
基于数据驱动的电动汽车动力电池SOC预测*
2021-02-02 08:13高志文
汽车工程 2021年1期
胡 杰,高志文
(1.武汉理工大学,现代汽车零部件技术湖北省重点实验室,武汉 430070;2.武汉理工大学,汽车零部件技术湖北省协同创新中心,武汉 430070;3.新能源与智能网联车湖北工程技术研究中心,武汉 430070)
前言
近年来,新能源汽车逐渐成为汽车工业的发展趋势,也是我国战略性新兴产业之一。但是其续驶里程短,充电设施少和电池能量密度低等问题仍阻碍电动汽车产业的发展[1]。为解决市场和用户对电动汽车能耗及续驶里程的担忧,除须推进电池技术的研发以及充电设施和电网的覆盖,还须基于实际运行数据对电动汽车能耗进行研究,以提高电池能量的利用率[2]。
为准确预测电动汽车动力电池能耗,国内外学者做了大量研究。其中Ng 等[3]首次提出安时积分法,该方法通过对电池充放电电流积分得到电池充放电能量,实现剩余电池容量的实时计算。Lee 等[4]对电池长时间静置下的开路电压与电池SOC进行线性分析,通过测量电压计算SOC 值。李革臣等[5]使用内阻法,通过分析电池内阻与SOC 的特定关系进行预测。Fang 等[6]提出基于卡尔曼滤波的方法,该方法在建立等效电池模型基础上建立卡尔曼滤波状态方程与观测方程,将SOC作为状态参数进行预测。在此基础上Zhang 等[7]提出一种基于扩展卡尔曼滤波算法与Rint 模型相结合的SOC 预测方法,可以有效减少计算量。Fan 等[8]提出结合安时积分法和EKF 算法,将工作电压和电池SOC 作为观测变量和状态变量,并通过递归最小二乘法确定模型参数,提高预测精度。在人工智能迅速发展的今天,智能算法也被用于动力电池的能耗预测。He 等[9]开发了基于人工神经网络的电池模型,根据测量的电流和电压预测SOC。Kang 等[10]提出一种径向基函数神经网络模型用于消除电池退化对原始训练模型精度的影响。Liu 等[11]提出一种用于电池剩余能量估计的反向传播神经网络。Alvarez Anton 等[12]使用支持向量机方法从实验数据集预测电池SOC。Hu 等[13]提出基于双重搜索优化过程的优化支持向量回归机的SOC预测方法。鲍伟等[14]提出使用支持向量机与贝叶斯优化的方法对电动公交车SOC 进行自主预测。
