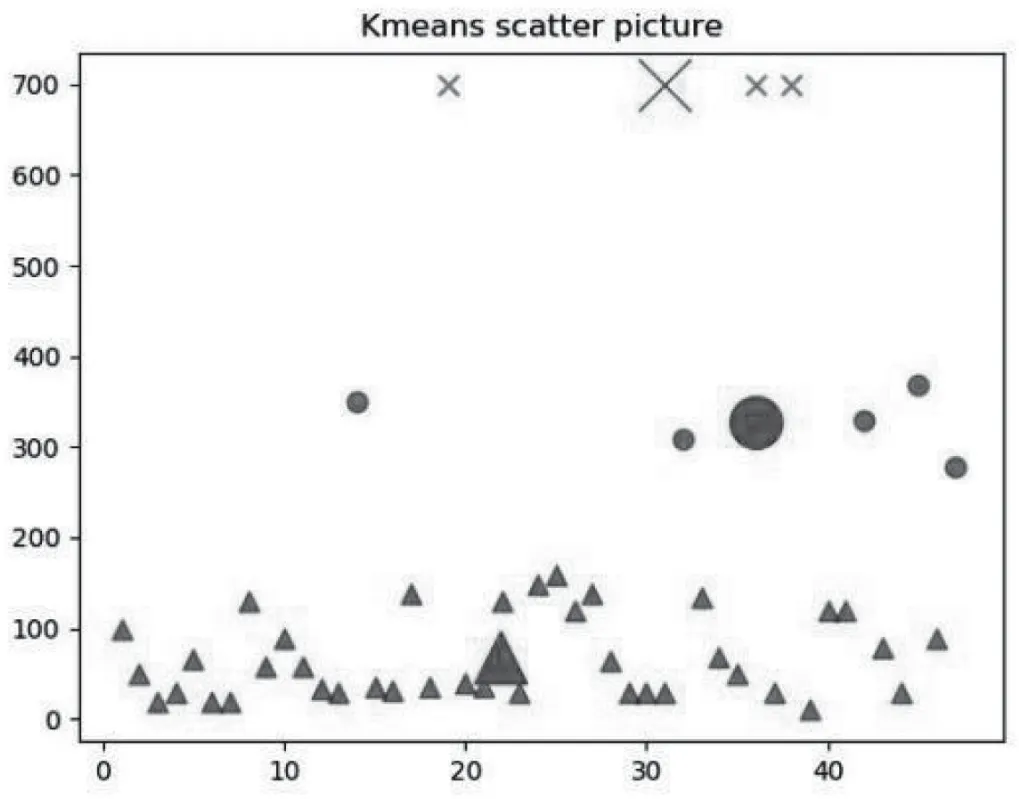
图9 k=3时数据聚类散点图
由散点图中的实验结果可以看出,k=2和k=4时的聚类效果都比k=3时效果要差,在k=2时,y值处在600~700的几个点无法独立成一个簇,使得其中一个簇的成员分布过于分散。而k=4时将最大的簇中的一些样本点强行分割成新簇,反而使聚类结果过于复杂化。
这种情况的出现,是因为对于K-means来说,它的算法在一些方面存在着局限性[11]。
在选定初始聚类中心时,一般只能在样本点中随机选择或者直接指定平均值,而这些值可能与理想位置相差甚远,导致在开始聚类时就已经可能出现误差。
由于K-means的簇数k值只能自选定,缺乏有效性和可检验性。

图10 k=4时数据聚类散点图
在样本点中,经常出现距离较近但实际上数据相关性较低,或是距离较远但数据相关性很高的多个样本点。而K-means算法只是基于样本点与类之间的距离进行划分的,无法有效辨别此两种样本。
上文提到的情况就是K-means算法局限性中的k值自选定问题。为了解决这种因为不同k值而导致的聚类分析效果差异问题,本文采用了上文提到的最优间距来提前衡量不同k值下K-means聚类的效果[12-15]。以搜集到的购买商品价格记录为例,计算出k值分别从2取到9时的最优间距,具体见表1。
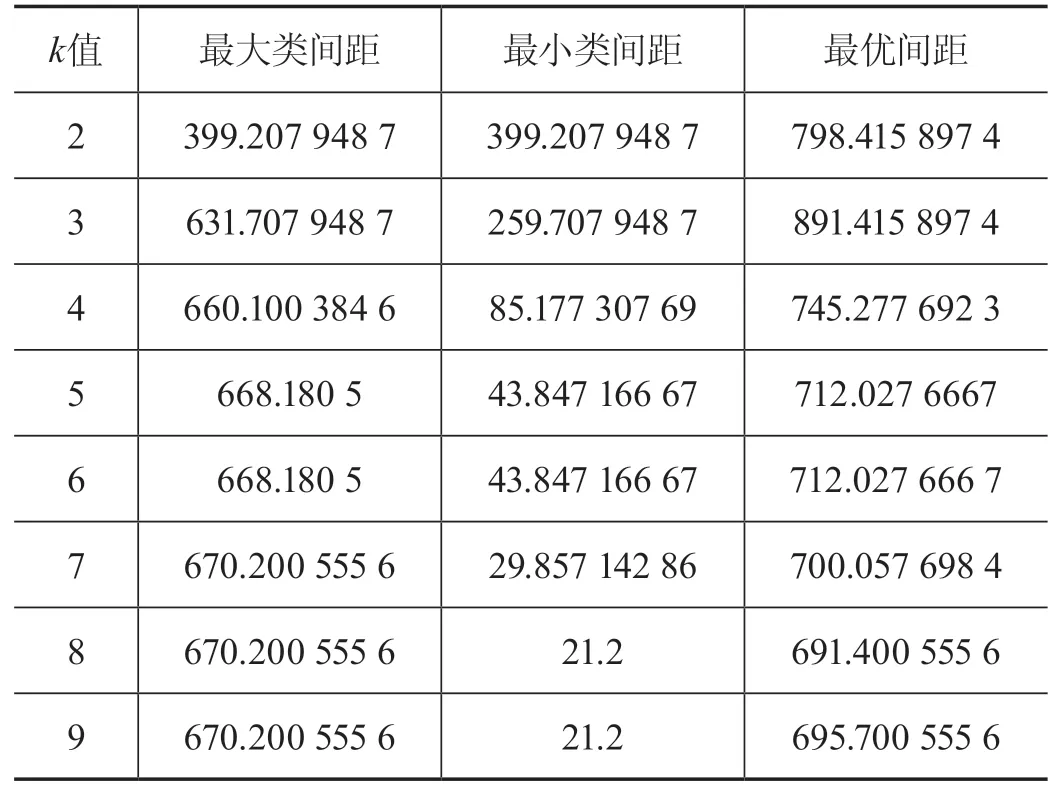
表1 不同k值下的最优间距
根据多次计算,k值在超过样本数量1/5后最优间距几乎不再进行上下波动,这是因为簇过多,最优间距完全是随其趋势变化,开始稳定,导致实验效果不准确。为了保证聚类效果,k值限定在样本数量的1/5之内。由于此样本记录约有50个,故将k限制在10以下。根据上表,我们可以画出k值与最优间距关系的折线图(见图11)。
