
基于语义分割模型的路面类型识别技术研究
2021-01-27 08:41王志红王少博颜莉蓉
公路交通科技 2021年1期
王志红,王少博,颜莉蓉,袁 雨
(武汉理工大学 汽车工程学院,湖北 武汉 430070)
0 引言
根据统计数据显示,自2007年以来中国16.12%的交通事故都与低附着率的道路状况有关[1]。通过对事故特点的分析,可以得出在水、雪、冰、冻结路面条件下,交通事故率增加,路面条件对公路交通安全和运输效率影响较大。试验表明,驾驶员及时了解当前行驶的路面状况,能够有效地降低交通事故的发生,因此关于路面状况识别技术的研究已经很迫切[2]。
在汽车制动性能的研究中,常将路面状况分表1所示的8种情况,这几种情况基本已经涵盖了所有汽车可能行驶的路面状态,冰雪路面附着系数明显低于普通路面附着系数,也是交通事故频发的重要原因。
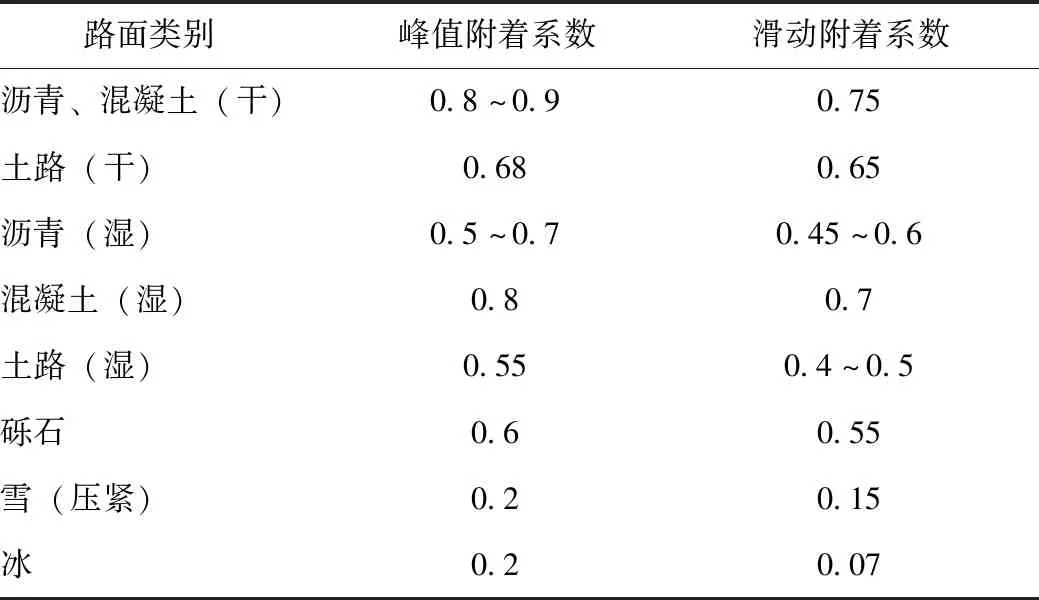
表1 路面状况分类及附着系数[3]Tab.1 Road condition classification and adhesion coefficient[3]
目前路面识别技术主要包括:(1)通过光学传感器测量路面粗糙度和干湿状态预测路面附着系数[4]。(2)通过轮胎中安装压电传感器测量局部应变应力识别路面[5]。(3)通过附着系数随滑移率的变化识别路面[6]。(4)通过麦克风获取车辆和轮胎噪声,进行路面状态识别[7]。(5)基于机器视觉的方法识别路面。但是方法1由于光学传感器受工作环境和外部因素影响较大,所以近些年研究较少;方法2因传感器安装在车轮中,所以需要无线传输和能量自给,导致价格较高,不够稳定;方法3对外界的抗干扰性比较差,并且对滑移率的估计精度要求较高;方法4因行车中噪音较多并且噪音产生机理比较复杂,因此难以准确预测[8];方法5因硬件成本低、识别效果好,成为了当今研究的热点。