综上所述,目前主流SOC 预测方法大多使用电池内部复杂电化学参数进行预测,主要侧重研究电池内部机理与物理特征,而对于汽车实际行驶工况与参数的可测量性以及实际路网中交通参数的结合研究较少[15]。汽车实际行驶时工况变化频繁,在不同工况下能耗差异较大,且复杂电化学参数在汽车实际行驶过程中测量困难。因此在上述研究的基础上,通过数据驱动的方法进行SOC预测,并将预测的SOC值与实际上传的车载BMS估计的SOC值进行相互佐证,为优化动力电池能量管理、发现电池能耗规律、提高能量利用率提供科学依据。
1 电动汽车数据采集
1.1 电动汽车数据采集流程
所使用数据为某新能源公司已投放使用的电动出租车在2018-2019 年内的实际运行数据,数据采集频率为0.1 Hz。数据由安装在汽车上的车载数据采集设备获取,数据传输按照GB/T 32960《电动汽车远程服务与管理系统技术规范》执行,车载数据采集设备由车载诊断系统(OBD)接口供电。当车辆启动后车载诊断系统从车辆的CAN 总线中实时读取车辆运行状态参数,同时利用定位系统(GPS)获取车辆位置数据,数据的采集频率可以根据需要进行调节。采集的数据符合国家标准的TCP 通信协议,数据以数据流的形式通过无线网络传输到监控平台,参照GB/T 32960 将所需要的信息解码,最终形成可以利用的数据。数据的采集处理流程如图1 所示,仅对数据应用层研究部分进行详细说明。
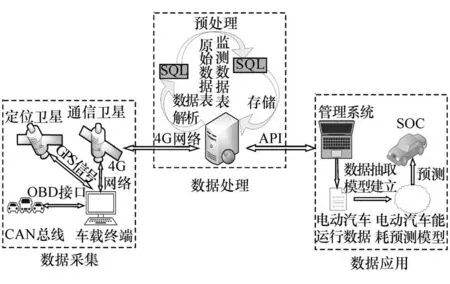
图1 电动汽车数据采集处理流程
电动汽车SOC是指电动汽车动力电池剩余容量与总容量之比[16],即电池剩余可用电量,计算公式为

式中:Qremain为电池中剩余的电池电荷容量;Qdischarged为最近一次充满电后电池中已经放掉的电荷量。
1.2 电动汽车能耗构成分析
为准确预测电动汽车动力电池能耗,首先须提取能耗相关影响因素。因此对电动汽车行驶中的能耗构成进行分析[17],具体如下。
电动汽车行驶模型如图2 所示。当汽车从A 点移动到B 点的过程中,电池所消耗的能量E总耗能可以分解为牵引力做功E牵引、空调能耗E空调和其他附件能耗E其他,而牵引力做功所消耗的能量又分为汽车行驶过程中动能变化ΔE动能、重力势能变化ΔE重力势能、克服道路滚动阻力耗能E滚阻、克服行驶过程中风阻耗能E风阻和传动系统能量损失E传动损失。