由图我们可以得出,当k值取3时,聚类的效果与平衡性之和达到了最大。因此可以确定,在正式使用K-means算法时将k值设置为3的聚类效果最好。

图11 k值与最优间距的关系折线图
3.2.2 用户画像绘制结果分析
用户画像中的标签各式各样,虽然均是从用户数据中提取而来,但其是否真正起到描述用户心理情况的作用,仍需要进行检验。因此,用户画像中的标签是否有效,是用户画像绘制结果的衡量标准之一。关于文字数据的关键字提取部分,本文提出了“假高频关键字”这个概念。它代表着那些出现概率高但毫无实际意义的关键字,实际上就是无效关键字。TF-IDF算法在完成关键字提取时,经常会出现无效关键字。将它们筛选掉是本文需要进行解决的问题之一[16]。
经常出现的“不与其他文字搭配的独立数字”(以下简称“独立数字”)就是假高频关键字的代表[17-20]。因此在这里,我们将通过这种独立数字的出现程度来衡量用户画像的误差值。计算独立数字出现的概率,首先需要读取所有已经通过数据处理功能获得的关键字。之后,需要对所有已经读取的关键词进行遍历,找出其中出现的独立数字,并统计其数量。因为独立数字的取值范围一般为0~999,所以可以将所有找到的符合关键字强制转换为浮点数进行检测。最后,计算独立数字出现概率与所有关键字的比值,就是此次用户画像的误差值。其核心公式为:,其中mis为误差值,topw为关键字总数,count为独立数字(或任何假高频关键字)的总数。
在用户画像研究领域中,上文提到的停用词筛选是比较常见的提高用户画像准确度的方法。在这里,我们使用极其容易出现独立数字的淘宝用户购买商品名称记录来统计此用户数据的用户画像的误差值[21]。
首先,分别在extract_tag方法中将采集关键字总数topK设置为40、30、20、10、5来计算独立数字的出现次数,并计算出现次数与关键字总数的比值,即用户画像的误差值。其结果如表2所示。
