
基于YOLO_V3的侧视视频交通流量统计方法与验证
2021-01-27 09:23赖见辉罗甜甜陈艳艳
公路交通科技 2021年1期
赖见辉,王 扬,罗甜甜,陈艳艳,刘 帅
(1. 北京工业大学 城市交通学院,北京 100124;2. 北京交通运输职业学院,北京 102618)
0 引言
随着社会经济快速的发展,我国机动车保有量急剧增长,截止2020年6月,全国机动车保有量达3.6亿,随之也造成很多问题,如交通拥堵、空气污染。交通流量可准确反映道路交通运行状态,为科学的交通管理、政策制定提供依据,例如长期固定的流量观测数据可用于道路规划、经济效益评估等;而且短期临时(若干小时、天)的流量观测数据可用于灵活的交通管理、优化,交通影响评价等。目前,交通流量的获取方法包括感应线圈[1]、红外[2]、超声波[3]、视频[4]等,这些方法精度高,在固定式流量观测方面取得较好效果,而针对临时性交通流量观测需求,以上方法在使用便利性和经济性方面不具有优势,目前用得最多的方法仍然是人工现场统计观测或者现场采集视频回内业观测统计。
短期临时交通流量观测通常需求灵活多变,如某个交叉口、路段在早、晚高峰时段分车型的交通流量,不可能为这一临时需求安装龙门架,布设感应线圈、激光雷达等,相比较而言,人工现场观测统计可能更“经济”。但随着人工成本的逐年提升,短期临时交通流量观测需求越来越难以满足应用要求。
本研究利用视频识别技术,从视频源采集便利性角度,考虑摄相头布置在路侧,视角方向与道路存在一定夹角时的场景采集,如图1所示,调查员可利用三脚架等支撑物将摄相头临时固定于一定高度,三脚架放置于人行道上。该方式采集视频源灵活便利,缺点是视频源中的车辆可能存在不同程度的相互遮挡,不利于车辆检测和跟踪。本研究以此为突破口,利用基于深度学习技术的YOLO检测方法,实现不同车型目标物的采集;利用卡尔曼滤波+匈牙利分配法+透视投影变换法,实现高精度的车辆跟踪,以摄相头在不同角度、高度和车流密度条件下,对方法的有效性开展测试。

图1 侧视视频采集示意图Fig.1 Schematic diagram of road-side video collection
1 相关工作
利用视频识别交通流量主要包括两个过程,一是车辆目标物检测,二是车辆连续跟踪。车辆目标物检测方法通常包括帧间差分法、光流法、背景差分法和近几年新提出的深度学习法。车辆连续跟踪包括轮廓追踪、特征追踪、贝叶斯滤波等。
1.1 视频检测方法
帧间差分法(Temporal Difference)通过对视频图像序列中相邻两帧作差分运算来获得运动目标轮廓的方法,对光线等场景变化不太敏感,能够适应各种动态环境,稳定性较好,缺点是当物体运动速度存在较大差异时,前后两帧中容易没有重叠或者完全重叠,此外,也不能够检测出静止的物体[5]。
光流法(Optical Flow Method)根据图像序列中像素强度变化值来判定各自像素位置的“运动”,即是时间上的变化与场景物体来描述共同运动物体,对于静止目标的识别效果较差。如张润初[6]利用光流运动点的分布和车辆在路面的占有情况之间的联系,提出基于交通流理论的车流量统计方法,在正视角度下测试了约40辆车,精度为97.56%。