目前有以下几种效果较好的路面识别技术,提出了一种通过车载摄像头,使用多分类器的路面状态识别系统。该系统首先通过摄像头获取路面信息,通过预处理模块获得感兴趣区域,然后通过预训练的多分类器进行路面识别获取分类结果,试验结果表明干湿路面的分类精度为86%。文献[9]提出一种基于BP神经网络的路面状态识别方法,BP网络的输入参数通过多传感器获得,试验表明在特定车辆模型和速度恒定的情况下,路面附着系数预测误差为0.05左右,但是神经网络参数需要针对特定车辆模型,因此难以普及使用。文献[10]提出一种基于SVM(支持向量机)对摄像头获取的路面图片进行分类的算法,试验结果表明分类精度可达90%。文献[11]提出一种使用加速度传感器和相机特征数据融合对路面类型进行分类的方法,试验结果表明分类精度可达90%。文献[12]提出了一种深度学习模型,通过处理摄像头获取的路面信息进行路面附着系数的识别,算法分为两步,第1步进行路面种类的识别,第2步进行路面附着系数高低的评估。试验结果表明第1步精度可达97%,第2步精度可达89%。以上效果较好的识别算法中大部分是基于机器视觉的,也说明了机器视觉是当今路面识别算法的主流。虽然以上方法取得了一定的成果,但是识别算法的鲁棒性和识别精度仍然有较大的提升空间。
本研究基于深度学习语义分割模型[13-14]提出了一种新的识别算法。首先通过Label(一种数据集标注工具)对收集的路面数据集进行像素点和类别的标注,使用深度学习语义分割模型对制作好的数据集进行800 epoch(批次)的训练,保存训练权重。根据训练权重预测通过摄像头采集到的路面图片,结果会得到图片中每一个像素点的分类标签,除去背景标签,将数目最多的类型标签作为最终道路类型的预测结果。
1 制作数据集和搭建网络模型
1.1 制作数据集
根据中国常见道路类型,从百度、360、搜狗搜索引擎中下载大量路面图片,这样可以保证数据集样本的多样性。将筛选出的路面图片分为以下9类:沥青(干)、沥青(湿)、混凝土(干)、混凝土(湿)、土路(干)、土路(湿)、砾石、雪地(压实)和冰面。共挑选出2 700张路面图片,每1类别包含300张。训练、验证和测试的图片数量如表2所示。