而如果我们使用停用词筛选,向停用词文本中逐个输入0~1000内的数来将所有可能出现的独立数字,将其作为停用词进行过滤后,再执行extract_tag方法进行误差值统计,其结果如下表所示,误差值有了非常明显的下降。因此,在用户画像的关键字采集时启用停用词筛选功能能够有效提高用户画像标签的有效性,进而提高用户画像的准确度(见表3)。
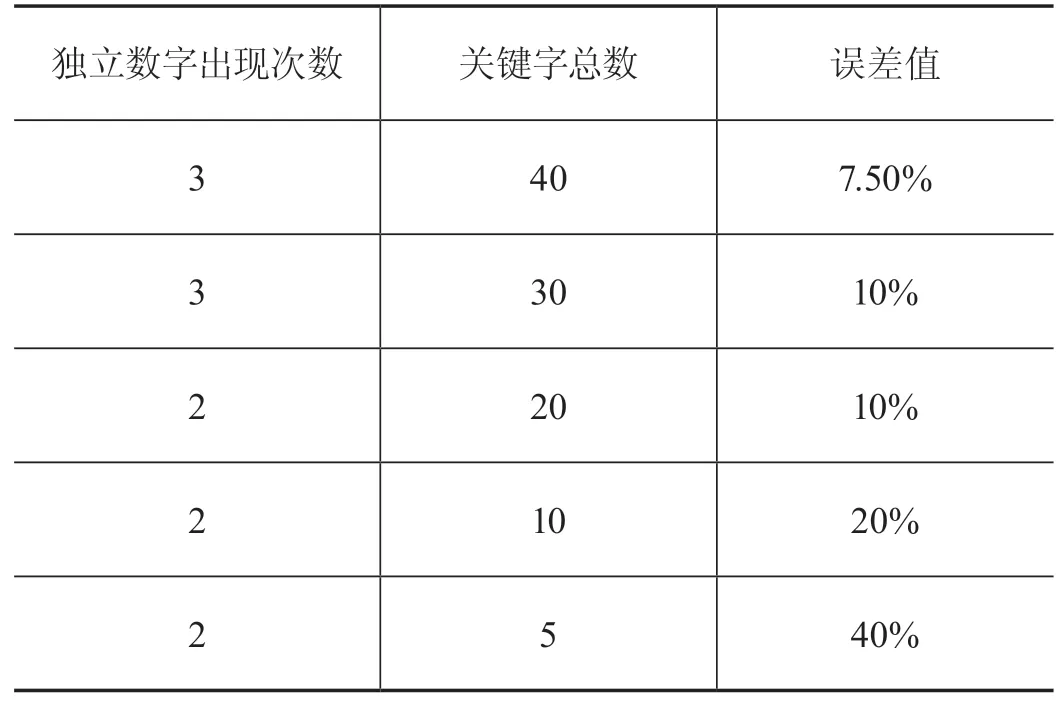
表2 误差值统计表
同时,由于TF-IDF算法是基于词在不同文本的出现频率来进行关键字的提取,而这种算法势必会忽略掉一些关键字,为了解决这个问题,本文还采用了基于有向有权图pagerank的textrank算法进行了关键字补遗操作。它的在通过TF-IDF算法筛选并提取关键字时同时采用textrank算法进行并行提取,在将关键字作为输入标签表前,会将textrank算法筛选出的关键字与TF-IDF算法筛选出的关键字进行比较,相同的关键字就直接输入标签表,若出现未被TF-IDF算法而是被textrank筛选筛选出的关键字,就将其加入标签表作为补遗,以此进一步提高用户画像的准确度。分别对文本进行TF-IDF算法和textrank算法的关键字分析,运行结果如图12所示。可以看出,textrank算法筛选出的关键字与TF-IDF算法的有一定重合,而其不重合部分正好可以作为补遗部分。
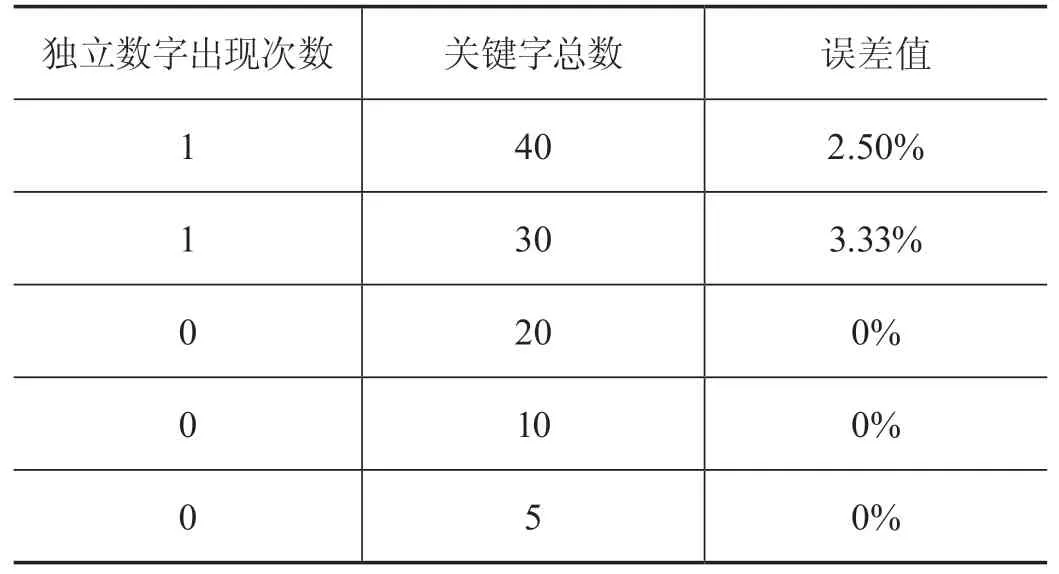
表3 停用词筛选后的误差值统计表

图12 两种算法运算结果对比
综上所述,我们在进行用户画像时,可以使用停用词文本对无效的关键字进行过滤,同时使用额外的关键字提取算法,如textrank算法进行关键字的补充,从而在进行用户画像时提高其准确性。
4 结语