背景差分法(Background Difference Method)易受光线变化影响,背景更新是关键,不适用于灵活多变的路侧场景。如李东[7]利用单高斯背景模型算法识别车辆,提高了检测车辆前景区域的完整性;刘畅[8]采用统计平均法进行背景建模,通过将视频当前帧与背景帧作差来获取前景目标,在正视角度下的测试精度为96.3%;胡云鹭[9]将背景差分法与帧间差分法相结合,在不同天气下不同车道的车速检测精度的均值都可达到 95%以上。
以上3类作为传统视频识别的主要方法,在不同方面应用取得较好效果,但仍然存在以下问题:
(1)视频场景要求高,如光线、阴影均易影响交通流量计数的精度,而复杂的路侧交通视频往往难以完全达到要求;
(2)算法在交通流量较小的场景下能取得较高精度,但高密度车流时精度急剧下降;
(3)算法主要针对道路正上方角度拍摄视频,车辆间的遮挡小,而侧视角度视频往往存在相互遮挡。
因此,传统视频识别方法无法满足侧视视角的交通流量视频识别要求。近年,深度学习法(Deep Learning Method)方法在不同领域应用取得长足进步[10-12]。它通过建立具有阶层结构的人工神经网络进行目标物检测,基于目标物的位置和类别进行跟踪计数。常见的目标物检测方法有R-CNN (Regions with Convolutional Neural Network)、Fast R-CNN (Fast Regions with Convolutional Neural Network feature)、SSD (Single Shot Detection)、YOLO (You Only Look Once)。R-CNN选用Selective search(选择性搜索)方法来生成候选区域,然后每个候选区域送入一个CNN模型,预测出候选区域中所含物体的属于每个类的概率值,该方法检测精度高,但计算效率低。Fast R-CNN[13]主要是为了减少候选区域使用CNN模型提取特征向量所消耗的时间,借鉴SPP-net思想,在计算效率上较RCNN有所提升。SSD采用了回归方法进行目标检测使得目标检测速度大大加快,采用archor机制使得目标定位和分类精度有了大幅度提高,如牛嘉郡[14]利用SSD网络模型对视频中的车辆进行检测,提出基于重叠率匹配和 SURF 特征提取的运动车辆目标跟踪与计数方法,结合虚拟线圈技术,分车道对跟踪车辆进行计数,在拥堵道路上正视角度视频的测试结果表明,该方法精度约85%。
YOLO[15]在识别精度和效率之间取得平衡,其核心思想是利用整张图作为网络的输入,直接在输出层回归边界框的位置及其所属的类别。YOLO代表的深度学习技术在图像检测中的最高水平之一,到目前为止,已经发展到第3代YOLO_V3,它很好地解决了小目标、遮挡目标识别精度不高的问题,总体而言,它比R-CNN快1 000倍,比Fast R-CNN快100倍。关于YOLO应用,目前有很多学者在不同领域开展了大量研究,包括用于安全帽佩戴检测[16](精度92.13%)、交通标识检测[17](精度80.1%)、机场场面飞机检测[18](精度83.7%)、车辆信息检测[19-20]、道路拥堵分析[21](精度80%)等。
本研究在YOLO_V3的基础上开展侧视频角度的交通流量计数方法研究。
1.2 目标跟踪方法