表2 数据集结构及数目Tab.2 Data set structure and numbers
使用Ubuntu系统的Labelme[15]工具对收集的数据集进行标注,不同类别的道路使用不同的标签。标注完成后,每张图片会得到一个Json类型的文件。通过Python编程实现Json文件批量转化为图片格式,转化时每种类别的标签采用不同的颜色。表3是从每一类道路数据集中选取的样本。数据集的结构分为test,test_labe,train,train_label,val,val_label和class_dict, 前6个文件夹分别存放测试、训练和验证数据集的图片和标签,class_dict用来说明每一个标签对应的RGB值。

表3 数据集样本Tab.3 Data set samples
1.2 搭建FC-DensenNet56模型
本研究使用的语义分割网络模型是FC-DensenNet56[16-17]。此网络模型结构如图1所示,主要包括5个下采样模块TD和5个上采样模块TU。实线代表模块之间的连接,箭头代表数据的流向,中间的虚线代表跳变连接,它将下采样路径中的特征图直接与上采样路径中对应的特征图连接起来。
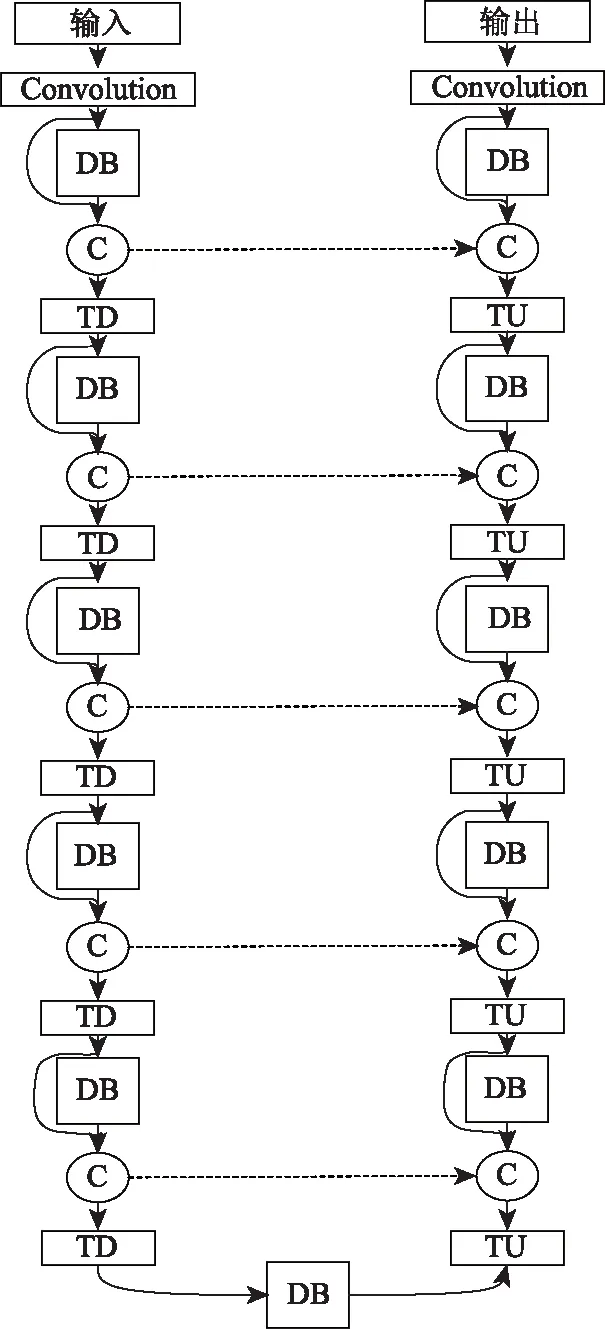
图1 FC-DensenNet56网络结构Fig.1 Fc-DensenNet56 network structure
模型中包含10个DB模块[18],每个DB模块主要包括4个卷积层。第1层产生k个特征图,这k个特征图直接与输出相连,同时传入第2层。第2层也产生k个特征图,同时输入到第3层。这样的操作进行4 次,最终会输出4×k个特征图。DB网络模型用于语义分割主要有以下3个优点:(1)缓解了特征图数量的激增。(2)DB 模块采用的上采样结构比普通的上采样效果要好。(3)该模型无需预训练模型和后处理。
模型中包含5个TU模块 ,TU模块为上采样模块。它由1层反卷积层组成,采用3×3的卷积核对DB模块输出的特征图进行反卷积操作,步长为2。卷积核的最优参数可以通过学习得到,因此上采样效果优于插值方法的上采样操作效果。