假设道路滚动阻力系数f 与坡度角θ 为常数,且E风阻与E传动损失之和与E牵引成正比,比例为λ,因此由动力学公式可以推导化简为


图2 电动汽车行驶模型
因此电动汽车行驶中能耗构成为
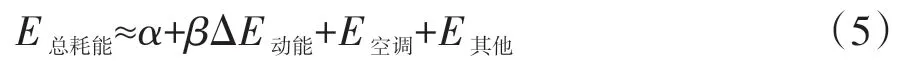
由上述分析可以得出,电动汽车动力电池能耗主要与动能变化和空调耗能有关。其中动能变化由汽车的行驶速度决定。而空调能耗在一般行驶工况下占整车能耗的10%~20%,怠速情况下占比为77.08%[18],且与外界温度直接相关,但通过车载终端无法直接获取外界温度信息,考虑使用经纬度与时间信息结合并通过爬虫技术进行温度匹配,而汽车的运行工况与电池工作工况又可通过电压电流进行表征,因此须提取上述能耗参数进行后续的分析与建模。
对原始数据进行能耗参数提取,并通过解码后的数据格式如表1 所示。其中共提取5 辆同款电动出租车在一年内的实际运行数据作为实验数据来源,有效数据共有3 000多万条。
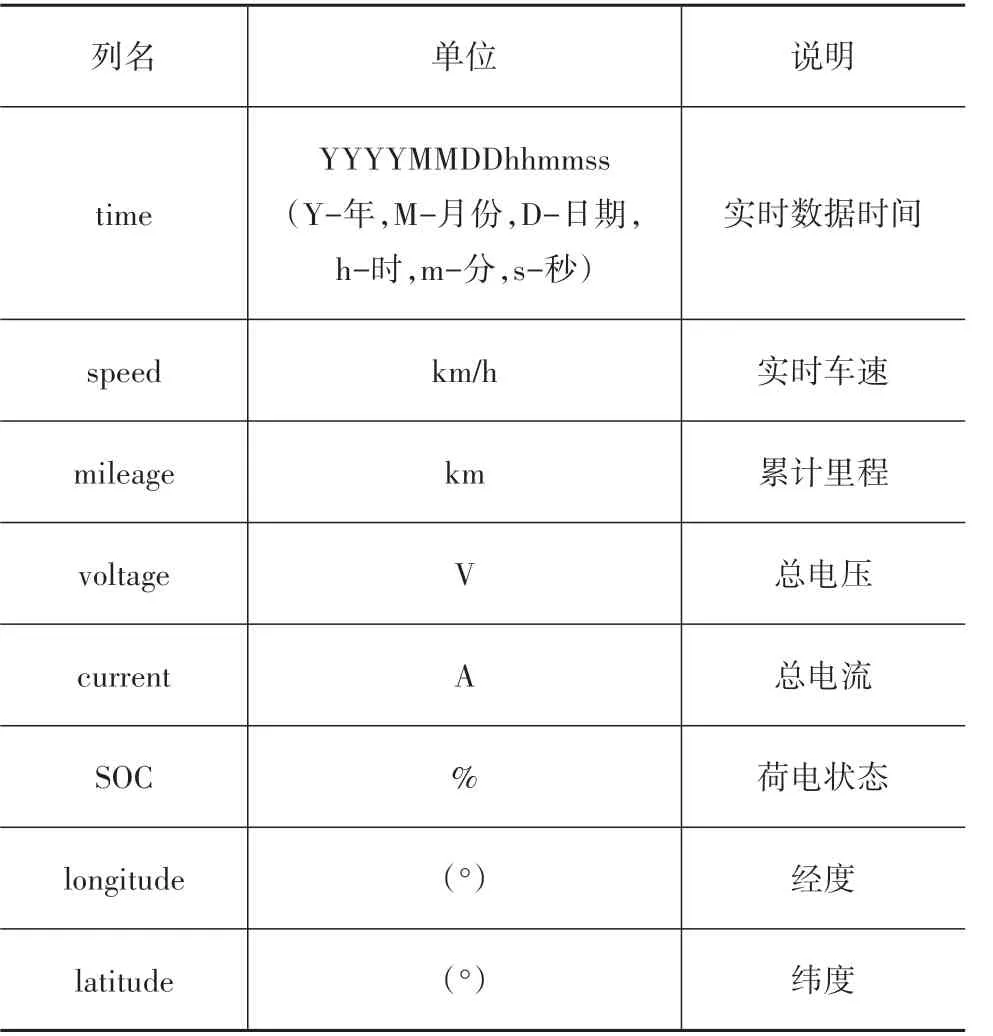
表1 数据信息格式说明
2 电动汽车数据预处理
2.1 数据可视化
绘制部分数据的SOC 分布如图3 所示。由于汽车行驶数据是通过传感器进行采集,传感器信号可能存在延迟和丢失等情况造成数据的异常与缺失,因此需对异常数据进行处理。

图3 SOC变化分布
2.2 数据清洗
由图3 可知,采集数据中包含大量充电数据,本文通过判断连续的静止片段内是否出现电流为负来筛选充电片段并进行删除处理,还对图4中里程为0的异常值与缺失值进行线性插值填补。

图4 行驶里程变化分布
汽车的实际行驶数据由多个运动片段组成,电动汽车的运动学片段定义为车辆从停车开始到下一次停车开始的运动[19],且通过运动学片段的特征数能够把握片段的主要属性。因此对行驶数据进行切片处理,使单条数据转换为运动学片段,每个运动学片段均由停车、匀速、加速和减速4种行为构成。
2.3 基于变量解耦的数据同分布