随着互联网的发展和网络用户的增多,针对用户个体的心理需求而进行服务的更新成了很多互联网企业的挽留客户的手段。而根据用户网络行为来进行心理刻画也就因此变成了服务中的一个必要工作。用户画像作为个人心理刻画的重要手段之一,一直在互联网研究领域中占有重要地位。本文对用户画像的绘制方式进行了探讨与实践,并队用户画像算法中的一些不足进行了研究与改进。本文在绘制用户画像的具体算法上采用了K-means算法和TFIDF算法来分别对数值文本和文字文本进行关键字提取和标签生成,并设计通过wordcloud算法实现了用户画像图片的生成。所有的算法均在PyCharm开发环境上使用Python语言实现,并通过tkinter模块实现用户界面操作。K-means算法存在着其k值上必须要事先由用户指定的问题,而TF-IDF算法在关键字提取时有着无效关键字过多和关键字遗漏的问题。本文通过研究K-means算法中的k值与聚类间距的关系,而在聚类执行前算出最适合当前数据的k值,然后直接代入算法,优化了K-means算法的执行效率;同时采用停用词过滤功能与textrank算法补遗,在TF-IDF算法执行完毕后对其获得的关键字结果进行了优化,提高了标签的有效性。
猜你喜欢
疯狂英语·新悦读(2023年9期)2023-12-02
小哥白尼(神奇星球)(2022年3期)2022-06-06
华人时刊(2022年1期)2022-04-26
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
动漫界·幼教365(大班)(2019年10期)2019-10-28
童话世界(2018年17期)2018-07-30
中国卫生(2014年9期)2014-11-12
延河(下半月)(2014年1期)2014-02-28
中国土地科学(2010年10期)2010-03-20