数据集中的图片来源于互联网,因此图片尺寸不同。为了减少网络参数和资源的占用,在图片输入到网络之前,将图片尺寸统一裁剪成128×96。
2 训练模型和预测图片
2.1 训练语义分割模型
使用前面制作的路面分类数据集,对FC-DensenNet56语义分割网络模型进行训练,训练时的基本参数设置如表4所示。其中深度学习模型的梯度下降学习率值一般根据经验值获取,即一般不存在普遍性规律,本研究参数采用经验值0.000 1。

表4 模型基本参数设置Tab.4 Setting basic parameters of model
经过大约7 h的训练,完成800 epoch。训练过程中平均Loss随epoch的变化如图2所示,平均验证精度随epoch的变化如图3所示,平均Iou值随epoch的变化如图4所示。
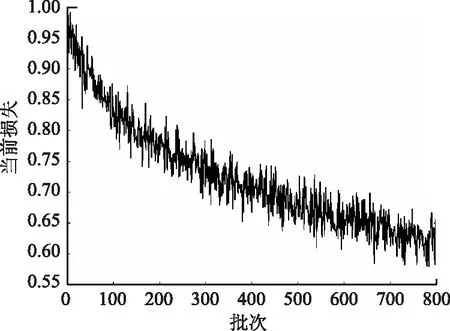
图2 平均损失函数图Fig.2 Graph of average loss function
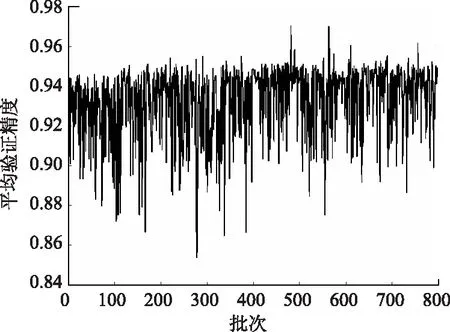
图3 训练验证精度图Fig.3 Graph of training verification accuracy
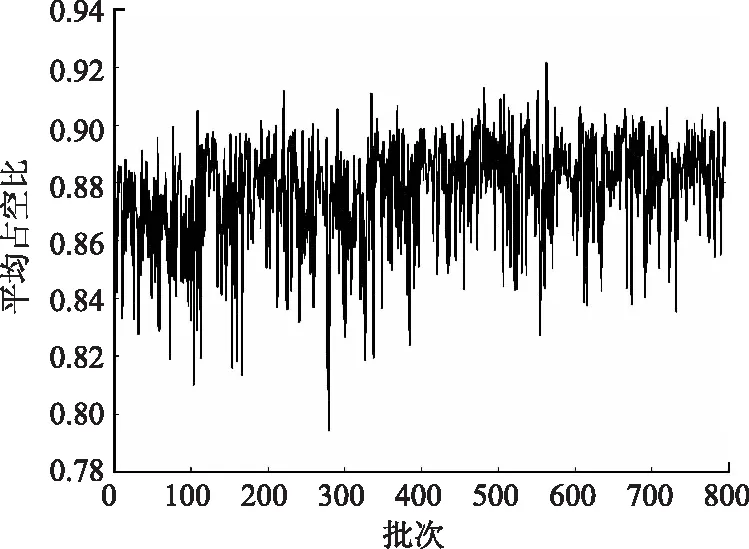
图4 平均占空比精度图Fig.4 Graph of average IOU accuracy
由图2可知经过800 epoch的训练,损失值已经明显下降到比较低的水平,到训练结束平均损失值大约为0.6左右,并且逐渐收敛。由图3可知,单个像素点的平均验证精度已达95%左右。由图4可知平均Iou值也随着训练的进行逐渐上升,最终平均Iou值为0.9左右。
2.2 预测图片