采集数据中训练数据集与测试数据集分布图如图5~图8所示,其中μ、σ、skew、kurtosis分别代表数据分布的均值、方差、峰度以及偏度,两条曲线分别为样本实际分布和拟合标准正态分布(Normal dist.)。由于目前多数机器学习算法须保证训练集与测试集的数据呈独立同分布,以使所训练的样本具有总体代表性,减小因训练集中的个例样本而导致的模型误差增大,但此数据下的SOC 和片段行驶里程特征表现为耦合状态。

图5 目标测试集SOC分布

图6 目标测试集里程分布
因此本文中提出了一种基于分箱处理的滑动窗口重采样方法,实现对多维变量耦合分布的解耦处理。该方案同时考虑了行程片段的起始SOC和片段行驶里程的影响,分箱方式如表2 所示。对于运动学片段的起始SOC 和行驶里程进行分段,考虑到算法效率与精度的结合,将起始SOC 在20%以上数据分为8段,标记为A-H,将行驶里程分为6段,标记为a-f。事实上当SOC 达到20%以下时,驾驶员应即刻去进行充电而不是选择继续行驶,但考虑到数据完整性,本文也将SOC 为20%以下的数据考虑在内,并将其标记为X。
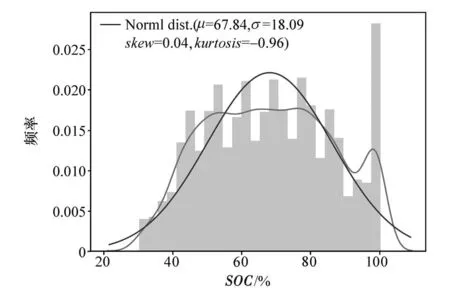
图7 训练数据集SOC分布
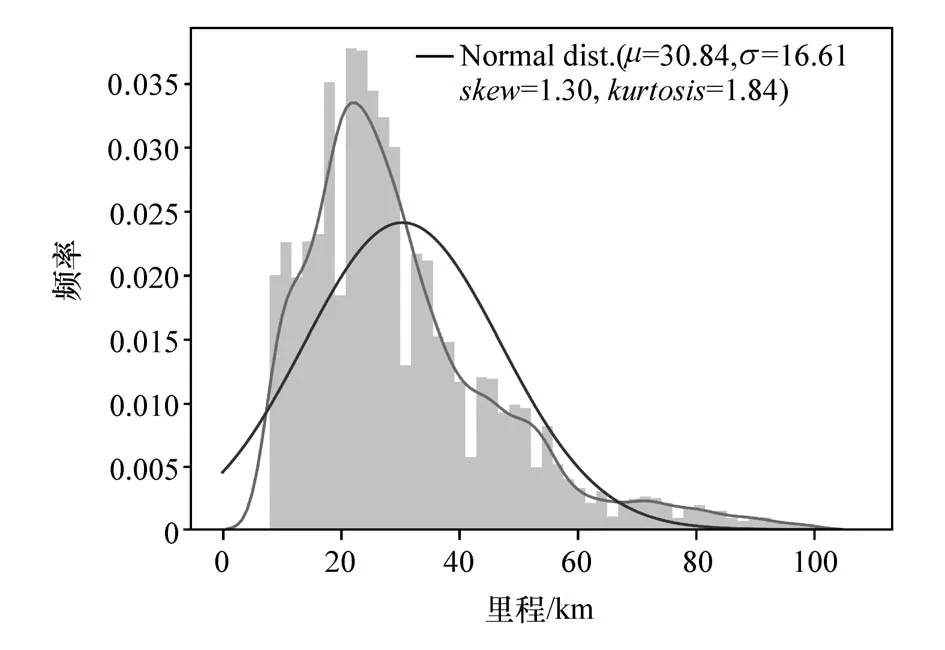
图8 训练数据集里程分布
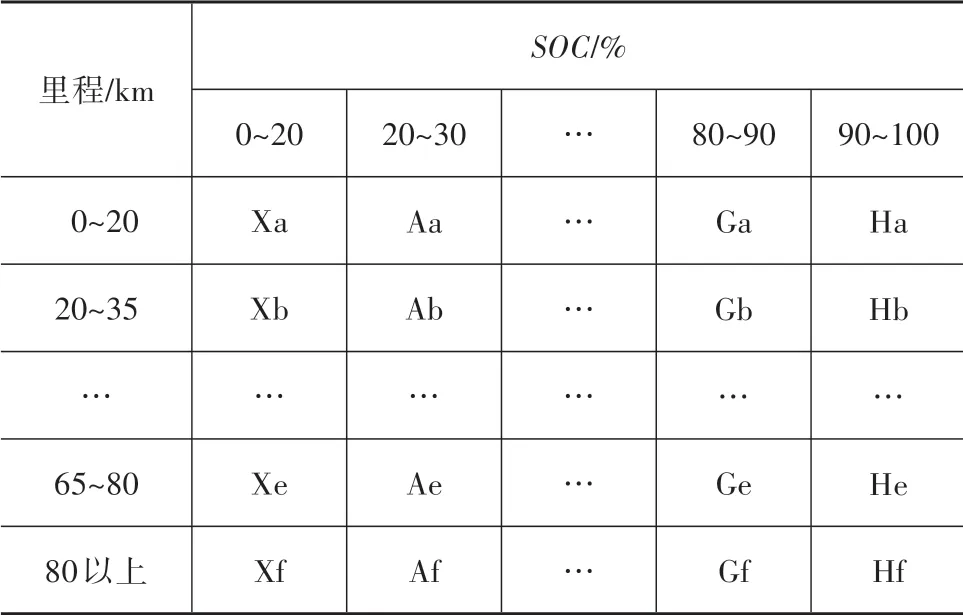
表2 SOC与里程分箱表
为使训练集与测试集同分布,并扩充训练集数据样本个数,采用基于滑动窗口重采样的方法对训练集样本进行重采样,可以得到大量新的运动学片段,将重采样数据与原始训练集合并后,根据测试集分布重新扩充原始的训练集,扩充结果如图9 和图10所示,此时训练集与测试集近似同分布。
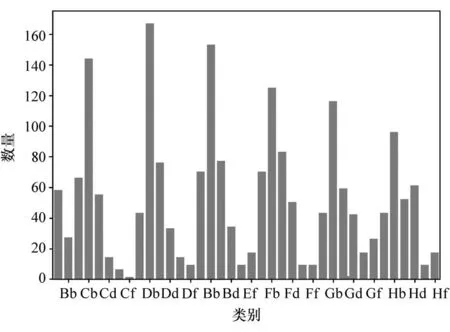
图9 测试集分布

图10 同分布后数据集分布
3 能耗特征构建与选择
机器学习中,为使算法达到最优性能,须通过特征工程对数据进行处理使原始数据转化为特征,从而对数据中所包含的信息进行充分挖掘,使模型能够更好地进行学习。因此须构造动力电池能耗相关特征,以便模型进行学习与训练。
3.1 能耗特征构建