基于分类的目标检测之后,在图像序列中持续地估计出车辆运动所在位置,形成车辆轨迹。目标跟踪分为单目标跟踪和多目标跟踪,单目标跟踪算法而言,存在一个先验假设是目标总是在视频范围内;多目标跟踪问题跟踪的对象位置变化很大,跟踪对象从场景进入、离开,跟踪目标个数不固定。
目标跟踪算法包括基于轮廓的追踪法、基于区域的追踪法、基于模型的追踪法、基于特征的追踪法和基于贝叶斯滤波特征的追踪法[22]。
(1)基于轮廓的追踪法[23]
以目标物的轮廓曲线为对象,进行匹配追踪,优点是匹配速度快,准确性较高,但存在遮挡时精度较差。
(2)基于区域的追踪法
在事先获得跟踪目标的区域,利用跟踪算法进行追踪,该方法场景固定的视频具备一定优势,但无法适用于灵活多变的视频。
(3)基于模型的追踪法[24]
利用目标的先验知识进行建模,通过模式匹配方法进行跟踪,该方法同样在发生较大形变、存在遮挡的情况则跟踪效果不佳。
(4)基于特征的追踪法[25]
该方法不考虑跟踪目标整体情况,将目标物体的特征点作为跟踪目标的方法,只对从目标物体上提取出来的显著特征进行跟踪。优点是物体的尺度、形状和光照的变换不敏感,即使存在遮挡,只要有部分特征点可见,也可完成对目标的跟踪。
(5)基于贝叶斯滤波特征的追踪法
用系统模型预测状态的先验概率密度,再使用最近的测量值进行修正,得到后验概率密度。典型的算法包括卡尔曼滤波[26](KalmanFilter)和粒子滤波[27](Partical Filter)。该方法对线性高斯系统和非线性高斯系统都有对应算法,而粒子滤波需大量样本才可较好估计后验概率密,卡尔曼滤波对遮挡敏感。
传统上利用图像识别方法开展交通流量计数,主要考虑目标物的特征和运动过程中产生的像素变化来识别车辆,这些方法对拍摄视频的角度和视频质量均有较高要求,如车辆间的遮挡,光照的变化,均可能较大地影响结果精度。而作为临时采集交通流量数据,通过将相机布置于路侧,难以满足以上条件。针对这些问题,本研究利用深度学习技术,提出了一种适用于侧视角度拍摄视频用于交通流量统计的方法。
2 模型建立
模型的基本假设:YOLO_V3识别的车辆在视频帧中的变化是连续的,不存在大幅度跳帧现象;不同车辆在图片中的中心点距离小于相同车辆在相邻两帧之间的移动距离。
首先利用YOLO_V3对视频连续帧中的目标检测区域进行目标物识别,识别信息包括目标物的类别、概率值和边框坐标;然后在帧图片中选择至少4个点,将这些点在图片中的像素坐标与现实环境中的真实坐标建立对应关系,建立透视转换模型,将检测目标物的像素坐标以此模型转换为真实坐标;计算相邻帧所有检测物的欧几里得距离,用匈牙利匹配算法求解最小费用,实现连续帧之间车辆的追踪;最后利用卡尔曼滤波算法实现车辆连续轨迹的修正预测,统计某车辆在流量检测区域出行的帧次数,超过指定阈值时,认定为一个有效流量。详细流程见图2。
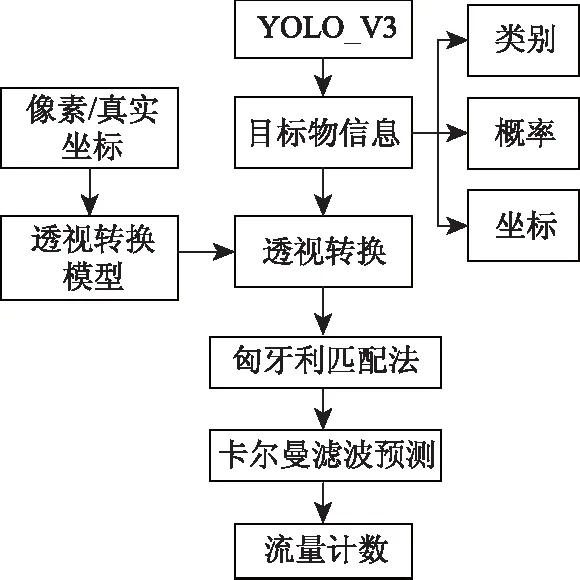
图2 算法流程图Fig.2 Flowchart of algorithm
2.1 目标跟踪
(1)透视转换模型
透视转换的目标是将图像投影到一个新的视平面,在本应用中是将相机拍摄存在透视角度图的坐标转换成真实环境中的坐标。其实现原理见公式(1),其中[x′y′w′]是真实环境的坐标,[uvw]是图片中的像素坐标,a矩阵是变换矩阵,本例中仅将路面作为检测区域,仅需要二维空间上的坐标转换。