使用训练好的权重和搭建的模型对200张图片进行预测,训练和预测使用的平台硬件配置如表5所示,针对像素点的预测正确率如表6所示,预测效果指标如表7所示。由表6可知,9种路面所对应像素点的正确率平均为98%,背景所对应像素点的正确率为93.9%。单张图片中的背景像素点占总像素点的比例较大,背景像素点的预测精度较低。同时可以发现结构化路面的识别精度较高,例如沥青、混泥土路面;非结构化路面识别精度较低,例如冰面、雪地和砾石路面。由表7可知,所有像素点的平均精度为94%左右;每张图片的平均预测时间为0.028 6 s,视频输出达到25帧以上时可满足实时性要求,处理时间理论上满足实时预测的要求。

表5 试验平台硬件配置参数Tab.5 Hardware configuration parameters of experimental platform

表6 图片像素点的识别结果Tab.6 Image pixel recognition result

表7 预测效果指标Tab.7 Prediction effect indicators
3 理论分析预测结果
语义分割模型是对图片中的每一个像素点进行预测,输入模型中的每一张图片的每一个像素点都会得到一个预测标签值,每一种标签对应一种道路类别。输入模型中的图片统一裁剪成128×96,每张图片共计122 88个标签值。语义分割模型无法直接得到整张图片的道路类型识别结果。统计图片中每一个像素点的预测标签数目,将数目最多的预测标签作为整张图片的道路类型预测结果,预测整体流程如图5所示。
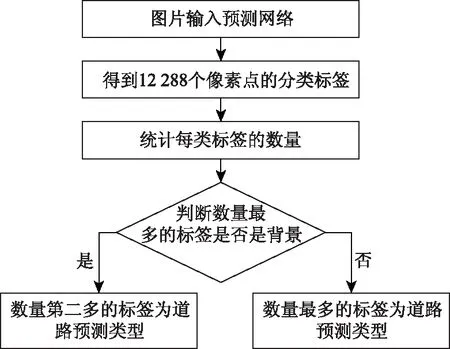
图5 道路类型预测流程图Fig.5 Flowchart of pavement type prediction
统计每张图片含有道路类型的数目,统计结果如下:含有一种路面类型的图片数目占总数据集图片数目的比例如式(1)所示,含有多种路面类型的图片数目占总数据集图片数目的比例如式(2)所示。
统计每张图片含有道路类型的数目。统计结果如下:含有一种路面类型的图片数目占总数据集图片数目的比例如式(1)所示,含有多种路面类型的图片数目占总数据集图片数目的比例如式(2)所示。
Proad=1=95.132%,
(1)
Proad=n=4.868%。