由于电动汽车在不同的行驶工况下,电池SOC的消耗规律不同,因此须构建汽车行驶工况相关特征。目前国内外对此研究较为深入,本文中基于Wu等[20]提出的10 个工况特征参数,并对其进行进一步完善,提出包括最大加速度、速度标准差和平均速度等15 个特征参数进行输入。其次外界环境温度影响动力电池的充放电性能,从而影响SOC 消耗。本文中通过爬虫技术,根据已知的经纬度与时间信息得到按小时记的温度信息作为外部环境特征,而车辆的自身状态信息可由汽车传感器获取。在此构建了共20 个特征,如表3 所示,由于特征维度较多,因此须进行特征选择。
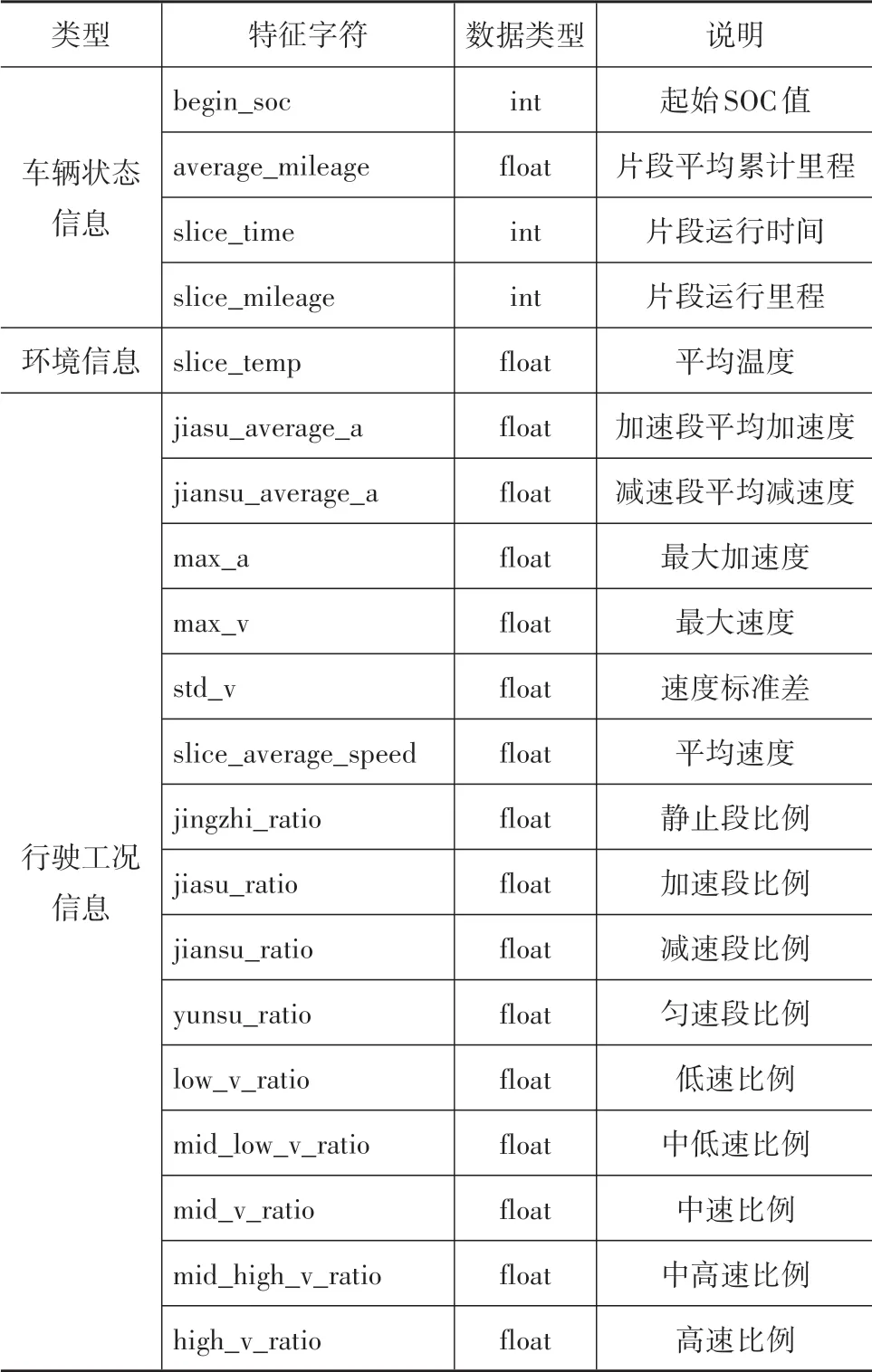
表3 能耗模型特征表
3.2 能耗特征选择
由于特征工程中所构建的特征可能存在信息重复或无关特征,若全部输入模型进行训练,则会使模型出现过拟合或维度灾难,降低模型预测效果。因此须进行特征筛选,排除冗余或无效特征以减少特征数量,增强模型的泛化能力。
本文中使用顶层特征选择算法中的稳定性选择进行特征筛选。稳定性选择是基于二次抽样和选择算法的结合,在不同的数据子集和特征子集上不断重复运行,最终得到汇总结果来进行特征筛选,可以有效克服过拟合,增强对数据的理解。使用随机森林与L1 正则化结合的稳定性选择方法,此方法能够自动选取正则化参数以提升模型效果。其输出结果如图11所示,图中对所构建的20个特征进行了重要性的排序,可看出部分特征对模型预测结果影响较小,因此剔除相关性较小的特征,以降低特征维度,提高模型训练速度。

图11 基于模型的特征筛选图
4 动力电池SOC 预测模型的构建
4.1 温度能耗模型原理
由于每种电池都有其最佳工作温度,且在不同温度下电池组内阻及放出的能量有很大差别。以锂离子电池为例,实验人员经过长时间的实验发现,在冬季(-10 ℃)其可放出能量仅为夏季(30 ℃)的66.6%[21]。同时,实验人员还做出了环境温度对锂电池放电容量的影响曲线。随着环境温度的降低,锂电池放电容量逐渐减小,尤其在低温时放电容量变化明显[22]。其原因是:(1)低温时电池内阻增大,放电电流相同时,内阻焦耳热增加,因此理论剩余能量相同时,低温时能量效率较低,电池可用能量减少;(2)低温时内阻增大,电池组会更早达到放电电压下限而停止放电,导致部分能量无法释放而可用能量减少[23]。其次,外界温度还影响车用空调的能耗,当电动汽车处于怠速工况下,空调系统能耗占整车功耗的77.08%[18]。因此不同温度下的电动汽车能耗相差较大。本文中通过绘制行驶里程与SOC消耗之间的关系将温度分为3层,如图12所示,二者呈明显的分层状态,每种分层状态下的能耗规律相差较大。因此,提出一种基于温度分层的融合模型来进行电动汽车动力电池SOC的预测。