(1)
透视转换效果见图3,图3(a)为相机拍摄视频原图,画对角线的多边形框体为车辆检测区域,因相机架设于路侧,图像存在显著变形,图3(b)是经透视转换模型校正后的效果,道路的横纵比例关系与真实环境基本完全吻合,因此该校正方法适用。

图3 透视投影变换效果Fig.3 Perspective projection transformation effect
(2)匈牙利匹配法
前后帧的车辆追踪问题,本研究将其描述为数学中的指派问题,即上一帧检测到n辆车,当前帧检测到m辆车,将m辆车中的车辆与上一帧的n辆车建立一一对应关系,目标是之间的总费用最低。前n与m不相等时,取最大值,并将不足的行列补0,形成方阵。通用数学模型见公式(2),其中:ci1为前后两帧间所有检测物的欧几里得距离矩阵,xi1为匹配结果矩阵,值为0时表示二者不匹配,为1时表示二者匹配。
(2)
(3)卡尔曼滤波预测法
卡尔曼滤波预测法提供了一种高效可计算的方法来估计过程的状态,并使估计均方误差最小。其基本思想是:以最小均方误差为最佳估计准则,利用前一时刻的估计值和当前时刻的观测值来更新对状态变量的估计,求出当前时刻的估计值,算法根据建立的系统方程和观测方程对需要处理的数据做出满足最小均方误差的估计。卡尔曼滤波预测法使用时包括预测和校正两个过程。
预测过程如下:
(3)
式中,u为帧坐标向量;P为协方差矩阵;F为状态转移矩阵;Q为过程噪声矩阵。校正过程如下:
(4)
式中,u为帧坐标向量;A为状态转移矩阵;b为当前帧坐标;P为协方差矩阵;Q为过程噪声矩阵;R为观测噪声矩阵;C为状态变量到观测量的转换矩阵;K为滤波增益矩阵。
利用卡尔曼滤波预测法可以有效减少噪声干扰数据对轨迹追踪精度的影响。
2.2 流量统计
考虑到卡尔曼滤波预测稳定性收敛需要一定的历史数据,本研究通过建立车辆检测区域和流量计数区域的二级检测框架提高流量计数的精度。如图4所示,沿车流方向在行车道范围内建立一个长约100 m的车辆检测区域(图中浅灰色区域),仅在该区域出现的车辆作为追踪对象,减少无效干扰车辆影响;在车辆检测区域中的下游处,建立长度约为25 m的流量计数区域(图中深灰色区域)。当追踪车辆经过流量检测区域时,记录其出现的帧次数量,当帧次数量达到一定阈值时,认为是一次有效的交通计数。阈值选择与流量检测区域大小、车辆平均行驶速度均有关,流量检测区域越大,车辆通过需要越长时间,可检测到的帧数越多;车辆平均行驶速度越快,通过流量检测区域时间越短,可检测到的帧数越少。

图4 交通流量检测示意图Fig.4 Schematic diagram of traffic volume detection
考虑到不同车型速度差异较大时,帧次数量阈值按车辆类型设置不同的值,如城市道路中,非机动车的速度通常只有机动的1/3~1/2,阈值可稍大于机动车。
依据实际数据的测试经验表明,各类型的车辆帧次数量阈值约为其最大可通过帧次的60%左右时,流量统计结果具有较高的精度。
该方法存在以下优点:
(1)采用二级检测框架,仅利用卡尔曼滤波预测收敛后的数据作为流量计数的依据,有利于提高追踪的精度。