(2)
根据图片中包含以上9种道路类型的数目,对整张图片的道路类型预测精度进行以下理论推导,理论推导过程分为以下2种情况:
(1)图片中只包含一种路面,图片中只包含1种路面的概率见式(3)。
Proad=1=95.132%。
(3)
此路面为当前行驶路面。图片中含有背景和真实路面2类标签,只有当两者的误判像素点数目大于真实路面的像素点数目时才会出现误判。假设两者都以最大概率出现误判,并且误判为同一种错误道路类型。以上假设为只有1种路面情况时出现误判的最大概率。
假设真实路面所占比例为A,背景所占比例为B,总像素点的个数为Z。通过以上图片验证结果可知,平均预测精度为94%,误判率为6%。当满足式(4)时会出现误判,根据式(4)和式(5)解得式(6)。
Z×(A+B)×6%>A×(1-6%),
(4)
A+B=1,
(5)
A<6.38%。
(6)
通过对数据集的统计分析,满足式(6)时的概率为式(7)。
P(A<6.38%)=0.27%
(7)
图片中只包含一种路面情况的误判概率为式(8)。
P1=Proad=1×P(A<6.38%)=0.257%。
(8)
(2)图片中含有两种及以上路面,图片中含有两种及以上路面的概率见式(9),由于此情况比较复杂不易计算出误判概率。因此采用最大误判概率P(all)=1时进行计算,如式(10)所示。
Proad=n=4.868%,
(9)
P2=Proad=n×P(all)=4.868%。
(10)
两种情况误判概率为Pfalse如式(11)所示,预测正确的概率Pright如式(12)所示。
Pfalse=P1+P2=0.257%+4.868%=5.125%,
(11)
Pright=1-Pfalse=94.875%。
(12)
4 算法验证及结果对比
为了验证以上理论推导,更全面地分析模型的实际效果,采集实际路面图片对Acc(accuracy)、PR(precision)和RE(recall)进行分析[15]。Acc指的是所有预测正确图片的数量占总预测图片的比例,它是模型效果对比最常用的指标;PR指的是预测标签为某一类别中预测正确的比例;RE指的是真实标签为某一类图片中预测正确的比例。算法验证结果如表8所示。