4.2 宏观回归预测模型

图12 温度分层图
由于运动学片段能够描述汽车一段时间内的实际运行工况,且在前述部分已经完成对运动学片段的特征提取。因此考虑对整个片段进行宏观的建模与分析。首先进行温度分层,并对分层后的数据进行模 型训 练,使 用模 型有Lasso、Ridge、LGBoost、Randon_Forest、XGBoost、AdaBoost 等,采用网格搜索和贝叶斯优化进行超参数的调整与寻优,提高模型预测精度与泛化能力。选取均方差MAE(mean squared error)作为评价指标,其定义为
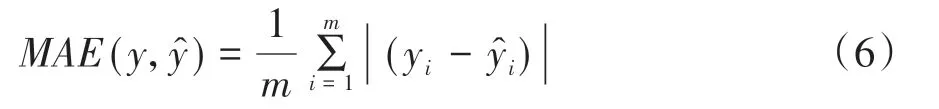
式中:yi为真 实 值;为 预测 值;m 为 训练 样本 的数量。
最终的单个模型预测效果如图13所示。

图13 单个模型训练效果
为进一步提升模型的预测效果,采用了Stacking模型[24]融合的方法。Stcaking 模型的原理是将训练数据分为n部分输入模型第一层的n个基分类器,再将基分类器的预测结果作为下一层元模型的输入,得到元模型的输出作为最终结果,相比独立的预测模型有更强稳健性,可以显著降低泛化误差。通过对比实验,最后选取了LGBoost、XGBoost 与Random_Forest 模型作为基模型,Lasso 作为元模型的组合进行模型融合。
其中基模型原理如下:LGBoost 与XGBoost 类似,是微软2017年提出的GBDT算法,基本原理是采用损失函数的负梯度作为当前决策树的残差近似值去拟合新的决策树。而Random_Forest 是在构建以决策树为基模型的基础上,引入了随机属性选择,对基决策树模型的每个节点属性集合中随机选择属性子集,再在子集中选择最优属性。
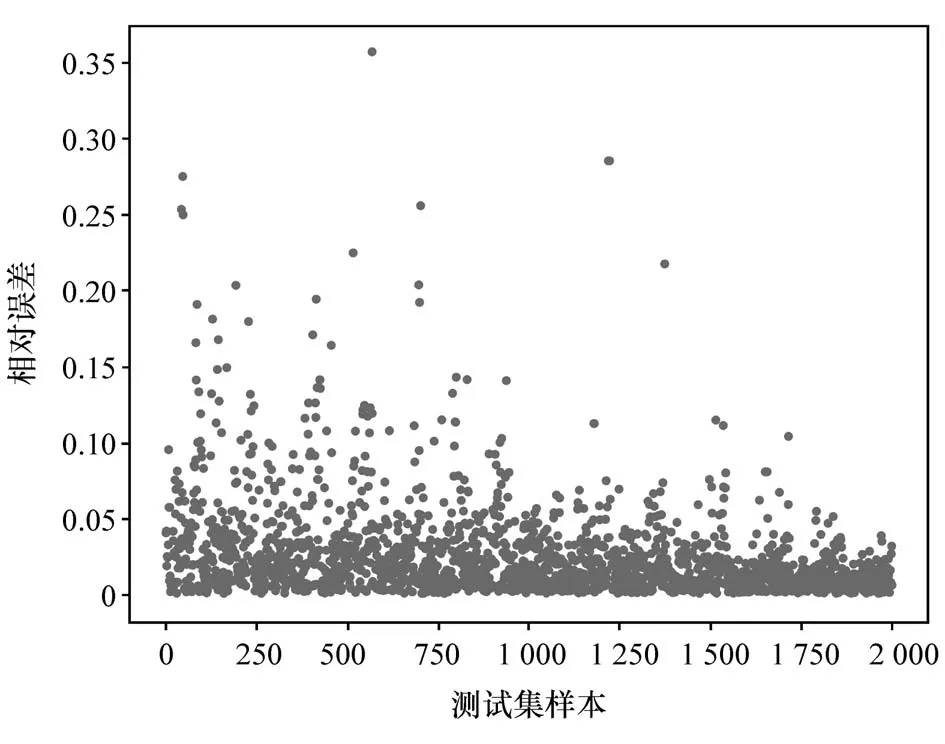
图14 基于温度分层的模型误差