(2)可以有效避免因车辆检测误差导致的流量误判,如车辆在连续帧中出现某帧识别错误,导致车辆追踪时误认为另一辆新车出现,但该误检车辆无法在流量检测区域达到阈值时,误计车辆将被舍弃。
3 验证与分析
3.1 试验条件
为保证试验结果的客观性,采用YOLO_V3官方提供已训练好的权重文件。
考虑到侧视角度采集的视频,流量计数结果精度的高低,不仅与算法设计相关,还与视频采集的角度、高度以及道路上的车流密度密切相关。为了验证方法的有效性,选择不同环境条件开展测试,包括3个主要指标:
(1)拍摄相机与道路相交角度
考虑相机的广角形变效果,相机与道路相交角度会影响透视变换效果,角度过大或过小均不利于视频识别,本研究选择测试角度分别为30°,45°和60°,记为A_30,A_45,A_60。
(2)拍摄相机架设高度
小型车辆一般高1.8 m,大型公交车高一般为3 m,考虑视频在路侧采集时布置相机的可行性,过低时存在大量车辆相互遮挡,过高时相机稳定性差,因此选择高度为2 m和3 m进行测试,记为HT_2,HT_3。
(3)道路车流密度
车流密度大小会影响跟踪的精度,当车流密度高时,车间距小,容易相互遮挡,极易在跟踪时产生误判。本研究选用交通流量(Veh/h)代表交通流密度,单向3车道,分别测试低、中、高3类(记为F_L,F_M,F_H)不同条件下的精度,不同类别对应的交通流量见表1。

表1 车流密度分类Tab.1 Classification of traffic densities
3.2 评估指标
统计不同周期内的检测的车辆数量Fi,同时人工统计对应的车辆数Ai,n为样本数量,以MAPE和RMSE对结果精度分别进行评价。
(1)平均绝对百分比误差MAPE
(5)
(2)均方根误差RMSE
(6)
(3)运行效率
用每秒传输帧数(Frames Per Second,FPS)表示。
3.3 结果分析
测试结果显示见表2,最小MAPE为2.74%,最大为10.37%,总体而言,随着夹角增大,MAPE逐渐增大,其主要原因是过大的夹角下视频拍摄道路范围减小,导致算法无法有效追踪车辆;相交角度相同时,相机架设越高,MAPE值越低,当达到3 m,夹角为30°时,MAPE值为2.74%,具有较高的辨识精度;此外,相交角度相同时,视频流量越低,MAPE值越低,精度越高。需要指出的是,在高度为2 m的,角度为30的测试视频中,连续出现大型公交车辆遮挡视野,导致MAPE提高到10.45%。均方根误差RMSE呈现的趋势特征与MAPE基本一致且数值较低,表明算法具有较高的稳定性。
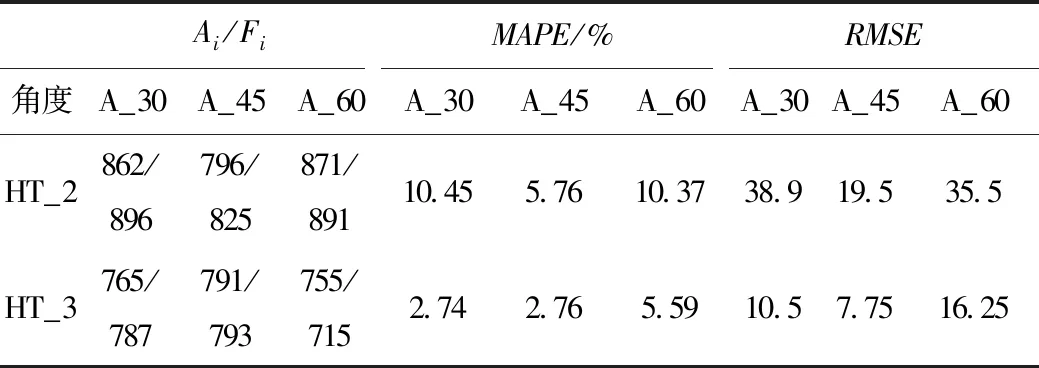
表2 角度与高度对识别精度的影响Tab.2 Influence of angle and height on recognition accuracy
当相机与道路夹角相同时,随着相机架设高度的增加,MAPE呈减小趋势,如在角度为30°,高度为2 m时,MAPE值为10.45%,而高度为3 m时,降为2.74%,精度大幅提升;如表3所示,在同等高度条件下,交通流量越大MAPE越小,测试的6组数据中,除一组数据因公交遮挡在16.5%,其余组主要分布在4%~6%之间,甚至有一组结果MAPE值为1.3%,RMSE也主要分布在10~20之间,表明具有较高稳定性,相机与道路角度相同时,交通流量的大小对精度影响不大,见表4。