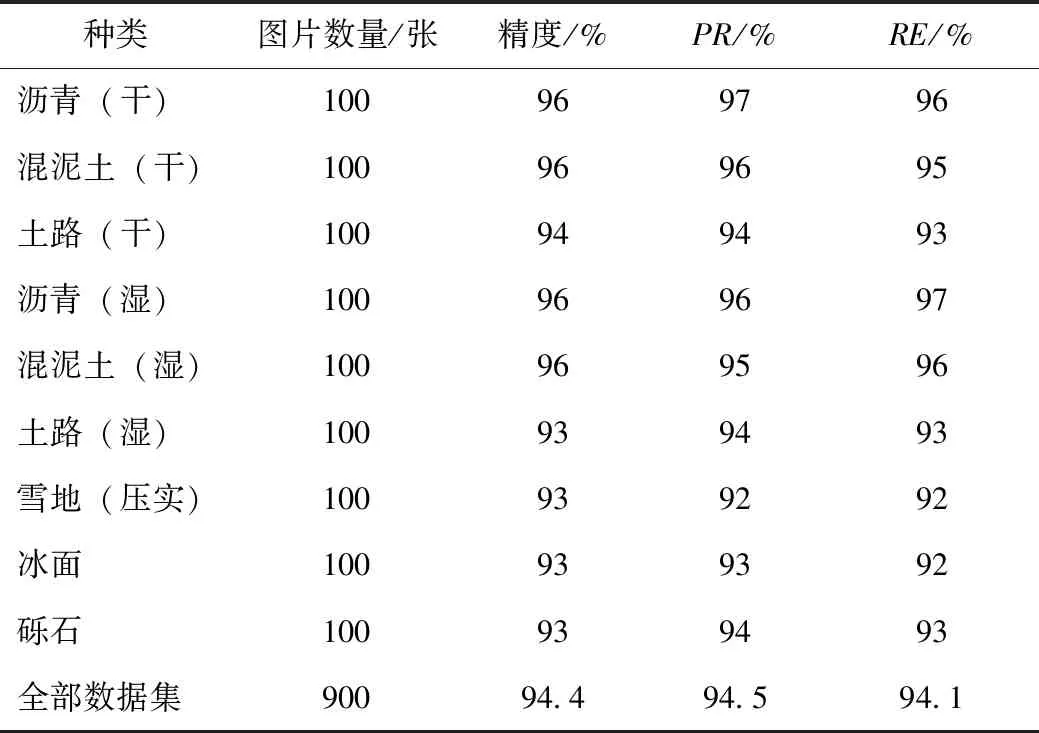
表8 算法验证结果Tab.8 Algorithm verification result
将算法验证测得的路面识别结果和当前主流的路面识别效果做以下对比,如表9所示,对比结果表明,本研究识别的道路种类比原来识别系统的识别种类要多,精度要高,在一定程度上说明了本方法具有较好的鲁棒性和较高的精度,对未来道路类型识别研究具有一定的帮助。
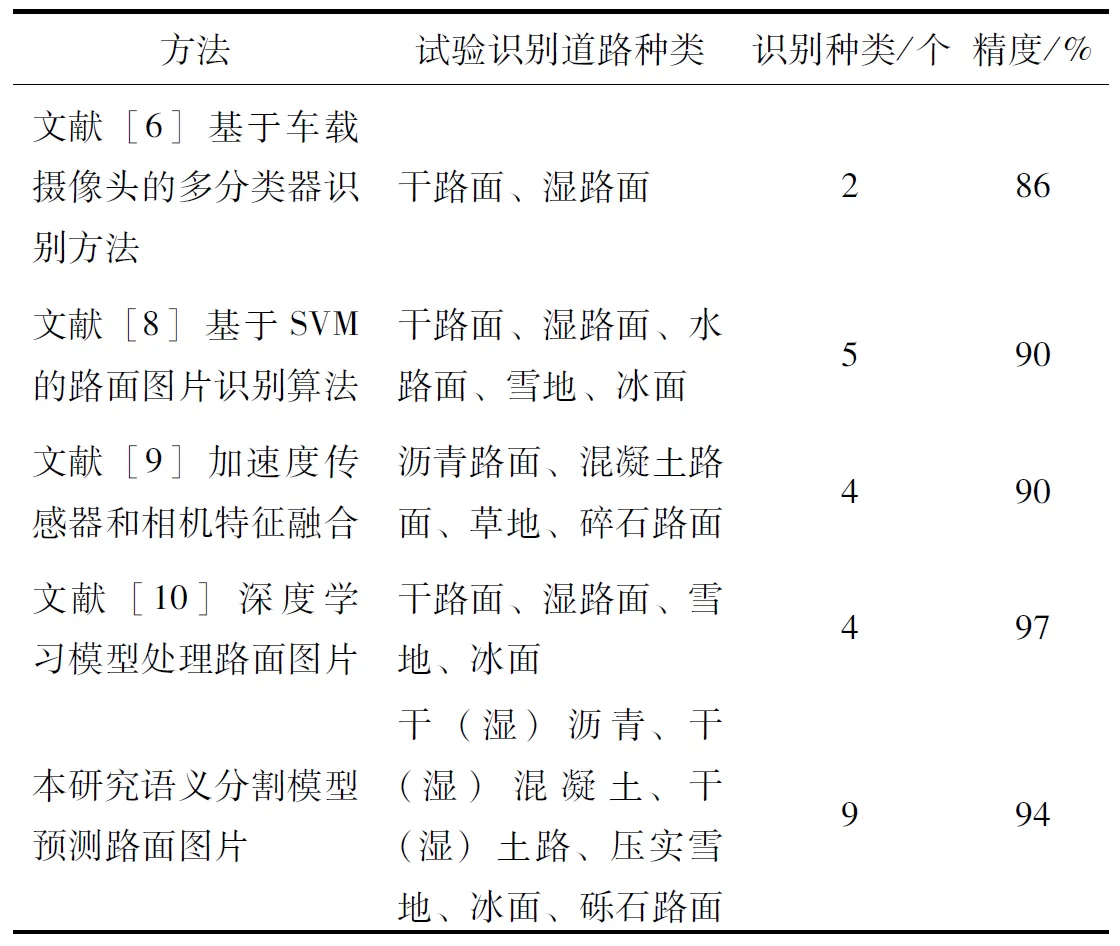
表9 识别效果对比Tab.9 Comparison of recognition effects
5 结论
本研究提出基于语义分割模型识别路面类型的新方法,并通过试验验证得出结论如下:
(1)通过试验验证本研究提出的方法具有较好的识别效果,平均精度可达94%左右。
(2)试验结果表明本方法具有一定的鲁棒性,对于复杂环境下的路面都能有较好的识别效果。
(3)试验结果表明采用本研究提出的方法每张图片的平均测试时间为0.028 6 s,满足实时性的要求。
该方法具有较好的应用前景,能够较容易的嵌入到车辆系统中。将道路类型的预测结果应用到ADAS中可以有效提高行车安全性。在未来的工作中,将会对语义分割模型进行优化,直接输出路面识别类型,减少模型计算参数。同时提高数据集质量,将路面类型所对应的附着系数区间进一步细化,达到路面附着系数更加精确的估计。
猜你喜欢
小猕猴智力画刊(2021年6期)2021-08-05
现代电子技术(2021年1期)2021-01-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
公民与法治(2016年10期)2016-05-17
中国民族医药杂志(2016年5期)2016-05-09
作文大王·低年级(2016年3期)2016-03-11