最后融合每一层预测结果误差如图14 所示,平均相对误差率仅为2.52%,而不采用温度分层模型的预测平均相对误差率达到4.20%,分层后预测精度明显提高。
4.3 微观分类预测模型
完成宏观建模后,通过图14 可知,对于样本数据量较小的运动学片段,即片段的运动时间短,行驶距离小,此时模型预测结果相对较差。由于原始数据中蕴含丰富的车辆微观行驶信息,因此考虑对小样本片段数据进行微观建模,通过提取每个行驶点数据的微观特征来进行预测,以提高小样本行驶片段的预测精度。
在原始数据中SOC 变化情况分为3 种:-1%、0和1%,分别对应SOC 下降1%、SOC 不变和SOC 增加1%(电动汽车制动能量回收)。为提高模型的预测精度,将小样本行驶片段的SOC 预测转化为分类问题,即预测每个时间点处的SOC,最后通过片段内所有预测值的叠加得到片段终点处的SOC值。同时为避免出现样本不均衡导致的预测误差增大,采用SMOTE 算法[25]对小样本数据进行过采样以降低类别的不平衡性。SMOTE 算法是对小样本数据进行人工合成新样本并添加到数据集中,首先计算样本与少数样本集之间的K 近邻欧氏距离,再根据采样倍率选择近邻并构造新样本。样本构造公式为

式中:xnew为新生成样本;为近邻样本;x 为少数样本。
采用滑动窗口技术,选择该数据点之前的汽车行驶信息构造滑动窗口作为该点的微观运动学特征。同样采用前述的特征筛选方案去除对预测贡献较小的冗余特征,筛选后特征如表4所示。
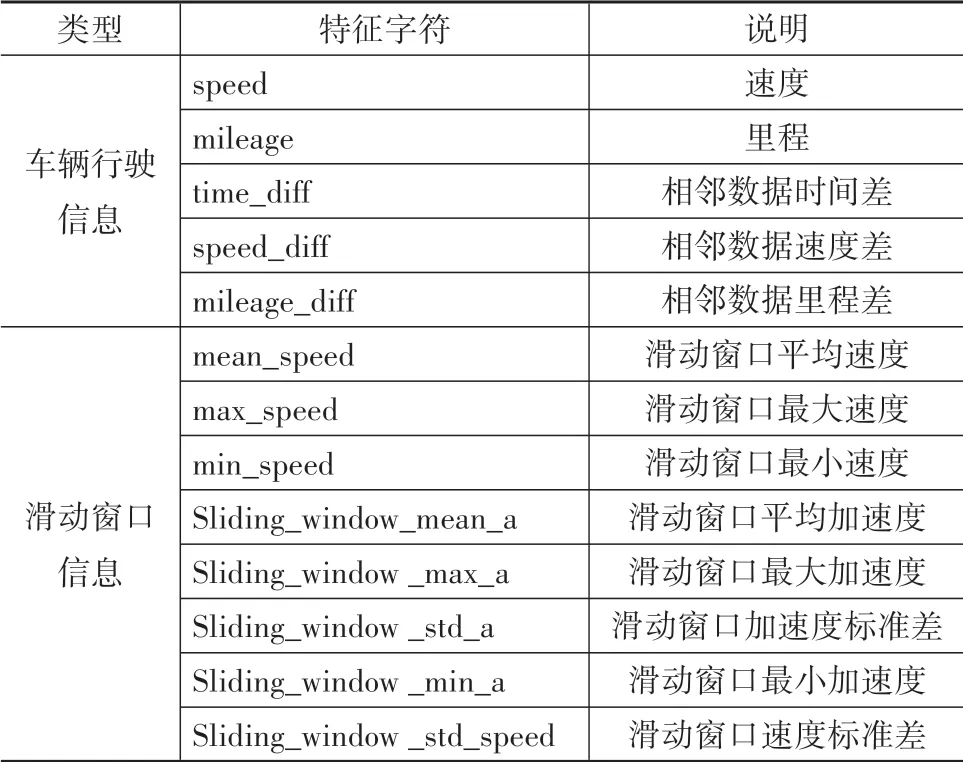
表4 微观特征表
4.4 基于温度分层的融合模型
完成微观模型的特征构建后,采用LightGBM 模型处理多分类问题,通过贝叶斯优化算法进行超参数的调整。最终将微观片段内的预测结果叠加得到单个行驶片段终点预测值,再将微观预测模型与宏观预测模型进行叠加融合得到最终的温度分层融合模型。
4.5 融合模型效果验证
为验证所构建的温度分层融合模型的预测效果,需要将模型预测的SOC 值与车载BMS 所提供的真实SOC值进行对比实验。首先构建对比实验所需的数据集片段,采用五折交叉验证(K-folds)的方法获取对比数据集。五折交叉验证是指将训练集随机等分为5 份互斥子集,取其中1 份数据作为测试集,其余4份作为训练集进行训练,重复5次并取测试结果的平均值作为最终预测结果输出[26],其原理如图15所示。