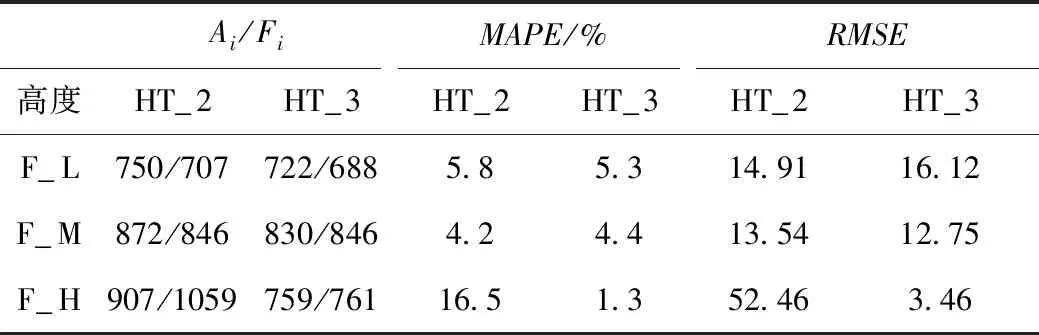
表3 车流密度与高度对识别精度的影响Tab.3 Influence of traffic density and height on recognition accuracy
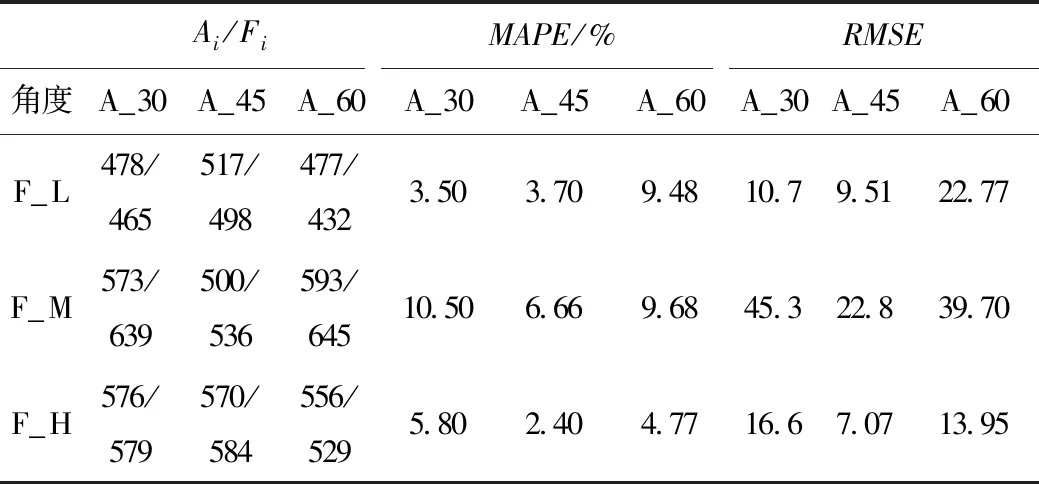
表4 角度与车流密度对识别精度的影响Tab.4 Influence of angel and traffic density on recognition accuracy
3.4 计算效率分析
程序运行环境为:windows10 x64操作系统,2080Ti显卡,64G内存,i7-7820XCPU,程序每次运行过程中均无其他程序运行,测试视频大小均为1080P,30FPS。
结果表明相机架设角度和高度均对程序运行效率无显著影响,而车流密度则影响较大,结果显示见表5,在低密度车流下,FPS值约为44,而高密度车流下,FPS值降为33左右,高密度客流下车辆数增多,卡尔曼滤波和匈牙利分配算法所消耗的时间均会显著增加,但仍然高于常用的视频流30FPS。表明该方法运行效率较高,可用于实时视频流的数据采集。

表5 车流密度对运行效率的影响Tab.5 Influence of traffic density and efficiency on recognition accuracy
4 结论
(1)以YOLO_V3为基础,对侧视视角的视频开展车辆目标物检测,建立车辆检测区域和流量计数区域的二级检测框架,提出基于卡尔曼滤波+匈牙利分配法+透视投影变换法的车辆追踪计数方法,实测结果显示,MAPE平均在5%左右,RMSE平均在15左右,表明该方法具有较高的试验精度和稳定性。
(2)基于YOLO_V3,利用本研究提出的交通流量统计方法,在相机高度为3 m,与路侧夹角为30°的视频环境中,流量计数的精度在95%,满足临时交通调查的需求。
(3)依然受大型公交、货车影响严重,当存在大型车辆通过时,其他车辆几乎完全被遮挡,导致流量计数出现偏差,尽管如此,精度仍然在90%左右。
(4)测试采用的18组视频在识别结果上均表现出较高的精度,表明本方法具备较高的鲁棒性,适合灵活多变的路侧采集方式。
(5)对深度学习方法YOLO_V3的识别结果依赖较强,测试采用的是官方已训练好的权重文件,国内车型与国外车型存在一定差异会影响精度,如面包车经常被识别成小货车,而国内通常认为面包车小客车。
(6)本方法对雨雪等恶劣天气条件下的适用性还需进一步验证。
猜你喜欢
作文小学高年级(2022年3期)2022-04-20
建材发展导向(2019年11期)2019-08-24
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
福建中学数学(2018年1期)2018-11-29
中国交通信息化(2018年7期)2018-09-14
电子制作(2018年11期)2018-08-04
37°女人(2017年8期)2017-08-12
滇池(2017年7期)2017-07-18
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