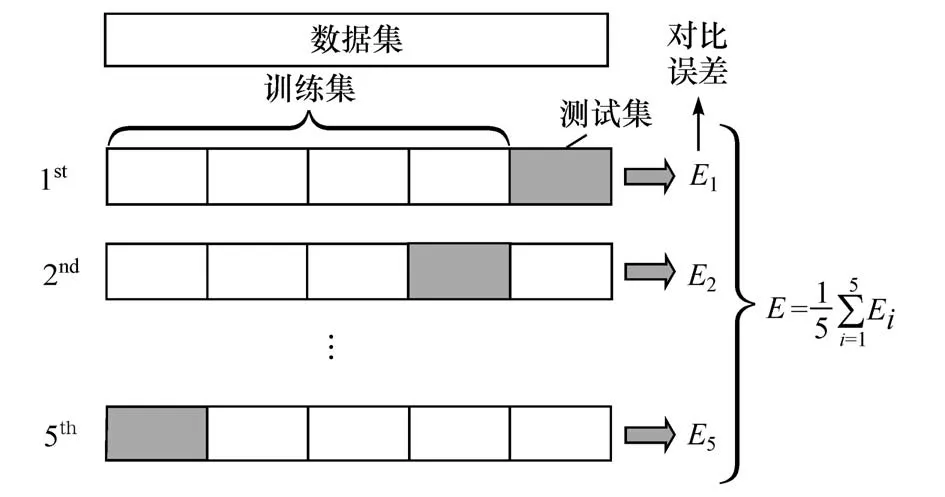
图15 交叉验证构建数据集原理
由交叉验证原理可知,通过五折交叉验证选取的对比片段优点在于,相比传统的随机划分,大大降低了数据的偶然性与预测效果的随机性,使测试集对比片段保留了原始数据的多样性,即可以遍历车辆的所有行驶工况,同时也可以显示模型的泛化能力。使用此模型对交叉后的五折测试集进行预测并求取均化对比误差,最终得到对比误差如图16 和图17 所示。由图可见,由温度分层融合模型所得的预测SOC 值相比车载BMS 提供的真实SOC 值的对比平均相对误差达到1.53%,平均绝对误差达到0.64。预测精度较高,且具有较强鲁棒性。
5 结论
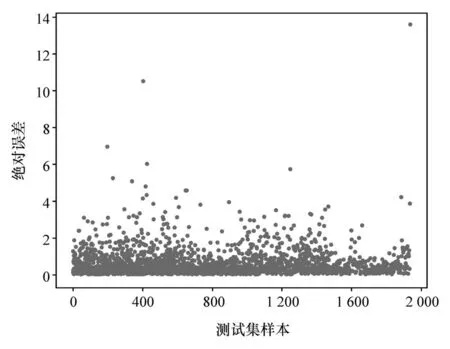
图16 测试集绝对误差
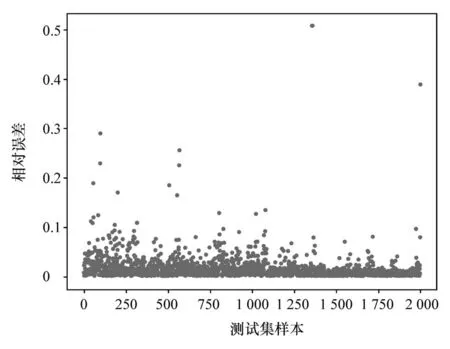
图17 测试集相对误差
提出一种基于数据驱动的电动汽车动力电池SOC 预测模型。首先分析电动汽车能耗构成以提取能耗影响因素,使用CAN 总线采集数据实现SOC 的预测。相比传统方法,此模型使用机器学习算法,实现了能耗与汽车实际工况以及交通路网参数的结合,并提出了温度能耗模型以优化温度影响,且预测精度较高。此外提出一种基于分箱处理的变量解耦方法以实现机器学习中多维变量耦合作用下的数据同分布。综上所述,该模型对优化动力电池的能量管理策略具有一定指导意义,也为电动汽车SOC 的在线预测和挖掘电动汽车运行数据背后的规律和价值提供参考。
猜你喜欢
消费电子(2022年7期)2022-10-31
汽车实用技术(2022年19期)2022-10-19
汽车工程学报(2022年5期)2022-10-12
机械工业标准化与质量(2022年8期)2022-10-09
煤气与热力(2022年4期)2022-05-23
舰船科学技术(2021年12期)2021-03-29
汽车工程(2021年12期)2021-03-08
建材发展导向(2021年23期)2021-03-08
汽车维修与保养(2021年8期)2021-02-16
汽车维修与保养(2021年8期)2021-02-16
